Sur l'Internet moderne, plus de 630 millions de sites, mais seulement 6% d'entre eux contiennent du contenu en russe. La barrière de la langue est le principal problème de la diffusion des connaissances entre les utilisateurs du réseau, et nous pensons qu'il doit être résolu non seulement par l'enseignement des langues étrangères, mais également par l'utilisation de la traduction automatique dans le navigateur.
Aujourd'hui, nous allons informer les lecteurs Habr de deux changements technologiques importants dans le traducteur Yandex.Browser. Premièrement, la traduction de certains mots et expressions utilise désormais un modèle hybride, et nous rappelons en quoi cette approche diffère de l'utilisation de réseaux exclusivement neuronaux. Deuxièmement, le réseau neuronal du traducteur prend désormais en compte la structure des pages Web, dont nous discuterons également les caractéristiques sous la coupe.
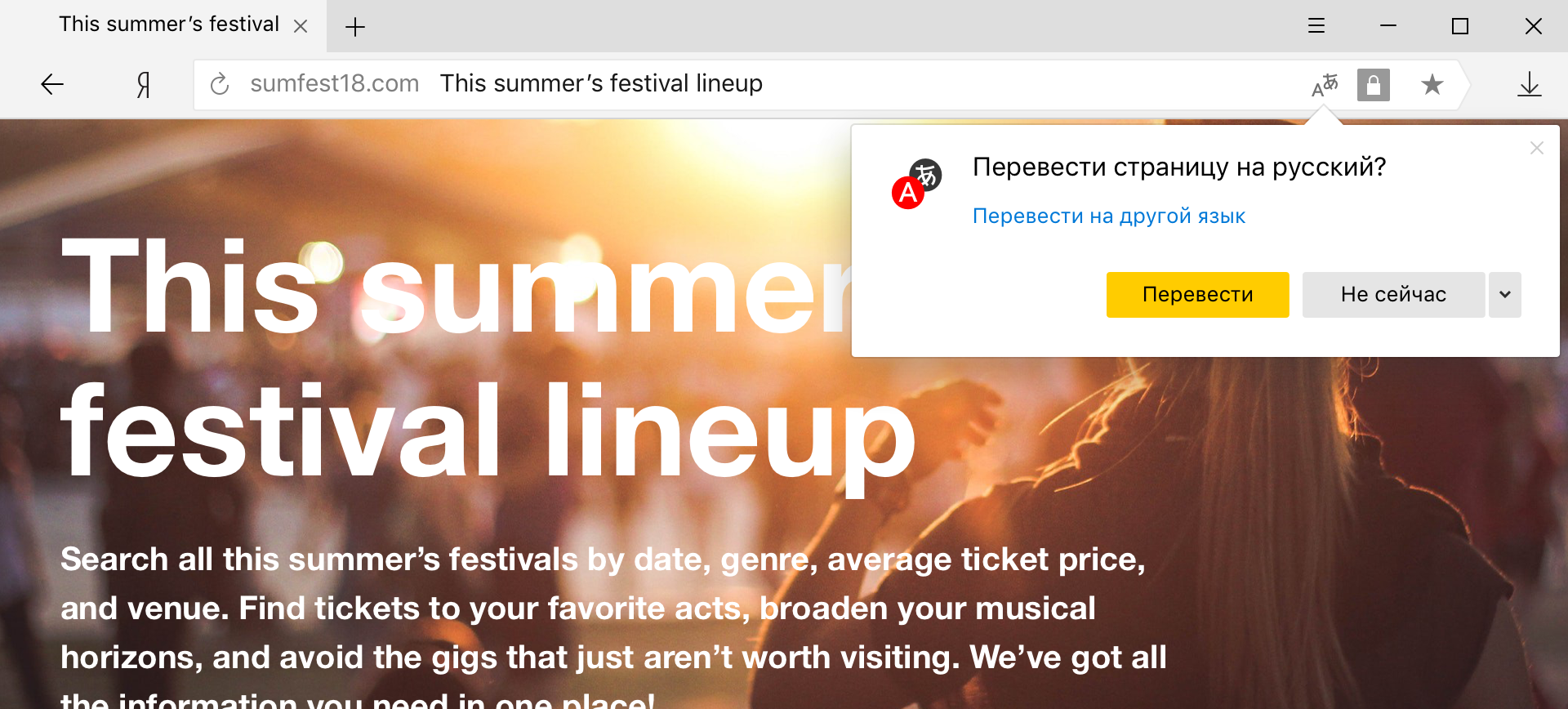
Traducteur hybride de mots et de phrases
Les premiers systèmes de traduction automatique étaient basés sur des
dictionnaires et des règles (en fait, des habitués écrits à la main), qui ont déterminé la qualité de la traduction. Les linguistes professionnels ont travaillé pendant des années pour trouver des règles manuelles de plus en plus détaillées. Ce travail prenait tellement de temps qu'une attention sérieuse n'était accordée qu'aux paires de langues les plus populaires, mais même dans le cadre de celles-ci, les machines se débrouillaient mal. La langue vivante est un système très complexe qui obéit mal aux règles. Il est encore plus difficile de décrire les règles de correspondance des deux langues.
La seule façon dont la machine peut s'adapter en permanence à des conditions changeantes est d'apprendre indépendamment sur un grand nombre de textes parallèles (de sens identique, mais écrits dans des langues différentes). Il s'agit de l'approche statistique de la traduction automatique. L'ordinateur compare des textes parallèles et révèle indépendamment des modèles.
Un
traducteur statistique a à la fois des avantages et des inconvénients. D'une part, il se souvient bien de mots et de phrases rares et complexes. S'ils ont été trouvés dans des textes parallèles, le traducteur s'en souviendra et continuera à traduire correctement. D'un autre côté, le résultat de la traduction peut être similaire au puzzle assemblé: l'image globale semble compréhensible, mais si vous regardez attentivement, vous pouvez voir qu'elle est composée de pièces séparées. La raison en est que le traducteur présente des mots individuels sous la forme d'identificateurs, qui ne reflètent en aucun cas la relation entre eux. Cela ne correspond pas à la façon dont les gens perçoivent le langage lorsque les mots sont déterminés par la façon dont ils sont utilisés, comment ils se rapportent à d'autres mots et comment ils diffèrent d'eux.
Les réseaux de neurones aident à résoudre ce problème. La représentation vectorielle des mots (intégration de mots) utilisée dans la traduction automatique de neurones, en règle générale, correspond à chaque mot avec un vecteur de plusieurs centaines de chiffres. Les vecteurs, contrairement aux identifiants simples issus d'une approche statistique, se forment lors de la formation d'un réseau neuronal et prennent en compte la relation entre les mots. Par exemple, un modèle peut reconnaître qu'étant donné que le «thé» et le «café» apparaissent souvent dans des contextes similaires, ces deux mots devraient être possibles dans le contexte du nouveau mot «déversement», qui, disons, un seul d'entre eux a été trouvé dans les données de formation.
Cependant, le processus d'enseignement des représentations vectorielles est clairement plus exigeant statistiquement que des exemples de mémorisation mécanique. De plus, il n'est pas clair que faire de ces mots d'entrée rares qui n'étaient pas souvent rencontrés suffisamment pour que le réseau puisse construire une représentation vectorielle acceptable pour eux. Dans cette situation, il est logique de combiner les deux méthodes.
Depuis l'année dernière, Yandex.Translator utilise un
modèle hybride . Lorsque le traducteur reçoit du texte de l'utilisateur, il le donne aux deux systèmes - à la fois le réseau neuronal et le traducteur statistique. Ensuite, un algorithme basé sur la méthode de formation
CatBoost évalue quelle traduction est la meilleure. Lors de la notation, des dizaines de facteurs sont pris en compte - de la longueur de la phrase (les phrases courtes sont mieux traduites par le modèle statistique) à la syntaxe. La traduction reconnue comme la meilleure est montrée à l'utilisateur.
C'est le modèle hybride qui est maintenant utilisé dans Yandex.Browser, lorsque l'utilisateur sélectionne des mots et des phrases spécifiques sur la page à traduire.
Ce mode est particulièrement pratique pour ceux qui parlent généralement une langue étrangère et qui souhaitent traduire uniquement des mots inconnus. Mais si, par exemple, au lieu de l'anglais habituel, vous rencontrez du chinois, alors il sera difficile de se passer d'un traducteur de page. Il semblerait que la différence ne concerne que le volume du texte traduit, mais pas si simple.
Traducteur Web Neural Network
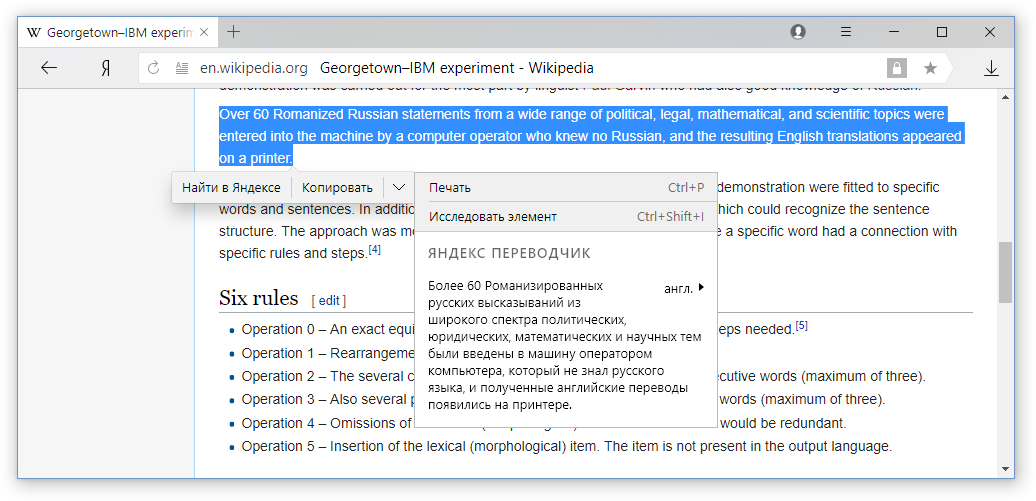
De l'époque de
l'expérience de Georgetown à presque aujourd'hui, tous les systèmes de traduction automatique ont été formés pour traduire chaque phrase du texte source individuellement. Alors qu'une page Web n'est pas seulement un ensemble de phrases, mais un texte structuré dans lequel il y a des éléments fondamentalement différents. Considérez les éléments de base de la plupart des pages.
Cap . Texte généralement clair et volumineux que nous voyons immédiatement lorsque vous accédez à la page. Le titre contient souvent l'essence de l'actualité, il est donc important de la traduire correctement. Mais cela est difficile à faire, car le texte dans le titre est petit et sans comprendre le contexte, vous pouvez faire une erreur. Dans le cas de la langue anglaise, c'est encore plus compliqué, car les titres en langue anglaise contiennent souvent des phrases avec une grammaire non traditionnelle, des infinitifs ou même des verbes manqués. Par exemple, la
préquelle de Game of Thrones a été annoncée .
La navigation Mots et phrases qui nous aident à naviguer sur le site. Par exemple,
Accueil ,
Précédent et
Mon compte ne valent guère la peine d'être traduits par «Accueil», «Précédent» et «Mon compte» s'ils se trouvent dans le menu du site et non dans le texte de la publication.
Le texte principal . Tout est plus simple avec lui, il diffère peu des textes et phrases ordinaires que l'on retrouve dans les livres. Mais même ici, il est important de garantir la cohérence des traductions, c'est-à-dire de veiller à ce qu'au sein d'une même page Web, les mêmes termes et concepts soient traduits de la même manière.
Pour une traduction de haute qualité des pages Web, il ne suffit pas d'utiliser un réseau de neurones ou un modèle hybride - vous devez également prendre en compte la structure des pages. Et pour cela, nous devions faire face à de nombreuses difficultés technologiques.
Classification des segments de texte . Pour ce faire, nous utilisons à nouveau CatBoost et des facteurs basés à la fois sur le texte lui-même et sur le balisage HTML des documents (balise, taille du texte, nombre de liens par unité de texte, ...). Les facteurs sont assez hétérogènes, c'est donc CatBoost (basé sur l'augmentation du gradient) qui affiche les meilleurs résultats (la précision de la classification est supérieure à 95%). Mais la classification des segments ne suffit pas.
Déséquilibre dans les données . Traditionnellement, les algorithmes Yandex.Translator apprennent sur les textes d'Internet. Il semblerait que ce soit une solution idéale pour former un traducteur de pages web (en d'autres termes, le réseau apprend à partir de textes de même nature que les textes sur lesquels nous allons l'utiliser). Mais dès que nous avons appris à séparer les différents segments les uns des autres, nous avons trouvé une fonctionnalité intéressante. En moyenne, le contenu occupe environ 85% de tout le texte des sites Web, tandis que les titres et la navigation ne représentent que 7,5% chacun. Rappelons également que les titres et les éléments de navigation dans le style et la grammaire eux-mêmes sont sensiblement différents du reste du texte. Ensemble, ces deux facteurs conduisent au problème du biais de données. Il est plus rentable pour un réseau de neurones d'ignorer simplement les caractéristiques de ces segments très mal représentés dans l'ensemble d'entraînement. Le réseau apprend à bien traduire uniquement le texte principal, à cause de cela la qualité de la traduction des en-têtes et de la navigation en souffre. Pour neutraliser cet effet désagréable, nous avons fait deux choses: pour chaque paire de phrases parallèles, nous avons attribué l'un des trois types de segments (contenu, titre ou navigation) en tant que méta-informations et augmenté artificiellement la concentration de ces deux derniers dans le bâtiment de formation à 33% du fait que a commencé à montrer des exemples similaires au réseau de neurones d'apprentissage plus souvent.
Apprentissage multi-tâches . Étant donné que nous sommes maintenant en mesure de séparer les textes des pages Web en trois classes de segments, il peut sembler naturel de former trois modèles distincts, chacun devant faire face à la traduction de son propre type de texte - en-têtes, navigation ou contenu. Cela fonctionne vraiment bien, mais le schéma fonctionne encore mieux lorsque nous formons un réseau de neurones pour traduire tous les types de textes à la fois. La clé de la compréhension réside dans l'idée de l'
apprentissage mutli-tâche (MTL): s'il existe une connexion interne entre plusieurs tâches d'apprentissage automatique, un modèle qui apprend à résoudre ces problèmes en même temps peut apprendre à résoudre chacun des problèmes mieux qu'un modèle spécialisé à profil étroit!
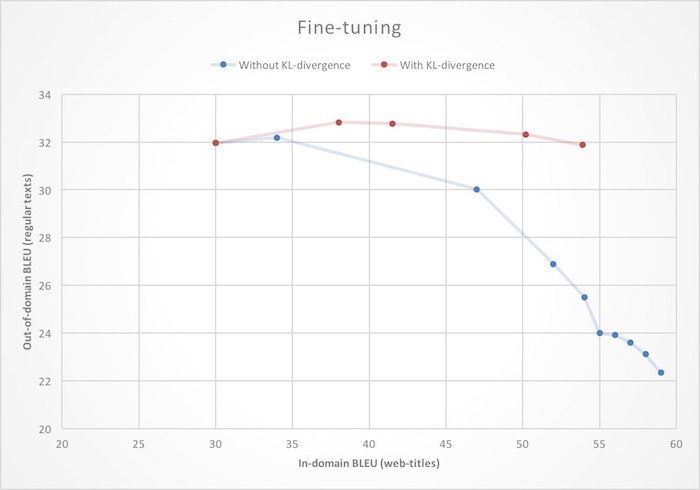
Réglage fin . Nous avions déjà une très bonne traduction automatique, il serait donc déraisonnable de former un nouveau traducteur pour Yandex.Browser à partir de zéro. Il est plus logique de prendre un système de base pour traduire des textes ordinaires et de le recycler pour travailler avec des pages Web. Dans le contexte des réseaux de neurones, cela est souvent appelé réglage fin. Mais si vous abordez cette tâche de front, c'est-à-dire juste pour initialiser les poids du réseau neuronal avec les valeurs du modèle fini et commencer à apprendre sur de nouvelles données, vous pouvez rencontrer l'effet d'un changement de domaine: à mesure que vous apprenez, la qualité de la traduction des pages Web (dans le domaine) augmentera, mais la qualité de la traduction de l'ordinaire (hors domaine) ) les textes tomberont. Pour se débarrasser de cette caractéristique désagréable, lors de la reconversion, nous imposons une restriction supplémentaire au réseau neuronal, lui interdisant de trop modifier les poids par rapport à l'état initial.
Mathématiquement, cela s'exprime en ajoutant le terme à la fonction de perte, qui
est la distance de Kullback - Leibler (divergence KL) entre les distributions de probabilité du mot suivant généré par les réseaux d'origine et recyclés. Comme vous pouvez le voir dans l'illustration, cela conduit au fait que l'augmentation de la qualité de la traduction des pages Web n'entraîne plus la dégradation de la traduction du texte brut.
 Polissage des phrases de fréquence de la navigation
Polissage des phrases de fréquence de la navigation . En train de travailler sur un nouveau traducteur, nous avons collecté des statistiques sur les textes de différents segments de pages Web et en avons vu un intéressant. Les textes relatifs aux éléments de navigation sont assez standardisés, il s'agit donc souvent des mêmes phrases de modèle. C'est un effet si puissant que plus de la moitié de toutes les phrases de navigation trouvées sur Internet ne représentent que 2 000 des phrases les plus fréquentes.
Bien sûr, nous en avons profité et avons donné plusieurs milliers des phrases les plus fréquentes et leurs traductions à nos traducteurs pour vérification afin d'être absolument sûr de leur qualité.
Alignements externes. Il y avait une autre exigence importante pour un traducteur de page Web dans le navigateur - il ne devrait pas fausser le balisage. Lorsque les balises HTML sont situées en dehors des phrases ou à leurs frontières, aucun problème ne se pose. Mais s'il y a, par exemple,
deux mots soulignés à l'intérieur de la phrase, alors dans la traduction, nous voulons voir «deux mots
soulignés ». C'est-à-dire du fait du transfert, deux conditions doivent être remplies:
- Le fragment souligné dans la traduction doit correspondre au fragment souligné dans le texte source.
- La cohérence de la traduction aux frontières du fragment souligné ne doit pas être violée.
Afin d'assurer ce comportement, nous traduisons d'abord le texte comme d'habitude, puis en utilisant des modèles statistiques d'
alignement mot par
mot, nous déterminons la correspondance entre les fragments des textes originaux et traduits. Cela permet de comprendre ce qui doit être souligné (surligné en italique, formaté en hyperlien, ...).
Observateur d'intersection . Les puissants modèles de traduction de réseaux neuronaux que nous avons formés nécessitent beaucoup plus de ressources informatiques sur nos serveurs (CPU et GPU) que les modèles statistiques des générations précédentes. Dans le même temps, les utilisateurs ne lisent pas toujours les pages à la fin, il est donc inutile d'envoyer tout le texte des pages Web dans le cloud. Pour économiser les ressources du serveur et le trafic des utilisateurs, nous avons appris au traducteur à utiliser l'
API Intersection Observer pour envoyer uniquement le texte affiché à l'écran pour la traduction. Pour cette raison, nous avons pu réduire la consommation de trafic de traduction de plus de 3 fois.
Quelques mots sur les résultats de l'introduction d'un traducteur de réseau de neurones prenant en compte la structure des pages web dans Yandex.Browser. Pour évaluer la qualité des traductions, nous utilisons la métrique BLEU *, qui compare les traductions effectuées par une machine et un traducteur professionnel, et évalue la qualité de la traduction automatique sur une échelle de 0 à 100%. Plus la traduction automatique est proche de la traduction humaine, plus le pourcentage est élevé. En règle générale, les utilisateurs remarquent un changement de qualité lorsque la métrique BLEU augmente d'au moins 3%. Le nouveau traducteur Yandex.Browser a montré une augmentation de près de 18%.

La traduction automatique est l'une des tâches les plus complexes, les plus recherchées et les plus recherchées dans le domaine des technologies de l'intelligence artificielle. Cela est dû à son attractivité purement mathématique et à sa pertinence dans le monde moderne, où chaque seconde une quantité incroyable de contenu est créée sur Internet dans différentes langues. La traduction automatique, qui jusqu'à récemment provoquait principalement des rires (souvenez-vous
des fabricants de souris ), aide aujourd'hui les utilisateurs à surmonter les barrières linguistiques.
La qualité idéale est encore loin, nous continuerons donc de nous placer à la pointe de la technologie dans cette direction afin que les utilisateurs de Yandex.Browser puissent aller au-delà, par exemple, Runet et trouver du contenu utile pour eux-mêmes partout sur Internet.