La vision industrielle est un sujet très brûlant de nos jours. Pour résoudre le problème de la reconnaissance des balises de magasin à l'aide de réseaux de neurones, nous avons choisi le framework TensorFlow.
L'article expliquera exactement comment l'utiliser pour localiser et identifier plusieurs objets sur la même étiquette de prix de magasin, ainsi que pour reconnaître son contenu.
Une tâche similaire de reconnaissance des étiquettes de prix IKEA a déjà été résolue sur Habré à l' aide des outils classiques de traitement d'image disponibles dans la bibliothèque OpenCV.
Par ailleurs, je voudrais noter que la solution peut fonctionner à la fois sur la plate-forme SAP HANA en conjonction avec Tensorflow Serving et sur la plate-forme SAP Cloud.
La tâche de reconnaître le prix des marchandises est pertinente pour les acheteurs qui veulent "échanger" les prix entre eux et choisir un magasin pour les achats, et pour les détaillants - ils veulent en savoir plus sur les prix des concurrents en temps réel.
Assez de paroles - allez à la technique!
Boîte à outilsPour la détection et la classification des images, nous avons utilisé des réseaux de neurones convolutionnels implémentés dans la bibliothèque TensorFlow et disponibles pour le contrôle via l'API Object Detection.
L'API de détection d'objets TensorFlow est une métaframe open source basée sur TensorFlow qui simplifie la création, la formation et le déploiement de modèles pour la détection d'objets.
Après avoir détecté l'objet souhaité, la reconnaissance de texte a été effectuée à l'aide de Tesseract, une bibliothèque de reconnaissance de caractères. Depuis 2006, Tesseract est considérée comme l'une des bibliothèques OCR les plus précises disponibles en open source.
Il est possible que vous posiez une question - pourquoi tout le traitement ne se fait-il pas sur TF? La réponse est très simple - il faudrait beaucoup plus de temps pour l'implémentation, mais il n'y en avait pas beaucoup de toute façon. Il était plus facile de sacrifier la vitesse de traitement et d'assembler un prototype fini que de s'embêter avec un OCR fait maison.
Création et préparation d'un jeu de donnéesPour commencer, il fallait collecter des matériaux pour le travail. Nous avons visité 3 magasins et pris environ 400 photos d'étiquettes de prix différentes sur un appareil photo de téléphone portable en mode automatique
Exemples de photos: Fig. 1. Exemple d'image d'étiquette de prix
Fig. 1. Exemple d'image d'étiquette de prix Fig. 2. Exemple d'image d'étiquette de prix
Fig. 2. Exemple d'image d'étiquette de prixAprès cela, vous devez traiter et marquer toutes les photos des étiquettes de prix. Dans le processus de collecte d'images, nous avons essayé de collecter des images de haute qualité (sans artefacts): étiquettes de prix approximativement du même format, sans flou, rotations importantes, etc. Cela a été fait pour faciliter la comparaison du contenu sur le prix réel et de son image numérique. Cependant, si nous formons le réseau neuronal uniquement sur les images de haute qualité disponibles, cela conduira très naturellement au fait que la confiance du modèle dans l'identification des exemples déformés diminuera considérablement. Afin d'entraîner le réseau neuronal à résister à de telles situations, nous avons utilisé la procédure bien connue pour élargir l'ensemble d'entraînement avec des versions déformées d'images (augmentation). Pour compléter l'échantillon d'apprentissage, nous avons appliqué des algorithmes de la bibliothèque Imgaug: décalages, petits virages, flou gaussien, bruit. Des images déformées ont été ajoutées à l'échantillon, ce qui l'a augmenté d'environ 5 fois (de 300 à 1 500 images).
Pour marquer l'image et sélectionner des objets, le programme LabelImg a été utilisé, qui est disponible dans le domaine public. Il vous permet de sélectionner les objets nécessaires dans l'image avec un rectangle et d'affecter chaque classe au cadre de sélection. Toutes les coordonnées et les étiquettes des cadres créés pour chaque photo sont enregistrées dans un fichier XML distinct.
Les objets suivants se démarquent sur chaque photo: étiquette de prix du produit, prix du produit, nom du produit et code-barres du produit sur l'étiquette de prix. Dans certains exemples d'images, où cela était logiquement justifié, les zones étaient marquées par un chevauchement.
 Fig. 3. Un exemple de photographie d'une paire d'étiquettes de prix marquées dans LabelImg. Les zones avec la description du produit, le prix et le code-barres sont mises en évidence.
Fig. 3. Un exemple de photographie d'une paire d'étiquettes de prix marquées dans LabelImg. Les zones avec la description du produit, le prix et le code-barres sont mises en évidence. Fig. 4. Un exemple de photographie d'une étiquette de prix marquée dans LabelImg. Les zones avec la description du produit, le prix et le code-barres sont mises en évidence.
Fig. 4. Un exemple de photographie d'une étiquette de prix marquée dans LabelImg. Les zones avec la description du produit, le prix et le code-barres sont mises en évidence.Une fois que toutes les photos ont été traitées et marquées, nous préparons l'ensemble de données avec la séparation de toutes les photos et des fichiers de balises en un échantillon de formation et de test. Prenez habituellement 80% de l'échantillon d'apprentissage à 20% de l'échantillon d'essai et mélangez au hasard.
Ensuite, sur la machine où le modèle sera formé, il est nécessaire d'installer toutes les bibliothèques nécessaires. Tout d'abord, nous installons la bibliothèque d'apprentissage automatique TensorFlow. Selon le type de votre système et vous devez installer une bibliothèque supplémentaire pour l'informatique sur le GPU. Ensuite, installez la bibliothèque d'API de détection d'objets Tensorflow et des bibliothèques supplémentaires pour travailler avec des images et des graphiques. Voici une liste des bibliothèques que nous avons utilisées dans notre travail:
TensorFlow-GPU v1.5, CUDA v9.0, cuDNN v7.0
Protobuf 3+, Python-tk, Pillow 1.0, lxml, tf Slim, notebook Jupyter, Matplotlib
Tensorflow, Cython, Cocoapi; Opencv-python; PandasUne fois toutes les étapes d'installation terminées, vous pouvez procéder à la préparation des données et à la définition des paramètres d'apprentissage.
Formation modèlePour résoudre notre problème, nous avons utilisé deux versions du réseau neuronal pré-formé MobileNet V2 et Faster-RCNN V2 sur le jeu de données coco comme extracteurs de propriétés d'image. Les modèles ont été recyclés en 4 nouvelles classes: étiquette de prix, description du produit, prix, code-barres. Comme principal, nous avons choisi MobileNet V2, qui est un modèle relativement simple qui nous permet de fournir une qualité acceptable à une vitesse agréable. MobileNet V2 vous permet d'implémenter la reconnaissance d'image même sur un appareil mobile.
Tout d'abord, vous devez indiquer à la bibliothèque d'API de détection d'objets Tensorflow le nombre d'étiquettes, ainsi que les noms de ces étiquettes.
La dernière chose à faire avant l'entraînement est de créer un raccourci et de modifier le fichier de configuration. La mappe d'étiquettes informe le modèle et mappe les noms de classe aux numéros d'identification de classe pour chaque objet.

Enfin, vous devez configurer les sources d'apprentissage pour la détection d'objets pour déterminer quel modèle et quels paramètres seront utilisés pour la formation. C'est la dernière étape avant de commencer l'entraînement.

La procédure de formation est lancée par la commande:
python train.py --logtostderr --train_dir=training/ --pipeline_config_path=training/mobilenet.config
Si tout est correctement configuré, TensorFlow initialise le recyclage du réseau neuronal. L'initialisation peut prendre jusqu'à 30 secondes avant le début de la formation proprement dite. Comme le réseau neuronal est recyclé à chaque étape, la valeur de la fonction d'erreur d'algorithme (perte) sera affichée. Pour MobileNet V2, la valeur initiale de la fonction de perte est d'environ 20. Le modèle doit être formé jusqu'à ce que la fonction de perte tombe à une valeur d'environ 2. Pour visualiser le processus d'apprentissage du réseau de neurones, vous pouvez utiliser l'utilitaire pratique TensorBoard.
: tensorboard
La commande initialise l'interface Web sur la machine locale, qui sera disponible sur localhost: 6006. Après l'arrêt, la procédure de formation peut être reprise plus tard à l'aide de points de contrôle enregistrés toutes les 5 minutes.
Reconnaissance des étiquettes de prix et de ses élémentsUne fois la formation terminée, la dernière étape consiste à créer un graphe de réseau neuronal. Cela se fait par la commande console, où sous les astérisques vous devez spécifier le plus grand nombre de fichiers cpkt existant dans le répertoire de formation.
python export_inference_graph.py --input_type image_tensor --pipeline_config_path training/faster_rcnn_inception_v2.config --trained_checkpoint_prefix training/model.ckpt-**** --output_directory inference_graph
Après cette procédure, le classificateur de détection d'objet est prêt à fonctionner. Pour vérifier la reconnaissance d'image, il suffit d'exécuter un script fourni avec la bibliothèque de détection d'objets Tensorflow indiquant le modèle qui a été précédemment formé et les photos à reconnaître. Un exemple de script Python standard est fourni
ici .
Dans notre exemple, il faut environ 1,5 seconde pour reconnaître une photo à l'aide du modèle ssd mobilenet sur un simple ordinateur portable.
 Fig. 5. Le résultat de la reconnaissance d'images avec des étiquettes de prix dans l'échantillon de test
Fig. 5. Le résultat de la reconnaissance d'images avec des étiquettes de prix dans l'échantillon de test Fig. 6. Le résultat de la reconnaissance d'images avec des étiquettes de prix dans l'échantillon d'essai
Fig. 6. Le résultat de la reconnaissance d'images avec des étiquettes de prix dans l'échantillon d'essaiLorsque nous sommes convaincus que les étiquettes de prix sont détectées normalement, il est nécessaire d'apprendre au modèle à lire les informations des éléments individuels: le prix des marchandises, le nom des marchandises et un code à barres. Pour cela, il existe des bibliothèques disponibles en Python pour reconnaître les caractères et codes-barres dans les photographies - Pyzbar et Tesseract.
Avant de commencer à reconnaître les caractères et les codes-barres d'une photo, vous devez découper cette photo en éléments dont nous avons besoin - afin d'augmenter la vitesse et de ne pas reconnaître les informations inutiles qui ne sont pas incluses dans le prix. Il est également nécessaire de «retirer» les coordonnées des objets que le modèle a reconnus avec leurs classes.

Ensuite, nous utilisons ces coordonnées pour couper notre photo en parties afin de reconnaître uniquement la zone nécessaire.


 Fig. 7. Un exemple de parties en surbrillance de l'étiquette de prix
Fig. 7. Un exemple de parties en surbrillance de l'étiquette de prixEnsuite, nous transférons toutes les zones de découpe dans les bibliothèques: le nom du produit et le prix du produit sont transférés vers tesseract, et le code-barres vers pyzbar, et nous obtenons le résultat de la reconnaissance.

 Fig. 8. Un exemple de contenu reconnu est la zone d'étiquette de prix.
Fig. 8. Un exemple de contenu reconnu est la zone d'étiquette de prix.À ce stade, la reconnaissance du texte et des codes à barres peut entraîner des problèmes si l'image d'origine était en basse résolution ou floue. Si le prix peut être reconnu normalement en raison des grands nombres sur l'étiquette de prix, alors le nom du produit et le code-barres seront mal définis ou pas du tout définis. Pour ce faire, il est recommandé de ne pas utiliser de petites photos pour la reconnaissance, et également de télécharger des images sans bruit et forte distorsion - par exemple, sans le manque de mise au point appropriée.
Exemple de reconnaissance d'image incorrecte:



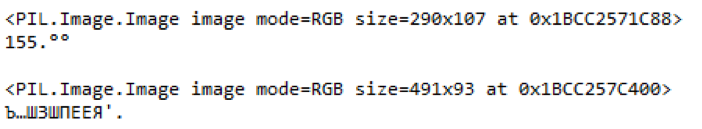 Fig. 9. Un exemple de parties en surbrillance d'une étiquette de prix floue et d'un contenu reconnu
Fig. 9. Un exemple de parties en surbrillance d'une étiquette de prix floue et d'un contenu reconnuDans cet exemple, vous pouvez voir que si le prix des marchandises était reconnu plus ou moins correctement à l'image de la mauvaise qualité, la bibliothèque ne pourrait pas gérer le nom des marchandises. Et le code-barres n'est pas du tout reconnu.
Le même texte de bonne qualité.

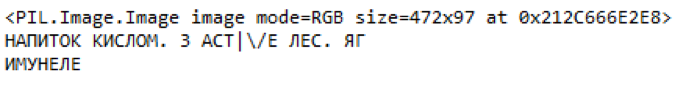 Fig. 10. Exemple de pièces d'étiquette de prix mises en évidence et de contenu reconnuConclusions
Fig. 10. Exemple de pièces d'étiquette de prix mises en évidence et de contenu reconnuConclusionsAu final, nous avons réussi à obtenir un modèle de qualité acceptable avec un faible pourcentage d'erreurs et un pourcentage élevé de détection d'objets pertinents. Faster-RCNN Inception V2 a une meilleure qualité de reconnaissance que MobileNet SSD V2, mais est d'environ un ordre de grandeur inférieur à la vitesse, ce qui est une limitation importante.
La précision obtenue de la reconnaissance des étiquettes de prix sur un échantillon retardé de 50 images est de 100%, c'est-à-dire que toutes les étiquettes de prix ont été identifiées avec succès sur toutes les photos. La précision de reconnaissance des zones avec un code-barres et un prix était de 90%. La précision de reconnaissance de la zone de texte est de 85%. La précision de la lecture des prix était d'environ 95%, et le texte - 80-85%. De plus, à titre expérimental, nous présentons le résultat de la reconnaissance des étiquettes de prix, qui est complètement différent des étiquettes de prix dans l'échantillon de formation.
 Fig. 11. Un exemple de reconnaissance d'étiquettes de prix atypiques qui ne font pas partie de l'ensemble de formation.
Fig. 11. Un exemple de reconnaissance d'étiquettes de prix atypiques qui ne font pas partie de l'ensemble de formation.Comme vous pouvez le voir, même avec des étiquettes de prix qui sont sensiblement différentes des étiquettes de prix de formation, les modèles ne sont pas sans erreurs, mais des objets importants peuvent être reconnus sur l'étiquette de prix.
Que pourrait-on faire d'autre?1) Un article intéressant sur l'augmentation automatique a récemment été publié, dont l'approche peut être utilisée
2) Le modèle formé fini peut et doit être sensiblement comprimé
3) Exemples de publication de services finis dans SCP et TFS
Pour préparer le prototype et cet article, les matériaux suivants ont été utilisés:1.
Apporter le Machine Learning (TensorFlow) à l'entreprise avec SAP HANA2.
Fondation SAP Leonardo ML - Apportez votre propre modèle (BYOM)3.
Référentiel GitHub de détection d'objets TensorFlow4.
Article sur la reconnaissance des chèques IKEA5.
Article sur les avantages de MobileNet6.
Article sur la détection d'objets TensorFlowL'article a été préparé par:
Sergey Abdurakipov, Dmitry Buslov, Alexey Khristenko