 Photo: Alexander Korolkov / WG
Photo: Alexander Korolkov / WGLe 3 juin, dernier jour du Festival du livre de Moscou sur la Place Rouge, le linguiste
Alexander Pipersky a parlé de linguistique informatique. Il a parlé des traductions automatiques, des réseaux de neurones, de la cartographie vectorielle des mots et a soulevé des questions sur les limites de l'intelligence artificielle.
Différentes personnes ont écouté la conférence. À ma droite, par exemple, une touriste chinoise lui a picoré le nez. Alexander, à coup sûr, a également compris - quelques chiffres, formules et mots supplémentaires sur les algorithmes, et les gens s'enfuiraient vers la tente suivante pour écouter les écrivains de science-fiction.
J'ai demandé à Alexandre de préparer pour Habr la "version de mise en scène" de la conférence, où rien n'a été découpé qui pourrait endormir les touristes au hasard. Après tout, la plupart de la présentation manquait d'audience avec des questions sensées et généralement une bonne discussion. Je pense que nous pouvons le développer ici.
Où commence l'IA?
Depuis récemment, nous communiquons constamment avec des ordinateurs en voix, et toutes sortes de voix Alice, Alexa et Siri nous répondent. Si vous regardez de côté, il semble que l'ordinateur nous comprenne, donne des listes de sites pertinents, signale l'adresse du restaurant le plus proche, indique comment y accéder.
Il semble que nous ayons affaire à un appareil assez intelligent. On pourrait même dire que cet appareil possède ce qu'on appelle l'intelligence artificielle (IA). Bien que personne ne comprenne vraiment ce que cela signifie et où vont les frontières.
Quand on nous dit, "l'IA remplit des fonctions créatives qui sont considérées comme l'apanage de l'homme" - qu'est-ce que cela signifie? Quelles sont les fonctionnalités créatives? Quelle fonction est créative et laquelle ne l'est pas? Choisir le restaurant chinois le plus proche est une fonctionnalité créative? Maintenant, il semble que non.
Nous sommes constamment enclins à refuser l'intelligence artificielle à un ordinateur. Dès que nous nous habituons aux manifestations intellectuelles d'un ordinateur, nous disons: «ce n'est pas de l'IA, c'est du non-sens complet, des tâches de modèle, rien d'intéressant».
Un exemple simple - de notre point de vue, il n'y a rien de plus stupide qu'une calculatrice de poche. Il est vendu dans n'importe quel stand pour 50 roubles. Prenez la calculatrice huit bits habituelle, piquez sur les boutons et obtenez le résultat en quelques secondes. Eh bien, vous pensez, il pense à certaines choses. Ce n'est pas de l'intelligence.
Et imaginez une telle machine au XVIIIe siècle. Cela semblerait être un miracle, car le calcul était l'apanage de l'homme.
La même chose se produit avec la linguistique informatique. Nous avons tendance à mépriser toutes ses réalisations. J'entre dans Google une requête "Versets de Pouchkine", il trouve une page qui dit "A.S. Pouchkine - Poèmes. " Il semblerait que cela? Comportement absolument normal. Mais les linguistes informaticiens ont dû passer des dizaines d'années pour que le mot poème se trouve dans les mots poèmes, pour que le mot Pouchkine se trouve dans le mot Pouchkine et ne se trouve pas dans Pouchkine.
Échecs informatiques et traduction automatique
La linguistique informatique est née en même temps que les échecs informatiques - et les échecs, aussi, étaient autrefois la prérogative de l'homme. Claude Shannon, l'un des fondateurs de l'informatique, a écrit
un article en 1950
sur la façon de programmer un ordinateur pour jouer aux échecs. Selon lui, on peut développer deux types de stratégies.
A - avec recherche exhaustive des suites. Il est nécessaire de tester tous les mouvements possibles à chaque étape.
B - itérer uniquement sur les extensions jugées prometteuses.
La personne, évidemment, utilise la stratégie B. Le grand maître, très probablement, ne passe que par les options qui sont raisonnables à son avis, et dans un temps assez rapide donne un bon coup.
La stratégie A est difficile à mettre en œuvre. Selon le calcul de Shannon, pour compter trois mouvements, vous devez trier 10
9 options, et si la position est estimée à une microseconde (ce qui était super optimiste au milieu du 20ème siècle), alors il faudra 17 minutes pour faire un mouvement. Et trois pas en avant est une profondeur de prédiction insignifiante.
Toute l'histoire ultérieure des échecs consiste à développer des techniques qui nous permettront de ne pas tout trier, mais de comprendre ce qui doit être trié et ce qui n'est pas nécessaire. Et la victoire sur l'homme a déjà été remportée, enfin et irrévocablement. L'ordinateur a contourné le champion du monde d'échecs il y a environ 20 ans et n'a fait que s'améliorer depuis.
Le meilleur programme a été considéré comme Stockfish. L'année dernière, AlphaZero a joué 100 matchs avec elle.
| Blancs | Noir | Victoire blanche | Dessiner | Victoire des Noirs |
|---|
| AlphaZero | Stockfish | 25 | 25 | 0 |
| Stockfish | AlphaZero | 0 | 47 | 3 |
AlphaZero est un réseau neuronal artificiel qui vient de jouer aux échecs pendant quatre heures avec lui-même. Et elle a appris à jouer mieux que tous les programmes avant elle.
Une chose similaire se produit actuellement en linguistique informatique - une augmentation de la modélisation des réseaux de neurones. Ils ont commencé à travailler sur les échecs machine simultanément avec des traductions automatiques - au milieu du siècle dernier. Depuis lors, trois stades de développement ont été distingués.
- Traduction automatique basée sur des règlesIl est conçu très simplement - quelque chose comme dans les cours de grammaire, l'ordinateur sélectionne le sujet, le prédicat, l'addition. Il comprend avec quels mots tout cela est traduit dans une autre langue, apprend à y exprimer le sujet, le prédicat, l'addition et tout.
Une telle traduction s'est développée sur 30 ans, sans grand succès.
- Traduction statistique (phrase)L'ordinateur s'appuie sur une grande base de données de textes traduits par l'homme. Il sélectionne les mots et les phrases qui correspondent aux mots et aux phrases de l'original, les rassemble en phrases dans la langue cible et donne le résultat.
Quand sur Internet, ils écrivent sur les «20 traductions automatiques les plus stupides» - il s'agit très probablement de la traduction de phrases. Bien qu'il ait obtenu un certain succès.
- Traduction du réseau de neuronesNous parlerons plus de lui. Il a fait son entrée en masse sous nos yeux: Google a activé la traduction du réseau de neurones fin 2016. Pour le russe, il est apparu en mars 2017. Yandex a lancé fin 2017 un système hybride basé sur des réseaux de neurones et des statistiques.
Réseaux de neurones
La traduction du réseau de neurones est basée sur l'idée suivante: si simuler et reproduire mathématiquement le travail des neurones dans la tête d'une personne, on peut supposer qu'un ordinateur apprendra à travailler avec une langue comme une personne.
Pour ce faire, jetez un œil aux cellules du cerveau humain.
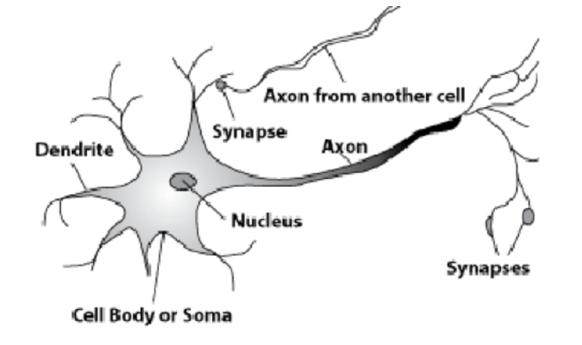
Voici un neurone naturel. Un long processus, un axone, s'écarte du noyau. Il s'attache aux processus d'autres cellules - les synapses. Selon les axones, des informations sur certains processus électrochimiques sont transmises aux synapses des cellules cellulaires. Un seul axone émerge de chaque cellule et de nombreuses synapses peuvent entrer. Les signaux se propagent, et c'est ainsi que les informations sont transmises.
Certaines cellules sont connectées au monde extérieur. Ils reçoivent des signaux qui sont ensuite traités par le réseau neuronal.
Et voici le modèle mathématique le plus simple de ce que nous pouvons faire ici. J'ai dessiné neuf cercles connectés. Ce sont des neurones.

Les six neurones à gauche sont la couche d'entrée, qui reçoit un signal de l'environnement externe. Les neurones des deuxième et troisième couches ne touchent pas l'environnement, mais uniquement avec d'autres neurones. Nous introduisons la règle - si au moins deux flèches de neurones activés pénètrent dans le neurone, alors ce neurone est également activé.
Le réseau neuronal traite le signal reçu à l'entrée et, finalement, la bonne sortie - le neurone s'allume ou ne s'allume pas. Avec cette architecture, pour activer le neurone droit, vous avez besoin d'au moins quatre neurones activés dans la rangée de gauche. Si 6 ou 5 est allumé, il s'allumera certainement, si de 0 à 3, il ne s'allumera certainement pas. Mais si quatre brûlent, il ne s'allumera que s'ils sont répartis uniformément: 2 dans la moitié supérieure et 2 dans la partie inférieure.
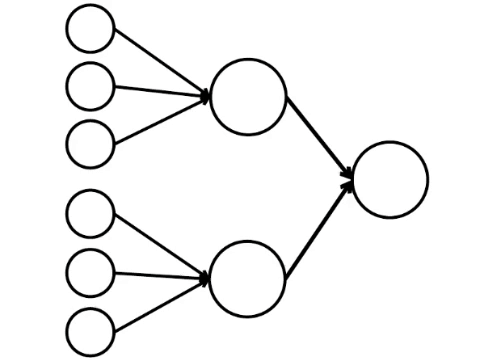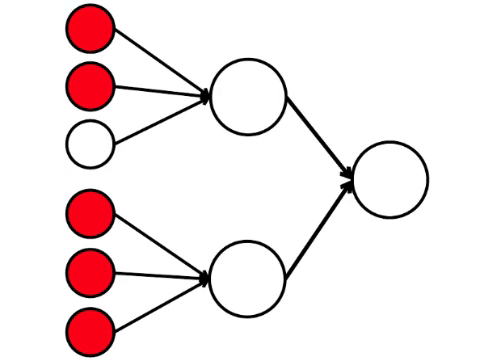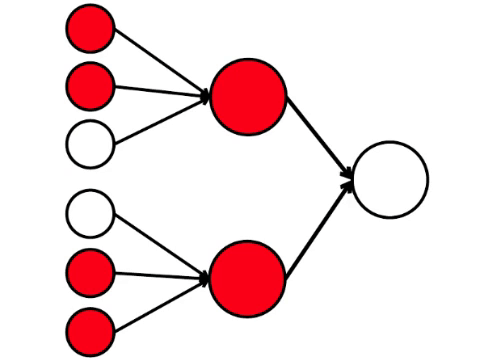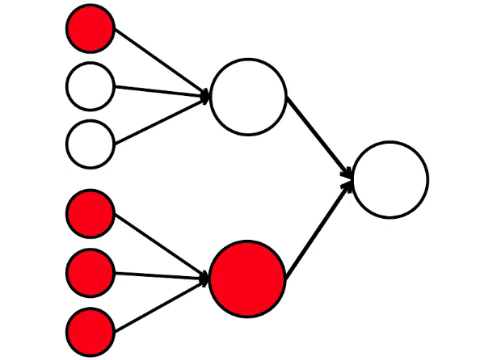
Il s'avère que le schéma le plus simple de neuf cercles conduit à un argument plutôt ramifié.
Les réseaux de neurones artificiels fonctionnent à peu près de la même manière, mais généralement pas avec des choses aussi simples que «éclairé / non éclairé» (c'est-à-dire 1 ou 0), mais avec des nombres réels.
Prenons par exemple un réseau de 5 neurones - deux dans la couche d'entrée, deux au milieu (caché) et un en sortie. Entre tous les neurones des couches voisines, il existe des connexions auxquelles des numéros sont attribués - des poids. Pour savoir ce qui se passe dans un neurone encore vide, faisons une chose très simple: voyons quelles connexions y mènent, multiplions le poids de chaque connexion par le nombre qui est écrit dans le neurone de la couche précédente d'où provient cette connexion, et nous résumerons tout cela. Dans le neurone vert supérieur du diagramme, on obtient 50 × 1 + 3 × 10 = 80 et dans le neurone inférieur - 50 × 0,5 - 3 × 10 = −5.
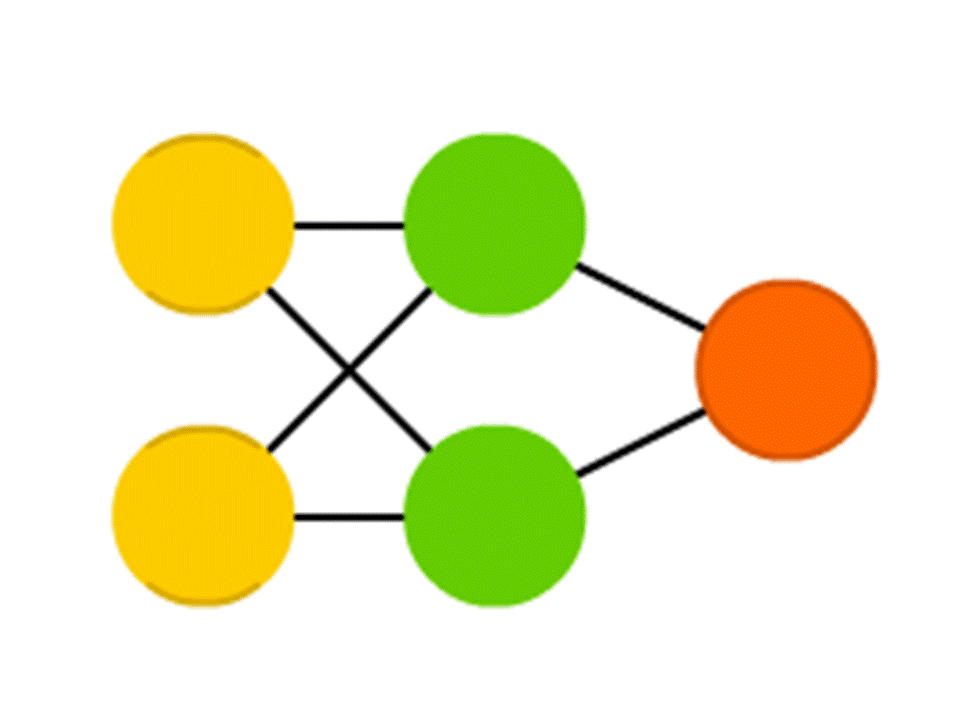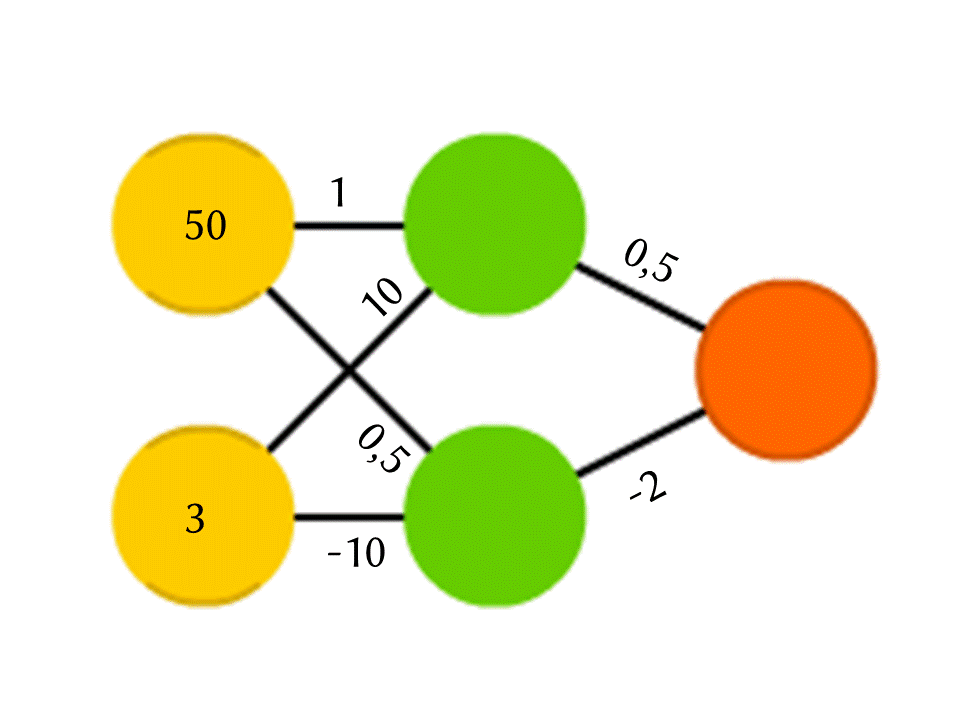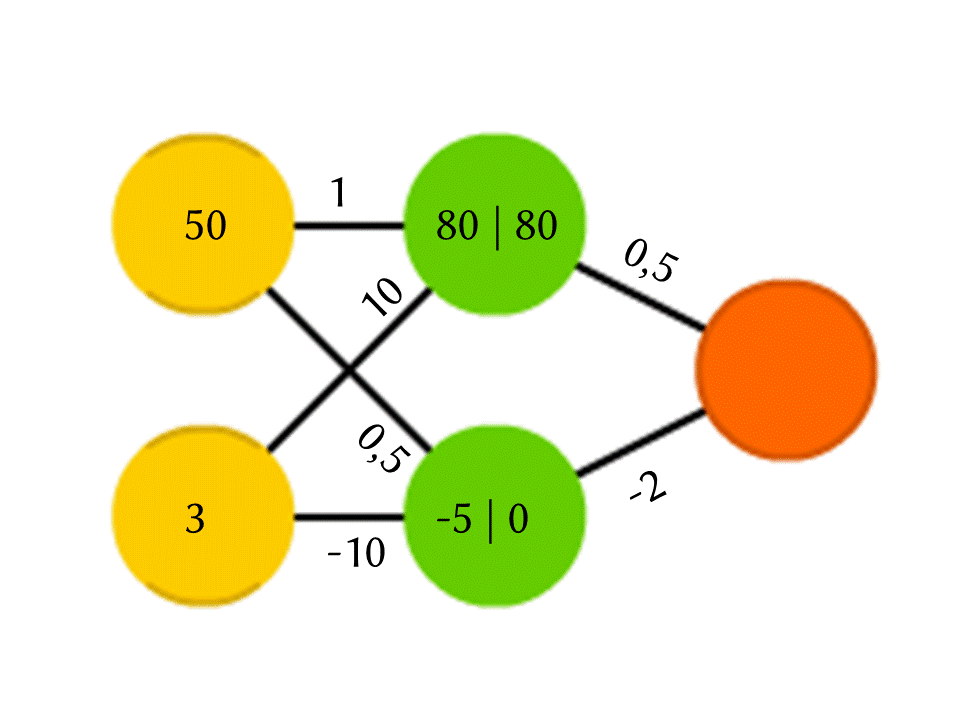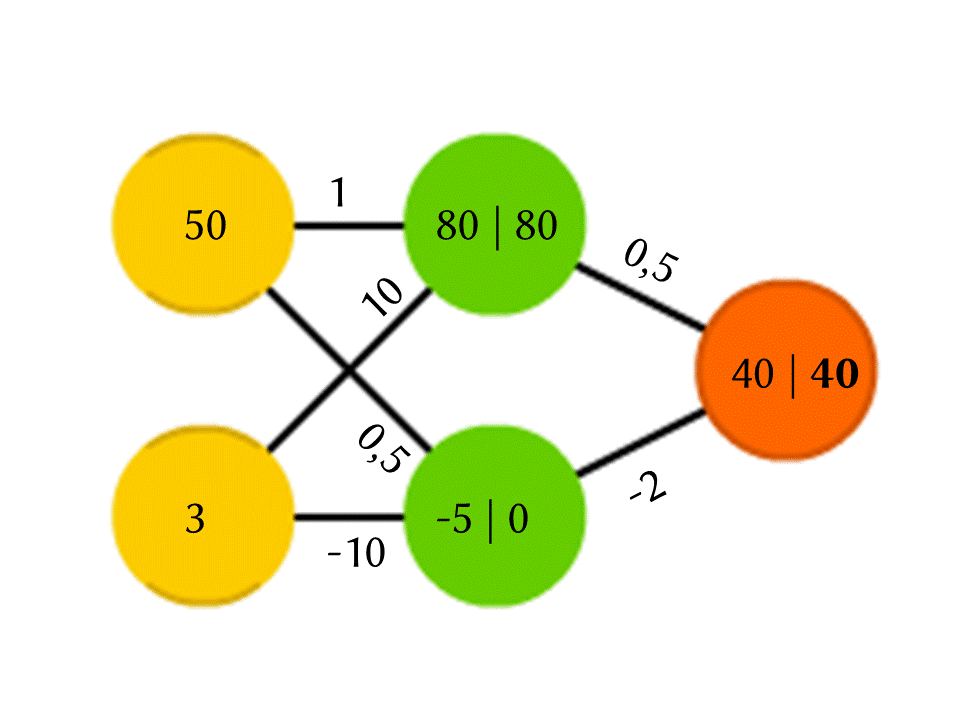
Cependant, si vous faites juste cela, la sortie sera simplement le résultat du calcul d'une fonction linéaire des valeurs d'entrée (dans notre exemple, 25 Y - 0,5 X sortiront, où X est le nombre dans le neurone jaune supérieur et Y est dans le neurone inférieur), donc quelque chose d'autre se passe à l'intérieur du neurone. La fonction la plus simple et en même temps donnant de bons résultats est ReLU (Rectified Linear Unit): si un nombre négatif est obtenu dans un neurone, sortez 0, et s'il n'est pas négatif, sortez-le inchangé.
Donc, dans notre schéma, −5 à la sortie du neurone vert inférieur se transforme en 0, et c'est ce nombre qui est utilisé dans d'autres calculs. Bien sûr, l'architecture des réseaux de neurones réels utilisés dans la pratique est beaucoup plus compliquée que nos exemples de jouets, et les poids ne sont pas pris au plafond, mais sont sélectionnés par la formation, mais le principe lui-même est important.
Qu'est-ce que cela a à voir avec la langue?
La plus directe, à condition de représenter la langue sous forme de chiffres. Nous encodons chaque mot et rencontrons un tel réseau de neurones.
Ici, une réalisation très importante de la linguistique informatique vient à la rescousse, apparue en termes d'idées il y a 50 ans, et en termes de mise en œuvre, les 10 dernières années se sont activement développées: la représentation vectorielle des mots.
 ceci et les deux photos suivantes sont extraites d'une présentation de Stefan Evert
ceci et les deux photos suivantes sont extraites d'une présentation de Stefan EvertIl s'agit d'une représentation des mots comme un tableau de nombres basé sur une considération très simple. Pour découvrir la signification d'un mot, nous ne regardons pas le dictionnaire, mais d'énormes tableaux de texte et considérons à côté de quoi notre mot est plus courant.
Par exemple, connaissez-vous le mot silencieux? Sinon, essayez de deviner en regardant les textes où le mot est étouffé.
- Un manteau noir et une casquette blanche. Eh bien, et toujours un silencieux indispensable ...
À côté de lui se trouvent des vêtements, un manteau et une casquette, et probablement un silencieux parmi eux. Ce n'est guère de la nourriture, à peine un élément de l'architecture.
- Pour une raison quelconque, sur son cou dans une nuit étouffante, un vieux silencieux rayé a été saupoudré.
Sur le cou - cela signifie qu'ils ne sont pas des chaussettes. Vous pouvez l'attraper - apparemment, il est flexible, en tissu et non pas en bois ou en pierre.
- Une serviette gaufrée kutsey Nerzhin était accrochée à son cou comme un silencieux.
Nous reconstituons et reconstituons la banque d'exemples et, en les regardant, nous comprendrons progressivement ce qui est étouffé - quelque chose comme un foulard. L'ordinateur fait exactement la même chose, qui regarde le texte et fait une chose simple - il capture les mots qui se trouvent à proximité.
Voici les hiéroglyphes égyptiens.
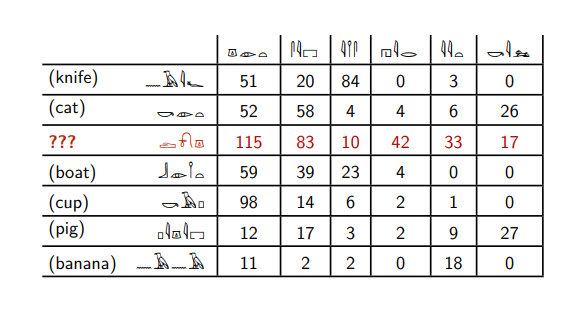
Supposons que vous connaissiez la signification de six d'entre eux et que vous vouliez comprendre quel type de mot est surligné en rouge. Ce tableau indique combien de fois ces mots se trouvent à côté d'autres hiéroglyphes égyptiens.
Le mot rouge apparaît avec le sixième mot - tout comme les mots
chat et
cochon . Et d'autres mots ne se produisent pas du tout avec lui.
Le mot rouge se retrouve beaucoup plus souvent avec le deuxième mot qu'avec le troisième, contrairement aux mots
couteau et
banane . Les mots
chat, bateau, cochon et
tasse se comportent de la même manière.
Sur la base d'un tel raisonnement, nous pouvons dire que le mot rouge est le plus similaire aux mots
chat et
porc - seulement ils rencontrent le sixième mot, ils ont un rapport similaire entre le deuxième et le troisième.
Et nous ne nous tromperons pas, car le mot rouge est le mot
chien .

En fait, ce ne sont pas des hiéroglyphes égyptiens, mais des noms et des verbes anglais, pour lesquels il est indiqué combien de fois ils apparaissent ensemble dans une grande collection de textes anglais. Ce sixième mot est le verbe
tuer .
Les mots
chat, chien et
cochon se trouvent souvent à droite du mot
tuer . Les couteaux, les bateaux et les bananes sont rarement tués. Bien qu'en russe, si vous le souhaitez, vous pouvez dire: «J'ai tué mon bateau», mais c'est une chose rare.
Exactement ce que fait un ordinateur lorsqu'il traite du texte. Il croit simplement qu'il rencontre quelque chose, et plus de chefs-d'œuvre de compréhension.
De plus, l'ordinateur présente les mots sous la forme d'un certain ensemble de nombres: dans l'exemple ci-dessus, le mot
chien correspond à des nombres (115; 83; 10; 42; 33; 17). En fait, nous devons calculer combien de fois cela se produit non pas avec six mots, mais avec tous les mots qui sont dans nos textes: si nous avons tous 100 000 mots différents, alors nous associons le mot
chien à un tableau de 100 000 nombres. Ce n'est pas très pratique dans la pratique, par conséquent, les méthodes de réduction de la dimension sont généralement utilisées pour convertir les résultats de chaque mot en un tableau de plusieurs centaines d'éléments (vous trouverez plus d'informations à ce sujet
ici ).
Il existe des bibliothèques prêtes à l'emploi pour les langages de programmation qui vous permettent de le faire: par exemple,
gensim pour Python. En lui soumettant le
corpus de langue brownienne anglaise avec un volume d'environ 1 million de mots, en quelques secondes je peux construire un modèle dans lequel le mot
chat ressemblera à ceci:

Nous représentons un animal, avec des cheveux, une queue, ça miaule. Mon ordinateur, auquel j'ai enseigné l'anglais, représente le mot
chat sous la forme d'une centaine de chiffres provenant des mots à côté.
Voici un exemple en russe du site
RusVectōres . J'ai pris le mot
corbeau et j'ai demandé à l'ordinateur de me dire quels mots lui ressemblaient le plus - ou, en d'autres termes, les ensembles de nombres pour lesquels les mots étaient les plus similaires à l'ensemble de nombres du mot
corbeau .

8 mots sur 10 se sont avérés être des noms d'oiseaux. Ne sachant rien, l'ordinateur a produit un excellent résultat - j'ai réalisé que les oiseaux ressemblaient à un corbeau. Mais d'où venaient les mots chauffés au rouge et ruchenka?
Vous pouvez devinerAvec les trois, le mot blanc est souvent utilisé: à la chaleur blanche, sous les poignées blanches, le corbeau blanc.
En recevant des tableaux de nombres et en les passant par eux-mêmes, les réseaux de neurones donnent un résultat incroyablement bon. Voici un texte philosophique assez compliqué d'un discours de l'académicien Andrei Zaliznyak sur le statut de la science dans le monde moderne. Il a été traduit en anglais par un traducteur il y a un mois et ne nécessite qu'une intervention éditoriale minimale.

C'est là que se pose la question philosophique globale.
C'est le problème de la soi-disant salle chinoise - une expérience de pensée sur les limites de l'intelligence artificielle. Il a été formulé par le philosophe John Searle en 1980.
Dans la pièce se trouve un homme qui ne connaît pas le chinois. On lui a donné des instructions, il a des livres, des dictionnaires et deux fenêtres. Dans une fenêtre, on lui donne des notes en chinois, et dans une autre fenêtre il donne des réponses - également en chinois, agissant exclusivement selon les instructions.
Par exemple, les instructions peuvent dire: «ici, vous avez une note, trouvez le caractère dans le dictionnaire. S'il s'agit du hiéroglyphe no 518, donnez le hiéroglyphe no 409 à la fenêtre de droite; si le hiéroglyphe no 711 est arrivé, donnez le hiéroglyphe no 35 à la fenêtre de droite et ainsi de suite. " Si la personne dans la pièce suit bien les instructions et si ces instructions sont bien écrites, alors la personne dans la rue qui donne et reçoit des notes peut supposer que la pièce ou la personne qui s'y trouve connaît le chinois. Après tout, ce qui se passe à l'intérieur n'est pas visible de l'extérieur.
Nous savons tous que c'est un homme qui a simplement reçu des instructions stupides. Il fait quelques opérations sur eux, mais ne connaît pas du tout le chinois. Du point de vue de l'observateur, c'est la connaissance de la langue.
La question philosophique - comment pouvons-nous nous y rapporter? La chambre parle-t-elle chinois? Peut-être que l'auteur de ces instructions connaît la langue chinoise? Et peut-être pas, car vous pouvez émettre des instructions basées sur un éventail de questions et réponses toutes faites.
D'un autre côté, que savent les Chinois? Ici, vous connaissez la langue russe. Que pouvez-vous faire? Que se passe-t-il dans votre tête? Une sorte de réaction biochimique. Les oreilles ou les yeux reçoivent un certain signal, cela provoque une sorte de réaction, vous comprenez quelque chose. Mais que signifie «comprendre»? Que faites-vous quand vous comprenez?
Et une question encore plus compliquée - faites-vous cela de manière optimale? Est-il vrai que vous travaillez avec la langue mieux que n'importe quelle machine pourrait fonctionner avec la langue? Pouvez-vous imaginer que vous parlerez le russe pire que n'importe quel ordinateur? Nous comparons toujours Siri, Alice avec la façon dont nous nous parlons et rions s'ils parlent mal de notre point de vue. D'un autre côté, vous et moi avons donné à l'ordinateur une grande partie de ce qui était auparavant considéré comme l'apanage de l'homme. Maintenant, les voitures sont bien meilleures pour compter et jouer aux échecs, mais avant elles ne pouvaient pas. Peut-être des choses similaires se produiront-elles avec les ordinateurs parlants: dans 100, 10 ou même 5 ans, nous reconnaissons que la machine maîtrise beaucoup mieux la langue, comprend beaucoup plus et est en général un locuteur natif bien meilleur que nous.
Que faire alors du fait qu'une personne est utilisée pour se définir à travers le langage? Après tout, ils disent que seule une personne parle la langue. Que se passera-t-il si nous reconnaissons la victoire à l'ordinateur dans ce domaine?
Laissez vos questions dans les commentaires. Peut-être qu'un peu plus tard, nous pourrons faire une interview avec Alexander. Ou peut-être qu'il viendra lui-même dans un commentaire sur notre invitation et discutera avec tous ceux qui sont intéressés.