 Salut Je m'appelle Marco, je travaille pour Badoo au département Platform. Nous avons beaucoup de choses écrites dans Go, et souvent elles sont essentielles aux performances du système. C'est pourquoi je vous propose aujourd'hui la traduction d'un article que j'ai beaucoup aimé et qui, je suis sûr, vous sera très utile. L'auteur montre pas à pas comment il a abordé les problèmes de performances et comment ils les ont résolus. Y compris vous vous familiariserez avec les riches outils disponibles dans Go pour un tel travail. Bonne lecture!
Salut Je m'appelle Marco, je travaille pour Badoo au département Platform. Nous avons beaucoup de choses écrites dans Go, et souvent elles sont essentielles aux performances du système. C'est pourquoi je vous propose aujourd'hui la traduction d'un article que j'ai beaucoup aimé et qui, je suis sûr, vous sera très utile. L'auteur montre pas à pas comment il a abordé les problèmes de performances et comment ils les ont résolus. Y compris vous vous familiariserez avec les riches outils disponibles dans Go pour un tel travail. Bonne lecture!Il y a quelques semaines, j'ai lu l'article «
Bon code contre mauvais code dans Go », où l'auteur, étape par étape, démontre la refactorisation d'une application réelle qui résout de vrais problèmes commerciaux. Il se concentre sur la transformation du «mauvais code» en «bon code»: plus idiomatique, plus compréhensible, utilisant pleinement les spécificités de Go. Mais l'auteur a également souligné l'importance des performances de l'application en question. La curiosité m'a fait un bond: essayons de l'accélérer!
Le programme, grosso modo, lit le fichier d’entrée, l’analyse ligne par ligne et remplit les objets en mémoire.
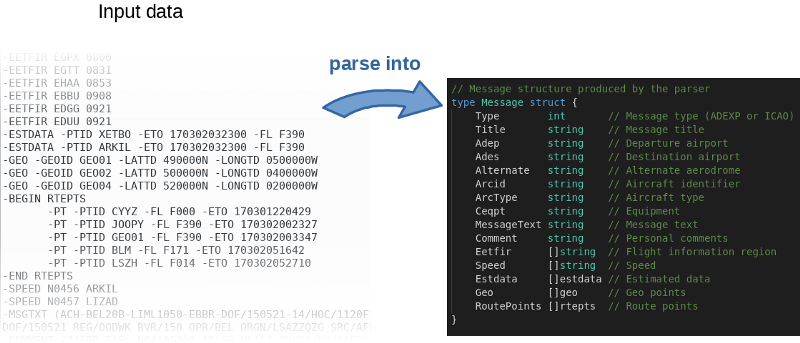
L'auteur a non seulement publié le
code source sur GitHub , mais a également écrit une référence. C’est une excellente idée. En fait, l'auteur a invité tout le monde à jouer avec le code et à essayer de l'accélérer. Pour reproduire les résultats de l'auteur, utilisez la commande suivante:
$ go test -bench=.
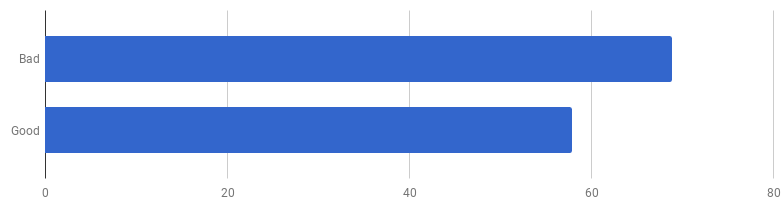 μs par appel (moins - mieux)
μs par appel (moins - mieux)Il s'avère que sur mon ordinateur, le «bon code» est 16% plus rapide. Pouvons-nous l'accélérer?
D'après mon expérience, il existe une corrélation entre la qualité du code et les performances. Si vous avez réussi à refactoriser le code, à le rendre plus propre et moins connecté, vous l'avez probablement rendu plus rapide car il est devenu moins encombré (et il n'y a plus d'instructions inutiles qui ont été précédemment exécutées en vain). Peut-être pendant la refactorisation vous avez remarqué des opportunités d'optimisation, ou maintenant vous avez juste la possibilité de les faire. Mais d'un autre côté, si vous voulez rendre le code encore plus productif, vous devez probablement vous éloigner de la simplicité et ajouter divers hacks. Vous économisez vraiment des millisecondes, mais la qualité du code en souffrira: il deviendra plus difficile de le lire et d'en parler, il deviendra plus fragile et flexible.
 Nous escaladons la montagne de la Simplicité, puis en redescendons
Nous escaladons la montagne de la Simplicité, puis en redescendonsC'est un compromis: jusqu'où êtes-vous prêt à aller?
Pour hiérarchiser correctement les travaux sur l'accélération, la stratégie optimale consiste à trouver des goulots d'étranglement et à se concentrer sur eux. Pour ce faire, utilisez les outils de profilage.
pprof et
trace sont vos amis:
$ go test -bench=. -cpuprofile cpu.prof $ go tool pprof -svg cpu.prof > cpu.svg
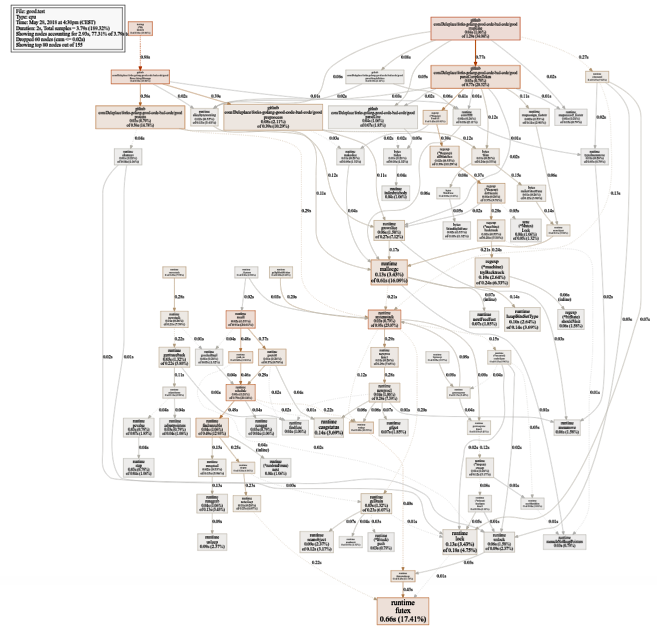 Un graphique assez grand de l'utilisation du processeur (cliquez pour SVG)
Un graphique assez grand de l'utilisation du processeur (cliquez pour SVG) $ go test -bench=. -trace trace.out $ go tool trace trace.out
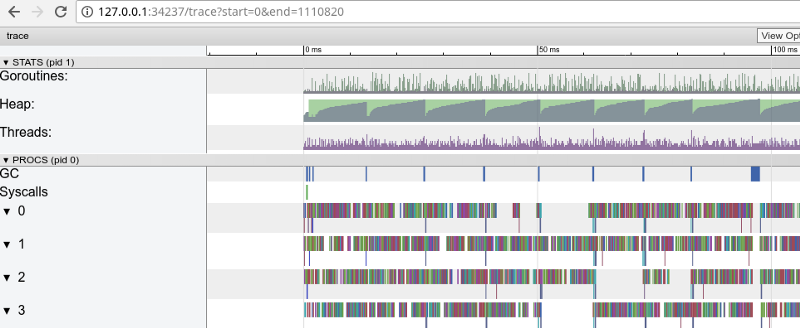 Tracé arc-en-ciel: beaucoup de petites tâches (cliquez pour ouvrir, fonctionne uniquement dans Google Chrome)
Tracé arc-en-ciel: beaucoup de petites tâches (cliquez pour ouvrir, fonctionne uniquement dans Google Chrome)Le traçage confirme que tous les cœurs de processeur sont occupés (lignes inférieures à 0, 1, etc.) et, à première vue, c'est bien. Mais elle montre également des milliers de «calculs» de petites couleurs et plusieurs zones vides où les noyaux étaient inactifs. Zoomons:
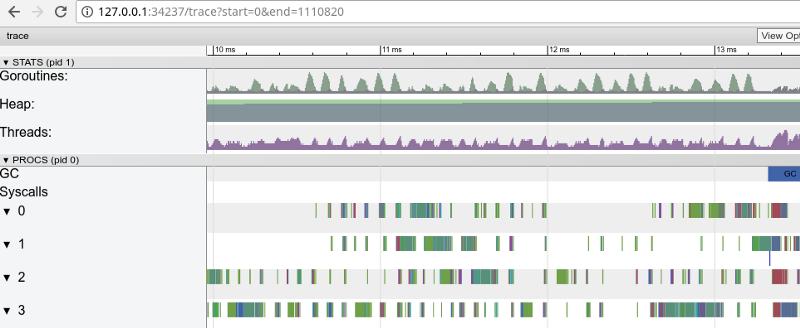 "Fenêtre" en 3 ms (cliquez pour ouvrir, fonctionne uniquement dans Google Chrome)
"Fenêtre" en 3 ms (cliquez pour ouvrir, fonctionne uniquement dans Google Chrome)Chaque cœur est inactif pendant un certain temps, et il "saute" entre les micro-tâches tout le temps. Il semble que la granularité de ces tâches n'est pas très optimale, ce qui conduit à un grand nombre de
changements de
contexte et à une concurrence due à la synchronisation.
Voyons ce que le
détecteur de vol nous dit. Y a-t-il des problèmes d'accès synchrone aux données (s'il y en a, nous avons des problèmes bien plus importants que les performances)?
$ go test -race PASS
Super! Tout est correct. Aucun vol trouvé. Les fonctions de test et les fonctions de référence sont des fonctions différentes (
voir la documentation ), mais ici, elles appellent la même fonction
ParseAdexpMessage , donc ce que nous avons vérifié pour les vols de données par des tests est correct.
Le modèle compétitif dans la «bonne» version consiste à traiter chaque ligne du fichier d'entrée dans une goroutine distincte (pour utiliser tous les cœurs). L'intuition de l'auteur a bien fonctionné ici, car les goroutins ont la réputation de fonctionnalités faciles et bon marché. Mais combien gagnons-nous grâce à l'exécution parallèle? Comparons avec le même code mais sans utiliser de goroutines (supprimez simplement le mot go qui vient avant l'appel de la fonction):

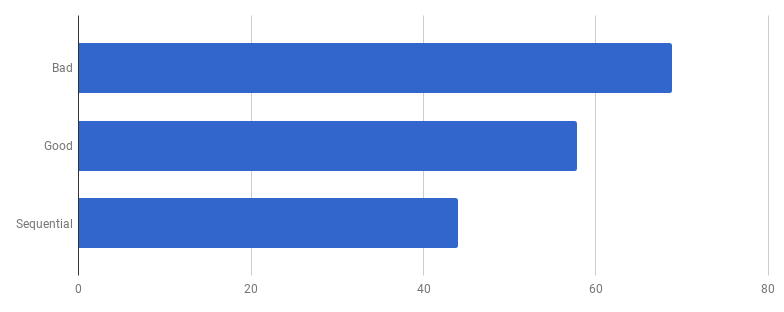
Oups, il semble que le code soit devenu plus rapide sans utiliser la concurrence. Cela signifie que le surcoût (non nul) pour le lancement de goroutines dépasse le temps que nous avons gagné en utilisant plusieurs cœurs en même temps. La prochaine étape naturelle devrait être de supprimer la surcharge (non nulle) pour utiliser les canaux pour envoyer les résultats. Remplaçons-le par une tranche régulière:
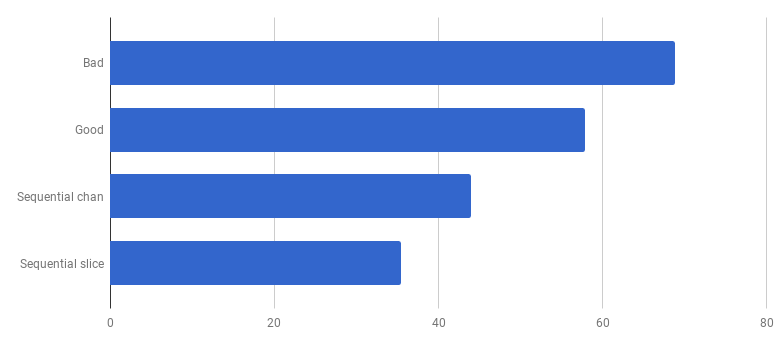 μs par appel (moins c'est mieux)
μs par appel (moins c'est mieux)Nous avons obtenu une accélération d'environ 40% par rapport à la «bonne» version, simplifiant le code et supprimant la concurrence (
diff ).
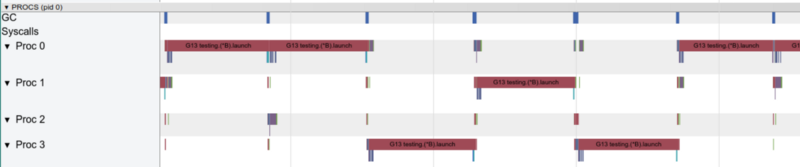 Avec un goroutine, un seul cœur fonctionne à la fois
Avec un goroutine, un seul cœur fonctionne à la foisVoyons maintenant les fonctions chaudes dans le graphique pprof:
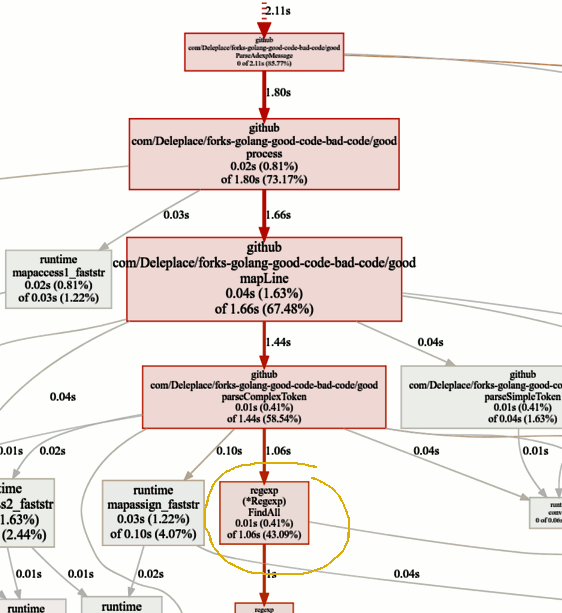 Recherche de goulots d'étranglement
Recherche de goulots d'étranglementLa référence de la version actuelle (fonctionnement séquentiel, tranches) passe 86% du temps à analyser les messages, ce qui est normal. Mais nous remarquerons rapidement que 43% du temps est consacré à l'utilisation des expressions régulières et de la fonction
(* Regexp) .FindAll .
Malgré le fait que les expressions régulières sont un moyen pratique et flexible d'obtenir des données à partir de texte brut, elles présentent des inconvénients, notamment l'utilisation d'un grand nombre de ressources, d'un processeur et de la mémoire. Ils sont un outil puissant, mais leur utilisation est souvent inutile.
Dans notre programme, un modèle
patternSubfield = "-.[^-]*"
Il est principalement destiné à mettre en évidence des commandes commençant par un tiret (-), et il peut y en avoir plusieurs sur la ligne. Cela, après avoir tiré un peu de code, peut être fait en utilisant
bytes.Split . Adaptons le code (
commit ,
commit ) pour changer les expressions régulières en Split:
 μs par appel (moins
μs par appel (moins c'est
mieux)Ouah! Code 40% plus productif! Le graphique de consommation du processeur ressemble maintenant à ceci:
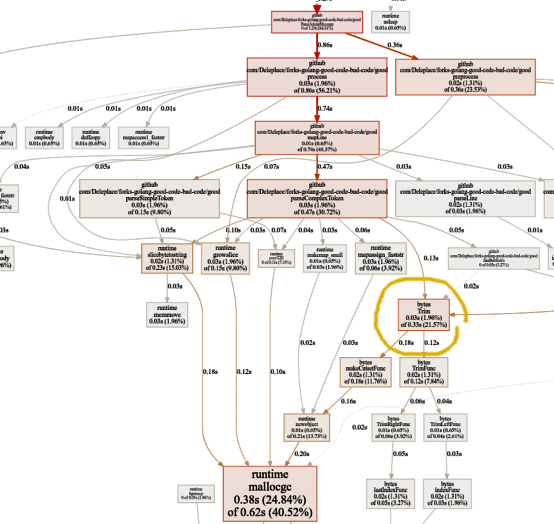
Plus de temps perdu sur les expressions régulières. Une partie importante de celui-ci (40%) va à l'allocation de mémoire de cinq fonctions différentes. Fait intéressant, maintenant 21% du temps est consacré à la fonction
octets.Trim :
 Cette fonctionnalité m'intrigue. Que pouvons-nous faire ici?
Cette fonctionnalité m'intrigue. Que pouvons-nous faire ici?
bytes.Trim attend une chaîne avec des caractères qu'il "coupe" comme argument, mais comme cette chaîne, nous passons une chaîne avec un seul caractère - un espace. Ceci est juste un exemple de la façon dont vous pouvez obtenir une accélération en raison de la complexité: créons notre fonction d'ajustement au lieu de la fonction standard. Notre fonction de
découpage personnalisée fonctionnera avec un seul octet au lieu d'une ligne entière:

 μs par appel (moins c'est mieux)
μs par appel (moins c'est mieux)Hourra, encore 20% de coupure! La version actuelle est quatre fois plus rapide que la «mauvaise» originale et n'utilise en même temps qu'un seul cœur. Pas mal!
Plus tôt, nous avons abandonné la compétitivité au niveau du traitement en ligne, mais je soutiens que l'accélération peut être obtenue en utilisant la compétitivité à un niveau supérieur. Par exemple, le traitement de 6 000 fichiers (6 000 messages) est plus rapide sur mon ordinateur si chaque fichier est traité dans son propre goroutine:
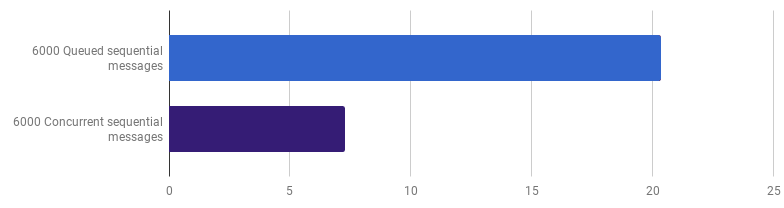 μs par appel (moins c'est mieux; le violet est une solution compétitive)
μs par appel (moins c'est mieux; le violet est une solution compétitive)Le gain est de 66% (c'est-à-dire une accélération trois fois). C'est bien, mais pas très, étant donné que les 12 cœurs de processeur que j'ai sont utilisés. Cela peut signifier que le nouveau code optimisé qui traite tout le fichier est toujours une «petite tâche», pour laquelle les frais généraux pour la création de goroutines et le coût de la synchronisation ne sont pas négligeables. Il est intéressant de noter que l'augmentation du nombre de messages de 6 000 à 120 000 n'a aucun effet sur la version monothread et réduit les performances de la version «un goroutine par message». En effet, malgré le fait que la création d'une telle quantité de goroutines soit possible et parfois utile, elle apporte sa propre surcharge dans la
zone de runtime-
sheduler .
Nous pouvons réduire davantage le temps d'exécution (pas de 12 fois, mais quand même) en créant seulement quelques travailleurs. Par exemple, 12 goroutines à longue durée de vie, dont chacune traitera une partie des messages:
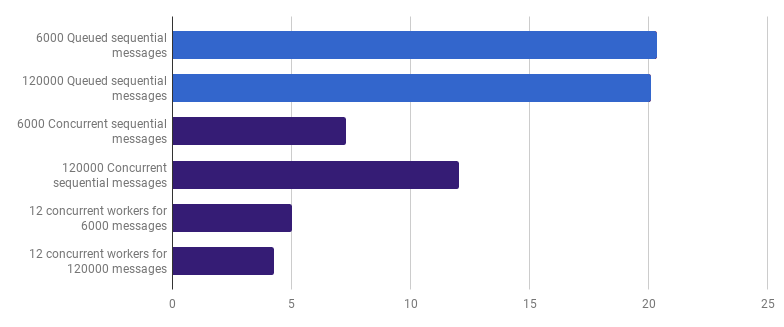 μs par appel (moins c'est mieux; le violet est une solution compétitive)
μs par appel (moins c'est mieux; le violet est une solution compétitive)Cette option réduit le temps d'exécution de 79% par rapport à la version à un seul thread. Notez que cette stratégie n'a de sens que si vous avez de nombreux fichiers à traiter.
L'utilisation optimale de tous les cœurs de processeur consiste à utiliser plusieurs goroutines, chacune d'elles traitant une quantité importante de données sans aucune interaction ni synchronisation avant la fin du travail.
Habituellement, ils prennent autant de processus (goroutine) que les cœurs du processeur, mais ce n'est pas toujours la meilleure option: tout dépend de la tâche spécifique. Par exemple, si vous lisez quelque chose dans le système de fichiers ou faites beaucoup d'appels réseau, alors pour obtenir plus de performances, vous devez utiliser plus de goroutines que vos cœurs.
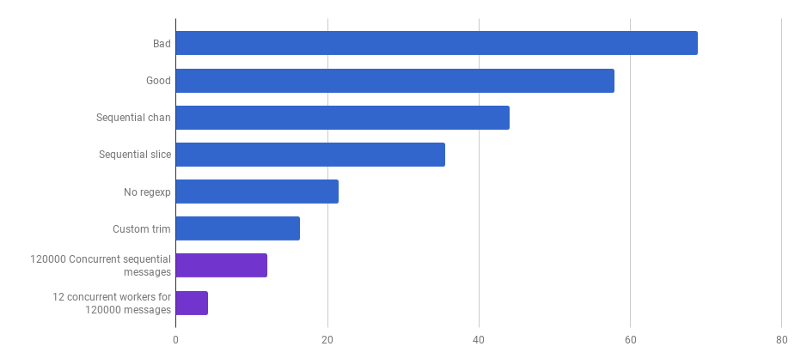 μs par appel (moins c'est mieux; le violet est une solution compétitive)
μs par appel (moins c'est mieux; le violet est une solution compétitive)Nous sommes arrivés au point où l'analyse des performances est difficile à augmenter avec certains changements localisés. Le runtime est dominé par le temps d'allocation de mémoire et de récupération de place. Cela semble logique car les fonctions de gestion de la mémoire sont plutôt lentes. La poursuite de l'optimisation des processus associés aux allocations reste un devoir pour les lecteurs.
L'utilisation d'autres algorithmes peut également entraîner un gain de performances important.
Ici, je me suis inspiré d'une conférence de Lexical Scanning in Go de Rob Pike,
pour créer un lexer personnalisé (
source ) et un analyseur personnalisé (
source ). Ce code n'est pas encore prêt (je ne traite pas un tas de cas d'angle), il est moins clair que l'algorithme d'origine, et parfois il est difficile d'écrire la bonne gestion des erreurs. Mais elle est petite et 30% plus rapide que la version la plus optimisée.
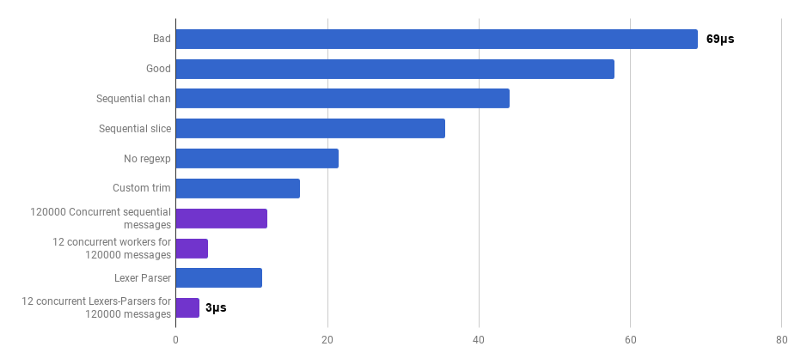 μs par appel (moins c'est mieux; le violet est une solution compétitive)
μs par appel (moins c'est mieux; le violet est une solution compétitive)Oui En conséquence, nous avons obtenu une accélération de 23 fois par rapport au code source.
C'est tout pour aujourd'hui. J'espère que vous avez apprécié cette aventure. Voici quelques notes et conclusions:
- La productivité peut être améliorée à différents niveaux d'abstraction, en utilisant différentes techniques, et le gain est souvent augmenté.
- Le réglage doit commencer par des abstractions de haut niveau: structures de données, algorithmes, découplage correct des modules. Reprenez les abstractions de bas niveau plus tard: E / S, traitement par lots, compétitivité, utilisation de la bibliothèque standard, utilisation de la mémoire, allocation de mémoire.
- L' analyse Big O est très importante, mais n'est généralement pas l'outil le plus approprié pour accélérer un programme.
- La rédaction de repères est un travail difficile. Utilisez le profilage et les repères pour trouver les goulots d'étranglement et mieux comprendre ce qui se passe dans le programme. Gardez à l'esprit que les résultats de référence ne sont pas les mêmes que ceux que vos utilisateurs connaîtront dans le travail réel.
- Heureusement, un ensemble d'outils ( Bench , pprof , trace , Race Detector , Cover ) rend la recherche sur les performances du code abordable et intéressante.
- Écrire de bons tests pertinents n'est pas une tâche banale. Mais ils sont sacrément importants de ne pas aller dans la nature. Vous pouvez refactoriser, en étant sûr que le code reste correct.
- Arrêtez-vous et demandez-vous à quelle vitesse est «assez rapide». Ne perdez pas votre temps à optimiser un script unique. N'oubliez pas que l'optimisation n'est pas gratuite: le temps de l'ingénieur, la complexité, les bugs et la dette technique.
- Réfléchissez bien avant de compliquer le code.
- Les algorithmes de complexité Ω (n²) et plus sont généralement trop chers.
- Les algorithmes de complexité O (n) ou O (n log n) et inférieurs sont généralement corrects.
- Divers facteurs cachés ne peuvent être ignorés. Par exemple, toutes les améliorations de l'article ont été apportées en réduisant ces facteurs et non en modifiant la classe de complexité de l'algorithme.
- Les E / S sont souvent un goulot d'étranglement: requêtes réseau, requêtes de base de données, système de fichiers.
- Les expressions régulières sont souvent trop chères et inutiles.
- Les allocations de mémoire sont plus chères que les calculs.
- Un objet alloué sur la pile est moins cher qu'un objet alloué sur le tas.
- Les tranches sont utiles comme alternative aux mouvements de mémoire coûteux.
- Les chaînes sont efficaces en lecture seule (y compris le redimensionnement). Dans tous les autres cas, [] octets sont plus efficaces.
- Il est très important que les données que vous traitez soient proches (caches du processeur).
- La compétitivité et le parallélisme sont très utiles, mais difficiles à préparer.
- Lorsque vous creusez profondément et bas, souvenez-vous du «plancher de verre» que vous ne voulez pas pénétrer dans Go. Si vos mains vous démangent d'essayer les instructions d'assembleur, les instructions SIMD, vous devrez peut-être utiliser Go uniquement pour le prototypage, puis basculer vers un langage de niveau inférieur pour obtenir un contrôle total du matériel et toutes les nanosecondes!