
Ce printemps, l'équipe Reydiks a préparé et publié la première version du logiciel pour créer des systèmes de stockage de blocs distribués fonctionnant sur des plates-formes de serveur Elbrus-4.4 basées sur des microprocesseurs Elbrus-4C.
L'utilité d'une telle symbiose est visible à l'œil nu - l'assemblage de systèmes de stockage à base de fer domestique et du système d'exploitation domestique devient un produit attrayant du marché intérieur, en particulier pour les clients axés sur la substitution des importations.
Cependant, le potentiel du système d'exploitation développé n'est pas limité aux plates-formes de serveurs russes. À l'heure actuelle, la compatibilité avec les serveurs x86-64 standard, qui sont largement distribués sur le marché, est testée et testée. De plus, le produit est "fini" à la fonctionnalité souhaitée, ce qui permettra sa mise en œuvre en dehors du marché russe.
Ci-dessous, nous présenterons une petite discussion sur la façon dont la solution logicielle (appelée RAIDIX RAIN) est organisée, ce qui permet de combiner les médias du serveur local en un seul cluster de stockage à tolérance de pannes avec une gestion centralisée et des capacités de mise à l'échelle horizontale et verticale.
Fonctionnalités de stockage distribué
Les systèmes de stockage traditionnels, réalisés sous la forme d'un complexe matériel-logiciel unique, ont un problème commun associé à la mise à l'échelle: les performances du système reposent sur des contrôleurs, leur nombre est limité, l'extension de la capacité en ajoutant des étagères d'extension avec des supports n'augmente pas la productivité.
Avec cette approche, les performances globales du système de stockage diminueront, car avec l'augmentation de la capacité, le nombre précédent de contrôleurs doit traiter davantage d'opérations d'accès à l'augmentation du volume de données.
RAIDIX RAIN prend en charge la mise à l'échelle horizontale des blocs, contrairement aux solutions traditionnelles, l'augmentation des nœuds (blocs serveur) du système entraîne une augmentation linéaire non seulement de la capacité, mais également des performances du système. Cela est possible car chaque nœud RAIDIX RAIN comprend non seulement des supports, mais également des ressources informatiques pour les E / S et le traitement des données.
Scénarios d'application
RAIDIX RAIN implique la mise en œuvre de tous les principaux scénarios d'application pour le stockage distribué par blocs: infrastructure de stockage cloud, bases de données très chargées et stockage analytique Big Data. RAIDIX RAIN peut également concurrencer les systèmes de stockage traditionnels avec des volumes de données suffisamment élevés et les capacités financières correspondantes du client.
Clouds publics et privés
La solution offre l'évolutivité flexible requise pour déployer une infrastructure cloud: les performances, le débit et la capacité de stockage augmentent avec chaque nœud ajouté au système.
Bases de données
Le cluster RAIDIX RAIN dans une configuration 100% flash est une solution efficace pour la maintenance des bases de données très chargées. La solution sera une alternative abordable aux produits Oracle Exadata pour Oracle RAC.
Analyse de Big Data
Avec un logiciel supplémentaire, il est possible d'utiliser une solution pour effectuer des analyses de Big Data. RAIDIX RAIN offre des niveaux de performances et une facilité de maintenance nettement supérieurs à ceux d'un cluster HDFS.
Architecture de la solution
RAIDIX RAIN prend en charge 2 options de déploiement: dédié (externe ou convergent) et hyperconvergé (HCI, infrastructure hyperconvergée).
Option de déploiement dédié
Dans la version sélectionnée, le cluster RAIDIX RAIN est un stockage logiciel classique. La solution est déployée sur le nombre requis de nœuds de serveurs dédiés (au moins 3, le nombre est pratiquement illimité d'en haut), dont les ressources sont entièrement utilisées pour les tâches de stockage.
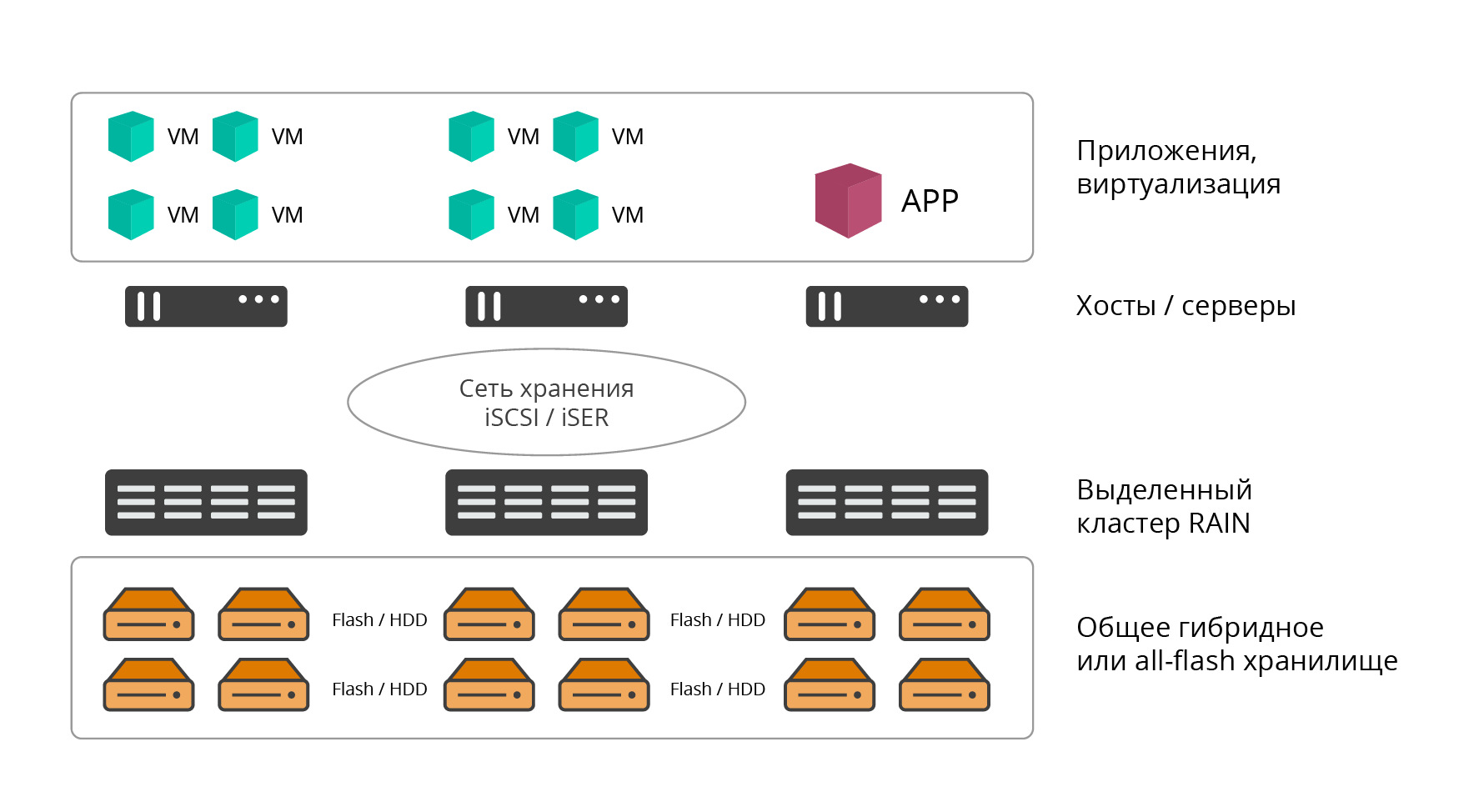 Fig. 1. Option de déploiement dédiée
Fig. 1. Option de déploiement dédiéeLe logiciel RAIDIX RAIN est installé directement sur du métal nu. Les applications, les services et les ressources informatiques qui utilisent RAIN pour stocker des informations sont hébergés sur des hôtes externes et connectés à celui-ci via un réseau de stockage (architecture de centre de données classique).
Option de déploiement hyperconvergé
L'option hyperconvergente implique le placement conjoint de la puissance de calcul (hyperviseur et machines virtuelles de production) et des ressources de stockage (stockage logiciel) du centre de données sur un ensemble de nœuds, principalement pour les infrastructures virtuelles. Avec cette approche, le logiciel RAIN est installé sur chaque hôte (nœud) de l'infrastructure (HCI) sous la forme d'une machine virtuelle.
 Fig. 2. Option de déploiement hyperconvergé
Fig. 2. Option de déploiement hyperconvergéL'interaction des nœuds du cluster RAIN entre eux et avec les utilisateurs finaux des ressources de stockage (serveurs, applications) s'effectue via les protocoles iSCSI (IP, IPoIB), iSER (RoCE, RDMA) ou NVMeOF.
L'option de déploiement hyperconvergé offre les avantages suivants:
- Consolidation des ressources informatiques et de stockage (pas besoin d'implémenter et de maintenir un stockage externe dédié).
- Mise à l'échelle horizontale conjointe des ressources informatiques et des ressources de stockage.
- Facilité de mise en œuvre et de maintenance.
- Gestion centralisée.
- Économisez la capacité de montage en rack et la consommation d'énergie.
En termes de média utilisé, RAIDIX RAIN prend en charge 3 configurations:
- All-flash - les nœuds de cluster sont fournis uniquement avec des supports flash (NVMe, SSD);
- Disque dur - les nœuds de cluster sont fournis uniquement avec des supports de disque dur;
- Hybride - deux niveaux de stockage indépendants sur disque dur et SSD.
Résilience productive
La valeur fondamentale de RAIDIX RAIN est l'équilibre optimal entre performances, tolérance aux pannes et utilisation efficace de la capacité de stockage.
En tant qu'élément de l'infrastructure informatique client, RAIDIX RAIN est également attrayant dans la mesure où nous avons un accès de bloc «honnête» en sortie, ce qui distingue la solution de la plupart des analogues du marché.
Actuellement, la plupart des produits concurrents présentent des performances élevées, uniquement lors de l'utilisation de la mise en miroir. Dans le même temps, la capacité de stockage utile est réduite de 2 fois ou plus: réplication de données unique (mise en miroir) - 50% de redondance, réplication de données double (double mise en miroir) - 66,6% de redondance.
L'utilisation de technologies d'optimisation du stockage telles que EC (Erasure Coding - codage silencieux), la déduplication et la compression mises en œuvre dans les systèmes de stockage distribués entraînent une dégradation significative des performances de stockage, ce qui est inacceptable pour les applications sensibles aux retards.
Par conséquent, dans la pratique, ces solutions sont généralement obligées de fonctionner sans l'utilisation de ces technologies, ou de les inclure uniquement pour les données «froides».
Exigences de basculement
Initialement, RAIDIX RAIN a été conçu avec un ensemble clair d'exigences initiales pour la résilience et la disponibilité du système:
- Le cluster doit survivre à une défaillance d'au moins deux nœuds, avec un nombre de nœuds strictement supérieur à 4. Pour trois et quatre, une défaillance d'un nœud est garantie.
- Un nœud doit survivre à une défaillance d'au moins deux disques dans chaque nœud s'il y a au moins 5 disques dans un nœud.
- Le niveau de redondance des disques sur un cluster typique (à partir de 16 nœuds) ne doit pas dépasser 30%
- Le niveau de disponibilité des données doit être d'au moins 99,999%
Cela a grandement influencé l'architecture de produit existante.
Capacités de codage d'effacement dans le stockage distribué
L'approche de tolérance aux pannes RAIDIX RAIN principale est l'utilisation de technologies uniques de codage par effacement. Les sociétés européennes connues pour leur produit phare sont également utilisées dans le stockage distribué, ce qui permet des performances comparables aux configurations en miroir. Cela s'applique aux charges aléatoires et séquentielles. Dans le même temps, un niveau prédéterminé de tolérance aux pannes est assuré et la capacité utile est considérablement augmentée, et les frais généraux ne représentent pas plus de 30% de la capacité de stockage brute.
Une mention distincte est requise de EC RAIDIX haute performance sur les opérations séquentielles, en particulier lors de l'utilisation de disques SATA de grande capacité.
En général, RAIDIX RAIN propose 3 options d'encodage à correction d'erreur:
- pour 3 nœuds, l'utilisation de RAID 1 est optimale;
- pour 4 nœuds, utilisation optimale de RAID 5;
- pour un sous-cluster de stockage de 5 à 20 nœuds, l'approche optimale est d'utiliser le RAID 6 réseau.
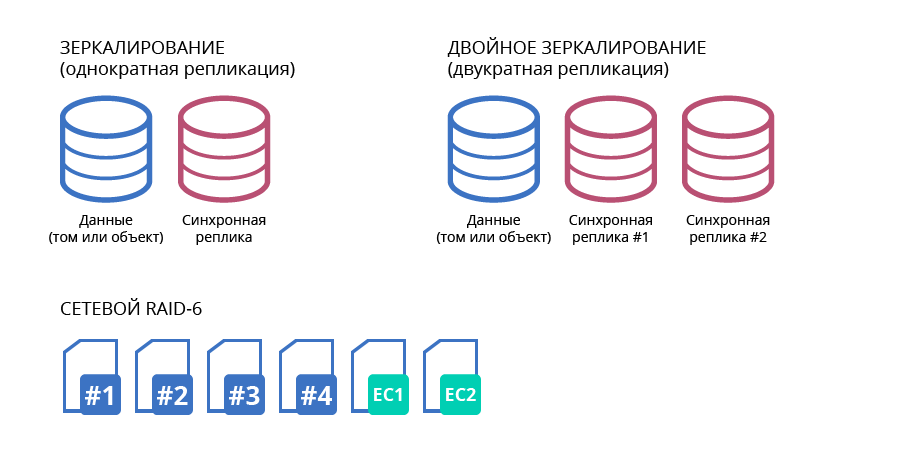 Fig. 3. Options de codage correcteur d'erreurs
Fig. 3. Options de codage correcteur d'erreursToutes les options supposent une distribution uniforme des données sur tous les nœuds du cluster avec l'ajout de redondance sous forme de sommes de contrôle (ou codes de correction). Cela nous permet d'établir des parallèles avec les codes Reed-Solomon utilisés dans les matrices RAID standard (RAID-6) et permettant le basculement de jusqu'à 2 porteuses. Le RAID-6 réseau fonctionne de manière similaire à un disque dur, mais il répartit les données entre les nœuds du cluster et permet le basculement de 2 nœuds.
En RAID 6, lorsque 1-2 porteuses tombent en panne dans un nœud, elles sont restaurées localement sans utiliser de sommes de contrôle distribuées, minimisant la quantité de données récupérées, la charge du réseau et la dégradation globale du système.
Domaines d'échec
RAIN prend en charge le concept de domaines de pannes ou de domaines de disponibilité. Cela vous permet de déterminer la défaillance non seulement de nœuds individuels, mais également de racks ou de paniers de serveurs entiers, dont les nœuds sont logiquement regroupés en domaines de défaillance. Cette possibilité est obtenue en distribuant des données pour assurer leur tolérance aux pannes non pas au niveau des nœuds individuels, mais au niveau du domaine, ce qui permettra de survivre à la défaillance de tous les nœuds qui y sont regroupés (par exemple, un rack de serveur entier). Dans cette approche, le cluster est divisé en sous-groupes indépendants (sous-clusters). Le nombre de nœuds dans un sous-groupe ne dépasse pas 20, ce qui impose la tolérance aux pannes et la disponibilité. De plus, le nombre de sous-groupes n'est pas limité.
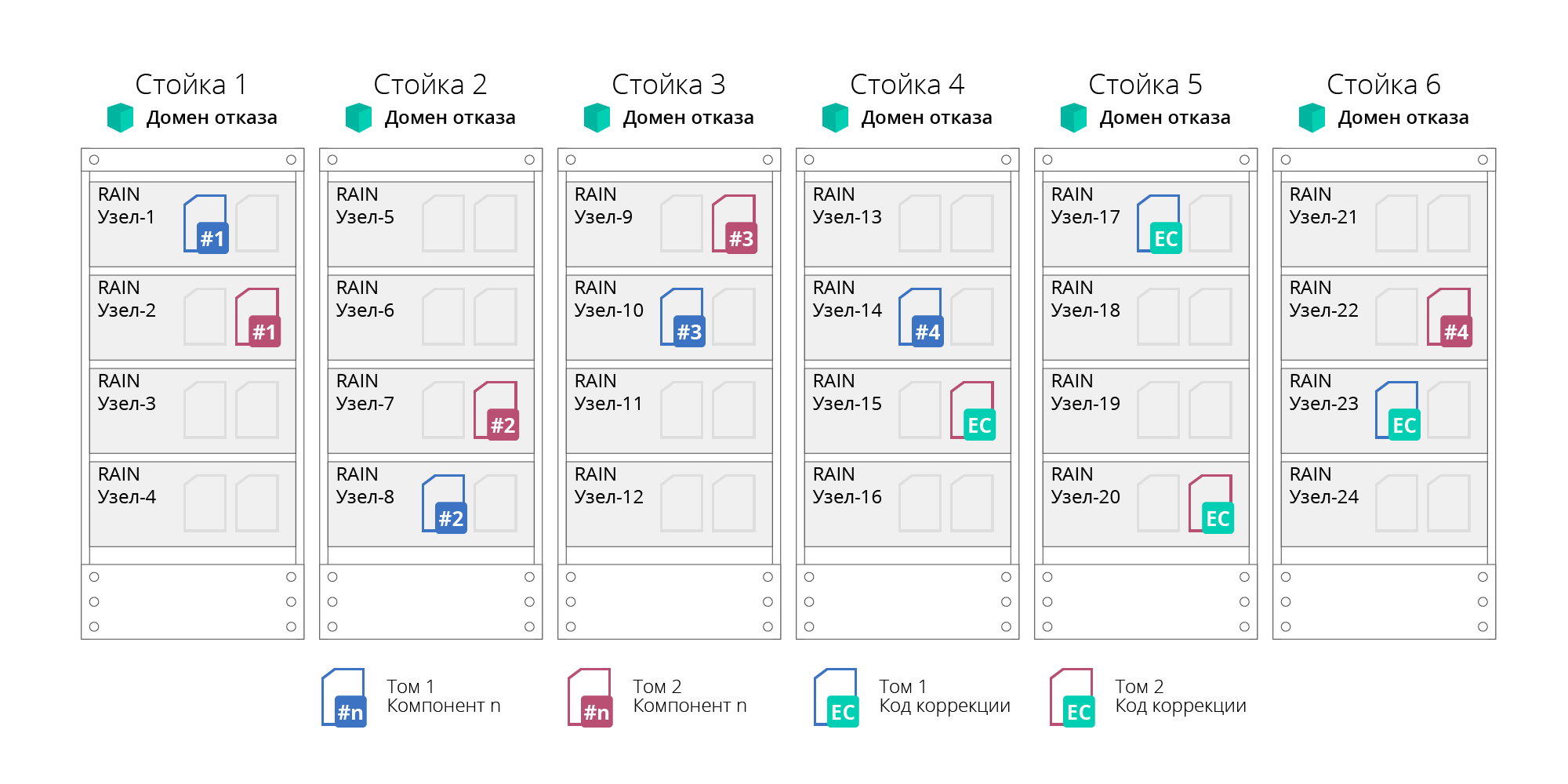 Fig. 4. Domaines d'échec
Fig. 4. Domaines d'échecLa défaillance de toute défaillance (disques, nœuds ou réseau) est exécutée automatiquement, sans arrêter le système.
De plus, tous les périphériques du cluster RAIDIX RAIN sont protégés contre les pannes de courant en se connectant à des alimentations sans coupure (UPS). Les appareils connectés au même onduleur sont appelés groupe de coupure de courant.
Caractéristiques et fonctionnalités
Considérez les principales fonctionnalités de RAIDIX RAIN.
Tableau 1. Fonctions de base de RAIDIX RAIN| Caractéristiques opérationnelles | Valeur |
|---|
| Types de nœuds pris en charge | Plates-formes de serveurs domestiques basées sur les processeurs Elbrus-4C
Serveurs x86-64 standard (perspective) |
| Types de supports pris en charge | Disque dur SATA et SAS, SSD SATA et SAS, NVMe |
| Capacité de stockage maximale | 16 EB |
| Taille maximale du cluster | 1024 noeuds |
| Fonctionnalité de base | Expansion à chaud
Ajout de nœuds à chaud au cluster
Rééquilibrage des clusters
Basculement sans temps d'arrêt |
| Technologies de résilience | Défaillance des nœuds, des médias, du réseau.
Codage d'effacement, distribué sur les nœuds du cluster: RAID réseau 1/1/5/6.
Codes de correction au niveau des porteuses hôtes locales (RAID 6 local)
Domaines d'échec |
En tant que caractéristique fonctionnelle importante de RAIDIX RAIN, il convient de noter que des services tels que l'
initialisation, la reconstruction et la redistribution (mise à l'échelle) passent en arrière-plan et peuvent être définis sur un paramètre de priorité .
Le réglage de priorité permet à l'utilisateur d'ajuster indépendamment la charge dans le système, accélérant ou ralentissant le travail de ces services. Par exemple, la priorité 0 signifie que les services ne fonctionnent que lorsqu'il n'y a pas de charge à partir des applications clientes.
Options de mise à l'échelle
Le processus d'extension d'un cluster RAIDIX RAIN est aussi simple et automatisé que possible, le système redistribue indépendamment les données dans le processus d'arrière-plan en tenant compte de la capacité des nouveaux nœuds, la charge devient équilibrée et uniforme, les performances globales et la capacité de stockage sont proportionnellement augmentées. Le processus de mise à l'échelle horizontale passe «à chaud» sans temps d'arrêt, ne nécessite pas l'arrêt des applications et des services.
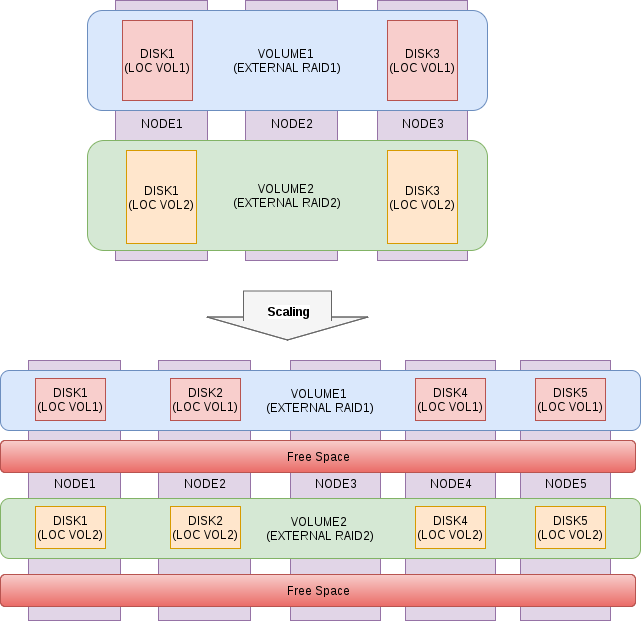 Fig. 5. Schéma du processus de mise à l'échelle
Fig. 5. Schéma du processus de mise à l'échelleFlexibilité de l'architecture
RAIDIX RAIN est un produit logiciel et n'est pas limité à une plate-forme matérielle spécifique - son concept suggère la possibilité d'installer sur n'importe quel matériel serveur compatible.
En fonction des spécificités de son infrastructure et de ses applications, chaque client choisit la meilleure option de déploiement: dédiée ou hyperconvergée.
La prise en charge de différents types de médias vous permet de construire sur la base du budget et des tâches à construire sur la base de RAIDIX RAIN:
1. stockage 100% flash distribué avec des performances élevées sans précédent et une faible latence garantie;
2. systèmes hybrides économiques qui satisfont la plupart des types de charges de base.
Indicateurs de performance
En conclusion, nous allons montrer quelques chiffres obtenus à la suite du test de RAIDIX RAIN sur la configuration d'un cluster NVMe à 6 nœuds. Encore une fois, nous notons que lors d'un tel assemblage (avec des serveurs x86-64), le produit est toujours en cours de finalisation, et ces chiffres ne sont pas définitifs.
Environnement de test
- 6 nœuds sur 2 disques NVMe HGST SN100
- Carte IB Mellanox MT27700 Family [ConnectX-4]
- Noyau Linux 4.11.6-1.el7.elrepo.x86_64
- MLNX_OFED_LINUX-4.3-1.0.1.0-rhel7.4-x86_64
- Raid local - raid 0
- Raid externe - raid 6
- Référence pour tester FIO 3.1
UPD: le chargement a été effectué en blocs 4K, séquentiels - 1M, profondeur de file d'attente 32. Le chargement a été lancé sur tous les nœuds du cluster en même temps et le tableau montre le résultat total. Les délais ne dépassent pas 1 ms (99,9 centile).
Tableau 2. Résultats des tests| Type de charge | Valeur |
|---|
| Lecture aléatoire 100% | 4 098 000 IOps |
| Écriture aléatoire 100% | 517 000 IOps |
| Lecture séquentielle 100% | 33,8 Go / s |
| Écriture séquentielle à 100% | 12 Go / s |
| Lecture aléatoire 70% / écriture aléatoire 30% | 1 000 000 IOps / 530 000 IOps |
| Lecture aléatoire 50% / écriture aléatoire 50% | 530 000 IOps / 530 000 IOps |
| Lecture aléatoire 30% / écriture aléatoire 70% | 187 000 IOps / 438 000 IOps |