Salut Dans cet article, je parlerai du classificateur bayésien comme l'une des options de filtrage des spams. Passons en revue la théorie, puis corrigeons-la avec de la pratique, et à la fin je donnerai mon croquis du code dans ma langue bien-aimée R. J'essaierai de l'exposer aussi légèrement que possible avec des expressions et des formulations. Commençons!

Aucune formule nulle part, eh bien, une brève théorie
Le classificateur bayésien appartient à la catégorie de l'apprentissage automatique. L'essentiel est le suivant: le système qui est confronté à la tâche de déterminer si la prochaine lettre est du spam a été formé à l'avance par un certain nombre de lettres qui savent exactement où «spam» et où «pas de spam». Il est déjà devenu clair qu'il s'agit d'enseigner avec un enseignant, où nous jouons le rôle d'un enseignant. Le classifieur bayésien présente un document (dans notre cas, une lettre) sous la forme d'un ensemble de mots qui ne dépendent pas les uns des autres (et cette naïveté même découle d'ici).
Il est nécessaire de calculer la note pour chaque classe (spam / non-spam) et de choisir celle qui est la plus élevée. Pour ce faire, utilisez la formule suivante:
- occurrence de mot
dans le document de classe
(avec lissage) *
- le nombre de mots inclus dans le document de classe
M - le nombre de mots de l'ensemble d'apprentissage
- le nombre d'occurrences du mot
dans le document de classe
- paramètre de lissage
Lorsque le volume du texte est très important, vous devez travailler avec de très petits nombres. Pour éviter cela, vous pouvez convertir la formule en fonction de la propriété logarithme **:
Remplacez et obtenez:
* Pendant les calculs, vous pouvez rencontrer un mot qui n'était pas au stade de la formation du système. Cela peut conduire à une évaluation égale à zéro et le document ne peut être affecté à aucune des catégories (spam / non-spam). Peu importe comment vous le souhaitez, vous n'enseignez pas à votre système tous les mots possibles. Pour ce faire, il est nécessaire d'appliquer un lissage, ou plutôt d'apporter de petites corrections à toutes les probabilités de mots entrant dans le document. Le paramètre 0 <α≤1 est sélectionné (si α = 1, alors c'est le lissage de Laplace)
** Le logarithme est une fonction qui augmente de façon monotone. Comme le montre la première formule, nous recherchons le maximum. Le logarithme de la fonction culminera au même point (en abscisse) que la fonction elle-même. Cela simplifie le calcul, car seule la valeur numérique change.
De la théorie à la pratique
Laissez notre système apprendre des lettres suivantes, connues à l'avance où «spam» et où «pas de spam» (exemple de formation):
Spam- “Bons à petit prix”
- «Promotion! Achetez une barre de chocolat et obtenez un téléphone en cadeau »
Pas de spam:- «La réunion aura lieu demain»
- «Achetez un kilogramme de pommes et une barre de chocolat»
Affectation: déterminez à quelle catégorie appartient la lettre suivante:
- «Le magasin a une montagne de pommes. Achetez sept kilos et une barre de chocolat »
Solution:Nous faisons une table. Nous supprimons tous les «mots vides», calculons les probabilités, prenons le paramètre de lissage comme un.
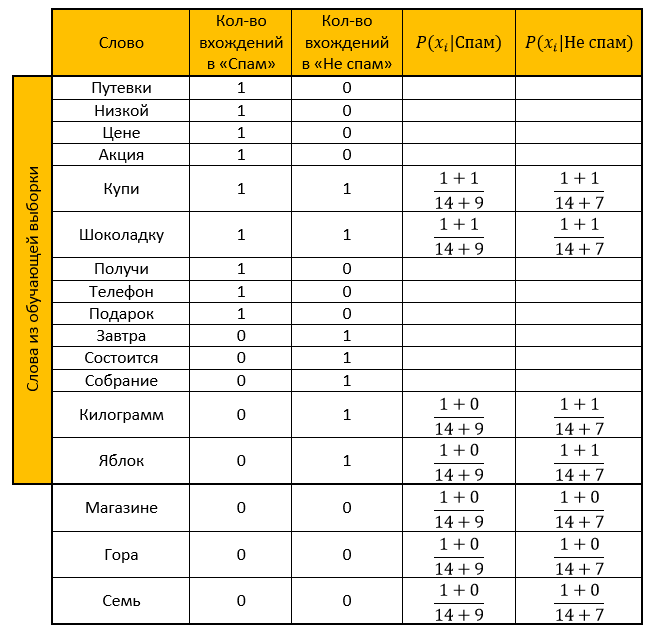
Évaluation pour la catégorie Spam:
Évaluation pour la catégorie «sans spam»:
Réponse: La note «Pas de spam» est supérieure à la note «Spam». La lettre de vérification n'est donc pas du spam!
Nous calculons la même chose à l'aide d'une fonction transformée par la propriété du logarithme:
Évaluation pour la catégorie Spam:
Évaluation pour la catégorie «sans spam»:
Réponse: similaire à la réponse précédente. E-mail de vérification - pas de spam!
Implémentation du langage de programmation R
Il a commenté presque toutes les actions, car je sais combien de fois je ne veux pas comprendre le code de quelqu'un d'autre, alors j'espère que la lecture du mien ne vous causera aucune difficulté. (oh comme j'espère)
Et ici, en fait, le code lui-mêmelibrary("tm") # stopwords library("stringr") # # : spam <- c( ' ', '! ' ) # : not_spam <- c( ' ', ' ' ) # test_letter <- " . " #---------------- -------------------- # spam <- str_replace_all(spam, "[[:punct:]]", "") # spam <- tolower(spam) # spam_words <- unlist(strsplit(spam, " ")) # , stopwords spam_words <- spam_words[! spam_words %in% stopwords("ru")] # unique_words <- table(spam_words) # data frame main_table <- data.frame(u_words=unique_words) # names(main_table) <- c("","") #--------------- ------------------ not_spam <- str_replace_all(not_spam, "[[:punct:]]", "") not_spam <- tolower(not_spam) not_spam_words <- unlist(strsplit(not_spam, " ")) not_spam_words <- not_spam_words[! not_spam_words %in% stopwords("ru")] #--------------- ------------------ test_letter <- str_replace_all(test_letter, "[[:punct:]]", "") test_letter <- tolower(test_letter) test_letter <- unlist(strsplit(test_letter, " ")) test_letter <- test_letter[! test_letter %in% stopwords("ru")] #--------------------------------------------- # main_table$_ <- 0 for(i in 1:length(not_spam_words)){ # need_word <- TRUE for(j in 1:(nrow(main_table))){ # " " , +1 if(not_spam_words[i]==main_table[j,1]) { main_table$_[j] <- main_table$_[j]+1 need_word <- FALSE } } # , data frame if(need_word==TRUE) { main_table <- rbind(main_table,data.frame(=not_spam_words[i],=0,_=1)) } } #------------- # , - main_table$_ <- NA # , - main_table$__ <- NA #------------- # Xi Qk formula_1 <- function(N_ik,M,N_k) { (1+N_ik)/(M+N_k) } #------------- # quantity <- nrow(main_table) for(i in 1:length(test_letter)) { # , need_word <- TRUE for(j in 1:nrow(main_table)) { # if(test_letter[i]==main_table$[j]) { main_table$_[j] <- formula_1(main_table$[j],quantity,sum(main_table$)) main_table$__[j] <- formula_1(main_table$_[j],quantity,sum(main_table$_)) need_word <- FALSE } } # , data frame, / if(need_word==TRUE) { main_table <- rbind(main_table,data.frame(=test_letter[i],=0,_=0,_=NA,__=NA)) main_table$_[nrow(main_table)] <- formula_1(main_table$[nrow(main_table)],quantity,sum(main_table$)) main_table$__[nrow(main_table)] <- formula_1(main_table$_[nrow(main_table)],quantity,sum(main_table$_)) } } # "" probability_spam <- 1 # " " probability_not_spam <- 1 for(i in 1:nrow(main_table)) { if(!is.na(main_table$_[i])) { # 1.1 , - probability_spam <- probability_spam * main_table$_[i] } if(!is.na(main_table$__[i])) { # 1.2 , - probability_not_spam <- probability_not_spam * main_table$__[i] } } # 2.1 , - probability_spam <- (length(spam)/(length(spam)+length(not_spam)))*probability_spam # 2.2 , - probability_not_spam <- (length(not_spam)/(length(spam)+length(not_spam)))*probability_not_spam # - ifelse(probability_spam>probability_not_spam," - !"," - !")
Merci beaucoup pour votre temps à lire mon article. J'espère que vous avez appris quelque chose de nouveau par vous-même ou que vous avez simplement mis en lumière des moments qui ne vous paraissent pas clairs. Bonne chance
Sources:- Un très bon article sur le classificateur naïf de Bayes
- Connaissances dérivées du Wiki: ici , ici et ici
- Conférences sur l'exploration de données Chubukova I.A.