Salut Vous trouverez ci-dessous une transcription de la vidéo du discours prononcé lors du rassemblement communautaire Apache Ignite à Saint-Pétersbourg le 20 juin. Vous pouvez télécharger les diapositives ici .
Il existe toute une classe de problèmes auxquels les utilisateurs novices sont confrontés. Ils viennent de télécharger Apache Ignite, exécutent les deux, trois, dix premières fois et nous posent des questions qui sont résolues de la même manière. Par conséquent, je propose de créer une liste de contrôle qui vous fera gagner beaucoup de temps et de nerfs lorsque vous ferez vos premières applications Apache Ignite. Nous parlerons des préparatifs de lancement; comment assembler le cluster; comment démarrer certains calculs dans la grille de calcul; Comment préparer un modèle de données et un code afin que vous puissiez écrire vos données dans Ignite, puis les lire avec succès. Et le plus important: comment ne rien casser dès le début.
Préparation au lancement - configurer la journalisation
Nous avons besoin de journaux. Si vous avez déjà posé une question sur la liste de diffusion Apache Ignite ou sur StackOverflow, comme "pourquoi tout a-t-il raccroché", la première chose qu'on vous a demandé d'envoyer était probablement tous les journaux de tous les nœuds.
Naturellement, la journalisation Apache Ignite est activée par défaut. Mais il y a des nuances. Tout d'abord, Apache Ignite écrit un peu en stdout . Par défaut, il démarre en mode dit silencieux. Dans stdout vous ne verrez que les erreurs les plus terribles, et tout le reste sera enregistré dans un fichier, le chemin vers lequel Apache Ignite s'affiche au tout début (par défaut - ${IGNITE_HOME}/work/log ). Vous ne l'effacez pas et conservez les journaux plus longtemps, cela peut être très utile.
stdout s'enflammer au démarrage par défaut
Pour faciliter la découverte des problèmes sans entrer dans des fichiers séparés et configurer une surveillance séparée pour Apache Ignite, vous pouvez l'exécuter en mode verbeux avec la commande
ignite.sh -v
puis le système commencera à écrire sur tous les événements dans stdout avec le reste de la journalisation de l'application.
Vérifiez les journaux! Très souvent, vous pouvez trouver des solutions à vos problèmes. Si le cluster s'est effondré, très souvent dans le journal, vous pouvez voir des messages comme «Augmenter tel ou tel délai dans telle ou telle configuration. Nous sommes tombés à cause de lui. Il est trop petit. Le réseau n'est pas assez bon. »
Assemblage de cluster
Invités non invités
Le premier problème auquel beaucoup sont confrontés est les invités non invités dans votre cluster. Ou vous vous trouvez vous-même être un invité non invité: démarrez un nouveau cluster et soudain, vous voyez que dans le premier instantané de topologie au lieu d'un nœud, vous avez deux serveurs dès le début. Comment ça? Vous n'en avez lancé qu'un.
Un message indiquant que le cluster a deux nœuds

Le fait est que par défaut Apache Ignite utilise la multidiffusion et au démarrage, il recherchera tous les autres Apache Ignite qui se trouvent dans le même sous-réseau, dans le même groupe de multidiffusion. Et si c'est le cas, il essaiera de se connecter. Et en cas d'échec de la connexion, il ne démarrera pas du tout. Par conséquent, dans le cluster sur mon ordinateur portable de travail, des nœuds supplémentaires du cluster sur l'ordinateur portable du collègue apparaissent régulièrement, ce qui bien sûr n'est pas très pratique.
Comment vous en protéger? La façon la plus simple de configurer une adresse IP statique. Au lieu de TcpDiscoveryMulticastIpFinder , qui est utilisé par défaut, il y a TcpDiscoveryVmIpFinder . Là, notez toutes les adresses IP et les ports auxquels vous vous connectez. C'est beaucoup plus pratique et vous protégera d'un grand nombre de problèmes, en particulier dans les environnements de développement et de test.
Trop d'adresses
Le prochain problème. Vous avez désactivé la multidiffusion, démarrez le cluster, dans une seule configuration, vous définissez une quantité décente d'IP à partir d'environnements différents. Et il arrive que vous lanciez le premier nœud dans un nouveau cluster pendant 5 à 10 minutes, bien que tous les suivants s'y connectent en 5 à 10 secondes.
Prenez une liste de trois adresses IP. Pour chacun, nous prescrivons des plages de 10 ports. Au total, 30 adresses TCP sont obtenues. Étant donné qu'Apache Ignite doit tenter de se connecter à un cluster existant avant de créer un nouveau cluster, il vérifiera chaque IP tour à tour. Cela peut ne pas blesser votre ordinateur portable, mais la protection de numérisation de port est souvent incluse dans certains environnements nuageux. Autrement dit, lorsque vous accédez à un port privé sur une adresse IP, vous ne recevrez aucune réponse tant que le délai d'expiration n'est pas écoulé. Par défaut, c'est 10 secondes. Et si vous avez 3 adresses de 10 ports, vous obtenez 3 * 10 * 10 = 300 secondes d'attente - ces mêmes 5 minutes pour vous connecter.
La solution est évidente: n'enregistrez pas les ports inutiles. Si vous avez trois IP, alors vous avez à peine besoin d'une plage par défaut de 10 ports. C'est pratique lorsque vous testez quelque chose sur la machine locale et exécutez 10 nœuds. Mais dans les systèmes réels, un seul port suffit généralement. Ou désactivez la protection contre l'analyse des ports sur le réseau interne, si vous en avez l'occasion.
Le troisième problème commun est IPv6. Vous pouvez voir d'étranges messages d'erreur réseau: impossible de se connecter, impossible d'envoyer un message, nœud segmenté. Cela signifie que vous êtes tombé du cluster. Très souvent, ces problèmes sont causés par des environnements mixtes IPv4 et IPv6. Cela ne veut pas dire qu'Apache Ignite ne prend pas en charge IPv6, mais pour le moment il y a certains problèmes.
La solution la plus simple consiste à passer l'option à la machine Java
-Djava.net.preferIPv4Stack=true
Ensuite, Java et Apache Ignite n'utiliseront pas IPv6. Cela résout une partie importante des problèmes liés à l'effondrement des clusters.
Préparation de la base de code - nous sérialisons correctement
Le cluster s'est rassemblé, il faut y démarrer quelque chose. L'un des éléments les plus importants dans l'interaction de votre code avec le code Apache Ignite est Marshaller, ou sérialisation. Pour écrire quelque chose dans la mémoire, pour persister, pour envoyer sur le réseau, Apache Ignite sérialise d'abord vos objets. Vous pouvez voir les messages qui commencent par les mots: «ne peut pas être écrit au format binaire» ou «ne peut pas être sérialisé à l'aide de BinaryMarshaller». Il n'y aura qu'un seul tel avertissement dans le journal, mais perceptible. Cela signifie que vous devez modifier un peu plus votre code pour vous lier d'amitié avec Apache Ignite.
Apache Ignite utilise trois mécanismes pour la sérialisation:
JdkMarshaller - sérialisation Java régulière;OptimizedMarshaller - sérialisation Java légèrement optimisée, mais les mécanismes sont les mêmes;BinaryMarshaller est une sérialisation écrite spécifiquement pour Apache Ignite, utilisée partout sous son capot. Elle a un certain nombre d'avantages. Quelque part, nous pouvons éviter une sérialisation et une désérialisation supplémentaires, et quelque part, nous pouvons même obtenir un objet non désérialisé dans l'API, travailler directement avec lui au format binaire comme avec quelque chose comme JSON.
BinaryMarshaller pourra sérialiser et dé-sérialiser vos POJO qui n'ont que des champs et des méthodes simples. Mais si vous avez une sérialisation personnalisée via readObject() et writeObject() , si vous utilisez Externalizable , alors BinaryMarshaller ne fonctionnera pas. Il verra que votre objet ne peut pas être sérialisé par l'enregistrement habituel des champs non transitoires et abandonnera - il reviendra à OptimizedMarshaller .
Pour vous faire des amis de tels objets avec Apache Ignite, vous devez implémenter l'interface Binarylizable . Il est très simple.
Par exemple, il existe un TreeMap standard de Java. Il a une sérialisation et une désérialisation personnalisées via un objet en lecture et en écriture. Il décrit d'abord certains champs, puis écrit la longueur et les données elles-mêmes dans OutputStream .
Implémentation de TreeMap.writeObject()
private void writeObject(java.io.ObjectOutputStream s) throws java.io.IOException {
writeBinary() et readBinary() de Binarylizable fonctionnent exactement de la même manière: BinaryTreeMap s'enveloppe dans un TreeMap normal et l'écrit dans OutputStream . Cette méthode est facile à écrire et augmentera considérablement la productivité.
BinaryTreeMap.writeBinary()
public void writeBinary(BinaryWriter writer) throws BinaryObjectException { BinaryRawWriter rewriter = writer. rewrite (); rawWriter.writeObject(map.comparator()); int size = map.size(); rawWriter.writeInt(size); for (Map.Entry<Object, Object> entry : ((TreeMap<Object, Object>)map).entrySet()) { rawWriter.writeObject(entry.getKey()); rawWriter.writeObject(entry.getValue()); } }
Lancement dans Compute Grid
Ignite vous permet non seulement de stocker des données, mais également d'exécuter l'informatique distribuée. Comment exécuter une sorte de lambda pour qu'il disperse tous les serveurs et s'exécute?
Pour commencer, quel est le problème avec ces exemples de code?
Quel est le problème?
Foo foo = …; Bar bar = ...; ignite.compute().broadcast( () -> doStuffWithFooAndBar(foo, bar) );
Et si oui?
Foo foo = …; Bar bar = ...; ignite.compute().broadcast(new IgniteRunnable() { @Override public void run() { doStuffWithFooAndBar(foo, bar); } });
Comme vous pouvez le deviner, beaucoup connaissent les pièges des lambdas et des classes anonymes, le problème est de capturer les variables de l'extérieur. Par exemple, nous expédions lambda. Il utilise quelques variables déclarées en dehors du lambda. Cela signifie que ces variables voyageront avec elle et traverseront le réseau vers tous les serveurs. Et puis toutes les mêmes questions se posent: ces objets sont-ils compatibles avec BinaryMarshaller ? De quelle taille sont-ils? Souhaitons-nous généralement qu'ils soient transférés quelque part, ou ces objets sont-ils si gros qu'il vaut mieux passer une sorte d'identification et recréer les objets à l'intérieur du lambda déjà de l'autre côté?
La classe anonyme est encore pire. Si le lambda ne peut pas emporter cela avec vous, jetez-le, s'il n'est pas utilisé, alors la classe anonyme le prendra à coup sûr, et cela ne mène généralement à rien de bon.
L'exemple suivant. Lambda à nouveau, mais qui utilise un peu l'API Apache Ignite.
L'utilisation de Ignite à l'intérieur de la fermeture de calcul est incorrecte
ignite.compute().broadcast(() -> { IgniteCache foo = ignite.cache("foo"); String sql = "where id = 42"; SqlQuery qry = new SqlQuery("Foo", sql).setLocal(true); return foo.query(qry); });
Dans la version originale, il prend le cache et y fait localement une sorte de requête SQL. Il s'agit d'un tel modèle lorsque vous devez envoyer une tâche qui ne fonctionne qu'avec des données locales sur des nœuds distants.
Quel est le problème ici? Le lambda capture à nouveau le lien, mais maintenant pas vers l'objet, mais vers le Ignite local sur le nœud avec lequel nous l'envoyons. Et cela fonctionne même, car l'objet Ignite a une méthode readResolve() , qui permet à la désérialisation de remplacer l'Ignite qui est venu sur le réseau par celui local sur le nœud où nous l'avons envoyé. Mais cela entraîne parfois aussi des conséquences indésirables.
Fondamentalement, vous transférez simplement plus de données sur le réseau que vous ne le souhaiteriez. Si vous avez besoin d'obtenir du code que vous ne contrôlez pas le lancement d'Apache Ignite ou de certaines de ses interfaces, alors le plus simple est d'utiliser la méthode Ignintion.localIgnite() . Vous pouvez l'appeler à partir de n'importe quel thread créé par Apache Ignite et obtenir un lien vers un objet local. Si vous avez des lambdas, des services, quoi que ce soit et que vous comprenez que vous avez besoin d'Ignite ici, alors je recommande cette méthode.
Nous utilisons correctement Ignite à l'intérieur de la fermeture de calcul - via localIgnite()
ignite.compute().broadcast(() -> { IgniteCache foo = Ignition.localIgnite().cache("foo"); String sql = "where id = 42"; SqlQuery qry = new SqlQuery("Foo", sql).setLocal(true); return foo.query(qry); });
Et le dernier exemple de cette partie. Apache Ignite possède une grille de services qui peut être utilisée pour déployer des microservices directement dans un cluster, et Apache Ignite aidera à garder le bon nombre d'instances en ligne. Disons que dans ce service, nous avons également besoin d'un lien vers Apache Ignite. Comment l'obtenir? Nous pourrions utiliser localIgnite() , mais ce lien devra ensuite être enregistré manuellement dans le champ.
Le service stocke incorrectement Ignite dans un champ - le prend comme argument pour le constructeur
MyService s = new MyService(ignite) ignite.services().deployClusterSingleton("svc", s); ... public class MyService implements Service { private Ignite ignite; public MyService(Ignite ignite) { this.ignite = ignite; } ... }
Il existe un moyen plus simple. Nous avons toujours des classes complètes, et non lambda, nous pouvons donc annoter le champ en tant que @IgniteInstanceResource . Une fois le service créé, Apache Ignite s'y mettra et vous pourrez l'utiliser en toute sécurité. Je vous conseille fortement de faire exactement cela, et de ne pas essayer de passer Apache Ignite et ses enfants au constructeur.
Le service utilise @IgniteInstanceResource
public class MyService implements Service { @IgniteInstanceResource private Ignite ignite; public MyService() { } ... }
Écriture et lecture de données
Surveiller la référence
Nous avons maintenant un cluster Apache Ignite et du code préparé.
Imaginons ce scénario:
- Un cache
REPLICATED - des copies des données sont disponibles sur tous les nœuds; - La persistance native est en cours d'écriture sur le disque.
Nous commençons un nœud. La persistance native étant activée, nous devons activer le cluster avant de travailler avec lui. Activez. Ensuite, nous lançons quelques nœuds supplémentaires.
Tout semble fonctionner: l'écriture et la lecture vont bien. Tous les nœuds ont des copies des données; vous pouvez arrêter un nœud en toute sécurité. Mais si vous arrêtez le tout premier nœud à partir duquel vous avez commencé le lancement, alors tout se casse: les données disparaissent et les opérations cessent de passer.
La raison en est la topologie de base - les nombreux nœuds qui stockent des données de persistance sur eux. Tous les autres nœuds n'auront pas de données persistantes.
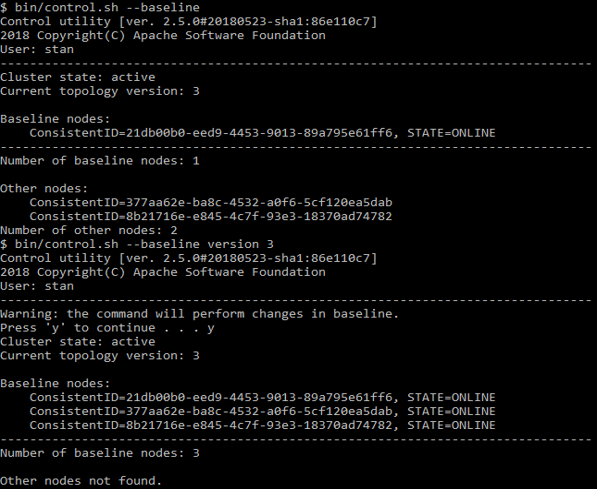
Cet ensemble de nœuds est déterminé pour la première fois au moment de l'activation. Et les nœuds que vous avez ajoutés par la suite ne sont plus inclus dans le nombre de nœuds de base. Autrement dit, une grande partie de la topologie de base se compose d'un seul, le tout premier nœud, lorsqu'il s'arrête, tout se casse. Pour éviter cela, démarrez d'abord tous les nœuds, puis activez le cluster. Si vous devez ajouter ou supprimer un nœud à l'aide de la commande
control.sh --baseline
Vous pouvez voir quels nœuds y sont répertoriés. Le même script peut mettre à jour la ligne de base à son état actuel.
Exemple avec control.sh
Colocation des données
Maintenant que nous savons que les données sont enregistrées, essayez de les lire. Nous avons un support SQL, vous pouvez faire SELECT - presque comme dans Oracle. Mais en même temps, nous pouvons évoluer et fonctionner sur n'importe quel nombre de nœuds, les données sont stockées de manière distribuée. Regardons un tel modèle:
public class Person { @QuerySqlField public Long id; @QuerySqlField public Long orgId; } public class Organization { @QuerySqlField private Long id; }
Demande
SELECT * FROM Person as p JOIN Organization as o ON p.orgId = o.id
ne renverra pas toutes les données. Qu'est-ce qui ne va pas?
Personne ( Person ) fait référence à l'organisation ( Organization ) par ID. Il s'agit d'une clé étrangère classique. Mais si nous essayons de combiner les deux tables et d'envoyer une telle requête SQL, alors avec plusieurs nœuds du cluster, nous ne recevrons pas toutes les données.
Le fait est que, par défaut, SQL JOIN ne fonctionne que dans un seul nœud. Si SQL parcourait constamment le cluster pour collecter des données et renvoyer le résultat complet, ce serait incroyablement lent. Nous perdrions tous les avantages d'un système distribué. Donc, à la place, Apache Ignite ne regarde que les données locales.
Pour obtenir les résultats corrects, nous devons regrouper les données (colocation). Autrement dit, pour la combinaison correcte de personne et d'organisation, les données des deux tables doivent être stockées sur le même nœud.
Comment faire La solution la plus simple consiste à déclarer une clé d'affinité. Il s'agit d'une valeur qui détermine sur quel nœud, dans quelle partition, dans quel groupe d'enregistrements telle ou telle valeur sera située. Si nous déclarons l'ID d'organisation dans Person comme clé d'affinité, cela signifie que les personnes ayant cet ID d'organisation doivent se trouver sur le même nœud que l'organisation avec le même ID.
Si, pour une raison quelconque, vous ne pouvez pas le faire, il existe une autre solution moins efficace: activez les jointures distribuées. Cela se fait via l'API, et la procédure dépend de ce que vous utilisez - Java, JDBC ou autre chose. Ensuite, JOIN sera exécuté plus lentement, mais ils renverront ensuite les résultats corrects.
Voyons comment travailler avec les clés d'affinité. Comment comprendre que tel ou tel ID, tel ou tel champ est approprié pour déterminer l'affinité? Si nous disons que toutes les personnes ayant le même orgId seront stockées ensemble, alors orgId est un groupe indivisible. Nous ne pouvons pas le répartir entre plusieurs nœuds. Si la base de données contient 10 organisations, alors il y aura 10 groupes indivisibles qui peuvent être placés sur 10 nœuds. S'il y a plus de nœuds dans le cluster, alors tous les nœuds "supplémentaires" resteront sans groupes. Ceci est très difficile à définir lors de l'exécution, alors pensez-y à l'avance.
Si vous avez une grande organisation et 9 petites, la taille des groupes sera différente. Mais Apache Ignite ne regarde pas le nombre d'enregistrements dans les groupes d'affinité lorsqu'il les distribue sur les nœuds. Par conséquent, il ne mettra pas un groupe sur un nœud, mais 9 autres sur un autre afin de niveler en quelque sorte la distribution. Au contraire, il leur mettra 5 et 5 (ou 6 et 4, ou même 7 et 3).
Comment répartir uniformément les données? Puissions-nous avoir
- Touches K;
- Une variété de clés d'affinité;
- P partitions, c'est-à-dire de grands groupes de données qu'Apache Ignite distribuera entre les nœuds;
- N nœuds.
Il faut alors que la condition
K >> A >> P >> N
où >> est "beaucoup plus" et les données seront distribuées de manière relativement uniforme.
Par ailleurs, la valeur par défaut est P = 1024.
Très probablement, vous ne réussirez pas dans une distribution uniforme. Ce fut le cas dans Apache Ignite 1.x à 1.9. Cela s'appelait FairAffinityFunction et ne fonctionnait pas très bien - cela entraînait trop de trafic entre les nœuds. Maintenant, l'algorithme est appelé RendezvousAffinityFunction . Il ne donne pas une distribution absolument honnête, l'erreur entre les nœuds sera de plus ou moins 5-10%.
Liste de contrôle pour les nouveaux utilisateurs d'Apache Ignite
- Configurer, lire, stocker des journaux
- Désactivez la multidiffusion, notez uniquement les adresses et les ports que vous utilisez
- Désactiver IPv6
- Préparez vos cours pour
BinaryMarshaller - Gardez une trace de votre ligne de base
- Configurer la collocation d'affinité