Le matériel, dont nous publions la traduction aujourd'hui, se concentrera sur ce qu'il faut faire dans une situation où les données reçues du serveur ne ressemblent pas aux besoins du client. À savoir, nous examinerons d'abord un problème typique de ce type, puis nous analyserons plusieurs façons de le résoudre.

Le problème de l'API serveur défaillante
Prenons un exemple conditionnel basé sur plusieurs projets réels. Supposons que nous développons un nouveau site Web pour une organisation qui existe depuis un certain temps. Elle a déjà des points de terminaison REST, mais ils ne sont pas tout à fait conçus pour ce que nous allons créer. Ici, nous devons accéder au serveur uniquement pour authentifier l'utilisateur, obtenir des informations à son sujet et télécharger une liste des notifications non consultées de cet utilisateur. Par conséquent, nous nous intéressons aux points de terminaison suivants de l'API serveur:
/auth : autorise l'utilisateur et retourne un jeton d'accès./profile : renvoie les informations utilisateur de base./notifications : permet d'obtenir des notifications utilisateur non lues.
Imaginez que notre application ait toujours besoin de recevoir toutes ces données dans une seule unité, c'est-à-dire que, idéalement, ce serait bien si au lieu de trois points de terminaison nous n'en avions qu'un seul.
Cependant, nous sommes confrontés à beaucoup plus de problèmes que trop de points finaux. En particulier, nous parlons du fait que les données que nous recevons ne semblent pas de la meilleure façon.
Par exemple, le point de terminaison
/profile été créé dans les temps anciens, il n'était pas écrit en JavaScript, par conséquent, les noms des propriétés dans les données qui lui sont retournées semblent inhabituels pour une application JS:
{ "Profiles": [ { "id": 1234, "Christian_Name": "David", "Surname": "Gilbertson", "Photographs": [ { "Size": "Medium", "URLS": [ "/images/david.png" ] } ], "Last_Login": "2018-01-01" } ] }
En général - rien de bon.
Certes, si vous regardez ce que le point de terminaison
/notifications produit, les données ci-dessus de
/profile sembleront plutôt intéressantes:
{ "data": { "msg-1234": { "timestamp": "1529739612", "user": { "Christian_Name": "Alice", "Surname": "Guthbertson", "Enhanced": "True", "Photographs": [ { "Size": "Medium", "URLS": [ "/images/alice.png" ] } ] }, "message_summary": "Hey I like your hair, it re", "message": "Hey I like your hair, it really goes nice with your eyes" }, "msg-5678": { "timestamp": "1529731234", "user": { "Christian_Name": "Bob", "Surname": "Smelthsen", "Photographs": [ { "Size": "Medium", "URLS": [ "/images/smelth.png" ] } ] }, "message_summary": "I'm launching my own cryptocu", "message": "I'm launching my own cryptocurrency soon and many thanks for you to look at and talk about" } } }
Ici, la liste des messages est un objet, pas un tableau. De plus, il y a des données utilisateur ici, qui sont tout aussi inconfortablement agencées que dans le cas du point d'extrémité
/profile . Et - voici une surprise - la propriété
timestamp contient le nombre de secondes depuis le début de 1970.
Si je devais dessiner un schéma de l'architecture de ce système incroyablement gênant dont nous venons de parler, il ressemblerait à celui illustré dans la figure ci-dessous. La couleur rouge est utilisée pour les parties de ce circuit qui correspondent à des données mal préparées pour d'autres travaux.
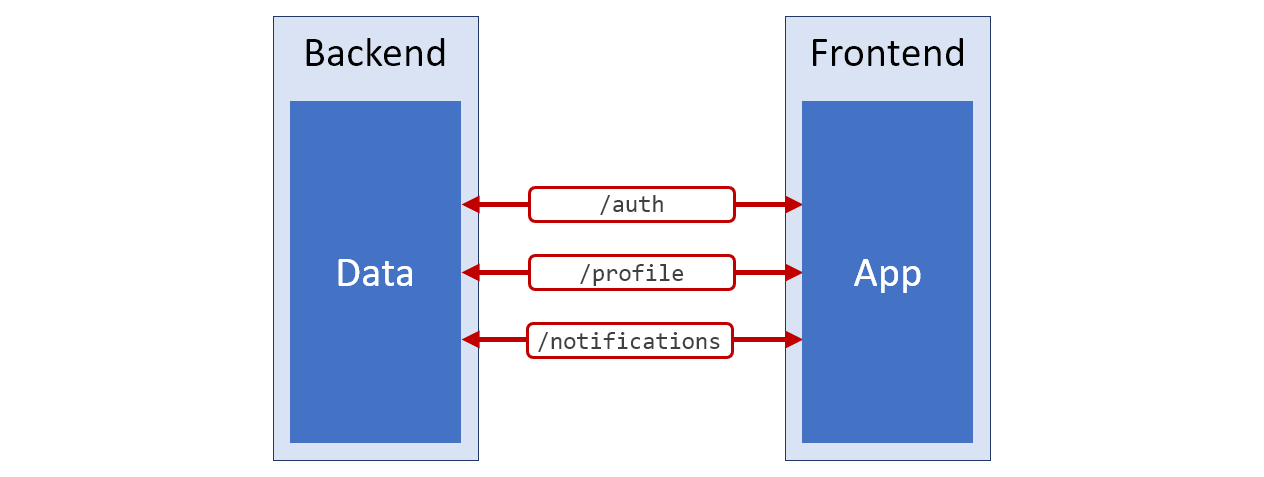 Schéma du système
Schéma du systèmeDans ces circonstances, nous ne pouvons pas nous efforcer de réparer l'architecture de ce système. Vous pouvez simplement charger les données de ces trois API et utiliser ces données dans l'application. Par exemple, si vous devez afficher le nom d'utilisateur complet sur la page, nous devrons combiner les propriétés
Christian_Name et
Surname .
Ici, je voudrais faire une remarque concernant les noms. L’idée de diviser le nom complet d’une personne en nom et prénom personnels est caractéristique des pays occidentaux. Si vous développez quelque chose conçu pour une utilisation internationale, essayez de considérer le nom complet de la personne comme une chaîne indivisible et ne faites aucune hypothèse sur la façon de diviser cette chaîne en parties plus petites afin d'utiliser ce qui s'est passé dans des endroits où besoin de brièveté ou souhaitez faire appel à l'utilisateur dans un style informel.
Revenons à nos structures de données imparfaites. Le premier problème évident que l'on peut voir ici s'exprime dans la nécessité de combiner des données disparates dans le code d'interface utilisateur. Elle consiste dans le fait que nous devrons peut-être répéter cette action à plusieurs endroits. Si vous ne devez le faire qu'occasionnellement, le problème n'est pas si grave, mais si vous en avez besoin souvent, c'est bien pire. En conséquence, il y a des phénomènes indésirables causés par l'inadéquation de la façon dont les données reçues du serveur sont organisées et comment elles sont utilisées dans l'application.
Le deuxième problème est la complexité du code utilisé pour former l'interface utilisateur. Je pense qu'un tel code devrait être, d'une part, aussi simple que possible, et d'autre part - aussi clair que possible. Plus vous devez effectuer de transformations de données internes sur le client, plus sa complexité et son code complexe sont les endroits où les erreurs se cachent généralement.
Le troisième problème concerne les types de données. À partir des extraits de code ci-dessus, vous pouvez voir que, par exemple, les identifiants de message sont des chaînes et les identifiants utilisateur sont des nombres. D'un point de vue technique, tout va bien, mais de telles choses peuvent confondre le programmeur. Regardez aussi la présentation des dates! Mais qu'en est-il du désordre dans la partie des données qui se rapporte à l'image de profil? Après tout, tout ce dont nous avons besoin est une URL menant au fichier correspondant, et non quelque chose à partir duquel nous devrons créer cette URL nous-mêmes, pataugeant dans la jungle des structures de données imbriquées.
Si nous traitons ces données, les transmettons au code de l'interface utilisateur, puis, en analysant les modules, nous ne pouvons pas immédiatement comprendre exactement avec quoi nous travaillons. La conversion de la structure de données interne et de son type lorsque vous travaillez avec elles crée une charge supplémentaire pour le programmeur. Mais sans toutes ces difficultés, il est tout à fait possible de le faire.
En fait, en option, il serait possible d'implémenter un système de type statique pour résoudre ce problème, mais un typage strict n'est pas capable, uniquement par le fait de sa présence, de rendre bon le mauvais code.
Maintenant que vous pouvez voir la gravité du problème auquel nous sommes confrontés, parlons des moyens de le résoudre.
Solution n ° 1: changer l'API du serveur
Si le périphérique gênant de l'API existante n'est pas dicté par des raisons importantes, rien ne vous empêche de créer une nouvelle version mieux adaptée aux besoins du projet et de localiser cette nouvelle version, par exemple, à
/v2 . Cette approche peut peut-être être considérée comme la solution la plus efficace aux problèmes ci-dessus. Le schéma d'un tel système est présenté dans la figure ci-dessous, la structure de données qui correspond parfaitement aux besoins du client est surlignée en vert.
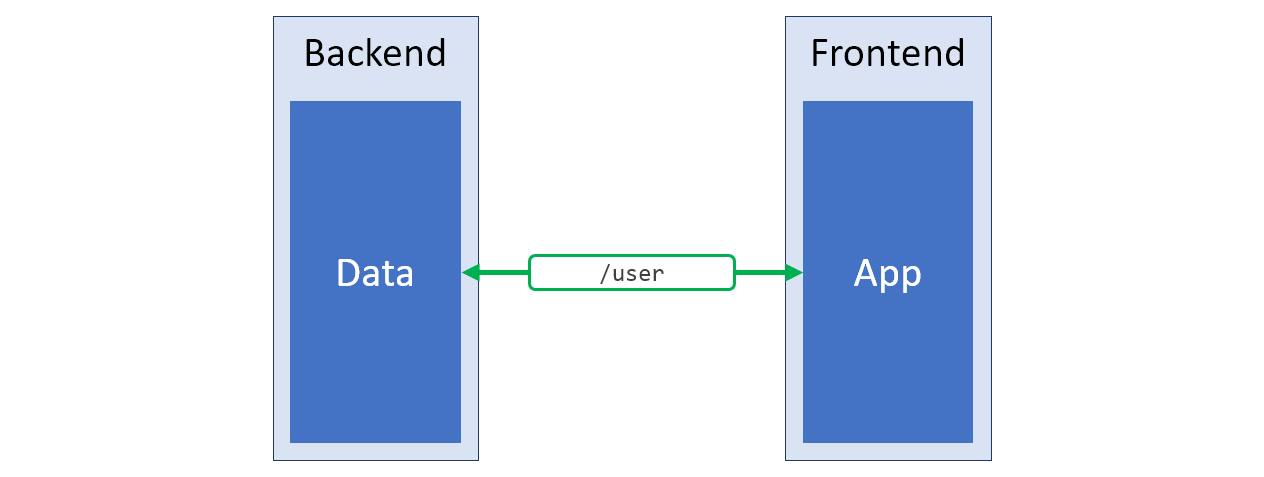 La nouvelle API serveur qui produit exactement ce dont le côté client du système a besoin
La nouvelle API serveur qui produit exactement ce dont le côté client du système a besoinCommençant à développer un nouveau projet, dont l'API laisse à désirer, je suis toujours intéressé par la possibilité de mettre en œuvre l'approche qui vient d'être décrite. Cependant, parfois, le périphérique API, bien que peu pratique, a des objectifs importants, ou changer l'API serveur n'est tout simplement pas possible. Dans ce cas, je recourt à l'approche suivante.
Solution n ° 2: modèle BFF
C'est un bon vieux modèle BFF (
Backend-For-the-Frontend ). En utilisant ce modèle, vous pouvez résumer à partir des points de terminaison REST universels complexes et donner au frontal exactement ce dont il a besoin. Voici une représentation schématique d'une telle solution.
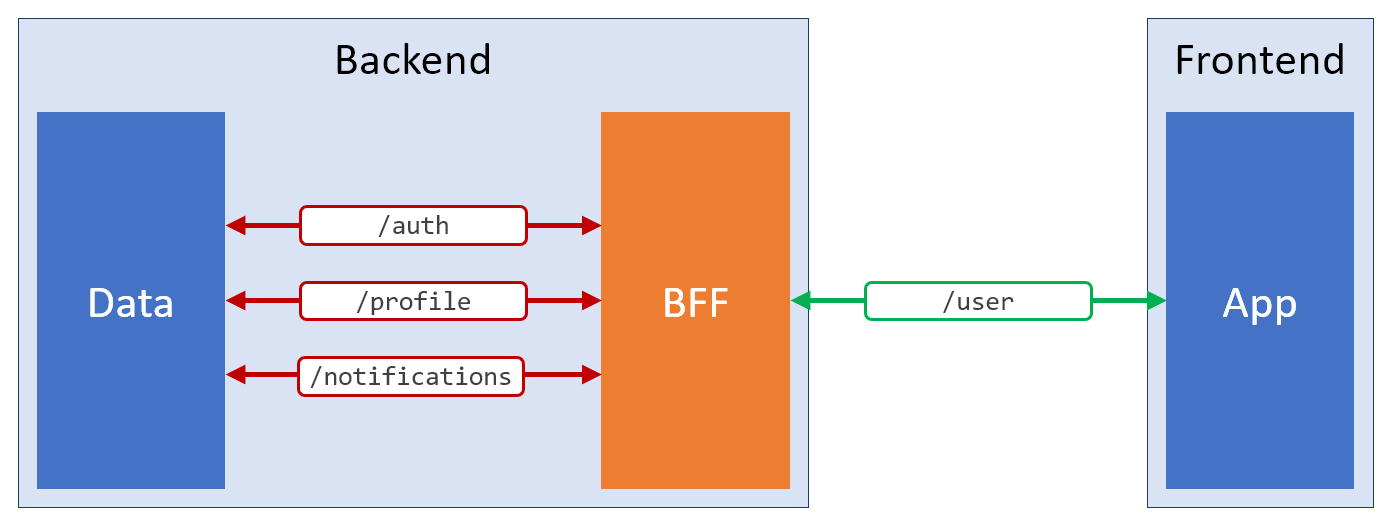 Application du modèle BFF
Application du modèle BFFLe sens de l'existence de la couche BFF est de satisfaire les besoins du frontend. Peut-être qu'il utilisera des points de terminaison REST supplémentaires, ou des services GraphQL, ou des sockets Web, ou toute autre chose. Son objectif principal est de faire tout son possible pour la commodité du côté client de l'application.
Mon architecture préférée est NodeJS BFF, à l'aide de laquelle les développeurs frontaux peuvent faire ce dont ils ont besoin, créant de superbes API pour les applications clientes qu'ils développent. Idéalement, le code correspondant se trouve dans le même référentiel que le code du frontal lui-même, ce qui simplifie le partage de code, par exemple, pour vérifier les données envoyées, à la fois sur le client et sur le serveur.
De plus, cela signifie que les tâches nécessitant des modifications de la partie client de l'application et de son API serveur sont effectuées dans un référentiel. Un peu comme on dit, mais sympa.
Cependant, BFF n'est pas toujours utilisé. Et ce fait nous amène à une autre solution au problème de l'utilisation pratique de mauvaises API de serveur.
Solution n ° 3: modèle BIF
Le modèle BIF (Backend In the Frontend) utilise la même logique qui peut être appliquée à l'aide de BFF (combinant plusieurs API et nettoyage de données), mais cette logique se déplace du côté client. En fait, cette idée n'est pas nouvelle, elle aurait pu être vue il y a vingt ans, mais une telle approche peut aider à travailler avec des API serveur mal organisées, c'est pourquoi nous en parlons. Voici à quoi ça ressemble.
 Application du modèle BIF
Application du modèle BIF▍ Qu'est-ce qu'un BIF?
Comme on peut le voir dans la section précédente, le BIF est un modèle, c'est-à-dire une approche pour comprendre le code et son organisation. Son utilisation n'entraîne pas la nécessité de supprimer toute logique du projet. Il sépare simplement la logique d'un type (modification des structures de données) de la logique d'un autre type (la formation de l'interface utilisateur). Cela ressemble à l'idée d'une «séparation des responsabilités», que tout le monde entend.
Ici, je voudrais noter que, bien que cela ne puisse pas être qualifié de catastrophe, j'ai souvent dû voir des implémentations BIF analphabètes. Par conséquent, il me semble que beaucoup seront intéressés d'entendre une histoire sur la façon de mettre correctement en œuvre ce modèle.
Le code BIF doit être considéré comme un code qui peut être une fois pris et transféré au serveur Node.js, après quoi tout fonctionnera de la même manière qu'auparavant. Ou même le transférer dans un package NPM privé, qui sera utilisé dans plusieurs projets front-end dans le cadre d'une entreprise, ce qui est tout simplement incroyable.
Rappelez-vous que nous avons discuté ci-dessus des principaux problèmes qui surviennent lorsque vous travaillez avec une API de serveur défaillante. Parmi eux se trouve un appel trop fréquent à l'API et le fait que les données retournées par eux ne répondent pas aux besoins du frontend.
Nous décomposerons la solution à chacun de ces problèmes en blocs de code séparés, chacun étant placé dans son propre fichier. Par conséquent, la couche BIF de la partie cliente de l'application se composera de deux fichiers. De plus, un fichier de test leur sera joint.
▍ Combinaison d'appels API
Faire beaucoup d'appels aux API du serveur dans notre code client n'est pas un problème si sérieux. Cependant, je voudrais l'abstraire, pour permettre de répondre à une seule «requête» (du code de l'application à la couche BIF), et obtenir exactement ce qui est nécessaire en réponse.
Bien sûr, dans notre cas, il n'est pas possible de faire trois requêtes HTTP au serveur, mais l'application n'a pas besoin de le savoir.
L'API de ma couche BIF est représentée comme des fonctions. Par conséquent, lorsque l'application a besoin de données sur l'utilisateur, elle appellera la fonction
getUser() , qui lui renverra ces données. Voici à quoi ressemble cette fonction:
import parseUserData from './parseUserData'; import fetchJson from './fetchJson'; export const getUser = async () => { const auth = await fetchJson('/auth'); const [ profile, notifications ] = await Promise.all([ fetchJson(`/profile/${auth.userId}`, auth.jwt), fetchJson(`/notifications/${auth.userId}`, auth.jwt), ]); return parseUserData(auth, profile, notifications); };
Ici, tout d'abord, une demande est faite au service d'authentification pour obtenir un jeton, qui peut être utilisé pour autoriser l'utilisateur (nous ne parlerons pas ici des mécanismes d'authentification, mais notre objectif principal est le BIF).
Après avoir reçu le jeton, vous pouvez exécuter simultanément deux demandes qui reçoivent des données de profil utilisateur et des informations sur les notifications non lues.
Soit dit en passant, regardez à quel point la construction
async/await belle lorsque vous travaillez avec elle en utilisant
Promise.all et en utilisant une affectation destructrice.
Donc, c'était la première étape, nous avons ici résumé le fait que l'accès au serveur comprend trois requêtes. Cependant, l'affaire n'a pas encore été faite. À savoir, faites attention à l'appel à la fonction
parseUserData() , qui, comme vous pouvez en juger par son nom,
parseUserData() les données reçues du serveur. Parlons d'elle.
▍ Nettoyage des données
Je veux immédiatement faire une recommandation qui, je crois, peut sérieusement affecter un projet qui n'avait pas de couche BIF auparavant, en particulier un nouveau projet. Essayez de ne pas penser à ce que vous obtenez du serveur pendant un certain temps. Concentrez-vous plutôt sur les données dont votre application a besoin.
En outre, il est préférable de ne pas essayer, lors de la conception de l'application, de prendre en compte ses éventuels besoins futurs, par exemple, liés à 2021. Essayez simplement de faire fonctionner l'application exactement comme elle le devrait aujourd'hui. Le fait est que l'enthousiasme excessif pour la planification et les tentatives de prédire l'avenir sont la principale raison de la complication injustifiée des projets logiciels.
Revenons donc à nos affaires. Nous savons maintenant à quoi ressemblent les données reçues des trois API de serveur, et nous savons ce qu'elles devraient devenir après analyse.
Il semble que ce soit l'un de ces rares cas où l'utilisation du TDD a vraiment du sens. Par conséquent, nous allons écrire un grand test long pour la fonction
parseUserData() :
import parseUserData from './parseUserData'; it('should parse the data', () => { const authApiData = { userId: 1234, jwt: 'the jwt', }; const profileApiData = { Profiles: [ { id: 1234, Christian_Name: 'David', Surname: 'Gilbertson', Photographs: [ { Size: 'Medium', URLS: [ '/images/david.png', ], }, ], Last_Login: '2018-01-01' }, ], }; const notificationsApiData = { data: { 'msg-1234': { timestamp: '1529739612', user: { Christian_Name: 'Alice', Surname: 'Guthbertson', Enhanced: 'True', Photographs: [ { Size: 'Medium', URLS: [ '/images/alice.png' ] } ] }, message_summary: 'Hey I like your hair, it re', message: 'Hey I like your hair, it really goes nice with your eyes' }, 'msg-5678': { timestamp: '1529731234', user: { Christian_Name: 'Bob', Surname: 'Smelthsen', }, message_summary: 'I\'m launching my own cryptocu', message: 'I\'m launching my own cryptocurrency soon and many thanks for you to look at and talk about' }, }, }; const parsedData = parseUserData(authApiData, profileApiData, notificationsApiData); expect(parsedData).toEqual({ jwt: 'the jwt', id: '1234', name: 'David Gilbertson', photoUrl: '/images/david.png', notifications: [ { id: 'msg-1234', dateTime: expect.any(Date), name: 'Alice Guthbertson', premiumMember: true, photoUrl: '/images/alice.png', message: 'Hey I like your hair, it really goes nice with your eyes' }, { id: 'msg-5678', dateTime: expect.any(Date), name: 'Bob Smelthsen', premiumMember: false, photoUrl: '/images/placeholder.jpg', message: 'I\'m launching my own cryptocurrency soon and many thanks for you to look at and talk about' }, ], }); });
Et voici le code de la fonction elle-même:
const getPhotoFromProfile = profile => { try { return profile.Photographs[0].URLS[0]; } catch (err) { return '/images/placeholder.jpg'; // } }; const getFullNameFromProfile = profile => `${profile.Christian_Name} ${profile.Surname}`; export default function parseUserData(authApiData, profileApiData, notificationsApiData) { const profile = profileApiData.Profiles[0]; const result = { jwt: authApiData.jwt, id: authApiData.userId.toString(), // ID name: getFullNameFromProfile(profile), photoUrl: getPhotoFromProfile(profile), notifications: [], // , }; Object.entries(notificationsApiData.data).forEach(([id, notification]) => { result.notifications.push({ id, dateTime: new Date(Number(notification.timestamp) * 1000), // , , , Unix, name: getFullNameFromProfile(notification.user), photoUrl: getPhotoFromProfile(notification.user), message: notification.message, premiumMember: notification.user.Enhanced === 'True', }) }); return result; }
Je voudrais noter que lorsqu'il est possible de rassembler en un seul endroit deux cents lignes de code chargées de modifier les données dispersées avant cela tout au long de l'application, cela crée un sentiment merveilleux. Maintenant, tout cela est dans un fichier, des tests unitaires sont écrits pour ce code, et tous les moments ambigus sont fournis avec des commentaires.
J'ai dit plus tôt que BFF est mon approche préférée pour combiner et effacer des données, mais il y a un domaine dans lequel BIF est supérieur à BFF. À savoir, les données reçues du serveur peuvent inclure des objets JavaScript qui ne prennent pas en charge JSON, tels que des objets
Date ou
Map (c'est peut-être l'une des fonctionnalités JavaScript les plus sous-utilisées). Par exemple, dans notre cas, nous devons convertir la date provenant du serveur (exprimée en secondes, pas en millisecondes) en un objet JS de type
Date .
Résumé
Si vous pensez que votre projet a quelque chose en commun avec celui sur lequel nous avons examiné les problèmes des API infructueuses, analysez son code en vous posant les questions suivantes sur l'utilisation des données du serveur sur le client:
- Devez-vous combiner des propriétés qui ne sont jamais utilisées séparément (par exemple, le nom et le prénom de l'utilisateur)?
- Le code JS doit-il fonctionner avec des noms de propriété formés d'une manière qui n'est pas acceptée dans JS (quelque chose comme PascalCase)?
- Quels sont les types de données des différents identifiants? Peut-être que parfois ce sont des chaînes, parfois des nombres?
- Comment les dates sont-elles présentées dans votre projet? Peut-être que parfois ce sont des objets
Date JS prêts à être utilisés dans l'interface, et parfois des nombres, voire des chaînes? - Devez-vous souvent vérifier l'existence des propriétés ou vérifier si une entité est un tableau avant de commencer à énumérer les éléments de cette entité pour former un fragment de l'interface utilisateur sur sa base? Se pourrait-il que cette entité ne soit pas un tableau, même vide?
- Devez-vous trier ou filtrer les tableaux lors de la formation de l'interface, qui, idéalement, devrait déjà être correctement triée et filtrée?
- S'il s'avère que, lors de la vérification de l'existence des propriétés, aucune propriété n'est recherchée, devez-vous passer à l'utilisation de certaines valeurs par défaut (par exemple, utiliser l'image standard lorsqu'il n'y a pas de photo d'utilisateur dans les données reçues du serveur)?
- Les propriétés sont-elles uniformément nommées? Arrive-t-il que la même entité puisse avoir des noms différents, ce qui est probablement dû à l'utilisation conjointe, relativement parlant, des «anciennes» et des «nouvelles» API serveur?
- Devez-vous, avec des données utiles, transférer quelque part des données qui ne sont jamais utilisées, uniquement parce qu'elles proviennent de l'API du serveur? Ces données inutilisées interfèrent-elles avec le débogage?
Si vous pouvez répondre positivement à une ou deux questions de cette liste, alors vous ne devriez peut-être pas réparer quelque chose qui fonctionne déjà correctement.
Cependant, si vous, en lisant ces questions, découvrez dans chacun d'eux les problèmes de votre projet, si le périphérique de votre code est inutilement compliqué à cause de tout cela, s'il est difficile à percevoir et à tester, s'il contient des erreurs difficiles à détecter, regardez le modèle BIF.
En fin de compte, je tiens à dire que lors de l'introduction de la couche BIF dans les applications existantes, les choses sont plus faciles car cela peut se faire par étapes, par petites étapes. Disons que la première version de la fonction de préparation des données, appelons-la
parseData() , peut simplement, sans modifications, retourner ce qui vient à son entrée. Ensuite, vous pouvez déplacer progressivement la logique du code responsable de la création de l'interface utilisateur vers cette fonction.
Chers lecteurs! , BIF?
