
La conception académique de l'entrepôt de données recommande de tout garder sous une forme normalisée, avec des connexions entre les deux. Ensuite, l'annulation des changements dans les mathématiques relationnelles fournira un référentiel fiable avec le support des transactions. Atomicité, cohérence, isolement, durabilité - c'est tout. En d'autres termes, le référentiel est spécialement conçu pour mettre à jour les données en toute sécurité. Mais ce n'est pas du tout optimal pour la recherche, surtout avec un geste large à travers les tables et les champs. Besoin d'index, de nombreux index. Les volumes augmentent, l'enregistrement ralentit. SQL LIKE n'est pas indexé et JOIN GROUP BY l'envoie au planificateur de requêtes pour méditer.
La charge croissante d'une machine l'oblige à s'étendre, verticalement dans le plafond ou horizontalement, en achetant quelques nœuds supplémentaires. Les exigences de basculement rendent les données réparties sur plusieurs nœuds. Et l'exigence d'une récupération immédiate après une panne, sans déni de service, vous oblige à configurer le cluster de machines afin qu'à tout moment l'une d'entre elles puisse effectuer à la fois l'écriture et la lecture. Autrement dit, être déjà un maître, ou devenir lui automatiquement et immédiatement.
Le problème de la recherche rapide a été résolu en installant un deuxième référentiel optimisé pour l'indexation à proximité. Recherche plein texte, à facettes, avec stemming et blackjack . Le deuxième stockage accepte les entrées des tables du premier en entrée, analyse et construit l'index. Ainsi, le cluster de stockage de données a été complété par un autre cluster pour leur recherche. Avec une configuration maître similaire pour correspondre au SLA global. Tout va bien, les affaires sont ravies, les administrateurs dorment la nuit ... jusqu'à ce qu'il y ait plus de trois machines dans le cluster maître-maître.
Élastique
Le mouvement NoSQL a considérablement élargi l'horizon d'échelle pour les petites et les grandes données. Les nœuds NoSQL du cluster peuvent distribuer des données entre eux afin que la défaillance d'un ou plusieurs d'entre eux n'entraîne pas un déni de service pour l'ensemble du cluster. Le paiement pour la haute disponibilité des données distribuées était l'incapacité d'assurer leur cohérence complète pour l'enregistrement à un moment donné. Au lieu de cela, NoSQL parle de cohérence éventuelle . Autrement dit, on pense qu'un jour toutes les données se disperseront vers les nœuds du cluster, et elles deviendront cohérentes à long terme.
Le modèle relationnel a donc été complété par le modèle non relationnel et a engendré de nombreux moteurs de base de données qui résolvent les problèmes du triangle CAP avec un certain succès. Les développeurs ont mis à disposition des outils à la mode pour créer leur propre couche de persistance idéale - pour tous les goûts, budgets et profils de charge.
ElasticSearch est un représentant de NoSQL en cluster avec une API JSON RESTful sur le moteur Lucene, open source en Java, capable non seulement de construire un index de recherche, mais aussi de stocker le document original. Une telle feinte permet de repenser le rôle d'un SGBD distinct pour le stockage des originaux, voire de l'abandonner. La fin de l'introduction.
Cartographie
Le mappage dans ElasticSearch est quelque chose comme un schéma (structure de table, en termes de SQL) qui vous indique exactement comment indexer les documents entrants (enregistrements, en termes de SQL). La cartographie peut être statique, dynamique ou absente. Le mappage statique ne se laisse pas modifier. Dynamique vous permet d'ajouter de nouveaux champs. Si le mappage n'est pas spécifié, ElasticSearch le fera par lui-même, après avoir reçu le premier document pour l'écriture. Il analysera la structure des champs, fera des hypothèses sur les types de données qu'ils contiennent, ignorera les paramètres par défaut et les notera. Un tel comportement sans circuit à première vue semble très pratique. Mais en fait, il est plus adapté à l'expérimentation qu'à des surprises en production.
Ainsi, les données sont indexées, et il s'agit d'un processus à sens unique. Une fois créé, le mappage ne peut pas être modifié dynamiquement comme ALTER TABLE en SQL. Parce que la table SQL stocke le document d'origine auquel vous pouvez attacher l'index de recherche. Mais dans ElasticSearch, c'est le contraire. Il est lui-même l'index de recherche auquel vous pouvez attacher le document original. C'est pourquoi le schéma d'index est statique. Théoriquement, on pourrait soit créer un champ dans la cartographie, soit le supprimer. En pratique, ElasticSearch vous permet uniquement d'ajouter des champs. Une tentative de suppression d'un champ ne mène à rien.
Alias
Alias - Il s'agit d'un nom supplémentaire pour l'index ElasticSearch. Il peut y avoir plusieurs alias pour un index. Ou un alias pour plusieurs indices. Ensuite, les indices sont logiquement combinés comme s'ils venaient de l'extérieur et ressemblent à un. Alias est très pratique pour les services qui communiquent avec l'index tout au long de sa vie. Par exemple, les produits d'alias peuvent masquer à la fois products_v2 et products_v25 , sans avoir à modifier les noms dans le service. L'alias est indispensable pour la migration des données, lorsqu'elles sont déjà transférées de l'ancien schéma vers le nouveau, et que vous devez basculer l'application pour qu'elle fonctionne avec le nouvel index. La commutation d'un alias d'index en index est une opération atomique. Autrement dit, il est effectué en une seule étape sans perte.
API de réindexation
La disposition des données, la cartographie, a tendance à changer de temps en temps. De nouveaux champs sont ajoutés, ceux inutiles sont supprimés. Si ElasticSearch joue le rôle du seul référentiel, vous avez besoin d'une sorte d'outil pour modifier le mappage à la volée. Pour ce faire, il existe une commande spéciale pour transférer des données d'un index à un autre, la soi-disant API _reindex . Il fonctionne avec un mappage prêt à l'emploi ou vide de l'index du destinataire, côté serveur, indexant rapidement par lots de 1000 documents à la fois.
La réindexation peut effectuer une conversion de type de champ simple. Par exemple, long en texte et retour en long , ou booléen en texte et retour en booléen . Mais -9,99 en booléen ne sait plus comment, ce n'est pas PHP pour vous . D'un autre côté, la conversion de type n'est pas sûre. Un service écrit dans une langue avec une frappe dynamique peut être pardonné pour un tel péché. Mais si la réindexation ne peut pas convertir le type, le document ne sera tout simplement pas écrit. En général, la migration des données doit se dérouler en 3 étapes: ajouter un nouveau champ, libérer un service avec lui, nettoyer l'ancien.
Un champ est ajouté comme ceci. Le schéma d'index source est pris, une nouvelle propriété est entrée, un index vide est créé. Puis la réindexation commence:
{ "source": { "index": "test" }, "dest": { "index": "test_clone" } }
Le champ est supprimé de la même manière. Le schéma d'index source est pris, le champ est supprimé, un index vide est créé. Ensuite, la réindexation démarre avec une liste des champs à copier:
{ "source": { "index": "test", "_source": ["field1", "field3"] }, "dest": { "index": "test_clone" } }
Pour plus de commodité, les deux cas sont combinés en une fonction de clonage dans Kaizen, un client de bureau pour ElasticSearch. Le clonage peut s'adapter au mappage de l'index de destination. L'exemple ci-dessous montre comment créer un clone partiel à partir d'un index avec trois collections (types, en termes d'ElasticSearch) act , line , scene . Seule la ligne avec deux champs y reste, le mappage statique est activé et le champ speech_number du texte devient long .
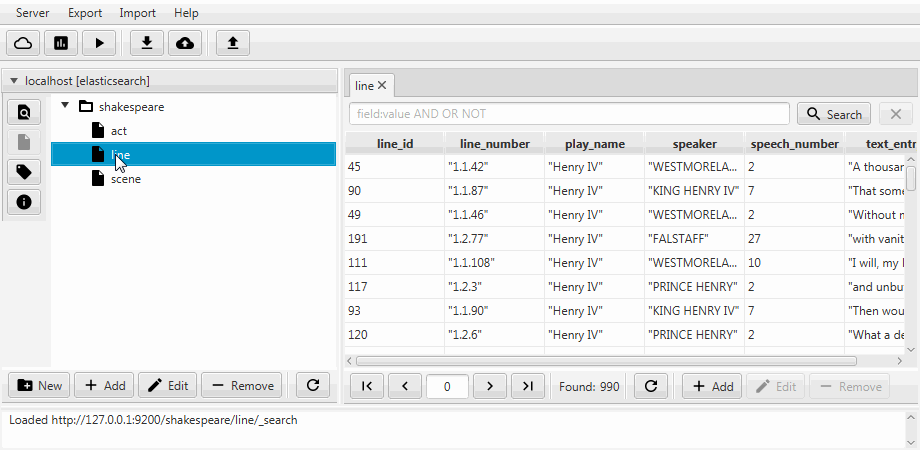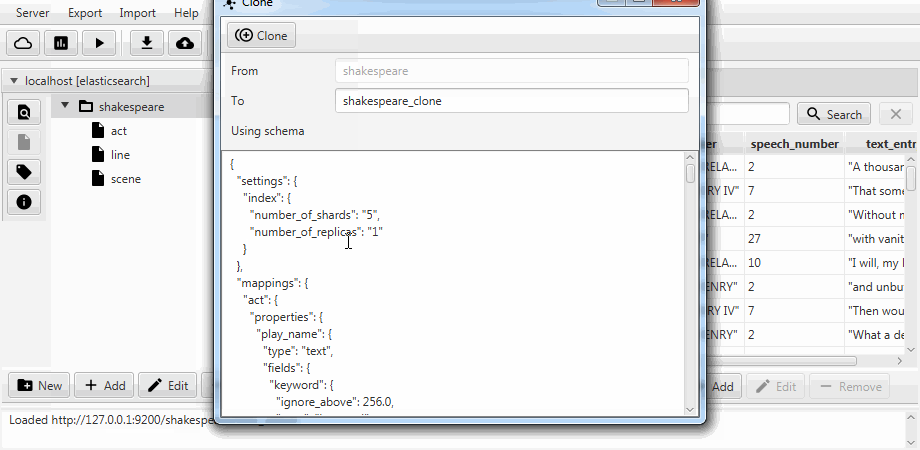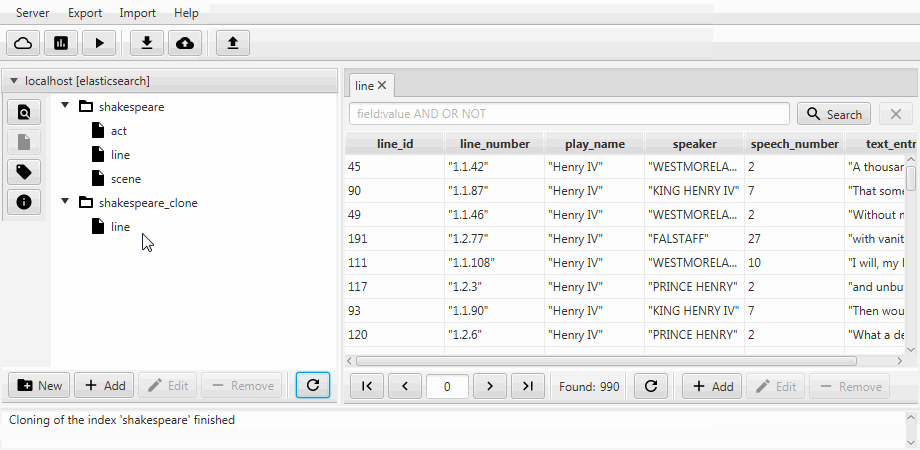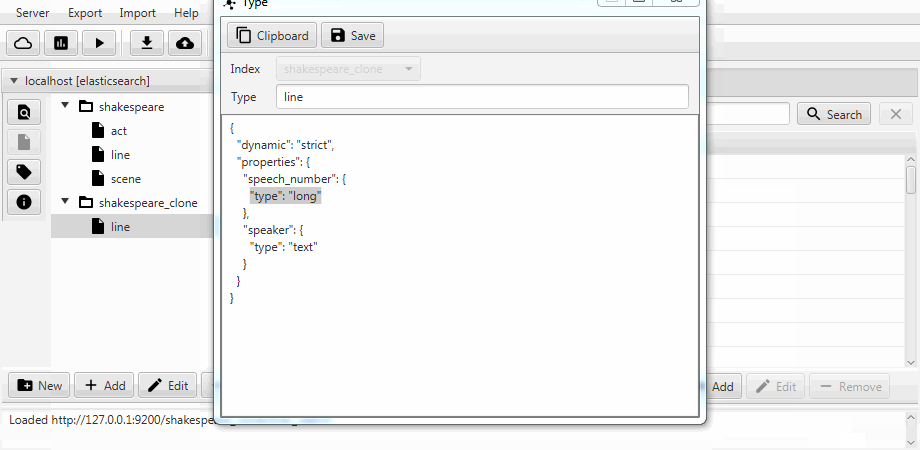
La migration
L'API de réindexation a une caractéristique désagréable - elle ne sait pas comment surveiller les changements dans l'index source. Si quelque chose change là-bas après le début de la réindexation, les modifications ne sont pas reflétées dans l'index des destinataires. Pour résoudre ce problème, ElasticSearch FollowUp Plugin a été développé, qui ajoute des commandes de journalisation. Le plugin peut surveiller l'index, renvoyant au format JSON les actions effectuées sur les documents dans l'ordre chronologique. L'index, le type, l'identifiant du document et son fonctionnement - INDEX ou DELETE sont mémorisés. FollowUp Plugin est publié sur GitHub et compilé pour presque toutes les versions d'ElasticSearch.
Ainsi, pour la migration de données sans perte, vous aurez besoin de FollowUp installé sur le nœud où la réindexation commencera. Il est supposé que l'index a déjà un alias et que toutes les applications fonctionnent avec lui. Juste avant de réindexer, le plugin est activé. Une fois la réindexation terminée, le plug-in s'arrête et l'alias est basculé vers le nouvel index. Ensuite, les actions enregistrées sont reproduites sur l'index du destinataire, rattrapant son état. Malgré la vitesse élevée de réindexation, deux types de collisions peuvent se produire pendant la lecture:
- il n'y a plus de document avec un tel _id dans le nouvel index. Ils ont réussi à supprimer le document après avoir basculé l'alias vers le nouvel index.
- dans le nouvel index, il existe un document avec un tel _id , mais avec un numéro de version supérieur à celui de l'index source. Ils ont réussi à mettre à jour le document après avoir basculé l'alias vers le nouvel index.
Dans ces cas, l'action ne doit pas être reproduite dans l'index de destination. D'autres modifications sont reproduites.
Bon codage!