 Ceci est une vraie histoire. Les événements décrits dans le billet se sont produits dans un pays chaud du 21e siècle. Au cas où, les noms des personnages ont été modifiés. Par respect pour la profession, tout est dit tel qu'il était réellement.
Ceci est une vraie histoire. Les événements décrits dans le billet se sont produits dans un pays chaud du 21e siècle. Au cas où, les noms des personnages ont été modifiés. Par respect pour la profession, tout est dit tel qu'il était réellement.
Salut, Habr. Dans cet article, nous parlerons des tests A / B notoires, malheureusement, même au 21e siècle, ils ne peuvent pas être évités. Des options de test alternatives existent et prospèrent en ligne depuis longtemps, tandis que celles hors ligne doivent s'adapter en fonction de la situation. Nous parlerons d'une telle adaptation dans le commerce de détail hors ligne de masse, en assaisonnant l'expérience de travailler avec un bureau de conseil supérieur, en général, sous cat.
Défi
 Dans le passé, j'ai travaillé sur un projet dans une grande entreprise qui possède un réseau d'épiceries, plus de 500 magasins. Je crains de ne pas nommer l'entreprise, nous appellerons cette organisation l'entreprise. L'essentiel est que les magasins sont de tailles différentes, peuvent varier en taille des dizaines de fois; les magasins peuvent être situés dans différentes villes, villages et villages; les magasins peuvent être situés dans différents quartiers de la ville avec leurs propres données démographiques. Ici, en général, j'ai tendance à dire que si vous avez besoin de tester une hypothèse, alors dans le paradigme du test A / B, il est presque impossible de le faire sans causer de dommages importants à l'entreprise. Considérons tout cela avec l'exemple de la bière. Une fois que le bureau de consultation arrive dans la société, vous savez, ceux-ci viennent d'en haut et disent: «Mais vous savez, mon cher, vous avez ici de la bière qui n'est pas des marques correctes dans les fenêtres, et généralement pas dans l'ordre dont vous avez besoin, expédiez-nous quelques or Kamaz et nous vous dirons de quelles marques vous avez besoin et comment les déployer, selon nos estimations, cela vous rapportera un milliard de dollars canadiens la première année après le pilote. " Le bureau est respecté, il ne fait donc aucun doute qu'un milliard. De même, les méthodes du Bureau ne peuvent être remises en cause, car elles ne peuvent mentir. Mais pas nous. En général, l'auteur de ces lignes revient avec une tâche de la forme "eh bien, regardez là comment ils font le pilote, aidez-les s'ils ont besoin de quelque chose".
Dans le passé, j'ai travaillé sur un projet dans une grande entreprise qui possède un réseau d'épiceries, plus de 500 magasins. Je crains de ne pas nommer l'entreprise, nous appellerons cette organisation l'entreprise. L'essentiel est que les magasins sont de tailles différentes, peuvent varier en taille des dizaines de fois; les magasins peuvent être situés dans différentes villes, villages et villages; les magasins peuvent être situés dans différents quartiers de la ville avec leurs propres données démographiques. Ici, en général, j'ai tendance à dire que si vous avez besoin de tester une hypothèse, alors dans le paradigme du test A / B, il est presque impossible de le faire sans causer de dommages importants à l'entreprise. Considérons tout cela avec l'exemple de la bière. Une fois que le bureau de consultation arrive dans la société, vous savez, ceux-ci viennent d'en haut et disent: «Mais vous savez, mon cher, vous avez ici de la bière qui n'est pas des marques correctes dans les fenêtres, et généralement pas dans l'ordre dont vous avez besoin, expédiez-nous quelques or Kamaz et nous vous dirons de quelles marques vous avez besoin et comment les déployer, selon nos estimations, cela vous rapportera un milliard de dollars canadiens la première année après le pilote. " Le bureau est respecté, il ne fait donc aucun doute qu'un milliard. De même, les méthodes du Bureau ne peuvent être remises en cause, car elles ne peuvent mentir. Mais pas nous. En général, l'auteur de ces lignes revient avec une tâche de la forme "eh bien, regardez là comment ils font le pilote, aidez-les s'ils ont besoin de quelque chose".
Après avoir écouté une courte conférence sur le fonctionnement de leur méthodologie de génération de l'affichage des marchandises sur une fenêtre d'affichage, le désir d'entrer dans les détails de l'algorithme a complètement disparu. J'ai décidé de me concentrer sur la mesure de la qualité, ce qui est beaucoup plus intéressant du point de vue théorique. Il permet également à la Société de ne pas investir dans des projets délibérément non rentables. Ayant accès à des univers parallèles, il serait possible de réaliser un test A / B, où dans l'univers A tout se passe comme avant, et dans l'univers B la disposition des marchandises a changé. Le test A / B est un type d'expérience contrôlée où les utilisateurs sont répartis au hasard en groupes de contrôle et de test. Une intervention est faite dans le groupe test, elle attend un certain temps, l'effet d'une telle intervention sur les indicateurs cibles est mesuré, et enfin les indicateurs des deux groupes sont comparés. Il serait souhaitable de minimiser le biais entre les groupes de contrôle et de test l'un par rapport à l'autre. Par exemple, pour qu'il n'y ait rien de tel que dans le groupe A il n'y a que des villes et dans le groupe B que des villages. Avec les sites, il semble que le problème de l'offset soit facilement résolu: montrez aux utilisateurs avec un ID pair une version, et avec un ID impair une autre version du site. Dans une situation avec une chaîne de magasins, tout n'est pas si simple, peu importe comment vous divisez les utilisateurs ou les magasins, il s'avère toujours que les groupes A et B ne se ressemblent pas. Ce groupe A vient au magasin pendant la journée et B le soir. En alignant le temps, il s'avère que A vient le week-end plus souvent que B. En alignant tous ces détails, il s'avère que pour des résultats statistiquement significatifs, vous devrez attendre six mois et annuler toutes les sociétés de marketing. Si vous frappez les villes, il s'avère que Moscou est présente dans un groupe et absente dans un autre. En général, il y a toujours un changement dans un groupe par rapport à un autre. Diverses campagnes de marketing mondiales et locales, des vacances et des circonstances imprévues sous la forme de réparations de stationnement s'y superposent.
Vous vous souvenez que l'Office vient du sommet des bureaux mondiaux et, naturellement, il a une solution au problème de test. Considérez leur méthodologie, avec un nom marketing fort - la méthodologie de la triple différence.
Méthodologie de la triple différence
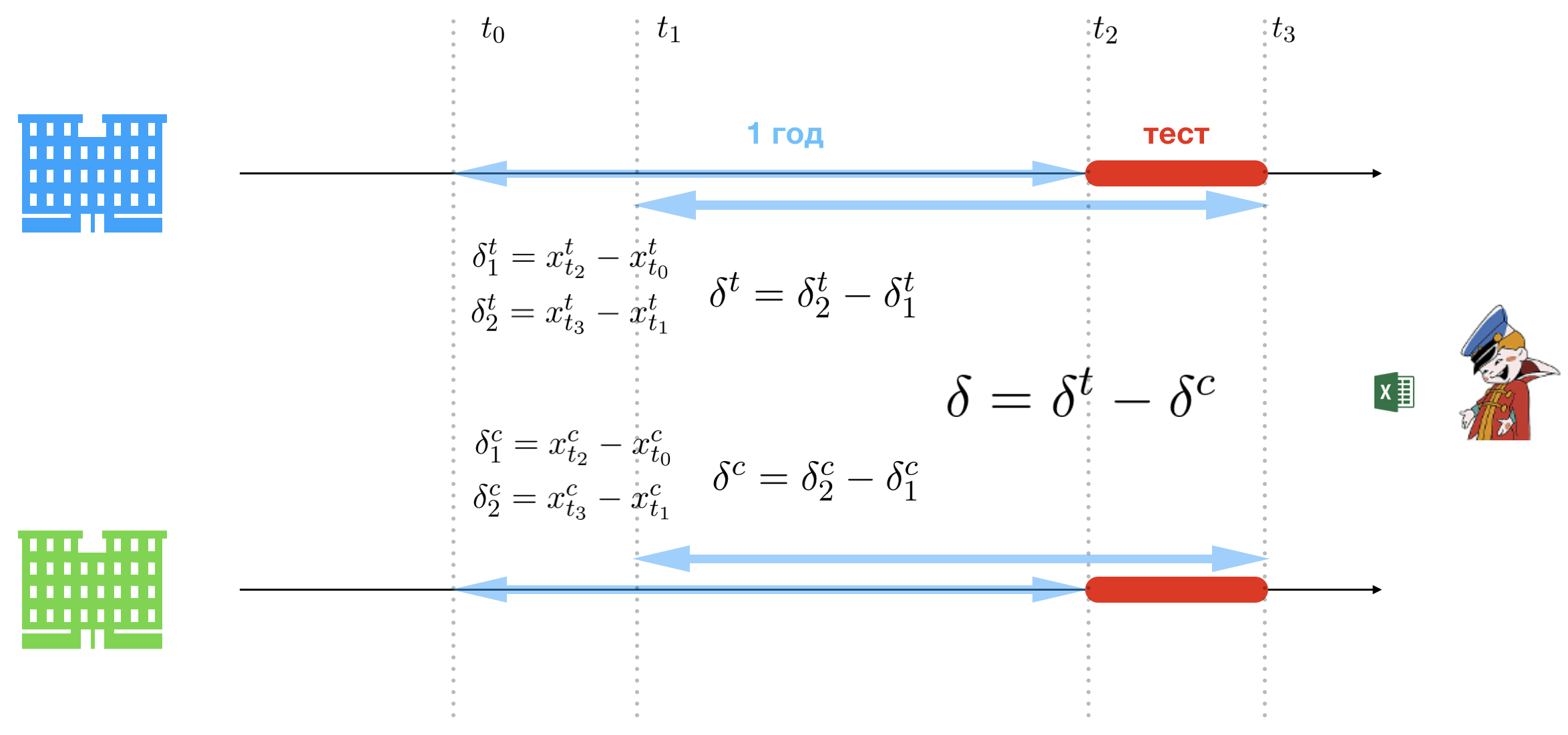
L'essence de la méthodologie de la triple différence est la simplicité. Et pour que les hauts de la Société ne se fatiguent pas lors de l'écoute de la présentation, cette présentation sera réalisée par une dame de pas mauvaise apparence. La simplicité est obtenue en assouplissant les limites du test A / B. La seule difficulté qui reste sur le chemin de l'Office est le choix d'un groupe de contrôle et de test, mais nous allons omettre cette partie du processus, car il n'y a rien d'intéressant à part un large ensemble d'hypothèses douteuses. Ainsi, à la suite d'une analyse approfondie de la chaîne de magasins existante, l'Office en sélectionne deux: un pour le groupe témoin (vert) et un pour le groupe test (bleu).
Nous introduisons la notation suivante:
- : date de début du pilote;
- : date de fin du pilote;
- : date correspondant à la date de début du pilote l'année dernière;
- : date correspondant à la dernière année du pilote.
Ainsi, nous avons deux périodes:
- : période du pilote (période de l'expérience);
- : période correspondant à la période du pilote l'année dernière.
Il est proposé de comparer les revenus du magasin test et la période de contrôle pour les périodes du pilote et il y a un an. Pour ce faire, vous devez compter trois groupes de différences. Indique les ventes par jour dans le magasin de test pour et - dans le contrôle. Le premier groupe définit la référence à partir de laquelle la croissance ou la baisse des ventes au cours de la période pilote sera mesurée:
- : la différence de ventes entre le début du pilote et la même date il y a un an dans le magasin de test;
- : différence de ventes entre la fin du pilote et la même date il y a un an dans le magasin de test;
- : la différence de ventes entre le début du pilote et la même date il y a un an dans le magasin de contrôle;
- : la différence de ventes entre la fin du pilote et la même date il y a un an dans le magasin de contrôle.
Le deuxième groupe de différences définit la croissance ou la baisse des ventes au cours de la période pilote:
- : différence de ventes entre la fin du pilote et le début du pilote dans le magasin de test (ajusté aux dates il y a un an);
- : différence de ventes entre la fin du pilote et le début du pilote dans le magasin de contrôle (ajusté aux dates il y a un an).
Et enfin, la différence décisive détermine quel magasin a le mieux fonctionné au cours de la période pilote:
Eh bien, la décision de mettre en œuvre un projet avec le coût de l'or KAMAZ est très simple si - cela signifie que le magasin test a vendu plus de bière, donc la méthodologie de l'Office fonctionne et donne un effet positif, il faut donc l'introduire. C’est tout.
Test A / B avec ligne de base ML
Après avoir étudié la méthodologie de la triple différence et découvert que les autorités ont déjà approuvé cette méthode de mesure et que le pilote a commencé à planifier, ma main m'a douloureusement frappé au visage. Il s'avère que le bureau nous propose d'investir de l'or KAMAZ dans le projet, même si la méthodologie ne fonctionne pas, et la différence de chiffre d'affaires était de 1 rouble, par hasard. Il était urgent de développer quelque chose qui donnerait au moins une certaine confiance dans l'efficacité de la nouvelle façon de mettre la bière en rayon. Comme vous vous en souvenez, l'un des moyens de réaliser un test A / B honnête hors ligne est l'existence d'univers parallèles, puis dans l'un, nous pouvons introduire la méthodologie de calcul de la bière, dans le second, nous laissons tout tel quel, attendons un peu et comparons les résultats. Mais que se passe-t-il si nous simulons des univers parallèles avec l'apprentissage automatique?

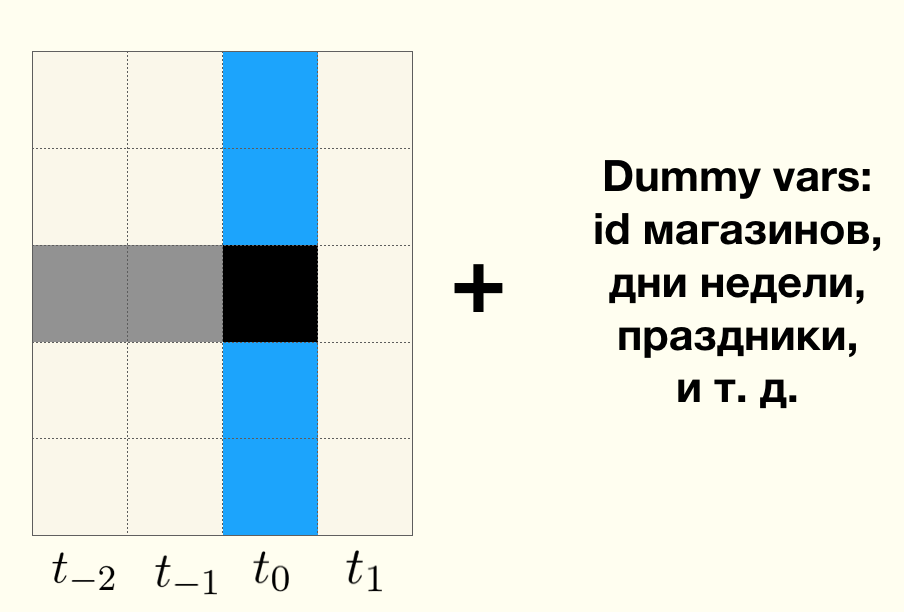
Supposons que nous ayons une série chronologique de ventes quotidiennes pour chaque magasin. La ligne grise continue divise les périodes
avant le pilote et
après le pilote . La zone entre la ligne grise continue et la ligne grise en pointillés est la période des acheteurs s'adaptant au nouveau mix de produits et aux nouvelles marques, pendant cette période, les données de vente n'affectent pas le résultat du test et sont simplement ignorées. Le rouge uni est la vente réelle de n'importe quel magasin au cours de la période précédant le pilote. Sur le côté droit se trouve une combinaison de magasins de test et de contrôle. La ligne pointillée verte est la prévision des ventes de n'importe quel magasin, en utilisant uniquement les données disponibles dans la période précédant le démarrage du pilote.
- La ligne rouge représente les ventes réelles du magasin de contrôle dans la période suivant le lancement du pilote. Pour les magasins du groupe témoin, dans la période suivant le démarrage du pilote, nous n'observons que les prévisions de ventes (vert intermittent) et les ventes réelles (rouge intermittent).
- Le bleu uni représente les ventes réelles du magasin du groupe de test dans la période suivant le lancement du pilote. Dans les magasins test, nous n'observons que les prévisions de ventes (vert intermittent) et les ventes réelles (bleu continu).
La ligne pointillée verte est la ligne de base de l'apprentissage automatique.
Si le pilote a réussi, c.-à-d. Étant donné que l'intervention de test sous la forme d'un assortiment mis à jour et d'une nouvelle présentation a un effet positif sur les ventes quotidiennes, les ventes réelles dans les magasins de test (bleu continu) seront en moyenne plus élevées que les ventes réelles dans les magasins de contrôle (rouge intermittent).
Voyons ce que cela signifie en moyenne. Pour cela nous devons faire une hypothèse, nous supposons que les erreurs de prévision du modèle ont une distribution normale:
 Ajoutons une hypothèse plus audacieuse, disons que les ventes dans la catégorie qui nous intéresse aujourd'hui dépendent linéairement des ventes dans des catégories connexes aujourd'hui et des ventes dans la catégorie qui nous intéresse hier et récemment, et vous pouvez également attribuer à cette dernière diverses métadonnées de magasin pour tenir compte des biais en démographie et autres attributs.
Ajoutons une hypothèse plus audacieuse, disons que les ventes dans la catégorie qui nous intéresse aujourd'hui dépendent linéairement des ventes dans des catégories connexes aujourd'hui et des ventes dans la catégorie qui nous intéresse hier et récemment, et vous pouvez également attribuer à cette dernière diverses métadonnées de magasin pour tenir compte des biais en démographie et autres attributs.
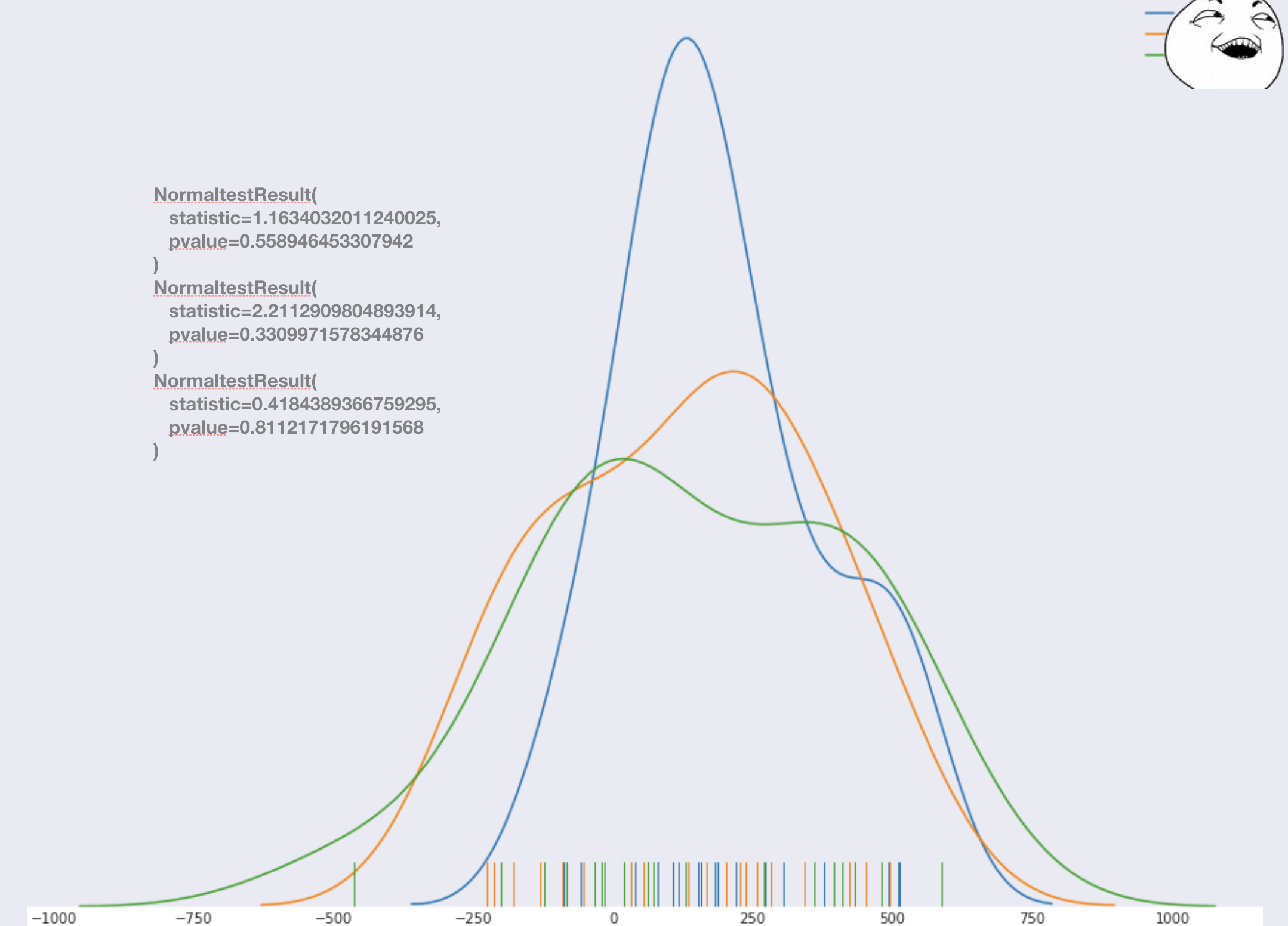
Il s'avère que c'est un modèle très familier . Il est à noter que le choix du modèle n'est pas particulièrement significatif ici, il est important que les erreurs aient une distribution normale, ou une autre connue, afin de réaliser un test statistique d'égalité des valeurs moyennes. Avec de telles déclarations du problème, on peut toujours effectuer un test de normalité au stade de la construction du modèle, et sur presque tous les modèles, la distribution sera normale, selon la version du test de norme , elle est vérifiée.
Donc, en tant que modèle prédictif, j'ai utilisé la régression linéaire, bien que ce ne soit pas une exigence obligatoire, et j'ai été guidé par la simplicité du modèle et l'interprétabilité. Il convient de noter que le modèle est prédictif, mais je l'appellerais explicatif. Puisque nous ne prédisons pas l'avenir, mais utilisons les ventes des catégories connexes le même jour, ce qui est essentiellement un datalik. Nous essayons plutôt d'expliquer les ventes de bière aujourd'hui par les ventes dans le magasin dans son ensemble. Cela crée un nouveau problème pour nous - il est nécessaire de sélectionner soigneusement les fonctionnalités utilisées dans le modèle. Les fonctionnalités liées aux catégories de produits associés peuvent être divisées en trois groupes:
- un groupe de biens qui nous intéressent (bière légère, bière brune, bière zéro, kvas, peut-être même une baleine jaune), certains de ces signes constituent la variable cible et certains sont complètement exclus du modèle;
- des groupes de produits qui sont probablement quelque peu corrélés avec le groupe cible, par exemple l'histoire de l'accordéon selon laquelle les ventes de couches et de bière ont un coefficient de corrélation positif élevé;
- les groupes de produits, qui n'ont certainement pas de corrélation significative avec les groupes cibles, il s'agit d'une telle méthode de régularisation avant même la construction du modèle, et il y aura une grande tentation d'ajouter tout au deuxième groupe, juste au cas où.
Comme variables explicatives, nous ajoutons des caractéristiques du deuxième groupe au modèle. L'idée est que nous supposons que les variations des ventes dans le deuxième groupe dans son ensemble ont un effet significatif sur le premier, et les variations des ventes dans le premier groupe n'ont pas d'effet spécial sur le second dans son ensemble (le second est beaucoup plus important et plus varié).
Une question populaire lors de la présentation de la méthode était la suivante: que se passe-t-il si dans le magasin de test / contrôle il y a une réparation de stationnement, le test se cassera? La réponse est non. Le stationnement affectera les ventes du magasin dans son ensemble, et pas spécifiquement la bière, et les ventes de bière dans notre pays dépendent des ventes dans d'autres catégories et, par conséquent, seront dépensées avec tout le monde. Vous pouvez effectuer de manière convaincante quelques simulations sur un rétrodatage.
Il convient également de noter que nous ne testons pas le calcul par la méthode A contre le calcul par la méthode B, mais nous testons le nouveau comportement par rapport à l' ancien . Cela signifie que les magasins et le groupe dans son ensemble ne doivent pas annuler les campagnes marketing planifiées qui ont été utilisées auparavant. Par exemple, si vous avez réduit le prix de la bière forte de 2 fois au cours des 6 derniers mois, les semaines paires, continuez à le faire, si vous cessez de le faire, le comportement sera différent. Abstenez-vous de mener de nouvelles expériences dans certains magasins.
L'étape de construction du modèle ne peut pas non plus se passer d'écueils. Les groupes de test et de contrôle peuvent inclure des magasins complètement différents, et la tâche de notre modèle est d'aligner tous les magasins, de sorte que pour tout magasin, une erreur de prévision aléatoire est centrée sur zéro (ou également décalée de zéro). Au début, je m'attendais à devoir trier toutes sortes d'hyperparamètres lors de la validation jusqu'à ce que le résultat souhaité soit obtenu. Mais il s'est avéré qu'avec un ensemble suffisant de fonctionnalités, cela est réalisé la première fois, ce qui est intéressant, et la variance de l'erreur aléatoire ne différait pas non plus beaucoup d'un magasin à l'autre. C'est probablement l'une des faiblesses de la méthode, car rien ne garantit que ces conditions seront remplies.  Une revue de la littérature n'a pas non plus donné de résultats, il semble que beaucoup de gens utilisent une base de référence sur l'apprentissage automatique, mais nulle part il n'y a rien sur les garanties théoriques. En général, après toutes ces fraudes, nous obtenons un modèle qui est formé sur toutes les données dans leur intégralité , et nous pouvons faire des prévisions de ventes quotidiennes pour n'importe quel magasin sélectionné . Et nous ne sommes pas particulièrement préoccupés par la précision, mais seulement si la distribution des erreurs pour tous les magasins était également biaisée (plus agréable bien sûr, sinon biaisée par rapport à zéro). Et le fait que la variance puisse être importante, cela n'affectera que la taille de l'ensemble de données requis pour la signification statistique du résultat du test (ce qui signifie que, pour une signification statistique a priori donnée et la puissance statistique du test, le nombre d'observations. La nécessité d'obtenir de tels résultats dépend de la variance )
Une revue de la littérature n'a pas non plus donné de résultats, il semble que beaucoup de gens utilisent une base de référence sur l'apprentissage automatique, mais nulle part il n'y a rien sur les garanties théoriques. En général, après toutes ces fraudes, nous obtenons un modèle qui est formé sur toutes les données dans leur intégralité , et nous pouvons faire des prévisions de ventes quotidiennes pour n'importe quel magasin sélectionné . Et nous ne sommes pas particulièrement préoccupés par la précision, mais seulement si la distribution des erreurs pour tous les magasins était également biaisée (plus agréable bien sûr, sinon biaisée par rapport à zéro). Et le fait que la variance puisse être importante, cela n'affectera que la taille de l'ensemble de données requis pour la signification statistique du résultat du test (ce qui signifie que, pour une signification statistique a priori donnée et la puissance statistique du test, le nombre d'observations. La nécessité d'obtenir de tels résultats dépend de la variance )
Revenons au tableau ci-dessus avec des lignes rouges, vertes et bleues et introduisons enfin le concept d'une moyenne supérieure ou inférieure. Pour les magasins de contrôle, nous pouvons soustraire des ventes quotidiennes réelles (ligne pointillée rouge) les ventes quotidiennes prédites par le modèle (ligne pointillée verte). En conséquence, nous obtenons une distribution normale des erreurs centrées sur zéro, donc rien n'a changé en elles et le modèle coïncidera en moyenne avec la réalité. Pour les magasins du groupe test, nous soustrayons également les ventes quotidiennes réelles (ligne continue bleue), les ventes des modèles de vente quotidiens (vert intermittent), et nous obtenons également une distribution normale. Ensuite, si rien n'a changé, alors le centre sera quelque part autour de zéro; si les ventes se sont améliorées, elles seront décalées vers la droite; si elles ont empiré, puis vers la gauche. Voici à quoi cela ressemble sur les données simulées.

Et nous nous retrouvons ici dans les conditions du test statistique habituel pour l'égalité de la moyenne de deux distributions, et rien ne nous empêche de faire ce test. Pour le test de statistiques, nous devons connaître les éléments suivants:
- et : choisissez vous-même, ou si vous êtes chanceux et que les gens instruits sont assis dans le marketing, alors nous choisissons avec eux;
- dispersion: prise d'un rétrodaté;
- ascenseur: nécessaire pour tester non seulement l'égalité, mais que la croissance des ventes dans le groupe test n'est pas inférieure à un certain montant de dollars canadiens conditionnels; nous ne voulons pas mettre en œuvre un projet qui vaut de l'or kamaz, mais pour qu'il soit rentable et ne soit pas rentable dans cent ans, nous ne construisons pas de pont vers la Crimée.
Ces données seront suffisantes pour calculer le nombre de jours requis pour le pilote. Un autre avantage de cette approche est l'évolutivité. Dans notre cas, le test a donné 60 jours, soit nous avons besoin de 60 jours d'observations pour le test et de 60 jours d'observations pour le groupe témoin pour obtenir des résultats de test statistiquement significatifs. Nous pouvons choisir un magasin dans chaque groupe et attendre 2 mois, ou deux dans chaque groupe et attendre 1 mois, etc. Naturellement, le budget de l'expérience dépend de l'ajout de nouveaux magasins au groupe de test, mais c'est votre tâche de choisir un tel équilibre. Je vous recommande d'étudier ce matériel afin de comprendre la méthodologie de calcul du nombre requis d'observations.
Données réelles
Considérons deux images avec de vraies ventes, le modèle est formé sur plusieurs années de rétro-vente. Boutique numéro un:
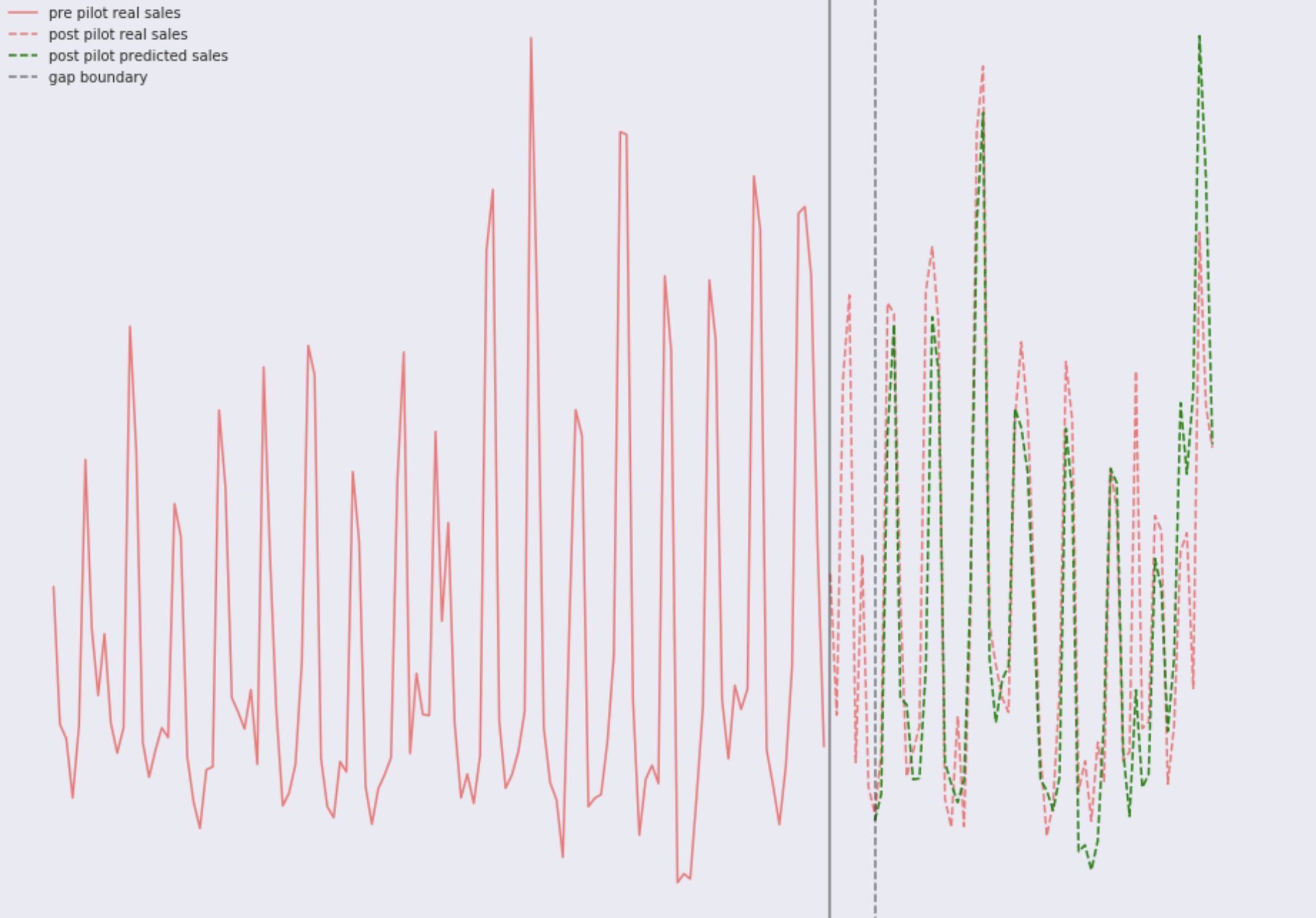
Et stocker le numéro deux:

Comme vous pouvez le voir
, tout est très bon
pour les yeux . Vous remarquerez facilement les tendances hebdomadaires, ainsi que quelque chose s'est clairement passé récemment dans l'un des magasins, la dynamique a changé. Si vous regardez attentivement, vous pouvez voir que le modèle dans les deux magasins fait plusieurs fois une erreur importante. Dans ce cas, il existe deux options:
:
. ,
. , , . , , ( , , ). .
, , , . .

, , . , . , , , … .
Conclusion
— ? , , 1-2 . - , — . , , , , . :
, - , . , , , , . , , , , .
? , , . -, . , .
, , , , . , .