Dans l'article, nous parlerons de l'utilisation de réseaux de neurones convolutifs pour résoudre une tâche commerciale pratique de restauration d'un réalogramme à partir de photographies d'étagères avec des marchandises. En utilisant l'API de détection d'objets Tensorflow, nous formerons le modèle de recherche / localisation. Nous améliorerons la qualité de la recherche de petits produits dans les photographies haute résolution en utilisant une fenêtre flottante et un algorithme de suppression non maximum. Chez Keras, nous mettons en œuvre un classificateur de produits par marque. En parallèle, nous comparerons les approches et les résultats avec les décisions d'il y a 4 ans. Toutes les données utilisées dans l'article sont disponibles pour téléchargement, et le code entièrement fonctionnel est sur
GitHub et est conçu comme un tutoriel.

Présentation
Qu'est-ce qu'un planogramme? Le schéma de disposition de l'affichage des marchandises sur l'équipement commercial de béton du magasin.
Qu'est-ce qu'un réalogramme? La disposition des marchandises sur un équipement commercial spécifique existant dans le magasin ici et maintenant.
Planogramme - comme il se doit, réalogramme - ce que nous avons.

Jusqu'à présent, dans de nombreux magasins, la gestion du reste des marchandises sur des étagères, des étagères, des comptoirs, des étagères est exclusivement du travail manuel. Des milliers d'employés vérifient la disponibilité des produits manuellement, calculent le solde, vérifient l'emplacement avec les exigences. C'est cher et des erreurs sont très probables. Un affichage incorrect ou un manque de marchandises entraîne une baisse des ventes.
En outre, de nombreux fabricants concluent des accords avec des détaillants pour afficher leurs produits. Et comme il y a beaucoup de fabricants, entre eux commence la lutte pour le meilleur endroit sur l'étagère. Tout le monde veut que son produit se situe au centre face aux yeux de l'acheteur et occupe la plus grande surface possible. Il faut un audit continu.
Des milliers de marchandiseurs se déplacent d'un magasin à l'autre pour s'assurer que les produits de leur entreprise sont en rayon et présentés conformément au contrat. Parfois, ils sont paresseux: il est beaucoup plus agréable de faire un rapport sans sortir de chez soi que de se rendre dans un point de vente. Un audit permanent des auditeurs est nécessaire.
Naturellement, la tâche d'automatisation et de simplification de ce processus est résolue depuis longtemps. L'une des parties les plus difficiles a été le traitement d'image: trouver et reconnaître des produits. Et ce n'est que relativement récemment que cette tâche a été tellement simplifiée que pour un cas particulier sous une forme simplifiée, sa solution complète peut être décrite dans un article. Voilà ce que nous allons faire.
L'article contient un minimum de code (uniquement pour les cas où le code est plus clair que le texte). La solution complète est disponible sous forme de tutoriel illustré dans les
cahiers jupyter . L'article ne contient pas de description de l'architecture des réseaux de neurones, des principes des neurones, des formules mathématiques. Dans l'article, nous les utilisons comme un outil d'ingénierie, sans trop entrer dans les détails de son appareil.
Données et approche
Comme pour toute approche basée sur les données, les solutions de réseau neuronal nécessitent des données. Vous pouvez également les assembler manuellement: pour capturer plusieurs centaines de compteurs et les marquer à l'aide, par exemple, de
LabelImg . Vous pouvez commander un balisage, par exemple, sur Yandex.Tolok.
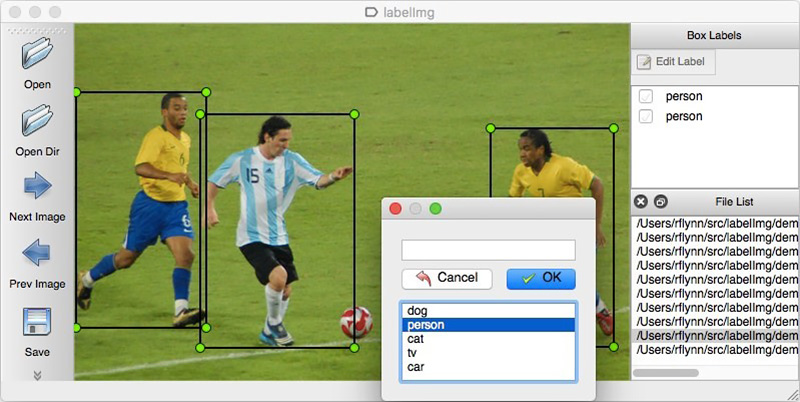
Nous ne pouvons pas divulguer les détails d'un projet réel, nous allons donc expliquer la technologie sur les données ouvertes. Faire du shopping et prendre des photos était trop paresseux (et nous n'aurions pas été compris là-bas), et le désir de faire nous-mêmes le balisage des photos trouvées sur Internet s'est arrêté après le centième objet classé. Heureusement, par hasard, je suis tombé sur les archives de l'ensemble de
données d'épicerie .
En 2014, les employés d'Idea Teknoloji, à Istanbul, en Turquie, ont téléchargé 354 photos de 40 magasins prises sur 4 caméras. Sur chacune de ces photographies, ils ont mis en évidence par des rectangles un total de plusieurs milliers d'objets, dont certains ont été classés en 10 catégories.
Ce sont des photos de paquets de cigarettes. Nous ne faisons pas la promotion ou la promotion du tabagisme. Il n'y avait tout simplement rien de plus neutre. Nous promettons que partout dans l'article, lorsque la situation le permettra, nous utiliserons des photos de chats.

En plus des photos étiquetées des étagères, ils ont écrit un article
Vers la reconnaissance des produits de détail sur les étagères des épiceries avec une solution au problème de localisation et de classification. Cela a établi une sorte de point de référence: notre solution utilisant de nouvelles approches devrait s'avérer plus simple et plus précise, sinon ce n'est pas intéressant. Leur approche consiste en une combinaison d'algorithmes:
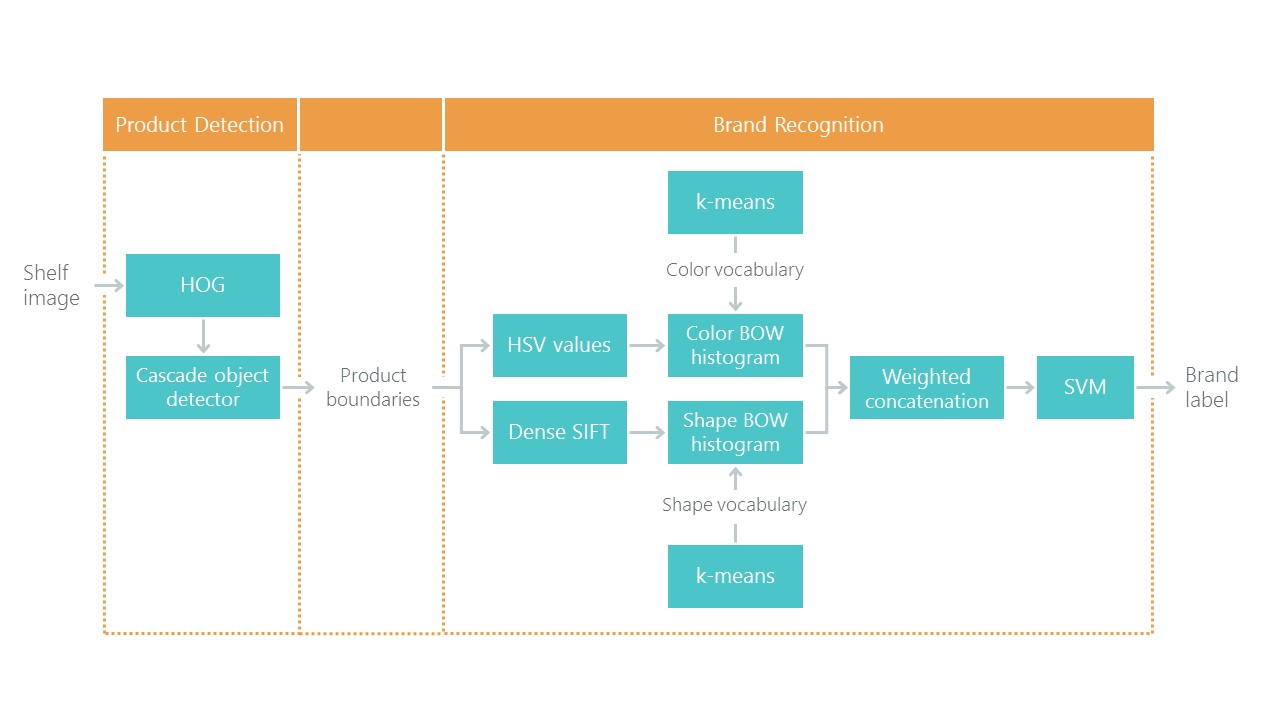
Récemment, les réseaux de neurones convolutifs (CNN) ont révolutionné le domaine de la vision par ordinateur et ont complètement changé l'approche pour résoudre ces problèmes. Au cours des dernières années, ces technologies sont devenues disponibles pour un large éventail de développeurs, et des API de haut niveau comme Keras ont considérablement abaissé leur seuil d'entrée. Désormais, presque tous les développeurs peuvent utiliser toute la puissance des réseaux de neurones convolutifs après seulement quelques jours de datation. L'article décrit l'utilisation de ces technologies à l'aide d'un exemple, montrant comment une cascade complète d'algorithmes peut facilement être remplacée par seulement deux réseaux de neurones sans perte de précision.
Nous allons résoudre le problème par étapes:
- Préparation des données. Nous pompons les archives et les transformons en une vue pratique pour le travail.
- Classification des marques. Nous résolvons le problème de classification en utilisant un réseau de neurones.
- Recherchez des produits sur la photo. Nous formons le réseau neuronal à la recherche de biens.
- Implémentation de la recherche. Nous améliorerons la qualité de la détection à l'aide d'une fenêtre flottante et d'un algorithme de suppression des non-maximums.
- Conclusion Expliquez brièvement pourquoi la vie réelle est beaucoup plus compliquée que cet exemple.
La technologie
Les principales technologies que nous utiliserons: Tensorflow, Keras, API de détection d'objets Tensorflow, OpenCV. Bien que Windows et Mac OS conviennent à l'utilisation de Tensorflow, nous recommandons toujours d'utiliser Ubuntu. Même si vous n'avez jamais travaillé avec ce système d'exploitation auparavant, son utilisation vous fera économiser une tonne de temps. L'installation de Tensorflow pour fonctionner avec le GPU est un sujet qui mérite un article séparé. Heureusement, de tels articles existent déjà. Par exemple,
Installation de TensorFlow sur Ubuntu 16.04 avec un GPU Nvidia . Certaines instructions peuvent être obsolètes.
Étape 1. Préparation des données ( lien github )Cette étape, en règle générale, prend beaucoup plus de temps que la simulation elle-même. Heureusement, nous utilisons des données prédéfinies, que nous convertissons sous la forme dont nous avons besoin.
Vous pouvez télécharger et décompresser de cette façon:
wget https://github.com/gulvarol/grocerydataset/releases/download/1.0/GroceryDataset_part1.tar.gz wget https://github.com/gulvarol/grocerydataset/releases/download/1.0/GroceryDataset_part2.tar.gz tar -xvzf GroceryDataset_part1.tar.gz tar -xvzf GroceryDataset_part2.tar.gz
Nous obtenons la structure de dossiers suivante:
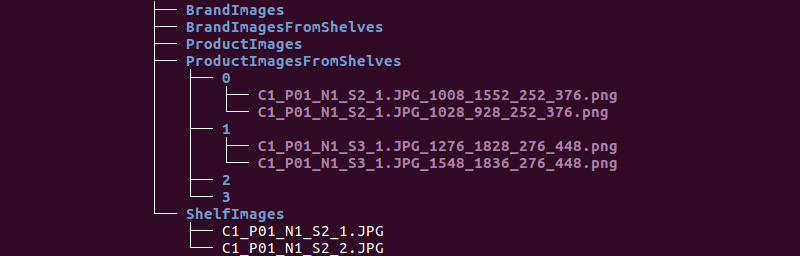
Nous utiliserons les informations des répertoires ShelfImages et ProductImagesFromShelves.
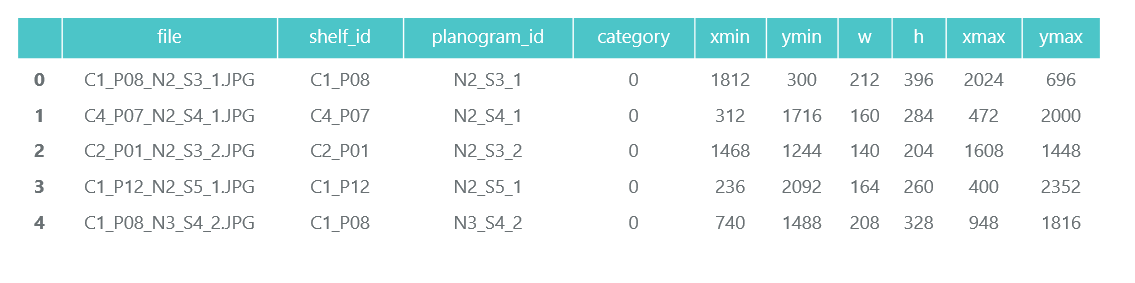
ShelfImages contient des photos des étagères elles-mêmes. Dans le nom, l'identifiant du rack avec l'identifiant de l'image est encodé. Il peut y avoir plusieurs photos d'un rack. Par exemple, une photographie dans son intégralité et 5 photographies en parties avec intersections.
Fichier C1_P01_N1_S2_2.JPG (rack C1_P01, snapshot N1_S2_2):

Nous parcourons tous les fichiers et collectons des informations dans le cadre de données pandas photos_df:
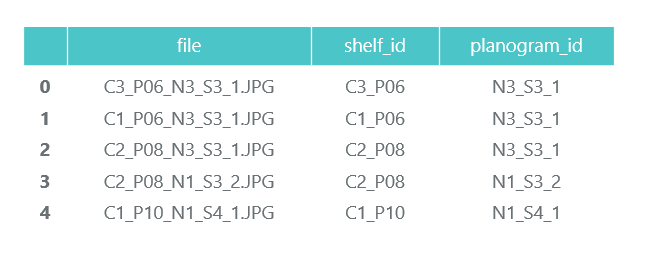
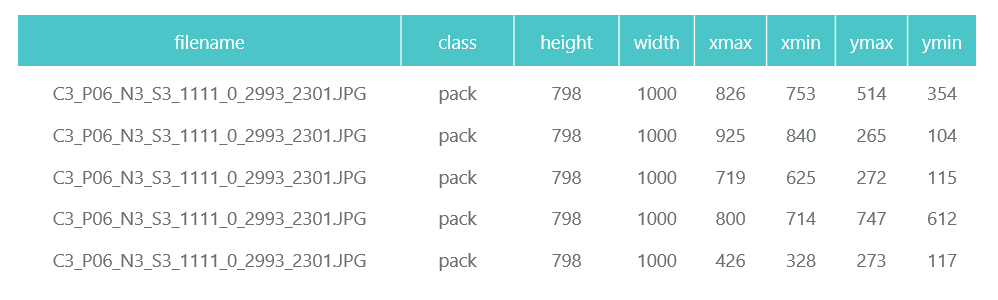
ProductImagesFromShelves contient des photos découpées de marchandises provenant des étagères dans 11 sous-répertoires: 0 - non classé, 1 - Marlboro, 2 - Kent, etc. Afin de ne pas en faire la publicité, nous n'utiliserons que des numéros de catégorie sans spécifier de noms. Les fichiers dans les noms contiennent des informations sur le rack, la position et la taille du pack.
Fichier C1_P01_N1_S3_1.JPG_1276_1828_276_448.png du répertoire 1 (catégorie 1, rack C1_P01, image N1_S3_1, coordonnées du coin supérieur gauche (1276, 1828), largeur 276, hauteur 448):
Nous n'avons pas besoin des photos des packs individuels eux-mêmes (nous les couperons des photos des étagères), et nous collectons des informations sur leur catégorie et leur position dans les produits de la trame de données pandas_df:
À la même étape, nous divisons toutes nos informations en deux sections: formation pour la formation et validation pour le suivi de la formation. Bien sûr, cela ne vaut pas la peine de le faire dans de vrais projets. Et aussi ne faites pas confiance à ceux qui font cela. Vous devez au moins allouer un autre test pour le test final. Mais même avec cette approche pas très honnête, il est important pour nous de ne pas trop nous tromper.
Comme nous l'avons déjà noté, il peut y avoir plusieurs photos d'un rack. En conséquence, le même pack peut se décliner en plusieurs images. Par conséquent, nous vous conseillons de ne pas décomposer par images, et encore plus non par packs, mais par racks. Cela est nécessaire pour qu'il ne se produise pas que le même objet, pris sous des angles différents, se retrouve à la fois en train et en validation.
Nous effectuons une répartition 70/30 (30% des racks vont pour la validation, le reste pour la formation):
Nous nous assurerons que lorsque nous nous séparons, il y a suffisamment de représentants de chaque classe pour la formation et la validation:

La couleur bleue indique le nombre de produits de la catégorie pour la validation et l'orange pour la formation. La situation n'est pas très bonne avec la catégorie 3 pour la validation, mais en principe il y a peu de ses représentants.
Au stade de la préparation des données, il est important de ne pas se tromper, car tout travail ultérieur est basé sur ses résultats. Nous avons encore fait une erreur et passé de nombreuses heures heureuses à essayer de comprendre pourquoi la qualité des modèles est très médiocre. Déjà ressenti comme un perdant pour les technologies de la «vieille école», jusqu'à ce que vous remarquiez accidentellement que certaines des photos originales ont été tournées de 90 degrés, et certaines ont été faites à l'envers.
Dans le même temps, le balisage est effectué comme si les photos étaient correctement orientées. Après une solution rapide, les choses sont devenues beaucoup plus amusantes.
Nous enregistrerons nos données dans des fichiers pkl pour les utiliser dans les étapes suivantes. Au total, nous avons:
- Un annuaire de photographies de racks et de leurs pièces avec des bundles,
- Un bloc de données avec une description de chaque rack avec une note s'il est destiné à la formation,
- Un cadre de données avec des informations sur tous les produits sur les étagères, indiquant leur position, leur taille, leur catégorie et indiquant s'ils sont destinés à la formation.
Pour vérification, nous affichons un rack selon nos données:
 Étape 2. Classification par marque ( lien sur github )
Étape 2. Classification par marque ( lien sur github )La classification des images est la tâche principale dans le domaine de la vision par ordinateur. Le problème est le «fossé sémantique»: la photographie n'est qu'une grande matrice de nombres [0, 255]. Par exemple, 800x600x3 (3 canaux RVB).

Pourquoi cette tâche est difficile:

Comme nous l'avons déjà dit, les auteurs des données que nous utilisons ont identifié 10 marques. C'est une tâche extrêmement simplifiée, car il y a beaucoup plus de marques de cigarettes sur les étagères. Mais tout ce qui ne rentre pas dans ces 10 catégories a été envoyé à 0 - non classé:

"
Leur article propose un tel algorithme de classification avec une précision totale de 92%:

Que ferons-nous:
- Nous préparerons les données pour la formation,
- Nous formons un réseau neuronal convolutionnel avec l'architecture ResNet v1,
- Vérifiez les photos pour validation.
Cela semble «volumineux», mais nous venons d'utiliser l'exemple de Keras «
Former un ResNet sur le jeu de données CIFAR10 » en lui reprenant la fonction de créer ResNet v1.
Pour démarrer le processus de formation, vous devez préparer deux tableaux: x - photos de packs avec une dimension (nombre de packs, hauteur, largeur, 3) et y - leurs catégories avec une dimension (nombre de packs, 10). Le tableau y contient les vecteurs dits chauds. Si la catégorie d'un pack de formation porte le numéro 2 (de 0 à 9), alors cela correspond au vecteur [0, 0, 1, 0, 0, 0, 0, 0, 0, 0].
Une question importante est de savoir quoi faire avec la largeur et la hauteur, car toutes les photos ont été prises avec différentes résolutions à différentes distances. Nous devons choisir une taille fixe, à laquelle nous pouvons apporter toutes nos photos des packs. Cette taille fixe est un méta-paramètre qui détermine comment notre réseau de neurones va s'entraîner et fonctionner.
D'une part, je veux rendre cette taille aussi grande que possible afin qu'aucun détail de l'image ne passe inaperçu. D'un autre côté, avec notre maigre quantité de données d'entraînement, cela peut conduire à un recyclage rapide: le modèle fonctionnera parfaitement sur les données d'entraînement, mais mal sur les données de validation. Nous avons choisi la taille 120x80, peut-être sur une taille différente nous obtiendrions un meilleur résultat. Fonction zoom:
Mettez à l'échelle et affichez un pack pour vérification. Le nom de la marque est difficile à lire par une personne, voyons comment le réseau neuronal va faire face à la tâche de classification:

Après préparation selon le flag obtenu à l'étape précédente, on décompose les tableaux x et y en x_train / x_validation et y_train / y_validation, on obtient:
x_train shape: (1969, 120, 80, 3) y_train shape: (1969, 10) 1969 train samples 775 validation samples
Les données sont préparées, nous copions la fonction du constructeur de réseau neuronal de l'architecture ResNet v1 à partir de l'exemple Keras:
def resnet_v1(input_shape, depth, num_classes=10): …
Nous construisons un modèle:
model = resnet_v1(input_shape=x_train.shape[1:], depth=depth, num_classes=num_classes) model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=lr_schedule(0)), metrics=['accuracy'])
Nous avons un ensemble de données assez limité. Par conséquent, afin d'empêcher le modèle de voir la même photo à chaque fois pendant la formation, nous utilisons l'augmentation: décaler l'image au hasard et la faire pivoter un peu. Keras fournit cet ensemble d'options pour cela:
Nous commençons le processus de formation.
Après formation et évaluation, nous obtenons une précision de l'ordre de 92%. Vous pouvez obtenir une précision différente: il y a très peu de données, donc la précision dépend beaucoup du succès de la partition. Sur cette partition, nous n'avons pas obtenu une précision significativement supérieure à celle qui était indiquée dans l'article, mais nous n'avons pratiquement rien fait nous-mêmes et avons écrit peu de code. De plus, nous pouvons facilement ajouter une nouvelle catégorie, et la précision devrait (en théorie) augmenter considérablement si nous préparons plus de données.
Pour l'intérêt, comparez les matrices de confusion:
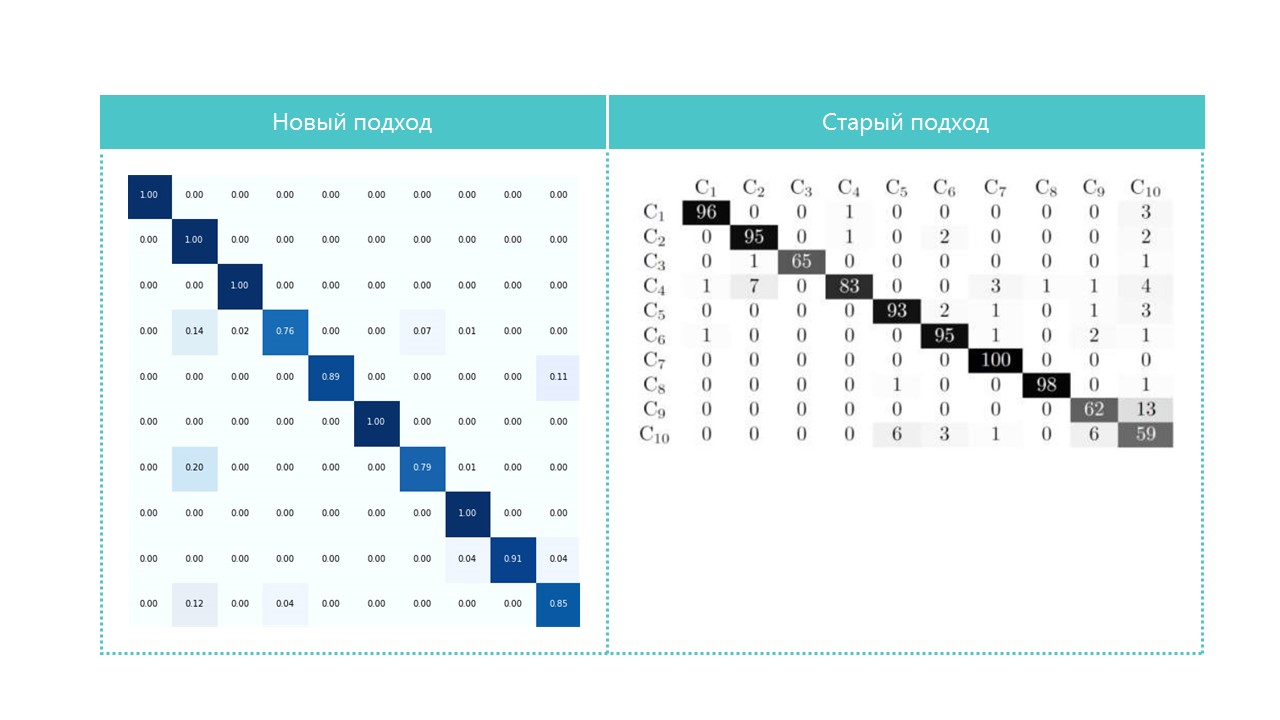
Presque toutes les catégories que notre réseau neuronal définit mieux, à l'exception des catégories 4 et 7. Il est également utile de regarder les représentants les plus brillants de chaque cellule de matrice de confusion:
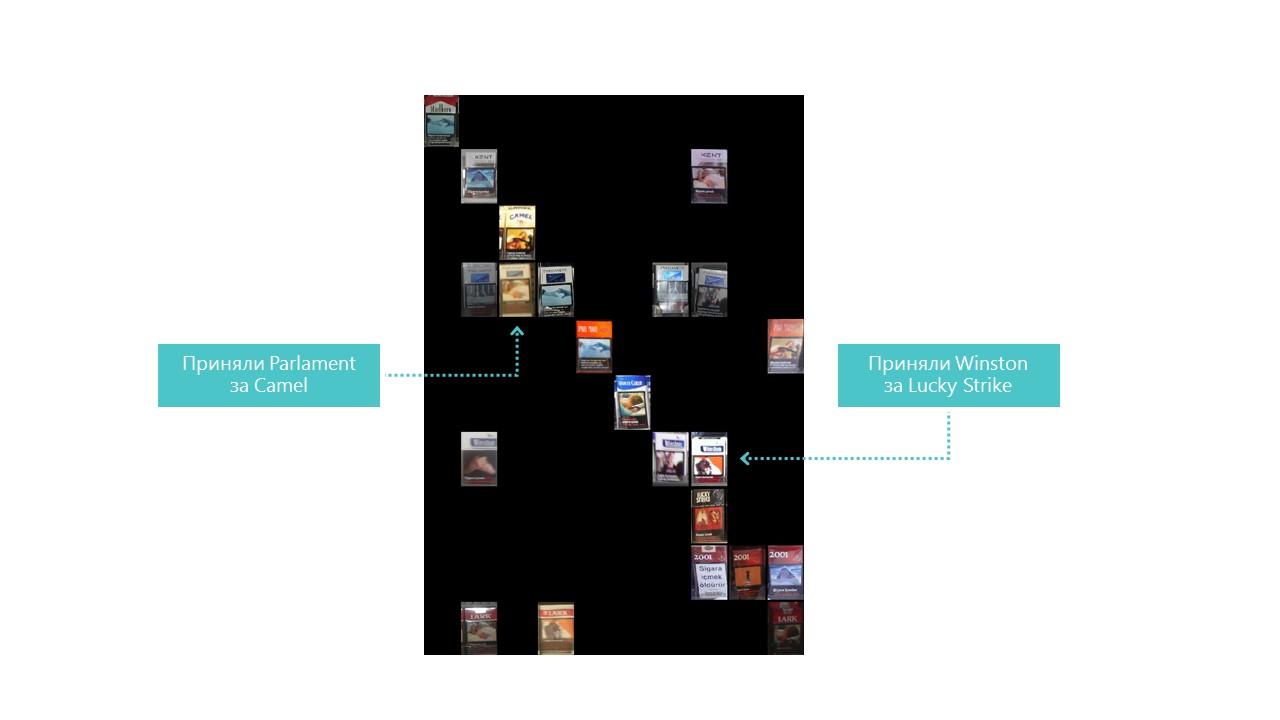
Vous pouvez également comprendre pourquoi le Parlement a été confondu avec Camel, mais pourquoi Winston a été confondu avec Lucky Strike est complètement incompréhensible, mais ils n'ont rien en commun. C'est le principal problème des réseaux de neurones - l'opacité totale de ce qui se passe à l'intérieur. Vous pouvez bien sûr visualiser certaines couches, mais pour nous, cette visualisation ressemble à ceci:

Une opportunité évidente d'améliorer la qualité de la reconnaissance dans nos conditions est d'ajouter plus de photos.
Ainsi, le classificateur est prêt. Allez au détecteur.
Étape 3. Recherchez des produits sur la photo ( lien sur github )Les tâches importantes suivantes dans le domaine de la vision par ordinateur sont la segmentation sémantique, la localisation, la recherche d'objets et la segmentation d'instances.
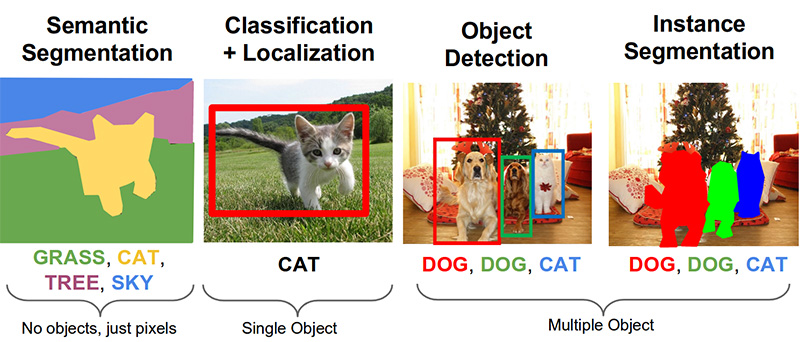
Notre tâche nécessite la détection d'objets. L'article de 2014 propose une approche basée sur la méthode Viola-Jones et HOG avec une précision visuelle:

Grâce à l'utilisation de restrictions statistiques supplémentaires, leur précision est très bonne:

Maintenant, la tâche de reconnaissance d'objets est résolue avec succès à l'aide de réseaux de neurones. Nous utiliserons le système API de détection d'objets Tensorflow et formerons un réseau de neurones avec l'architecture SSD Mobilenet V1. La formation d'un tel modèle à partir de zéro nécessite beaucoup de données et peut prendre des jours, nous utilisons donc un modèle formé sur les données COCO selon le principe de l'apprentissage par transfert.
Le concept clé de cette approche est le suivant. Pourquoi un enfant n'a-t-il pas besoin de montrer des millions d'objets pour qu'il apprenne à trouver et à distinguer une balle d'un cube? Parce que l'enfant a 500 millions d'années de développement du cortex visuel. L'évolution a fait de la vision le plus grand système sensoriel. Près de 50% (mais ce n'est pas exact) des neurones du cerveau humain sont responsables du traitement de l'image. Les parents ne peuvent montrer que le ballon et le cube, puis corriger l'enfant plusieurs fois pour qu'il trouve et se distingue parfaitement l'un de l'autre.
D'un point de vue philosophique (avec des différences techniques plus que générales), l'apprentissage par transfert dans les réseaux de neurones fonctionne de manière similaire. Les réseaux de neurones convolutifs sont constitués de niveaux, chacun définissant des formes de plus en plus complexes: il identifie les points clés, les combine en lignes, qui à leur tour se combinent en figures. Et ce n'est qu'au dernier niveau de la totalité des signes trouvés que détermine l'objet.
Les objets du monde réel ont beaucoup en commun. Lors du transfert d'apprentissage, nous utilisons les niveaux déjà définis de définition des fonctionnalités de base et ne formons que les couches responsables de l'identification des objets. Pour ce faire, quelques centaines de photos et quelques heures de fonctionnement d'un GPU ordinaire nous suffisent. Le réseau a été initialement formé sur le jeu de données COCO (Microsoft Common Objects in Context), qui comprend 91 catégories et 2 500 000 images! Beaucoup, mais pas 500 millions d'années d'évolution.
En regardant un peu en avant, cette animation gif (un peu lente, ne défile pas immédiatement) de tensorboard visualise le processus d'apprentissage. Comme vous pouvez le voir, le modèle commence à produire un résultat de haute qualité presque immédiatement, puis vient le broyage:

Le «formateur» du système API de détection d'objets Tensorflow peut effectuer indépendamment une augmentation, découper des parties aléatoires des images pour la formation et sélectionner des exemples «négatifs» (sections de photos qui ne contiennent aucun objet). En théorie, aucun prétraitement photo n'est nécessaire. Cependant, sur un ordinateur personnel avec un disque dur et une petite quantité de RAM, il a refusé de travailler avec des images haute résolution: au début, il a suspendu pendant longtemps, a bruissé avec un disque, puis s'est envolé.
En conséquence, nous avons compressé les photos à une taille de 1000x1000 pixels tout en conservant le rapport d'aspect. Mais comme lors de la compression d'une grande photo, beaucoup de signes sont perdus, d'abord plusieurs carrés de taille aléatoire ont été coupés de chaque photo du rack et compressés en 1000x1000. En conséquence, les packs en haute résolution (mais pas assez) et en petits (mais beaucoup) sont tombés dans les données d'entraînement. Nous répétons: cette étape est forcée et, très probablement, complètement inutile et peut-être nuisible.
Les photos préparées et compressées sont enregistrées dans des répertoires séparés (eval et train), et leur description (avec les bundles qu'ils contiennent) est formée sous la forme de deux données pandas (train_df et eval_df):
Le système API de détection d'objets Tensorflow requiert que les entrées soient présentées sous forme de fichiers tfrecord. Vous pouvez les former à l'aide de l'utilitaire, mais nous en ferons un code:
def class_text_to_int(row_label): if row_label == 'pack': return 1 else: None def split(df, group): data = namedtuple('data', ['filename', 'object']) gb = df.groupby(group) return [data(filename, gb.get_group(x)) for filename, x in zip(gb.groups.keys(), gb.groups)] def create_tf_example(group, path): with tf.gfile.GFile(os.path.join(path, '{}'.format(group.filename)), 'rb') as fid: encoded_jpg = fid.read() encoded_jpg_io = io.BytesIO(encoded_jpg) image = Image.open(encoded_jpg_io) width, height = image.size filename = group.filename.encode('utf8') image_format = b'jpg' xmins = [] xmaxs = [] ymins = [] ymaxs = [] classes_text = [] classes = [] for index, row in group.object.iterrows(): xmins.append(row['xmin'] / width) xmaxs.append(row['xmax'] / width) ymins.append(row['ymin'] / height) ymaxs.append(row['ymax'] / height) classes_text.append(row['class'].encode('utf8')) classes.append(class_text_to_int(row['class'])) tf_example = tf.train.Example(features=tf.train.Features(feature={ 'image/height': dataset_util.int64_feature(height), 'image/width': dataset_util.int64_feature(width), 'image/filename': dataset_util.bytes_feature(filename), 'image/source_id': dataset_util.bytes_feature(filename), 'image/encoded': dataset_util.bytes_feature(encoded_jpg), 'image/format': dataset_util.bytes_feature(image_format), 'image/object/bbox/xmin': dataset_util.float_list_feature(xmins), 'image/object/bbox/xmax': dataset_util.float_list_feature(xmaxs), 'image/object/bbox/ymin': dataset_util.float_list_feature(ymins), 'image/object/bbox/ymax': dataset_util.float_list_feature(ymaxs), 'image/object/class/text': dataset_util.bytes_list_feature(classes_text), 'image/object/class/label': dataset_util.int64_list_feature(classes), })) return tf_example def convert_to_tf_records(images_path, examples, dst_file): writer = tf.python_io.TFRecordWriter(dst_file) grouped = split(examples, 'filename') for group in grouped: tf_example = create_tf_example(group, images_path) writer.write(tf_example.SerializeToString()) writer.close() convert_to_tf_records(f'{cropped_path}train/', train_df, f'{detector_data_path}train.record') convert_to_tf_records(f'{cropped_path}eval/', eval_df, f'{detector_data_path}eval.record')
Il nous reste à préparer un répertoire spécial et à démarrer les processus:
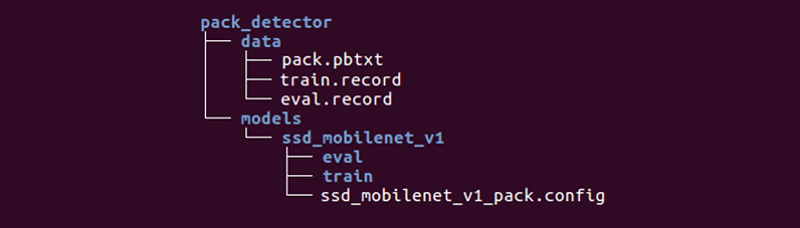
La structure peut être différente, mais nous la trouvons très pratique.
Le répertoire de données contient les fichiers que nous avons créés avec tfrecords (train.record et eval.record), ainsi que pack.pbtxt avec les types d'objets pour lesquels nous formerons le réseau neuronal. Nous n'avons qu'un seul type d'objet à définir, donc le fichier est très court:
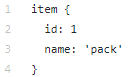
Le répertoire des modèles (il peut y avoir de nombreux modèles pour résoudre un problème) dans le répertoire enfant ssd_mobilenet_v1 contient les paramètres de formation dans le fichier .config, ainsi que deux répertoires vides: train et eval. En train, le «formateur» enregistrera les points de contrôle du modèle, «l'évaluateur» les récupérera, les exécutera sur les données pour évaluation et les placera dans le répertoire eval. Tensorboard gardera une trace de ces deux répertoires et affichera les informations sur le processus.
Description détaillée de la structure des fichiers de configuration, etc. peut être trouvé
ici et
ici . Les instructions d'installation de l'API de détection d'objets Tensorflow peuvent être trouvées
ici .
Nous allons dans le répertoire models / research / object_detection et dégonflons le modèle pré-formé:
wget http://download.tensorflow.org/models/object_detection/ssd_mobilenet_v1_coco_2017_11_17.tar.gz tar -xvzf ssd_mobilenet_v1_coco_2017_11_17.tar.gz
Nous y copions le répertoire pack_detector que nous avons préparé.
Commencez d'abord le processus de formation:
python3 train.py --logtostderr \ --train_dir=pack_detector/models/ssd_mobilenet_v1/train/ \ --pipeline_config_path=pack_detector/models/ssd_mobilenet_v1/ssd_mobilenet_v1_pack.config
Nous commençons le processus d'évaluation. Nous n'avons pas de deuxième carte vidéo, nous la lançons donc sur le processeur (en utilisant l'instruction CUDA_VISIBLE_DEVICES = ""). Pour cette raison, il sera très en retard concernant le processus de formation, mais ce n'est pas si mal:
CUDA_VISIBLE_DEVICES="" python3 eval.py \ --logtostderr \ --checkpoint_dir=pack_detector/models/ssd_mobilenet_v1/train \ --pipeline_config_path=pack_detector/models/ssd_mobilenet_v1/ssd_mobilenet_v1_pack.config \ --eval_dir=pack_detector/models/ssd_mobilenet_v1/eval
Nous commençons le processus de tensorboard:
tensorboard --logdir=pack_detector/models/ssd_mobilenet_v1
Après cela, nous pouvons voir de beaux graphiques, ainsi que le travail réel du modèle sur les données estimées (gif au début):
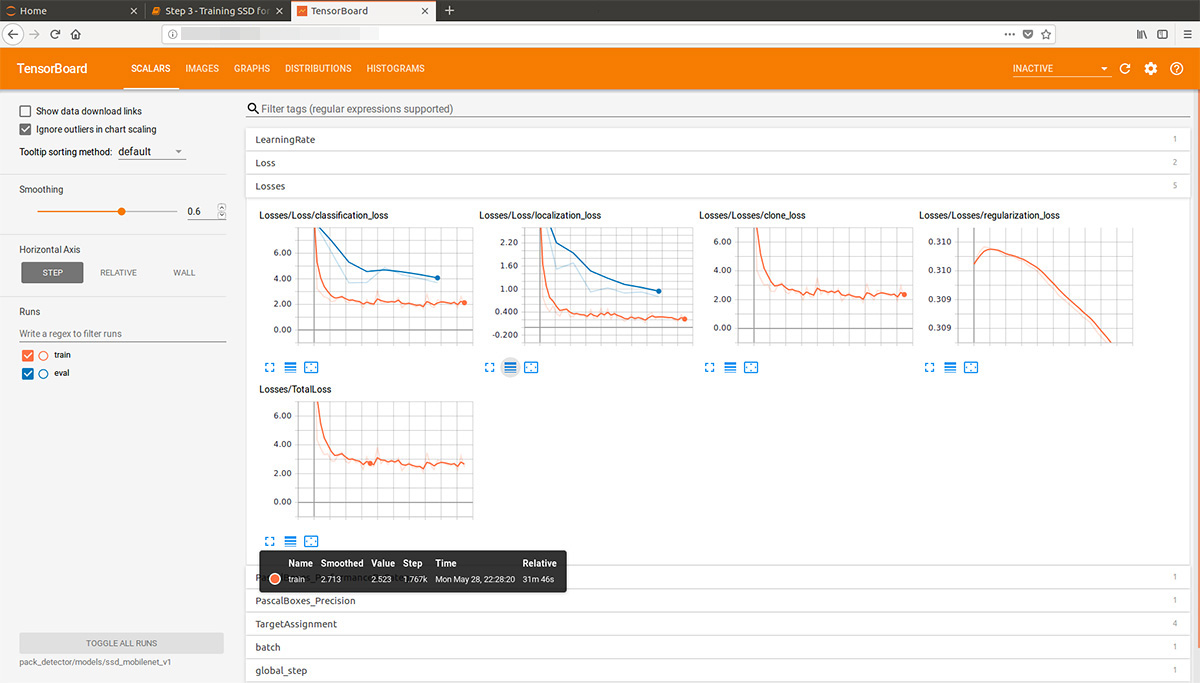
Le processus de formation peut être interrompu et repris à tout moment. Lorsque nous pensons que le modèle est suffisamment bon, nous enregistrons le point de contrôle sous la forme d'un graphique d'inférence:
python3 export_inference_graph.py \ --input_type image_tensor \ --pipeline_config_path pack_detector/models/ssd_mobilenet_v1/ssd_mobilenet_v1_pack.config \ --trained_checkpoint_prefix pack_detector/models/ssd_mobilenet_v1/train/model.ckpt-13756 \ --output_directory pack_detector/models/ssd_mobilenet_v1/pack_detector_2018_06_03
Ainsi, à cette étape, nous avons obtenu un graphe d'inférence, que nous pouvons utiliser pour rechercher des objets groupés. Nous passons à son utilisation.
Étape 4. Implémentation de la recherche ( lien github )Le code de chargement et d'initialisation du graphe d'inférence se trouve sur le lien ci-dessus. Fonctions de recherche clés:
La fonction trouve des boîtes délimitées pour les packs non pas dans toute la photo, mais dans sa partie. La fonction filtre également les rectangles trouvés avec un faible score de détection spécifié dans le paramètre de coupure.
Cela s'avère être un dilemme. D'une part, avec une coupure élevée, nous perdons beaucoup d'objets, d'autre part, avec une coupure basse, nous commençons à trouver de nombreux objets qui ne sont pas des paquets. En même temps, on ne trouve toujours pas tout et pas idéalement:

Cependant, notez que si nous exécutons la fonction pour un petit morceau de la photo, la reconnaissance est presque parfaite avec cutoff = 0.9:

Cela est dû au fait que le modèle SSD MobileNet V1 accepte des photos 300x300 en entrée. Naturellement, avec une telle compression, beaucoup de signes sont perdus.
Mais ces signes persistent si l'on découpe un petit carré contenant plusieurs packs. Cela suggère l'idée d'utiliser une fenêtre flottante: nous parcourons un petit rectangle sur une photo et nous nous souvenons de tout ce que nous avons trouvé.
 Un problème se pose: on retrouve plusieurs fois les mêmes packs, parfois dans une version très tronquée. Ce problème peut être résolu à l'aide d'un algorithme de suppression non maximal. L'idée est extrêmement simple: en une seule étape, nous trouvons un rectangle avec un score de détection maximal, rappelez-vous, supprimez tous les autres rectangles qui ont une zone d'intersection avec elle plus que overlapTresh (une implémentation a été trouvée sur Internet avec quelques modifications):
Un problème se pose: on retrouve plusieurs fois les mêmes packs, parfois dans une version très tronquée. Ce problème peut être résolu à l'aide d'un algorithme de suppression non maximal. L'idée est extrêmement simple: en une seule étape, nous trouvons un rectangle avec un score de détection maximal, rappelez-vous, supprimez tous les autres rectangles qui ont une zone d'intersection avec elle plus que overlapTresh (une implémentation a été trouvée sur Internet avec quelques modifications):
Le résultat est visuellement presque parfait: Le résultat du travail sur une photo de mauvaise qualité avec un grand nombre de packs:
Le résultat du travail sur une photo de mauvaise qualité avec un grand nombre de packs: Comme nous pouvons le voir, le nombre d'objets et la qualité des photos ne nous ont pas empêchés de reconnaître correctement tous les colis, ce que nous visions.
Comme nous pouvons le voir, le nombre d'objets et la qualité des photos ne nous ont pas empêchés de reconnaître correctement tous les colis, ce que nous visions.Conclusion
«»: , . , , .. .
, , :
- 150 , , ,
- 3-7 ,
- 100 ,
- ,
- (),
- (, ),
- , «»,
- , , (SSD ),
- , ,
- .
, , .