 Comment la traduction de l' IA peut apprendre à générer des images de chats
Comment la traduction de l' IA peut apprendre à générer des images de chats .
La recherche sur les réseaux génératifs de lutte contre la fraude (GAN) publiée en 2014 a été une percée dans le domaine des modèles génératifs. Le chercheur principal, Yann Lekun, a qualifié les filets antagonistes de "meilleure idée d'apprentissage automatique au cours des vingt dernières années". Aujourd'hui, grâce à cette architecture, nous pouvons créer une IA qui génère des images réalistes de chats. Cool!
 DCGAN pendant la formation
DCGAN pendant la formationTout le code de travail se trouve dans le
référentiel Github . Il vous sera utile si vous avez une expérience en programmation Python, en apprentissage profond, en travaillant avec Tensorflow et les réseaux de neurones convolutifs.
Et si vous débutez dans le deep learning, je vous recommande de vous familiariser avec l'excellente série d'articles
Machine Learning is Fun!Qu'est-ce que DCGAN?
Les Réseaux Adversaires Génératifs Convolutionnels Profonds (DCGAN) sont une architecture d'apprentissage en profondeur qui génère des données similaires aux données de l'ensemble de formation.
Ce modèle remplace par des couches convolutives les couches entièrement connectées du réseau contradictoire génératif. Pour comprendre le fonctionnement de DCGAN, nous utilisons la métaphore de la confrontation entre un critique d'art expert et un falsificateur.
Le falsificateur («générateur») essaie de créer une fausse image de Van Gogh et de la faire passer pour une vraie.
Un critique d'art («discriminateur») tente de condamner un falsificateur, utilisant sa connaissance des véritables toiles de Van Gogh.
Au fil du temps, le critique d'art définit de plus en plus les faux, et le falsificateur les rend tous plus parfaits.
 Comme vous pouvez le voir, les DCGAN sont composés de deux réseaux neuronaux d'apprentissage en profondeur distincts qui se font concurrence.
Comme vous pouvez le voir, les DCGAN sont composés de deux réseaux neuronaux d'apprentissage en profondeur distincts qui se font concurrence.- Le générateur essaie de créer des données crédibles. Il ne sait pas quelles sont les données réelles, mais il apprend des réponses du réseau neuronal ennemi, changeant les résultats de son travail à chaque itération.
- Le discriminateur essaie de déterminer les fausses données (en les comparant aux vraies), en évitant autant que possible les faux positifs par rapport aux données réelles. Le résultat de ce modèle est une rétroaction pour le générateur.
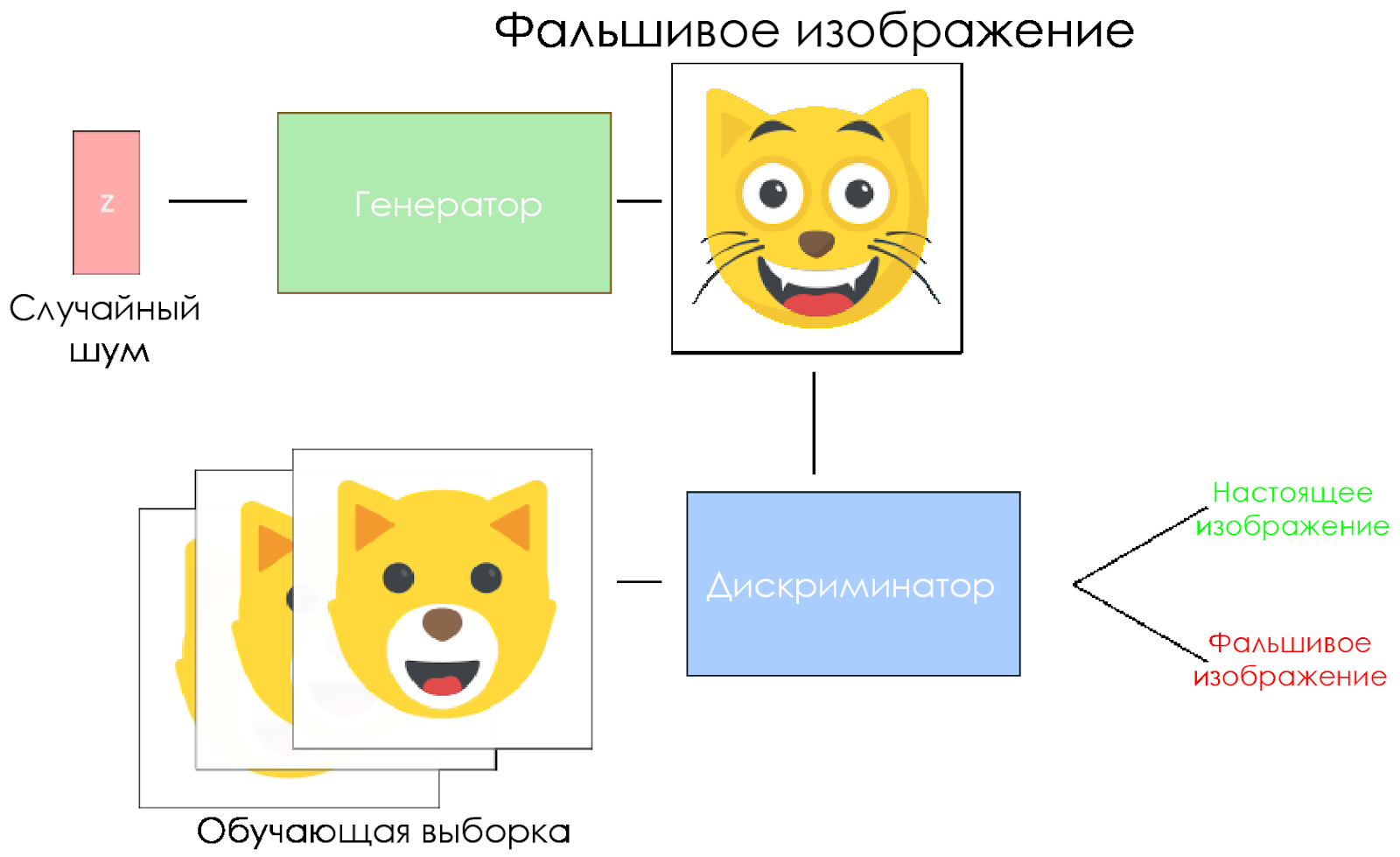 Schéma DCGAN.
Schéma DCGAN.- Le générateur prend un vecteur de bruit aléatoire et génère une image.
- L'image est donnée au discriminateur, il la compare à l'échantillon d'apprentissage.
- Le discriminateur renvoie un nombre - 0 (faux) ou 1 (image réelle).
Créons un DCGAN!
Nous sommes maintenant prêts à créer notre propre IA.
Dans cette partie, nous nous concentrerons sur les principaux composants de notre modèle. Si vous voulez voir le code entier, allez
ici .
Entrer les données
Créez des stubs pour l'entrée:
inputs_real pour le discriminateur et
inputs_z pour le générateur. Veuillez noter que nous aurons deux taux d'apprentissage, séparément pour le générateur et le discriminateur.
Les DCGAN sont très sensibles aux hyperparamètres, il est donc très important de les affiner.
def model_inputs(real_dim, z_dim): """ Create the model inputs :param real_dim: tuple containing width, height and channels :param z_dim: The dimension of Z :return: Tuple of (tensor of real input images, tensor of z data, learning rate G, learning rate D) """
Discriminateur et générateur
Nous utilisons
tf.variable_scope pour deux raisons.
Tout d'abord, pour vous assurer que tous les noms de variables commencent par générateur / discriminateur. Plus tard, cela nous aidera à former deux réseaux de neurones.
Deuxièmement, nous réutiliserons ces réseaux avec différentes données d'entrée:
- Nous formerons le générateur, puis prendrons un échantillon des images générées par celui-ci.
- Dans le discriminateur, nous partagerons des variables pour les images d'entrée fausses et réelles.

Créons un discriminateur. N'oubliez pas qu'en entrée, il prend une image réelle ou fausse et renvoie 0 ou 1 en réponse.
Quelques notes:
- Nous devons doubler la taille du filtre dans chaque couche convolutionnelle.
- L'utilisation du sous-échantillonnage n'est pas recommandée. Au lieu de cela, seules les couches convolutives dépouillées sont applicables.
- Dans chaque couche, nous utilisons la normalisation par lots (à l'exception de la couche d'entrée), car cela réduit le décalage de covariance. En savoir plus dans ce merveilleux article .
- Nous utiliserons Leaky ReLU comme fonction d'activation, cela aidera à éviter l'effet de la «disparition» du gradient.
def discriminator(x, is_reuse=False, alpha = 0.2): ''' Build the discriminator network. Arguments --------- x : Input tensor for the discriminator n_units: Number of units in hidden layer reuse : Reuse the variables with tf.variable_scope alpha : leak parameter for leaky ReLU Returns ------- out, logits: ''' with tf.variable_scope("discriminator", reuse = is_reuse):
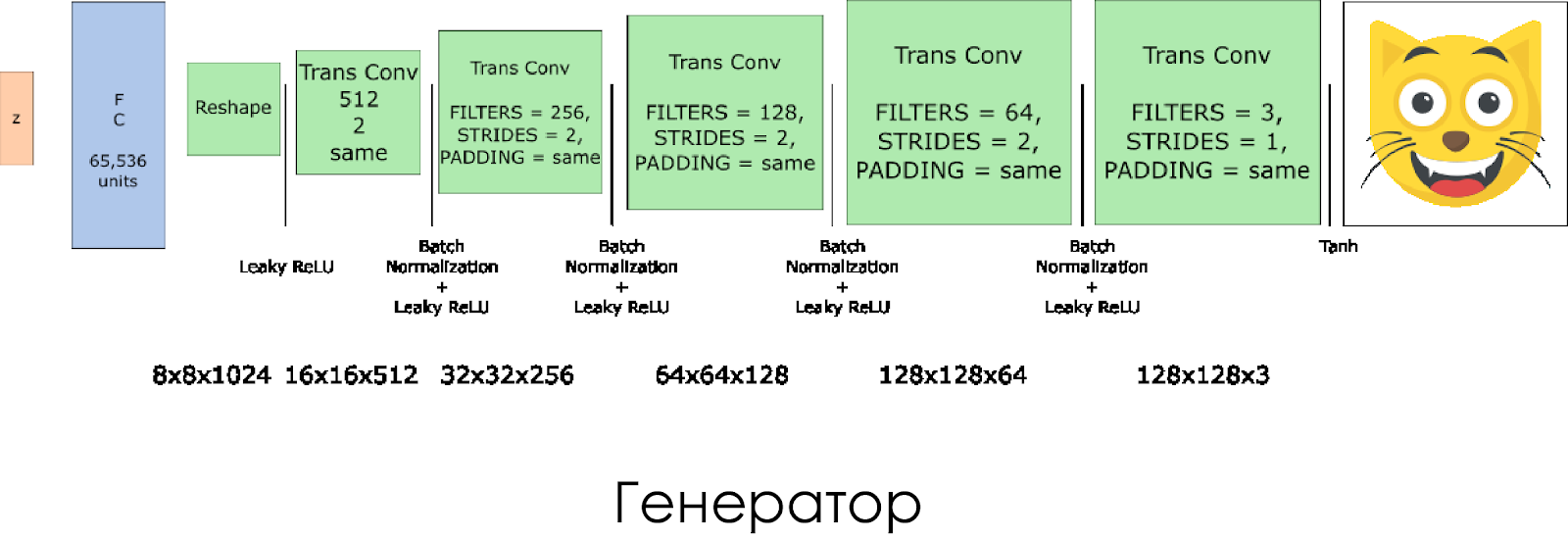
Nous avons créé un générateur. N'oubliez pas qu'il prend le vecteur de bruit (z) en entrée et, grâce aux couches de convolution transposées, crée une fausse image.
Sur chaque calque, nous divisons par deux la taille du filtre et doublons également la taille de l'image.
Le générateur fonctionne mieux lorsque vous utilisez
tanh comme fonction d'activation de sortie.
def generator(z, output_channel_dim, is_train=True): ''' Build the generator network. Arguments --------- z : Input tensor for the generator output_channel_dim : Shape of the generator output n_units : Number of units in hidden layer reuse : Reuse the variables with tf.variable_scope alpha : leak parameter for leaky ReLU Returns ------- out: ''' with tf.variable_scope("generator", reuse= not is_train):
Pertes dans le discriminateur et le générateur
Puisque nous formons à la fois le générateur et le discriminateur, nous devons calculer les pertes pour les deux réseaux de neurones. Le discriminateur doit donner 1 lorsqu'il «considère» que l'image est réelle et 0 si l'image est fausse. Conformément à cela et vous devez configurer la perte. La perte du discriminateur est calculée comme la somme des pertes pour l'image réelle et fausse:
d_loss = d_loss_real + d_loss_fakeoù
d_loss_real est la perte lorsque le discriminateur considère que l'image est fausse, mais en fait elle est réelle. Il est calculé comme suit:
- Nous utilisons
d_logits_real , toutes les étiquettes sont égales à 1 (car toutes les données sont réelles). labels = tf.ones_like(tensor) * (1 - smooth) . Utilisons le lissage d'étiquette: abaissez les valeurs d'étiquette de 1,0 à 0,9 pour aider le discriminateur à mieux généraliser.
d_loss_fake est une perte lorsque le discriminateur considère que l'image est réelle, mais en fait elle est fausse.
- Nous utilisons
d_logits_fake , toutes les étiquettes sont 0.
Pour perdre le générateur,
d_logits_fake du discriminateur est utilisé. Cette fois, toutes les étiquettes sont égales à 1, car le générateur veut tromper le discriminateur.
def model_loss(input_real, input_z, output_channel_dim, alpha): """ Get the loss for the discriminator and generator :param input_real: Images from the real dataset :param input_z: Z input :param out_channel_dim: The number of channels in the output image :return: A tuple of (discriminator loss, generator loss) """
Optimiseurs
Après avoir calculé les pertes, le générateur et le discriminateur doivent être mis à jour individuellement. Pour ce faire, utilisez
tf.trainable_variables() créer une liste de toutes les variables définies dans notre graphique.
def model_optimizers(d_loss, g_loss, lr_D, lr_G, beta1): """ Get optimization operations :param d_loss: Discriminator loss Tensor :param g_loss: Generator loss Tensor :param learning_rate: Learning Rate Placeholder :param beta1: The exponential decay rate for the 1st moment in the optimizer :return: A tuple of (discriminator training operation, generator training operation) """
La formation
Maintenant, nous implémentons la fonction de formation. L'idée est assez simple:
- Nous sauvegardons notre modèle toutes les cinq périodes (époque).
- Nous enregistrons l'image dans le dossier avec des images tous les 10 lots formés.
- Toutes les 15 périodes, nous
g_loss , d_loss et l'image générée. En effet, le bloc-notes Jupyter peut se bloquer lors de l'affichage de trop de photos. - Ou nous pouvons générer directement des images réelles en chargeant un modèle enregistré (cela économisera 20 heures de formation).
def train(epoch_count, batch_size, z_dim, learning_rate_D, learning_rate_G, beta1, get_batches, data_shape, data_image_mode, alpha): """ Train the GAN :param epoch_count: Number of epochs :param batch_size: Batch Size :param z_dim: Z dimension :param learning_rate: Learning Rate :param beta1: The exponential decay rate for the 1st moment in the optimizer :param get_batches: Function to get batches :param data_shape: Shape of the data :param data_image_mode: The image mode to use for images ("RGB" or "L") """
Comment courir
Tout cela peut être exécuté directement sur votre ordinateur si vous êtes prêt à attendre 10 ans. Il est donc préférable d'utiliser des services GPU basés sur le cloud comme AWS ou FloydHub. Personnellement, j'ai formé ce DCGAN pendant 20 heures sur Microsoft Azure et leur
machine virtuelle Deep Learning . Je n'ai pas de relation commerciale avec Azure, j'aime juste leur service client.
Si vous rencontrez des difficultés lors de l'exécution sur une machine virtuelle, consultez ce merveilleux
article .
Si vous améliorez le modèle, n'hésitez pas à faire une demande de pull.
