Aujourd'hui, nous allons parler de Kubernetes, du râteau qui peut être collecté dans son utilisation pratique, et des développements qui ont aidé l'auteur et qui devraient vous aider aussi. Nous allons essayer de prouver que sans k8 dans le monde moderne n'importe où. Pour les adversaires des k8, nous fournissons également d'excellentes raisons pour lesquelles vous ne devriez pas y passer. Autrement dit, dans l'histoire, nous allons non seulement défendre Kubernetes, mais aussi le gronder. D'ici au nom est venu ceci
[pas] .
Cet article est basé sur une
présentation d'Ivan Glushkov (
gli ) lors de la conférence DevOops 2017. Les deux derniers lieux de travail d'Ivan étaient en quelque sorte liés à Kubernetes: il a travaillé dans les infracommandes à la fois dans Postmates et Machine Zone, et ils affectent très étroitement Kubernetes. De plus, Ivan dirige le podcast
DevZen . Une autre présentation sera faite au nom d'Ivan.

Tout d'abord, je vais brièvement expliquer pourquoi il est utile et important pour beaucoup, pourquoi ce battage médiatique se produit. Ensuite, je vais vous parler de notre expérience dans l'utilisation de la technologie. Eh bien, alors les conclusions.
Dans cet article, toutes les diapositives sont insérées sous forme d'images, mais vous souhaitez parfois copier quelque chose. Par exemple, il y aura des exemples avec des configurations. Les diapositives PDF peuvent être téléchargées
ici .
Je ne le dirai pas strictement à tout le monde: assurez-vous d'utiliser Kubernetes. Il y a des avantages et des inconvénients, donc si vous venez chercher des inconvénients, vous les trouverez. Vous avez le choix, ne regardez que les avantages, seulement les inconvénients et regardez généralement tout ensemble.
Simon Cat m'aidera avec les pros, et le chat noir traversera la route quand il y aura un moins.

Alors, pourquoi ce battage médiatique s'est-il produit, pourquoi la technologie X est-elle meilleure que Y. Kubernetes est exactement le même système, et il y en a beaucoup plus d'un. Il y a Puppet, Chef, Ansible, Bash + SSH, Terraform. Mon SSH préféré m'aide maintenant, pourquoi devrais-je aller quelque part. Je pense qu'il existe de nombreux critères, mais j'ai souligné les plus importants.
Le temps entre la validation et la sortie est une très bonne note, et les gars d'Express 42 sont d'excellents experts en la matière. L'automatisation de l'assemblage, l'automatisation de l'ensemble du pipeline est une très bonne chose, vous ne pouvez pas en faire l'éloge, cela aide en fait. Intégration continue, déploiement continu. Et, bien sûr, combien d'efforts vous consacrerez à tout faire. Tout peut être écrit dans Assembler, comme je l'ai dit, un système de déploiement aussi, mais cela n'ajoutera pas de commodité.

Je ne vous dirai pas une brève introduction à Kubernetes, vous savez ce que c'est. J'aborderai ces domaines un peu plus loin.
Pourquoi tout cela est-il si important pour les développeurs? La répétabilité est importante pour eux, c'est-à-dire s'ils ont écrit une sorte d'application, exécuté un test, cela fonctionnera pour vous, pour votre voisin et pour la production.
Le second est un environnement standardisé: si vous avez étudié Kubernetes et que vous vous rendez dans une entreprise voisine où se trouve Kubernetes, alors tout sera pareil. La simplification de la procédure de test et de l'intégration continue n'est pas le résultat direct de l'utilisation de Kubernetes, mais cela simplifie toujours la tâche, donc tout devient plus pratique.

Pour les développeurs de versions, il existe de nombreux autres avantages. Premièrement, c'est une infrastructure immuable.
Deuxièmement, l'infrastructure est comme du code stocké quelque part. Troisièmement, l'idempotence, la possibilité d'ajouter une version avec un seul bouton. Les annulations de versions se produisent assez rapidement et l'introspection du système est assez pratique. Bien sûr, tout cela peut être fait sur votre système, écrit sur le genou, mais vous ne pouvez pas toujours le faire correctement, et Kubernetes l'a déjà implémenté.
Qu'est-ce que Kubernetes n'est pas et que ne permet-il pas de faire? Il existe de nombreuses idées fausses à cet égard. Commençons par les conteneurs. Kubernetes court dessus. Les conteneurs ne sont pas des machines virtuelles légères, mais une entité complètement différente. Ils sont faciles à expliquer à l'aide de ce concept, mais en fait c'est faux. Le concept est complètement différent, il doit être compris et accepté.
Deuxièmement, Kubernetes ne rend pas l'application plus sécurisée. Il ne le rend pas automatiquement évolutif.
Vous devez vous efforcer de démarrer Kubernetes, il n'en sera pas ainsi "en appuyant sur un bouton, et tout a fonctionné automatiquement". Ça va faire mal.

Notre expérience. Nous voulons que vous et tout le monde ne cassiez rien. Pour ce faire, vous devez regarder plus loin - et voici notre côté.

Premièrement, Kubernetes ne va pas seul. Lorsque vous construisez une structure qui gérera entièrement les versions et les déploiements, vous devez comprendre que Kubernetes est un dé et qu'il doit y en avoir 100. Pour construire tout cela, vous devez tout étudier attentivement. Les débutants qui viendront dans votre système étudieront également cette pile, une énorme quantité d'informations.
Kubernetes n'est pas le seul bloc important, il existe de nombreux autres blocs importants sans lesquels le système ne fonctionnera pas. Autrement dit, vous devez vous soucier beaucoup de la tolérance aux pannes.

Pour cette raison, Kubernetes est un inconvénient. Le système est complexe, vous devez vous en occuper beaucoup.

Mais il y a des avantages. Si une personne a étudié Kubernetes dans une entreprise, dans une autre, ses cheveux ne resteront pas en place en raison du système de libération. Au fil du temps, lorsque Kubernetes prendra plus de place, la transition des personnes et la formation seront plus faciles. Et pour cela - un plus.


Nous utilisons Helm. Ce système, qui est construit au-dessus de Kubernetes, ressemble à un gestionnaire de packages. Vous pouvez cliquer sur le bouton, dire que vous souhaitez installer * Wine * sur votre système. Peut être installé dans Kubernetes. Il fonctionne, se télécharge automatiquement, démarre et tout fonctionnera. Il vous permet de travailler avec des plug-ins, une architecture client-serveur. Si vous travaillez avec lui, nous vous recommandons d'exécuter un Tiller sur l'espace de noms. Cela isole l'espace de noms les uns des autres, et la rupture de l'un ne rompt pas l'autre.

En fait, le système est très complexe. Un système, qui devrait être une abstraction d'un niveau supérieur et plus simple et plus compréhensible, ne le rend pas vraiment plus facile à comprendre. Pour ce moins.

Comparons les configurations. Très probablement, vous avez également des configurations si vous exécutez votre système en production. Nous avons notre propre système appelé BOOMer. Je ne sais pas pourquoi nous l'avons appelée ainsi. Il se compose de marionnettes, chef, Ansible, Terraform et tout le reste, il y a une grande bouteille.

Voyons comment cela fonctionne. Voici un exemple d'une configuration réelle qui fonctionne actuellement en production. Que voyons-nous ici?
Premièrement, nous voyons où lancer l'application, deuxièmement, ce qui doit être lancé et, troisièmement, comment elle doit être préparée pour le lancement. Dans une bouteille, les concepts sont déjà mélangés.

Si nous regardons plus loin, parce que nous avons ajouté l'héritage pour rendre les configurations plus complexes, nous devrions regarder ce qui se trouve dans la configuration commune à laquelle nous nous référons. De plus, nous ajoutons la configuration du réseau, les droits d'accès, la planification de la charge. Tout cela dans une config dont nous avons besoin pour exécuter une vraie application en production, nous mélangeons un tas de concepts en un seul endroit.
C'est très difficile, c'est très faux, et c'est un énorme plus pour Kubernetes, car vous déterminez simplement quoi exécuter. La configuration du réseau a été effectuée lors de l'installation de Kubernetes, le provisionnement complet a été résolu à l'aide du docker - vous avez eu l'encapsulation, tous les problèmes ont été séparés d'une manière ou d'une autre et dans ce cas, la configuration n'a que votre application, et il y a un avantage pour cela.

Examinons de plus près. Ici, nous n'avons qu'une seule application. Pour que le déploiement fonctionne, vous avez besoin de tout un tas de plus pour fonctionner. Tout d'abord, vous devez définir les services. Comment les secrets, ConfigMap, l'accès à Load Balancer nous parviennent.

N'oubliez pas que vous disposez de plusieurs environnements. Il y a Stage / Prod / Dev. Tout cela n'est pas un petit morceau que j'ai montré, mais un énorme ensemble de configurations, ce qui est vraiment difficile. Pour ce moins.

Modèle de barre pour comparaison. Il répète complètement les modèles Kubernetes, s'il y a un fichier dans Kubernetes avec la définition de déploiement, le même sera dans Helm. Au lieu de valeurs spécifiques pour l'environnement, vous disposez de modèles qui sont substitués à partir de valeurs.
Vous avez un modèle distinct, des valeurs distinctes qui devraient être substituées dans ce modèle.
Bien sûr, vous devez également définir les différentes infrastructures de Helm lui-même, malgré le fait que vous disposez de nombreux fichiers de configuration dans Kubernetes que vous devez faire glisser et déposer dans Helm. Tout cela est très difficile, pour lequel un inconvénient.
Un système qui devrait simplifier complique en fait. Pour moi, c'est clairement un inconvénient. Soit besoin d'ajouter autre chose, soit de ne pas utiliser
Allons plus loin, nous ne sommes pas assez profonds.

Tout d'abord, comment nous travaillons avec les clusters. J'ai lu l'article de Google
«Borg, Omega et Kubernetes», qui préconise fortement le concept selon lequel vous devez avoir un grand cluster. J'étais aussi pour cette idée, mais, finalement, nous l'avons laissée. À la suite de nos différends, nous utilisons quatre grappes différentes.
Premier cluster e2e à tester Kubernetes lui-même et à tester des scripts qui déploient l'environnement, les plug-ins, etc. Le deuxième, bien sûr, prod et stage. Ce sont des concepts standard. Troisièmement, c'est admin, dans lequel tout le reste est chargé - en particulier, nous avons CI là-bas, et il semble qu'à cause de cela, ce cluster sera toujours le plus grand.
Il y a beaucoup de tests: par commit, par merge, tout le monde fait un tas de commits, donc les clusters sont juste énormes.

Nous avons essayé de regarder CoreOS, mais ne l'avons pas utilisé. Ils ont TF ou CloudFormation à l'intérieur, et les deux nous permettent très mal de comprendre ce qui est à l'intérieur de l'état. Pour cette raison, il y a des problèmes lors de la mise à niveau. Lorsque vous souhaitez mettre à jour les paramètres de votre Kubernetes, par exemple, sa version, vous pouvez rencontrer le fait que la mise à jour ne fonctionne pas de cette façon, dans le mauvais ordre. C'est un gros problème de stabilité. C'est un inconvénient.

Deuxièmement, lorsque vous utilisez Kubernetes, vous devez télécharger des images quelque part. Il peut s'agir d'une source interne, d'un référentiel ou externe. S'il est interne, il y a des problèmes. Je recommande d'utiliser Docker Distribution car il est stable, il a été créé par Docker. Mais le prix de soutien est toujours élevé. Pour que cela fonctionne, vous devez le rendre tolérant aux pannes, car c'est le seul endroit où vos applications obtiennent des données à partir desquelles travailler.

Imaginez qu'au moment crucial, lorsque vous avez trouvé un bug sur la production, votre référentiel est tombé - vous ne pouvez pas mettre à jour l'application. Vous devez le rendre tolérant aux pannes, et de tous les problèmes possibles qui ne peuvent être que.
Deuxièmement, si la masse des équipes, chacune a sa propre image, elles s'accumulent beaucoup et très rapidement. Vous pouvez tuer votre distribution Docker. Il est nécessaire de faire le nettoyage, de supprimer des images, de fournir des informations aux utilisateurs, quand et ce que vous allez nettoyer.
Troisièmement, avec de grandes images, disons, si vous avez un monolithe, la taille de l'image sera très grande. Imaginez que vous devez libérer 30 nœuds. 2 gigaoctets par 30 nœuds - calculez le flux, la vitesse de téléchargement sur tous les nœuds. Je voudrais qu'il appuie sur un bouton et devienne immédiatement vert. Mais non, vous devez d'abord attendre qu'il soit téléchargé. Il est nécessaire d'accélérer ce téléchargement, et tout fonctionne à partir d'un point.

Avec les référentiels externes, il y a les mêmes problèmes avec le garbage collector, mais le plus souvent cela se fait automatiquement. Nous utilisons Quay. Dans le cas de référentiels externes, il s'agit de services tiers dont la plupart des images sont publiques. Qu'il n'y avait pas d'images publiques, il faut donner accès. Nous avons besoin de secrets, de droits d'accès aux images, tout cela est spécialement configuré. Bien sûr, cela peut être automatisé, mais dans le cas d'un lancement local de Cuba sur votre système, vous devez encore le configurer.

Pour installer Kubernetes, nous utilisons kops. C'est un très bon système, nous sommes les premiers utilisateurs à partir du moment où ils n'avaient pas encore écrit sur le blog. Il ne prend pas pleinement en charge CoreOS, fonctionne bien avec Debian, sait comment configurer automatiquement les nœuds maîtres Kubernetes, fonctionne avec les modules complémentaires et a la possibilité de ne faire aucun temps d'arrêt pendant les mises à jour de Kubernetes.
Toutes ces fonctionnalités sont prêtes à l'emploi, pour lesquelles un gros et audacieux plus. Excellent système!


À partir des liens, vous pouvez trouver de nombreuses options pour configurer un réseau dans Kubernetes. Il y en a vraiment beaucoup, chacun a ses avantages et ses inconvénients. Kops ne prend en charge qu'une partie de ces options. Vous pouvez bien sûr le configurer pour qu'il fonctionne via CNI, mais il est préférable d'utiliser les plus courants et les plus standard. Ils sont testés par la communauté et sont très probablement stables.

Nous avons décidé d'utiliser Calico. Cela a bien fonctionné à partir de zéro, sans beaucoup de problèmes, utilise BGP, une encapsulation plus rapide, prend en charge IP-in-IP, vous permet de travailler avec plusieurs nuages, pour nous, c'est un gros plus.
Bonne intégration avec Kubernetes, l'utilisation d'étiquettes délimite le trafic. Car c'est un plus.
Je ne m'attendais pas à ce que Calico se rende dans l'État lorsqu'il est allumé, et tout fonctionne sans problème.

La haute disponibilité, comme je l'ai dit, nous le faisons via kops, vous pouvez utiliser 5-7-9 nœuds, nous en utilisons trois. Nous sommes assis sur etcd v2, à cause d'un bug, ils n'ont pas été mis à jour sur v3. Théoriquement, cela accélérera certains processus. Je ne sais pas, j'en doute.

Un moment difficile, nous avons un cluster spécial pour expérimenter avec des scripts, roulement automatique à travers CI. Nous pensons que nous avons une protection contre les actions complètement fausses, mais pour certaines versions spéciales et complexes, juste au cas où nous ferions des instantanés de tous les disques, nous ne faisons pas de sauvegardes tous les jours.


L'autorisation est une question éternelle. Chez Kubernetes, nous utilisons RBAC, l'accès basé sur les rôles. C'est bien mieux qu'ABAC, et si vous l'avez configuré, alors vous comprenez ce que je veux dire. Regardez les configurations - soyez surpris.
Nous utilisons Dex, un fournisseur OpenID qui pompe toutes les informations d'une source de données.
Et pour vous connecter à Kubernetes, il y a deux façons. Il est nécessaire de s'inscrire en quelque sorte dans .kube / config où aller et ce qu'il peut faire. Il est nécessaire de récupérer cette configuration. Ou l'utilisateur se rend sur l'interface utilisateur, où il se connecte, reçoit les configurations, les copie dans / config et fonctionne. Ce n'est pas très pratique. Nous sommes progressivement passés au fait qu'une personne entre dans la console, clique sur le bouton, se connecte, les configurations sont automatiquement générées à partir de lui et empilées au bon endroit. Beaucoup plus pratique, nous avons décidé d'agir de cette façon.

En tant que source de données, nous utilisons Active Directory. Kubernetes vous permet de transmettre des informations sur le groupe dans toute la structure d'autorisation, ce qui se traduit par un espace de noms et des rôles. Ainsi, nous distinguons immédiatement entre où une personne peut aller, où elle n'a pas le droit d'aller et ce qu'elle peut libérer.

Le plus souvent, les gens ont besoin d'accéder à AWS. Si vous ne disposez pas de Kubernetes, une machine exécute l'application. Il semblerait que tout ce dont vous avez besoin soit d'obtenir les journaux, de les voir et c'est tout. C'est pratique lorsqu'une personne peut se rendre à sa voiture et voir comment fonctionne l'application. Du point de vue de Kubernetes, tout fonctionne dans des conteneurs. Il existe une commande `kubectl exec` - entrez dans le conteneur de l'application et voyez ce qui s'y passe. Par conséquent, il n'est pas nécessaire d'accéder aux instances AWS. Nous avons refusé l'accès à tout le monde sauf à la sous-commande.
De plus, nous avons interdit les clés d'administration à longue durée de jeu, l'entrée via les rôles. S'il est possible d'utiliser le rôle d'administrateur - je suis l'administrateur. De plus, nous avons ajouté la rotation des clés. Il est pratique de le configurer via la commande awsudo, c'est un projet sur le github, je le recommande vivement, il vous permet de travailler comme avec une sudo-team.



Quotas. Une très bonne chose à Kubernetes, travailler dès la sortie de la boîte. Vous limitez tout espace de noms, par exemple, par le nombre d'objets, de mémoire ou de CPU que vous pouvez consommer. Je pense que c'est important et utile à tout le monde. Nous n'avons pas encore atteint la mémoire et le CPU, nous n'utilisons que le nombre d'objets, mais nous ajouterons tout cela.
Gros et gros plus, vous permet de faire beaucoup de choses délicates.


Mise à l'échelle. Vous ne pouvez pas mélanger la mise à l'échelle à l'intérieur de Kubernetes et à l'extérieur de Kubernetes. À l'intérieur de Kubernetes fait la mise à l'échelle elle-même. Il peut augmenter automatiquement les pods en cas de forte charge.
Ici, je parle de la mise à l'échelle des instances Kubernetes elles-mêmes. Cela peut être fait à l'aide d'AWS Autoscaler, il s'agit d'un projet github. Lorsque vous ajoutez un nouveau pod et qu'il ne peut pas démarrer car il manque de ressources sur toutes les instances, AWS Autoscaler peut ajouter automatiquement des nœuds. Cela vous permet de travailler sur des instances Spot, nous ne l'avons pas encore ajouté, mais nous le ferons, cela nous permet d'économiser beaucoup.


Lorsque vous avez beaucoup d'utilisateurs et d'applications utilisateur, vous devez en quelque sorte les surveiller. Il s'agit généralement de télémétrie, de journaux, de beaux graphismes.

Pour des raisons historiques, nous avions Sensu, il n'était pas très adapté à Kubernetes. Un projet plus métrique était nécessaire. Nous avons examiné l'intégralité de la pile TICK, en particulier InfluxDB. Bonne interface utilisateur, langage de type SQL, mais pas assez de fonctionnalités. Nous sommes passés à Prométhée.
Il est bon. Bon langage de requête, bonnes alertes, et tout hors de la boîte.

Pour envoyer la télémétrie, nous avons utilisé Cernan. Ceci est notre propre projet écrit en Rust. C'est le seul projet sur Rust qui travaille dans notre production depuis un an maintenant. Il a plusieurs concepts: il existe un concept de source de données, vous configurez plusieurs sources. Vous configurez où les données seront fusionnées. Nous avons une configuration de filtres, c'est-à-dire que les données qui circulent peuvent être traitées d'une manière ou d'une autre. Vous pouvez convertir les journaux en métriques, les métriques en journaux, tout ce que vous voulez.
Malgré le fait que vous ayez plusieurs entrées, plusieurs conclusions, et que vous montrez que là où il va, il y a quelque chose comme un grand système de graphes, cela s'avère assez pratique.

Nous passons maintenant de manière transparente de la pile Statsd / Cernan / Wavefront actuelle à Kubernetes. En théorie, Prometheus veut prendre les données des applications par lui-même, vous devez donc ajouter un point de terminaison à toutes les applications, à partir desquelles il prendra des mesures. Cernan est le lien de transmission, il devrait fonctionner partout. Il existe deux possibilités: vous pouvez exécuter Kubernetes sur chaque instance, en utilisant le concept Sidecar, lorsqu'un autre conteneur fonctionne dans votre champ de données qui envoie des données. Nous faisons ceci et cela.

À l'heure actuelle, tous les journaux sont envoyés à stdout / stderr. Toutes les applications sont conçues pour cela, donc l'une des exigences essentielles est que nous ne quittions pas ce système. Cernan envoie des données à ElasticSearch, les événements de l'ensemble du système Kubernetes y sont envoyés via Heapster. C'est un très bon système, je le recommande.
Après cela, vous pouvez voir tous les journaux au même endroit, par exemple, dans la console. Nous utilisons Kibana. Il y a un merveilleux produit Stern, juste pour les journaux. Il vous permet de regarder, de peindre différents pods de différentes couleurs, de savoir comment un sous est mort et l'autre a redémarré. Récupère automatiquement tous les journaux. Un projet idéal, je le recommande vivement, c'est un gros plus Kubernetes, tout va bien ici.


Secrets Nous utilisons S3 et KMS. Nous envisageons de passer à Vault ou à des secrets dans Kubernetes lui-même. Ils étaient en 1.7 en état alpha, mais quelque chose doit être fait avec cela.

Nous sommes arrivés à la partie intéressante. Le développement de Kubernetes n'est généralement pas très pris en compte.
Il dit essentiellement: "Kubernetes est un système idéal, tout va bien, passons."Mais en fait, le fromage gratuit n'est que dans une souricière, et pour les développeurs de Kubernetes, c'est l'enfer. Pas du point de vue que tout est mauvais, mais du fait que vous devez regarder les choses différemment. Je compare le développement dans Kubernetes à la programmation fonctionnelle: jusqu'à ce que vous le touchiez, vous pensez dans votre style impératif, tout va bien. Afin de développer le fonctionnalisme, vous devez tourner légèrement la tête de l'autre côté - la même chose ici.Vous pouvez le développer, vous pouvez bien le faire, mais vous devez le voir différemment. Commençons par le concept Docker Way. Ce n'est pas si difficile, mais c'est assez problématique de le comprendre complètement. La plupart des développeurs sont habitués à se rendre sur leur machine locale, distante ou virtuelle via SSH, en disant: "Permettez-moi de corriger quelque chose ici, podshaman."Vous lui dites que Kubernetes ne le fera pas parce que vous avez une infrastructure en lecture seule. Lorsque vous souhaitez mettre à jour l'application, faites une nouvelle image qui fonctionnera, et l'ancienne, s'il vous plaît ne touchez pas, elle mourra simplement. J'ai personnellement travaillé sur l'introduction de Kubernetes dans différentes équipes et je vois l'horreur dans les yeux des gens quand ils comprennent qu'ils devront abandonner complètement toutes les anciennes habitudes, en trouver de nouvelles, un nouveau système, ce qui est très difficile.De plus, vous devrez faire beaucoup de choix: par exemple, lorsque vous apportez des modifications, si le développement est local, vous devez le valider dans le référentiel d'une manière ou d'une autre, puis le référentiel du pipeline exécute les tests, puis dit: "Oh, il y a une faute de frappe en un mot", vous avez besoin de tout faire localement. Montez le dossier en quelque sorte, allez-y, mettez à jour le système, au moins compilez-le. Si l'exécution de tests localement n'est pas pratique, il peut au moins valider dans CI pour vérifier certaines actions locales, puis les envoyer à CI pour vérification. Ces choix sont assez compliqués.C'est particulièrement difficile lorsque vous avez une application branchée composée d'une centaine de services, et pour que l'un d'entre eux fonctionne, vous devez vous assurer que tout le monde travaille côte à côte. Vous devez soit émuler l'environnement, soit s'exécuter localement. Tout ce choix n'est pas anodin, le développeur doit y réfléchir sérieusement. Cela crée une attitude négative envers Kubernetes. Il est, bien sûr, bon - mais il est mauvais, car il faut beaucoup réfléchir et changer ses habitudes.Par conséquent, ici, trois gros chats ont traversé la route.
Pas du point de vue que tout est mauvais, mais du fait que vous devez regarder les choses différemment. Je compare le développement dans Kubernetes à la programmation fonctionnelle: jusqu'à ce que vous le touchiez, vous pensez dans votre style impératif, tout va bien. Afin de développer le fonctionnalisme, vous devez tourner légèrement la tête de l'autre côté - la même chose ici.Vous pouvez le développer, vous pouvez bien le faire, mais vous devez le voir différemment. Commençons par le concept Docker Way. Ce n'est pas si difficile, mais c'est assez problématique de le comprendre complètement. La plupart des développeurs sont habitués à se rendre sur leur machine locale, distante ou virtuelle via SSH, en disant: "Permettez-moi de corriger quelque chose ici, podshaman."Vous lui dites que Kubernetes ne le fera pas parce que vous avez une infrastructure en lecture seule. Lorsque vous souhaitez mettre à jour l'application, faites une nouvelle image qui fonctionnera, et l'ancienne, s'il vous plaît ne touchez pas, elle mourra simplement. J'ai personnellement travaillé sur l'introduction de Kubernetes dans différentes équipes et je vois l'horreur dans les yeux des gens quand ils comprennent qu'ils devront abandonner complètement toutes les anciennes habitudes, en trouver de nouvelles, un nouveau système, ce qui est très difficile.De plus, vous devrez faire beaucoup de choix: par exemple, lorsque vous apportez des modifications, si le développement est local, vous devez le valider dans le référentiel d'une manière ou d'une autre, puis le référentiel du pipeline exécute les tests, puis dit: "Oh, il y a une faute de frappe en un mot", vous avez besoin de tout faire localement. Montez le dossier en quelque sorte, allez-y, mettez à jour le système, au moins compilez-le. Si l'exécution de tests localement n'est pas pratique, il peut au moins valider dans CI pour vérifier certaines actions locales, puis les envoyer à CI pour vérification. Ces choix sont assez compliqués.C'est particulièrement difficile lorsque vous avez une application branchée composée d'une centaine de services, et pour que l'un d'entre eux fonctionne, vous devez vous assurer que tout le monde travaille côte à côte. Vous devez soit émuler l'environnement, soit s'exécuter localement. Tout ce choix n'est pas anodin, le développeur doit y réfléchir sérieusement. Cela crée une attitude négative envers Kubernetes. Il est, bien sûr, bon - mais il est mauvais, car il faut beaucoup réfléchir et changer ses habitudes.Par conséquent, ici, trois gros chats ont traversé la route.
 Lorsque nous avons examiné Kubernetes, nous avons essayé de comprendre, peut-être qu'il existe des systèmes de développement pratiques. En particulier, il existe une chose telle que Deis, c'est sûr que vous en avez tout entendu. Il est très facile à utiliser, et nous avons vérifié, en fait, que tous les projets simples passent très facilement à Deis. Mais le problème est que les projets plus complexes peuvent ne pas passer à Deis.Comme je l'ai dit, nous sommes passés à Helm Charts. Mais le seul problème que nous voyons en ce moment est que beaucoup de bonne documentation est nécessaire. Nous avons besoin de quelques procédures, de FAQ, pour qu'une personne puisse démarrer rapidement, copier les configurations actuelles, coller les leurs, changer les noms pour que tout soit correct. Il est également important de comprendre cela à l'avance et vous devez tout faire. J'ai répertorié des boîtes à outils courantes pour le développement ici, je ne vais pas aborder tout cela sauf le mini-cube.
Lorsque nous avons examiné Kubernetes, nous avons essayé de comprendre, peut-être qu'il existe des systèmes de développement pratiques. En particulier, il existe une chose telle que Deis, c'est sûr que vous en avez tout entendu. Il est très facile à utiliser, et nous avons vérifié, en fait, que tous les projets simples passent très facilement à Deis. Mais le problème est que les projets plus complexes peuvent ne pas passer à Deis.Comme je l'ai dit, nous sommes passés à Helm Charts. Mais le seul problème que nous voyons en ce moment est que beaucoup de bonne documentation est nécessaire. Nous avons besoin de quelques procédures, de FAQ, pour qu'une personne puisse démarrer rapidement, copier les configurations actuelles, coller les leurs, changer les noms pour que tout soit correct. Il est également important de comprendre cela à l'avance et vous devez tout faire. J'ai répertorié des boîtes à outils courantes pour le développement ici, je ne vais pas aborder tout cela sauf le mini-cube. Le minikube est un très bon système, dans le sens où il est bon qu'il l'est, mais c'est mauvais qu'il l'est. Il vous permet d'exécuter Kubernetes localement, vous permet de tout voir sur votre ordinateur portable, pas besoin d'aller n'importe où sur SSH, etc.Je travaille sur MacOS, j'ai un Mac, respectivement, pour exécuter une application locale, je dois exécuter le docker localement. Cela ne peut pas être fait. En fin de compte, vous devez exécuter virtualbox ou xhyve. Les deux choses sont, en fait, des émulations au-dessus de mon système d'exploitation. Nous utilisons xhyve, mais nous vous recommandons d'utiliser VirtualBox, car il y a beaucoup de bugs, ils doivent être contournés.Mais l'idée qu'il y a de la virtualisation, et à l'intérieur de la virtualisation, un autre niveau d'abstraction pour la virtualisation est lancé, est une sorte de ridicule, délirant. En général, il est bon que cela fonctionne d'une manière ou d'une autre, mais il serait préférable qu'il soit terminé.
Le minikube est un très bon système, dans le sens où il est bon qu'il l'est, mais c'est mauvais qu'il l'est. Il vous permet d'exécuter Kubernetes localement, vous permet de tout voir sur votre ordinateur portable, pas besoin d'aller n'importe où sur SSH, etc.Je travaille sur MacOS, j'ai un Mac, respectivement, pour exécuter une application locale, je dois exécuter le docker localement. Cela ne peut pas être fait. En fin de compte, vous devez exécuter virtualbox ou xhyve. Les deux choses sont, en fait, des émulations au-dessus de mon système d'exploitation. Nous utilisons xhyve, mais nous vous recommandons d'utiliser VirtualBox, car il y a beaucoup de bugs, ils doivent être contournés.Mais l'idée qu'il y a de la virtualisation, et à l'intérieur de la virtualisation, un autre niveau d'abstraction pour la virtualisation est lancé, est une sorte de ridicule, délirant. En général, il est bon que cela fonctionne d'une manière ou d'une autre, mais il serait préférable qu'il soit terminé.
 CI n'est pas directement lié à Kubernetes, mais c'est un système très important, surtout si vous avez Kubernetes, si vous l'intégrez, vous pouvez obtenir de très bons résultats. Nous avons utilisé Concourse pour CI, une fonctionnalité très riche, vous pouvez créer des graphiques effrayants, de quoi, où, comment cela commence, de quoi cela dépend. Mais les développeurs de Concourse sont très étranges au sujet de leur produit. Disons qu'en passant d'une version à une autre, ils ont rompu la compatibilité descendante et n'ont pas réécrit la plupart des plugins. De plus, la documentation n'était pas complète et lorsque nous avons essayé de faire quelque chose, rien n'a fonctionné du tout.Il y a peu de documentation en général dans tous les CI, vous devez lire le code et, en général, nous avons abandonné Concourse. Nous sommes passés à Drone.io - il est petit, très léger, agile, la fonctionnalité est beaucoup moins, mais plus souvent c'est suffisant. Oui, il serait pratique d'avoir des graphiques de dépendance volumineux et lourds, mais vous pouvez également travailler sur de petits graphiques. Aussi un peu de documentation, nous lisons le code, mais c'est ok.Chaque étape du pipeline fonctionne dans son propre conteneur Docker, ce qui facilite le passage à Kubernetes. Si vous avez une application qui s'exécute sur une vraie machine, pour l'ajouter à CI, utilisez le conteneur Docker, et après cela, passer à Kubernetes est simple.Nous avons configuré la libération automatique du cluster admin / stage, alors que nous avons peur d'ajouter le paramètre au cluster de production. De plus, il existe un système de plugins.Ceci est un exemple de configuration simple de drone. Tiré du système de travail terminé, dans ce cas, il y a cinq étapes dans le pipeline, chaque étape fait quelque chose: collecte, test, etc. Avec cet ensemble de fonctionnalités qui est dans Drone, je pense que c'est une bonne chose.
CI n'est pas directement lié à Kubernetes, mais c'est un système très important, surtout si vous avez Kubernetes, si vous l'intégrez, vous pouvez obtenir de très bons résultats. Nous avons utilisé Concourse pour CI, une fonctionnalité très riche, vous pouvez créer des graphiques effrayants, de quoi, où, comment cela commence, de quoi cela dépend. Mais les développeurs de Concourse sont très étranges au sujet de leur produit. Disons qu'en passant d'une version à une autre, ils ont rompu la compatibilité descendante et n'ont pas réécrit la plupart des plugins. De plus, la documentation n'était pas complète et lorsque nous avons essayé de faire quelque chose, rien n'a fonctionné du tout.Il y a peu de documentation en général dans tous les CI, vous devez lire le code et, en général, nous avons abandonné Concourse. Nous sommes passés à Drone.io - il est petit, très léger, agile, la fonctionnalité est beaucoup moins, mais plus souvent c'est suffisant. Oui, il serait pratique d'avoir des graphiques de dépendance volumineux et lourds, mais vous pouvez également travailler sur de petits graphiques. Aussi un peu de documentation, nous lisons le code, mais c'est ok.Chaque étape du pipeline fonctionne dans son propre conteneur Docker, ce qui facilite le passage à Kubernetes. Si vous avez une application qui s'exécute sur une vraie machine, pour l'ajouter à CI, utilisez le conteneur Docker, et après cela, passer à Kubernetes est simple.Nous avons configuré la libération automatique du cluster admin / stage, alors que nous avons peur d'ajouter le paramètre au cluster de production. De plus, il existe un système de plugins.Ceci est un exemple de configuration simple de drone. Tiré du système de travail terminé, dans ce cas, il y a cinq étapes dans le pipeline, chaque étape fait quelque chose: collecte, test, etc. Avec cet ensemble de fonctionnalités qui est dans Drone, je pense que c'est une bonne chose.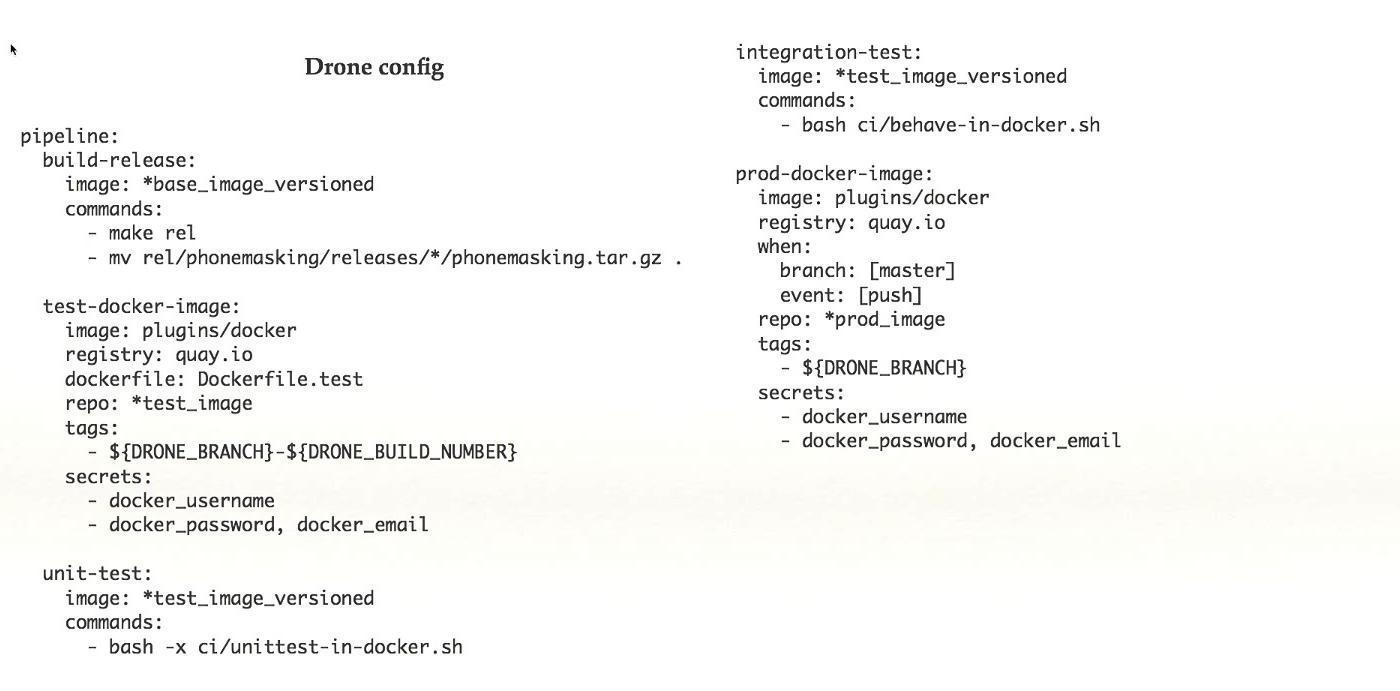
 Nous avons beaucoup discuté du nombre de clusters à avoir: un ou plusieurs. Lorsque nous avons eu l'idée de plusieurs clusters, nous avons commencé à travailler davantage dans cette direction, créé des scripts, mis en place un tas d'autres cubes pour nos Kubernetes. Après cela, ils sont venus sur Google et ont demandé des conseils, est-ce que tout le monde l'a fait, peut-être que quelque chose doit être corrigé.Google a convenu que l'idée d'un cluster unique n'est pas applicable dans Kubernetes. Il existe de nombreuses imperfections, en particulier, le travail avec les géolocalisations. Il s'avère que l'idée est vraie, mais il est trop tôt pour en parler. Peut-être plus tard. Bien que Service Mesh puisse vous aider.
Nous avons beaucoup discuté du nombre de clusters à avoir: un ou plusieurs. Lorsque nous avons eu l'idée de plusieurs clusters, nous avons commencé à travailler davantage dans cette direction, créé des scripts, mis en place un tas d'autres cubes pour nos Kubernetes. Après cela, ils sont venus sur Google et ont demandé des conseils, est-ce que tout le monde l'a fait, peut-être que quelque chose doit être corrigé.Google a convenu que l'idée d'un cluster unique n'est pas applicable dans Kubernetes. Il existe de nombreuses imperfections, en particulier, le travail avec les géolocalisations. Il s'avère que l'idée est vraie, mais il est trop tôt pour en parler. Peut-être plus tard. Bien que Service Mesh puisse vous aider. En général, si vous voulez voir comment fonctionne notre système, faites attention à la géodésique. C'est un produit similaire à ce que nous faisons. C'est open source, un choix très similaire de concept de design. Nous envisageons de faire équipe et éventuellement de les utiliser.
En général, si vous voulez voir comment fonctionne notre système, faites attention à la géodésique. C'est un produit similaire à ce que nous faisons. C'est open source, un choix très similaire de concept de design. Nous envisageons de faire équipe et éventuellement de les utiliser. Oui, dans notre pratique de travailler avec Kubernetes, il y a aussi des problèmes.Il y a un problème avec les noms locaux, avec les certificats. Il y a un problème avec le téléchargement d'images volumineuses et leur travail, peut-être lié au système de fichiers, nous n'y avons pas encore creusé. Il existe déjà trois façons différentes d'installer les extensions Kubernetes. Nous travaillons sur ce projet depuis moins d'un an, et nous avons déjà trois façons différentes, les anneaux annuels se multiplient.
Oui, dans notre pratique de travailler avec Kubernetes, il y a aussi des problèmes.Il y a un problème avec les noms locaux, avec les certificats. Il y a un problème avec le téléchargement d'images volumineuses et leur travail, peut-être lié au système de fichiers, nous n'y avons pas encore creusé. Il existe déjà trois façons différentes d'installer les extensions Kubernetes. Nous travaillons sur ce projet depuis moins d'un an, et nous avons déjà trois façons différentes, les anneaux annuels se multiplient. Soyons comme tous les inconvénients.Donc, je pense que l'un des principaux inconvénients est la grande quantité d'informations à étudier, non seulement les nouvelles technologies, mais aussi les nouveaux concepts et habitudes. C’est comme apprendre une nouvelle langue: en principe, ce n’est pas difficile, mais il est difficile de tourner la tête un peu à tous les utilisateurs. Si vous n'avez jamais travaillé avec des concepts similaires auparavant, passer à Kubernetes est difficile.Kubernetes ne sera qu'une petite partie de votre système. Tout le monde pense qu'ils vont installer Kubernetes, et tout fonctionnera immédiatement. Non, c'est un petit cube, et il y en aura beaucoup.Certaines applications sont généralement difficiles à exécuter sur Kubernetes - et il vaut mieux ne pas les exécuter. Fichiers de configuration également très lourds et volumineux, et dans les concepts au-dessus de Kubernetes, ils sont encore plus compliqués. Toutes les solutions actuelles sont brutes.Tous ces inconvénients sont bien sûr dégoûtants.Les compromis et une transition difficile créent une image négative de Kubernetes, et je ne sais pas comment y faire face. Nous ne pouvions pas surmonter beaucoup, il y a des gens qui détestent tout le mouvement, ne veulent pas et ne comprennent pas ses avantages.Pour exécuter Minikube, votre système devra travailler dur pour que tout fonctionne. Comme vous pouvez le voir, il existe de nombreux inconvénients, et ceux qui ne veulent pas travailler avec Kubernetes ont leurs propres raisons. Si vous ne voulez pas entendre parler des pros, fermez les yeux et les oreilles, car ils iront plus loin.
Soyons comme tous les inconvénients.Donc, je pense que l'un des principaux inconvénients est la grande quantité d'informations à étudier, non seulement les nouvelles technologies, mais aussi les nouveaux concepts et habitudes. C’est comme apprendre une nouvelle langue: en principe, ce n’est pas difficile, mais il est difficile de tourner la tête un peu à tous les utilisateurs. Si vous n'avez jamais travaillé avec des concepts similaires auparavant, passer à Kubernetes est difficile.Kubernetes ne sera qu'une petite partie de votre système. Tout le monde pense qu'ils vont installer Kubernetes, et tout fonctionnera immédiatement. Non, c'est un petit cube, et il y en aura beaucoup.Certaines applications sont généralement difficiles à exécuter sur Kubernetes - et il vaut mieux ne pas les exécuter. Fichiers de configuration également très lourds et volumineux, et dans les concepts au-dessus de Kubernetes, ils sont encore plus compliqués. Toutes les solutions actuelles sont brutes.Tous ces inconvénients sont bien sûr dégoûtants.Les compromis et une transition difficile créent une image négative de Kubernetes, et je ne sais pas comment y faire face. Nous ne pouvions pas surmonter beaucoup, il y a des gens qui détestent tout le mouvement, ne veulent pas et ne comprennent pas ses avantages.Pour exécuter Minikube, votre système devra travailler dur pour que tout fonctionne. Comme vous pouvez le voir, il existe de nombreux inconvénients, et ceux qui ne veulent pas travailler avec Kubernetes ont leurs propres raisons. Si vous ne voulez pas entendre parler des pros, fermez les yeux et les oreilles, car ils iront plus loin. Le premier avantage est qu'avec le temps, les débutants devront apprendre moins. Il arrive souvent que lorsqu'un nouveau venu entre dans le système, il commence à arracher tous ses cheveux, car pendant les 1 à 2 premiers mois, il essaie de comprendre comment tout libérer, si le système est grand et vit longtemps, de nombreux anneaux annuels ont poussé. Kubernetes facilite les choses.Deuxièmement, Kubernetes ne le fait pas lui-même, mais vous permet de faire un cycle de libération court. Un commit a créé un CI, CI a créé une image, pompé automatiquement, vous avez appuyé sur un bouton et tout est entré en production. Cela réduit considérablement le temps de sortie.Ce qui suit est le fractionnement de code. Notre système et la plupart de vos systèmes collectent des configurations de différents niveaux en un seul endroit, c'est-à-dire que vous avez un code d'infrastructure, un code d'entreprise, toutes les logiques sont mélangées en un seul endroit. Dans Kubernetes, cela ne sortira pas des sentiers battus, choisir le bon concept permet d'éviter cela à l'avance.Une communauté importante et très active, ce qui signifie un grand nombre de changements. La plupart de ce que j'ai mentionné au cours des deux dernières années est devenu si stable qu'ils peuvent être mis en production. Certains d'entre eux sont peut-être apparus plus tôt, mais n'étaient pas très stables.Je considère que c'est un gros avantage que vous puissiez voir à la fois les journaux d'application et les journaux de Kubernetes qui fonctionnent avec votre application, ce qui est inestimable. Et il n'y a pas d'accès aux nœuds. Lorsque nous avons supprimé l'accès aux nœuds aux utilisateurs, cela a immédiatement coupé une grande classe de problèmes.
Le premier avantage est qu'avec le temps, les débutants devront apprendre moins. Il arrive souvent que lorsqu'un nouveau venu entre dans le système, il commence à arracher tous ses cheveux, car pendant les 1 à 2 premiers mois, il essaie de comprendre comment tout libérer, si le système est grand et vit longtemps, de nombreux anneaux annuels ont poussé. Kubernetes facilite les choses.Deuxièmement, Kubernetes ne le fait pas lui-même, mais vous permet de faire un cycle de libération court. Un commit a créé un CI, CI a créé une image, pompé automatiquement, vous avez appuyé sur un bouton et tout est entré en production. Cela réduit considérablement le temps de sortie.Ce qui suit est le fractionnement de code. Notre système et la plupart de vos systèmes collectent des configurations de différents niveaux en un seul endroit, c'est-à-dire que vous avez un code d'infrastructure, un code d'entreprise, toutes les logiques sont mélangées en un seul endroit. Dans Kubernetes, cela ne sortira pas des sentiers battus, choisir le bon concept permet d'éviter cela à l'avance.Une communauté importante et très active, ce qui signifie un grand nombre de changements. La plupart de ce que j'ai mentionné au cours des deux dernières années est devenu si stable qu'ils peuvent être mis en production. Certains d'entre eux sont peut-être apparus plus tôt, mais n'étaient pas très stables.Je considère que c'est un gros avantage que vous puissiez voir à la fois les journaux d'application et les journaux de Kubernetes qui fonctionnent avec votre application, ce qui est inestimable. Et il n'y a pas d'accès aux nœuds. Lorsque nous avons supprimé l'accès aux nœuds aux utilisateurs, cela a immédiatement coupé une grande classe de problèmes. La deuxième partie des avantages est un peu plus conceptuelle. La plupart de la communauté Kubernetes voit la partie technologique. Mais nous avons vu la partie gestion conceptuelle. Une fois que vous êtes passé à Kubernetes, et s'il est correctement configuré, la sous-commande (ou le backend - je ne sais pas comment vous l'appelez correctement) n'est plus nécessaire pour libérer les applications.L'utilisateur veut décharger l'application, il ne viendra pas le demander, mais lancera simplement un nouveau pod, il y a une commande pour cela. Une équipe d'infrastructure n'est pas nécessaire pour enquêter sur les problèmes. Il suffit de regarder les journaux, notre ensemble de designs n'est pas si grand, il y a une liste par laquelle il est très facile de trouver le problème. Oui, parfois un support est nécessaire si le problème est dans Kubernetes, dans certains cas, mais le plus souvent, c'est avec des applications.Nous avons ajouté le budget d'erreur. Voici le concept suivant: chaque équipe dispose de statistiques sur le nombre de problèmes survenant en production. S'il y a trop de problèmes, l'équipe coupe les versions jusqu'à ce que cela prenne un certain temps. C'est bien parce que l'équipe surveillera sérieusement que leurs versions sont très stables. Besoin de nouvelles fonctionnalités - veuillez libérer. Vous voulez libérer à deux heures du matin - s'il vous plaît. Si après les versions, vous n'avez que «neuf» en SLA - faites ce que vous voulez, tout est stable, vous pouvez tout faire. Cependant, si la situation est pire, nous ne serons probablement pas autorisés à publier autre chose que des correctifs.C'est une chose pratique à la fois pour la stabilité du système et pour l'ambiance au sein de l'équipe. Nous cessons d'être la "police morale", ce qui nous empêche de la libérer tard dans la nuit. Faites ce que vous voulez tout en ayant un bon budget d'erreurs. Cela réduit considérablement le stress au sein de l'entreprise.Vous pouvez utiliser l' e - mail ou le tweet pour me contacter : @gliush .Et à la fin, il y a beaucoup de liens pour vous, vous pouvez télécharger et voir tout vous-même:
La deuxième partie des avantages est un peu plus conceptuelle. La plupart de la communauté Kubernetes voit la partie technologique. Mais nous avons vu la partie gestion conceptuelle. Une fois que vous êtes passé à Kubernetes, et s'il est correctement configuré, la sous-commande (ou le backend - je ne sais pas comment vous l'appelez correctement) n'est plus nécessaire pour libérer les applications.L'utilisateur veut décharger l'application, il ne viendra pas le demander, mais lancera simplement un nouveau pod, il y a une commande pour cela. Une équipe d'infrastructure n'est pas nécessaire pour enquêter sur les problèmes. Il suffit de regarder les journaux, notre ensemble de designs n'est pas si grand, il y a une liste par laquelle il est très facile de trouver le problème. Oui, parfois un support est nécessaire si le problème est dans Kubernetes, dans certains cas, mais le plus souvent, c'est avec des applications.Nous avons ajouté le budget d'erreur. Voici le concept suivant: chaque équipe dispose de statistiques sur le nombre de problèmes survenant en production. S'il y a trop de problèmes, l'équipe coupe les versions jusqu'à ce que cela prenne un certain temps. C'est bien parce que l'équipe surveillera sérieusement que leurs versions sont très stables. Besoin de nouvelles fonctionnalités - veuillez libérer. Vous voulez libérer à deux heures du matin - s'il vous plaît. Si après les versions, vous n'avez que «neuf» en SLA - faites ce que vous voulez, tout est stable, vous pouvez tout faire. Cependant, si la situation est pire, nous ne serons probablement pas autorisés à publier autre chose que des correctifs.C'est une chose pratique à la fois pour la stabilité du système et pour l'ambiance au sein de l'équipe. Nous cessons d'être la "police morale", ce qui nous empêche de la libérer tard dans la nuit. Faites ce que vous voulez tout en ayant un bon budget d'erreurs. Cela réduit considérablement le stress au sein de l'entreprise.Vous pouvez utiliser l' e - mail ou le tweet pour me contacter : @gliush .Et à la fin, il y a beaucoup de liens pour vous, vous pouvez télécharger et voir tout vous-même:- Mise en réseau native de conteneurs - Comparaison
- Livraison continue par Jez Humble, David Farley.
- Les conteneurs ne sont pas des machines virtuelles
- Docker Distribution (registre d'images)
- Quay - Registre d'images en tant que service
- etcd-operator - Gestionnaire du cluster etcd au sommet de Kubernetes
- Dex - OpenID Connect Identity (OIDC) et fournisseur OAuth 2.0 avec connecteurs enfichables
- awsudo - utilitaire de type sudo pour gérer les informations d'identification AWS
- Autoscaling-related components for Kubernetes
- Simon's cat
- Helm: Kubernetes package manager
- Geodesic: framework to create your own cloud platform
- Calico: Configuring IP-in-IP
- Sensu: Open-core monitoring system
- InfluxDB: Scalable datastore for metrics, events, and real-time analytics
- Cernan: Telemetry and logging aggregation server
- Prometheus: Open Source monitoring solution
- Heapster: Compute Resource Usage Analysis and Monitoring of Container Clusters
- Stern: Multi pod and container log tailing for Kubernetes
- Minikube: tool to run Kubernetes locally
- Docker machine driver fox xhyve native OS X Hypervisor
- Drone: Continuous Delivery platform built on Docker, written in Go
- Borg, Omega and Kubernetes
- Container-Native Networking — Comparison
- Bug in minikube when working with xhyve driver.
Minute de publicité. Si vous avez aimé ce rapport de la conférence DevOops - notez que le 14 octobre, le nouveau DevOops 2018 se tiendra à Saint-Pétersbourg, il y aura beaucoup de choses intéressantes dans son programme. Le site a déjà les premiers intervenants et rapports.