Préface
L'implémentation de PHP trie décrite ici rend le dictionnaire trop gras jusqu'à présent, ce qui prend donc un certain temps pour se charger en mémoire, ce qui nivelle la assez bonne vitesse de son travail. La vitesse de recherche est d'environ 80 000 mots par seconde. Le dictionnaire est composé de la liste des lemmes du dictionnaire opencorpora.org et comprend 389844 mots. Sous forme non compressée, le dictionnaire pèse ~ 150 Mo et le gzip compressé ~ 6 Mo. Cependant, de très bons résultats de performances prouvent qu'en PHP pur, vous pouvez créer un arbre de préfixes de tri entièrement fonctionnel.
Je demande aux programmeurs à l'avance avec l'étoffe des critiques littéraires de ne pas écrire de commentaires malveillants. Cet article devrait être intéressant pour les débutants, comme moi-même. Trop paresseux pour lire, vous pouvez immédiatement voir le code sur
github .
Comment tout a commencé
Depuis un certain temps maintenant, j'échappe à l'idée d'écrire un analyseur morphologique pour mes projets PHP, qui sera capable de mener rapidement une analyse morphologique de mots donnés, ainsi que de transformer des mots dans la forme morphologique souhaitée.
PHP a déjà une bibliothèque similaire appelée phpmorhy. Cela fonctionne assez rapidement et je l'utiliserais et n'inventerais rien, mais le compilateur de dictionnaire est fait comme une application non PHP distincte, ce qui me rend impossible d'utiliser cette bibliothèque. La bibliothèque elle-même est construite sur la base du dictionnaire AOT tant attendu, ce qui réduit encore son utilité.
Des semaines et des mois ont passé, j'ai lu
un article de Khabrovchanin, puis
un article de I. Segalovich sur un algorithme morphologique rapide pour un moteur de recherche, puis un tas d'articles différents.
Peu à peu, j'ai mûri pour écrire mon propre
lunapark avec le blackjack et les os d'un analyseur morphologique. Je pense: "
Eh bien, les progrès ont progressé, en PHP, vous pouvez déjà analyser le génome humain! "
J'ai pris le dictionnaire opencorpora.org, je l'ai mis dans mysql et j'ai obtenu une vitesse de recherche de 2 000 mots par seconde. Il faut, je pense, charger le dictionnaire en mémoire. Et ici, il s'avère que pour avoir des structures de données régulières disponibles en PHP comme un tableau ou un objet, vous devez stocker environ 3 Go de RAM pour un dictionnaire de 3 millions. Toutes les implémentations de php trie qui me sont parvenues n'étaient appropriées que comme tutoriel pour démontrer la logique du travail, car elles-mêmes étaient construites sur des structures de stockage de données PHP natives.
Dispositif de stockage de dictionnaire et principe de fonctionnement
Partout où j'ai pu lire, écouter ou regarder dans l'arbre des préfixes trie, il n'est pas expliqué exactement comment les données seront stockées en mémoire. Ici, nous avons le nœud, et voici ses héritiers, et voici le drapeau de la fin du mot, qui n'est pas représenté sous le capot. J'ai donc dû inventer moi-même une méthode de stockage.
Comme vous le savez, l'arborescence des préfixes trie est constituée de nœuds. Un nœud stocke un préfixe, des liens vers les nœuds suivants (descendants) et un pointeur sur le fait que ce préfixe est le dernier de la chaîne. Tout indique intelligiblement à propos de Trie des Indiens
ici .
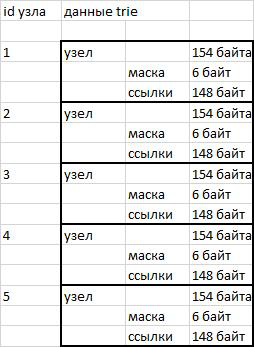
Les nœuds de mon implémentation trie sont des blocs de données d'une longueur fixe de 154 octets. Les 6 premiers octets (48 bits) contiennent le masque de bits des héritiers. Les 46 premiers bits sont l'alphabet russe, les chiffres, les guillemets, le tiret et l'apostrophe. L'apostrophe a été ajoutée car dans le dictionnaire opencorpora.org il y a le mot "cote d'ivoire", qui utilise le signe de l'apostrophe. Le 47e bit est utilisé pour stocker l'indicateur de fin de mot. Les 148 octets suivants après le masque de bits sont utilisés pour stocker les références aux héritiers du nœud. 3 octets par caractère (46 * 3 = 148).
Les nœuds sont stockés sous forme de données binaires dans une chaîne. L'accès à la section souhaitée est effectué à l'aide de la fonction substr () et du déballage ultérieur ().
L'utilisation de nœuds de longueur fixe simplifie le processus d'adressage. Pour passer au nœud souhaité, il suffit de connaître son numéro de série (id) et la longueur du nœud. Nous multiplions le numéro de série par la longueur et découvrons le décalage par rapport au début de la ligne - tout est très simple.
fig. 1 Schéma de stockage
Inconvénients
Le schéma de stockage utilisé simplifie l'adressage, mais il consomme de l'espace. Le stockage de 380 000 mots nécessite un peu plus d'un million de nœuds. 154 octets * 1000000 nœuds = 146,86 mégaoctets. C'est-à-dire environ 400 octets par mot. Si vous écrivez des mots dans un simple fichier texte encodé en utf8, ces mêmes 380 000 mots peuvent tenir dans 16 mégaoctets.
Plans
Pour utiliser la mémoire de manière plus rationnelle, je veux passer à une longueur variable de nœuds, puis en tant que lien, je devrai enregistrer non pas l'identifiant du nœud, mais son emplacement en octets. L'emplacement du lien vers le nœud souhaité sera déterminé comme suit. Sur l'exemple du mot "abv."
La lettre "a" est la première de l'alphabet, par conséquent, son nœud est également le premier, respectivement, le décalage 0. Lire 6 octets, à partir de 0.
$str = substr($dic, 0, 6);
Déballez la ligne:
$mask = (ord($str[5]) << 40) + (ord($str[4]) << 32) + (ord($str[3]) << 24) + (ord($str[2]) << 16) + (ord($str[1]) << 8) + ord($str[0]);
On regarde le masque du 2ème bit (lettre "b")
bit_get($mask, 2);
Le bit est défini, nous comptons maintenant le nombre de bits levés dans le masque à 2. Disons que le bit de la lettre "a" est également levé à notre nœud, donc notre bit de la lettre "b" sera le deuxième bit levé. Compter le décalage pour lire le lien
$offset = 6 + 3;
Masque de 6 octets + 3 octets, que le premier lien occupe, il s'avère 9 octets. Nous lisons le morceau de ficelle souhaité.
$str = substr($dic, $offset, 3);
Décompressez le lien:
$ref = (ord($str[2]) << 16) + (ord($str[1]) << 8) + ord($str[0]);
Allez au nœud suivant et répétez tout à nouveau. Dans la dernière lettre, nous vérifions la présence de 47 bits dans le masque, s'il est défini, il y a un mot de recherche dans notre trie.
J'espère qu'il sera possible de maintenir une vitesse d'au moins 50 000 mots par seconde.
Remerciements
Je tiens à remercier les participants du forum nulled.cc et php.ru pour leur aide avec les fonctions bit à bit.