DeepMind, une fois une division de Google Corporation, développe l'IA (sa forme faible) à diverses fins. Maintenant, l'équipe DeepMind est activement impliquée dans la création de diverses formes d'IA, affinées pour les jeux, à la fois logiques, de bureau et de tireurs. Il existe de nombreux jeux - c'est parti, et StarCraft, et maintenant - et Quake III Arena.
Les développeurs ont
déclaré sur leur blog qu'ils avaient formé le système d'IA à jouer à Quake III Arena de la même manière qu'une personne. Autrement dit, le système informatique a appris à s'adapter à des conditions de jeu en évolution rapide, notamment en changeant de niveau et de leurs éléments. Traditionnellement, un
système renforcé était utilisé pour la formation.
Lors de ce type de formation, l'ordinateur reçoit une récompense ou une amende, selon que le passage est réussi ou non. En règle générale, le problème d'un ordinateur est qu'il ne peut pas s'adapter assez rapidement aux conditions changeantes - tout comme une personne le fait. Malgré le fait que les réseaux de neurones ont longtemps pu apprendre de leurs propres erreurs, les jeux informatiques sont difficiles pour eux si le système ne connaît pas les conditions initiales.
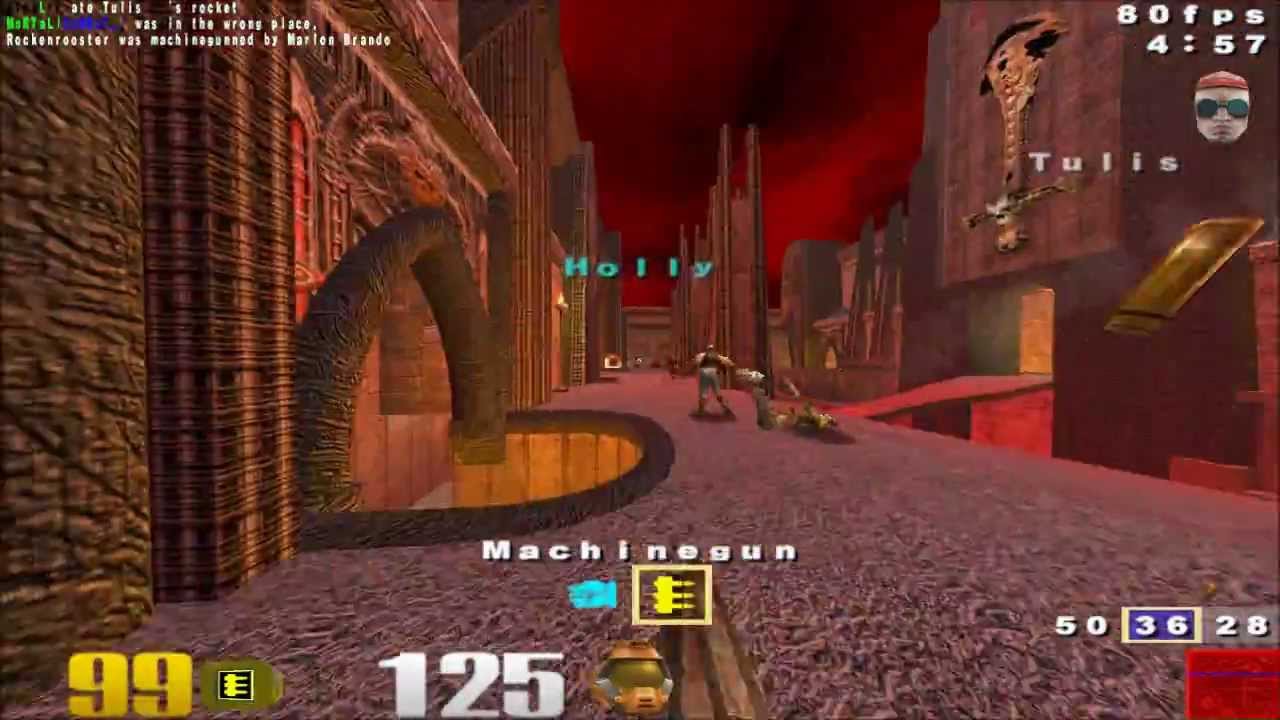
Le système a été formé pour jouer en mode Capture The Flag. Dans ce cas, le joueur doit essayer de capturer le drapeau de l'adversaire, mais en aucun cas il ne doit permettre que le sien soit capturé. Si une équipe peut capturer et tenir le drapeau de l'adversaire pendant le nombre maximum de fois dans les cinq minutes, alors une telle équipe sera gagnante.
Afin d'empêcher l'IA d'apprendre simplement les caractéristiques du niveau, y compris l'emplacement des pièces, des bâtiments, etc., chaque fois que le réseau neuronal était forcé de jouer à un nouveau niveau. Dans ce cas, l'IA a développé sa propre stratégie de jeu sans bourrage. L'ordinateur surveillait les actions des autres joueurs, étudiait la «géographie» du niveau et agissait en fonction de la situation.
De plus, les développeurs de Deepmind ont formé l'IA à jouer avec toute l'équipe, composée de différents agents. L'ensemble du système s'appelle For The Win (FTW).
Ainsi, For The Win (FTW) a appris à gérer son équipe, à coordonner et diriger les actions de chaque agent. La tâche, comme mentionné ci-dessus, est de préserver son propre drapeau et de capturer celui de quelqu'un d'autre. Après que l'ordinateur ait atteint un certain niveau de compétence, DeepMind s'est vu proposer de jouer avec des joueurs ordinaires dans un tournoi spécial.
Les 40 personnes y ont participé. Les équipes du tournoi étaient mixtes - c'est-à-dire que dans une équipe, il pouvait y avoir à la fois des personnes et des agents de l'IA. Selon les résultats du jeu, il est devenu clair que l'IA dans sa forme pure a remporté plus de victoires que les équipes de personnes. Dans les équipes mixtes, l'IA a montré un niveau de coopération plus élevé que les gens ne le démontrent habituellement. Ainsi, l'ordinateur, si nécessaire, servait d'esclave ou était directement impliqué dans l'attaque de la base ennemie.
Selon les développeurs, les principes de travail qui ont été utilisés pour créer For The Win (FTW) peuvent très bien être utilisés pour jouer à d'autres titres, par exemple StarCraft II ou Dota 2.
Au début de ce mois, DeepMind a
démontré le processus d' apprentissage de l'IA pour passer des jeux à l'ancienne - sur Atari. Le principe de l'entraînement par renforcement a également été utilisé ici, et il est assez difficile d'apprendre à l'IA à passer les vieux jeux, car de nombreuses actions du protagoniste sont très implicites.
La base a été prise le jeu Montezuma's Revenge. Il n'y a ni tâche claire, ni direction à suivre, ni compréhension de ce qui doit être rassemblé ou contre qui parler. Deux méthodes ont été utilisées pour enseigner l'exemple: TDC (classification de distance temporelle) et CDC (classification de distance temporelle inter-modale).
L'ordinateur a été formé pour jouer au jeu en utilisant des procédures vidéo de YouTube - il y en a beaucoup sur le service. Pendant le passage, les images de l'enregistrement vidéo de passage des niveaux d'IA et de ses "professeurs" de YouTube ont été comparées. Si la comparaison montrait un haut niveau de similitude, l'IA recevrait une récompense. Comme il s'est avéré, après un certain temps, l'IA effectue la même séquence d'actions que la personne.
Quant à StarCraft, qui a été mentionné ci-dessus, en 2017, une personne a
encore vaincu la voiture , et sèche, avec un score de 4: 0. Le professionnel de StarCraft Song Byung-gu a ensuite combattu quatre robots StarCraft différents.