Ces
nouvelles (+
recherches ) sur l'invention du générateur de mèmes par des scientifiques de l'Université de Stanford m'ont incité à écrire un article. Dans mon article, je vais essayer de montrer que vous n'avez pas besoin d'être un scientifique de Stanford pour faire des choses intéressantes avec les réseaux de neurones. Dans l'article, je décris comment en 2017 nous avons formé un réseau de neurones sur un corps d'environ 30000 textes et l'avons forcé à générer de nouveaux mèmes Internet et des mèmes (signes de communication) au sens sociologique du terme. Nous décrivons l'algorithme d'apprentissage automatique que nous avons utilisé, les difficultés techniques et administratives que nous avons rencontrées.
Un peu d'histoire sur la façon dont nous sommes arrivés à l'idée d'un neuro-écrivain et en quoi elle consistait exactement. En 2017, nous avons réalisé un projet pour un site Web public de Vkontakte, dont le nom et les captures d'écran étaient interdits aux modérateurs Habrahabr de publier, considérant sa mention comme «soi» PR. Le public existe depuis 2013 et unit les messages avec l'idée générale de décomposer l'humour à travers une ligne et de séparer les lignes avec le symbole "@":
@
@
Le nombre de lignes peut varier, l'intrigue peut être quelconque. Le plus souvent, il s'agit d'humour ou de notes sociales nettes sur les faits rampants de la réalité. En général, cette conception est appelée «buhurt».
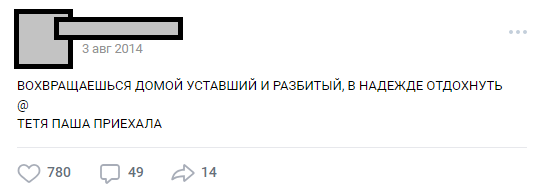 L'un des buhurts typiques
L'un des buhurts typiquesAu fil des ans, le public est devenu une tradition interne (personnages, intrigues, lieux) et le nombre de publications a dépassé les 30 000. Au moment de leur analyse des besoins du projet, le nombre de lignes sources du texte dépassait le demi-million.
Partie 0. L'émergence d'idées et d'équipes
Dans le sillage de la popularité de masse des réseaux de neurones, l'idée de former ANN sur nos textes était dans l'air depuis environ six mois, mais a finalement été formulée à l'aide de E7su en décembre 2016. En même temps, le nom a été inventé («Neurobugurt»). A cette époque, l'équipe intéressée par le projet n'était composée que de trois personnes. Nous étions tous des étudiants sans expérience pratique des algorithmes et des réseaux de neurones. Pire encore, nous n'avions même pas un seul GPU adapté à la formation. Tout ce que nous avions, c'était l'enthousiasme et la confiance que cette histoire pouvait être intéressante.
Partie 1. La formulation de l'hypothèse et des tâches
Notre hypothèse s'est avérée être l'hypothèse que si vous mélangez tous les textes publiés sur trois ans et demi et formez le réseau neuronal sur ce bâtiment, vous pouvez obtenir:
a) plus créatif que les gens
b) drôle
Même si les mots ou les lettres dans le buhurt s'avèrent être confus par la machine et disposés au hasard - nous pensions que cela pourrait fonctionner comme un service de fans et plairait encore aux lecteurs.
La tâche a été grandement simplifiée par le fait que le format des buhurts est essentiellement textuel. Nous n'avons donc pas eu à plonger dans la vision industrielle et d'autres choses complexes. Une autre bonne nouvelle est que l'ensemble des textes est très similaire. Cela a permis de ne pas utiliser l'apprentissage renforcé - au moins dans les premiers stades. Dans le même temps, nous avons clairement compris que la création d'un rédacteur de réseau neuronal avec une sortie lisible plus d'une fois n'est pas si facile. Le risque de donner naissance à un monstre qui jettera des lettres au hasard était très grand.
Partie 2. Préparation du corps des textes
On pense que la phase de préparation peut prendre beaucoup de temps, car elle est associée à la collecte et au nettoyage des données. Dans notre cas, cela s'est avéré être assez court: un petit
analyseur a été écrit qui a pompé environ 30 000 messages du mur de la communauté et les a placés dans un
fichier txt .
Nous n'avons pas effacé les données avant la première formation. À l'avenir, cela a joué une blague cruelle avec nous, car en raison de l'erreur qui s'est glissée à ce stade, nous n'avons pas pu mettre les résultats sous une forme lisible pendant longtemps. Mais plus à ce sujet plus tard.
 Fichier écran avec des hamburgers
Fichier écran avec des hamburgersPartie 3. Annonce, raffinement de l'hypothèse, choix de l'algorithme
Nous avons utilisé une ressource accessible - un grand nombre d'abonnés publics. L'hypothèse était que parmi 300 000 lecteurs, il y a plusieurs passionnés qui possèdent des réseaux de neurones à un niveau suffisant pour combler les lacunes dans les connaissances de notre équipe. Nous sommes partis de l'idée d'annoncer largement le concours et d'attirer les passionnés de machine learning à la discussion du problème formulé. Après avoir écrit les textes, nous avons fait part de notre idée aux gens et espéré une réponse.
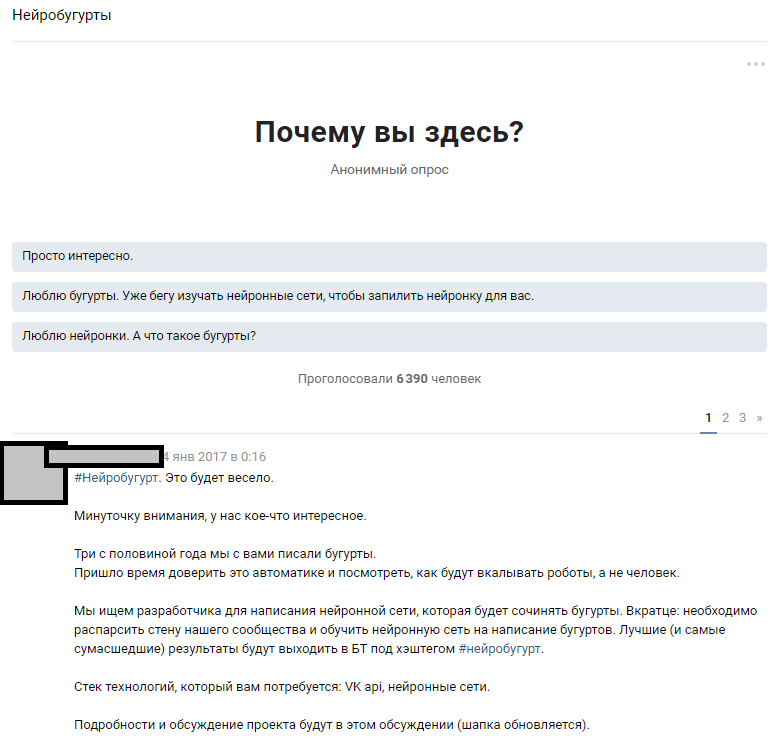 Annonce d'une discussion thématique
Annonce d'une discussion thématiqueLa réaction des gens a dépassé nos attentes les plus folles. La discussion sur le fait que nous allons former un réseau de neurones a propagé l'holivar par près de 1000 commentaires. La plupart des lecteurs ont simplement disparu et ont essayé d'imaginer à quoi ressemblerait le résultat. Environ 6 000 personnes ont regardé la discussion thématique et plus de 50 amateurs intéressés ont laissé des commentaires à qui nous avons donné un ensemble de test de
814 lignes de buhurt pour effectuer les premiers tests et la formation. Chaque personne intéressée pourrait prendre un ensemble de données et apprendre l'algorithme qui lui est le plus intéressant, puis discuter avec nous et d'autres passionnés. Nous avons annoncé à l'avance que nous continuerons à travailler avec les participants dont les résultats seront les plus lisibles.
Le travail a commencé: quelqu'un a assemblé silencieusement un générateur sur des chaînes de Markov, quelqu'un a essayé diverses implémentations avec un github, et la plupart sont juste devenus fous dans la discussion et nous ont convaincus avec de la mousse à la bouche que rien n'en sortirait. Cela a commencé la partie technique du projet.
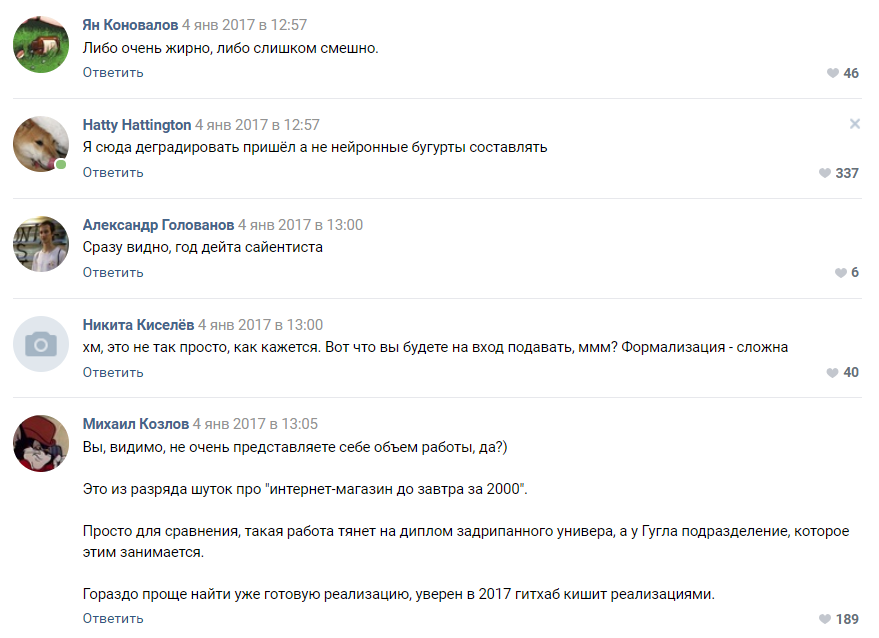
Quelques suggestions de passionnés
Les gens ont offert des dizaines d'options pour la mise en œuvre:
- Chaînes de Markov.
- Trouvez une implémentation prête à l'emploi de quelque chose de similaire à GitHub et entraînez-la.
- Un générateur de phrases aléatoires écrit en Pascal.
- Obtenez un nègre littéraire qui écrira des bêtises aléatoires, et nous passerons cela comme une sortie de réseau neuronal.
 Évaluation de la complexité du projet par l'un des abonnés
Évaluation de la complexité du projet par l'un des abonnésLa plupart des commentateurs ont convenu que notre projet est voué à l'échec et que nous n'atteindrons même pas le stade du prototype. Comme nous l'avons compris plus tard, les gens sont toujours enclins à percevoir les réseaux de neurones comme une sorte de magie noire qui se produit dans la "tête de Zuckerberg" et les divisions secrètes de Google.
Partie 4. Sélection d'algorithmes, formation et expansion de l'équipe
Après un certain temps, la campagne que nous avons lancée pour des idées de crowdsourcing pour l'algorithme a commencé à porter ses premiers fruits. Nous avons obtenu environ 30 prototypes fonctionnels, dont la plupart ont donné des bêtises complètement illisibles.
A ce stade, nous avons d'abord rencontré une démotivation de l'équipe. Tous les résultats étaient très faiblement similaires aux buhurts et représentaient le plus souvent l'abracadabra des lettres et des symboles. Le travail de dizaines de passionnés est tombé en poussière, ce qui les a démotivés, nous et nous.
L'algorithme basé sur pyTorch s'est montré meilleur que les autres. Il a été décidé de prendre cette implémentation et l'algorithme LSTM comme base. Nous avons reconnu l'abonné qui l'a proposé comme gagnant et avons commencé à travailler avec lui sur l'amélioration de l'algorithme. Notre équipe répartie est passée à quatre personnes. Le fait amusant ici est que le
gagnant du concours , il s'est avéré, n'avait que 16 ans. Cette victoire a été son premier vrai prix dans le domaine de la Data Science.
Pour la première formation, un cluster de 8 cartes graphiques GXT1080 a été loué.
 Console de gestion de cluster de cartes
Console de gestion de cluster de cartesLe référentiel d'origine et tous les manuels de projet Torch-rnn sont ici:
github.com/jcjohnson/torch-rnn . Plus tard, sur la base de cela, nous avons publié
notre référentiel , dans lequel se trouvent nos sources, ReadMe pour l'installation, ainsi que les neurobugurts finis eux-mêmes.
Les premières fois, nous nous sommes entraînés à l'aide d'une configuration préconfigurée sur un cluster GPU payant. L'installation ne s'est pas avérée si difficile - seules les instructions du développeur Torch et l'aide de l'administration d'hébergement, qui est incluse dans le paiement, suffisent.
Cependant, très rapidement, nous avons rencontré des difficultés: chaque formation a coûté le temps de location du GPU - ce qui signifie qu'il n'y avait tout simplement pas d'argent dans le projet. Pour cette raison, en janvier-février 2017, nous avons organisé une formation dans les installations achetées et nous avons essayé de lancer la génération sur nos machines locales.
Tout texte convient à la formation de modèle. Avant la formation, vous devez le prétraiter, pour lequel Torch a un algorithme spécial preprocess.py qui convertit votre my_data.txt en deux fichiers: HDF5 et JSON:
Le script de prétraitement s'exécute comme suit:
python scripts/preprocess.py \ --input_txt my_data.txt \ --output_h5 my_data.h5 \ --output_json my_data.json
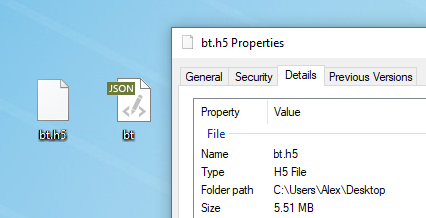 Après le prétraitement, deux fichiers apparaissent sur lesquels le réseau de neurones sera formé à l'avenir
Après le prétraitement, deux fichiers apparaissent sur lesquels le réseau de neurones sera formé à l'avenirLes différents indicateurs pouvant être modifiés au stade du prétraitement sont décrits
ici . Il est également possible d'exécuter
Torch à partir de Docker , mais l'auteur de l'article ne l'a pas vérifié.
Formation au réseau de neurones
Après le prétraitement, vous pouvez procéder à la formation du modèle. Dans le dossier avec HDF5 et JSON, vous devez exécuter l'utilitaire e, qui est apparu avec vous si vous avez correctement installé Torch:
th train.lua -input_h5 my_data.h5 -input_json my_data.json
La formation prend énormément de temps et génère des fichiers de la forme cv / checkpoint_1000.t7, qui sont les «poids» de notre réseau de neurones. Ces fichiers pèsent une quantité impressionnante de mégaoctets et contiennent la force des liens entre des lettres spécifiques dans votre jeu de données d'origine.
 Un réseau de neurones est souvent comparé au cerveau humain, mais il me semble une analogie beaucoup plus claire avec une fonction mathématique qui prend des paramètres en entrée (votre jeu de données) et donne le résultat (nouvelles données) en sortie.
Un réseau de neurones est souvent comparé au cerveau humain, mais il me semble une analogie beaucoup plus claire avec une fonction mathématique qui prend des paramètres en entrée (votre jeu de données) et donne le résultat (nouvelles données) en sortie.Dans notre cas, chaque formation sur un cluster de 8 GTX 1080 dans un ensemble de données de 500 000 lignes a pris environ une heure ou deux, et une formation similaire sur une sorte de CPU i3-2120 a pris environ 80 à 100 heures. Dans le cas d'une formation plus longue, le réseau neuronal a commencé à se recycler de manière rigide - les symboles se répétaient trop souvent, tombant dans de longs cycles de prépositions, de conjonctions et de mots introductifs.
Il est pratique que vous puissiez choisir la fréquence des points de contrôle et pendant une formation, vous obtiendrez immédiatement de nombreux modèles: du moins formé (checkpoint_1000) au recyclage (checkpoint_1000000). Seul assez d'espace serait suffisant.
Nouvelle génération de texte
Après avoir reçu au moins un fichier prêt à l'emploi avec des poids (checkpoint _ *******), vous pouvez passer à l'étape suivante et la plus intéressante: commencer à générer des textes. Pour nous, ce fut un vrai moment de vérité, car pour la première fois nous avons obtenu un résultat tangible - un bug écrit par une machine.
À ce stade, nous avons finalement cessé d'utiliser le cluster et toutes les générations ont été effectuées sur nos machines de faible puissance. Cependant, lors de la tentative de démarrage local, nous n'avons tout simplement pas réussi à suivre les instructions et à installer Torch. Le premier obstacle a été l'utilisation de machines virtuelles. Sur Ubuntu 16 virtuel, le stick ne décolle pas - oubliez-le. StackOverflow venait souvent à la rescousse, mais certaines erreurs étaient si simples que la réponse ne pouvait être trouvée qu'avec beaucoup de difficultés.
L'installation de Torch sur une machine locale a bloqué le projet pendant quelques semaines: nous avons rencontré toutes sortes d'erreurs lors de l'installation de nombreux packages requis, nous avons également eu des problèmes avec la virtualisation (virtualenv .env) et nous ne l'avons finalement pas utilisé. Plusieurs fois le stand a été démoli au niveau de sudo rm -rf et a été simplement réinstallé.
En utilisant le fichier résultant avec des poids, nous avons pu commencer à générer des textes sur notre machine locale:
 Une des premières conclusions
Une des premières conclusionsPartie 5. Effacement des textes
Une autre difficulté évidente était que le sujet des articles est très différent, et notre algorithme n'implique aucune division et considère les 500 000 lignes comme un seul texte. Nous avons envisagé différentes options pour regrouper l'ensemble de données et étions même prêts à décomposer manuellement le corps des textes par sujet ou à placer des balises dans plusieurs milliers de buhurts (il y avait une ressource humaine nécessaire pour cela), mais nous avons constamment rencontré des difficultés techniques pour soumettre des clusters lors de l'apprentissage du LSTM. Changer l'algorithme et refaire le concours ne semble pas être l'idée la plus sensée en termes de timing du projet et de motivation des participants.
Il semblait que nous étions dans une impasse - nous ne pouvions pas regrouper les buhurts, et la formation sur un seul ensemble de données énorme a donné des résultats douteux. Je ne voulais pas prendre du recul et changer l'algorithme et l'implémentation presque en flèche - le projet pourrait simplement tomber dans le coma. L'équipe n'avait désespérément pas suffisamment de connaissances pour résoudre la situation normalement, mais le bon vieux SME-KAL-OCHK-A est venu à la rescousse. La solution finale à la
béquille s'est avérée être géniale: dans le jeu de données d'origine, séparez les buhurts existants les uns des autres avec des lignes vides et entraînez à nouveau le LSTM.
Nous avons organisé les battements dans 10 espaces verticaux après chaque buhurt, répété la formation et pendant la génération, nous avons fixé une limite au volume de sortie de 500 caractères (la longueur moyenne d'un buhurt «plot» dans l'ensemble de données d'origine).
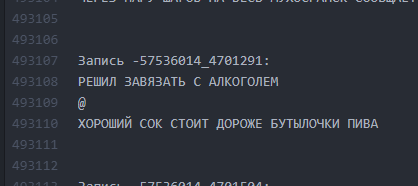 Comme c'était. Les intervalles entre les textes sont minimes.
Comme c'était. Les intervalles entre les textes sont minimes.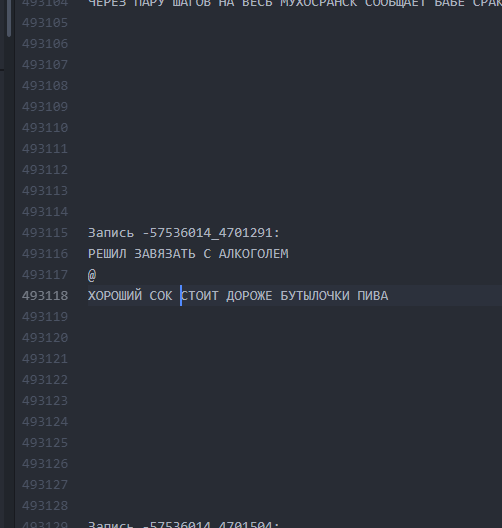 Comment est-ce devenu? Des intervalles de 10 lignes permettent au LSTM de «comprendre» qu'un bogurt est terminé et qu'un autre a commencé.
Comment est-ce devenu? Des intervalles de 10 lignes permettent au LSTM de «comprendre» qu'un bogurt est terminé et qu'un autre a commencé.Ainsi, il a été possible de réaliser qu'environ 60% de tous les buhurts générés commençaient à avoir un tracé lisible (bien que souvent très délirant) sur toute la longueur du buhurt du début à la fin. La longueur d'une parcelle était en moyenne de 9 à 13 lignes.
Partie 6. Recyclage
Après avoir estimé l'économie du projet, nous avons décidé de ne plus dépenser d'argent pour la location d'un cluster, mais d'investir dans l'achat de nos propres cartes. Le temps d'apprentissage augmenterait, mais après avoir acheté une carte une fois, nous pourrions générer constamment de nouveaux buhurts. Dans le même temps, il n'était souvent plus nécessaire de dispenser une formation.
 Paramètres de combat sur la machine locale
Paramètres de combat sur la machine localePartie 7. Équilibrer les résultats
Au tournant de mars-avril 2017, nous avons re-formé le réseau neuronal, en précisant les paramètres de température et le nombre d'époques d'entraînement. En conséquence, la qualité de la sortie a légèrement augmenté.
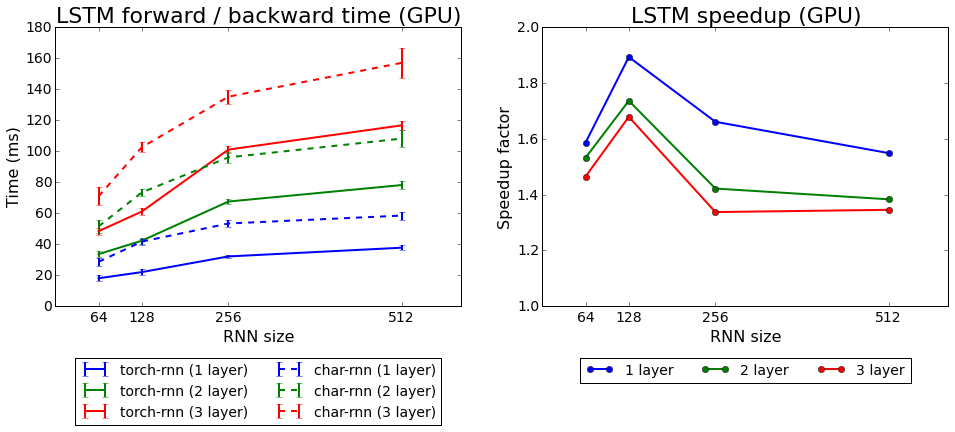 Vitesse d'apprentissage torch-rnn par rapport à char-rnn
Vitesse d'apprentissage torch-rnn par rapport à char-rnnNous avons testé les deux algorithmes fournis avec Torch: rnn et LSTM. La seconde s'est avérée meilleure.
Partie 8. Qu'avons-nous réalisé?
Le premier neurobugurt a été publié le 17 janvier 2017 - immédiatement après la formation sur le cluster - et le premier jour, plus de 1000 commentaires ont été collectés.
 L'un des premiers neurobugurts
L'un des premiers neurobugurtsLes neurobugurts ont si bien atteint le public qu'ils sont devenus une section distincte, qui tout au long de l'année est sortie sous le hashtag # neurobugurt et a amusé les abonnés. Au total, en 2017 et début 2018, nous avons généré plus de
18000 neurobugurts , avec une moyenne de 500 caractères chacun. De plus, tout un mouvement de parodies publiques est apparu, dont les participants ont dépeint des neurobugurs, réarrangeant au hasard des phrases par endroits.

Partie 9. Au lieu d'une conclusion
Avec cet article, je voulais montrer que même si vous n'avez pas d'expérience dans les réseaux de neurones, ce chagrin n'est pas un problème. Vous n'avez pas besoin de travailler à Stanford pour faire des choses simples mais intéressantes avec les réseaux de neurones. Tous les participants à notre projet étaient des étudiants ordinaires avec leurs tâches actuelles, leurs diplômes, leurs travaux, mais la cause commune nous a permis de mener le projet à son terme. Grâce à l'idée réfléchie, à la planification et à l'énergie des participants, nous avons pu obtenir les premiers résultats sensés en moins d'un mois après la formulation finale de l'idée (la plupart des travaux techniques et organisationnels sont tombés sur les vacances d'hiver 2017).
 Plus de 18 000 buhurts générés par machine
Plus de 18 000 buhurts générés par machineJ'espère que cet article aide quelqu'un à planifier son propre projet ambitieux avec des réseaux de neurones. Je demande de ne pas juger strictement car c'est mon premier article sur Habré. Si vous, comme moi, un passionné de ML, soyons
amis .