Il y a quelque temps, un de mes collègues a déclaré que la place dans le DC s'épuisait, qu'il n'y avait nulle part où placer le serveur, que la charge augmentait et que la marche à suivre n'était pas claire, et vous devrez probablement changer tous les serveurs disponibles en serveurs plus puissants.
À cette époque, j'étais engagé dans la tâche de compiler des plannings optimaux, et je me suis dit - mais que faire si nous appliquons des algorithmes d'optimisation pour augmenter l'utilisation du serveur dans le DC? De là est né le projet dont je veux écrire.
Pour les utilisateurs avancés, je dirai tout de suite que dans cet article, nous parlerons de l'emballage de la corbeille, et pour les autres qui veulent apprendre à économiser jusqu'à 30% des ressources du serveur à l'aide de calculs relativement simples, bienvenue à cat.
Nous avons donc un contrôleur de domaine avec environ 100 serveurs, qui hébergent environ 7 000 machines virtuelles. Ce qui est à l'intérieur des machines virtuelles - nous ne savons pas et ne devons pas savoir. Il est nécessaire de placer des machines virtuelles sur des serveurs de manière à effectuer le SLA et en même temps utiliser le nombre minimum de serveurs.
Nous savons:
- liste de serveurs
- quantité de ressources sur chaque serveur (temps CPU, cœurs CPU, RAM, disque, io disque, io réseau).
- liste des machines virtuelles (VM)
- la quantité de ressources consommées par chaque machine virtuelle (temps CPU, cœurs CPU, RAM, disque, io disque, io réseau).
- consommation de ressources par le système hôte sur les serveurs.
Nous devons répartir les machines virtuelles entre les serveurs afin que pour chacune des ressources sur chaque serveur ne dépasse pas la quantité disponible de la ressource, et en même temps utiliser le nombre minimum de serveurs.
Cette tâche dans la littérature scientifique est appelée problème d'emballage de bacs (comment sera-t-elle en russe?). En termes simples, il s'agit d'une tâche sur la façon de pousser de petites boîtes de tailles arbitraires dans de grandes boîtes, et en même temps d'utiliser le nombre minimum de grandes boîtes. Le problème bien connu en mathématiques, NP-complete, n'est précisément résolu que par une recherche exhaustive, dont le coût croît de manière combinatoire.
L'image ci-dessous illustre l'essence de l'algorithme d'emballage de casier pour le cas unidimensionnel:
 Fig. 1. Illustration d'un problème d'emballage de bac, placement non optimal
Fig. 1. Illustration d'un problème d'emballage de bac, placement non optimalDans la première figure, les articles sont en quelque sorte répartis entre les paniers et 3 paniers sont utilisés pour les placer.
 Fig. 2. Illustration d'un problème d'emballage de bacs, placement optimal
Fig. 2. Illustration d'un problème d'emballage de bacs, placement optimalLa deuxième image montre la distribution optimale, pour laquelle vous n'avez besoin que de 2 paniers.
La formulation standard de l'algorithme d'emballage de bacs suppose également que tous les paniers sont identiques. Nos serveurs ne sont pas les mêmes, car ils ont été achetés à des moments différents et leur configuration est différente - nombre différent de cœurs de processeur, mémoire, disque, puissance de processeur différente.
Une solution sous-optimale peut être obtenue en utilisant l'heuristique, les algorithmes génétiques, la recherche d'arbres de monte-carlo et les réseaux de neurones profonds. Nous avons opté pour l'algorithme heuristique BestFit, qui converge vers une solution pas plus de 1,7 fois pire que l'optimale, ainsi que sur une certaine variation de l'algorithme génétique. Ci-dessous, je donnerai les résultats de leur application.
Mais d'abord, discutons de ce qu'il faut faire avec des mesures variant dans le temps, telles que l'utilisation du processeur, le disque io, le réseau io. Le moyen le plus simple consiste à remplacer la métrique variable par une constante. Mais comment choisir la valeur de cette constante? Nous avons pris la valeur maximale de la métrique pour une période caractéristique (auparavant le lissage des valeurs aberrantes). La semaine s'est avérée être une période caractéristique dans notre cas, car la saisonnalité principale de la charge était associée aux jours de travail et aux jours de repos.
Dans ce modèle, chaque machine virtuelle se voit allouer une bande de ressources de la taille de la valeur de ressource consommée maximale, et chaque machine virtuelle est décrite par les constantes utilisation maximale du processeur, RAM, disque, disque max io, réseau max io.
Ensuite, nous utilisons l'algorithme pour calculer l'emballage optimal et obtenir une carte de l'emplacement de la VM sur les serveurs physiques.
La pratique montre que si vous ne laissez pas une certaine marge pour chacune des ressources sur le serveur, alors lorsque la machine virtuelle est allouée de manière dense, le serveur devient surchargé. Par conséquent, pour l'utilisation du processeur, nous laissons une marge de 30%, pour la RAM 20%, pour le disque io - 20%, pour le réseau io - 20%, ces limites sont sélectionnées empiriquement.
Nous avons également plusieurs types de disques (SSD rapides et disques durs bon marché lents), pour chaque type de disque, nous prenons séparément les mesures disque et disque io, de sorte que le modèle final devient un peu plus compliqué et a plus de dimensions.
Le résultat de l'optimisation du placement des machines virtuelles est illustré dans le diagramme:
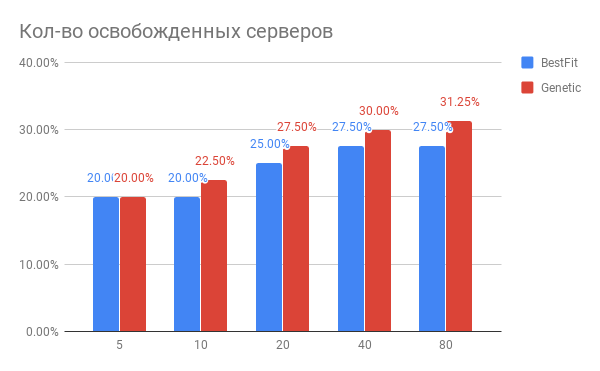 Fig. 3. Le résultat de l'optimisation du placement de VM sur les serveurs
Fig. 3. Le résultat de l'optimisation du placement de VM sur les serveursHorizontal - le nombre de serveurs qui ont été optimisés, vertical - le nombre de serveurs libérés pour l'heuristique BestFit et pour l'algorithme génétique.
Quelles conclusions peut-on tirer du diagramme?
- Pour les tâches en cours, vous pouvez utiliser 20 à 30% de serveurs en moins.
- Plus vous optimisez de serveurs à la fois, plus vous gagnez en%, avec le nombre de serveurs 40 et plus, la saturation se produit.
- L'algorithme génétique est légèrement supérieur à l'heuristique BestFit. Si nous voulons améliorer encore nos résultats, nous allons creuser dans cette direction.
Quels autres problèmes sont apparus dans la pratique?
- Si vous souhaitez secouer une centaine de serveurs avec 7 000 machines virtuelles, le volume des migrations sera très important, de sorte que l'idée ne sera pas réalisable. Mais si vous travaillez avec des groupes de 20 à 40 serveurs en séquence, l'effet que vous obtiendrez sera presque le même, mais le nombre de migrations sera beaucoup moins élevé. Et vous pouvez optimiser votre DC en plusieurs parties.
- Si vous devez effectuer des migrations en direct, vous pouvez rencontrer une situation où la migration ne peut pas se terminer. Cela signifie qu'à l'intérieur de la machine virtuelle, il y a une écriture intensive sur le disque et / ou l'état des changements de mémoire, et les états de la machine virtuelle entre l'ancienne et la nouvelle réplique n'ont pas le temps de se synchroniser jusqu'à ce que l'état de l'ancienne réplique change. Dans ce cas, vous devez prédéfinir ces machines virtuelles et les marquer comme non mobiles. À son tour, cela nécessite la modification des algorithmes d'optimisation. Ce qui est agréable, c'est que le gain total est pratiquement indépendant du nombre de ces machines, s'il n'y a pas plus de 10 à 15% du nombre total de VM.
Comment la charge du serveur change-t-elle après l'optimisation du placement des VM?
Ok, nous avons optimisé le placement des VM. Peut-être que le nouvel état qui en résulte est très fragile par rapport à l'augmentation de charge? Peut-être que les serveurs fonctionnent à la limite et toute augmentation de la charge les tuera?
Nous avons comparé l'utilisation des ressources du serveur avant l'optimisation et après une période d'une semaine. Ce qui s'est passé est illustré à la figure 2:
 Fig. 4. Modification de la charge CPU après optimisation de l'allocation des VM
Fig. 4. Modification de la charge CPU après optimisation de l'allocation des VMSelon l'utilisation du processeur: l'utilisation moyenne du processeur est passée de 10% à seulement 18%. C'est-à-dire nous avons une triple marge de performance CPU, tandis que les serveurs resteront dans la zone dite "verte".
Comment cela a-t-il été fait dans le logiciel?
Nous collectons les mesures dont nous avons besoin dans Yandex.ClickHouse (nous avons essayé InfluxDB, mais sur nos volumes de données, les requêtes avec agrégation sont effectuées trop lentement) avec une fréquence de 30 secondes. À partir de là, la tâche de calcul de l'état optimal lit les métriques, calcule leur consommation maximale et génère une tâche de calcul qui est placée dans la file d'attente. Dès que la tâche de calcul est terminée, des tests sont exécutés pour vérifier que le résultat ne dépasse pas les limites spécifiées.
Quelqu'un a-t-il déjà fait cela?
D'après ce que nous savons, des algorithmes similaires se trouvent dans VMware vSphere et Nutanix et apparaissent dans OpenStack (projet OpenStack Watcher).
Est-il possible de faire encore mieux?
Oui tu peux. Dans le prochain article, je vous dirai comment emballer des machines virtuelles encore plus denses sans violer le SLA, et pourquoi des neurones sont nécessaires pour cela.