
Dans le domaine de la reconnaissance des émotions, la voix est la deuxième source de données émotionnelles après le visage. La voix peut être caractérisée par plusieurs paramètres. La hauteur de la voix est l'une des principales caractéristiques de ce type, cependant, dans le domaine de la technologie acoustique, il est plus correct d'appeler ce paramètre la fréquence fondamentale.
La fréquence du ton fondamental est directement liée à ce que nous appelons l'intonation. Et l'intonation, par exemple, est associée aux caractéristiques émotionnellement expressives de la voix.
Néanmoins, la détermination de la fréquence du ton fondamental n'est pas une tâche complètement triviale avec des nuances intéressantes. Dans cet article, nous discuterons des caractéristiques des algorithmes pour sa détermination et comparerons les solutions existantes avec des exemples d'enregistrements audio spécifiques.
PrésentationPour commencer, rappelons quelle est, en substance, la fréquence du ton fondamental et dans quelles tâches il peut être nécessaire.
La fréquence fondamentale , également appelée CHOT, Fundamental Frequency ou F0, est la fréquence des cordes vocales lorsqu'elles prononcent des sons vocaux. Lors de la prononciation de sons non tonaux (non vocaux), par exemple, en parlant à voix basse ou en émettant des sifflements et des sifflements, les ligaments n'hésitent pas, ce qui signifie que cette caractéristique n'est pas pertinente pour eux.
* Veuillez noter que la division en sons tonaux et non sonores n'est pas équivalente à la division en voyelles et consonnes.
La variabilité de la fréquence du ton fondamental est assez grande, et elle peut varier considérablement non seulement entre les personnes (pour les voix masculines moyennes inférieures, la fréquence est de 70-200 Hz, et pour les voix féminines, elle peut atteindre 400 Hz), mais aussi pour une personne, en particulier dans le discours émotionnel .
La détermination de la fréquence du ton fondamental est utilisée pour résoudre un large éventail de problèmes:
- Reconnaissance des émotions, comme nous l'avons dit plus haut;
- Détermination du sexe;
- Lorsque vous résolvez le problème de la segmentation audio à plusieurs voix ou de la division du discours en phrases;
- En médecine, pour déterminer les caractéristiques pathologiques de la voix (par exemple, en utilisant les paramètres acoustiques Jitter et Shimmer). Par exemple, l'identification des signes de la maladie de Parkinson [ 1 ]. Jitter et Shimmer peuvent également être utilisés pour reconnaître les émotions [ 2 ].
Cependant, il existe un certain nombre de difficultés pour déterminer F0. Par exemple, il est souvent possible de confondre F0 avec les harmoniques, ce qui peut conduire à ce que l'on appelle les effets de doublage de hauteur / réduction de hauteur [
3 ]. Et dans les enregistrements audio de mauvaise qualité, F0 est assez difficile à calculer, car le pic souhaité aux basses fréquences disparaît presque.
Au fait, tu
te souviens de l'histoire de
Laurel et Yanny ? Les différences dans les mots que les gens entendent en écoutant le même enregistrement audio sont dues précisément à la différence de perception F0, qui est influencée par de nombreux facteurs: l'âge de l'auditeur, le degré de fatigue et l'appareil de lecture. Ainsi, lorsque vous écoutez des enregistrements dans des haut-parleurs avec une reproduction de haute qualité des basses fréquences, vous entendrez Laurel, et dans les systèmes audio où les basses fréquences sont mal reproduites, Yanny. L'effet de transition est visible sur un seul appareil, par exemple
ici . Et dans cet
article , le réseau neuronal agit comme un auditeur. Dans un autre
article, vous pouvez lire comment le phénomène Yanny / Laurel est expliqué en termes de formation de la parole.
Étant donné qu'une analyse détaillée de toutes les méthodes de détermination de F0 serait trop volumineuse, l'article est de nature générale et peut aider à naviguer dans le sujet.
Méthodes de détermination de F0Les méthodes de détermination de F0 peuvent être divisées en trois catégories: en fonction de la dynamique temporelle du signal ou du domaine temporel; basé sur la structure de fréquence, ou domaine de fréquence, ainsi que des méthodes combinées. Nous vous suggérons de vous familiariser avec l'
article de synthèse sur le sujet, où les méthodes indiquées pour extraire F0 sont analysées en détail.
Notez que l'un des algorithmes discutés comprend 3 étapes principales:
Prétraitement (filtrage du signal, division en images)
Recherche des valeurs possibles de F0 (candidats)
Le suivi est le choix de la trajectoire la plus probable F0 (puisque pour chaque moment dans le temps nous avons plusieurs candidats en compétition, nous devons trouver la piste la plus probable parmi eux)
Domaine temporelNous soulignons quelques points généraux. Avant d'appliquer les méthodes du domaine temporel, le signal est pré-filtré, ne laissant que les basses fréquences. Des seuils sont définis - les fréquences minimale et maximale, par exemple de 75 à 500 Hz. La détermination de F0 est faite uniquement pour les zones avec parole harmonique, car pour les pauses ou les bruits, cela n'a pas seulement de sens, mais peut également introduire des erreurs dans les trames adjacentes lors de l'interpolation et / ou du lissage. La longueur de trame est sélectionnée de manière à contenir au moins trois périodes.
La principale méthode, sur la base de laquelle toute une famille d'algorithmes est apparue par la suite, est l'autocorrélation. L'approche est assez simple - il faut calculer la fonction d'autocorrélation et prendre son premier maximum. Il affichera la composante de fréquence la plus prononcée du signal. Quelle pourrait être la difficulté dans le cas de l'autocorrélation et pourquoi est-il loin d'être toujours que le premier maximum correspondra à la fréquence souhaitée? Même dans des conditions proches des conditions idéales sur des enregistrements de haute qualité, la méthode peut être erronée en raison de la structure complexe du signal. Dans des conditions proches du réel, où, entre autres, on peut rencontrer la disparition du pic souhaité dans des enregistrements bruyants ou des enregistrements de qualité initialement faible, le nombre d'erreurs augmente fortement.
Malgré les erreurs, la méthode d'autocorrélation est assez pratique et attrayante en raison de sa simplicité de base et de sa logique, c'est pourquoi elle est utilisée comme base dans de nombreux algorithmes, y compris YIN. Même le nom de l'algorithme nous renvoie à un équilibre entre la commodité et l'inexactitude de la méthode d'autocorrélation: «Le nom YIN de '' yin '' et '' yang '' de la philosophie orientale fait référence à l'interaction entre l'autocorrélation et l'annulation qu'il implique.» [
4 ]
Les créateurs de YIN ont tenté de corriger les faiblesses de l'approche d'autocorrélation. Le premier changement est l'utilisation de la fonction de différence moyenne normalisée cumulée, qui devrait réduire la sensibilité aux modulations d'amplitude, rendre les pics plus prononcés:
\ commencer {équation}
d'_t (\ tau) =
\ begin {cases}
1, & \ tau = 0 \\
d_t (\ tau) \ bigg / \ bigg [\ frac {1} {\ tau} \ sum \ limits_ {j = 1} ^ {\ tau} d_t (j) \ bigg], & \ text {sinon}
\ end {cases}
\ end {équation}
YIN essaie également d'éviter les erreurs qui se produisent dans les cas où la longueur de la fonction de fenêtre n'est pas complètement divisée par la période d'oscillation. Pour cela, une interpolation minimale parabolique est utilisée. À la dernière étape du traitement du signal audio, la fonction Best Local Estimate est exécutée pour empêcher les sauts brusques des valeurs (que ce soit bon ou mauvais - c'est un point discutable).
Domaine de fréquenceSi nous parlons du domaine fréquentiel, alors la structure harmonique du signal apparaît, c'est-à-dire la présence de pics spectraux à des fréquences qui sont des multiples de F0. Vous pouvez «réduire» ce schéma périodique en un pic clair en utilisant l'analyse cepstrale. Cepstrum - Transformée de Fourier du logarithme du spectre de puissance; le pic cepstral correspond à la composante la plus périodique du spectre (on peut le lire
ici et
ici ).
Méthodes hybrides pour déterminer F0Le prochain algorithme, qui mérite d'être exploré plus en détail, porte le nom parlant YAAPT - Yet Another Algorithm of Pitch Tracking - et est en fait hybride, car il utilise à la fois des informations de fréquence et de temps. Une description complète se trouve dans l'
article , nous ne décrivons ici que les principales étapes.
 Figure 1. Diagramme de l'algorithme YAAPTalgo ( lien )
Figure 1. Diagramme de l'algorithme YAAPTalgo ( lien ) .
YAAPT comprend plusieurs étapes principales, dont la première est le prétraitement. À ce stade, les valeurs du signal d'origine sont mises au carré et une deuxième version du signal est obtenue. Cette étape poursuit le même objectif que la fonction de différence moyenne normalisée cumulative dans YIN - amplification et restauration des pics «bloqués» d'autocorrélation. Les deux versions du signal sont filtrées - elles prennent généralement la plage de 50 à 1500 Hz, parfois de 50 à 900 Hz.
Ensuite, la trajectoire de base F0 est calculée à partir du spectre du signal converti. Les candidats pour F0 sont déterminés à l'aide de la fonction de corrélation des harmoniques spectrales (SHC).
\ commencer {équation}
SHC (t, f) = \ sum \ limits_ {f '= - WL / 2} ^ {WL / 2} \ prod \ limits_ {r = 1} ^ {NH + 1} S (t, rf + f')
\ end {équation}
où S (t, f) est le spectre d'amplitude pour la trame t et la fréquence f, WL est la longueur de la fenêtre en Hz, NH est le nombre d'harmoniques (les auteurs recommandent d'utiliser les trois premières harmoniques). La puissance spectrale est également utilisée pour déterminer les trames voisées-non voisées, après quoi la trajectoire la plus optimale est recherchée, et la possibilité de doublage / réduction de hauteur est prise en compte [
3 , Section II, C].
En outre, les candidats pour F0 sont déterminés à la fois pour le signal initial et le signal converti, et au lieu de la fonction d'autocorrélation, la corrélation croisée normalisée (NCCF) est utilisée ici.
\ commencer {équation}
NCCF (m) = \ frac {\ sum \ limits_ {n = 0} ^ {Nm-1} x (n) * x (n + m)} {\ sqrt {\ sum \ limits_ {n = 0} ^ {{ Nm-1} x ^ 2 (n) * \ sum \ limits_ {n = 0} ^ {Nm-1} x ^ 2 (n + m)}} \ text {,} \ hspace {0,3 cm} 0 <m <M_ {0}
\ end {équation}
L'étape suivante consiste à évaluer tous les candidats possibles et à calculer leur importance ou leur poids (mérite). Le poids des candidats obtenus à partir du signal audio dépend non seulement de l'amplitude du pic NCCF, mais également de leur proximité avec la trajectoire F0 déterminée à partir du spectre. Autrement dit, le domaine fréquentiel est considéré comme grossier en termes de précision, mais stable [
3 , Section II, D].
Ensuite, pour toutes les paires des candidats restants, la matrice des coûts de transition est calculée - le prix de transition, auquel ils trouvent finalement la trajectoire optimale [
3 , Section II, E].
Des exemplesMaintenant, nous appliquons tous les algorithmes ci-dessus à des enregistrements audio spécifiques. Comme point de départ, nous utiliserons
Praat , un outil fondamental pour de nombreux spécialistes de la parole. Et puis en Python, nous examinerons l'implémentation de YIN et YAAPT et nous comparerons les résultats reçus.
En tant que matériel audio, vous pouvez utiliser n'importe quel audio disponible. Nous avons pris plusieurs extraits de notre base de données
RAMAS - un
ensemble de données multimodal créé avec la participation d'acteurs VGIK. Vous pouvez également utiliser du matériel provenant d'autres bases de données ouvertes, telles que
LibriSpeech ou
RAVDESS .
Pour un exemple illustratif, nous avons pris des extraits de plusieurs enregistrements avec des voix masculines et féminines, à la fois neutres et émotionnellement colorées, et pour plus de clarté, nous les avons combinés en un seul
enregistrement . Regardons notre signal, son spectrogramme, son intensité (couleur orange) et F0 (couleur bleue). Dans Praat, cela peut être fait en utilisant Ctrl + O (Ouvrir - Lire à partir du fichier) puis le bouton Afficher et modifier.
 Figure 2. Spectrogramme, intensité (couleur orange), F0 (couleur bleue) à Praat.
Figure 2. Spectrogramme, intensité (couleur orange), F0 (couleur bleue) à Praat.L'audio montre assez clairement que dans le discours émotionnel, la hauteur augmente chez les hommes et les femmes. Dans le même temps, F0 pour la parole masculine émotionnelle peut être comparé à F0 d'une voix féminine.
SuiviSélectionnez l'onglet Analyze periodicity - to Pitch (ac) dans le menu Praat, c'est-à-dire la définition de F0 en utilisant l'autocorrélation. Une fenêtre de définition des paramètres apparaîtra dans laquelle il est possible de définir 3 paramètres pour déterminer les candidats pour F0 et 6 autres paramètres pour l'algorithme de recherche de chemin, qui construit le chemin F0 le plus probable parmi tous les candidats.
De nombreux paramètres (dans Praat, leur description est également sur le bouton Aide)- Seuil de silence - le seuil de l'amplitude relative du signal pour déterminer le silence, la valeur standard est 0,03.
- Seuil de voisement - le poids du candidat non voisé, la valeur maximale est 1. Plus ce paramètre est élevé, plus les images seront définies comme non voisées, c'est-à-dire ne contenant pas de sons de tonalité. Dans ces trames, F0 ne sera pas déterminé. La valeur de ce paramètre est le seuil des pics de la fonction d'autocorrélation. La valeur par défaut est 0,45.
- Coût en octave - détermine combien plus de poids les candidats haute fréquence ont par rapport à ceux basse fréquence. Plus la valeur est élevée, plus la préférence est donnée au candidat haute fréquence. La valeur par défaut est 0,01 par octave.
- Coût du saut d'octave - avec une augmentation de ce coefficient, le nombre de transitions brusques de type saut entre les valeurs successives de F0 diminue. La valeur par défaut est 0,35.
- Coût voisé / non facturé - l'augmentation de ce coefficient diminue le nombre de transitions voisées / non voisées. La valeur par défaut est 0,14.
- Plafond du pitch (Hz) - les candidats au-dessus de cette fréquence ne sont pas pris en compte. La valeur par défaut est 600 Hz.
Une description détaillée de l'algorithme peut être trouvée dans
un article de 1993.
A quoi ressemble le résultat du tracker (path-finder) peut être vu en cliquant sur OK puis en affichant (View & Edit) le fichier Pitch résultant. On peut voir qu'en plus de la trajectoire choisie, il y avait encore des candidats assez importants avec une fréquence inférieure.
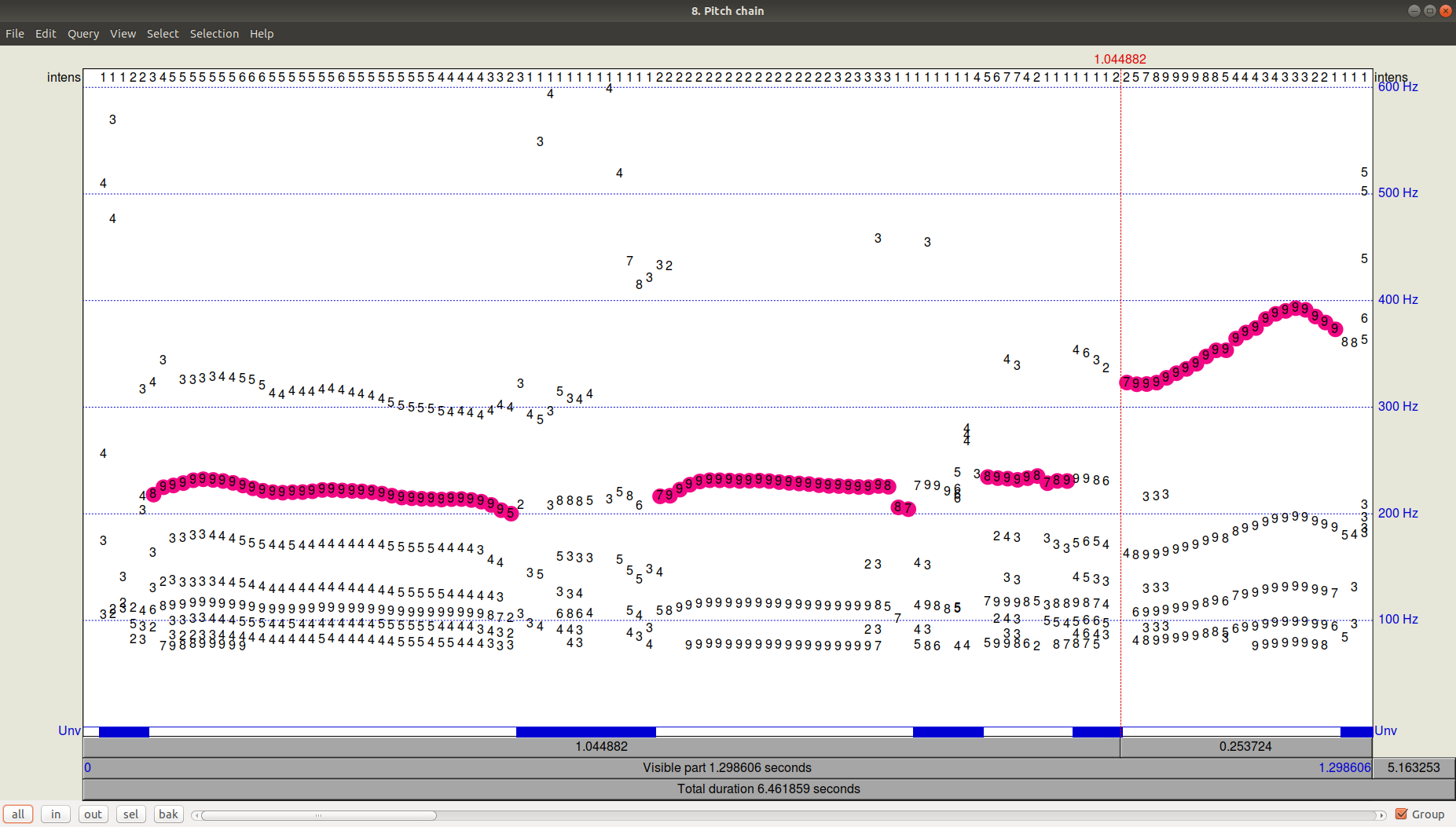 Figure 3. PitchPath pour les 1,3 premières secondes d'enregistrement audio.Mais qu'en est-il de Python?
Figure 3. PitchPath pour les 1,3 premières secondes d'enregistrement audio.Mais qu'en est-il de Python?Prenons deux bibliothèques offrant le suivi de hauteur -
aubio , dans lequel l'algorithme par défaut est YIN, et la bibliothèque
AMFM_decompsition , qui a une implémentation de l'algorithme YAAPT. Dans le fichier séparé (fichier
PraatPitch.txt ),
insérez les valeurs F0 de Praat (cela peut être fait manuellement: sélectionnez le fichier son, cliquez sur View & Edit, sélectionnez le fichier entier et sélectionnez la liste Pitch-Pitch dans le menu supérieur).
Comparez maintenant les résultats pour les trois algorithmes (YIN, YAAPT, Praat).
Beaucoup de codeimport amfm_decompy.basic_tools as basic import amfm_decompy.pYAAPT as pYAAPT import matplotlib.pyplot as plt import numpy as np import sys from aubio import source, pitch
 Figure 4. Comparaison du fonctionnement des algorithmes YIN, YAAPT et Praat.
Figure 4. Comparaison du fonctionnement des algorithmes YIN, YAAPT et Praat.Nous voyons qu'avec les paramètres par défaut, YIN est assez éliminé, obtenant une trajectoire très plate avec des valeurs inférieures à Praat et perdant complètement les transitions entre les voix masculines et féminines, ainsi qu'entre la parole émotionnelle et non émotionnelle.
YAAPT a réduit un ton très élevé dans le discours émotionnel des femmes, mais dans l'ensemble, il a nettement mieux réussi. En raison de ses caractéristiques spécifiques, YAAPT fonctionne mieux - il est impossible de répondre tout de suite, bien sûr, mais on peut supposer que le rôle est joué en obtenant des candidats de trois sources et un calcul plus méticuleux de leur poids que dans YIN.
ConclusionPuisque la question de déterminer la fréquence du ton fondamental (F0) sous une forme ou une autre se pose avant presque tous ceux qui travaillent avec le son, il existe de nombreuses façons de le résoudre. La question de la précision et des caractéristiques nécessaires du matériel audio dans chaque cas détermine la précision avec laquelle il est nécessaire de sélectionner les paramètres, ou dans un autre cas, vous pouvez vous limiter à une solution de base comme YAAPT. En prenant Praat comme algorithme standard pour le traitement de la parole (néanmoins, un grand nombre de chercheurs l'utilisent), nous pouvons conclure que YAAPT est, à première vue, plus fiable et précis que YIN, bien que notre exemple se soit révélé compliqué pour lui.
Publié par
Eva Kazimirova , chercheuse au laboratoire de neurodonnées, spécialiste du traitement de la parole.
Offtop : Aimez-vous l'article? En fait, nous avons un tas de tâches intéressantes en ML, en mathématiques et en programmation, et nous avons besoin de cerveaux. Êtes-vous curieux? Venez chez nous! Courriel: hr@neurodatalab.com
Les références- Rusz, J., Cmejla, R., Ruzickova, H., Ruzicka, E. Mesures acoustiques quantitatives pour la caractérisation des troubles de la parole et de la voix dans la maladie de Parkinson précoce non traitée. Le Journal de l'Acoustical Society of America, vol. 129, numéro 1 (2011), pp. 350-367. Accès
- Farrús, M., Hernando, J., Ejarque, P. Jitter and Shimmer Measurements for Speaker Recognition. Actes de la conférence annuelle de l'International Speech Communication Association, INTERSPEECH, vol. 2 (2007), pp. 1153-1156. Accès
- Zahorian, S., Hu, HA. Méthode spectrale / temporelle pour un suivi robuste des fréquences fondamentales. Le Journal de l'Acoustical Society of America, vol. 123, numéro 6 (2008), pp. 4559-4571. Accès
- De Cheveigné, A., Kawahara, H. YIN, un estimateur de fréquence fondamental pour la parole et la musique. Le Journal de l'Acoustical Society of America, vol. 111, numéro 4 (2002), pp. 1917-1930. Accès