
Les «modèles» dans le contexte de C ++ se réfèrent généralement à des constructions de langage très spécifiques. Il existe des modèles simples qui simplifient le travail avec le même type de code - ce sont des modèles de classe et de fonction. Si un modèle possède l'un des paramètres par lui-même, il peut s'agir de modèles de second ordre et ils génèrent d'autres modèles en fonction de leurs paramètres. Mais que faire si leurs capacités ne sont pas suffisantes et plus faciles pour générer immédiatement le texte source? Beaucoup de code source?
Les fans de Python et de mises en page HTML connaissent un outil (moteur, bibliothèque) pour travailler avec des modèles de texte appelé
Jinja2 . À l'entrée, ce moteur reçoit un fichier modèle dans lequel le texte peut être mélangé avec des structures de contrôle, la sortie est un texte clair dans lequel toutes les structures de contrôle sont remplacées par du texte conformément aux paramètres spécifiés de l'extérieur (ou de l'intérieur). En gros, c'est quelque chose comme des pages ASP (ou C ++ - préprocesseur), seul le langage de balisage est différent.
Jusqu'à présent, l'implémentation de ce moteur était uniquement pour Python. Maintenant c'est pour C ++. Comment et pourquoi cela s'est produit, et sera discuté dans l'article.
Pourquoi ai-je même repris ça
En effet, pourquoi? Après tout, il y a Python, pour cela - une excellente implémentation, un tas de fonctionnalités, une spécification complète pour le langage. Prenez et utilisez! Je n'aime pas Python - vous pouvez prendre
Jinja2CppLight ou
inja , des ports partiels Jinja2 en C ++. Vous pouvez, à la fin, prendre le port C ++ {{
Moustache }}. Le diable, comme d'habitude, dans les détails. Donc, disons, j'avais besoin de la fonctionnalité des filtres de Jinja2 et des capacités de la construction extend, qui vous permet de créer des modèles extensibles (et aussi des macros et include, mais plus tard). Et aucune des implémentations mentionnées ne prend en charge cela. Puis-je m'en passer? Aussi une bonne question. Jugez par vous-même. J'ai un
projet dont le but est de créer un générateur de code passe-partout C ++ - to-C ++. Cet autogénérateur reçoit, disons, un fichier d'en-tête écrit manuellement avec des structures ou des énumérations, et génère en fonction de lui des fonctions de sérialisation / désérialisation ou, par exemple, de conversion d'éléments d'énumération en chaînes (et vice versa). Vous pouvez écouter plus de détails sur cet utilitaire dans mes rapports
ici (eng) ou
ici (rus).
Ainsi, une tâche typique résolue dans le processus de travail sur l'utilitaire est la création de fichiers d'en-tête, dont chacun a un en-tête (avec ifdefs et inclut), un corps avec le contenu principal et un pied de page. De plus, le contenu principal est les déclarations générées bourrées d'espace de noms. En exécution C ++, le code pour créer un tel fichier d'en-tête ressemble à ceci (et ce n'est pas tout):
Beaucoup de code C ++void Enum2StringGenerator::WriteHeaderContent(CppSourceStream &hdrOs) { std::vector<reflection::EnumInfoPtr> enums; WriteNamespaceContents(hdrOs, m_namespaces.GetRootNamespace(), [this, &enums](CppSourceStream &os, reflection::NamespaceInfoPtr ns) { for (auto& enumInfo : ns->enums) { WriteEnumToStringConversion(os, enumInfo); WriteEnumFromStringConversion(os, enumInfo); enums.push_back(enumInfo); } }); hdrOs << "\n\n"; { out::BracedStreamScope flNs("\nnamespace flex_lib", "\n\n", 0); hdrOs << out::new_line(1) << flNs; for (reflection::EnumInfoPtr enumInfo : enums) { auto scopedParams = MakeScopedParams(hdrOs, enumInfo); { hdrOs << out::new_line(1) << "template<>"; out::BracedStreamScope body("inline const char* Enum2String($enumFullQualifiedName$ e)", "\n"); hdrOs << out::new_line(1) << body; hdrOs << out::new_line(1) << "return $namespaceQual$::$enumName$ToString(e);"; } { hdrOs << out::new_line(1) << "template<>"; out::BracedStreamScope body("inline $enumFullQualifiedName$ String2Enum<$enumFullQualifiedName$>(const char* itemName)", "\n"); hdrOs << out::new_line(1) << body; hdrOs << out::new_line(1) << "return $namespaceQual$::StringTo$enumName$(itemName);"; } } } { out::BracedStreamScope flNs("\nnamespace std", "\n\n", 0); hdrOs << out::new_line(1) << flNs; for (reflection::EnumInfoPtr enumInfo : enums) { auto scopedParams = MakeScopedParams(hdrOs, enumInfo); out::BracedStreamScope body("inline std::string to_string($enumFullQualifiedName$ e)", "\n"); hdrOs << out::new_line(1) << body; hdrOs << out::new_line(1) << "return $namespaceQual$::$enumName$ToString(e);"; } } }
D'ici .
De plus, ce code change peu d'un fichier à l'autre. Bien sûr, vous pouvez utiliser le format clang pour le formatage. Mais cela n'annule pas le reste du travail manuel sur la génération du texte source.
Et puis un beau moment, j'ai réalisé que ma vie devait être simplifiée. Je n'ai pas envisagé l'option de visser un langage de script à part entière en raison de la complexité de la prise en charge du résultat final. Mais pour trouver un moteur de modèle approprié - pourquoi pas? Je l'ai trouvé utile pour rechercher, je l'ai trouvé, puis j'ai trouvé la spécification Jinja2 et j'ai réalisé que c'était exactement ce dont j'avais besoin. Pour, conformément à cette spécification, les modèles de génération d'en-têtes devraient ressembler à ceci:
{% extends "header_skeleton.j2tpl" %} {% block generator_headers %} #include <flex_lib/stringized_enum.h> #include <algorithm> #include <utility> {% endblock %} {% block namespaced_decls %}{{super()}}{% endblock %} {% block namespace_content %} {% for enum in ns.enums | sort(attribute="name") %} {% set enumName = enum.name %} {% set scopeSpec = enum.scopeSpecifier %} {% set scopedName = scopeSpec ~ ('::' if scopeSpec) ~ enumName %} {% set prefix = (scopedName + '::') if not enumInfo.isScoped else (scopedName ~ '::' ~ scopeSpec ~ ('::' if scopeSpec)) %} inline const char* {{enumName}}ToString({{scopedName}} e) { switch (e) { {% for itemName in enum.items | map(attribute="itemName") | sort%} case {{prefix}}{{itemName}}: return "{{itemName}}"; {% endfor %} } return "Unknown Item"; } inline {{scopedName}} StringTo{{enumName}}(const char* itemName) { static std::pair<const char*, {{scopedName}}> items[] = { {% for itemName in enum.items | map(attribute="itemName") | sort %} {"{{itemName}}", {{prefix}}{{itemName}} } {{',' if not loop.last }} {% endfor %} }; {{scopedName}} result; if (!flex_lib::detail::String2Enum(itemName, items, result)) flex_lib::bad_enum_name::Throw(itemName, "{{enumName}}"); return result; } {% endfor %}{% endblock %} {% block global_decls %} {% for ns in [rootNamespace] recursive %} {% for enum in ns.enums %} template<> inline const char* flex_lib::Enum2String({{enum.fullQualifiedName}} e) { return {{enum.namespaceQualifier}}::{{enum.name}}ToString(e); } template<> inline {{enum.fullQualifiedName}} flex_lib::String2Enum<{{enum.fullQualifiedName}}>(const char* itemName) { return {{enum.namespaceQualifier}}::StringTo{{enum.name}}(itemName); } inline std::string to_string({{enum.fullQualifiedName}} e) { return {{enum.namespaceQualifier}}::{{enum.name}}ToString(e); } {% endfor %} {{loop(ns.namespaces)}} {% endfor %} {% endblock %}
D'ici .

Il n'y avait qu'un seul problème: aucun des moteurs que j'ai trouvés ne supportait l'ensemble des fonctionnalités dont j'avais besoin. Eh bien, bien sûr, tout le monde avait une
faille fatale standard. J'ai réfléchi un peu et j'ai décidé qu'un autre monde n'empirerait pas d'une autre implémentation du moteur de modèle. De plus, selon les estimations, la fonctionnalité de base n'était pas tellement difficile à mettre en œuvre. Après tout, maintenant en C ++ il y a des expressions rationnelles!
Et donc le projet
Jinja2Cpp est né . Au détriment de la complexité de la mise en œuvre de la fonctionnalité de base (très basique), j'ai presque deviné. Dans l'ensemble, j'ai raté exactement le coefficient Pi au carré: il m'a fallu un peu moins de trois mois pour écrire tout ce dont j'avais besoin. Mais quand tout a été fini, fini et inséré dans le "Programmeur automatique" - j'ai réalisé que je n'ai pas essayé en vain. En fait, l'utilitaire de génération de code a reçu un langage de script puissant combiné à des modèles, ce qui lui a ouvert de nouvelles opportunités de développement.
NB: J'ai eu une idée pour fixer Python (ou Lua). Mais aucun des moteurs de script à part entière existants ne résout les problèmes «prêts à l'emploi» lors de la génération de texte à partir de modèles. Autrement dit, Python devrait encore visser le même Jinja2, mais pour Lua, recherchez quelque chose de différent. Pourquoi ai-je besoin de ce lien supplémentaire?
Implémentation de l'analyseur
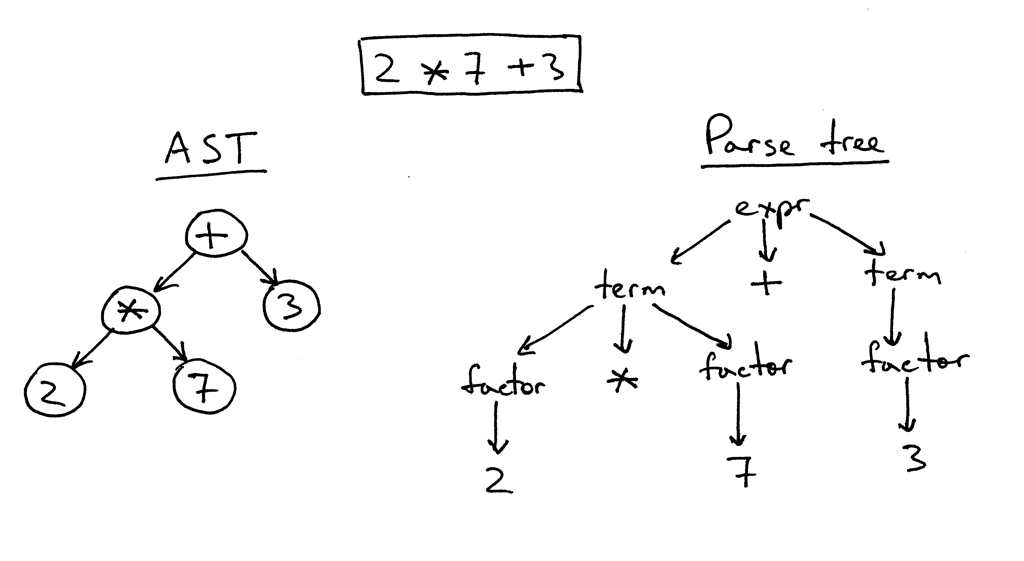
L'idée derrière la structure des modèles Jinja2 est assez simple. S'il y a quelque chose dans le texte inclus dans une paire de "{{" / "}}", alors c'est "quelque chose" - une expression qui doit être évaluée, convertie en une représentation textuelle et insérée dans le résultat final. A l'intérieur de la paire "{%" / "%}" se trouvent des opérateurs tels que, si, set, etc. Après avoir étudié l'implémentation de Jinja2CppLight, j'ai décidé qu'essayer de trouver manuellement toutes ces structures de contrôle dans le texte du modèle n'était pas une très bonne idée. Par conséquent, je me suis armé d'une expression rationnelle assez simple: ((\ \ {\ {) | (\} \}) | (\ {%) | (% \}) | (\ {#) | (# \}) | (\ n. Et l'a appelé la phase approximative de l'analyse. Au stade initial du travail, l'idée a montré son efficacité (oui, en fait, elle montre toujours), mais, dans le bon sens, elle devra être refactorisée à l'avenir, car maintenant des restrictions mineures sont imposées sur le texte du modèle: paires d'échappement "{{" et "}}" dans le texte est également traité "front".
Dans la deuxième phase, seul ce qui se trouve à l'intérieur des «crochets» est analysé en détail. Et ici, je devais bricoler. Avec inja, avec Jinja2CppLight, l'analyseur d'expression est assez simple. Dans le premier cas - sur la même expression rationnelle, dans le second - manuscrite, mais ne supportant que des conceptions très simples. La prise en charge des filtres, des testeurs, de l'arithmétique complexe ou de l'indexation est hors de question. Et c'est précisément ces caractéristiques de Jinja2 que je voulais le plus. Par conséquent, je n'avais pas d'autre choix que de froisser un analyseur LL (1) à part entière (à certains endroits - sensible au contexte) qui implémente la grammaire nécessaire. Il y a environ dix à quinze ans, je prendrais probablement Bison ou ANTLR pour cela et implémenterais un analyseur avec leur aide. Il y a environ sept ans, j'aurais essayé Boost.Spirit. Maintenant, je viens d'implémenter l'analyseur dont j'ai besoin, en utilisant la méthode de descente récursive, sans générer de dépendances inutiles et augmenter considérablement le temps de compilation, comme ce serait le cas si des utilitaires externes ou Boost.Spirit étaient utilisés. À la sortie de l'analyseur, j'obtiens un AST (pour les expressions ou pour les opérateurs), qui est enregistré en tant que modèle, prêt pour le rendu ultérieur.
Un exemple de logique d'analyse ExpressionEvaluatorPtr<FullExpressionEvaluator> ExpressionParser::ParseFullExpression(LexScanner &lexer, bool includeIfPart) { ExpressionEvaluatorPtr<FullExpressionEvaluator> result; LexScanner::StateSaver saver(lexer); ExpressionEvaluatorPtr<FullExpressionEvaluator> evaluator = std::make_shared<FullExpressionEvaluator>(); auto value = ParseLogicalOr(lexer); if (!value) return result; evaluator->SetExpression(value); ExpressionEvaluatorPtr<ExpressionFilter> filter; if (lexer.PeekNextToken() == '|') { lexer.EatToken(); filter = ParseFilterExpression(lexer); if (!filter) return result; evaluator->SetFilter(filter); } ExpressionEvaluatorPtr<IfExpression> ifExpr; if (lexer.PeekNextToken() == Token::If) { if (includeIfPart) { lexer.EatToken(); ifExpr = ParseIfExpression(lexer); if (!ifExpr) return result; evaluator->SetTester(ifExpr); } } saver.Commit(); return evaluator; } ExpressionEvaluatorPtr<Expression> ExpressionParser::ParseLogicalOr(LexScanner& lexer) { auto left = ParseLogicalAnd(lexer); if (!left) return ExpressionEvaluatorPtr<Expression>(); if (lexer.NextToken() != Token::LogicalOr) { lexer.ReturnToken(); return left; } auto right = ParseLogicalOr(lexer); if (!right) return ExpressionEvaluatorPtr<Expression>(); return std::make_shared<BinaryExpression>(BinaryExpression::LogicalOr, left, right); } ExpressionEvaluatorPtr<Expression> ExpressionParser::ParseLogicalAnd(LexScanner& lexer) { auto left = ParseLogicalCompare(lexer); if (!left) return ExpressionEvaluatorPtr<Expression>(); if (lexer.NextToken() != Token::LogicalAnd) { lexer.ReturnToken(); return left; } auto right = ParseLogicalAnd(lexer); if (!right) return ExpressionEvaluatorPtr<Expression>(); return std::make_shared<BinaryExpression>(BinaryExpression::LogicalAnd, left, right); } ExpressionEvaluatorPtr<Expression> ExpressionParser::ParseLogicalCompare(LexScanner& lexer) { auto left = ParseStringConcat(lexer); if (!left) return ExpressionEvaluatorPtr<Expression>(); auto tok = lexer.NextToken(); BinaryExpression::Operation operation; switch (tok.type) { case Token::Equal: operation = BinaryExpression::LogicalEq; break; case Token::NotEqual: operation = BinaryExpression::LogicalNe; break; case '<': operation = BinaryExpression::LogicalLt; break; case '>': operation = BinaryExpression::LogicalGt; break; case Token::GreaterEqual: operation = BinaryExpression::LogicalGe; break; case Token::LessEqual: operation = BinaryExpression::LogicalLe; break; case Token::In: operation = BinaryExpression::In; break; case Token::Is: { Token nextTok = lexer.NextToken(); if (nextTok != Token::Identifier) return ExpressionEvaluatorPtr<Expression>(); std::string name = AsString(nextTok.value); bool valid = true; CallParams params; if (lexer.NextToken() == '(') params = ParseCallParams(lexer, valid); else lexer.ReturnToken(); if (!valid) return ExpressionEvaluatorPtr<Expression>(); return std::make_shared<IsExpression>(left, std::move(name), std::move(params)); } default: lexer.ReturnToken(); return left; } auto right = ParseStringConcat(lexer); if (!right) return ExpressionEvaluatorPtr<Expression>(); return std::make_shared<BinaryExpression>(operation, left, right); }
D'ici .
Fragment de classes d'arbres d'expression AST class ExpressionFilter; class IfExpression; class FullExpressionEvaluator : public ExpressionEvaluatorBase { public: void SetExpression(ExpressionEvaluatorPtr<Expression> expr) { m_expression = expr; } void SetFilter(ExpressionEvaluatorPtr<ExpressionFilter> expr) { m_filter = expr; } void SetTester(ExpressionEvaluatorPtr<IfExpression> expr) { m_tester = expr; } InternalValue Evaluate(RenderContext& values) override; void Render(OutStream &stream, RenderContext &values) override; private: ExpressionEvaluatorPtr<Expression> m_expression; ExpressionEvaluatorPtr<ExpressionFilter> m_filter; ExpressionEvaluatorPtr<IfExpression> m_tester; }; class ValueRefExpression : public Expression { public: ValueRefExpression(std::string valueName) : m_valueName(valueName) { } InternalValue Evaluate(RenderContext& values) override; private: std::string m_valueName; }; class SubscriptExpression : public Expression { public: SubscriptExpression(ExpressionEvaluatorPtr<Expression> value, ExpressionEvaluatorPtr<Expression> subscriptExpr) : m_value(value) , m_subscriptExpr(subscriptExpr) { } InternalValue Evaluate(RenderContext& values) override; private: ExpressionEvaluatorPtr<Expression> m_value; ExpressionEvaluatorPtr<Expression> m_subscriptExpr; }; class ConstantExpression : public Expression { public: ConstantExpression(InternalValue constant) : m_constant(constant) {} InternalValue Evaluate(RenderContext&) override { return m_constant; } private: InternalValue m_constant; }; class TupleCreator : public Expression { public: TupleCreator(std::vector<ExpressionEvaluatorPtr<>> exprs) : m_exprs(std::move(exprs)) { } InternalValue Evaluate(RenderContext&) override; private: std::vector<ExpressionEvaluatorPtr<>> m_exprs; };
D'ici .
Exemples de classes d'opérateurs d'arbre AST struct Statement : public RendererBase { }; template<typename T = Statement> using StatementPtr = std::shared_ptr<T>; template<typename CharT> class TemplateImpl; class ForStatement : public Statement { public: ForStatement(std::vector<std::string> vars, ExpressionEvaluatorPtr<> expr, ExpressionEvaluatorPtr<> ifExpr, bool isRecursive) : m_vars(std::move(vars)) , m_value(expr) , m_ifExpr(ifExpr) , m_isRecursive(isRecursive) { } void SetMainBody(RendererPtr renderer) { m_mainBody = renderer; } void SetElseBody(RendererPtr renderer) { m_elseBody = renderer; } void Render(OutStream& os, RenderContext& values) override; private: void RenderLoop(const InternalValue& val, OutStream& os, RenderContext& values); private: std::vector<std::string> m_vars; ExpressionEvaluatorPtr<> m_value; ExpressionEvaluatorPtr<> m_ifExpr; bool m_isRecursive; RendererPtr m_mainBody; RendererPtr m_elseBody; }; class ElseBranchStatement; class IfStatement : public Statement { public: IfStatement(ExpressionEvaluatorPtr<> expr) : m_expr(expr) { } void SetMainBody(RendererPtr renderer) { m_mainBody = renderer; } void AddElseBranch(StatementPtr<ElseBranchStatement> branch) { m_elseBranches.push_back(branch); } void Render(OutStream& os, RenderContext& values) override; private: ExpressionEvaluatorPtr<> m_expr; RendererPtr m_mainBody; std::vector<StatementPtr<ElseBranchStatement>> m_elseBranches; }; class ElseBranchStatement : public Statement { public: ElseBranchStatement(ExpressionEvaluatorPtr<> expr) : m_expr(expr) { } bool ShouldRender(RenderContext& values) const; void SetMainBody(RendererPtr renderer) { m_mainBody = renderer; } void Render(OutStream& os, RenderContext& values) override; private: ExpressionEvaluatorPtr<> m_expr; RendererPtr m_mainBody; };
D'ici .
Les nœuds AST sont associés uniquement au texte du modèle et sont convertis en valeurs totales au moment du rendu, en tenant compte du contexte de rendu actuel et de ses paramètres. Cela nous a permis de créer des modèles thread-safe. Mais plus à ce sujet en termes de rendu réel.
En tant que tokenizer principal, j'ai choisi la bibliothèque
lexertk . Il a la licence dont j'ai besoin et uniquement en-tête. Certes, j'ai dû couper toutes les cloches et les sifflets du calcul de l'équilibre des crochets, etc., et ne laisser que le tokenizer lui-même, qui (après un peu de redressement avec un fichier) a appris à fonctionner non seulement avec char, mais aussi avec les caractères wchar_t. En plus de ce tokenizer, j'ai encapsulé une autre classe qui remplit trois fonctions principales: a) il extrait le code de l'analyseur du type de caractères avec lequel nous travaillons, b) reconnaît les mots clés spécifiques à Jinja2 et c) fournit une interface pratique pour travailler avec le flux de jetons:
LexScanner class LexScanner { public: struct State { Lexer::TokensList::const_iterator m_begin; Lexer::TokensList::const_iterator m_end; Lexer::TokensList::const_iterator m_cur; }; struct StateSaver { StateSaver(LexScanner& scanner) : m_state(scanner.m_state) , m_scanner(scanner) { } ~StateSaver() { if (!m_commited) m_scanner.m_state = m_state; } void Commit() { m_commited = true; } State m_state; LexScanner& m_scanner; bool m_commited = false; }; LexScanner(const Lexer& lexer) { m_state.m_begin = lexer.GetTokens().begin(); m_state.m_end = lexer.GetTokens().end(); Reset(); } void Reset() { m_state.m_cur = m_state.m_begin; } auto GetState() const { return m_state; } void RestoreState(const State& state) { m_state = state; } const Token& NextToken() { if (m_state.m_cur == m_state.m_end) return EofToken(); return *m_state.m_cur ++; } void EatToken() { if (m_state.m_cur != m_state.m_end) ++ m_state.m_cur; } void ReturnToken() { if (m_state.m_cur != m_state.m_begin) -- m_state.m_cur; } const Token& PeekNextToken() const { if (m_state.m_cur == m_state.m_end) return EofToken(); return *m_state.m_cur; } bool EatIfEqual(char type, Token* tok = nullptr) { return EatIfEqual(static_cast<Token::Type>(type), tok); } bool EatIfEqual(Token::Type type, Token* tok = nullptr) { if (m_state.m_cur == m_state.m_end) { if(type == Token::Type::Eof && tok) *tok = EofToken(); return type == Token::Type::Eof; } if (m_state.m_cur->type == type) { if (tok) *tok = *m_state.m_cur; ++ m_state.m_cur; return true; } return false; } private: State m_state; static const Token& EofToken() { static Token eof; eof.type = Token::Eof; return eof; } };
D'ici .
Ainsi, malgré le fait que le moteur puisse fonctionner à la fois avec char et wchar_t-templates, le code d'analyse principal ne dépend pas du type de caractère. Mais plus à ce sujet dans la section sur les aventures avec les types de personnages.
Séparément, j'ai dû bricoler avec les structures de contrôle. À Jinja2, beaucoup d'entre eux sont jumelés. Par exemple, pour / endfor, if / endif, block / endblock, etc. Chaque élément de la paire va dans ses propres «crochets», et entre les éléments il peut y avoir un tas de tout: juste du texte brut et d'autres blocs de contrôle. Par conséquent, l'algorithme d'analyse syntaxique du modèle devait être fait sur la base de la pile, à l'élément supérieur actuel dont toutes les constructions et instructions nouvellement trouvées, ainsi que des fragments de texte simple entre eux, «s'accrochent». En utilisant la même pile, l'absence de déséquilibrage du type if-for-endif-endfor est vérifiée. À la suite de tout cela, le code s'est avéré ne pas être aussi "compact" que, disons, Jinja2CppLight (ou inja), où l'implémentation entière est dans une seule source (ou en-tête). Mais la logique d'analyse et, en fait, la grammaire du code sont plus clairement visibles, ce qui simplifie son support et son extension. C'est du moins ce que je visais. Il n'est toujours pas possible de minimiser le nombre de dépendances ou la quantité de code, vous devez donc le rendre plus clair.
Dans la
partie suivante, nous parlerons du processus de rendu des modèles, mais pour l'instant - liens:
Spécification Jinja2:
http://jinja.pocoo.org/docs/2.10/templates/Implémentation de Jinja2Cpp:
https://github.com/flexferrum/Jinja2CppImplémentation de Jinja2CppLight:
https://github.com/hughperkins/Jinja2CppLightImplémentation endommagée:
https://github.com/pantor/injaUtilitaire pour générer du code basé sur des modèles Jinja2:
https://github.com/flexferrum/autoprogrammer/tree/jinja2cpp_refactor