Dans les deux derniers articles, nous avons parlé de IIoT - l'Internet industriel des objets - construit une architecture pour recevoir les données des capteurs, soudé les capteurs eux-mêmes. La pierre angulaire des architectures IIoT et de toutes les architectures fonctionnant avec BigData est le traitement des flux de données. Il est basé sur le concept de messagerie et de mise en file d'attente. La norme pour travailler avec la messagerie est désormais devenue Apache Kafka. Cependant, afin de comprendre ses avantages (et ses inconvénients), il serait bon de comprendre les bases du fonctionnement des systèmes de files d'attente dans leur ensemble, leurs mécanismes de fonctionnement, leurs modes d'utilisation et leurs fonctionnalités de base.

Nous avons trouvé une excellente série d'articles qui compare les fonctionnalités d'Apache Kafka et d'un autre géant (à juste titre ignoré) parmi les systèmes de file d'attente - RabbitMQ. Nous avons traduit cette série d'articles, leur avons fourni des commentaires et les avons complétés. Bien que la série ait été écrite en décembre 2017, le monde des systèmes de messagerie (et en particulier Apache Kafka) évolue si rapidement qu'à l'été 2018, certaines choses ont changé.
Source
RabbitMQ vs Kafka
La messagerie est la partie centrale de nombreuses architectures, et les deux piliers dans ce domaine sont RabbitMQ et Apache Kafka. À ce jour, Apache Kafka est devenu une norme presque industrielle dans le traitement et l'analyse des données, donc dans cette série, nous examinerons de plus près RabbitMQ et Kafka dans le contexte de leur utilisation dans les infrastructures en temps réel.
Apache Kafka est maintenant à la hausse, mais il semble qu'ils aient commencé à oublier RabbitMQ. Tout le battage médiatique s'est concentré sur Kafka, et cela se produit pour des raisons évidentes, mais RabbitMQ est toujours un excellent choix pour la messagerie. L'une des raisons pour lesquelles Kafka s'est tournée vers lui-même est son obsession générale pour l'évolutivité, et évidemment Kafka est plus évolutif que RabbitMQ, mais la plupart d'entre nous ne se soucient pas des échelles auxquelles RabbitMQ a des problèmes. La plupart d'entre nous ne sont ni Google ni Facebook. La plupart d'entre nous traitons des volumes quotidiens de messages de centaines de milliers à des centaines de millions, et non des volumes de milliards à des milliards (mais en passant, il y a des cas où les gens ont réduit RabbitMQ à des milliards de messages quotidiens).
Ainsi, dans notre série d'articles, nous ne parlerons pas de cas où une évolutivité extrême est requise (et c'est la prérogative de Kafka), mais nous nous concentrerons plutôt sur les avantages uniques que chacun des systèmes considérés offre. Fait intéressant, chaque système a ses propres avantages, mais en même temps, ils sont assez différents les uns des autres. Bien sûr, j'ai beaucoup écrit sur RabbitMQ, mais je vous assure que je n'y accorde aucune préférence particulière. J'aime les choses bien faites, et RabbitMQ et Kafka sont tous deux des systèmes de messagerie assez matures, fiables et, oui, évolutifs.
Nous allons commencer au niveau supérieur, puis commencer à étudier les différents aspects de ces deux technologies. Cette série d'articles est destinée aux professionnels impliqués dans l'organisation de systèmes de messagerie ou aux architectes / ingénieurs qui souhaitent comprendre les détails du niveau inférieur et leur application. Nous n'écrirons pas de code, mais nous nous concentrerons plutôt sur les fonctionnalités offertes par les deux systèmes, les modèles de processus de messagerie que chacun d'eux propose et les décisions que les développeurs et architectes de décisions doivent prendre.
Dans cette partie, nous verrons ce que sont RabbitMQ et Apache Kafka, et leur approche de la messagerie. Les deux systèmes abordent l'architecture de messagerie sous différents angles, chacun ayant ses forces et ses faiblesses. Dans ce chapitre, nous ne tirerons pas de conclusions importantes; nous proposons plutôt de prendre cet article comme un manuel technologique pour les débutants, afin que nous puissions approfondir les prochains articles de la série.
Rabbitmq
RabbitMQ est un système de gestion de file d'attente de messages distribué. Distribué, car il fonctionne généralement comme un cluster de nœuds, où les files d'attente sont réparties entre les nœuds et, éventuellement, sont répliquées afin d'être résistantes aux erreurs et de haute disponibilité. Régulièrement, il implémente AMQP 0.9.1 et propose d'autres protocoles, tels que STOMP, MQTT et HTTP via des modules supplémentaires.
RabbitMQ utilise des approches de messagerie classiques et innovantes. Classique dans le sens où il se concentre sur la file d'attente de messages et innovant - dans la possibilité d'un routage flexible. Cette fonction de routage est son avantage unique. La création d'un système de messagerie distribué rapide, évolutif et fiable est une réussite en soi, mais la fonctionnalité de routage de messagerie le rend vraiment exceptionnel parmi de nombreuses technologies de messagerie.
Échange et files d'attente
Revue super simplifiée:
- Les éditeurs (éditeurs) envoient des messages aux échanges
- Exchange'i envoie des messages dans les files d'attente et à d'autres échanges
- RabbitMQ envoie des confirmations aux éditeurs dès réception d'un message
- Les destinataires (consommateurs) maintiennent des connexions TCP persistantes à RabbitMQ et annoncent la ou les files d'attente qu'ils reçoivent
- RabbitMQ envoie des messages aux destinataires
- Les destinataires envoient des confirmations de réussite / d'erreur
- Une fois la réception réussie, les messages sont supprimés des files d'attente.
Cette liste contient un grand nombre de décisions que les développeurs et les administrateurs doivent prendre pour obtenir les garanties de livraison dont ils ont besoin, les caractéristiques de performance, etc., dont nous discuterons plus tard.
Voyons un exemple de travail avec un seul éditeur, échange, file d'attente et destinataire:

Fig. 1. Un éditeur et un destinataire
Que faire si vous avez plusieurs éditeurs du même
des messages? Et si nous avons plusieurs destinataires, chacun souhaitant recevoir tous les messages?

Fig. 2. Plusieurs éditeurs, plusieurs destinataires indépendants
Comme vous pouvez le voir, les éditeurs envoient leurs messages au même échangeur, qui envoie chaque message dans trois files d'attente, chacune ayant un destinataire. Dans le cas de RabbitMQ, les files d'attente permettent à différents destinataires de recevoir tous les messages. Comparez avec le tableau ci-dessous:
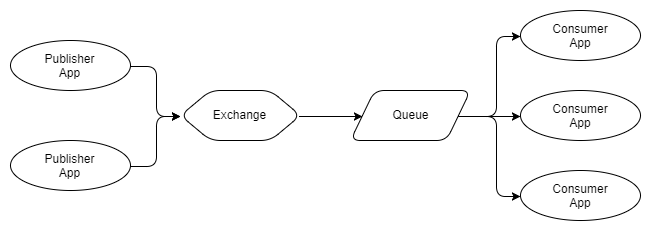
Fig. 3. Plusieurs éditeurs, une file d'attente avec plusieurs destinataires concurrents
Dans la figure 3, nous voyons trois destinataires qui utilisent la même file d'attente. Ce sont des destinataires concurrents, c'est-à-dire qu'ils sont en concurrence pour recevoir des messages de la file d'attente. Ainsi, on peut s'attendre à ce qu'en moyenne, chaque destinataire reçoive un tiers des messages de la file d'attente. Nous utilisons des destinataires concurrents pour faire évoluer notre système de traitement des messages, et en utilisant RabbitMQ, il est très simple de le faire: ajouter ou supprimer des destinataires sur demande. Quel que soit le nombre de destinataires concurrents dont vous disposez, RabbitMQ ne remettra des messages qu'à un seul destinataire.
Nous pouvons combiner du riz. 2 et 3 pour recevoir plusieurs ensembles de destinataires concurrents, chaque ensemble recevant chaque message.

Fig. 4. Plusieurs éditeurs, plusieurs files d'attente avec des destinataires concurrents
Les flèches entre les échangeurs et les files d'attente sont appelées liaisons, et nous en parlerons plus en détail.
Garanties
RabbitMQ donne des garanties de «livraison unique» et «au moins une livraison», mais pas «exactement une livraison».
Note du traducteur: Avant la version 0.11 de Kafka, la livraison d'un message de livraison en une seule fois n'était pas disponible; actuellement, des fonctionnalités similaires sont présentes dans Kafka.
Les messages sont remis dans l'ordre où ils arrivent dans la file d'attente (après tout, c'est la définition de la file d'attente). Cela ne garantit pas que l'achèvement du traitement des messages correspond au même ordre lorsque vous avez des destinataires concurrents. Ce n'est pas une erreur RabbitMQ, mais la réalité fondamentale du traitement parallèle d'un ensemble ordonné de messages. Ce problème peut être résolu à l'aide de l'échange de hachage cohérent, comme vous le verrez dans le chapitre suivant sur les modèles et les topologies.
Destinataires push et prefetch
RabbitMQ envoie des messages aux destinataires (il existe également une API pour extraire les messages de RabbitMQ, mais cette fonctionnalité est obsolète pour le moment). Cela peut submerger les destinataires si les messages arrivent dans la file d'attente plus rapidement que les destinataires ne peuvent les traiter. Pour éviter cela, chaque destinataire peut définir une limite de prélecture (également appelée limite QoS). En fait, la limite de QoS est une limite sur le nombre de messages qui n'ont pas été acquittés par le destinataire accumulés. Il agit comme un fusible lorsque le récepteur commence à prendre du retard.
Pourquoi a-t-il été décidé que les messages dans la file d'attente sont poussés (push) et non déchargés (pull)? D'abord parce qu'il y a moins de temps de retard. Deuxièmement, idéalement, lorsque nous avons des destinataires concurrents de la même file d'attente, nous voulons répartir uniformément la charge entre eux. Si chaque destinataire demande / télécharge des messages, selon la quantité demandée, la répartition du travail peut devenir assez inégale. Plus la distribution des messages est inégale, plus le retard et la perte d'ordre des messages pendant le traitement sont importants. Ces facteurs orientent l'architecture RabbitMQ vers un mécanisme push à message à la fois. C'est l'une des limites de la mise à l'échelle de RabbitMQ. La limitation est atténuée par le fait que les confirmations peuvent être regroupées.
Acheminement
Les échanges sont essentiellement des routeurs de messages pour les files d'attente et / ou d'autres échanges. Pour qu'un message soit déplacé de l'échange vers une file d'attente ou vers un autre échange, une liaison est nécessaire. Différents échanges nécessitent des liaisons différentes. Il existe quatre types d'échanges et de liaisons associées:
- Fanout Dirige vers toutes les files d'attente et échangeurs liés à l'échange du sous-modèle standard de Pub.
- Direct (direct). Achemine les messages en fonction de la clé de routage que le message emporte avec elle, définie par l'éditeur. La clé de routage est une chaîne courte. Les échangeurs directs envoient des messages aux files d'attente d'échange / qui ont une clé d'appariement qui correspond exactement à la clé de routage.
- Sujet (thématique). Achemine les messages en fonction de la clé de routage, mais autorise l'utilisation d'une correspondance incomplète (caractère générique).
- En-tête (en-tête). RabbitMQ vous permet d'ajouter des en-têtes de destinataire aux messages. Les échanges d'en-tête envoient des messages en fonction de ces valeurs d'en-tête. Chaque liaison inclut une correspondance exacte des valeurs d'en-tête. Vous pouvez ajouter plusieurs valeurs à la liaison avec TOUTES ou TOUTES les valeurs nécessaires pour correspondre.
- Hachage cohérent. Il s'agit d'un échangeur qui hache soit une clé de routage, soit un en-tête de message, et envoie uniquement dans une file d'attente. Cela est utile lorsque vous devez respecter les garanties des ordres de traitement et être en mesure de mettre à l'échelle les destinataires.

Fig. 5. Exemple d'échange de sujets
Nous considérerons également le routage plus en détail, mais l'exemple d'échange de sujet est donné ci-dessus. Dans cet exemple, les éditeurs publient des journaux d'erreurs en utilisant le format de clé de routage LEVEL (niveau d'erreur) .AppName.
La file d'attente 1 recevra tous les messages car elle utilise un numéro générique avec plusieurs mots.
La file d'attente 2 recevra n'importe quel niveau de journalisation d'application ECommerce.WebUI. Il utilise un caractère générique *, capturant ainsi le niveau d'une seule dénomination de sujet (ERROR.Ecommerce.WebUI, NOTICE.ECommerce.WebUI, etc.).
La file d'attente 3 affichera tous les messages d'ERREUR de n'importe quelle application. Il utilise le caractère générique # pour couvrir toutes les applications (ERROR.ECommerce.WebUi, ERROR.SomeApp.SomeSublevel, etc.).
Grâce à quatre méthodes d'acheminement des messages et avec la possibilité d'échanger des messages pour envoyer des messages à d'autres échanges, RabbitMQ vous permet d'utiliser un ensemble puissant et flexible de modèles d'échange de messages. Plus loin, nous parlerons d'échanges avec échanges de lettres mortes, d'échanges et de files d'attente sans données (échanges et files d'attente éphémères), et RabbitMQ se développera à son plein potentiel.
Échange non livré
Note du traducteur: lorsque les messages de la file d'attente ne peuvent pas être reçus pour une raison ou une autre (la consommation électrique n'est pas suffisante, problèmes de réseau, etc.), ils peuvent être retardés et traités séparément.
Nous pouvons configurer des files d'attente pour que les messages soient envoyés à l'échange dans les conditions suivantes:
- La file d'attente dépasse le nombre de messages spécifié.
- La file d'attente dépasse le nombre d'octets spécifié.
- Le délai de transmission des messages (TTL) a expiré. L'éditeur peut définir la durée de vie du message et la file d'attente elle-même peut également avoir un TTL spécifié pour le message. Dans ce cas, un TTL plus court des deux sera utilisé.
Nous créons une file d'attente qui est liée aux échanges avec des messages non livrés, et ces messages y sont stockés jusqu'à ce qu'une action soit entreprise.
Comme de nombreuses fonctions de RabbitMQ, les échanges avec des messages non distribuables permettent d'utiliser des modèles qui n'étaient pas fournis à l'origine. Nous pouvons utiliser des messages TTL et des échanges avec des messages non livrés pour implémenter des files d'attente différées et réessayer des files d'attente.
Échangeurs et files d'attente sans données
Les échanges et les files d'attente peuvent être créés dynamiquement et vous pouvez définir des critères pour leur suppression automatique. Cela permet l'utilisation de modèles tels que les RPC basés sur des messages.
Modules supplémentaires
Le premier plug-in que vous souhaitez probablement installer est le plug-in de gestion, qui fournit un serveur HTTP avec une interface Web et une API REST. Il est très facile à installer et possède une interface facile à utiliser. Le déploiement de scripts via l'API REST est également très simple.
De plus:
- Échange de hachage cohérent, échange de partage, etc.
- des protocoles comme STOMP et MQTT
- crochets Web
- types d'échangeurs supplémentaires
- Intégration SMTP
Il y a beaucoup d'autres choses à dire sur RabbitMQ, mais c'est un bon exemple qui vous permet de décrire ce que RabbitMQ peut faire. Maintenant, nous regardons Kafka, qui utilise une approche complètement différente de la messagerie et, en même temps, a également son propre ensemble de fonctionnalités distinctives et intéressantes.
Apache kafka
Kafka est un journal de validation répliqué distribué. Kafka n'a aucun concept de files d'attente, ce qui peut sembler étrange au premier abord, étant donné qu'il est utilisé comme système de messagerie. Les files d'attente sont depuis longtemps synonymes de systèmes de messagerie. Voyons d'abord ce que signifie un «journal de validation des modifications distribué et répliqué»:
- Distribué car Kafka est déployé en tant que cluster de nœuds, à la fois pour la tolérance aux erreurs et pour la mise à l'échelle
- Répliqué, car les messages sont généralement répliqués sur plusieurs nœuds (serveurs).
- Un journal de validation, car les messages sont stockés dans des journaux segmentés et ajoutés uniquement appelés rubriques. Ce concept de journalisation est le principal avantage unique de Kafka.
Comprendre le journal (et le sujet) et les partitions est la clé pour comprendre Kafka. En quoi un journal partitionné diffère-t-il d'un ensemble de files d'attente? Imaginons à quoi ça ressemble.
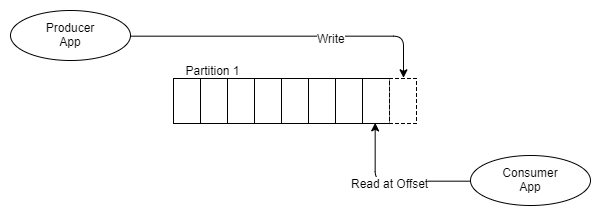
Fig. 6 Un producteur, un segment, un destinataire
Au lieu de placer des messages dans la file d'attente FIFO et de surveiller l'état de ce message dans la file d'attente, comme le fait RabbitMQ, Kafka l'ajoute simplement au journal, et c'est tout.
Le message reste, qu'il soit reçu une ou plusieurs fois. Il est supprimé conformément à la politique de conservation, également appelée période de fenêtre. Comment les informations sont-elles tirées du sujet?
Chaque destinataire garde une trace de l'endroit où il se trouve dans le journal: il y a un pointeur vers le dernier message reçu et ce pointeur est appelé l'adresse de décalage. Les destinataires prennent en charge cette adresse via les bibliothèques clientes, et selon la version de Kafka, l'adresse est stockée dans ZooKeeper ou dans Kafka lui-même.
Une caractéristique distinctive du modèle de journalisation est qu'il élimine instantanément de nombreuses difficultés concernant l'état de la remise des messages et, plus important encore pour les destinataires, leur permet de rembobiner, retourner et recevoir des messages à l'adresse relative précédente. Par exemple, imaginez que vous déployez un service qui émet des factures qui prennent en compte les commandes passées par les clients. Le service a une erreur et ne calcule pas correctement toutes les factures en 24 heures. Avec RabbitMQ au mieux, vous devrez en quelque sorte republier ces commandes uniquement sur le service de compte. Mais avec Kafka, vous déplacez simplement l'adresse relative de ce destinataire il y a 24 heures.
Voyons donc à quoi cela ressemble quand il y a un sujet dans lequel il y a une partition et deux destinataires, chacun devant recevoir chaque message.

Fig. 7. Un producteur, une partition, deux destinataires indépendants
Comme le montre le diagramme, deux destinataires indépendants reçoivent la même partition, mais lisent à des adresses de décalage différentes. Le service de facturation prend peut-être plus de temps pour traiter les messages que le service de notification push. ou peut-être que le service de facturation n'était pas disponible depuis un certain temps et a essayé de rattraper son retard plus tard. Ou peut-être qu'il y a eu une erreur et que l'adresse de décalage a dû être reportée de plusieurs heures.
Supposons maintenant que le service de facturation doive être divisé en trois parties, car il ne peut pas suivre la vitesse du message. Avec RabbitMQ, nous déployons simplement deux autres applications de service de facturation qui proviennent de la file d'attente de facturation. Mais Kafka ne prend pas en charge les destinataires concurrents dans la même partition; le bloc de concurrence Kafka est la partition elle-même. Par conséquent, si nous avons besoin de trois destinataires de factures, nous avons besoin d'au moins trois partitions. Nous avons donc maintenant:
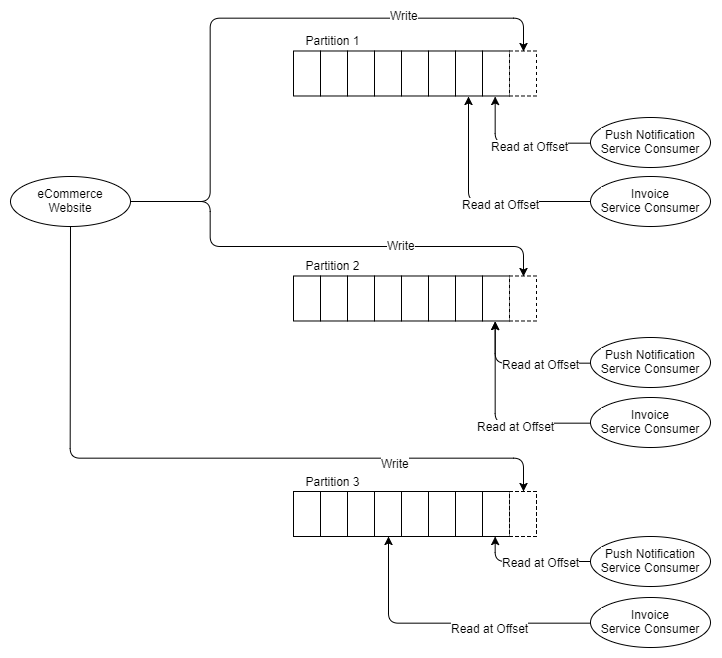
Fig. 8. Trois partitions et deux groupes de trois destinataires
Ainsi, il est entendu que vous avez besoin d'au moins autant de partitions que le destinataire horizontal le plus évolué. Parlons un peu des partitions.
Partitions et groupes de destinataires
Chaque partition est un fichier distinct dans lequel la séquence des messages est garantie. Il est important de s'en souvenir: l'ordre des messages est garanti dans une seule partition. À l'avenir, cela peut conduire à une certaine contradiction entre les exigences de mise en file d'attente des messages et les exigences de performances, car les performances dans Kafka sont également mises à l'échelle par les partitions. La partition ne peut pas prendre en charge les destinataires concurrents, notre application de facturation ne peut donc utiliser qu'une seule partie pour chaque section.
Les messages peuvent être redirigés vers des segments par un algorithme cyclique ou via une fonction de hachage: hachage (clé de message)% nombre de partitions. , , , , , , . .
RabbitMQ. . , RabbitMQ , . , .
RabbitMQ . Kafka , .
, , Kafka , RabbitMQ — . RabbitMQ , . Kafka , . , , Kafka , .
, , , ( ). , , . , , , .
RabbitMQ — Consistent Hashing exchange, . Kafka' , Kafka , , , , , -. RabbitMQ , , , .
: , , Id 1000 , Id 1000 . , , . , .
(push) (pull)
RabbitMQ (push) , , . RabbitMQ . , Kafka (pull), . , , Kafka long-polling.
(pull) Kafka - . Kafka , , .
RabbitMQ, , , , . Kafka , .
Kafka /» , , . , .
Fig. 9.
, , Kafka :
Fig. 10. ,

, :

Fig. 11.
, , .
, , , , .

Fig. 12.
. .

:
, . , , .
Kafka – , , , , , . . , . , , .
— . , 50 . – . , , , .
, , . , , . , . , , , .
. , , .
, RabbitMQ, Kafka, Kafka . RabbitMQ , , ZooKeeper Consul.
RabbitMQ , Kafka. RabbitMQ, , . : .
. , . . , . . . , , - .
, Kafka, . . , , .
, . RabbitMQ , Kafka .
Conclusions
RabbitMQ , . , , . , . , , .
Kafka . , . Kafka , RabbitMQ . , Kafka , RabbitMQ, , .
RabbitMQ.
, , IoT , . : t.me/justiothings