Commentaires dans une publication récente "Quelle est la qualité de l'écosystème open source de R pour résoudre les problèmes commerciaux?" Quant aux téléchargements dans Excel, ils ont conduit à l'idée qu'il est logique de passer du temps et de décrire l'une des approches possibles éprouvées qui peuvent être mises en œuvre sans quitter R.
La situation est assez typique. L'entreprise dispose toujours de N méthodes par lesquelles les gestionnaires essaient manuellement de créer des rapports dans Excel. Même s'ils sont automatisés, il reste toujours une situation où il est urgent de faire une nouvelle coupe arbitraire ou de faire une présentation pour un certain manager sous une forme spécifique.
Et il existe un certain nombre de dictionnaires Excel pris en charge manuellement pour transformer la présentation des données dans des rapports et des échantillons dans la terminologie correcte.
Étant donné qu'aucun outil approprié (la masse des nuances supplémentaires sera inférieure) n'a pu être trouvé, j'ai dû empiler le "constructeur universel" sur Shiny + R. En raison de l'universalité et de la paramétrisation des paramètres, un tel constructeur peut facilement être implanté sur presque n'importe quel système dans n'importe quel domaine.
Il s'agit d'une continuation des publications précédentes .
Bref énoncé du problème
- Comme source de données techniques, il existe un stockage de type OLAP principal (nous nous concentrons sur Clickhouse), plusieurs autres (Postgre, MS SQL, API REST) et des répertoires manuels xml, json, xlsx. Étant donné que des analyses ad hoc sont nécessaires, y compris le calcul de valeurs uniques, il est uniquement nécessaire de travailler avec les données source, et non avec des agrégats.
- Entrées dans la base de données - des centaines de milliards de lignes pour plusieurs centaines de colonnes (événements temporels), il est conseillé de faire l'analyse dans un mode mesuré pas plus de plusieurs dizaines de secondes, les requêtes peuvent être complètement imprévisibles, les données sont stockées sous forme technique (abréviations anglaises, nombre d'entrées de dictionnaire, etc. ) Dans l'état cible, ~ 200 To de données brutes sont attendues.
- Les événements accumulés ont des spécificités de version, c.-à-d. au fur et à mesure que le système fonctionne, des informations provenant de différentes versions et versions de sources qui se rapportent de diverses manières s'y accumulent.
- Les gestionnaires fonctionnent bien dans Excel, mais ne devraient pas connaître (et ne peuvent pas physiquement) la composante technique du système.
Comment résoudre le problème
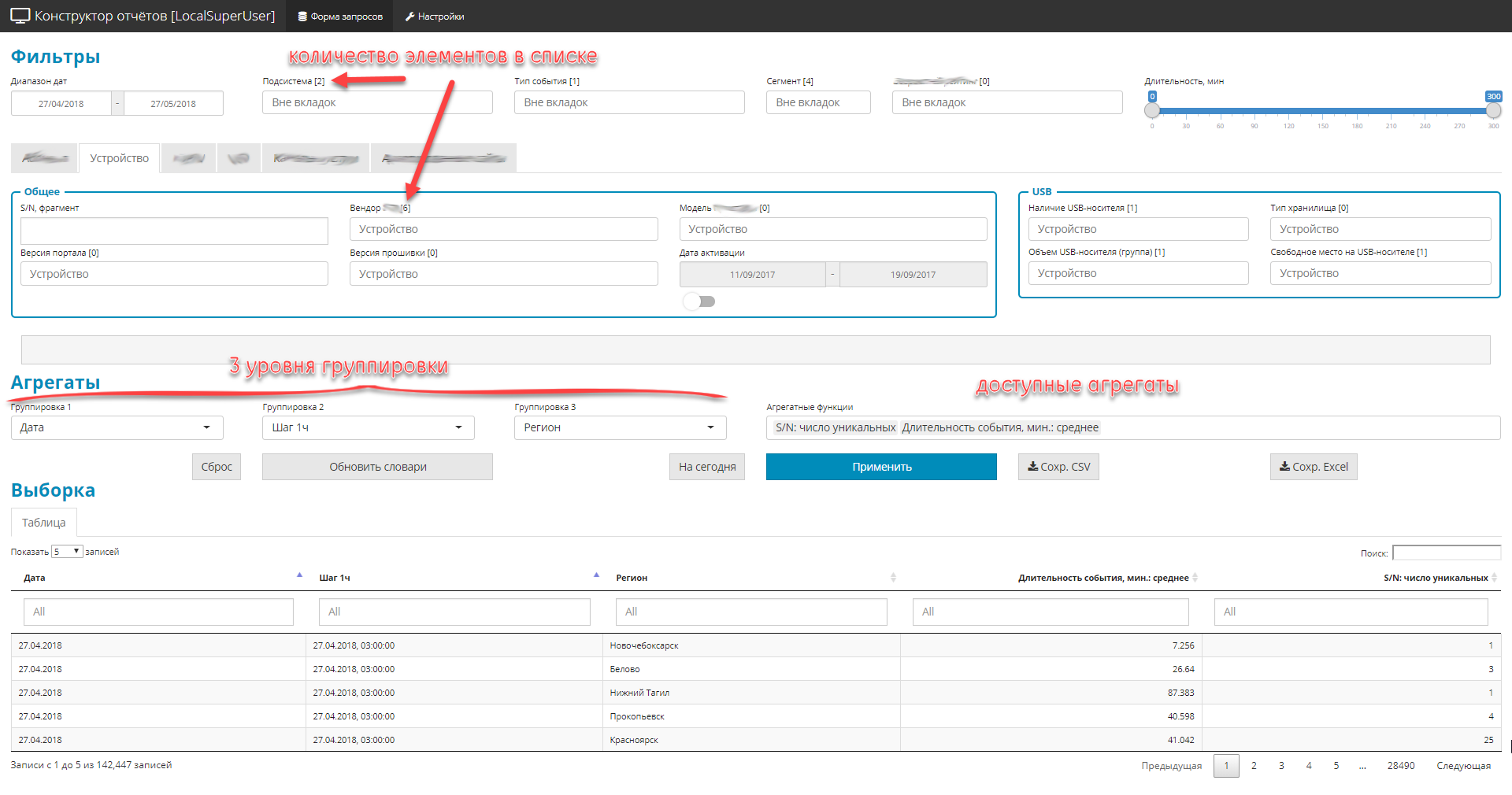
Le scénario général du travail est assez simple. Le gestionnaire a reçu une tâche urgente pour la section analytique - le gestionnaire ouvre l'application, forme des échantillons arbitraires en fonction du domaine - regarde et tord le résultat tabulaire - décharge le résultat arrangé en excel - dessine une image pour la gestion. La commodité et la simplicité de l'interface utilisateur ont été choisies comme point zéro.
- Tout est conçu comme une application Shiny à écran unique avec des menus de navigation et des signets.
- Tous les contrôles sont divisés en 3 parties:
- filtres (globaux et privés). Limitez la zone de sélection, il existe 4 types: liste déroulante-dictionnaire, dates, fragments de texte, plage numérique.
- 3 niveaux d'imbrication des groupes de requêtes
- liste des quantités agrégées (à savoir les quantités).
- En raison du fait qu'il y a beaucoup de champs dans la source d'origine (environ 2,5 cents), mais que vous devez tout afficher, les éléments de contrôle sont regroupés en blocs thématiques.
Exemple d'interface
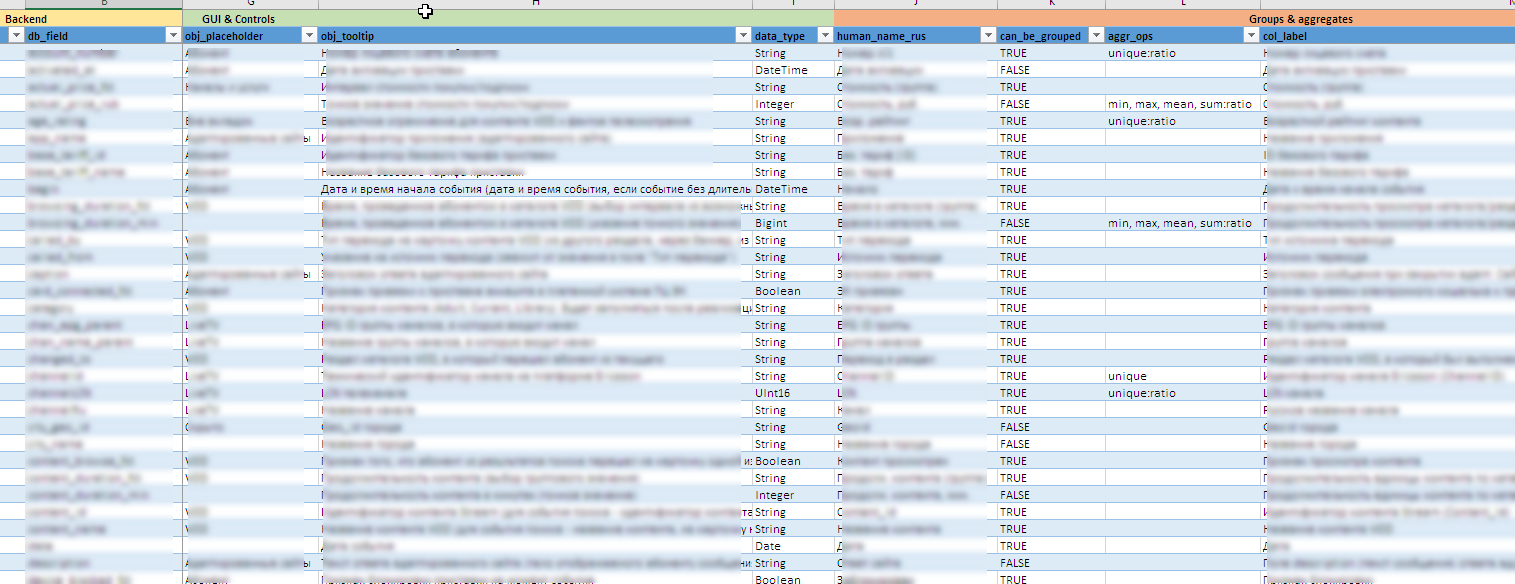
Exemple de fichier avec des méta-informations
"Puces" utiles dans les coulisses:
- À mesure que les sources de données évoluent, toute la configuration de l'interface, y compris la création de contrôles, d'infobulles, le contenu des regroupements et agrégats disponibles, les règles d'exportation dans Excel, etc. décoré comme un métamodèle sous la forme d'un fichier Excel. Cela vous permet de modifier rapidement le "concepteur" pour les nouveaux champs ou unités de calcul sans changements importants (ou aucun changement du tout) au code source.
- Il est difficile de dire à l’avance quelles valeurs peuvent se produire dans un domaine particulier et en trouver une, je ne sais pas quoi, est encore plus difficile. La maintenance manuelle des 90 commandes dynamiques est presque impossible. Dans certaines listes, le vocabulaire comprend plusieurs centaines de significations. Par conséquent, les entrées de dictionnaire pour les contrôles sont mises à jour en arrière-plan en fonction des données accumulées dans le backend.
- Les gestionnaires doivent voir tous les champs et contenus en russe. Et dans les sources, ces données peuvent être stockées sous une forme officielle. Par conséquent, une combinaison de technologies de dictionnaire Clickhouse et de post-traitement bidirectionnel des valeurs de champ au niveau Shiny est utilisée. Il assure immédiatement le traitement de toutes sortes d'exceptions aux règles et aux nuances versionnées du contenu des champs.
- Pour éviter les sélections incorrectes, une connexion croisée a été établie entre les listes pour le regroupement. Le niveau 2 ne peut être sélectionné que si le niveau 1 est défini, et le niveau 3, uniquement si le niveau 2. Et les listes de valeurs disponibles sont dynamiquement réduites en tenant compte des valeurs déjà sélectionnées.
- Un élément important est le contrôle de l'affichage de la sélection à l'écran et lors du téléchargement ultérieur vers Excel. Ici aussi, il existe un certain nombre de fonctionnalités dans le post-traitement visant à la commodité de l'outil pour le gestionnaire:
- support organisé de la «matrice de visibilité» sous forme de fichier excel. Cette matrice détermine l'affichage ou le masquage de certains champs dans la sélection, en fonction des filtres installés.
- modification dynamique ligne par ligne du contenu de l'échantillon. Selon le contenu de différents champs, le contenu d'un autre champ peut être modifié (par exemple, si 0 est spécifié dans le champ «quantité commandée», une ligne vide s'affiche alors dans le champ «type de commande»).
- gestion de l'affichage des données personnelles. selon les droits d'accès au rôle configurés pers. les données peuvent être affichées ainsi que partiellement masquées avec
* . - gestion de la précision. juste pour mentionner. afficher 10 décimales - Moveton, mais il existe des situations où la précision de 2 décimales n'est pas suffisante. 80% des objets, par exemple, ont un pourcentage de
0.00% - vous devez augmenter les caractères significatifs lors de l'arrondi, afin que la différence entre les lignes soit visible. Et la quantité au déchargement dans Excel devrait converger (la quantité sur toutes les lignes de la colonne fractionnaire est raisonnablement attendue dans la région de 100%). - fournir un accès aux rôles au niveau des contrôles de contenu disponibles. Les droits d'accès sont contrôlés par le fichier de configuration json.
- Contrôle dynamique de la profondeur des requêtes. Dans le cas où aucun regroupement et agrégat n'est spécifié (l'étude est en cours et il vous suffit de renvoyer les données brutes qui relèvent des filtres installés), la protection contre la surcharge du backend est activée. L'utilisateur peut définir l'intervalle de temps pour la recherche en 1 an, mais a vraiment besoin des 1000 derniers enregistrements de la sélection. Sachant que des millions d'enregistrements arrivent quotidiennement, une demande d'essai de profondeur réduite est d'abord effectuée (il y a 3 à 7 jours). Si le nombre de lignes reçues n'est pas suffisant (conditions de filtrage strictes), une requête complète est lancée pour toute la période.
- Déchargement des échantillons reçus au format Excel. Tout est formaté, tout en russe, est accompagné d'une feuille séparée avec la fixation de tous les paramètres de l'échantillon, afin que vous puissiez facilement comprendre comment tel ou tel résultat a été obtenu.
- Un journal détaillé est conservé dans l'application, afin que vous puissiez vous faire une idée des actions de l'utilisateur et du fonctionnement de la mécanique du compartiment moteur.
Anticipant d'éventuels commentaires sur le «vélo», s'il y en aura 100%, je vous propose tout de suite de les écrire avec une indication du produit open source que vous connaissez. Je serai heureux de nouvelles découvertes.
Naturellement, un lien vers le produit doit être donné en tenant compte de l'ensemble des exigences avancées. Eh bien, de préférence immédiatement avec l'évaluation de l'infrastructure requise. Pour cette option, deux ou trois serveurs de capacité moyenne (64-128 Go; cœur de processeur 12-20, disque - en fonction de la quantité de données) sont suffisants pour l'ensemble du complexe. ELK ne convenait pas, car la tâche principale est l'analyse numérique et ne fonctionne pas avec du texte.
Ensemble des exigences détaillées
Ci-dessous, pour information, une liste détaillée des exigences pour l'unité d'analyse est donnée dans la partie des interfaces machine-machine et homme-machine (le «concepteur de rapports» n'est qu'une partie).
Importer \ Exporter \ Environnement
- Les fichiers journaux sont normalisés et structurés uniquement en termes d'horodatages, de modules et de sous-systèmes. Le système doit traiter les fichiers journaux avec un contenu arbitraire du contenu du message (corps de journal de l'enregistrement), prenant en charge à la fois le corps de journal structuré et non structuré de l'enregistrement.
- Pour enrichir les données, le système doit disposer d'adaptateurs d'importation pour au moins les types de sources de données suivants:
- fichiers plats (csv, txt)
- fichiers structurés xml, json, xlsx
- sources compatibles ODBC, en particulier MS SQL, MySQL, PostgreSQL
- données fournies via l'API REST.
- Le système doit prendre en charge l'importation automatique et l'importation à la demande de l'utilisateur. Lors de l'importation de données utilisateur, le système doit fournir:
- la possibilité de validation technique des données importées (l'exactitude du nombre de champs, leur type, leur exhaustivité, la présence de valeurs
- la possibilité de validation logique (contenu des champs, validation, validation croisée, ...)
- la possibilité de configurer les paramètres de validation (sous n'importe quelle forme) conformément à la logique de la procédure d'importation;
- Un rapport détaillé sur les erreurs techniques et logiques détectées, permettant à l'opérateur de localiser rapidement et d'éliminer les dysfonctionnements dans les données importées.
- Le système doit prendre en charge l'exportation des résultats, au moins, dans les formats suivants:
- exportation de données vers des fichiers plats csv, txt
- exporter des données vers des fichiers xml, json, xlsx structurés
- exportation de données vers des sources compatibles ODBC, en particulier MS SQL, MySQL, PostgreSQL
- fournir un accès aux données via le protocole API REST
- Le système devrait avoir la fonctionnalité pour générer des rapports imprimés:
- une combinaison cohérente de texte, de représentations tabulaires et de représentations graphiques dans un seul document selon un modèle préformé (narration);
- la formation de tous les éléments calculés (tableaux, graphiques) au moment de la génération du formulaire d'impression;
- l'utilisation de sources externes et de répertoires nécessaires à la préparation d'un rapport en mode à la volée selon les protocoles mentionnés ci-dessus, sans intégration et duplication de données
- export des rapports générés aux formats html, docx, pdf
- la formation de représentations imprimées doit être prise en charge à la fois sur demande et en arrière-plan, selon un calendrier.
- Le système doit conserver un journal détaillé des calculs, des actions actives de l'utilisateur ou de l'interaction avec les systèmes externes.
- Le système doit être installé sur site.
- L'installation et les opérations ultérieures doivent être effectuées en isolant complètement le système d'Internet.
Calculs
- Le système doit prendre en charge le calcul de métriques agrégées (minimum, maximum, moyenne, médiane, quartiles) pour un intervalle de temps arbitraire dans un mode dans un mode proche du temps réel.
- Le système doit prendre en charge le calcul de métriques de base (nombre de valeurs, nombre de valeurs uniques) pour un intervalle de temps arbitraire dans un mode proche du temps réel.
- Lors du calcul des données agrégées, les périodes d'agrégation doivent être déterminées par l'utilisateur à partir de plages prédéfinies: 5 minutes, 10 minutes, 15 minutes, 20 minutes, 30 minutes, 1 heure, 2 heures, 24 heures, 1 semaine, 1 mois
- Le système doit inclure un constructeur pour former des échantillons arbitraires. La composition des opérations possibles doit être déterminée par un métamodèle de données prédéfini. Le constructeur doit prendre en charge les paramètres minimum suivants:
- Prise en charge du filtre pour les dates: [début de la période de rapport - fin de la période de rapport]
- Prise en charge des filtres (listes déroulantes) avec multi-sélection pour les champs énumérés (par exemple, villes: Moscou, Saint-Pétersbourg, ...)
- Formation automatique du contenu des listes déroulantes pour les filtres de champs énumérables basés sur des répertoires externes dynamiques ou des données accumulées.
- prise en charge d'au moins trois niveaux de regroupement séquentiel des données dans l'échantillon demandé; les paramètres de regroupement sont définis par l'utilisateur à partir de la liste des ensembles de données disponibles au niveau du métamodèle.
- restriction des champs disponibles pour le regroupement à l'un ou l'autre niveau, en tenant compte des champs sélectionnés aux niveaux supérieurs de regroupement (par exemple, si «ville» a été choisi au 1er niveau, ce paramètre ne devrait pas être disponible au 2e ou 3e m niveaux de regroupement)
- possibilité de regroupement par paramètres de temps augmentés: jour de la semaine, groupe d'heures (11-12; 12-13), semaine
- prise en charge des agrégats calculés de base: (minimum, maximum, moyenne, médiane, quantité, nombre d'unités uniques);
- prise en charge des filtres de test pour fournir une recherche en texte intégral dans la sélection;
- assistance au stade de l'affichage de l'enrichissement et de la transformation des données obtenues sur demande à partir de données provenant de répertoires ou de sources externes.
- Le système devrait avoir des mécanismes pour calculer les métriques en coordonnées spatiales (sp = point spatial) pour soutenir la géoanalytique.
- Pour les métriques de temps (transactions, opérations, requêtes, ...), le système doit calculer et afficher la densité de la distribution du temps d'exécution des requêtes.
- Tous les indicateurs calculés doivent être effectués pour tous les objets dans leur ensemble, ainsi que pour les sous-échantillons définis par l'utilisateur à l'aide de filtres
- Le système doit effectuer tous les calculs en mémoire.
- Tous les événements ont un horodatage, le système doit donc prendre en charge le travail avec des séries temporelles équidistantes et arbitraires.
- Le système doit prendre en charge la capacité de configurer et d'activer des mécanismes de restauration des données manquées dans les séries chronologiques (divers algorithmes), de déterminer les anomalies, de prédire les séries chronologiques, de classer / regrouper.
Partie interface
- L'ensemble de l'interface utilisateur, y compris le contenu des éléments graphiques et de tableau, doit être localisé.
- Pour les contrôles et les colonnes de représentations tabulaires, la possibilité de former des info-bulles avec une description détaillée (pointe de survol), formée à la fois de manière statique et dynamique (par exemple, dans l'info-bulle peut être les paramètres utilisés pour calculer), doit être prise en charge.
- L'interface de travail ne doit être construite qu'avec l'utilisation de technologies HTML, CSS, JS, sans utiliser de technologies obsolètes, dépendantes de la plateforme ou non portables, telles qu'Adobe Flash, MS Silverlight, etc.
- L'heure sur les graphiques doit être affichée au format 24 heures.
- Les paramètres d'affichage des données sur les axes doivent prendre en charge la mise à l'échelle automatique (fréquence des étiquettes et format d'affichage) en fonction de la plage de valeurs. Un exemple typique est l'affichage des heures avec une plage de mesure dans une journée, l'affichage des jours avec une plage de mesure dans une semaine.
- Le système doit, au minimum, prendre en charge les formats d'affichage graphique atomique suivants:
- Histogramme (barre)
- Spot
- Linéaire
- Heatmap
- Contours (contours)
- Diagrammes à secteurs
- Le système doit prendre en charge la possibilité de placer automatiquement et intelligemment des marqueurs (par exemple, des valeurs) d'un certain sous-ensemble de points avec un chevauchement minimum de ces marqueurs.
- Le système devrait prendre en charge la possibilité de combiner sur une seule représentation graphique des données obtenues à partir de différentes sources de données. La possibilité de spécifier différents formats d'affichage graphique atomique pour chaque source de données doit être prise en charge, à condition que les axes de coordonnées et le type de système de coordonnées correspondent.
- Le système doit prendre en charge la distribution à facettes (partitionnement des graphes sur la grille M x N) des graphes atomiques pour une variable de paramétrage donnée. Dans l'affichage des facettes, pour chaque graphique, une mise à l'échelle indépendante de l'axe X et de l'axe Y doit être possible.
- Les graphiques doivent prendre en charge le paramétrage des caractéristiques suivantes:
- La couleur
- Type de ligne ou de point
- L'épaisseur de la ligne ou du contour du point
- Taille du point
- La transparence
- Pour les tâches de géoanalyse des données, le système doit prendre en charge le travail avec les fichiers de formes, y compris l'importation, l'affichage, la coloration paramétrée de la zone et veiller à ce que divers éléments graphiques et indicateurs calculés soient superposés au géopode généré.
- Les contrôles de l'interface utilisateur (listes, champs, panneaux, etc.) doivent prendre en charge le changement dynamique de leur contenu en fonction de l'état des autres éléments. Par exemple, lors du choix d'une certaine région, le contenu de l'élément de sélection de ville doit être limité à la liste des villes incluses dans la région.
- Le modèle de rôle d'accès aux applications de génération de rapports doit être pris en charge:
- prise en charge du métamodèle de données pour fournir un accès aux rôles au niveau de l'url (possible / impossible)
- prise en charge d'un métamodèle de données pour fournir un accès basé sur les rôles au niveau du contenu d'un élément de contrôle (par exemple, la liste des objets disponibles dans les listes déroulantes est déterminée par la responsabilité régionale du gestionnaire)
- prise en charge du métamodèle de données pour garantir un accès basé sur les rôles au niveau de la visualisation des données personnelles (par exemple, masquer «*» d'une certaine partie des numéros de courrier électronique ou d'autres champs)
Conclusion
L'objectif principal de la publication est de montrer que les possibilités de R s'étendent assez fortement au-delà des frontières des statistiques classiques. Il est vérifié pratiquement, il n'est pas nécessaire de sacrifier la qualité ou la fonctionnalité.
Article précédent - «Quelle est la qualité de l'écosystème open source de R pour résoudre les problèmes commerciaux?» .