L'une des nouvelles les plus populaires et discutées au cours des dernières années est de savoir qui a ajouté l'intelligence artificielle à où et quels pirates ont cassé quoi et où. En combinant ces sujets, des études très intéressantes apparaissent, et il y avait déjà plusieurs articles sur le hub qui pouvaient tromper les modèles d'apprentissage automatique, par exemple: un article sur les limites de l'apprentissage en profondeur , sur la façon d'attirer les réseaux de neurones . De plus, je voudrais examiner ce sujet plus en détail du point de vue de la sécurité informatique:

Tenez compte des problèmes suivants:
- Termes importants.
- Qu'est-ce que l'apprentissage automatique, si tout à coup vous ne saviez toujours pas.
- Qu'est-ce que la sécurité informatique a à voir avec ça?!
- Est-il possible de manipuler le modèle d'apprentissage automatique pour mener une attaque ciblée?
- Les performances du système peuvent-elles être dégradées?
- Puis-je profiter des limites des modèles d'apprentissage automatique?
- Catégorisation des attaques.
- Moyens de protection.
- Conséquences possibles.
1. La première chose que je voudrais commencer est la terminologie.
Cette déclaration possible peut provoquer un grand holivar de la part des communautés scientifiques et professionnelles en raison de plusieurs articles déjà écrits en russe, mais je voudrais noter que le terme «renseignement contradictoire» est traduit par «renseignement ennemi». Et le mot «contradictoire» lui-même devrait être traduit non pas par le terme juridique «contradictoire», mais par un terme plus approprié de sécurité «malveillant» (on ne se plaint pas de la traduction du nom de l'architecture du réseau neuronal). Ensuite, tous les termes connexes en russe prennent une signification beaucoup plus claire, comme «exemple contradictoire» - une instance malveillante de données, «paramètres contradictoires» - un environnement malveillant. Et le domaine même que nous considérerons comme «l'apprentissage machine contradictoire» est l'apprentissage machine malveillant.
Au moins dans le cadre de cet article, de tels termes en russe seront utilisés. J'espère qu'il sera possible de montrer que ce sujet est beaucoup plus sur la sécurité afin d'utiliser équitablement les termes de ce domaine, plutôt que le premier exemple d'un traducteur.
Donc, maintenant que nous sommes prêts à parler la même langue, nous pouvons commencer essentiellement :)
2. Qu'est-ce que l'apprentissage automatique, si soudain vous ne saviez toujours pas
Eh bien, toujours déjà au courantPar méthodes d'apprentissage automatique, nous entendons généralement des méthodes de construction d'algorithmes capables d'apprendre et d'agir sans programmer explicitement leur comportement sur des données présélectionnées. Par données, nous pouvons signifier n'importe quoi, si nous pouvons le décrire avec des signes ou le mesurer. S'il existe un signe inconnu pour certaines données, mais que nous en avons vraiment besoin, nous utilisons des méthodes d'apprentissage automatique pour restaurer ou prédire ce signe sur la base de données déjà connues.
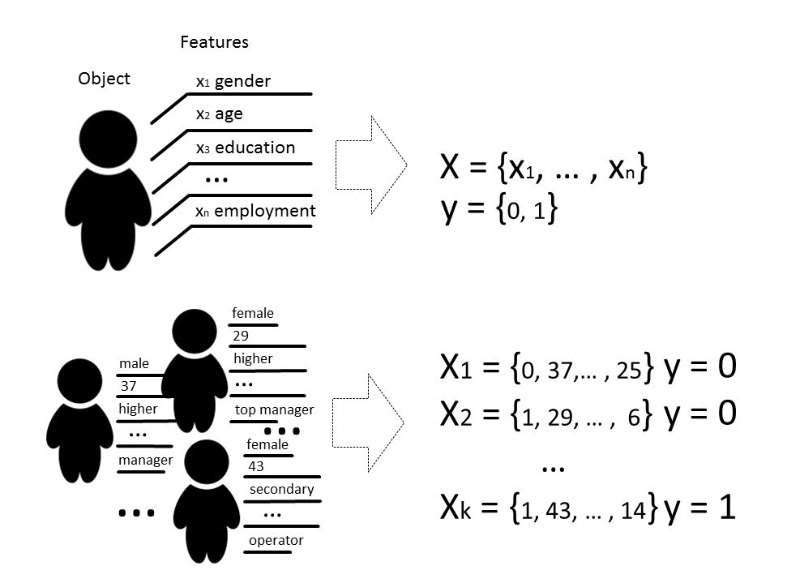
Il existe plusieurs types de problèmes qui peuvent être résolus à l'aide de l'apprentissage automatique, mais nous parlerons principalement du problème de classification.
Classiquement, le but de l'étape d'apprentissage du modèle de classificateur est de sélectionner une relation (fonction) qui montrera la correspondance entre les caractéristiques d'un objet particulier et l'une des classes connues. Dans un cas plus complexe, une prédiction de la probabilité d'appartenance à une catégorie particulière est requise.
Autrement dit, la tâche de classification consiste à construire un tel hyperplan qui divisera l'espace, où, en règle générale, sa dimension est la taille du vecteur d'entité, de sorte que les objets de différentes classes se trouvent sur les côtés opposés de cet hyperplan.
Pour un espace à deux dimensions, un tel hyperplan est une ligne. Prenons un exemple simple:

Dans l'image, vous pouvez voir deux classes, des carrés et des triangles. Il est impossible de trouver la dépendance et de les diviser le plus précisément par une fonction linéaire. Par conséquent, à l'aide de l'apprentissage automatique, on peut choisir une fonction non linéaire qui distinguerait le mieux ces deux ensembles.
La tâche de classification est une tâche d'enseignement assez typique avec un enseignant. Pour former le modèle, un tel ensemble de données est nécessaire afin qu'il soit possible de distinguer les caractéristiques de l'objet et de sa classe.
3. Qu'est-ce que la sécurité informatique a à voir avec ça?!
Dans le domaine de la sécurité informatique, diverses méthodes d'apprentissage automatique sont utilisées depuis longtemps dans le filtrage du spam, l'analyse du trafic et la détection des fraudes ou des logiciels malveillants.
Et dans un sens, c'est un jeu où, après avoir fait un mouvement, vous vous attendez à ce que l'ennemi réagisse. Par conséquent, en jouant à ce jeu, vous devez constamment ajuster les modèles, enseigner de nouvelles données ou les changer complètement, en tenant compte des dernières réalisations de la science.
Par exemple, alors que les antivirus utilisent l'analyse de signature, l'heuristique manuelle et les règles qui sont assez difficiles à maintenir et à étendre, l'industrie de la sécurité continue de débattre sur les avantages réels de l'antivirus et beaucoup considèrent les antivirus comme un produit mort. Les attaquants contournent toutes ces règles, par exemple à l'aide de l'obscurcissement et du polymorphisme. En conséquence, la préférence est donnée aux outils qui utilisent des techniques plus intelligentes, par exemple, les méthodes d'apprentissage automatique qui sélectionnent automatiquement les fonctionnalités (même celles qui ne sont pas interprétées par les humains), peuvent traiter rapidement de grandes quantités d'informations, les généraliser et prendre des décisions rapidement.
Autrement dit, l'apprentissage automatique est utilisé comme un outil de protection. D'un autre côté, cet outil est également utilisé pour des attaques plus intelligentes.
Voyons voir si cet outil peut être vulnérable?
Pour tout algorithme, non seulement la sélection des paramètres est très importante, mais aussi les données sur lesquelles l'algorithme est formé. Bien sûr, dans une situation idéale, il est nécessaire qu'il y ait suffisamment de données pour la formation, les classes doivent être équilibrées et le temps de formation passer inaperçu, ce qui est pratiquement impossible dans la vie réelle.
La qualité d'un modèle entraîné est généralement comprise comme l'exactitude de la classification sur des données que le modèle n'a pas encore «vues», dans le cas général, comme un certain rapport de copies de données correctement classées par rapport à la quantité totale de données que nous avons transmises au modèle.
En général, toutes les évaluations de la qualité sont directement liées aux hypothèses sur la distribution attendue des données d'entrée du système et ne prennent pas en compte les conditions environnementales nocives ( paramètres contradictoires ), qui vont souvent au-delà de la distribution attendue des données d'entrée. Un environnement malveillant est compris comme un environnement où il est possible de confronter ou d'interagir avec le système. Des exemples typiques de tels environnements sont ceux qui utilisent des filtres anti-spam, des algorithmes de détection de fraude et des systèmes d'analyse de logiciels malveillants.
Ainsi, la précision peut être considérée comme une mesure de la performance moyenne du système dans son utilisation moyenne, tandis que l'évaluation de la sécurité s'intéresse à sa pire mise en œuvre.
Autrement dit, les modèles d'apprentissage automatique sont généralement testés dans un environnement assez statique où la précision dépend de la quantité de données pour chaque classe particulière, mais en réalité la même distribution ne peut pas être garantie. Et nous voulons faire un mauvais modèle. En conséquence, notre tâche est de trouver autant de vecteurs que possible qui donnent le mauvais résultat.
Lorsqu'ils parlent de la sécurité d'un système ou d'un service, ils signifient généralement qu'il est impossible de violer une politique de sécurité au sein d'un modèle de menace donné dans le matériel ou le logiciel, en essayant de vérifier le système à la fois au stade du développement et au stade des tests. Mais aujourd'hui, un grand nombre de services fonctionnent sur la base d'algorithmes d'analyse de données, donc les risques résident non seulement dans les fonctionnalités vulnérables, mais aussi dans les données elles-mêmes, sur la base desquelles le système peut prendre des décisions.
Personne ne reste immobile et les pirates maîtrisent également quelque chose de nouveau. Et les méthodes qui aident à étudier les algorithmes d'apprentissage automatique pour la possibilité de compromis par un attaquant qui peut utiliser la connaissance du fonctionnement du modèle sont appelées apprentissage automatique contradictoire , ou en russe, il s'agit toujours d' un apprentissage automatique malveillant .
Si nous parlons de la sécurité des modèles d'apprentissage automatique du point de vue de la sécurité de l'information, alors conceptuellement j'aimerais considérer plusieurs questions.
4. Est-il possible de manipuler le modèle d'apprentissage automatique pour mener une attaque ciblée?
Voici un bon exemple avec l'optimisation des moteurs de recherche. Les gens étudient le fonctionnement des algorithmes des moteurs de recherche intelligents et manipulent les données sur leurs sites pour être plus élevés dans le classement de recherche. La question de la sécurité d'un tel système dans ce cas n'est pas si aiguë tant qu'elle n'a pas compromis certaines données ou causé de graves dommages.
À titre d'exemple d'un tel système, nous pouvons citer des services qui utilisent essentiellement la formation en ligne sur le modèle, c'est-à-dire la formation dans laquelle le modèle reçoit des données dans un ordre séquentiel pour mettre à jour les paramètres actuels. En sachant comment le système est formé, vous pouvez planifier l'attaque et fournir au système des données pré-préparées.
Par exemple, de cette manière, les systèmes biométriques sont trompés , qui mettent progressivement à jour leurs paramètres à mesure que de petits changements dans l'apparence d'une personne se produisent , par exemple, avec un changement naturel d'âge , ce qui est une fonctionnalité absolument naturelle et nécessaire du service dans ce cas. En utilisant cette propriété du système, vous pouvez préparer les données et les soumettre au système biométrique, en mettant à jour le modèle jusqu'à ce qu'il mette à jour les paramètres à une autre personne. Ainsi, l'attaquant recyclera le modèle et pourra s'identifier à la place de la victime.

Ce problème découle tout à fait naturellement du fait que le modèle d'apprentissage automatique est souvent testé dans un environnement plutôt statique, et sa qualité est évaluée par la distribution des données sur lesquelles le modèle a été formé. Dans le même temps, des questions très souvent très spécifiques sont posées aux spécialistes de l'analyse des données, auxquelles le modèle doit répondre:
- Le fichier est-il malveillant?
- Cette transaction appartient-elle à la fraude?
- Le trafic actuel est-il légitime?
Et on s'attend à ce que l'algorithme ne puisse pas être précis à 100%, il ne peut qu'avec une certaine probabilité attribuer l'objet à une certaine classe, nous devons donc trouver des compromis dans le cas d'erreurs du premier et du deuxième type, lorsque notre algorithme ne peut pas être complètement sûr dans son choix et toujours faux.
Prenons un système qui produit très souvent des erreurs du premier et du deuxième type. Par exemple, l'antivirus a bloqué votre fichier car il le considérait comme malveillant (bien que ce ne soit pas le cas), ou l'antivirus a ignoré un fichier malveillant. Dans ce cas, l'utilisateur du système le considère inefficace et le plus souvent le désactive, bien qu'il soit probable qu'un ensemble de ces données vient d'être capturé.
Et l'ensemble de données sur lequel le modèle montre le pire résultat existe toujours. Et la tâche de l'attaquant est de rechercher ces données afin de le faire éteindre le système. De telles situations sont plutôt désagréables et, bien sûr, le modèle devrait les éviter. Et vous pouvez imaginer l'ampleur des conséquences des enquêtes sur tous les faux incidents!
Les erreurs du premier type sont perçues comme une perte de temps, tandis que les erreurs du second type sont perçues comme une opportunité manquée. Bien qu'en fait, le coût de ces types d'erreurs pour chaque système spécifique puisse être différent. Si un antivirus peut être moins cher, une erreur du premier type peut être commise, car il est préférable de le jouer en toute sécurité et de dire que le fichier est malveillant, et si le client arrête le système et que le fichier s'avère vraiment malveillant, alors l'antivirus "tel qu'il a été averti" et la responsabilité incombe à l'utilisateur. Si nous prenons, par exemple, un système de diagnostic médical, alors les deux erreurs seront assez coûteuses, car en tout cas le patient risque un traitement incorrect et un risque pour la santé.
6. Un attaquant peut-il utiliser les propriétés d'une méthode d'apprentissage automatique pour perturber le système? C'est-à-dire, sans interférer dans le processus d'apprentissage, trouver de telles limitations de modèle qui donnent évidemment des prédictions incorrectes.
Il semblerait que les systèmes d'apprentissage profond soient pratiquement protégés de l'intervention humaine dans la sélection des signes, il serait donc possible de dire qu'il n'y a pas de facteur humain lors de la prise de décisions par le modèle. Le charme de l'apprentissage en profondeur est qu'il suffit de donner à l'entrée du modèle des données presque «brutes», et le modèle lui-même, à travers de multiples transformations linéaires, met en évidence les caractéristiques qu'il «considère» les plus importantes et prend une décision. Mais est-ce vraiment si bon?
Il existe des travaux qui décrivent les méthodes de préparation de tels exemples malveillants sur le modèle d'apprentissage en profondeur, que le système classe incorrectement. L'un des rares mais populaires exemples est un article sur les attaques physiques efficaces contre les modèles d'apprentissage en profondeur.
Les auteurs ont réalisé des expériences et proposé des méthodes pour contourner les modèles basés sur la restriction de l'apprentissage profond qui trompent le système de "vision", en utilisant l'exemple de la reconnaissance des panneaux de signalisation. Pour un résultat positif, il suffit que les attaquants trouvent de telles zones sur l'objet qui renversent le plus fortement le classificateur, et c'est une erreur. Les expériences ont été réalisées sur la marque «STOP» qui, en raison des changements de chercheurs, a qualifié le modèle de marque «SPEED LIMIT 45». Ils ont testé leur approche sur d'autres panneaux et ont obtenu un résultat positif.
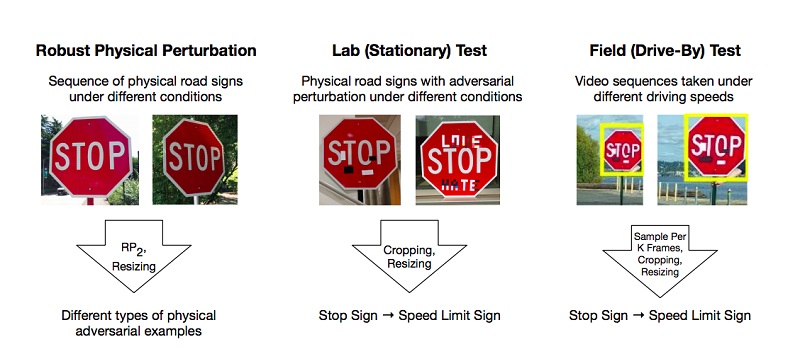
En conséquence, les auteurs ont proposé deux façons de tromper le système d'apprentissage automatique: l'attaque par impression d'affiches, qui implique une série de petits changements sur tout le périmètre de la marque, appelée camouflage, et les attaques par autocollants, lorsque certains autocollants étaient superposés sur la marque dans certaines zones.
Mais ce sont des situations bien réelles - lorsque le signe est dans la saleté de la poussière de la route ou lorsque de jeunes talents ont abandonné leur travail dessus. Il est probable que l'intelligence artificielle et l'art n'ont pas leur place dans un seul monde.

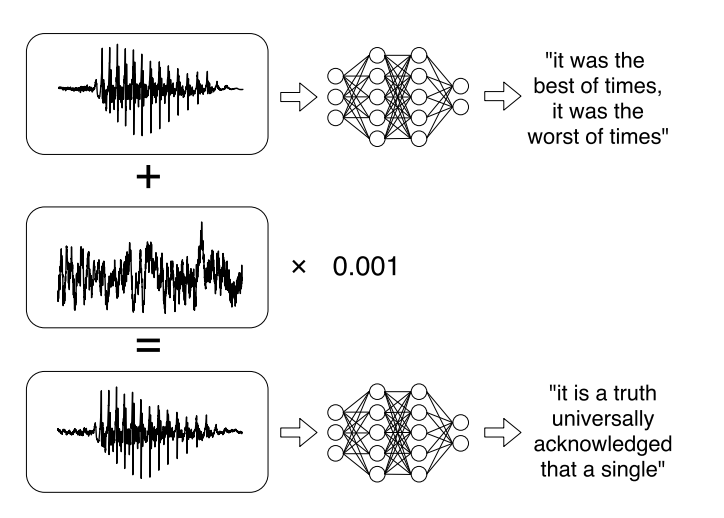
Ou des recherches récentes sur les attaques ciblées contre les systèmes de reconnaissance vocale automatique . Les messages vocaux sont devenus une tendance à la mode lors de la communication sur les réseaux sociaux, mais les écouter n'est pas toujours pratique. Par conséquent, il existe des services qui vous permettent de diffuser un enregistrement audio en texte. Les auteurs de l'ouvrage ont appris à analyser l'audio d'origine, à prendre en compte le signal sonore, puis à créer un autre signal sonore, similaire à 99% à l'original, en lui apportant une petite modification. Par conséquent, le classificateur déchiffre l'enregistrement comme l'attaquant le souhaite.
À cet égard, il serait possible de classer les attaques existantes de plusieurs manières :
Par la méthode d'exposition (Influence):
- Les attaques causales affectent l'entraînement du modèle par l'interférence dans l'ensemble d'entraînement.
- Les attaques exploratoires utilisent des erreurs de classificateur sans affecter l'ensemble d'apprentissage.
Violation de sécurité:
- Les attaques d'intégrité compromettent le système par des erreurs du deuxième type.
- Les attaques de disponibilité provoquent un arrêt du système, généralement basé sur des bogues du premier type.
Spécificité:
- L'attaque ciblée (attaque ciblée) vise à modifier la prédiction du classificateur en une classe spécifique.
- L'attaque de masse (attaque aveugle) vise à changer la réponse du classificateur à n'importe quelle classe sauf la bonne.
Le but de la sécurité est de protéger les ressources contre un attaquant et le respect des exigences, dont les violations conduisent à une compromission partielle ou complète d'une ressource.
Divers modèles d'apprentissage automatique sont utilisés pour la sécurité. Par exemple, les systèmes de détection de virus visent à réduire la vulnérabilité aux virus en les détectant avant que le système ne soit infecté ou en détectant un existant pour suppression. Un autre exemple est le système de détection d'intrusion (IDS), qui détecte qu'un système a été compromis en détectant du trafic malveillant ou un comportement suspect dans le système. Une autre tâche proche est le système de prévention des intrusions (IPS), qui détecte les tentatives d'intrusion et empêche les intrusions dans le système.
Dans le cadre de problèmes de sécurité, l'objectif des modèles d'apprentissage automatique est, dans le cas général, de séparer les événements malveillants et de les empêcher d'interférer avec le système.
En général, l'objectif peut être divisé en deux:
intégrité : empêcher un attaquant d'accéder aux ressources système
accessibilité : empêcher un attaquant d'interférer avec le fonctionnement normal.
Il existe un lien clair entre les erreurs de second type et les violations d'intégrité: les instances malveillantes qui passent dans le système peuvent être nuisibles. Tout comme les erreurs du premier type violent généralement l'accessibilité, car le système lui-même rejette des copies fiables des données.
8. Quels sont les moyens de se protéger contre les cybercriminels manipulant les modèles d'apprentissage automatique?
À l'heure actuelle, il est plus difficile de protéger un modèle d'apprentissage automatique contre les attaques malveillantes que de l'attaquer. Tout simplement parce que peu importe combien nous formons le modèle, il y aura toujours un ensemble de données sur lequel il fonctionnera le plus.
Et aujourd'hui, il n'existe aucun moyen suffisamment efficace pour faire fonctionner le modèle avec une précision de 100%. Mais il existe quelques conseils qui peuvent rendre le modèle plus résistant aux exemples malveillants.
En voici le principal: s'il est possible de ne pas utiliser de modèles d'apprentissage automatique dans un environnement malveillant, il vaut mieux ne pas les utiliser. Cela n'a aucun sens de refuser l'apprentissage automatique si vous êtes confronté à la tâche de classer des images ou de générer des mèmes. Il n'est guère possible d'infliger des dommages importants qui entraîneraient des conséquences sociales ou économiques importantes en cas d'attaque délibérée. , , , , , .
, , , . .
, , . , , , , , , , . , , , , , , .
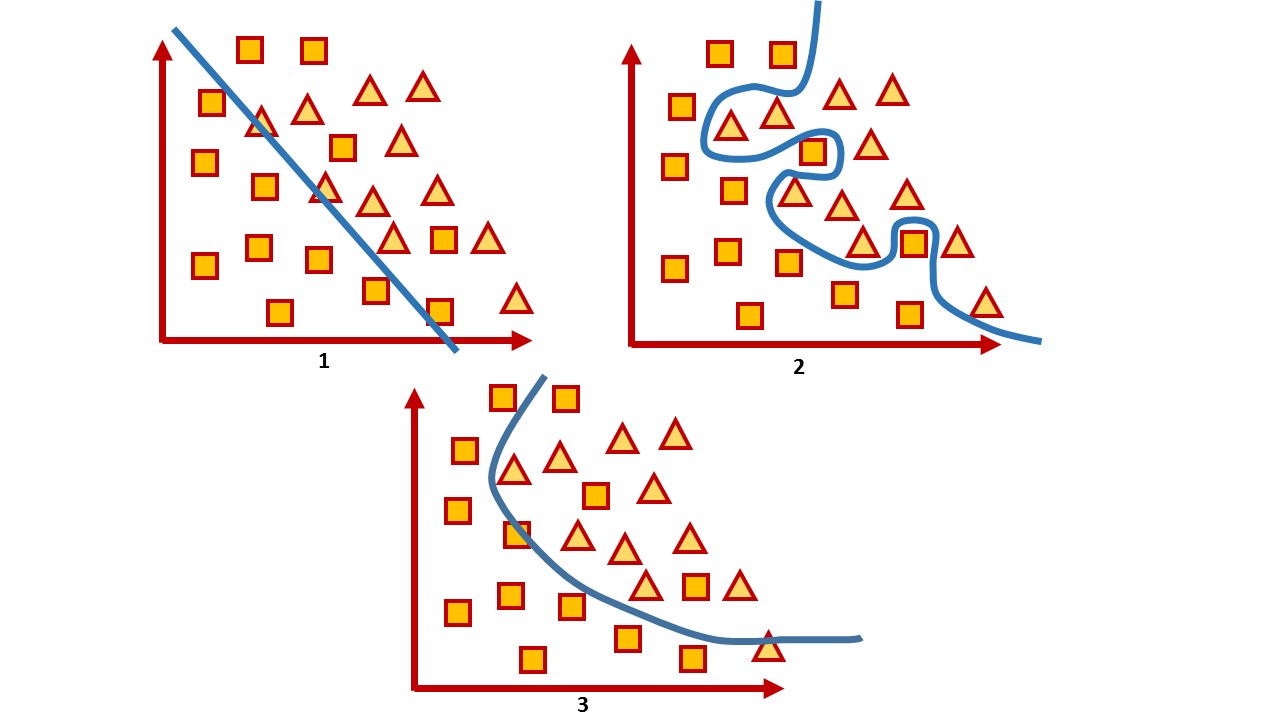
1 — , 2 — , 3 —
, , : . . , .
. , . , . 100%- - , .
- , — . , — , . , .
, , .
9. ?
. : , , , , .
, . . , . , , , «».
, - , . , , . - Twitter, Microsoft, .
? , , — , , . , , , — , , .
, , , « — , »?