Développer des tests d'application n'est pas une expérience agréable. Ce processus prend beaucoup de temps, nécessite beaucoup de concentration et est extrêmement demandé. Le langage Kotlin fournit un ensemble d'outils qui facilite la création de votre propre langage orienté problème (DSL). Il y a de l'expérience lorsque Kotlin DSL a remplacé les constructeurs et les méthodes statiques pour tester le module de planification des ressources, ce qui a fait de l'ajout de nouveaux tests et de la prise en charge des anciens d'une routine un processus amusant.
Au cours de l'article, nous analyserons tous les principaux outils de l'arsenal du développeur et comment ils peuvent être combinés pour résoudre des problèmes de test. Nous irons de la conception du test idéal au lancement du test le plus approximatif, le plus propre et le plus compréhensible pour le système de planification des ressources basé sur Kotlin.
L'article sera utile aux ingénieurs praticiens, à ceux qui considèrent Kotlin comme un langage pour écrire confortablement des tests compacts et à ceux qui souhaitent améliorer le processus de test dans leur projet.
Cet article est basé sur une présentation d'Ivan Osipov (
i_osipov ) à la conférence JPoint. Une narration supplémentaire est menée en son nom. Ivan travaille comme programmeur à Haulmont. Le principal produit de l'entreprise est CUBA, une plate-forme de développement d'entreprise et de diverses applications Web. En particulier, des projets d'impartition sont en cours sur cette plate-forme, parmi lesquels il y a eu récemment un projet dans le domaine de l'éducation, dans lequel Ivan s'est engagé à établir un calendrier pour un établissement d'enseignement. Il se trouve que depuis trois ans, Ivan travaille avec les planificateurs d'une manière ou d'une autre, et spécifiquement à Haulmont, ils testent ce planificateur depuis un an.
Pour ceux qui veulent exécuter des exemples -
gardez un lien vers GitHub . Sous le lien, vous trouverez tout le code que nous allons analyser, exécuter et écrire aujourd'hui. Ouvrez le code et c'est parti!

Aujourd'hui, nous discuterons:
- quelles sont les langues axées sur les problèmes;
- langages intégrés axés sur les problèmes;
- établir un horaire pour un établissement d'enseignement;
- comment tout est testé avec Kotlin.
Aujourd'hui, je vais parler en détail des outils que nous avons dans la langue, vous montrer quelques démos, et nous écrirons tout le test du début à la fin. Dans le même temps, je voudrais être plus objectif, je vais donc parler de certains des inconvénients que je me suis identifiés lors du développement.
Commençons par parler du module de création de planning. Ainsi, la construction du planning se déroule en plusieurs étapes. Chacune de ces étapes doit être testée séparément. Vous devez comprendre que malgré le fait que les étapes sont différentes, nous avons un modèle de données commun.

Ce processus peut être représenté comme suit: à l'entrée, il y a des données avec un modèle commun, à la sortie, il y a un calendrier. Les données sont validées, filtrées, puis des groupes de formation sont créés. Il s'agit de la matière de l'horaire de l'établissement d'enseignement. Sur la base des groupes construits et sur la base d'autres données, nous plaçons la leçon. Aujourd'hui, nous ne parlerons que de la dernière étape - du placement des classes.

Un peu sur le test du planificateur.
Tout d'abord, comme vous l'avez déjà compris, les différentes étapes doivent être testées séparément. On peut distinguer un processus de test plus ou moins standard: il y a l'initialisation des données, il y a un lancement du planificateur, il y a une vérification des résultats de ce planificateur lui-même. Il existe un grand nombre d'analyses de rentabilisation différentes qui doivent être couvertes et différentes situations qui doivent être prises en compte afin que lors de la création d'un calendrier, ces situations persistent également.
Un modèle peut parfois être lourd, et pour créer une seule entité, il est nécessaire d'initialiser cinq entités supplémentaires, voire plus. Ainsi, au total, une grande quantité de code est obtenue, que nous écrivons encore et encore pour chaque test. La prise en charge de ces tests prend beaucoup de temps. Si vous souhaitez mettre à jour le modèle, et cela se produit parfois, l'échelle des modifications affecte les tests.
Écrivons un test:

Écrivons le test le plus simple pour que vous compreniez généralement l'image.
Qu'est-ce qui vous vient à l'esprit lorsque vous pensez aux tests? Ce sont peut-être des tests primitifs de ce type: vous créez une classe, créez une méthode dedans, marquez-la avec le
test d' annotation. En conséquence, nous utilisons les capacités de JUnit, et initialisons certaines données, valeurs par défaut, puis valeurs spécifiques aux tests, faisons de même pour le reste du modèle, et enfin créons un objet ordonnanceur, transférez-y nos données, nous commençons, nous recevons des résultats et nous les vérifions. Processus plus ou moins standard. Mais il y a évidemment duplication de code. La première chose qui me vient à l'esprit est la possibilité de tout mettre en méthodes statiques. Puisqu'il y a un tas de valeurs par défaut, pourquoi ne pas le cacher?

C'est une bonne première étape vers la réduction de la duplication.

En regardant cela, vous comprenez que je voudrais garder le modèle plus compact. Ici, nous avons un modèle de générateur dans lequel, quelque part sous le capot, la valeur par défaut est initialisée et les valeurs spécifiques au test sont initialisées juste là. Cela va mieux, cependant, nous écrivons toujours le code passe-partout, et nous le réécrivons à chaque fois. Imaginez 200 tests - vous devez écrire ces trois lignes 200 fois. Évidemment, je voudrais me débarrasser de cela d'une manière ou d'une autre. En développant l'idée, nous arrivons à une certaine limite. Ainsi, par exemple, nous pouvons créer un générateur de modèles en général pour tout.

Vous pouvez créer un planificateur de A à Z jusqu'à la fin, définir toutes les valeurs dont nous avons besoin, commencer la planification et tout est super. Si vous regardez cet exemple en détail et l'analysez en détail, il s'avère que beaucoup de code inutile est en cours d'écriture. Je voudrais rendre les tests plus lisibles afin que vous puissiez y jeter un coup d'œil et les comprendre immédiatement, sans plonger dans les schémas, etc.
Donc, nous avons du code inutile. Les mathématiques simples suggèrent qu'il y a 55% de lettres de plus que ce dont nous avons besoin, et je voudrais en quelque sorte m'en éloigner.

Après un certain temps, la prise en charge de nos tests s'avère plus coûteuse, car vous devez prendre en charge plus de code. Parfois, si nous ne faisons aucun effort, la lisibilité laisse beaucoup à désirer, ou elle s'avère acceptable, mais nous aimerions encore mieux. Peut-être que plus tard, nous commencerons à ajouter une sorte de frameworks, bibliothèques, pour rendre les tests plus faciles à écrire. Pour cette raison, nous augmentons le niveau d'entrée dans le test de notre application. Ici, nous avons une application déjà compliquée, le niveau d'entrée dans ses tests est important et nous l'augmentons encore plus.
Test parfait
C'est génial de dire à quel point tout est mauvais, mais réfléchissons à la façon dont ce serait très bien. Un exemple idéal que nous aimerions obtenir en conséquence:

Imaginez qu'il y ait une déclaration dans laquelle nous disons que c'est un test avec un nom spécifique, et nous voulons utiliser un espace pour séparer les mots dans le nom, pas CamelCase. Nous construisons un calendrier, nous avons des données et les résultats du planificateur sont vérifiés. Étant donné que nous travaillons principalement avec Java et que tout le code de l'application principale est écrit dans ce langage, j'aimerais avoir des capacités de test compatibles. Je voudrais initialiser les données aussi clairement que possible pour le lecteur. Je veux initialiser certaines données communes et une partie du modèle dont nous avons besoin. Par exemple, créez des élèves, des enseignants et décrivez quand ils sont disponibles. Ceci est notre parfait exemple.
Langue spécifique au domaine

En regardant tout cela, il commence à ressembler à une sorte de langage orienté vers les problèmes. Vous devez comprendre ce que c'est et quelle est la différence. Les langues peuvent être divisées en deux types: les langues à usage général (ce que nous écrivons constamment, résolvent absolument toutes les tâches et font face à absolument tout) et les langues axées sur les problèmes. Ainsi, par exemple, SQL nous aide à extraire parfaitement les données de la base de données, et certains autres langages aident également à résoudre d'autres problèmes spécifiques.

Une façon d'implémenter des langages orientés problème est les langages intégrés, ou internes. Ces langues sont implémentées sur la base d'une langue à usage général. Autrement dit, plusieurs constructions de notre langage polyvalent forment quelque chose comme une base - c'est ce que nous utilisons lorsque nous travaillons avec un langage orienté problème. Dans ce cas, bien sûr, une opportunité se présente dans un langage axé sur les problèmes pour utiliser toutes les fonctionnalités et fonctionnalités qui proviennent d'un langage à usage général.

Encore une fois, jetez un œil à notre exemple parfait et pensez à la langue à choisir. Nous avons trois options.

La première option est Groovy. Un langage merveilleux et dynamique qui a fait ses preuves dans la création de langages orientés problèmes. Encore une fois, vous pouvez donner un exemple de fichier de construction dans Gradle, que beaucoup d'entre nous utilisent. Il y a aussi Scala, qui offre un grand nombre de possibilités pour la mise en œuvre de quelque chose qui leur est propre. Et enfin, il y a Kotlin, qui nous aide également à construire un langage orienté problème, et aujourd'hui il sera discuté. Je ne voudrais pas multiplier les guerres et comparer Kotlin à autre chose, mais cela reste dans votre conscience. Aujourd'hui, je vais vous montrer ce que Kotlin a pour développer des langages orientés problèmes. Lorsque vous souhaitez comparer cela et dire qu'une langue est meilleure, vous pouvez revenir à cet article et voir facilement la différence.

Que nous apporte Kotlin pour développer un langage orienté problème?
Tout d'abord, c'est un typage statique, et tout ce qui en découle. Au stade de la compilation, un grand nombre de problèmes sont détectés, ce qui économise considérablement, en particulier dans le cas où vous ne souhaitez pas rencontrer de problèmes liés à la syntaxe et à l'écriture dans les tests.
Ensuite, il existe un grand système d'inférence de type qui vient de Kotlin. C'est merveilleux, car il n'est pas nécessaire d'écrire des types encore et encore, tout est affiché par le compilateur avec un bang.
Troisièmement, il existe un excellent support pour l'environnement de développement, et cela n'est pas surprenant, car la même société crée l'environnement de développement principal pour aujourd'hui, et c'est le cas de Kotlin.
Enfin, à l'intérieur de DSL, nous pouvons évidemment utiliser Kotlin. À mon avis, la prise en charge DSL est beaucoup plus facile que la prise en charge des classes utilitaires. Comme vous le verrez plus tard, la lisibilité est légèrement meilleure que celle des constructeurs. Ce que j'entends par «mieux»: vous obtenez un peu moins de syntaxe que vous devez écrire - quelqu'un qui lit votre langage orienté problème le prendra plus rapidement. Enfin, écrire votre vélo est beaucoup plus amusant! Mais en fait, l'implémentation d'un langage axé sur les problèmes est beaucoup plus facile que l'apprentissage d'un nouveau cadre.
Je rappellerai une fois de plus le
lien vers GitHub , si vous voulez écrire des démos plus loin, alors vous pouvez aller chercher le code sur le lien.
Concevoir l'idéal sur Kotlin
Passons à la conception de notre idéal, mais déjà chez Kotlin. Jetez un œil à notre exemple:

Et par étapes, nous commencerons à le reconstruire.
Nous avons un test qui se transforme en fonction dans Kotlin, qui peut être nommé en utilisant des espaces.

Nous le marquerons avec l'annotation
Test , qui est disponible pour nous depuis JUnit. Dans Kotlin, vous pouvez utiliser la forme abrégée pour écrire des fonctions et, grâce à
=, vous débarrasser des accolades supplémentaires pour la fonction elle-même.
Horaire que nous transformons en bloc. La même chose se produit avec de nombreux modèles, car nous travaillons toujours chez Kotlin.

Passons au reste. Les accolades apparaissent à nouveau, nous ne nous en débarrasserons pas, mais essayez au moins de nous rapprocher de notre exemple. En construisant des constructions avec des espaces, nous pourrions en quelque sorte nous affiner et les rendre quelque peu différents, mais il me semble qu'il vaut mieux faire les méthodes habituelles qui encapsuleront le traitement, mais en général cela sera évident pour l'utilisateur .

Notre étudiant se transforme en un bloc dans lequel nous travaillons avec des propriétés, avec des méthodes, et nous continuerons à analyser cela avec vous.

Enfin, les enseignants. Ici, nous avons quelques blocs imbriqués.

Dans le code ci-dessous, nous passons aux contrôles. Nous avons besoin de vérifier la compatibilité avec les langages Java - et oui, Kotlin est compatible avec Java.

Arsenal de développement DSL à Kotlin

Passons à la liste des outils dont nous disposons. Ici, j'ai apporté une tablette, elle répertorie peut-être tout ce qui est nécessaire pour développer des langages axés sur les problèmes dans Kotlin. Vous pouvez lui revenir de temps en temps et lui rafraîchir la mémoire.
Le tableau présente une comparaison de la syntaxe orientée problème et de la syntaxe habituelle disponible dans la langue.
Lambdas à Kotlin
val lambda: () -> Unit = { }Commençons par la brique la plus élémentaire que nous ayons dans Kotlin - ce sont des lambdas.
Aujourd'hui, par type lambda, je veux dire juste un type fonctionnel. Les lambdas sont dénotés comme suit:
( ) -> .
Nous initialisons le lambda à l'aide d'accolades, à l'intérieur, nous pouvons écrire du code qui sera appelé. Autrement dit, un lambda, en fait, cache simplement ce code en lui-même. L'exécution d'un tel lambda ressemble à un appel de fonction, juste des parenthèses.

Si nous voulons passer une sorte de paramètre, premièrement, nous devons le décrire dans le type.
Deuxièmement, nous avons accès à l'identifiant par défaut, que nous pouvons utiliser, cependant, si cela ne nous convient pas, nous pouvons définir notre propre nom de paramètre et les utiliser.

Dans le même temps, nous pouvons ignorer l'utilisation de ce paramètre et utiliser le trait de soulignement afin de ne pas produire d'identifiants. Dans ce cas, pour ignorer l'identifiant, il serait possible de ne rien écrire du tout, mais dans le cas général pour plusieurs paramètres il y a le "_" mentionné.

Si nous voulons passer plus d'un paramètre, nous devons définir explicitement leurs identifiants.

Enfin, que se passera-t-il si nous essayons de passer le lambda à une fonction et de l'exécuter là-bas. Il ressemble à l'approximation initiale comme suit: nous avons une fonction à laquelle nous passons lambda entre accolades, et si dans Kotlin lambda est écrit comme dernier paramètre, nous pouvons en quelque sorte le mettre hors de ces accolades.

S'il ne reste plus rien entre crochets, nous pouvons supprimer les crochets. Ceux qui connaissent Groovy devraient le savoir.

Où cela s'applique-t-il? Absolument partout. Autrement dit, les accolades très bouclés dont nous avons déjà parlé, nous les utilisons, ce sont les lambdas mêmes.

Maintenant, regardons une des variétés de lambdas, je les appelle lambdas avec contexte. Vous trouverez d'autres noms, par exemple, lambda avec récepteur, et ils diffèrent des lambdas ordinaires lors de la déclaration d'un type comme suit: à gauche, nous ajoutons une classe de contexte, il peut s'agir de n'importe quelle classe.

À quoi ça sert? Ceci est nécessaire pour qu'à l'intérieur du lambda nous ayons accès au mot-clé this - c'est le mot-clé lui-même, il nous indique notre contexte, c'est-à-dire à un objet que nous avons lié à notre lambda. Ainsi, par exemple, nous pouvons créer un lambda qui produira une chaîne, naturellement, nous utiliserons la classe de chaîne pour déclarer un contexte et l'appel d'un tel lambda ressemblera à ceci:



Si vous souhaitez passer un contexte en tant que paramètre, vous pouvez également le faire. Cependant, nous ne pouvons pas transmettre complètement le contexte, c'est-à-dire qu'une lambda avec un contexte nécessite une attention! - le contexte, oui. Que se passe-t-il si nous commençons à passer un lambda avec un contexte à une méthode? Ici, nous regardons à nouveau notre méthode exec:

Renommez-le en méthode étudiant - rien n'a changé:

Nous passons donc progressivement à notre construction, la construction étudiante, qui sous les accolades cache toute l'initialisation.

Voyons cela. Nous avons une sorte de fonction étudiant qui prend un lambda avec le contexte étudiant.

De toute évidence, nous avons besoin de contexte.

Ici, nous créons un objet et exécutons ce lambda dessus.

Par conséquent, nous pouvons également initialiser certaines valeurs par défaut avant de lancer le lambda, nous encapsulons donc tout ce dont nous avons besoin pour la fonction.

Pour cette raison, à l'intérieur du lambda, nous avons accès au mot-clé this - c'est pourquoi, probablement, il y a des lambdas avec contexte.

Naturellement, nous pouvons nous débarrasser de ce mot-clé et nous avons la possibilité d'écrire de telles constructions.

Encore une fois, si nous avons non seulement des méthodes propriétaires, mais aussi certaines méthodes, nous pouvons également les appeler, cela semble assez naturel.

Candidature
Tous ces lambdas dans le code sont des lambdas de contexte. Il existe un grand nombre de contextes, ils se recoupent d'une manière ou d'une autre et nous permettent de construire notre langage orienté problème.

Résumant les lambdas - nous avons des lambdas ordinaires, il y en a avec le contexte, et ceux-ci et d'autres peuvent être utilisés.

Les opérateurs
Kotlin dispose d'un ensemble limité d'opérateurs que vous pouvez remplacer à l'aide des conventions et du mot clé operator.
Regardons l'enseignant et son accessibilité. Supposons que nous disons que l'enseignant travaille le lundi à partir de 8 heures du matin pendant 1 heure. Nous voulons également dire que, en plus de cette heure, cela fonctionne à partir de 13h00 pendant 1 heure. Je voudrais exprimer cela en utilisant l'opérateur
+ . Comment cela peut-il se faire?

Il existe une méthode de disponibilité qui accepte un lambda avec un contexte
AvailabilityTable . Cela signifie qu'il existe une classe qui s'appelle ainsi et que la méthode du lundi est déclarée dans cette classe. Cette méthode renvoie
DayPointer depuis vous devez attacher notre opérateur à quelque chose.

Voyons ce qu'est DayPointer. Ceci est un pointeur vers le tableau de disponibilité de certains enseignants, et la journée est à son horaire. Nous avons également une fonction temporelle qui transformera en quelque sorte certaines lignes en indices entiers: dans Kotlin, nous avons une classe
IntRange pour cela.
À gauche se trouve
DayPointer , à droite se trouve le temps, et nous aimerions les combiner avec l'opérateur
+ . Pour ce faire, vous pouvez créer notre opérateur dans la classe
DayPointer . Il faudra une plage de valeurs de type Int et retourner
DayPointer pour que nous puissions enchaîner notre DSL encore et encore.
Maintenant, jetons un coup d'œil à la conception clé par laquelle tout commence, par laquelle commence notre DSL. Sa mise en œuvre est légèrement différente, et maintenant nous allons le découvrir.
Kotlin a un concept singleton intégré à la langue. Pour ce faire, au lieu du mot-clé class, le mot-clé
object est utilisé. Si nous créons une méthode à l'intérieur d'un singleton, nous pouvons y accéder de telle manière qu'il n'est pas nécessaire de recréer une instance de cette classe. Nous nous y référons simplement comme une méthode statique dans une classe.

Si vous regardez le résultat de la décompilation (c'est-à-dire, dans l'environnement de développement, cliquez sur Outils -> Kotlin -> Afficher le bytecode Kotlin -> Décompiler), vous pouvez voir l'implémentation singleton suivante:

C'est juste une classe ordinaire, et rien de surnaturel ne se passe ici.
Un autre outil intéressant est l'instruction
invoke . Imaginez que nous avons une classe A, nous avons son instance, et nous aimerions exécuter cette instance, c'est-à-dire appeler des parenthèses sur un objet de cette classe, et nous pouvons le faire grâce à l'opérateur
invoke .

En fait, les parenthèses nous permettent d'appeler la méthode invoke et ont un modificateur d'opérateur. Si nous passons un lambda avec contexte à cet opérateur, alors nous obtenons une telle construction.

La création d'instances à chaque fois est une autre activité, nous pouvons donc combiner les connaissances antérieures et actuelles.
Faisons un singleton, appelons-le planning, à l'intérieur de celui-ci nous déclarerons l'opérateur invoke, à l'intérieur nous créerons un contexte, et il acceptera un lambda avec le contexte que nous créons ici. Il s'avère qu'un seul point d'entrée dans notre DSL, et, par conséquent, nous obtenons la même construction - calendrier avec des accolades bouclés.

Eh bien, nous avons parlé de calendrier, jetons un œil à nos chèques.
Nous avons des professeurs, nous avons construit une sorte d'horaire, et nous voulons vérifier que dans l'horaire de cet enseignant un certain jour dans une certaine leçon, il y a un objet avec lequel nous allons travailler.

Je voudrais utiliser des crochets et accéder à notre calendrier d'une manière qui ressemble visuellement à l'accès aux tableaux.

Cela peut être fait en utilisant l'opérateur: get / set:

Ici, nous ne faisons rien de nouveau, suivez simplement les conventions. Dans le cas de l'opérateur set, nous devons également transmettre les valeurs à notre méthode:

Ainsi, les crochets pour la lecture se transforment en get, et les crochets à travers lesquels nous attribuons se transforment en set.
Démo: objet, opérateurs
Vous pouvez lire un texte supplémentaire ou
regarder la vidéo ici . La vidéo a une heure de début claire, mais aucune heure de fin n'est spécifiée - en principe, une fois démarrée, vous pouvez la regarder avant la fin de l'article.
Pour plus de commodité, je décrirai brièvement l'essence de la vidéo directement dans le texte.
Écrivons un test. Nous avons un objet de planification, et si nous allons à son implémentation via ctrl + b, nous verrons tout ce dont j'ai parlé auparavant.

À l'intérieur de l'objet de planification, nous voulons initialiser les données, puis effectuer quelques vérifications, et dans les données, nous aimerions dire que:
- notre école est ouverte à partir de 8 heures du matin;
- il y a un certain ensemble d'articles pour lesquels nous allons construire un calendrier;
- il y a des enseignants qui ont décrit une sorte d'accessibilité;
- avoir un étudiant;
- en principe, pour un étudiant, il suffit de dire qu'il étudie une matière spécifique.

Et ici, l'un des inconvénients de Kotlin et des langages orientés problème se manifeste en principe: il est assez difficile de traiter certains objets que nous avons créés plus tôt. Dans cette démo, je vais tout indiquer comme des indices, c'est-à-dire que rus est l'indice 0, les mathématiques est l'indice 2. Et l'enseignant dirige naturellement quelque chose. Il ne va pas seulement au travail, mais il est engagé dans quelque chose. Pour les lecteurs de cet article, je voudrais offrir une autre option pour l'adressage, vous pouvez créer des balises uniques et y stocker des entités dans Map, et lorsque vous devez accéder à l'une d'entre elles, vous pouvez toujours la trouver par balise. Continuez à démonter la DSL.
Ici, ce qu'il faut noter: tout d'abord, nous avons l'opérateur +, à la mise en œuvre duquel nous pouvons également aller et voir que nous avons effectivement la classe DayPointer, qui nous aide à lier tout cela avec l'aide de l'opérateur.
Et grâce au fait que nous avons accès au contexte, l'environnement de développement nous dit que dans notre contexte à travers le mot-clé this, nous avons accès à une collection, et nous allons l'utiliser.

Autrement dit, nous avons une collection d'événements. L'événement encapsule un ensemble de propriétés, par exemple: qu'il y a un étudiant, un enseignant, quel jour ils se rencontrent à quelle leçon.

Nous continuons à écrire le test plus loin.

Ici encore, nous utilisons l'opérateur get; ce n'est pas si facile d'accéder à son implémentation, mais nous pouvons le faire.

En fait, nous suivons simplement l'accord, nous avons donc accès à cette conception.
Revenons à la présentation et continuons la conversation sur Kotlin. Nous voulions que les contrôles soient mis en œuvre sur Kotlin, et nous avons vécu ces événements:

Un événement est essentiellement un ensemble encapsulé de 4 propriétés. Je voudrais décomposer cet événement en un ensemble de propriétés, comme un tuple. En russe, une telle construction est appelée
multi-déclaration (je n'ai trouvé qu'une telle traduction), ou
déclaration de déstructuration , et elle fonctionne comme suit:

Si l'un d'entre vous n'est pas familier avec cette fonctionnalité, cela fonctionne comme ceci: vous pouvez prendre l'événement, et à l'endroit où il est utilisé, à l'aide de parenthèses, le décomposer en un ensemble de propriétés.

Cela fonctionne parce que nous avons une méthode componentN, c'est-à-dire que c'est une méthode qui est générée par le compilateur grâce au modificateur de données que nous écrivons avant la classe.

Parallèlement à cela, un grand nombre d'autres méthodes nous parviennent. Nous nous intéressons à la méthode componentN, qui est générée à partir des propriétés listées dans la liste des paramètres du constructeur primaire.

Si nous n'avions pas de modificateur de données, il faudrait écrire manuellement un opérateur qui fera la même chose.


Donc, nous avons quelques méthodes componentN, et elles se décomposent en un tel appel:

En substance, c'est du sucre syntaxique qui fait appel à plusieurs méthodes.
Nous avons déjà parlé d'un tableau de disponibilité et, en fait, je vous ai trompé. Ça arrive. Aucune
avaiabilityTable n'existe, elle n'est pas dans la nature, mais il existe une matrice de valeurs booléennes.

Aucune classe supplémentaire n'est nécessaire: vous pouvez prendre la matrice des valeurs booléennes et la renommer pour plus de netteté. Cela peut être fait en utilisant les soi-disant
typealias ou
alias de type . Malheureusement, nous n'obtenons aucun bonus supplémentaire, c'est juste un changement de nom. Si vous prenez la disponibilité et la renommez à la matrice des valeurs booléennes, rien ne changera du tout. Le code a fonctionné et fonctionnera.
Jetons un œil au professeur, c'est exactement cette accessibilité, et parlons de lui:
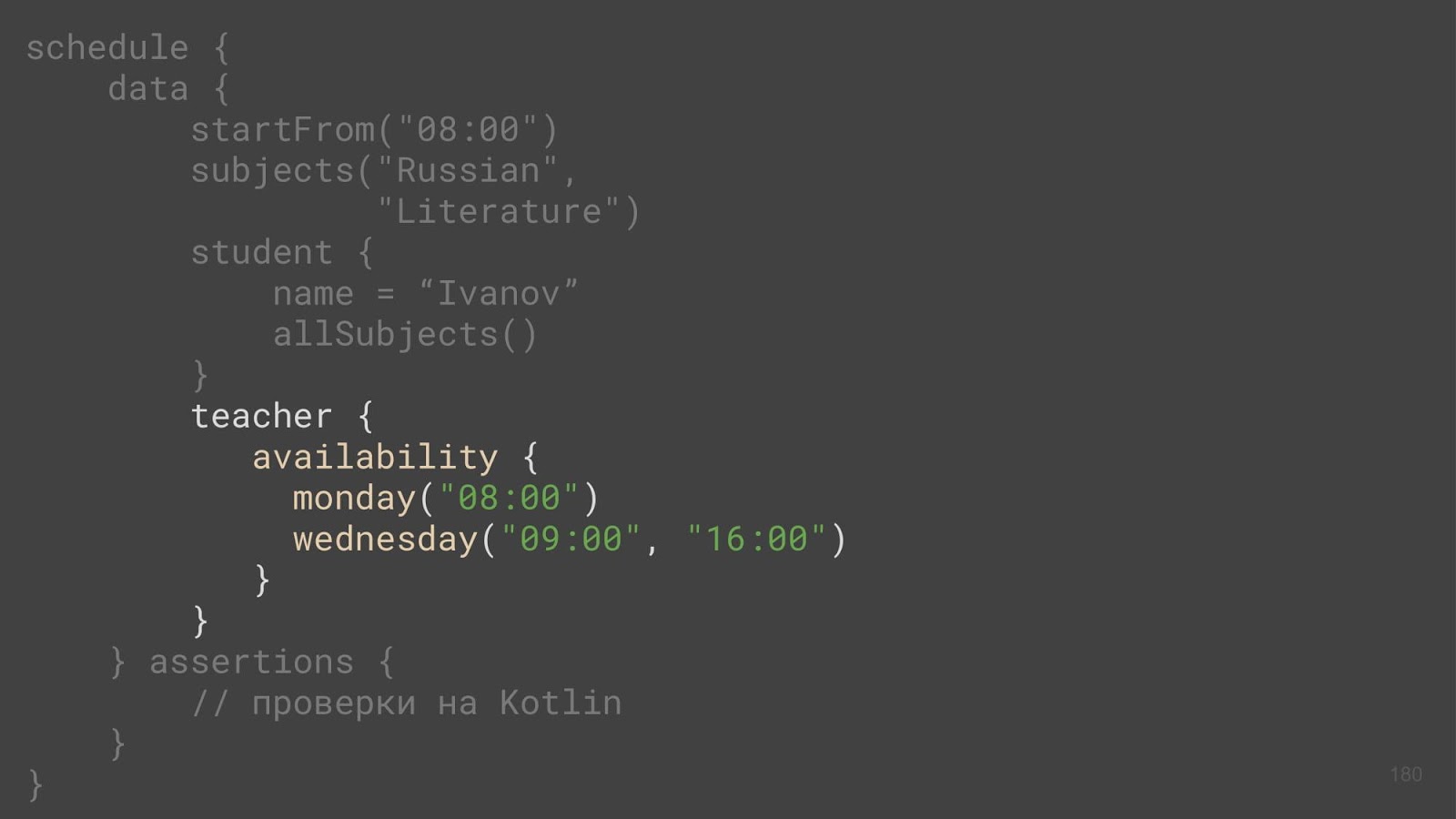
Nous avons un professeur, et la méthode de disponibilité est appelée (n'avez-vous pas encore perdu le fil du raisonnement? :-). D'où venait-il? Autrement dit, un enseignant est une sorte d'entité qui a une classe, et c'est un code d'entreprise. Et il ne peut y avoir de méthode supplémentaire.

Cette méthode apparaît en raison des fonctions d'extension. Nous prenons et attachons à notre classe une autre fonction que nous pouvons exécuter sur les objets de cette classe.
Si nous passons du lambda à cette fonction, puis l'exécutons sur une propriété existante, alors tout va bien - la méthode de disponibilité dans son implémentation initialise la propriété de disponibilité. Vous pouvez vous en débarrasser. Nous connaissons déjà l'opérateur invoke, qui peut être attaché à un type, et en même temps être une fonction d'extension. Si vous passez un lambda à cet opérateur, alors là, sur le mot-clé this, nous pouvons exécuter ce lambda. Par conséquent, lorsque nous travaillons avec un enseignant, l'accessibilité est une propriété de l'enseignant, et non une méthode supplémentaire, et aucun rassynchronisme ne se produit ici.

En prime, des fonctions d'extension peuvent être créées pour les types nullables. C'est bien, car s'il existe une variable avec un type nullable contenant une valeur nulle, notre fonction est déjà prête pour cela et ne tombera pas de NullPointer. Dans cette fonction, cela peut être nul et cela doit être géré.

Résumé des fonctions d'extension: vous devez comprendre qu'il n'y a accès qu'à l'API publique de la classe et que la classe elle-même n'est en aucune façon modifiée. Une fonction d'extension est déterminée par le type de la variable et non par le type réel. De plus, un membre de la classe avec la même signature sera priorisé. Vous pouvez créer une fonction d'extension pour une classe, mais l'écrire dans une classe complètement différente, et à l'intérieur de cette fonction d'extension, vous aurez accès à deux contextes simultanément. Il s'avère que l'intersection des contextes. Et enfin, c'est une excellente occasion de prendre et de fixer les opérateurs en général à n'importe quel endroit où nous voulons.

L'outil suivant est les fonctions d'infixation. Un autre marteau dangereux entre les mains du développeur. Pourquoi dangereux? Ce que vous voyez, c'est du code. Un tel code peut être écrit en Kotlin, et ne le faites pas! Veuillez ne pas le faire. Néanmoins, l'approche est bonne. Grâce à cela, il est possible de se débarrasser des points, des crochets - de toute cette syntaxe bruyante, dont nous essayons de nous éloigner le plus possible et de rendre notre code un peu plus propre.

Comment ça marche? Prenons un exemple plus simple - une variable entière. Créons une fonction d'extension pour cela, appelons-la shouldBeEqual, cela fera quelque chose, mais ce n'est pas intéressant. Si nous ajoutons le modificateur infixe à sa gauche, cela suffit. Vous pouvez vous débarrasser des points et des crochets, mais il y a quelques nuances.

Sur cette base, seule la construction de données et d'assertions est implémentée, attachée ensemble.

Voyons cela. Nous avons un SchedulingContext - le contexte général de la planification du démarrage. Il existe une fonction de données qui renvoie le résultat de cette planification. En même temps, nous créons une fonction d'extension et en même temps les assertions de la fonction infixe, ce qui lancera un lambda qui vérifie nos valeurs.

Il y a un sujet, un objet et une action, et vous devez en quelque sorte les connecter. Dans ce cas, le résultat de l'exécution des données avec des accolades est le sujet. La lambda que nous transmettons à la méthode des assertions est un objet, et la méthode des assertions elle-même est une action. Tout cela semble se coller.

En parlant d'infixe de fonction, il est important de comprendre qu'il s'agit d'une étape pour se débarrasser de la syntaxe bruyante. Cependant, nous devons avoir un sujet et un objet de cette action, et nous devons utiliser le modificateur infixe. Il peut y avoir exactement un paramètre - c'est-à-dire, zéro paramètre ne peut pas être, deux ne peuvent pas être, trois - eh bien, vous comprenez. Vous pouvez passer, par exemple, des lambdas à cette fonction, et de cette manière, des constructions que vous n'avez pas vues auparavant sont obtenues.
Passons à la prochaine démo. Il vaut mieux regarder la vidéo et ne pas lire le texte.
Maintenant, tout semble prêt: l'infixe de fonction que vous avez vu, l'extension de la fonction que vous avez vue, la déclaration de déstructuration est prête.
Revenons à notre présentation, et ici nous allons passer à un point assez important lors de la construction de langages orientés problème - ce à quoi vous devriez penser est le contrôle de contexte.

Il y a des situations où nous pouvons prendre DSL et le réutiliser directement à l'intérieur, mais nous ne voulons pas le faire. Notre utilisateur (peut-être un utilisateur inexpérimenté) écrit des données dans des données, et cela n'a aucun sens. Nous voudrions en quelque sorte lui interdire de le faire.
Avant Kotlin version 1.1, nous devions faire ce qui suit: en réponse au fait que nous avons une méthode de données dans
SchedulingContext , nous avons dû créer une autre méthode de données dans
DataContext , dans laquelle nous acceptons un lambda (bien que sans implémentation), nous devons marquer cette méthode annotation
@Deprecated et dire au compilateur de ne pas le compiler. Vous voyez que cette méthode démarre - ne compilez pas. En utilisant cette approche, nous obtenons même un message significatif lorsque nous écrivons du code sans signification.

Après la version Kotlin 1.1, une merveilleuse annotation
@DslMarker . Cette annotation est nécessaire pour signaler les annotations dérivées. Avec eux, à notre tour, nous délimiterons les langages axés sur les problèmes. Pour chaque langue orientée problème, vous pouvez créer une annotation que vous marquez
@DslMarker et la suspendre à chaque contexte nécessaire. Il n'est plus nécessaire d'écrire des méthodes supplémentaires dont la compilation doit être interdite - tout fonctionne simplement. Non compilé.
Cependant, il existe un tel cas particulier lorsque nous travaillons avec notre modèle commercial. Il est généralement écrit en Java.
Il y a un contexte, il y a une annotation qui doit être marquée comme contexte. Selon vous, quel est le contexte de l'élève dans la méthode? Classe Student. Ceci fait partie de notre modèle économique, Kotlin n'est pas là.
 Nous aimerions également contrôler cette situation, car dans ce cas, il y a accès au design suivant: créer un étudiant à l'intérieur des étudiants. Je ne veux pas vous amener à faire des associations incorrectes, mais nous voulons l'interdire, c'est faux.
Nous aimerions également contrôler cette situation, car dans ce cas, il y a accès au design suivant: créer un étudiant à l'intérieur des étudiants. Je ne veux pas vous amener à faire des associations incorrectes, mais nous voulons l'interdire, c'est faux. Nous avons trois options.
Nous avons trois options.- Créez tout un contexte responsable pour notre élève. Appelons cela StudentContext. Nous décrivons toutes les propriétés là-bas, puis nous allons créer un étudiant sur la base de celui-ci. Une sorte de folie - un tas de code est en cours d'écriture, probablement plus que pour la production.
- – , , . . StudentContext , IStudent . , Student, IStudent StudentContext. DslMarker , .
- : deprecated . , . , . extension-, . .
 Ainsi, même à ce niveau, vous pouvez contrôler le contexte, mais avec certaines limitations qui doivent être contournées.
Ainsi, même à ce niveau, vous pouvez contrôler le contexte, mais avec certaines limitations qui doivent être contournées. Résumé sur le contrôle de contexte. Protégez vos utilisateurs contre les erreurs. Il est clair que les utilisateurs ne commettront pas d'erreurs, car cela est évident, mais il est toujours souhaitable de le contrôler. De plus, la mise en place d'un tel contrôle ne prend pas autant de temps et d'argent. Utilisez l'annotation @DslMarker avec laquelle vous marquez vos propres annotations. Dans les situations où vous ne pouvez pas utiliser l'annotation @DslMarker, utilisez l'annotation @Deprecated, cela vous aidera à contourner les cas qui ne fonctionnent pas encore.Ainsi, la démo de contrôle de contexte:
Résumé sur le contrôle de contexte. Protégez vos utilisateurs contre les erreurs. Il est clair que les utilisateurs ne commettront pas d'erreurs, car cela est évident, mais il est toujours souhaitable de le contrôler. De plus, la mise en place d'un tel contrôle ne prend pas autant de temps et d'argent. Utilisez l'annotation @DslMarker avec laquelle vous marquez vos propres annotations. Dans les situations où vous ne pouvez pas utiliser l'annotation @DslMarker, utilisez l'annotation @Deprecated, cela vous aidera à contourner les cas qui ne fonctionnent pas encore.Ainsi, la démo de contrôle de contexte:
Inconvénients et problèmes
Tout d'abord, la réutilisation de pièces DSL. Aujourd'hui, vous avez déjà vu que l'adressage d'entités créées en utilisant DSL peut être problématique. Il existe des moyens de contourner cela, mais il est conseillé d'y penser à l'avance afin d'avoir un plan pour cela.Imaginez que vous ayez un morceau de code et que vous vouliez simplement le répéter, par exemple, dans un cycle pour pouvoir créer des étudiants, plusieurs, plusieurs fois les mêmes étudiants ou toute autre entité. Comment faire Vous pouvez utiliser la boucle for - pas la meilleure option. Vous pouvez créer une méthode supplémentaire à l'intérieur de votre DSL, et ce sera une meilleure solution, cependant, vous devrez résoudre ces problèmes directement au niveau DSL. Attention au mot-clé this et à la dénomination par défaut du paramètre it. Heureusement, avec la version Kotlin du plugin 1.2.20, nous avons des indices qui sont visibles directement dans l'environnement de développement. Le code gris nous indique dans quel contexte nous travaillons ou de quoi il s'agit.L'imbrication peut être un problème. Vous avez construit une belle DSL, mais l'initialisation du modèle va plus loin, plus profondément, plus profondément et, par conséquent, vous utilisez souvent un défilement horizontal plutôt que vertical. Il est conseillé de masquer les valeurs par défaut sous l'implémentation par défaut. Un utilisateur qui a juste besoin d'un étudiant ne veut rien savoir d'un programme de formation, ni rien d'autre, il veut juste créer un étudiant sans détails, ne veut même pas indiquer de nom. Essayez de raccourcir la syntaxe. Par exemple, spécifiez des valeurs par défaut, passez un lambda vide, etc.Enfin, la documentation. À mon avis subjectif, la meilleure documentation pour votre langue orientée problème est plus que le nombre d'exemples de cette DSL. Super quand vous avez des quais Kotlin, c'est un bon bonus. Cependant, si l'utilisateur DSL n'a aucune idée des modèles disponibles, lui et les quais Kotlin n'ont nulle part où aller. Avez-vous déjà ressenti cela? Lorsque vous venez d'écrire un fichier Gradle au tout début, vous ne comprenez pas ce qu'il contient et vous avez besoin d'exemples. Vous ne vous souciez pas des contextes, vous voulez des exemples, et c'est la meilleure documentation qui peut être utilisée par les nouveaux utilisateurs de votre DSL. Ne mettez pas DSL dans toutes les fissures, s'il vous plaît. Je veux vraiment le faire lorsque vous possédez cet outil. Je veux dire, créons une DSL ici, peut-être ici et ici. Premièrement, c'est un travail ingrat. Deuxièmement, il est toujours souhaitable de l'appliquer à destination. Où cela vous aide vraiment à résoudre un problème.Enfin, apprenez Kotlin. Explorez les possibilités offertes par ce langage, de nouvelles fonctions, pour que votre code soit plus propre, plus court, plus compact, il sera beaucoup plus facile à lire. Et lorsque vous revenez aux tests (par exemple, vous avez ajouté quelque chose, vous devez faire un test pour cela), vous serez beaucoup plus heureux de le faire car DSL est aussi compact et confortable que possible, et vous n'avez aucun problème à en créer une douzaine étudiants. En quelques lignes, cela se fait.Entraînez-vous sur les "chats" en tant que héros d'un film célèbre. À mon avis, au début, il est plus facile d'amener Kotlin à votre projet en tant que test. C'est une bonne occasion de vérifier la langue, de l'essayer, de regarder ses fonctionnalités. C'est un tel champ de bataille où même si rien ne fonctionne, ça va, vous pouvez toujours l'utiliser.Enfin, préconfigurez la DSL. Aujourd'hui, j'ai montré un exemple parfait et nous avons marché par étapes pour créer un langage axé sur les problèmes. Si vous pré-concevez le DSL, ce sera finalement beaucoup plus facile, vous ne le remodelerez pas 10 fois, vous ne vous inquiétez pas que les contextes se chevauchent en quelque sorte et sont logiquement fortement connectés. Pré-concevez simplement la DSL - il est assez facile de le faire sur un morceau de papier lorsque vous connaissez l'ensemble des dessins que je vous ai dit aujourd'hui.Et enfin, des contacts pour la communication. Je m'appelle Ivan Osipov, télégramme: @ivan_osipov , Twitter: @_osipov_ , Habr: i_osipov . J'attendrai vos commentaires.
Ne mettez pas DSL dans toutes les fissures, s'il vous plaît. Je veux vraiment le faire lorsque vous possédez cet outil. Je veux dire, créons une DSL ici, peut-être ici et ici. Premièrement, c'est un travail ingrat. Deuxièmement, il est toujours souhaitable de l'appliquer à destination. Où cela vous aide vraiment à résoudre un problème.Enfin, apprenez Kotlin. Explorez les possibilités offertes par ce langage, de nouvelles fonctions, pour que votre code soit plus propre, plus court, plus compact, il sera beaucoup plus facile à lire. Et lorsque vous revenez aux tests (par exemple, vous avez ajouté quelque chose, vous devez faire un test pour cela), vous serez beaucoup plus heureux de le faire car DSL est aussi compact et confortable que possible, et vous n'avez aucun problème à en créer une douzaine étudiants. En quelques lignes, cela se fait.Entraînez-vous sur les "chats" en tant que héros d'un film célèbre. À mon avis, au début, il est plus facile d'amener Kotlin à votre projet en tant que test. C'est une bonne occasion de vérifier la langue, de l'essayer, de regarder ses fonctionnalités. C'est un tel champ de bataille où même si rien ne fonctionne, ça va, vous pouvez toujours l'utiliser.Enfin, préconfigurez la DSL. Aujourd'hui, j'ai montré un exemple parfait et nous avons marché par étapes pour créer un langage axé sur les problèmes. Si vous pré-concevez le DSL, ce sera finalement beaucoup plus facile, vous ne le remodelerez pas 10 fois, vous ne vous inquiétez pas que les contextes se chevauchent en quelque sorte et sont logiquement fortement connectés. Pré-concevez simplement la DSL - il est assez facile de le faire sur un morceau de papier lorsque vous connaissez l'ensemble des dessins que je vous ai dit aujourd'hui.Et enfin, des contacts pour la communication. Je m'appelle Ivan Osipov, télégramme: @ivan_osipov , Twitter: @_osipov_ , Habr: i_osipov . J'attendrai vos commentaires.Minute de publicité. JPoint — , 19-20 - Joker 2018 — Java-. . , .