Quoi de plus désagréable que le "test rouge"? Le test est soit vert soit rouge, et on ne sait pas pourquoi. Lors de notre conférence Heisenbug 2017 à Moscou,
Andrei Solntsev (Codeborne) a expliqué pourquoi ils pouvaient survenir et comment réduire leur nombre. Les exemples de son rapport sont tels que vous ressentez la douleur directement dans la peau lorsque vous entrez en collision avec eux. Et les conseils sont utiles - et cela vaut la peine de faire la connaissance des testeurs et des développeurs. Il y a quelque chose d'inattendu: vous pouvez découvrir comment parfois vous pouvez résoudre un problème si vous vous éloignez de l'écran et jouez des cubes avec votre fille.
En conséquence, le public a apprécié le rapport et nous avons décidé non seulement de publier la vidéo, mais aussi de faire une version texte du rapport pour Habr.
À mon avis, les tests feuilletés sont le sujet le plus pertinent dans le monde de l'automatisation. Parce que la question "qu'est-ce qui se fait dans le monde, comment faites-vous avec l'automatisation?" tous répondent: «Il n'y a pas de stabilité! Nos tests tombent périodiquement. »
Vous avez effectué un test chez vous, il est vert, encore deux jours verts, puis une fois et tout à coup tombé sur Jenkins. Vous essayez de le répéter, de le démarrer et il redevient vert. Et au final, on ne sait jamais: est-ce un bug ou est-ce juste un test au glucane? Et chaque fois que vous devez comprendre.
Souvent, après un lancement nocturne de tests sur Jenkins, le testeur voit d'abord "30 tests sont tombés, vous devez étudier", mais tout le monde sait ce qui se passe ensuite ...

Vous avez bien sûr deviné quel mot indécent déguisé: "Je vais recommencer". Comme, "aujourd'hui, il n'y a aucune réticence à comprendre ..." C'est comme ça que ça se passe habituellement, et c'est un vrai désastre.
Il n'y a pas de statistiques exactes, mais j'ai souvent entendu des gens différents dire qu'ils avaient environ 30% des tests - floconneux. En gros, ils en lancent un millier, dont 300 sont périodiquement rouges, puis ils vérifient avec leurs mains s'ils sont effectivement tombés.
Google a publié
un article il y a quelques années: il dit qu'ils ont 1,5% de tests floconneux et explique comment ils se battent pour réduire leur nombre. Je peux me vanter un peu et dire que mon projet chez Codeborne est maintenant de 0,1%. Mais en fait, tout cela est mauvais, même 0,1%. Pourquoi?
Prenez 1,5%, ce chiffre semble faible, mais qu'est-ce que cela signifie en pratique? Disons qu'il y a mille tests dans un projet. Cela peut signifier que 15 tests sont tombés dans une version, les 12 suivants, puis 18. Et c'est terriblement mauvais, car dans ce cas, presque toutes les versions sont rouges, et vous devez constamment vérifier avec vos mains si c'est vrai ou non.
Et même notre ppm (0,1%) est toujours mauvais. Supposons que nous ayons 1000 tests, alors 0,1% signifie que régulièrement un build sur dix tombe avec 1-2 tests rouges. Voici la vraie image de notre Jenkins, et il s'avère: avec un run, un test feuilleté est tombé, avec un autre départ un autre.
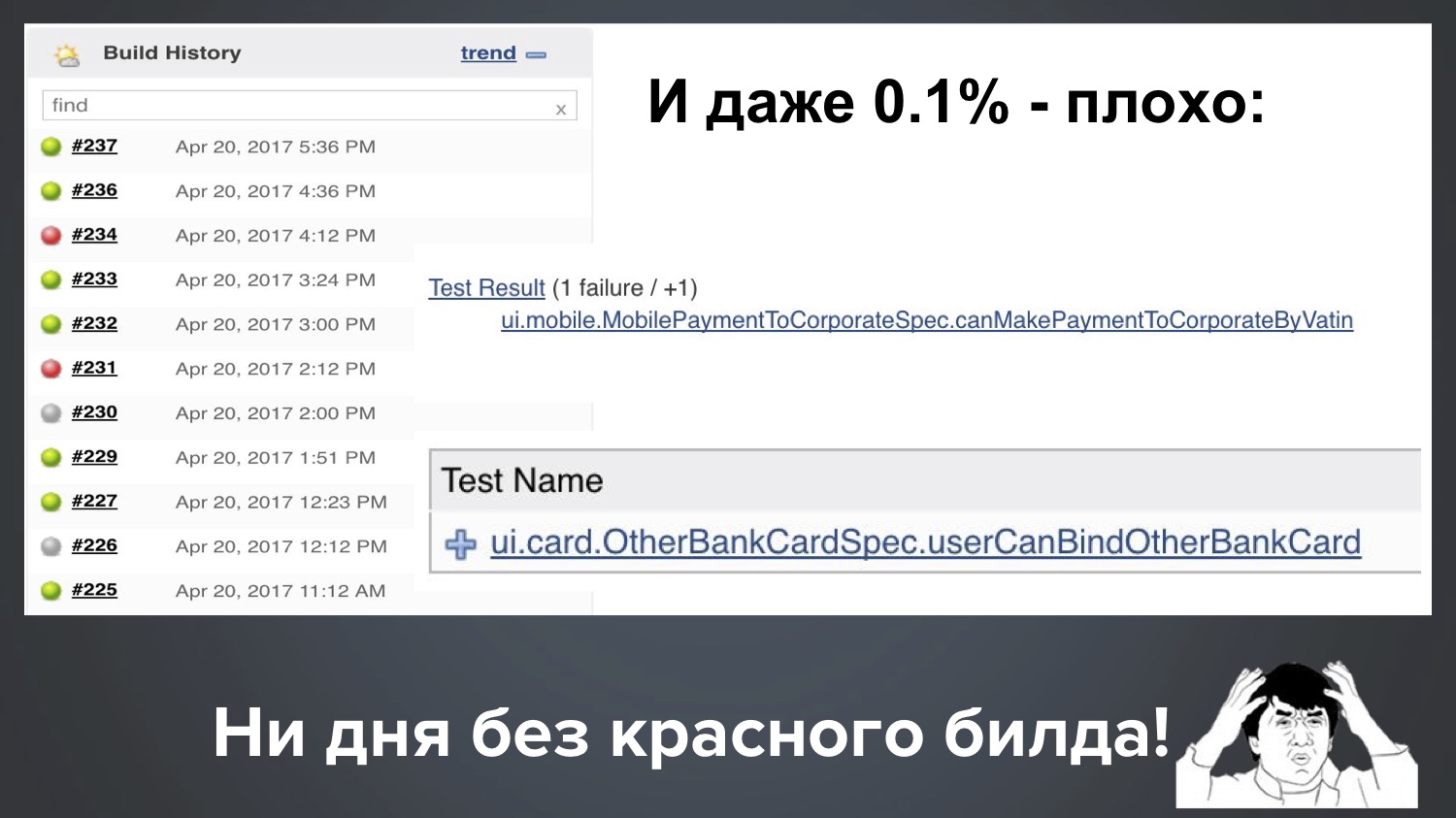
Il s’avère que nous n’avons pas de journée sans construction rouge. Puisqu'il y a beaucoup de vert, tout semble aller bien, mais le client a le droit de nous demander: "Les gars, nous vous payons de l'argent, et vous nous fournissez toujours du rouge!" Que fais-tu? "
Je serais insatisfait chez le client et expliquer "en général, c'est normal dans l'industrie, tout est rouge pour tout le monde" n'est pas bon, non? Par conséquent, à mon avis, il s'agit d'un problème très urgent, et essayons de comprendre ensemble comment y faire face.
Le plan est le suivant:
- Ma collection de tests instables (de ma pratique, des cas absolument réels, des histoires de détective complexes et intéressantes)
- Causes d'instabilité (certains ont même mis des années à rechercher)
- Comment y faire face? (j'espère que ce sera la partie la plus utile)
Commençons donc avec ma collection, que j'apprécie beaucoup: cela m'a coûté de nombreuses heures de vie et de débogage. Commençons par un exemple simple.
Exemple 1: classique
Pour les semences - le script classique de sélénium:
driver.navigate().to("https://www.google.com/"); driver.findElement(By.name("q")).sendKeys("selenide"); driver.findElement(By.name("btnK")).click(); assertEquals(9, driver.findElements(By.cssSelector("#ires .g")).size());
- Nous ouvrons WebDriver;
- Trouvez l'élément q, entrez le mot pour y chercher;
- Trouvez l'élément «Button» et cliquez;
- Vérifiez que la réponse est de neuf résultats.
Question: quelle ligne peut casser ici?
C'est vrai, nous le savons tous bien! N'importe quelle ligne peut casser, pour des raisons complètement différentes:
La première ligne est l'Internet lent, le service est tombé en panne, les administrateurs n'ont pas configuré quelque chose.
La deuxième ligne - l'élément n'a pas encore eu le temps de s'afficher s'il est dessiné dynamiquement.
Qu'est-ce qui pourrait casser en troisième ligne? Ici, c'était inattendu pour moi: j'ai écrit ce test pour la conférence, l'ai exécuté localement et il est tombé sur la troisième ligne avec cette erreur:

Cela signifie que l'élément à ce stade n'est pas cliquable. Il semblerait qu'un simple formulaire Google de base. Le secret était que dans la deuxième ligne, nous avons frappé le mot, et pendant que nous le saisissions, Google a déjà trouvé les premiers résultats, a montré les premiers résultats dans une telle fenêtre pop-up, et ils ont fermé le bouton suivant. Et cela ne se produit pas dans tous les navigateurs et pas toujours. Cela m'est arrivé avec ce script environ une fois sur cinq.
La quatrième ligne peut tomber, par exemple, car cet élément est dessiné dynamiquement et n'a pas encore eu le temps de dessiner.
Dans cet exemple, je veux dire que, selon mon expérience, 90% des tests feuilletés sont basés sur les mêmes raisons:
- Ajax demande la vitesse: parfois, ils fonctionnent plus lentement, parfois plus vite;
- L'ordre des demandes Ajax;
- Vitesse js.
Heureusement, il existe un remède pour ces raisons!
Selenide résout ces problèmes. Comment décide-t-il? Nous réécrivons notre test Google sur Selenide - presque tout y ressemble, seuls les signes $ sont utilisés:
@Test public void userCanLogin() { open(“http:
Ce test passe toujours. Étant donné que les méthodes setValue (), click () et shouldHave () sont intelligentes: si quelque chose n'a pas le temps de peindre, elles attendent un peu et réessayent (c'est ce qu'on appelle des «attentes intelligentes»).
Si vous regardez un peu plus en détail, alors toutes ces méthodes devraient * sont intelligentes:

Ils peuvent attendre si nécessaire. Par défaut, ils attendent jusqu'à 4 secondes, et ce délai, bien sûr, est configurable, vous pouvez en spécifier un autre. Par exemple, comme ceci: mvn -Dselenide.timeout = 8000.
Exemple 2: nbob
Ainsi, 90% des problèmes avec les tests feuilletés sont résolus avec Selenide. Mais 10% des cas beaucoup plus sophistiqués restent avec des raisons complexes et déroutantes. C'est précisément à propos d'eux que je veux parler aujourd'hui, car c'est une telle «zone grise». Permettez-moi de vous donner un exemple: un test feuilleté, que j'ai immédiatement rencontré dans un nouveau projet. À première vue, cela ne peut tout simplement pas se produire, mais c'est quelque chose d'intéressant.
Nous avons testé l'application clavier pour la connexion dans les kiosques. Le test voulait se connecter en tant qu'utilisateur "bob", c'est-à-dire entrer trois lettres dans le champ "login": bob. Pour ce faire, les boutons à l'écran ont été utilisés. En règle générale, cela a fonctionné, mais parfois le test s'est écrasé, et la valeur "nbob" est restée dans le champ "login":

Naturellement, vous avez du mal à chercher par le code où nous aurions pu écrire "nbob" - mais dans tout le projet ce n'est pas du tout (ni dans la base de données, ni dans le code, ni même dans les fichiers Excel). Comment est-ce possible?
Nous regardons le code plus en détail - il semblerait que tout est simple, sans énigmes:
@Test public void loginKiosk() { open(“http:
Nous avons commencé à débattre davantage, à aller pas à pas, et avec cette méthode, nous avons réussi à comprendre: cette erreur apparaît parfois après la ligne $ («body»). Cliquez sur (). Autrement dit, à cette étape, «n» apparaît dans le champ «connexion», puis «bob» est ajouté aux étapes suivantes. Qui a déjà deviné d'où vient "n"?
Il se trouve que la lettre N était au milieu de l'écran, et la fonction click () au moins dans Chrome fonctionne comme ceci: elle calcule la coordonnée centrale d'un élément et clique dessus. Puisque le corps est un grand élément, elle a cliqué au centre de tout l'écran.
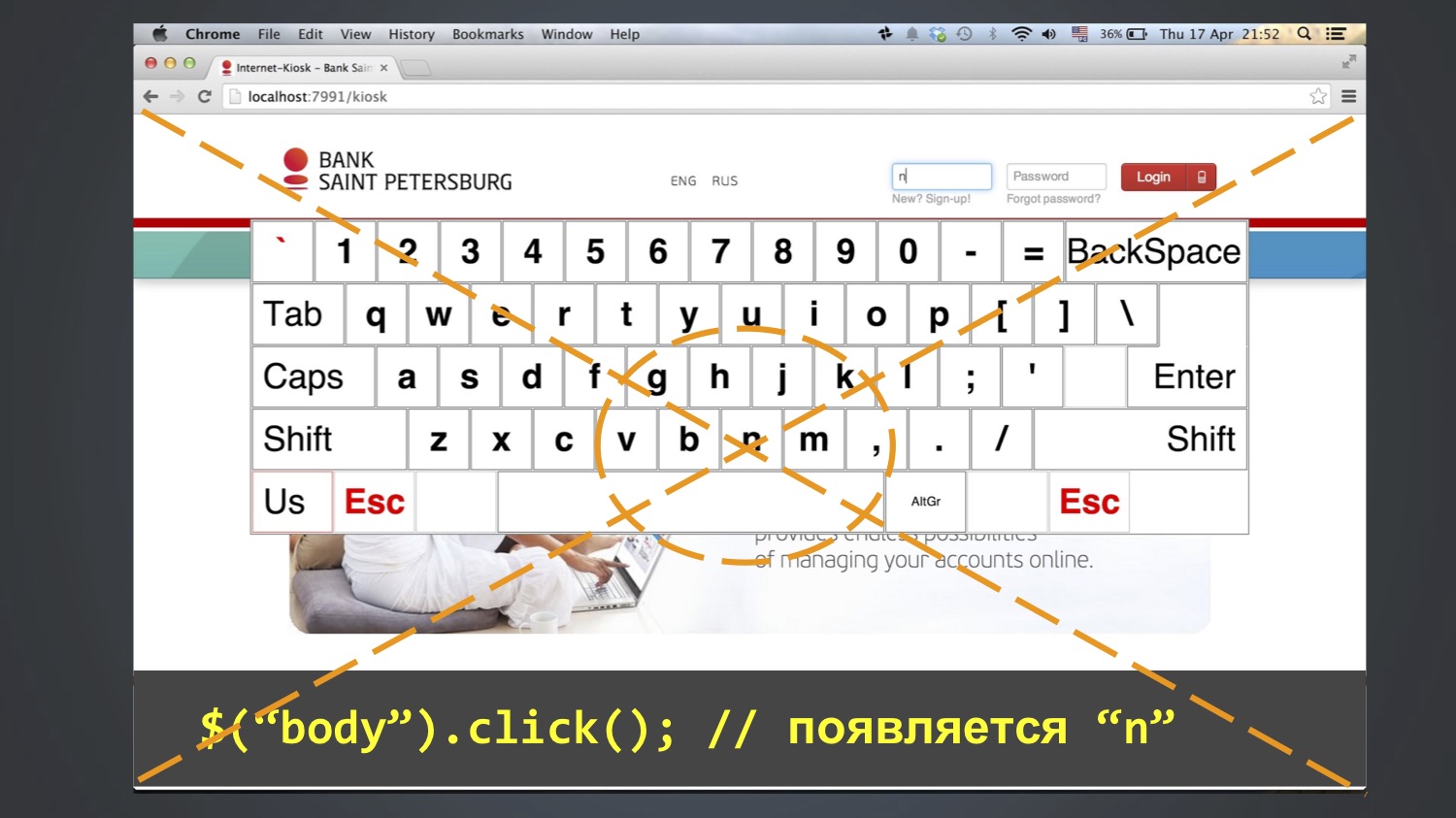
Et cela ne tombait pas toujours. Qui sait pourquoi? En fait, je ne le sais pas moi-même. Peut-être dû au fait que la fenêtre du navigateur s’ouvrait tout le temps dans différentes tailles, et cela ne tombait pas toujours dans la lettre N.
Vous avez probablement une question: pourquoi quelqu'un a-t-il fait $ ("body"). Cliquez sur ()? Je ne sais pas non plus jusqu'à la fin, mais je suppose que pour supprimer le focus du champ. Il y a un tel problème dans Selenium que click () existe, mais unclick () ne l'est pas. S'il y a un focus dans le champ, il ne peut pas être supprimé de là, vous ne pouvez que cliquer sur n'importe quel autre élément. Et comme il n'y avait pas d'autres éléments raisonnables, ils ont cliqué sur le corps et ont obtenu un tel effet.
D'où la morale: n'insérez rien qui pénètre dans le <body>. En d'autres termes, vous n'avez pas besoin de faire de mouvements supplémentaires en panique. En fait, cela arrive souvent: puisque je traite avec Selenide, je reçois souvent des plaintes «quelque chose ne fonctionne pas», puis il s'avère que quelque part dans les méthodes de configuration, il y avait 15 lignes supplémentaires qui ne font rien d'utile et interfèrent . Pas besoin de se tracasser et de s'insérer quand même dans des tests comme «du coup ça sera plus fiable».
En conséquence, nous élargissons la liste des raisons des tests instables:
- Vitesse de requête Ajax;
- L'ordre des demandes Ajax;
- Vitesse js;
- Taille de la fenêtre du navigateur;
- Vanité!
Et en même temps, ma recommandation est: ne pas exécuter de tests en maximisé (c'est-à-dire, ne pas ouvrir le navigateur dans une fenêtre complète). En règle générale, tout le monde le fait, et dans Selenide, c'était par défaut (ou l'est toujours). Au lieu de cela, je vous conseille de toujours lancer un navigateur avec une résolution d'écran strictement définie, car alors ce facteur aléatoire est exclu. Et je vous conseille de définir la taille minimale prise en charge par votre application en fonction des spécifications.
Exemple 3: comptes fantômes
Un exemple est intéressant en ce que tout ce qui ne peut que coïncider coïncide immédiatement.
Un test a vérifié qu'il devrait y avoir 5 comptes sur cet écran.

En règle générale, il était vert, mais parfois, il n'était pas clair dans quelles conditions il tombait et disait qu'il n'y avait pas cinq, mais six chefs d'accusation à l'écran.
J'ai commencé à chercher d'où vient la facture supplémentaire. Absolument incompréhensible. La question s'est posée: peut-être que nous avons un autre test, qui pendant le test crée un nouveau compte? Il s'est avéré que oui, il existe un tel test de prêt. Et entre celui-ci et la baisse de AccountsTest (qui attend cinq comptes), il peut y avoir un million d'autres tests.
Nous essayons de comprendre comment il en est ainsi: le LoansTest, qui crée le compte, ne devrait-il pas le supprimer à la fin? Nous regardons son code - oui, il devrait, à la fin il y a une fonction After pour cela. Alors, en théorie, tout devrait bien se passer, quel est le problème?
Peut-être que le test le supprime, mais il reste en cache quelque part? Nous regardons le code de production qui charge les comptes - il a vraiment l'annotation @CacheFor, il met en cache les comptes pendant cinq minutes.
La question se pose: mais le test ne devrait-il pas vider ce cache? Ce serait logique, ne peut-il y avoir un tel montant? Nous regardons son code - oui, il efface vraiment le cache avant chaque test. Quoi de neuf? Ici, vous êtes déjà perdu, car les hypothèses sont terminées: l'objet est supprimé, le cache est vidé, les arbres, quoi d'autre pourrait poser problème? Puis il a commencé à grimper le code, cela a pris du temps, peut-être même quelques jours. Jusqu'à ce que je regarde enfin cette classe et cette superclasse, et que j'y trouve une chose suspecte:

Quelqu'un a déjà remarqué, non? C'est vrai: dans l'enfant et dans la classe parent il y a une méthode avec le même nom, et elle n'appelle pas super.
Et en Java, c'est très facile à faire: vous appuyez sur Alt + Entrée ou Ctrl + Insérer dans IntelliJ IDEA ou Eclipse, par défaut, il crée la méthode setUp () pour vous, et vous ne remarquez pas qu'il remplace la méthode dans la superclasse. Autrement dit, le cache n'a toujours pas été appelé. Quand j'ai vu ça, j'étais extrêmement en colère. C'est joyeux pour moi maintenant.
D'où la morale:
- Dans les tests, il est très important de surveiller le code propre. Si dans le code de production tout le monde est attentif à cela, ils procèdent à une révision du code, puis à des tests - pas toujours.
- Si le code de production est vérifié par des tests, alors qui testera les tests? Par conséquent, il est particulièrement important d'utiliser des vérifications dans l'EDI.
Après cet incident, j'ai trouvé dans IDEA une telle inspection, désactivée par défaut, qui vérifie: si la méthode est remplacée quelque part, mais qu'il n'y a pas d'annotation @ Overrid, cela marque cela comme une erreur. Maintenant, je coche toujours hystériquement cette case.
Résumons à nouveau: comment cela s'est-il produit, pourquoi le test n'a-t-il pas toujours échoué? Tout d'abord, cela dépendait de l'ordre de ces deux tests, ils se déroulent toujours dans un ordre aléatoire. Un autre test dépendait du temps qui s'est écoulé entre eux. Les comptes sont mis en cache pendant cinq minutes, si plus de réussite, le test était vert, et si moins, il est tombé, et cela s'est rarement produit.
Nous élargissons la liste des raisons pour lesquelles les tests peuvent être instables:
- Vitesse de requête Ajax;
- L'ordre des demandes Ajax;
- Vitesse js;
- Taille de la fenêtre du navigateur;
- Cache d'application;
- Données des tests précédents;
- Le temps.
Exemple 4: Java Time
Un test a fonctionné sur tous nos ordinateurs et sur nos Jenkins, mais s'est parfois écrasé sur un client Jenkins. Nous regardons le test, comprenons pourquoi. Il s'est avéré qu'elle était en baisse, car lors de la vérification "la date de paiement devrait être maintenant ou dans le passé", elle s'est avérée être "à l'avenir".
assert payment.time <= new Date();
Nous regardons dans le code, tout à coup, sous certaines conditions, pouvons-nous fixer une date dans le futur? Nous ne pouvons pas: au seul endroit où le délai de paiement est initialisé, une nouvelle date () est utilisée, et c'est toujours l'heure actuelle (dans les cas extrêmes, elle peut être dans le passé si le test était très lent). Comment est-ce encore possible? Ils se sont battus la tête pendant longtemps, ils ne pouvaient pas comprendre.
Et une fois qu'ils ont regardé dans le journal des applications. D'où la première morale - il est très utile lors de l'examen des tests pour consulter le journal de l'application elle-même. Levez la main, qui le fait. En général, pas la majorité, hélas. Et il y a des informations utiles: par exemple, le journal des demandes, telle ou telle URL a été exécutée à un tel moment, a donné telle ou telle réponse.

Y a-t-il quelque chose de suspect ici, remarquez? Regardons l'heure: cette demande a été traitée moins trois secondes. Comment est-ce possible? Ils se sont battus pendant longtemps, ne pouvaient pas comprendre. Enfin, lorsque nous avons manqué de théorie, nous avons pris une décision stupide: Jenkins a écrit un script simple qui enregistre l'heure actuelle dans un cycle une fois par seconde. Je l'ai lancé. Le lendemain, lorsque ce test feuilleté est tombé une fois la nuit, ils ont commencé à regarder un extrait de ce fichier pour le moment où il tombait:

Donc: 34 secondes, 35, 36, 37, 35, 39 ... C'est cool que nous l'avons trouvé, mais comment est-ce encore possible? Les théories se terminèrent à nouveau, deux autres jours se grattant la tête. C'est vraiment le cas lorsque la matrice plaisante avec vous, non?
Jusqu'à ce qu'une idée me frappe enfin ... Et cela s'est avéré être. Linux a un service de synchronisation horaire qui s'exécute sur un serveur central et demande "combien de millisecondes sont maintenant?" Et il s'avère que deux services différents ont été lancés sur ce Jenkins particulier. Le test a commencé à planter lorsque Ubuntu a été mis à jour sur ce serveur.
Là, un service ntp était précédemment configuré, qui accédait à un serveur bancaire spécial et prenait du temps à partir de là. Et avec la nouvelle version d'Ubuntu, un nouveau service léger a été inclus par défaut, par exemple, systemd-timesyncd. Et les deux ont fonctionné. Personne ne l'a remarqué. Pour une raison quelconque, le serveur bancaire central et un serveur Ubuntu central ont émis une réponse avec une différence de 3 secondes. Naturellement, ces deux services se sont interférés. Quelque part au fond de la documentation Ubuntu, il est dit que, bien sûr, ne permettent pas cette situation ... Eh bien, merci pour l'info :)
Soit dit en passant, j'ai en même temps appris une nuance intéressante de Java, qui auparavant, malgré mes nombreuses années d'expérience, ne connaissait pas. L'une des méthodes les plus élémentaires de Java est appelée System.currentTimeMillis (), à l'aide de laquelle elle est généralement programmée pour appeler quelque chose, beaucoup ont écrit un tel code:
long start = System.currentTimeMillis();
Ce code se trouve dans les bibliothèques Apache Commons, Guava. Autrement dit, si vous devez détecter le nombre de millisecondes qu'il a fallu pour appeler quelque chose, ils le font généralement. Et beaucoup ont probablement entendu dire que cela ne devrait pas être fait. J'ai aussi entendu, mais je ne savais pas pourquoi, et trop paresseux pour comprendre. Je pensais que la question était exactement parce que System.nanoTime () est apparu dans une version de Java - il est plus précis, il produit des nanosecondes qui sont un million de fois plus précises. Et comme, en règle générale, mes appels durent une seconde ou une demi-seconde, cette précision n'est pas importante pour moi, et j'ai continué à utiliser System.currentTimeMillis (), que nous avons vu dans le journal où il était de -3 secondes. Donc, en fait, la bonne façon est la suivante, et maintenant j'ai découvert pourquoi:
long start = System.nanoTime();
En fait, cela est écrit dans la documentation des méthodes, mais je ne le lis jamais. J'ai pensé toute ma vie que System.currentTimeMillis () et System.nanoTime () sont la même chose, mais avec un million de fois de différence. Mais il s'est avéré que ce sont des choses fondamentalement différentes.
System.currentTimeMillis () renvoie la date actuelle réelle - combien de millisecondes sont maintenant depuis le 1er janvier 1970. Et System.nanoTime () est une sorte de compteur abstrait qui n'est pas lié au temps réel: oui, il est garanti de croître toutes les nanosecondes par unité, mais il n'est pas connecté à l'heure actuelle, il peut même être négatif. Au début de la JVM, un point dans le temps est en quelque sorte choisi au hasard et il commence à croître. Ce fut une surprise pour moi. Pour toi aussi? Eh bien, ce n'est pas en vain qu'il est arrivé.
Exemple 5: La malédiction du bouton vert
Ici, notre test remplit un certain formulaire, clique sur le bouton vert Confirmer, et parfois il ne va pas plus loin. Pourquoi cela ne marche pas est incompréhensible.
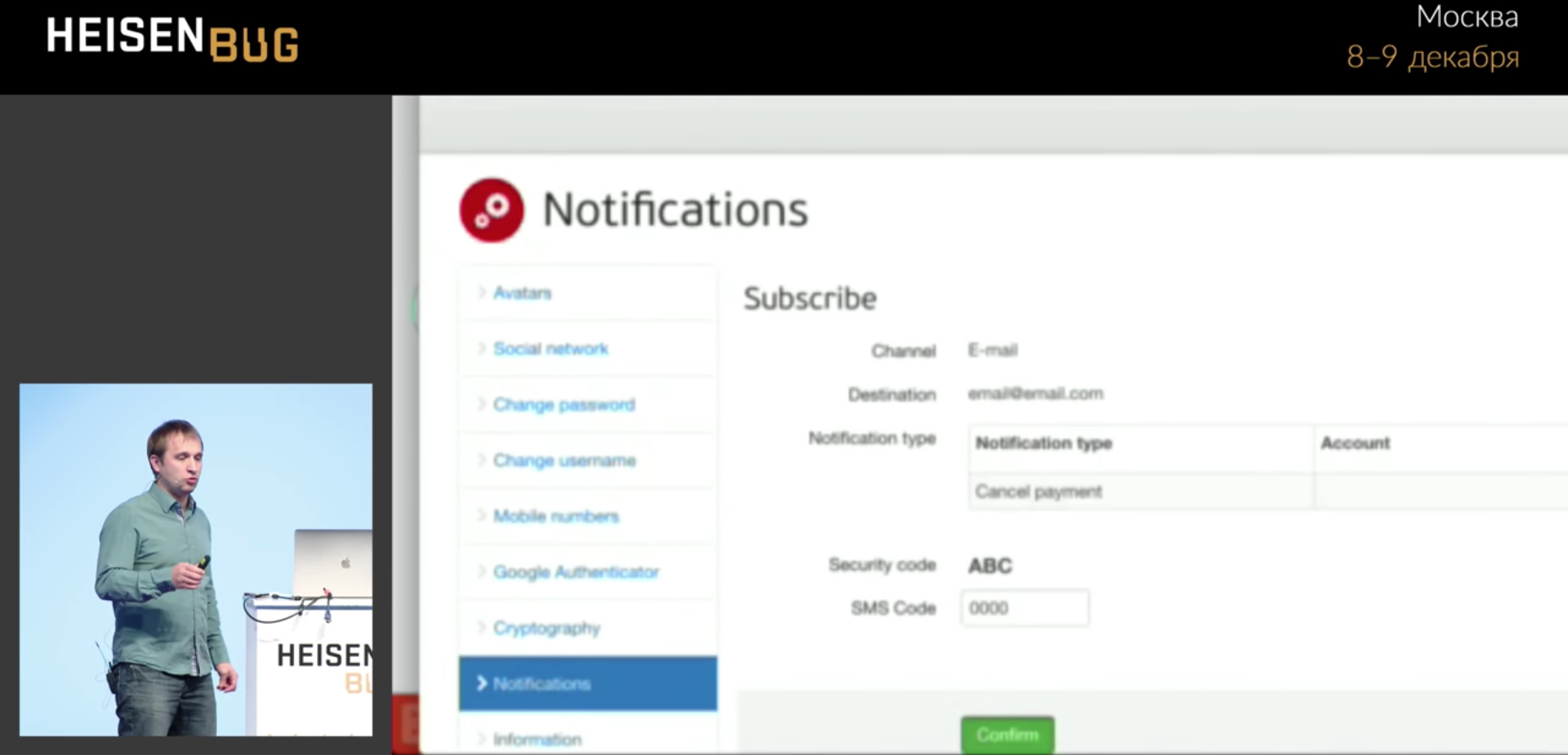
Nous conduisons en quatre zéros et accrochons, ne passez pas à la page suivante. Le clic se produit sans erreur. J'ai tout regardé: requêtes Ajax, attente, délais d'attente, journaux d'application, cache - je n'ai rien trouvé. La bibliothèque
Video Recorder écrite par Sergey Pirogov n'est pas encore apparue. Il permet, en ajoutant une annotation au code, d'enregistrer de la vidéo. Puis j'ai pu filmer une
vidéo de ce test, la regarder au ralenti, et cela a finalement clarifié la situation que je n'ai pas pu résoudre pendant plusieurs mois avant la vidéo.

La barre de progression a bloqué le bouton pendant une fraction de seconde, et le clic a fonctionné exactement à ce moment et a frappé cette barre de progression. Autrement dit, la barre de progression a cliqué et a disparu! Et il ne sera pas visible dans aucune capture d'écran, dans aucun journal, vous ne saurez jamais ce qui s'est passé.
En principe, il s'agit en quelque sorte d'un bug d'application: une barre de progression est apparue parce que l'application rampe vraiment hors du bord de l'écran, et si vous faites défiler, cela s'avère être beaucoup de données utiles. Mais les utilisateurs ne s'en sont pas plaints, car tout tient sur le grand écran, il ne tient pas seulement sur le petit.
Exemple 6: pourquoi Chrome se fige-t-il?
Une enquête policière de deux ans est un cas absolument réel. La situation est la suivante: nos tests étaient assez souvent floconneux et sont tombés, et dans les traces de la pile, il était clair que Chrome gèle: pas notre test, à savoir Chrome. Dans les journaux, il était visible "Build fonctionne 36 heures ..." Ils ont commencé à supprimer les vidages de threads et les traces de pile - ils montrent que tout va bien dans les tests, l'appel au Chromedriver se bloque et, en règle générale, au moment de la fermeture (nous appelons la méthode close, et cette méthode ne fait rien, se bloque 36 heures). Si c'est intéressant, alors la trace de la pile ressemblait à ceci:

Nous avons essayé de faire tout ce qui ne pouvait que nous venir à l'esprit:
- Configurez le délai d'ouverture / fermeture du navigateur (si vous ne parvenez pas à ouvrir / fermer le navigateur en 15 secondes, réessayez après 15 secondes, jusqu'à trois tentatives). Ouvrez et fermez le navigateur dans un thread séparé. Résultat: les trois tentatives se sont bloquées de la même manière.
- Tuez les anciens processus Chrome. Ils ont créé un travail séparé dans «kill-chrome» de Jenkins, par exemple, comme ceci, vous pouvez «tuer» tous les processus de plus d'une heure:
killall - chromedriver plus vieux que 1h
killall - plus vieux que 1h chrome
Cela a au moins libéré de la mémoire, mais n'a pas répondu à la question «que se passe-t-il?». En fait, cette chose ne nous a retardé que le moment de la décision. - Activez les journaux d'application de débogage.
- Activez les journaux de débogage WebDriver.
- Rouvrez le navigateur tous les 20 tests. Cela peut sembler ridicule, mais la pensée était: "Et si Chrome se fige parce qu'il est fatigué?" Eh bien, une fuite de mémoire ou autre chose.
Le résultat de la dernière tentative était complètement inattendu: le problème a commencé à se répéter plus souvent! Et nous espérions que cela aiderait à stabiliser Chrome afin qu'il fonctionne mieux. Il s'agit généralement d'un plat à emporter. Mais en fait, lorsque le problème commence à se reproduire plus souvent, il ne faut pas être triste, mais se réjouir! Cela permet de mieux l'étudier. Si elle commençait à répéter plus souvent, on devrait s'y accrocher: "Oui, oui, maintenant je vais ajouter autre chose, des journaux, des points d'arrêt ..."
Nous essayons de répéter le problème: nous écrivons un cycle de 1 à 1000, dans le cycle nous ouvrons simplement le navigateur et fermons la première page de notre application. Nous avons écrit un tel cycle, et ... bingo! Résultat: le problème a commencé à se répéter de manière stable (bien qu'environ toutes les 80 itérations)! Cool! Certes, cette réalisation n'a rien donné pendant longtemps. Vous l'avez commencé, attendu la 80e itération, Chrome s'est écrasé ... et ensuite que faire? Vous regardez les traces de pile, les vidages, les journaux - il n'y a rien d'utile là-bas. Les outils de développement dans Chrome peuvent aider, mais jusqu'en septembre 2017, ces outils ne fonctionnaient pas avec Selenium (les ports étaient en conflit: vous lancez Chrome depuis Selenium et DevTools ne s'ouvre pas). Pendant longtemps, je ne pouvais pas penser à quoi faire.
Et ici, dans cette histoire commence un moment fabuleux. Une fois, après un nombre infini de tentatives, j'ai exécuté à nouveau ces tests, il se bloque à nouveau sur une sorte d'itération comme la 56e, je pense "creusons autre chose" (bien que je ne sache pas où mettre le point d'arrêt ou quoi ajouter un journal). En ce moment, ma fille propose de jouer aux cubes, mais mon test se bloque juste ici. Je dis: "Attendez", elle m'a dit: "Quoi, vous ne comprenez pas, j'ai
un b et un ici!"
Que faire, a malheureusement quitté l'ordinateur, est allé jouer des cubes ... Et soudain, après environ 20 minutes, je jette un coup d'œil accidentel à l'écran, et je vois une image complètement inattendue:

Que se passe-t-il: il y a un compte à rebours, après combien de minutes la session expire, et je construis une tour de cubes, il y en a deux, un ... la session expire, le test continue, se termine et tombe (il n'y a plus aucun élément, la session a expiré).
Qu'est-ce qui se passe: Chrome n'a pas vraiment gelé, comme nous le pensions tout ce temps, il attendait quelque chose depuis tout ce temps. Lorsque la session a expiré, a attendu, a continué. À quoi exactement Chrome s'attendait - il est complètement incompréhensible de comprendre cela, j'ai dû pelleter tout le code en utilisant la méthode de recherche binaire: jeter la moitié de JavaScript et HTML, essayer de répéter à nouveau 80 itérations - cela ne s'est pas bloqué, oh, cela signifie quelque part là-bas ... En général, nous avons compris expérimentalement que le problème est là:
var timeout = setTimeout(sessionWatcher);
Il y avait du JavaScript sur toutes nos pages - celle qui montre la fenêtre que la session expire. Tous les programmeurs JavaScript savent probablement que ce n'est pas très correct: tout ce qui s'exécute dans les balises <script> démarre immédiatement. Et cela n'est généralement pas sûr, car s'il utilise des éléments qui n'ont pas encore été chargés, cela peut ne pas fonctionner. Par conséquent, il est toujours recommandé d'envelopper JavaScript - si vous utilisez jQuery, puis dans $, et tout ce qui se trouve dans le bloc fonction ne démarrera que lorsque tous les éléments seront chargés à la fin: var timeout; $(function() { timeout = setTimeout(...); });
C'est l'ABC de la programmation Web, tout le monde le sait probablement. Et nous ne l’avions pas, nous nous étions trompés. Lorsque j'ai changé cela et répété l'expérience pendant 1000 itérations, elle ne s'est plus bloquée.Certes, je ne connais pas pleinement toutes les réponses: par exemple, je ne sais pas pourquoi cela ne pendait pas toujours, mais seulement parfois très rarement. C'est peut-être un bug Chrome, bon sang. Oui, il a vraiment fallu deux ans pour rechercher ce problème.Cela veut dire que certains cas avec des tests floconneux sont si irréalistes que peut-être tout le monde ne voudra pas leur gâcher la vie. En général, si vous essayez de conclure de cela - il est intéressant de noter que la tentative la plus ridicule et stupide, drôle et insensée (pour redémarrer un navigateur fatigué) s'est avérée réussie. C'était complètement stupide, mais a soudainement conduit au succès. Je ne sais pas quelle moralité en déduire: faire des tentatives stupides?Dans Chrome, pendant longtemps, nous avions également une telle raison pour les tests floconneux: il ne savait pas toujours comment fermer les fenêtres d'alerte natives, parfois il ne le savait pas, et le processus restait suspendu, personne ne l'a tué.Parfois, les effets de l'interface utilisateur affectent également: vous voulez cliquer sur un bouton, et à ce moment, il se déplace ou passe d'un coin à l'autre. Vous appelez la méthode click (), elle calcule les coordonnées du point central de ce bouton et y figure, et le bouton est déjà parti à ce moment-là. Et, plus important encore, ce qui se passe: la méthode click () a fonctionné sans erreur et vous ne vous retrouvez pas sur la page suivante. Quelqu'un a cliqué à nouveau, non? :)
Lorsque les navigateurs sont lancés en parallèle, ils perdent le focus. S'il existe des fonctionnalités conçues pour la mise au point, le survol, elles tomberont également lorsqu'elles seront lancées en parallèle. En conséquence, je conseille de ne pas les utiliser, ou d'utiliser des solutions où les navigateurs sont vraiment séparés, exécutés sur différents écrans ou dans différents Dockers.Les exemples sont terminés, donnons maintenant une théorie pour expliquer pourquoi les tests sont instables. Rappelons les problèmes typiques:- Vitesse de requête Ajax;
- L'ordre des demandes Ajax;
- Vitesse js;
- Taille de la fenêtre du navigateur;
- Cache d'application;
- Données des tests précédents;
- Le temps;
- Stabilité du navigateur;
- Effets de l'interface utilisateur
- Navigateurs parallèles (perte de focalisation).
Il existe également de vrais bugs pour les tests floconneux, comme vous pouvez les trouver. Il arrive que ce soient des bugs et des bugs qui soient découverts, et ceci est un cas simple: vous obtenez un bug, ils vont le corriger.Des cas reproductibles difficiles se produisent également pour nous. Il existe des bogues «irréalistes». Nous avons eu des cas où le test feuilleté s'est cassé, car la protection sur le nombre de clics par seconde sur le bouton avec le même ID fonctionnait, et le test feuilleté a réussi à cliquer plusieurs fois. Mais le vrai utilisateur n'aura jamais le temps de le faire.Il y a de vrais bugs, mais non critiques: vous avez un test, il est parfois rouge, mais personne ne va le corriger.Il arrive souvent qu'un test feuilleté parle d'un problème d'utilisation, comme avec une barre de progression où une partie de l'écran était fermée et le test feuilleté l'a montré. Donc, parfois, vous devez regarder le test de chute sous un tel angle.Le problème est que si vous ne le justifiez pas correctement, personne ne corrigera quoi que ce soit ... Plus récemment, nous avons eu un cas lorsque nous avons commencé à creuser, nous avons réalisé que le test floconneux a trouvé un bogue de sécurité que les tests ordinaires n'ont pas remarqué. Mais je ne le dirai pas aujourd'hui, car il n'a pas encore été réparé!Parlons de ce que vous pouvez faire pour minimiser le nombre de tests feuilletés:- Test de la pyramide;
- Selenide
- Émulateurs de service;
- Une base propre avant chaque test.
La pyramide est une vérité éternelle. Pourquoi est-ce précisément en ce qui concerne les tests feuilletés qu'il est important qu'il y ait un ordre de grandeur plus de tests unitaires que les tests UI? Non pas parce qu'ils sont plus rapides (bien que ce soit important), mais parce qu'ils sont beaucoup plus stables et beaucoup moins susceptibles d'être feuilletés.A propos de Selenide a déjà dit.Émulateurs. Pendant les tests, vous ne pouvez en aucun cas accéder à de vrais services externes (par exemple, envoyer de vrais sms / lettres pendant les tests). Ce n'est pas une blague, j'entends souvent des questions comme «comment lire une lettre d'un test?». Assurez-vous d'utiliser des émulateurs pour ces services, d'autant plus qu'ils sont faciles à faire. Artyom Eroshenko dans son rapport a montré que je ne m'arrêterai pas.Idéalement, avant chaque test, réinitialisez l'état des données, nettoyez l'état de la base de données. Comment le faire spécifiquement, je ne dirai pas maintenant, c'est un problème technique, mais il existe des options pour le faire tout simplement. Cela arrive vraiment chez nous: avant chaque test, la base de données est à partir de zéro, nouvelle, toujours avec le même ensemble de données (10 utilisateurs, 20 comptes, l'un avec un million, l'autre avec dix roubles). Tous les tests pour cela peuvent être garantis pour compter, et aucun feuilleté en raison des données n'existe pas.Ce que vous devez adopter afin d'explorer plus en détail les tests feuilletés:- Journaux des versions précédentes;
- Captures d'écran
- Vidéo
L'élément «enregistrer les journaux des versions précédentes» peut également sembler évident, mais dans chaque projet où je suis venu, j'ai vu cette situation: certaines erreurs et captures d'écran ne peuvent être vues que dans la dernière version. Si votre dernière version est "verte" et la précédente était "rouge", alors c'est tout: il y avait un test feuilleté, mais vous ne pouvez plus savoir pourquoi il était feuilleté. Aucun journal, rien n'a été conservé, et c'est un désastre. Et cela se fait très facilement. Par exemple, si vous utilisez le pipeline Jenkins, alors dans Jenkins, il suffit d'écrire un tel morceau de code: finally { stage("Reports") { junit 'build/test-results/**/*.xml' artifacts = 'build./reports/**/*,build/test-results/**/*,logs/**/*' archiveArtifacts artifacts: artifacts } }
La méthode finally s'exécutera quand même, même si les tests échouent. Vous lui dites simplement: copiez tel ou tel journal de tel ou tel papa. Et Jenkins enregistrera pour chaque build tous les résultats des tests, tous les rapports. En conséquence, dans l'ancien Jenkins, il était possible de placer les tiques au bon endroit, etc. Cela est nécessaire, tout d'abord.Assurez-vous de prendre des captures d'écran des tests effectués (Selenide le fait automatiquement, donc c'est généralement facile là-bas). Je vous conseille également de filmer des vidéos à partir de tests feuilletés. En particulier, il y a l' enregistreur vidéo déjà mentionné , c'est généralement facile là-bas: ajoutez l'annotation vidéo au test suspect - et c'est tout, vous avez la vidéo!Une alternative pour ceux qui sont prêts à exécuter des tests dans Docker: il y a une bonne bibliothèque TestContainers (il y avait un rapport à ce sujet sur ce Heisenbug ). Là, vous insérez également une règle , une annotation dans le test - avant le test lui-même, il déploie le Docker avec la version souhaitée du navigateur, enregistre la vidéo et la tue à la fin du test. Dans ce cas, vous aurez également une vidéo sur l'échec du test. @Rule public BrowserWebDriverContainer chrome = new BrowserWebDriverContainer() .withRecordingMode(RECORD_ALL, new File("build")) .withDesiredCapabilities(chrome());
Le message final.Je veux d'abord contacter les développeurs. Les développeurs, très chers, assurez-vous de participer aux tests, d'aider à écrire des tests, d'enquêter, d'aider les testeurs intéressés à lire les journaux. Parce qu'ils ne peuvent jamais faire face à de tels tests floconneux de leur vie.Managers, patrons de ces développeurs! En règle générale, le problème est avec vous :) Laissez les développeurs et encouragez les développeurs à participer aux tests. Si vous ne le faites pas, si vous dites «ils n'ont pas le temps pour cela, ils doivent écrire du code, ils sont chers», alors vous gaspillerez de l'argent sur l'automatisation car l'efficacité de l'automatisation sera faible.Et le message le plus important est pour les experts en automatisation, ceux qui sont impliqués dans les tests, enquêtent sur les tests de chute et font quelque chose avec eux. A votre retour au travail, effectuez les travaux préventifs décrits, armez-vous des moyens précités et ... attendez! :) Et la prochaine fois que votre test floconneux tombe - réjouissez-vous: vous partez à la chasse!Si vous avez aimé ce reportage, faites attention: les 6-7 décembre, Heisenbug revient à Moscou. Il y aura à nouveau des conseils utiles et des histoires incroyables, et les mondes des testeurs et des développeurs reviendront en contact. Vous pouvez toujours voir l'état actuel du programme (et, si vous le souhaitez, acheter un billet) sur le site Web de la conférence .