Les réseaux de neurones profonds ont conduit à une percée dans de nombreuses tâches de reconnaissance d'image, telles que la vision par ordinateur et la reconnaissance vocale. Le réseau neuronal convolutif est l'un des types populaires de réseaux neuronaux.
Fondamentalement, un réseau neuronal convolutionnel peut être considéré comme un réseau neuronal qui utilise de nombreuses copies identiques du même neurone. Cela permet au réseau d'avoir un nombre limité de paramètres lors du calcul de grands modèles.
 Réseau neuronal convolutif 2D
Réseau neuronal convolutif 2DCette technique avec plusieurs copies du même neurone a une analogie étroite avec l'abstraction des fonctions en mathématiques et en informatique. Lors de la programmation, la fonction est écrite une fois puis réutilisée, sans que vous ayez à écrire plusieurs fois le même code à différents endroits, ce qui accélère l'exécution du programme et réduit le nombre d'erreurs. De même, un réseau neuronal convolutionnel, une fois qu'il a formé un neurone, l'utilise à de nombreux endroits, ce qui facilite la formation du modèle et minimise les erreurs.
La structure des réseaux de neurones convolutifs
Supposons qu'une tâche soit donnée dans laquelle il est nécessaire de prédire à partir de l'audio s'il y a une voix d'une personne dans le fichier audio.
En entrée, nous obtenons des échantillons audio à différents moments. Les échantillons sont répartis uniformément.

Le moyen le plus simple de les classer avec un réseau de neurones est de connecter tous les échantillons à une couche entièrement connectée. Dans ce cas, chaque entrée est connectée à chaque neurone.
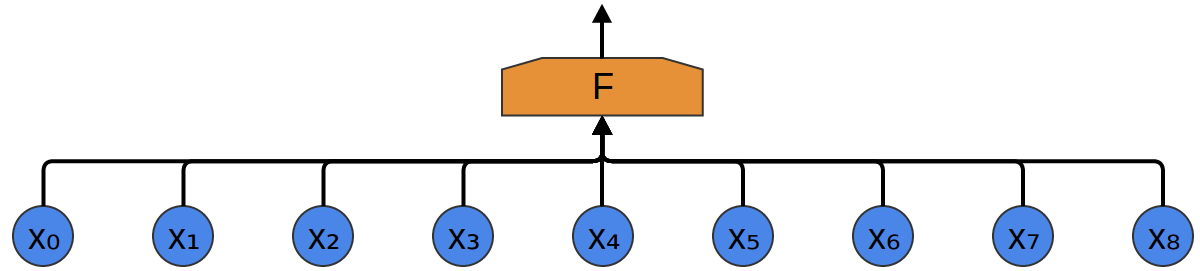
Une approche plus complexe prend en compte une certaine symétrie dans les propriétés qui se trouvent dans les données. Nous prêtons beaucoup d'attention aux propriétés locales des données: quelle est la fréquence du son pendant un certain temps? Augmenter ou diminuer? Et ainsi de suite.
Nous prenons en compte les mêmes propriétés à tout moment. Il est utile de connaître les fréquences au début, au milieu et à la fin. Notez que ce sont des propriétés locales, car vous n'avez besoin que d'une petite fenêtre de séquence audio pour les définir.
Ainsi, il est possible de créer un groupe de neurones A, qui considèrent de petits segments de temps dans nos données. A examine tous ces segments et calcule certaines fonctions. Ensuite, la sortie de cette couche convolutionnelle est introduite dans une couche F. entièrement connectée
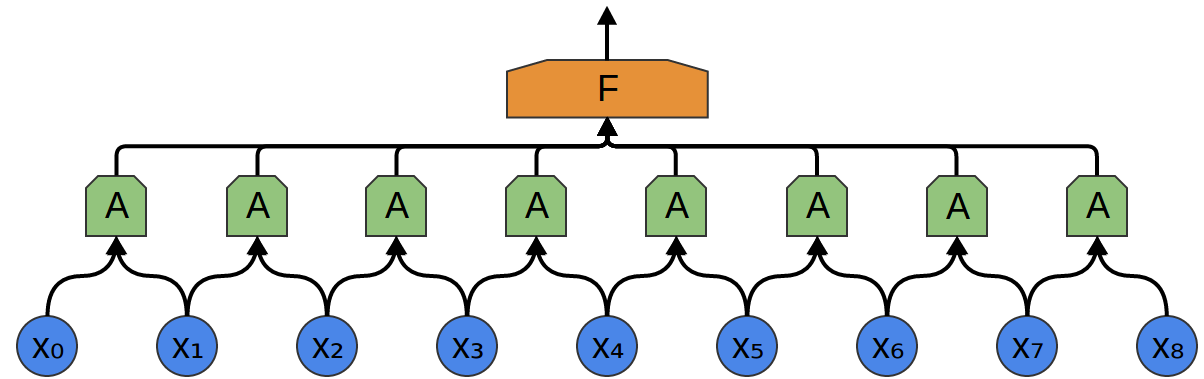
Dans l'exemple ci-dessus, A n'a traité que des segments à deux points. C'est rare dans la pratique. Habituellement, la fenêtre de la couche de convolution est beaucoup plus grande.
Dans l'exemple suivant, A reçoit 3 segments en entrée. Cela est également peu probable pour les tâches du monde réel, mais, malheureusement, il est difficile de visualiser A connectant plusieurs entrées.
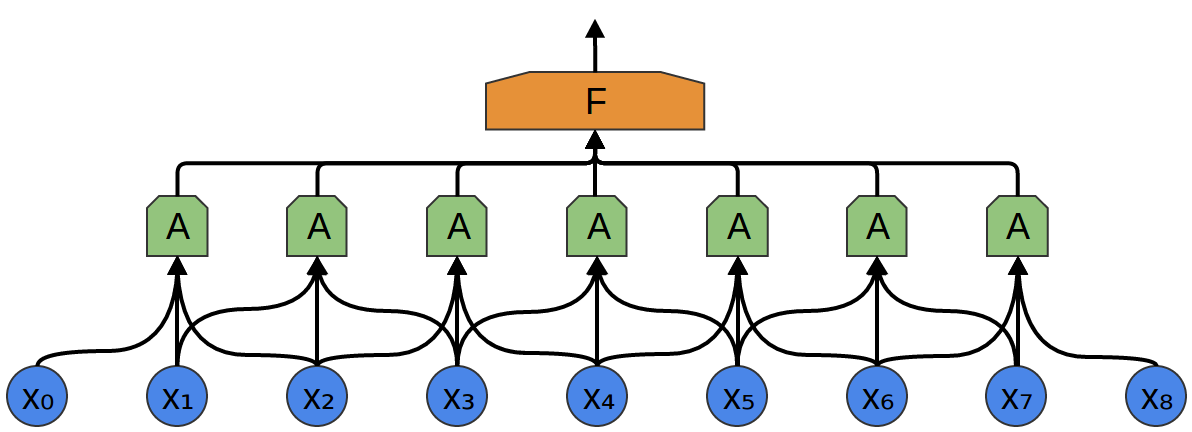
Une belle propriété des couches convolutives est qu'elles sont composites. Vous pouvez transmettre la sortie d'une couche convolutionnelle à une autre. Avec chaque couche, le réseau découvre des fonctions plus élevées et plus abstraites.
Dans l'exemple suivant, il y a un nouveau groupe de neurones B. B est utilisé pour créer une autre couche convolutionnelle posée au-dessus de la précédente.
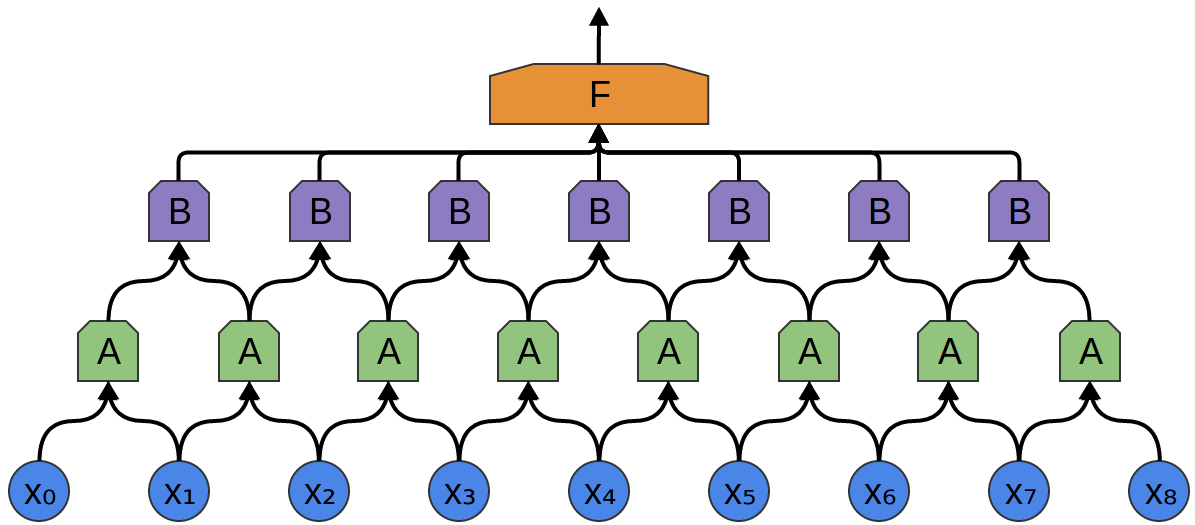
Les couches convolutives sont souvent entrelacées par la mise en commun (combinaison) de couches. En particulier, il existe une sorte de couche appelée max-pooling, qui est extrêmement populaire.
Souvent, nous ne nous soucions pas du moment exact où un signal utile est présent dans les données. Si un changement de fréquence du signal se produit tôt ou tard, est-ce important?
La mise en commun maximale absorbe le maximum de fonctionnalités des petits blocs du niveau précédent. La conclusion indique si le signal de fonction souhaité était présent dans la couche précédente, mais pas exactement où.
Couches de regroupement maximal - il s'agit d'une "diminution". Il permet aux couches convolutives ultérieures de travailler sur de grandes quantités de données, car les petits correctifs après la couche de fusion correspondent au correctif beaucoup plus grand devant lui. Ils nous rendent également invariants à certaines très petites transformations de données.
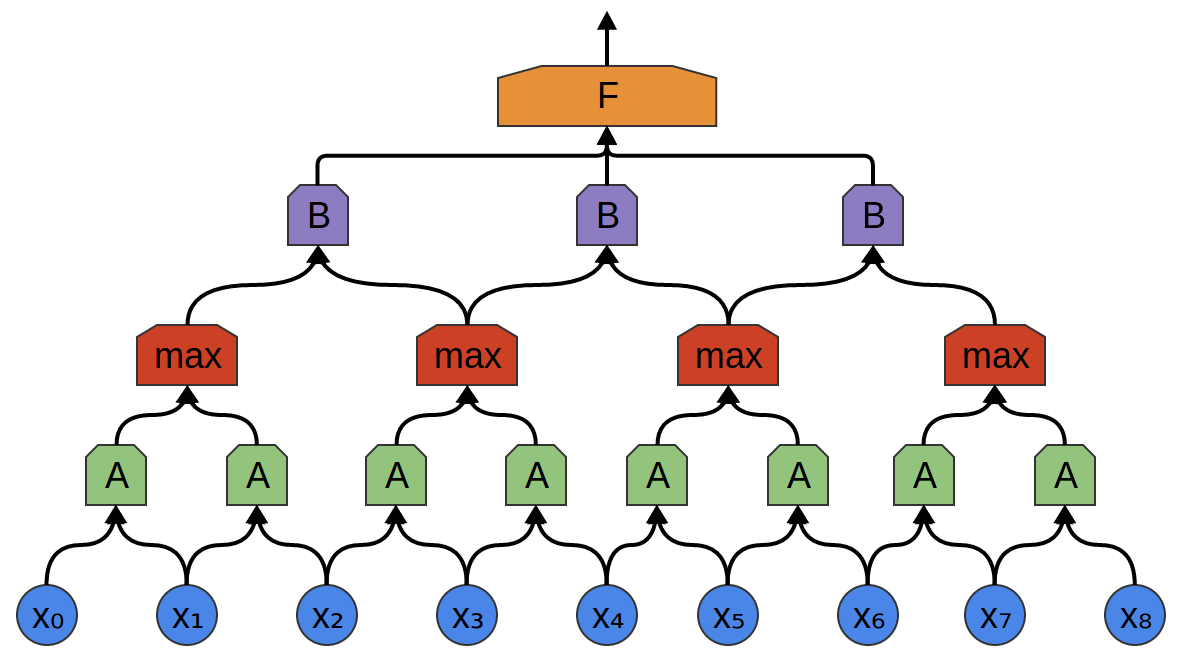
Dans nos exemples précédents, des couches convolutives unidimensionnelles ont été utilisées. Cependant, les couches convolutives peuvent fonctionner avec des données plus volumineuses. En fait, les solutions les plus célèbres basées sur des réseaux de neurones convolutifs utilisent des réseaux de neurones convolutifs bidimensionnels pour la reconnaissance de formes.
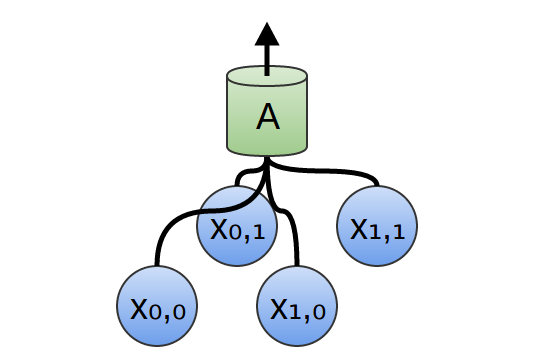
Dans une couche convolutionnelle bidimensionnelle, au lieu de regarder les segments, A examinera les patchs.
Pour chaque patch, A calculera la fonction. Par exemple, elle peut apprendre à détecter la présence d'un bord, ou d'une texture, ou le contraste entre deux couleurs.
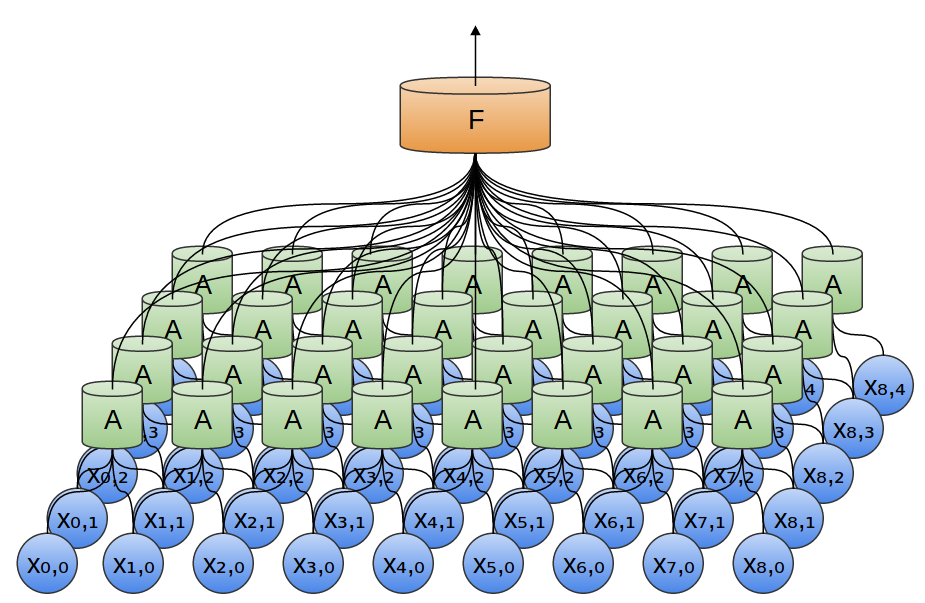
Dans l'exemple précédent, la sortie de la couche convolutionnelle a été introduite dans une couche entièrement connectée. Mais, il est possible de composer deux couches convolutives, comme ce fut le cas dans le cas unidimensionnel considéré.
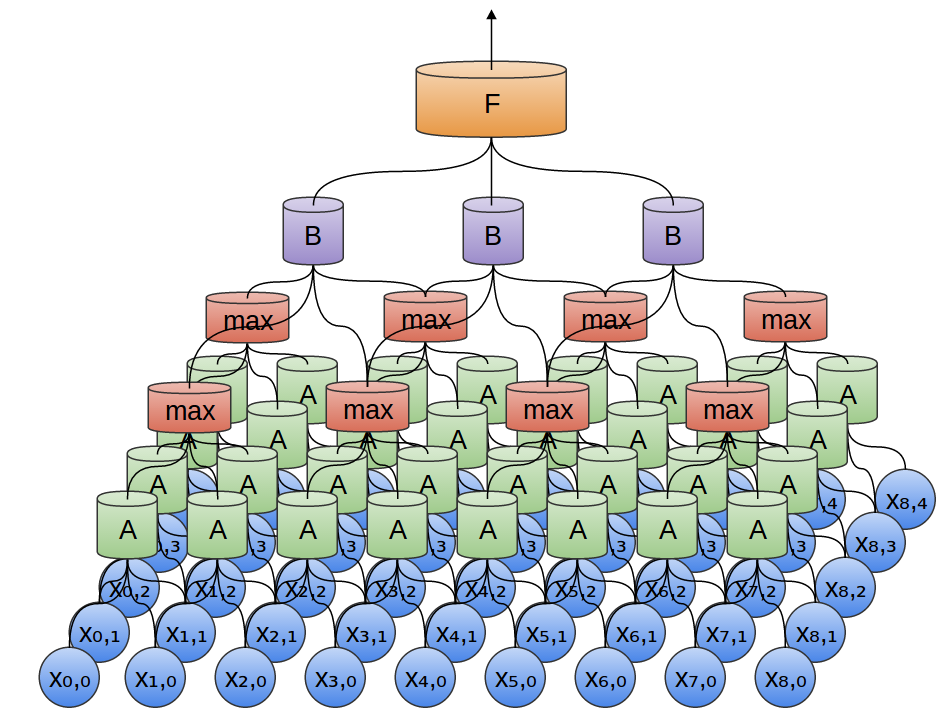
Nous pouvons également effectuer un max-pooling en deux dimensions. Ici, nous prenons le maximum de fonctionnalités d'un petit patch.
Cela se résume au fait que lorsque l'on considère l'image entière, la position exacte du bord, jusqu'au pixel, n'est pas importante. Il suffit de savoir où il se trouve à quelques pixels près.
En outre, les réseaux de convolution tridimensionnels sont parfois utilisés pour des données telles que des données vidéo ou en vrac (par exemple, le balayage 3D en médecine). Cependant, ces réseaux sont peu utilisés et beaucoup plus difficiles à visualiser.
Plus tôt, nous avons dit que A est un groupe de neurones. Nous serons plus précis en cela: qu'est-ce que A?
Dans les couches convolutives traditionnelles, A est un faisceau parallèle de neurones, tous les neurones reçoivent les mêmes signaux d'entrée et calculent différentes fonctions.
Par exemple, dans une couche convolutionnelle bidimensionnelle, un neurone peut détecter des bords horizontaux, un autre, des bords verticaux et un troisième contraste de couleur vert-rouge.
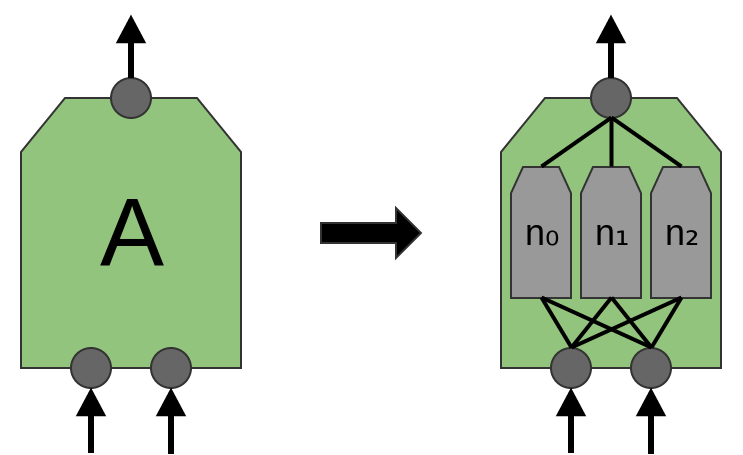
L'article «Network in Network» (Lin et al. (2013)) propose une nouvelle couche, «Mlpconv». Dans ce modèle, A a plusieurs niveaux de neurones, la dernière couche dérivant des fonctions de niveau supérieur pour la région traitée. Dans l'article, le modèle obtient des résultats impressionnants, établissant un nouveau niveau de technologie dans un certain nombre de jeux de données de référence.
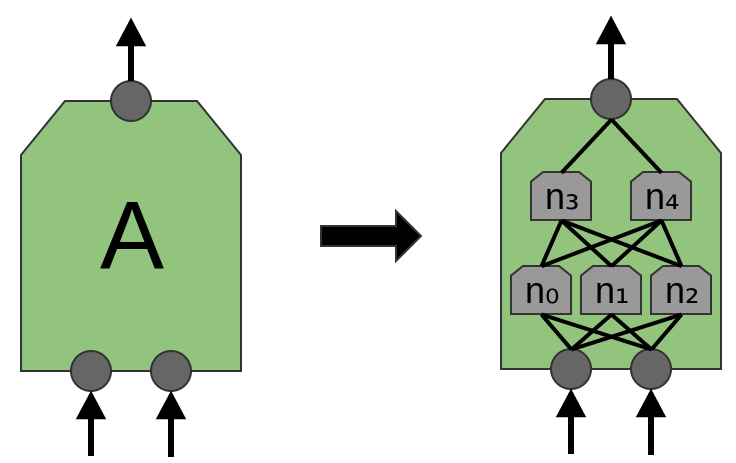
Aux fins de cette publication, nous nous concentrerons sur les couches convolutives standard.
Résultats du réseau neuronal convolutif
En 2012, Alex Krizhevsky, Ilya Sutskever et Geoff Hinton ont réalisé une amélioration significative de la qualité de la reconnaissance par rapport aux solutions connues à l'époque (Krizehvsky et al. (2012)).
Les progrès sont le résultat de la combinaison de plusieurs approches. Des processeurs graphiques ont été utilisés pour former un grand réseau neuronal profond (selon les normes de 2012). Un nouveau type de neurone (ReLU) et une nouvelle technique ont été utilisés pour réduire le problème appelé «surajustement» (DropOut). Nous avons utilisé un grand ensemble de données avec un grand nombre de catégories d'images (ImageNet). Et bien sûr, c'était un réseau neuronal convolutif.
L'architecture présentée ci-dessous était profonde. Il comprend 5 couches convolutives, 3 pools alternés et 3 couches entièrement connectées.
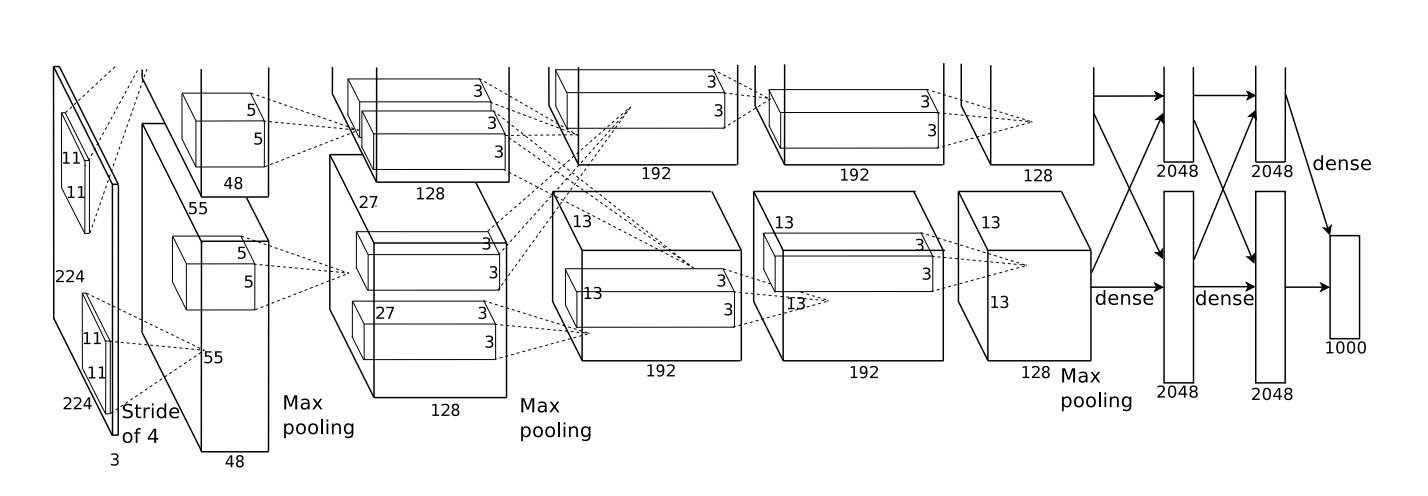
D'après Krizehvsky et al. (2012)
Le réseau a été formé pour classer les photos en milliers de catégories différentes.
Le modèle de Krizhevsky et al. A pu donner la bonne réponse dans 63% des cas. De plus, la bonne réponse parmi les 5 meilleures réponses, il y a 85% de prévisions!

Illustrons ce que reconnaît le premier niveau du réseau.
Rappelons que les couches convolutives étaient réparties entre deux GPU. Les informations ne vont pas d'avant en arrière sur chaque couche. Il s'avère que chaque fois que le modèle démarre, les deux côtés se spécialisent.

Filtres obtenus par la première couche convolutionnelle. La moitié supérieure correspond à une couche sur un GPU, la moitié inférieure sur l'autre. D'après Krizehvsky et al. (2012)
Les neurones d'un côté se concentrent sur le noir et blanc, apprenant à détecter des bords d'orientations et de tailles différentes. Les neurones, d'autre part, se spécialisent dans la couleur et la texture, détectent les contrastes et les motifs de couleur. N'oubliez pas que les neurones sont initialisés au hasard. Pas une seule personne n'est allée les placer comme détecteurs de frontières, ni les a divisés de cette façon. Cela s'est produit lors de la formation du réseau de classification d'images.
Ces résultats remarquables (et d'autres résultats passionnants à l'époque) n'étaient que le début. Ils ont été rapidement suivis par de nombreux autres travaux qui ont testé des approches modifiées et amélioré progressivement les résultats ou les ont appliqués dans d'autres domaines.
Les réseaux de neurones convolutifs sont un outil important en vision par ordinateur et en reconnaissance de formes modernes.
Formalisation des réseaux de neurones convolutifs
Considérons une couche convolutionnelle unidimensionnelle avec des entrées {xn} et des sorties {yn}:
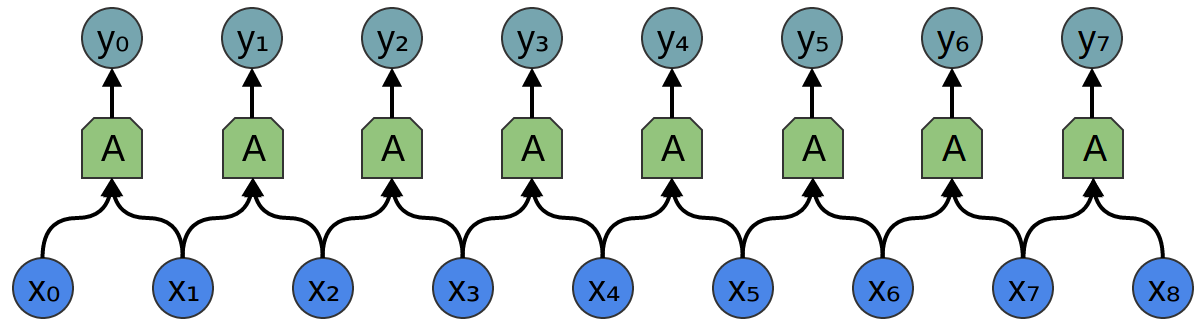
Il est relativement facile de décrire les résultats en termes de saisie:
yn = A (x, x + 1, ...)
Par exemple, dans l'exemple ci-dessus:
y0 = A (x0, x1)
y1 = A (x1, x2)
De même, si nous considérons une couche convolutionnelle bidimensionnelle avec des entrées {xn, m} et des sorties {yn, m}:
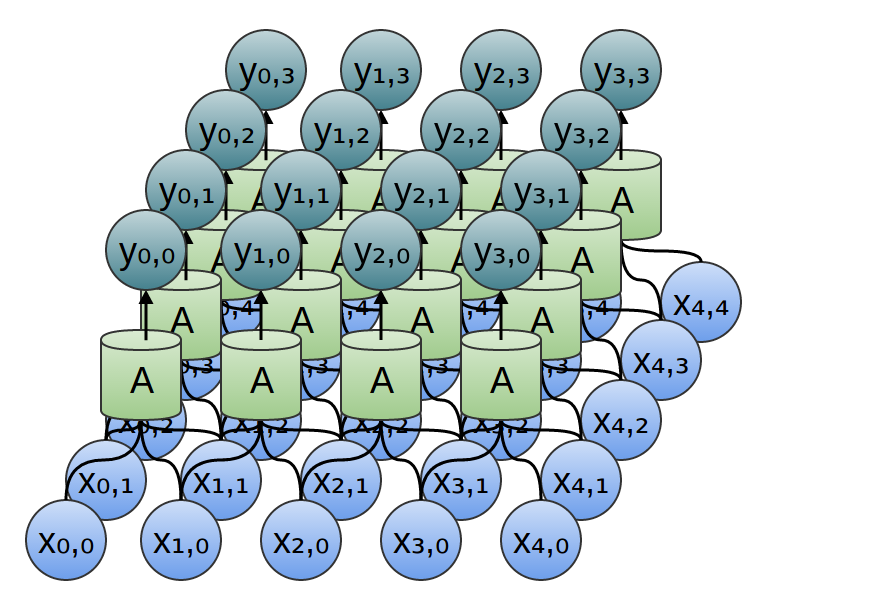
Le réseau peut être représenté par une matrice de valeurs bidimensionnelle.
Conclusion
L'opération de convolution est un outil puissant. En mathématiques, l'opération de convolution se pose dans différents contextes, de l'étude des équations aux dérivées partielles à la théorie des probabilités. En partie à cause de son rôle dans la PDE, la convolution est importante dans les sciences physiques. La convolution joue également un rôle important dans de nombreux domaines d'application, tels que l'infographie et le traitement du signal.