
La
phase de qualification de DataScienceGame2018, qui s'est déroulée au format kaggle InClass, s'est récemment terminée.
DataScienceGame est un concours international d'étudiants organisé sur une base annuelle. Notre équipe a réussi à être à la 3ème place parmi plus de 100 équipes et en même temps NE PAS aller à l'étape finale.
Interaction d'équipe

Dans les grandes compétitions de kaggle, les équipes sont généralement formées en cours de route par des personnes ayant une avance proche dans le classement (un
exemple typique d'une équipe ), et représentent donc différentes villes et, souvent, différents pays. Immédiatement, selon les termes du concours, chaque équipe doit être composée de 4 personnes d'un établissement d'enseignement (nous représentions le MIPT). Et cela signifie que la plupart des participants, il me semble, toutes les discussions ont eu lieu hors ligne. Par exemple, nous avions toute l'équipe vivant sur un étage de l'auberge, nous nous sommes donc réunis le soir avec quelqu'un dans la chambre.
Nous n'avions pas de séparation des tâches, de planification ou de constitution d'équipe. Au début du concours, nous nous sommes simplement assis en cercle, avons discuté de ce que nous pouvons faire à l'avenir et nous ne l'avons pas fait. Le code a été écrit par une seule personne, et les autres à l'époque ont simplement regardé et donné des conseils. Je n'aime pas vraiment écrire du code, j'ai donc aimé cette interaction, même si ce n'était évidemment pas la meilleure. Mais comme la phase de qualification s'est déroulée exactement lors de la session à l'université, une partie de l'équipe n'a pas pu consacrer beaucoup de temps et j'ai quand même dû écrire le code moi-même.
Description de la tâche
Selon l'historique fourni par BNP, il était nécessaire de prédire si l'utilisateur serait intéressé par une certaine sécurité (Isin) la semaine prochaine ou non. Dans le même temps, l '«intérêt» était déterminé par la colonne TradeStatus, qui décrivait l'état de la transaction et avait les valeurs uniques suivantes:
- La transaction a été effectuée (c'est-à-dire que l'utilisateur a acheté / vendu du papier)
- L'utilisateur a regardé le document, mais n'a pas effectué de transaction
- L'utilisateur réserve du papier pour un futur achat / vente
- La transaction n'a pas été conclue pour des raisons techniques.
- Tenir
Donc, si TradeStatus prend la valeur 1) -4), il est considéré que l'utilisateur était intéressé par cet article et n'était pas intéressé par tous les autres cas. Dans le même temps, le paragraphe 4) indiquait que la ligne avec cette transaction était fictive et avait été faite pour faciliter les rapports. À savoir, à la fin de chaque mois, le statut du portefeuille de chaque utilisateur a été comparé à son état il y a un mois, et si, par exemple, l'utilisateur en quelque sorte dans le portefeuille, le montant d'une certaine sécurité a augmenté de 10 000, alors cette même ligne marquée «achat» "Et avec une valeur nominale de 10k. Les lignes marquées «en attente» avaient une variable cible de 0 (l'utilisateur n'était pas intéressé).
Si vous y réfléchissez, vous pouvez comprendre que l'ensemble de données se déroulait comme suit: les utilisateurs étaient actifs sur le site Web de la banque - ils ont cherché / acheté des papiers, et toutes ces actions ont été enregistrées dans la base de données. Par exemple, un utilisateur avec id = 15 a décidé de reporter le papier avec id = 7 pour de futurs achats. Immédiatement dans la base de données est apparue la ligne correspondante avec la cible 1 (l'utilisateur s'est intéressé)
| Identifiant utilisateur | Identifiant de sécurité | Type de transaction | Statut de l'accord | Champs supplémentaires | Cible |
|---|
| 15 | 7 | Acheter | Mettre de côté pour l'avenir | ... | 1 |
De plus, des enregistrements mensuels avec le statut de détention et la cible 0 ont été ajoutés à cela. Par exemple, l'utilisateur 15 a augmenté le nombre de parts 93 pour une raison quelconque (peut-être l'a-t-il acheté sur un autre site), alors qu'il n'a pas lui-même utilisé ce papier sur le site Web de BNP interagi (pas intéressé).
| Identifiant utilisateur | Identifiant de sécurité | Type de transaction | Statut de l'accord | Champs supplémentaires | Cible |
|---|
| 15 | 93 | Acheter | Tenir | ... | 0 |
Mais, évidemment, pour BNP, il est inutile de prédire ces mêmes avoirs, car ils peuvent être restaurés sans ambiguïté à partir de la base. Cela signifie qu'il existe un autre type de jetons qui ne figurent pas dans la table de formation, à savoir les triplets «utilisateur - papier - type de transaction» qui n'apparaissent pas dans la base de données. Autrement dit, l'utilisateur n'était PAS intéressé par une certaine action, cela signifie qu'il n'a pas interagi avec elle dans le système BNP, donc la ligne correspondante n'apparaissait pas dans la base de données, ce qui signifie qu'il devrait avoir une cible de 0. Et cela suggère que vous devez générer de telles lignes pour vous entraîner vous-même ( voir la section «Compilation d'un exemple de formation»). Tout cela pourrait créer une certaine confusion, car de nombreux participants pensaient probablement - il existe un ensemble de données, il y a des zéros et des uns - que vous pouvez prévoir. Mais pas si simple.
Ainsi, dans le train, il y a un tableau avec l'historique des transactions (c'est-à-dire l'interaction «utilisateur - papier - type de transaction» et quelques informations supplémentaires à leur sujet) et un tas d'autres plaques avec les caractéristiques de l'utilisateur, le stock, les conditions du marché mondial. Dans le test, il n'y a que des triplets «utilisateur - papier - type de transaction» et pour chacun de ces triples, vous devez prédire si elle apparaîtra la semaine prochaine. Par exemple, vous devez prédire si l'utilisateur id = 8 sera intéressé par l'action id = 46 avec le type de transaction «vente»?
| Identifiant utilisateur | Identifiant de sécurité | Type de transaction | Cible |
|---|
| 8 | 46 | À vendre | ? |
Caractéristiques de la création d'un ensemble de données
Comme, comme je l'ai déjà dit, dans la vraie base de données BNP, il n'y avait pas de lignes avec des zéros «non conservés», les organisateurs ont en quelque sorte généré ces lignes pour le test eux-mêmes. Et là où il y a génération de données artificielles, il y a souvent des visages et d'autres informations implicites qui peuvent améliorer considérablement le résultat sans changer les modèles / fonctionnalités. Cette section décrit certaines caractéristiques de la construction d'un ensemble de données que nous avons réussi à comprendre, mais qui, malheureusement, ne nous ont d'aucune façon aidé.

Si vous regardez les triplets «utilisateur - papier - type de transaction» dans le tableau de test, il est facile de remarquer que le nombre de transactions avec les types «achat» et «vente» est exactement le même, et le tableau est strictement trié par cet attribut: d'abord tous les achats, puis tous les ventes. Évidemment, ce n'est pas un accident et la question se pose: comment cela a-t-il pu arriver? Par exemple, de cette façon: les organisateurs ont pris tous les vrais enregistrements de leur base de données pour la semaine dont nous avons besoin pour faire une prédiction (ces lignes ont un objectif de 1), ont en quelque sorte généré de nouvelles lignes (leur objectif est 0), qui ne coïncident pas avec celles décrites ci-dessus. Il s'est donc avéré un tableau dans lequel les types de transactions (achat / vente) sont organisés dans un ordre aléatoire:
| Identifiant utilisateur | Identifiant de sécurité | Type de transaction | Cible |
|---|
| 8 | 46 | À vendre | 1 |
| 2 | 6 | Acheter | 1 |
| 158 | 73 | Acheter | 1 |
| 3 | 29 | À vendre | 0 |
| 67 | 9 | Acheter | 0 |
| 17 | 465 | À vendre | 0 |
Il est maintenant possible de définir le type d'achat sur toutes les lignes avec le type de transaction "vente", et si la cible était une, elle deviendra nulle (dans la plupart des cas, l'utilisateur était intéressé par du papier avec un seul statut: achat ou vente). Cela se traduira par le tableau suivant:
| Identifiant utilisateur | Identifiant de sécurité | Type de transaction | Cible |
|---|
| 8 | 46 | Acheter | 0 |
| 2 | 6 | Acheter | 1 |
| 158 | 73 | Acheter | 1 |
| 3 | 29 | Acheter | 0 |
| 67 | 9 | Acheter | 0 |
| 17 | 465 | Acheter | 0 |
La dernière étape reste: faire de même, mais en remplaçant "l'achat à vendre" et organiser les bons objectifs:
| Identifiant utilisateur | Identifiant de sécurité | Type de transaction | Cible |
|---|
| 8 | 46 | À vendre | 1 |
| 2 | 6 | À vendre | 0 |
| 158 | 73 | À vendre | 0 |
| 3 | 29 | À vendre | 0 |
| 67 | 9 | À vendre | 0 |
| 17 | 465 | À vendre | 0 |
En concaténant la table avec «achats» et la table avec «ventes», nous obtenons (si nous étions les organisateurs) une table telle qu'elle nous a été donnée dans le test. Il est facile de comprendre que les première et deuxième moitiés des tables ainsi construites ont le même ordre de paires utilisateur-papier, ce qui s'est avéré être le cas dans la table de test.
Une autre caractéristique était qu'il y avait beaucoup de lignes dans l'ensemble de données de formation dans lesquelles l'index d'utilisateur était répété plusieurs fois de suite, malgré le fait que l'ensemble de données n'était trié par aucun des signes:
| Identifiant utilisateur | Identifiant de sécurité | Type de transaction | Cible |
|---|
| 8 | 46 | À vendre | ? |
| 8 | 152 | À vendre | ? |
| 8 | 73 | Acheter | ? |
Le coéquipier a considéré que c'était normal, et le jeu de données a été initialement trié par ID utilisateur, et les organisateurs l'ont simplement mal gâché (par exemple, si le mélange a été organisé sur des permutations aléatoires et qu'il n'y avait pas assez de telles permutations). Essayant de s'en assurer, il est passé par quatre mélanges de différentes bibliothèques, mais nulle part de telles répétitions fréquentes ne se sont produites. Le test avait également cette fonctionnalité. Il y avait une idée que les organisateurs n'avaient pas généré les zéros, mais avaient simplement pris les vieilles paires du train. Pour vérifier, j'ai décidé de faire ce qui suit: pour chaque paire «utilisateur - papier» du test, comparer le numéro de ligne du train lorsque cette paire s'est rencontrée pour la première fois et faire un tracé à partir de cela. Autrement dit, nous regardons la première ligne du test, laissons-la avoir un identifiant utilisateur = 8 et id = papier = 15. Maintenant, nous parcourons le tableau de formation de haut en bas et cherchons quand cette paire est apparue pour la première fois, que ce soit, par exemple, 51e ligne. Nous avons obtenu une comparaison: la 1ère ligne du test était dans le 51e train, nous traçons donc le point avec les coordonnées (1, 51) sur la carte. Nous faisons cela pour l'ensemble du test et obtenons le graphique suivant:
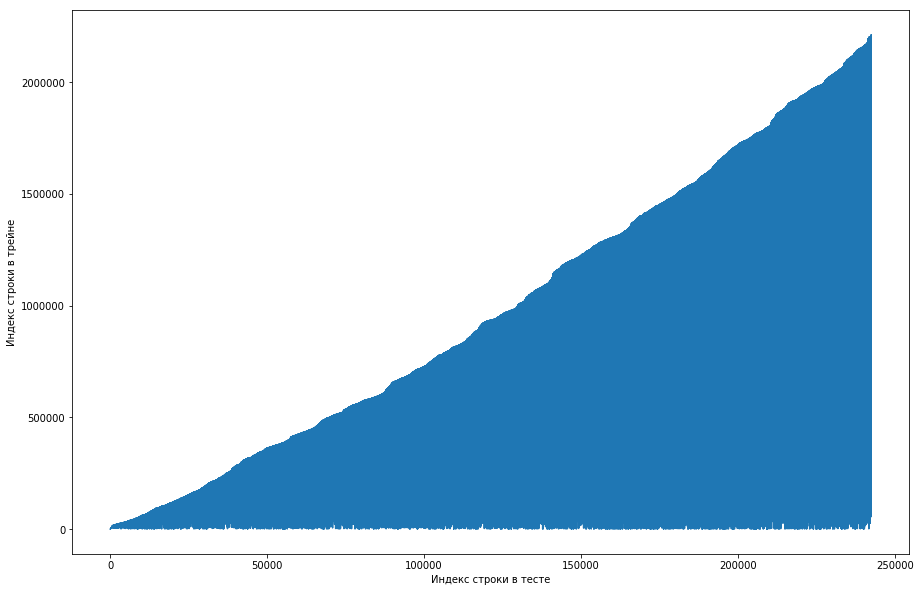
On peut en déduire que, fondamentalement, si un couple s'était déjà rencontré dans le train, alors dans la table de test, sa position sera plus élevée. Mais en même temps, il y a des valeurs aberrantes sur le graphique (il n'y en a pas vraiment beaucoup, mais à cause de la résolution des écrans, il semble qu'il y ait un triangle plein). De plus, le nombre d'émissions coïncidait approximativement avec le nombre prévu d'unités dans le test. Bien sûr, nous avons essayé de marquer les émissions comme des unités et de les envoyer au classement, mais, malheureusement, cela n'a pas fonctionné. Mais il me semblait toujours qu'il pourrait y avoir une sorte de visage (), et, en tant que capitaine de l'équipe, j'ai suggéré de passer plus de temps à comprendre comment cela pouvait se produire, et nous avons encore le temps de former les modèles et de générer les signes. Avertissement: nous avons passé beaucoup de temps à ce sujet, mais une semaine avant la fin du concours, les organisateurs ont écrit sur le forum que seuls les triplets des 6 derniers mois étaient inclus dans le jeu de données de test, et pas tous. Eh bien, si vous effectuez les opérations décrites ci-dessus, mais pour les 6 derniers mois, et pas seulement l'ensemble de données, vous obtenez une courbe monotone plate:
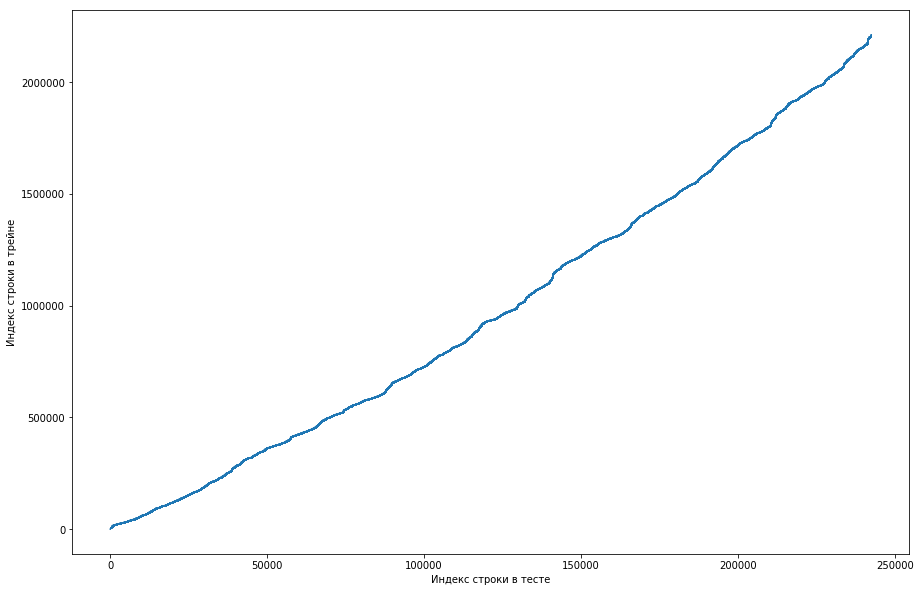
Et cela signifie qu'il n'y a pas de visage ici et ne peut pas l'être.
Mise en place de la formation
Étant donné que dans le test, vous devez faire une prédiction pour les triplets pendant une semaine, nous diviserons l'ensemble de données de formation en semaines (en même temps, chaque semaine, il y a en moyenne 20 000 triplets «utilisateur - papier - type de transaction»). Maintenant, pour trois personnes, nous pouvons dire si elle s'est rencontrée au cours d'une semaine donnée ou non. Dans le même temps, nous avons déjà des triplets positifs (ce sont tous des entrées de cette semaine dans la table des trains), et des négatifs doivent être générés d'une manière ou d'une autre. Il existe de nombreuses options pour ce faire. Par exemple, vous pouvez trier absolument tous les triplets qui n'étaient pas là pendant une semaine particulière dans l'ensemble de données d'entraînement. Il est clair que l'échantillon sera alors très déséquilibré, ce qui est mauvais. Vous pouvez d'abord générer des utilisateurs proportionnellement à la fréquence de leur occurrence dans l'ensemble de données, puis leur ajouter des promotions. Mais avec cette approche, il y aura un tas de lignes pour lesquelles des statistiques raisonnables ne peuvent pas être calculées, ce qui est également mauvais. Comme nous l'avons fait: nous avons pris toutes sortes de triplets précédemment rencontrés dans le train, les avons copiés, en remplaçant acheter / vendre par l'opposé, et avons concaténé ces deux tables. Il est clair que des doublons auraient pu se produire de cette façon (par exemple, si l'utilisateur avait déjà acheté et vendu un stock), mais ils étaient peu nombreux et, après la suppression, un tableau de 500 000 triplets uniques a été obtenu. C'est tout, maintenant pour chaque semaine pour chacun de ces triples, vous pouvez dire si elle s'est rencontrée ou non (et combien de fois?).
Étant donné qu'il s'agit essentiellement de séries chronologiques - un utilisateur examine une annonce spécifique plusieurs fois par semaine, nous allons créer un tableau pour former le classificateur de manière classique pour les séries chronologiques. À savoir, nous prendrons la dernière semaine disponible du train, voir si tous les trois «client - isin - acheter ou vendre» se sont rencontrés cette semaine. Ce sera une cible. Et nous compterons diverses statistiques comme fonctionnalités, par exemple, au cours des 6 dernières semaines (plus d'informations sur les statistiques dans la section "Signes"). Maintenant, oublions l'existence de la semaine dernière et faisons de même, mais pour l'avant-dernière semaine et concaténons les tableaux. Cela peut être fait plusieurs fois, augmentant ainsi le train de «hauteur», mais en même temps, l'intervalle sur lequel nous considérons les statistiques diminue naturellement. Nous avons répété cette opération 10 fois, car si nous en faisions plus, les vacances du Nouvel An et les problèmes connexes seraient ciblés, ce qui aggraverait la qualité finale du modèle. Image explicative:
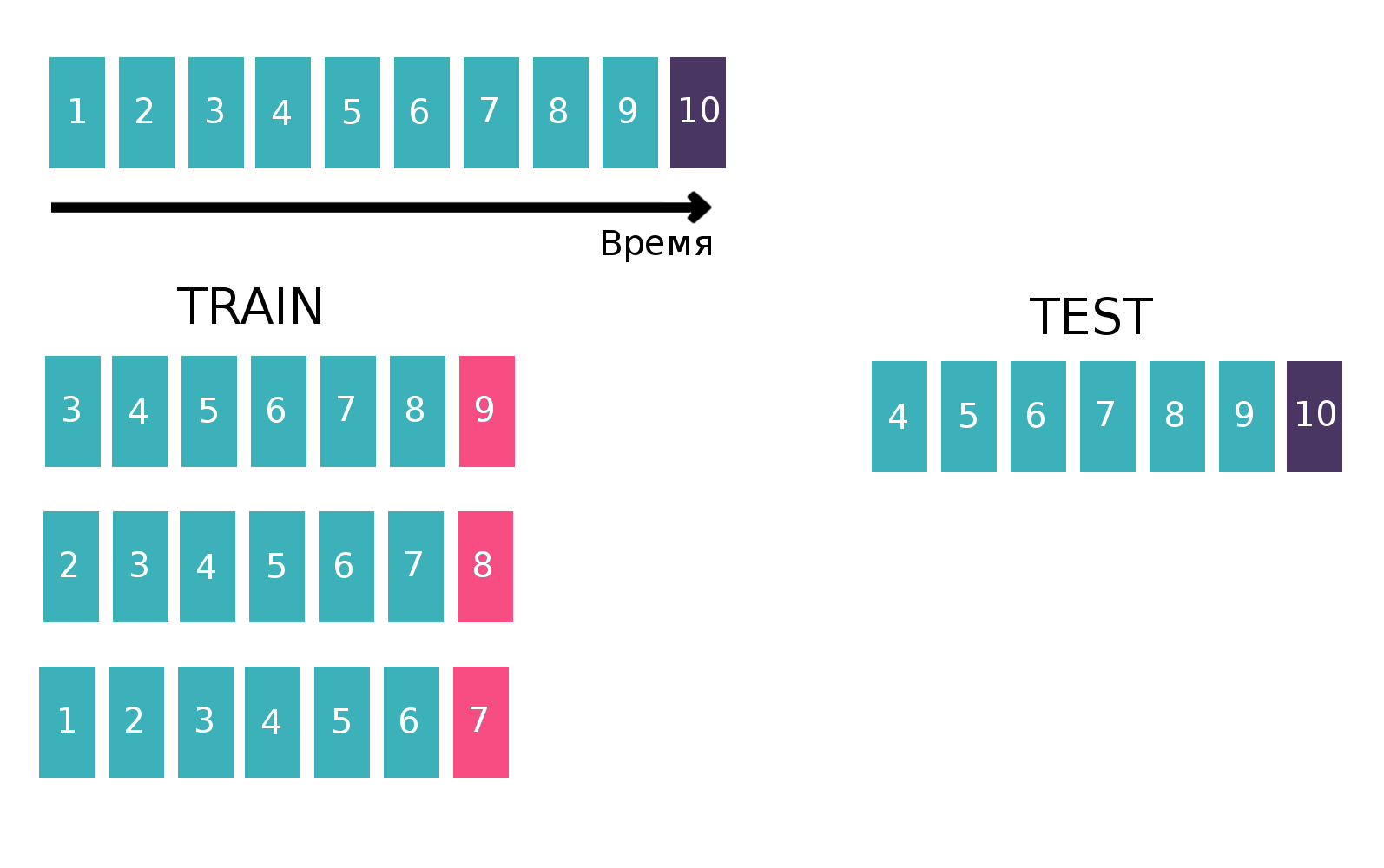
Pour plus d'informations sur les séries chronologiques et la validation des séries chronologiques,
cliquez ici .
Signes
Comme je l'ai dit, il y avait de nombreux tableaux qui caractérisaient en quelque sorte les conditions des utilisateurs, des actions ou du marché mondial (principales devises et certains indicateurs). Mais tous n'ont quasiment pas amélioré la qualité, et les principaux signes étaient des statistiques calculées pour les paires «client - isin» et triples «client - isin - acheter ou vendre», par exemple, telles que:
- À quelle fréquence un couple / trois se sont-ils rencontrés au cours des 1, 2, 5, 20, 100 dernières semaines?
- Statistiques sur les intervalles de temps entre les réunions d'une paire / triples dans un ensemble de données (moyenne, std, max, min)
- La distance dans le temps à la première / dernière fois qu'un couple / trois se sont rencontrés
- La proportion de chaque valeur TradeStatus pour une paire / triple
- Statistiques sur combien de fois par semaine un couple / triple se produit (moyenne, std, max, min)
De plus, le dernier jour du concours, j'ai lu sur le formulaire que pour vendre un stock, vous devez d'abord l'acheter. Cette connaissance vous permet de trouver de nombreux signes plus utiles, mais, pour une raison quelconque, pour moi, ce n'était pas évident.
Dans le code, tout cela était exprimé par une fonction de 200 lignes de longueur, qui générait des signes similaires pour chacun des dix trains (pour la partie où la cible, par exemple, la semaine 7, nous ne devrions pas utiliser les informations pour le 8 et le 9). En tenant compte des tableaux supplémentaires, environ 300 panneaux ont été recrutés. Comme je l'ai déjà dit, nous avons généré 500 000 triplets uniques et pris les 10 dernières semaines comme cibles, donc la table de formation «élevée» était de 500 000 * 10 = 5 000 lignes.
Quelques autres aveux ont été décrits dans
la deuxième décision . Les gars ont construit une table utilisateur / papier, où dans chaque cellule il y avait une unité si l'utilisateur était jamais intéressé par ce papier et zéro sinon. En calculant la distance cosinus entre les utilisateurs dans ce tableau, vous pouvez obtenir la convergence des utilisateurs entre eux. Si vous appliquez l'ACP au tableau de similarité résultant, vous obtenez un ensemble de fonctionnalités qui caractérisent l'utilisateur d'une manière ou d'une autre.
Modèles ou se battre pour des millièmes
Il convient de noter que pendant près de trois semaines, personne n'a pu battre la ligne de base du BNP, qui avait une vitesse de 0,794 (ROC AUC) au classement, et cela malgré le fait que la décision de «simplement compter le nombre de fois où le couple s'est rencontré plus tôt» a donné 0,71 au classement, et certains les participants ont reçu tous les 0,74 sans avoir recours à l'apprentissage automatique.
Mais nous avons utilisé le machine learning, d'ailleurs, le dernier jour de la compétition (qui a coïncidé par coïncidence avec la fin de la session), nous avons décidé d'arrêter
si vous savez ce que je veux dire et de faire un grand mélange de différents modèles formés sur différents sous-ensembles de signes avec différents nombres de semaines dans Train. Comme je l'ai déjà dit, notre échantillon de formation se composait de 1,5k lignes, avec une cible parmi elles environ 150k. La taille du test était de 400k, alors que le nombre estimé d'unités était de 20k (en moyenne, il y a tellement de triplets uniques). Autrement dit, la proportion d'unités dans le test était significativement plus élevée que dans le train. Par conséquent, dans tous nos modèles, nous avons ajusté le paramètre scale_pos_weight, qui place le poids sur les classes. Plus d'informations sur ce paramètre peuvent être trouvées dans l'
analyse de la meilleure solution de l'un des DataScienceGame de l'année dernière. La matrice de corrélation des prédictions de nos modèles est présentée dans la figure:
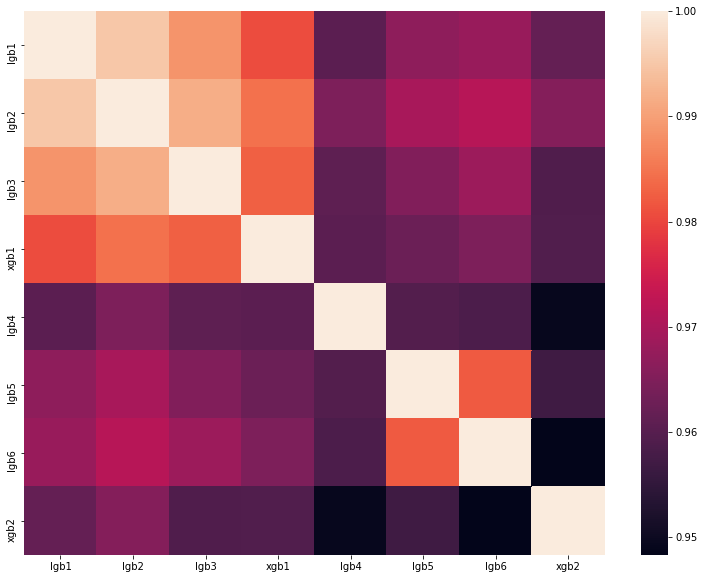
Comme vous pouvez le voir, nous avions beaucoup de modèles très différents, ce qui nous a permis d'obtenir une vitesse de 0,80204 au classement.
Pourquoi on ne va pas en France pour la phase finale
En conséquence, nous avons montré un bon résultat et pris la troisième place du classement privé. Mais les organisateurs ont fixé les règles suivantes pour la sélection des finalistes:
- Pas plus de 20 meilleures équipes
- Pas plus de 5 meilleures équipes du pays
- Pas plus d'une équipe d'un établissement d'enseignement
Et tout irait bien si une autre équipe de l'Institut de physique et de technologie de Moscou avec la vitesse de 0.80272 ne serait pas en deuxième position. Autrement dit, nous sommes seulement 0,00068 derrière. C'est dommage, mais il n'y a rien à faire. Très probablement, les organisateurs ont établi de telles règles pour que les gens d'une université ne s'entraident en aucune façon, mais dans notre cas, nous ne savions rien de l'équipe voisine et ne la contactions d'aucune façon.
Résumé
Cette année en septembre à Paris, 5 équipes russes, 1 ukrainienne et 2 allemandes et finlandaises, composées d'étudiants russophones, se disputeront la première place. Un total de 8 équipes de la communauté ru, ce qui prouve une fois de plus la dominance du segment ru des données. Et je suis
transféré à Sharaga, je m'entraîne et
je travaille sur moi-même, pour que l'année prochaine je puisse encore franchir l'étape de qualification.