Cet article ne couvrira pas les bases d'Hibernate (comment définir une entité ou écrire une requête de critères). Ici, je vais essayer de parler de points plus intéressants qui sont vraiment utiles dans le travail. Informations sur lesquelles je n'ai pas rencontré en un seul endroit.

Je ferai une réservation tout de suite. Tout ce qui suit est vrai pour Hibernate 5.2. Des erreurs sont également possibles du fait que j'ai mal compris quelque chose. Si vous trouvez - écrivez.
Problèmes de mappage d'un modèle d'objet dans un relationnel
Mais commençons par les bases de l'ORM. ORM - mapping objet-relationnel - en conséquence, nous avons des modèles relationnels et objet. Et lors de l'affichage les uns des autres, il y a des problèmes que nous devons résoudre nous-mêmes. Prenons-les à part.
Pour illustrer cela, prenons l'exemple suivant: nous avons l'entité «Utilisateur», qui peut être un Jedi ou un avion d'attaque. Les Jedi doivent avoir de la force et la spécialisation des avions d'attaque. Voici un diagramme de classes.
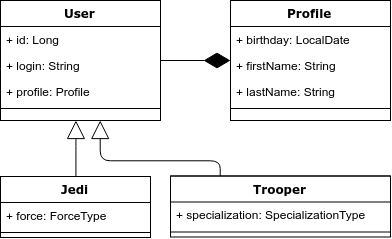
Problème 1. Héritage et requêtes polymorphes.
Il existe un héritage dans le modèle objet, mais pas dans le modèle relationnel. En conséquence, c'est le premier problème - comment mapper correctement l'héritage au modèle relationnel.
Hibernate propose 3 options pour afficher un tel modèle d'objet:
- Tous les héritiers sont dans le même tableau:
@Inheritance (stratégie = InheritanceType.SINGLE_TABLE)

Dans ce cas, les champs communs et les champs des héritiers se trouvent dans une seule table. En utilisant cette stratégie, nous évitons les jointures lors de la sélection des entités. Parmi les inconvénients, il convient de noter que, premièrement, nous ne pouvons pas définir la restriction «NOT NULL» pour la colonne «force» dans le modèle relationnel, et deuxièmement, nous perdons la troisième forme normale. (une dépendance transitive d'attributs non clés apparaît: force et disque).
Soit dit en passant, y compris pour cette raison, il existe 2 façons de spécifier une contrainte de champ non nulle - NotNull est responsable de la validation; @Column (nullable = true) - responsable de la contrainte non null dans la base de données.
À mon avis, c'est la meilleure façon de mapper un modèle objet sur un modèle relationnel.
- Les champs spécifiques à l'entité se trouvent dans une table distincte.
@Inheritance (stratégie = InheritanceType.JOINED)
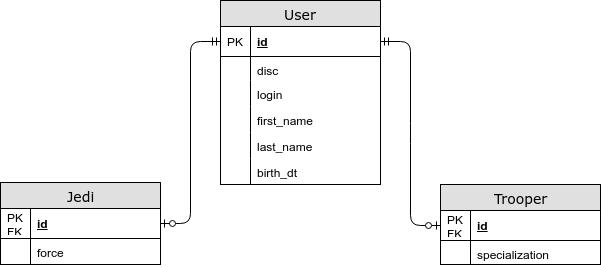
Dans ce cas, les champs communs sont stockés dans une table commune, et spécifiques aux entités enfants sont stockés dans des entités distinctes. En utilisant cette stratégie, nous obtenons un JOIN lors du choix d'une entité, mais maintenant nous enregistrons le troisième formulaire normal, et nous pouvons également spécifier une contrainte NOT NULL dans la base de données. - Chaque entité a sa propre table.
@ InheritanceType.TABLE_PER_CLASS
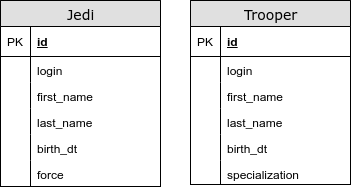
Dans ce cas, nous n'avons pas de table commune. En utilisant cette stratégie, nous utilisons UNION pour les requêtes polymorphes. Nous rencontrons des problèmes avec les générateurs de clés primaires et d'autres contraintes d'intégrité. Ce type de mappage d'héritage est fortement déconseillé.
Au cas où, je mentionnerai l'annotation - @MappedSuperclass. Il est utilisé lorsque vous souhaitez «masquer» des champs communs pour plusieurs entités du modèle objet. De plus, la classe annotée elle-même n'est pas considérée comme une entité distincte.
Problème 2. Rapport de composition en POO
Revenant à notre exemple, nous notons que dans le modèle objet, nous avons pris le profil utilisateur dans une entité distincte - Profil. Mais dans le modèle relationnel, nous n'avons pas sélectionné de table distincte pour cela.
L'attitude OneToOne est souvent une mauvaise pratique car dans select, nous avons un JOIN injustifié (même en spécifiant fetchType = LAZY dans la plupart des cas, nous aurons JOIN - nous discuterons de ce problème plus tard).
Il existe des annotations @Embedable et @Embeded pour afficher une composition dans un tableau commun. Le premier est placé au-dessus du champ et le second au-dessus de la classe. Ils sont interchangeables.
Gestionnaire d'entités
Chaque instance d'EntityManager (EM) définit une session d'interaction avec la base de données. Au sein d'une instance EM, il existe un cache de premier niveau. Ici, je vais souligner les points importants suivants:
- Capture de la connexion à la base de données
Ceci est juste un point intéressant. Hibernate ne capture pas la connexion au moment de la réception de l'EM, mais au premier accès à la base de données ou à l'ouverture de la transaction (bien que ce problème puisse être résolu ). Ceci est fait afin de réduire le temps de connexion occupée. Lors de la réception d'EM-a, la présence d'une transaction JTA est vérifiée. - Les entités persistantes ont toujours un identifiant
- Les entités décrivant une ligne dans la base de données sont équivalentes par référence
Comme mentionné ci-dessus, EM a un cache de premier niveau, les objets y sont comparés par référence. En conséquence, la question se pose - quels champs doivent être utilisés pour remplacer égal et hashcode? Considérez les options suivantes:
- Comment fonctionne le rinçage
Flush - exécute les insert-s, update-s et delete-s accumulés dans la base de données. Par défaut, le vidage est exécuté dans les cas:
- Avant d'exécuter la requête (à l'exception d'em.get), cela est nécessaire pour se conformer au principe ACID. Par exemple: nous avons changé la date de naissance de l'avion d'attaque, puis nous avons voulu obtenir le nombre d'avions d'attaque adultes.
Si nous parlons de CriteriaQuery ou JPQL, alors le vidage sera exécuté si la requête affecte une table dont les entités sont dans le cache du premier niveau. - Lors de la validation d'une transaction;
- Parfois, lors de la persistance d'une nouvelle entité - dans le cas où nous ne pouvons obtenir son identifiant que par insertion.
Et maintenant un petit test. Combien d'opérations UPDATE seront effectuées dans ce cas?
val spaceCraft = em.find(SpaceCraft.class, 1L); spaceCraft.setCoords(...); spaceCraft.setCompanion( findNearestSpaceCraft(spacecraft) );
Une fonctionnalité d'hibernation intéressante est cachée sous l'opération de vidage - elle essaie de réduire le temps nécessaire pour verrouiller les lignes dans la base de données.
Notez également qu'il existe différentes stratégies pour l'opération de rinçage. Par exemple, vous pouvez interdire la «fusion» des modifications apportées à la base de données - elle est appelée MANUELLE (elle désactive également le mécanisme de vérification incorrecte).
- Vérification sale
Dirty Checking est un mécanisme exécuté lors d'une opération de vidage. Son but est de trouver des entités qui ont changé et de les mettre à jour. Pour implémenter un tel mécanisme, hibernate doit stocker la copie originale de l'objet (avec quoi l'objet réel sera comparé). Pour être plus précis, hibernate stocke une copie des champs de l'objet, pas l'objet lui-même.
Il convient de noter que si le graphique des entités est grand, l'opération de vérification incorrecte peut être coûteuse. N'oubliez pas qu'hibernate stocke 2 copies d'entités (grosso modo).
Afin de "réduire le coût" de ce processus, utilisez les fonctionnalités suivantes:
- em.detach / em.clear - détache des entités d'EntityManager
- FlushMode = MANUAL- utile dans les opérations de lecture
- Immuable - évite également les opérations de vérification sales
- Les transactions
Comme vous le savez, hibernate vous permet de mettre à jour des entités uniquement dans une transaction. Les opérations de lecture offrent plus de liberté - nous pouvons les exécuter sans ouvrir explicitement une transaction. Mais c'est précisément la question: cela vaut-il la peine d'ouvrir une transaction explicitement pour les opérations de lecture?
Je citerai quelques faits:
- Toute instruction est exécutée dans la base de données à l'intérieur de la transaction. Même si nous ne l'avons évidemment pas ouvert. (mode auto-commit).
- En règle générale, nous ne sommes pas limités à une seule requête dans la base de données. Par exemple: pour obtenir les 10 premiers enregistrements, vous souhaiterez probablement renvoyer le nombre total d'enregistrements. Et c'est presque toujours 2 demandes.
- Si nous parlons de données de printemps, les méthodes de référentiel sont transactionnelles par défaut , tandis que les méthodes de lecture sont en lecture seule.
- L'annotation @Transactional spring (readOnly = true) affecte également FlushMode, plus précisément, Spring la met en statut MANUAL, ainsi la mise en veille prolongée n'effectuera pas de vérification de la saleté.
- Des tests synthétiques avec une ou deux requêtes de base de données montreront que la validation automatique est plus rapide. Mais en mode combat, ce n'est peut-être pas le cas. ( excellent article sur ce sujet , + voir commentaires)
En un mot: il est de bonne pratique d'effectuer toute communication avec la base de données lors d'une transaction.
Générateurs
Des générateurs sont nécessaires pour décrire comment les clés primaires de nos entités recevront des valeurs. Passons rapidement en revue les options:
- GenerationType.AUTO - la sélection du générateur est basée sur le dialecte. Ce n'est pas la meilleure option, car la règle «explicite vaut mieux que l'implicite» s'applique juste ici.
- GenerationType.IDENTITY est le moyen le plus simple de configurer un générateur. Il s'appuie sur la colonne d'incrémentation automatique du tableau. Par conséquent, pour obtenir id avec persist, nous devons faire une insertion. C'est pourquoi il élimine la possibilité de persistance différée et donc de batch.
- GenerationType.SEQUENCE est le cas le plus pratique lorsque nous obtenons id à partir d'une séquence.
- GenerationType.TABLE - dans ce cas, hibernate émule une séquence via une table supplémentaire. Pas la meilleure option, car dans une telle solution, hibernate doit utiliser une transaction distincte et verrouiller par ligne.
Parlons un peu plus de séquence. Afin d'augmenter la vitesse de fonctionnement, hibernate utilise différents algorithmes d'optimisation. Tous visent à réduire le nombre de conversations avec la base de données (le nombre d'aller-retour). Examinons-les plus en détail:
- aucune - aucune optimisation. pour chaque id, nous tirons la séquence.
- pooled et pooled-lo - dans ce cas, notre séquence doit augmenter d'un certain intervalle - N dans la base de données (SequenceGenerator.allocationSize). Et dans l'application, nous avons un certain pool, les valeurs à partir desquelles nous pouvons attribuer à de nouvelles entités sans accéder à la base de données ..
- hilo - pour générer un ID, l'algorithme hilo utilise 2 nombres: hi (stocké dans la base de données - la valeur obtenue à partir de l'appel de séquence) et lo (stocké uniquement dans l'application - SequenceGenerator.allocationSize). Sur la base de ces chiffres, l'intervalle de génération de id est calculé comme suit: [(hi - 1) * lo + 1, hi * lo + 1). Pour des raisons évidentes, cet algorithme est considéré comme obsolète et il n'est pas recommandé de l'utiliser.
Voyons maintenant comment l'optimiseur est sélectionné. Hibernate possède plusieurs générateurs de séquences. Nous serons intéressés par 2 d'entre eux:
- SequenceHiLoGenerator est un ancien générateur qui utilise l'optimiseur hilo. Sélectionné par défaut si nous avons la propriété hibernate.id.new_generator_mappings == false.
- SequenceStyleGenerator - utilisé par défaut (si la propriété hibernate.id.new_generator_mappings == true). Ce générateur prend en charge plusieurs optimiseurs, mais la valeur par défaut est mise en commun.
Vous pouvez également configurer l'annotation du générateur @GenericGenerator.
Impasse
Regardons un exemple de situation de pseudo-code qui peut conduire à un blocage:
Thread #1: update entity(id = 3) update entity(id = 2) update entity(id = 1) Thread #2: update entity(id = 1) update entity(id = 2) update entity(id = 3)
Pour éviter de tels problèmes, hibernate dispose d'un mécanisme qui évite les blocages de ce type - le paramètre hibernate.order_updates. Dans ce cas, toutes les mises à jour seront ordonnées par id et exécutées. Je mentionnerai également une fois de plus qu'hibernate essaie de "retarder" la capture de la connexion et l'exécution des insert-s et update-s.
Ensemble, sac, liste
Hibernate a 3 façons principales de présenter la collection de communication OneToMany.
- Ensemble - un ensemble non ordonné d'entités sans répétitions;
- Sac - un ensemble non ordonné d'entités;
- La liste est un ensemble ordonné d'entités.
Il n'y a pas de classe pour Bag in java core qui décrirait une telle structure. Par conséquent, toutes les listes et collections sont sac sauf si vous spécifiez une colonne selon laquelle notre collection sera triée (annotation OrderColumn. À ne pas confondre avec SortBy). Je déconseille fortement d'utiliser l'annotation OrderColumn en raison de la mauvaise mise en œuvre (à mon avis) des fonctionnalités - pas de requêtes SQL optimales, NULL possibles dans la feuille.
La question se pose, mais quoi de mieux d'utiliser un sac ou un ensemble? Pour commencer, lors de l'utilisation d'un sac, les problèmes suivants sont possibles:
- Si votre version de hibernate est inférieure à 5.0.8, alors il y a un bug assez sérieux - HHH-5855 - la duplication est possible lors de l'insertion d'une entité enfant (dans le cas de cascadType = MERGE et PERSIST);
- Si vous utilisez bag pour la relation ManyToMany, hibernate génère des requêtes extrêmement inappropriées lors de la suppression d'une entité de la collection - il supprime d'abord toutes les lignes de la table de jointure, puis effectue l'insertion;
- Hibernate ne peut pas récupérer plusieurs sacs pour la même entité en même temps.
Dans le cas où vous souhaitez ajouter une autre entité à la connexion @OneToMany, il est plus rentable d'utiliser Bag, car il ne nécessite pas de charger toutes les entités liées pour cette opération. Voyons un exemple:
Références de force
La référence est une référence à un objet, que nous avons décidé de reporter le chargement. Dans le cas de la relation de ManyToOne avec fetchType = LAZY, nous obtenons une telle référence. L'initialisation de l'objet a lieu au moment de l'accès aux champs de l'entité, à l'exception de id (puisque nous connaissons la valeur de ce champ).
Il convient de noter que dans le cas du chargement différé, la référence fait toujours référence à une ligne existante dans la base de données. Pour cette raison, la plupart des cas de chargement différé ne fonctionnent pas dans les relations OneToOne - la mise en veille prolongée doit être jointe pour vérifier si la connexion existe et il y avait déjà une jointure, puis la mise en veille prolongée la charge dans le modèle d'objet. Si nous indiquons nullable = true dans OneToOne, alors LazyLoad devrait fonctionner.
Nous pouvons créer notre propre référence en utilisant la méthode em.getReference. Certes, dans ce cas, rien ne garantit que la référence se réfère à une ligne existante dans la base de données.
Donnons un exemple d'utilisation d'un tel lien:
Juste au cas où, je vous rappelle que nous obtiendrons une LazyInitializationException en cas d'EM fermé ou de lien détaché.
Date et heure
Malgré le fait que java 8 possède une excellente API pour travailler avec la date et l'heure, l'API JDBC vous permet toujours de travailler uniquement avec l'ancienne API de date. Par conséquent, nous analyserons certains points intéressants.
Tout d'abord, vous devez comprendre clairement les différences entre LocalDateTime et Instant et ZonedDateTime. (Je ne m'étirerai pas, mais je donnerai d'excellents articles sur ce sujet: le
premier et le
deuxième )
Si brièvementLocalDateTime et LocalDate représentent un tuple régulier de nombres. Ils ne sont pas liés à un moment précis. C'est-à-dire l'heure d'atterrissage de l'avion ne peut pas être stockée dans LocalDateTime. Et la date de naissance via LocalDate est tout à fait normale. Instant représente un point dans le temps, par rapport auquel nous pouvons obtenir l'heure locale à n'importe quel point de la planète.
Un point plus intéressant et plus important est la façon dont les dates sont stockées dans la base de données. Si le type TIMESTAMP WITH TIMEZONE est apposé, il ne devrait pas y avoir de problème, mais si TIMESTAMP (WITHOUT TIMEZONE) se tient, il y a une chance que la date soit écrite / lue incorrectement. (hors LocalDate et LocalDateTime)
Voyons pourquoi:
Lorsque nous enregistrons la date, une méthode avec la signature suivante est utilisée:
setTimestamp(int i, Timestamp t, java.util.Calendar cal)
Comme vous pouvez le voir, l'ancienne API est utilisée ici. L'argument Calendar facultatif est nécessaire pour convertir l'horodatage en une représentation sous forme de chaîne. C'est-à-dire qu'il stocke le fuseau horaire en soi. Si le calendrier n'est pas transmis, le calendrier est utilisé par défaut avec le fuseau horaire JVM.
Il existe 3 façons de résoudre ce problème:
- Définissez la JVM de fuseau horaire souhaitée
- Utilisez le paramètre hibernate - hibernate.jdbc.time_zone (ajouté en 5.2) - ne corrigera que ZonedDateTime et OffsetDateTime
- Utilisez le type TIMESTAMP WITH TIMEZONE
Une question intéressante, pourquoi LocalDate et LocalDateTime ne relèvent pas d'un tel problème?
La réponsePour répondre à cette question, vous devez comprendre la structure de la classe java.util.Date (java.sql.Date et java.sql.Timestamp, ses héritiers et leurs différences dans ce cas ne nous dérangent pas). Date stocke la date en millisecondes depuis 1970, grosso modo en UTC, mais la méthode toString convertit la date en fonction de la zone horaire du système.
Par conséquent, lorsque nous obtenons une date sans fuseau horaire de la base de données, elle est mappée à un objet Timestamp afin que la méthode toString affiche sa valeur souhaitée. Dans le même temps, le nombre de millisecondes depuis 1970 peut différer (selon le fuseau horaire). C'est pourquoi seule l'heure locale est toujours affichée correctement.
Je donne également un exemple du code responsable de la conversion de Timesamp en LocalDateTime et Instant:
Batching
Par défaut, les requêtes sont envoyées à la base de données une par une. Lorsque le traitement par lots est activé, hibernate pourra envoyer plusieurs instructions en une seule requête à la base de données. (c'est-à-dire que le traitement par lots réduit le nombre d'aller-retour dans la base de données)
Pour ce faire, vous devez:
- Activez le traitement par lots et définissez le nombre maximal d'instructions:
hibernate.jdbc.batch_size (5 à 30 recommandés) - Activez le tri des insertions et des mises à jour:
hibernate.order_inserts
hibernate.order_updates
- Si nous utilisons le contrôle de version, nous devons également activer
hibernate.jdbc.batch_versioned_data - attention ici, vous avez besoin du pilote jdbc pour pouvoir donner le nombre de lignes affectées lors de la mise à jour.
Je vais également vous rappeler l'efficacité de l'opération em.clear () - elle délie les entités d'em, libérant ainsi de la mémoire et réduisant le temps de l'opération de vérification sale.
Si nous utilisons postgres, nous pouvons également dire hibernate pour utiliser
l'insertion multi-raw .
Problème N + 1
C'est un sujet assez omniprésent, alors revenez-y rapidement.
Un problème N + 1 est une situation où, au lieu d'une seule demande de sélection de N livres, au moins N + 1 demandes se produisent.
La façon la plus simple de résoudre le problème N + 1 consiste à récupérer les tables associées. Dans ce cas, nous pouvons rencontrer plusieurs autres problèmes:
- Pagination. dans le cas des relations OneToMany, hibernate ne pourra pas spécifier de décalage et de limite. Par conséquent, la pagination se produira en mémoire.
- Le problème d'un produit cartésien est une situation où une base de données renvoie N * M * K lignes pour choisir N livres avec M chapitres et K auteurs.
Il existe d'autres façons de résoudre le problème N + 1.
- FetchMode - vous permet de modifier l'algorithme de chargement des entités enfants. Dans notre cas, nous nous intéressons aux éléments suivants:
- FetchType.SUBSELECT - Charge les enregistrements enfants dans une demande distincte. L'inconvénient est que toute la complexité de la requête principale est répétée en sous-sélection.
- BATCH (annotation FetchType.SELECT + BatchSize) - charge également les enregistrements en tant que demande distincte, mais avec la sous-requête, il crée une condition comme WHERE parent_id IN (?,?,?, ..., N)
Il convient de noter que lors de l'utilisation de l'extraction dans l'API Criteria, FetchType est ignoré - JOIN est toujours utilisé - JPA EntityGraph et Hibernate FetchProfile - vous permettent de faire des règles de chargement d'entité dans une abstraction distincte - à mon avis, les deux implémentations sont gênantes.
Test
Idéalement, l'environnement de développement devrait fournir autant d'informations utiles que possible sur le fonctionnement de la mise en veille prolongée et sur l'interaction avec la base de données. À savoir:
- Journalisation
- org.hibernate.SQL: débogage
- org.hibernate.type.descriptor.sql: trace
- Statistiques
- hibernate.generate_statistics
Parmi les utilitaires utiles, on peut distinguer les suivants:
- DBUnit - vous permet de décrire l'état de la base de données au format XML. Parfois, c'est pratique. Mais mieux réfléchir si vous en avez besoin.
- DataSource-proxy
- p6spy est l'une des solutions les plus anciennes. offre une journalisation avancée des requêtes, un runtime, etc.
- com.vladmihalcea: db-util: 0.0.1 est un utilitaire pratique pour trouver les problèmes N + 1. Il vous permet également d'enregistrer des requêtes. La composition comprend une annotation Retry intéressante, qui réessaye la transaction dans le cas d'une exception OptimisticLockException.
- Sniffy - vous permet de faire une affirmation sur le nombre de demandes via l'annotation. À certains égards, plus élégant que la décision de Vlad.
Mais je répète encore une fois que ce n'est que pour le développement, cela ne devrait pas être inclus dans la production.
Littérature