Certains lecteurs ont peut-être déjà entendu parler de Centrifugo . Cet article se concentrera sur le développement de la deuxième version du serveur et de la nouvelle bibliothèque en temps réel pour le langage Go qui le sous-tend.
Je m'appelle Alexander Emelin. L'été dernier, j'ai rejoint l'équipe Avito, où j'aide maintenant à développer le backend messenger Avito. Le nouveau travail, directement lié à la livraison rapide des messages aux utilisateurs, et les nouveaux collègues m'ont inspiré pour continuer à travailler sur le projet open source Centrifugo.

En un mot - c'est un serveur qui se charge de maintenir des connexions constantes des utilisateurs de votre application. Le polyfill Websocket ou SockJS est utilisé comme transport; il peut, s'il n'est pas possible d'établir une connexion Websocket, fonctionner via Eventsource, le streaming XHR, l'interrogation longue et d'autres transports basés sur HTTP. Les clients s'abonnent aux canaux sur lesquels le backend via l'API Centrifuge publie de nouveaux messages au fur et à mesure qu'ils apparaissent - après quoi les messages sont remis aux utilisateurs abonnés au canal. En d'autres termes, c'est un serveur PUB / SUB.
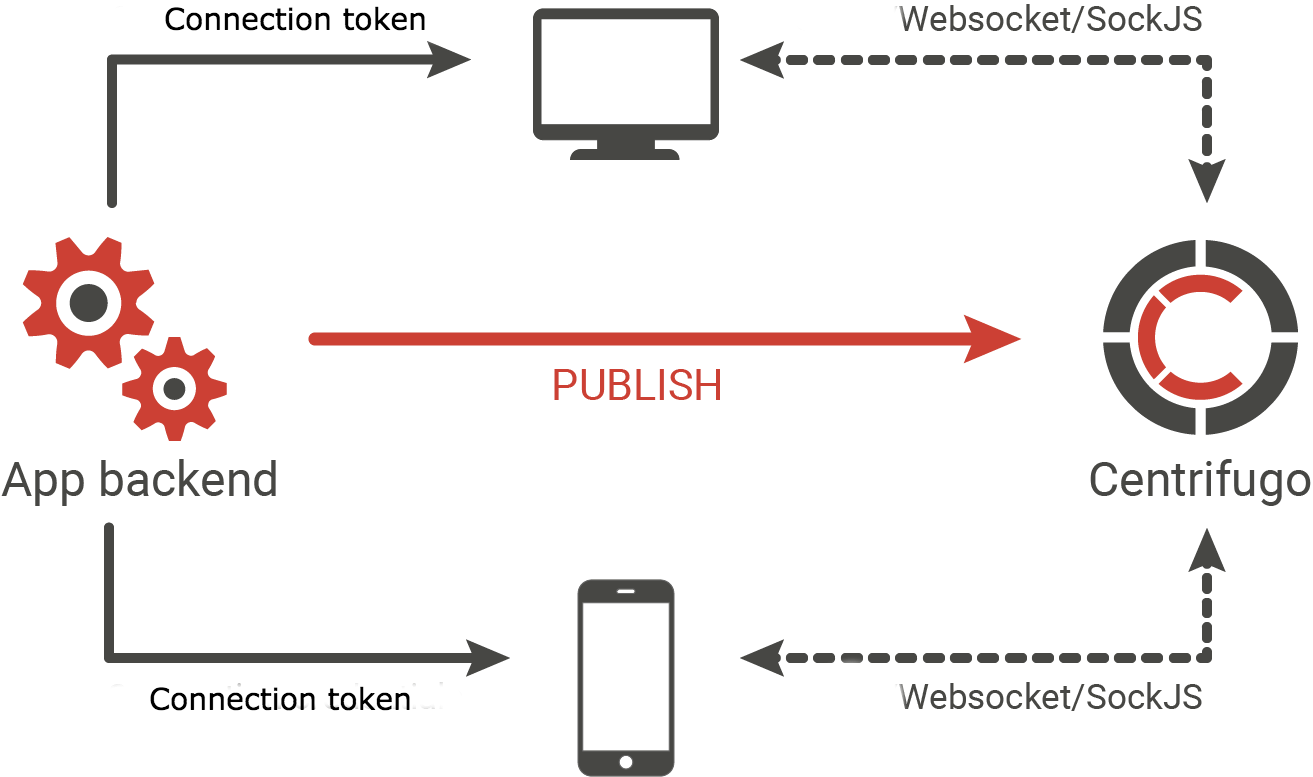
Actuellement, le serveur est utilisé dans un nombre assez important de projets. Parmi eux, par exemple, certains projets Mail.Ru (intranet, plates-formes de formation Technopark / Technosphere, Centre de certification, etc.), avec Centrifugo, un beau tableau de bord fonctionne à la réception du bureau de Badoo à Moscou, et 350 000 utilisateurs sont connectés simultanément au service spot.im à la centrifugeuse.
Quelques liens vers des articles précédents sur le serveur et son application pour ceux qui ont entendu parler pour la première fois du projet:
J'ai commencé à travailler sur la deuxième version en décembre de l'année dernière et continue à ce jour. Voyons ce qui se passe. J'écris cet article non seulement pour vulgariser le projet, mais aussi pour obtenir un retour un peu plus constructif avant la sortie de Centrifugo v2 - maintenant il y a de la place pour la manœuvre et des changements incompatibles.
Bibliothèque en temps réel pour Go
Dans la communauté Go, la question se pose de temps en temps - existe-t-il des alternatives à socket.io sur Go? Parfois, j'ai remarqué que les développeurs en réponse à cela sont invités à se tourner vers Centrifugo. Cependant, Centrifugo est un serveur auto-hébergé, pas une bibliothèque - la comparaison n'est pas juste. On m'a également demandé à plusieurs reprises si le code Centrifugo pouvait être réutilisé pour écrire des applications en temps réel dans Go. Et la réponse était: théoriquement possible, mais je ne pouvais pas garantir la rétrocompatibilité de l'API des packages internes à mes risques et périls. Il est clair qu'il n'y a aucune raison pour que quelqu'un le prenne, et la fourche est également une option. De plus, je ne dirais pas que l'API pour les packages internes a été généralement préparée pour une telle utilisation.
Par conséquent, l'une des tâches ambitieuses que je voulais résoudre dans le processus de travail sur la deuxième version du serveur était d'essayer de séparer le cœur du serveur dans une bibliothèque distincte sur Go. Je crois que cela a du sens, compte tenu du nombre de fonctionnalités de la centrifugeuse pour être adapté à la production. De nombreuses fonctionnalités prêtes à l'emploi permettent de créer des applications évolutives en temps réel, éliminant ainsi la nécessité pour les développeurs d'écrire leurs propres solutions. J'ai écrit sur ces fonctionnalités plus tôt et j'en décrirai également certaines ci-dessous.
J'essaierai de justifier un plus de l'existence d'une telle bibliothèque. La plupart des utilisateurs de Centrifugo sont des développeurs qui écrivent des backends dans des langages / frameworks avec un support de concurrence faible (par exemple Django / Flask / Laravel / ...): travaillent avec beaucoup de connexions persistantes si possible, de manière non évidente ou inefficace. En conséquence, tous les utilisateurs ne peuvent pas aider au développement d'un serveur écrit en Go (ringard en raison d'un manque de connaissance de la langue). Par conséquent, même une très petite communauté de développeurs Go autour de la bibliothèque pourra aider à développer le serveur Centrifugo en l'utilisant.
Le résultat est une bibliothèque Centrifuge . C'est toujours WIP, mais absolument toutes les fonctionnalités indiquées dans la description sur Github sont implémentées et fonctionnent. Étant donné que la bibliothèque fournit une API assez riche, avant de garantir la compatibilité descendante, je voudrais entendre plusieurs exemples réussis d'utilisation dans de vrais projets sur Go. Il n'y en a pas encore. En plus d'échec :). Il n'y en a pas.
Je comprends qu'en nommant la bibliothèque de la même manière que le serveur, je gérerai à jamais la confusion. Mais je pense que c'est le bon choix, car les clients (tels que centrifuge-js, centrifuge-go) fonctionnent à la fois avec la bibliothèque Centrifuge et le serveur Centrifugo. De plus, le nom est déjà bien ancré dans l'esprit des utilisateurs, et je ne veux pas perdre ces associations. Et pourtant, pour un peu plus de clarté, je vais encore clarifier:
- Centrifuge - une bibliothèque pour la langue Go,
- Centrifugo est une solution clé en main, un service distinct, qui dans la version 2 sera construit sur la bibliothèque Centrifuge.
En raison de sa conception, Centrifugo (un service autonome qui ne sait rien de votre backend) suppose que le flux de messages via le transport en temps réel ira du serveur au client. Que voulez-vous dire? Si, par exemple, l'utilisateur écrit un message dans le chat, ce message doit d'abord être envoyé au backend de l'application (par exemple, AJAX dans le navigateur), validé côté backend, enregistré dans la base de données si nécessaire, puis envoyé à l'API Centrifuge. La bibliothèque supprime cette restriction, vous permettant d'organiser l'échange bidirectionnel de messages asynchrones entre le serveur et le client, ainsi que les appels RPC.
Regardons un exemple simple: nous implémentons un petit serveur sur Go en utilisant la bibliothèque Centrifuge. Le serveur recevra les messages des clients du navigateur via Websocket, le client disposera d'un champ de texte dans lequel vous pourrez conduire un message, appuyez sur Entrée - et le message sera envoyé à tous les utilisateurs abonnés à la chaîne. Autrement dit, la version la plus simplifiée du chat. Il m'a semblé qu'il serait plus commode de placer cela sous la forme d'un résumé .
Vous pouvez exécuter comme d'habitude:
git clone https:
Et puis allez sur http: // localhost: 8000 , ouvrez plusieurs onglets de navigateur.
Comme vous pouvez le voir, le point d'entrée de la logique métier de l'application se produit lors du blocage des fonctions de rappel On().Connect() :
node.On().Connect(func(ctx context.Context, client *centrifuge.Client, e centrifuge.ConnectEvent) centrifuge.ConnectReply { client.On().Disconnect(func(e centrifuge.DisconnectEvent) centrifuge.DisconnectReply { log.Printf("client disconnected") return centrifuge.DisconnectReply{} }) log.Printf("client connected via %s", client.Transport().Name()) return centrifuge.ConnectReply{} })
L'approche basée sur le rappel m'a semblé la plus pratique pour interagir avec la bibliothèque. De plus, une approche similaire, mais faiblement typée, est utilisée dans la mise en œuvre du serveur socket-io sur Go . Si tout à coup vous avez des idées sur la façon dont l'API pourrait être réalisée de manière plus idiomatique - je serai heureux de l'entendre.
Il s'agit d'un exemple très simple qui ne montre pas toutes les fonctionnalités de la bibliothèque. Quelqu'un peut noter qu'à de telles fins, il est plus facile de prendre une bibliothèque pour travailler avec Websocket. Par exemple, Gorilla Websocket. Il en est ainsi. Cependant, même dans ce cas, vous devrez copier un morceau de code de serveur décent à partir de l'exemple dans le référentiel Gorilla Websocket. Et si:
- vous devez faire évoluer l'application sur plusieurs machines,
- ou vous n'avez pas besoin d'un canal commun, mais de plusieurs - et les utilisateurs peuvent s'abonner et se désabonner dynamiquement d'eux lorsque vous naviguez dans votre application,
- ou vous devez travailler lorsque la connexion Websocket n'a pas pu être établie (il n'y a pas de support dans le navigateur du client, il y a une extension de navigateur, une sorte de proxy sur le chemin entre le client et le serveur coupe la connexion),
- ou vous devez restaurer les messages manqués par le client pendant de courtes pauses dans la connexion Internet sans charger la base de données principale,
- ou vous avez besoin de contrôler l'autorisation utilisateur dans le canal,
- ou vous devez déconnecter la connexion permanente des utilisateurs qui sont désactivés dans l'application,
- ou vous avez besoin d'informations sur qui est actuellement sur la chaîne ou sur les événements auxquels une personne s'est abonnée / désabonnée de la chaîne,
- ou avez-vous besoin de mesures et de surveillance?
La bibliothèque Centrifuge peut vous y aider - en fait, elle a hérité de toutes les fonctionnalités de base qui étaient auparavant disponibles dans Centrifugo. Plus d'exemples montrant les points énoncés ci-dessus peuvent être trouvés sur Github .
Le fort héritage de Centrifugo peut être un inconvénient, car la bibliothèque a adopté toutes les mécaniques de serveur, qui sont assez originales et, peut-être, peuvent sembler peu évidentes ou surchargées de fonctionnalités inutiles pour quelqu'un. J'ai essayé d'organiser le code de telle manière que les fonctionnalités inutilisées n'affectent pas les performances globales.
Il existe des optimisations dans la bibliothèque qui permettent une utilisation plus efficace des ressources. Il s'agit de combiner plusieurs messages dans une trame Websocket pour économiser sur les appels système Write ou, par exemple, utiliser Gogoprotobuf pour sérialiser les messages Protobuf et autres. En parlant de Protobuf.
Protocole Protobuf binaire
Je voulais vraiment que Centrifugo travaille avec des données binaires ( et pas seulement moi ), donc dans la nouvelle version, je voulais ajouter un protocole binaire en plus de celui existant basé sur JSON. Maintenant, le protocole entier est décrit comme un schéma Protobuf . Cela nous a permis de le rendre plus structuré, de repenser certaines décisions non évidentes dans le protocole de la première version.
Je pense que vous n'avez pas besoin de dire longtemps quels sont les avantages de Protobuf par rapport à JSON - compacité, vitesse de sérialisation, schéma strict. Il y a un inconvénient sous la forme d'illisibilité, mais maintenant les utilisateurs ont la possibilité de décider ce qui est le plus important pour eux dans une situation particulière.
En général, le trafic généré par le protocole Centrifugo lors de l'utilisation de Protobuf au lieu de JSON devrait diminuer d'environ 2 fois (à l'exclusion des données d'application). La consommation de CPU dans mes tests de charge synthétique a diminué de la même manière ~ 2 fois par rapport à JSON. Ces chiffres parlent en fait peu de ce que, dans la pratique, tout dépendra du profil de charge d'une application particulière.
Pour des raisons d'intérêt, j'ai lancé sur une machine avec Debian 9.4 et 32 processeurs Intel® Xeon® Platinum 8168 @ 2.70GHz vCPU, ce qui nous a permis de comparer la bande passante de l'interaction client-serveur en cas d'utilisation du protocole JSON et du protocole Protobuf. Il y avait 1000 abonnés à 1 chaîne. Sur cette chaîne, les messages ont été publiés en 4 flux et remis à tous les abonnés. La taille de chaque message était de 128 octets.
Résultats pour JSON:
$ go run main.go -s ws:
Résultats pour le cas Protobuf:
$ go run main.go -s ws:
Vous pouvez remarquer que le débit d'une telle installation est plus de 2 fois supérieur dans le cas de Protobuf. Le script client peut être trouvé ici - c'est le script de référence Nats adapté aux réalités de Centrifuge .
Il convient également de noter que les performances de la sérialisation JSON sur le serveur peuvent être "améliorées" en utilisant la même approche que dans gogoprotobuf - pool de tampons et génération de code - actuellement JSON est sérialisé par un package de la bibliothèque standard Go construite sur Reflect. Par exemple, dans Centrifugo, la première version de JSON est sérialisée manuellement à l'aide d'une bibliothèque qui fournit un pool de mémoire tampon . Quelque chose de similaire peut être fait à l'avenir dans le cadre de la deuxième version.
Il convient de souligner que protobuf peut également être utilisé lors de la communication avec le serveur à partir d'un navigateur. Le client javascript utilise pour cela la bibliothèque protobuf.js. Étant donné que la bibliothèque protobufjs est assez lourde et que le nombre d'utilisateurs au format binaire sera petit, en utilisant webpack et son algorithme de tremblement d'arbre, nous générons deux versions du client - l'une avec prise en charge du protocole JSON uniquement, et l'autre avec prise en charge JSON et protobuf. Pour les autres environnements où la taille des ressources ne joue pas un rôle aussi critique, les clients ne peuvent pas s'inquiéter de cette séparation.
Jeton Web JSON (JWT)
L'un des problèmes liés à l'utilisation d'un serveur autonome tel que Centrifugo est qu'il ne sait rien de vos utilisateurs et de leur méthode d'authentification, ni du type de mécanisme de session utilisé par votre backend. Et vous devez en quelque sorte authentifier la connexion.
Pour ce faire, dans la première version Centrifuge, lors de la connexion, la signature SHA-256 HMAC a été utilisée, basée sur une clé secrète connue uniquement du backend et de la Centrifuge. Ainsi, l'ID utilisateur transmis par le client lui appartient réellement.
Peut-être que le transfert correct des paramètres de connexion et la génération d'un jeton ont été l'une des principales difficultés à intégrer Centrifugo dans le projet.
Lorsque la centrifugeuse est apparue, la norme JWT n'était pas encore si populaire. Maintenant, quelques années plus tard, des bibliothèques pour la génération JWT sont disponibles pour les langues les plus populaires . L'idée principale de JWT est exactement ce dont la centrifugeuse a besoin: la confirmation de l'authenticité des données transmises. Dans la deuxième version de HMAC, une signature générée manuellement a fait place à l'utilisation de JWT. Cela a permis de supprimer le besoin de prise en charge des fonctions d'assistance pour la génération correcte de jetons dans des bibliothèques pour différentes langues.
Par exemple, en Python, un jeton de connexion à Centrifugo peut être généré comme suit:
import jwt import time token = jwt.encode({"user": "42", "exp": int(time.time()) + 10*60}, "secret").decode() print(token)
Il est important de noter que si vous utilisez la bibliothèque Centrifuge, vous pouvez authentifier l'utilisateur en utilisant la méthode Go native - à l'intérieur du middleware. Des exemples sont dans le référentiel.
GRPC
Pendant le développement, j'ai essayé le streaming bidirectionnel GRPC comme moyen de transport pour la communication entre le client et le serveur (en plus des solutions de secours Websocket et HTTP SockJS). Que puis-je dire? Il a travaillé. Cependant, je n'ai pas trouvé un seul scénario où le streaming GRPC bidirectionnel serait mieux que Websocket. J'ai regardé principalement les métriques du serveur: trafic généré via l'interface réseau, consommation CPU par le serveur avec un grand nombre de connexions entrantes, consommation mémoire par connexion.
GRPC a perdu Websocket à tous égards:
- GRPC génère 20% de trafic supplémentaire dans des scénarios similaires,
- GRPC consomme 2 à 3 fois plus de CPU (selon la configuration des connexions - tous sont abonnés à des canaux différents ou tous sont abonnés à un canal),
- GRPC consomme 4 fois plus de RAM par connexion. Par exemple, sur des connexions 10 000, le serveur Websocket a consommé 500 Mo de mémoire et GRPC - 2 Go.
Les résultats étaient assez ... attendus. En général, dans GRPC, en tant que transport client, je ne voyais pas beaucoup de sens - et j'ai supprimé le code avec une conscience claire jusqu'à ce que, peut-être, des temps meilleurs.
Cependant, GRPC est bon pour ce pour quoi il a été principalement créé - pour générer du code qui vous permet de faire des appels RPC entre les services en utilisant un schéma prédéterminé. Par conséquent, en plus de l'API HTTP, la centrifugeuse aura désormais également la prise en charge de l'API basée sur GRPC, par exemple pour la publication de nouveaux messages sur le canal et d'autres méthodes d'API de serveur disponibles.
Difficultés avec les clients
Les modifications apportées dans la deuxième version, j'ai supprimé le support obligatoire des bibliothèques pour l'API serveur - il est devenu plus facile à intégrer côté serveur, cependant, le protocole client du projet a été modifié et dispose d'un nombre suffisant de fonctionnalités. Cela rend la mise en œuvre des clients assez difficile. Pour la deuxième version, nous avons maintenant un client pour Javascript qui fonctionne dans les navigateurs, devrait fonctionner avec NodeJS et React-Native. Il existe un client sur Go et construit sur sa base et sur la base des liants de projet gomobile pour iOS et Android .
Pour un bonheur complet, il n'y a pas assez de bibliothèques natives pour iOS et Android. Pour la première version de Centrifugo, ils ont été achetés par des gars de la communauté open-source. Je veux croire que quelque chose comme ça va arriver maintenant.
J'ai récemment tenté ma chance en envoyant une demande de subvention MOSS de Mozilla , dans l'intention d'investir dans le développement client, mais a été refusée. La raison en est la communauté insuffisamment active sur Github. Malheureusement, cela est vrai, mais comme vous pouvez le voir, je prends des mesures pour améliorer la situation.

Conclusion
Je n'ai pas annoncé toutes les fonctionnalités qui apparaîtront dans Centrifugo v2 - un peu plus d'informations sont dans le problème sur Github . La version du serveur n'a pas encore eu lieu, mais elle arrivera bientôt. Il reste des moments inachevés, notamment la nécessité de compléter la documentation. Le prototype de la documentation peut être consulté ici . Si vous êtes un utilisateur de Centrifugo, c'est le bon moment pour influencer la deuxième version du serveur. Un moment où ce n'est pas si effrayant de casser quelque chose, de mieux faire plus tard. Pour les intéressés: le développement est concentré dans la branche c2 .
Il est difficile pour moi de juger de la demande de la bibliothèque Centrifuge qui sous-tend Centrifugo v2. Pour le moment, je suis heureux d'avoir pu le ramener à son état actuel. L'indicateur le plus important pour moi maintenant est la réponse à la question "est-ce que j'utiliserais moi-même cette bibliothèque dans mon projet personnel?" Ma réponse est oui. Au travail? Oui Par conséquent, je crois que d'autres développeurs l'apprécieront.
PS Je voudrais remercier les gars qui ont aidé avec le travail et les conseils - Dmitry Korolkov, Artemy Ryabinkov, Oleg Kuzmin. Ce serait serré sans toi.