Bonjour collègues! Nous vous rappelons qu'il n'y a pas si longtemps, nous avons publié un
livre sur Spark et qu'en ce moment, un
livre sur Kafka est en cours de révision.
Nous espérons que ces livres auront suffisamment de succès pour poursuivre le sujet - par exemple, pour la traduction et la publication de littérature sur Spark Streaming. Nous voulions vous offrir une traduction sur l'intégration de cette technologie avec Kafka aujourd'hui.
1. JustificationApache Kafka + Spark Streaming est l'une des meilleures combinaisons pour créer des applications en temps réel. Dans cet article, nous discuterons en détail les détails d'une telle intégration. De plus, nous allons voir un exemple avec Spark Streaming-Kafka. Ensuite, nous discutons de «l'approche du destinataire» et de l'option d'intégration directe de Kafka et Spark Streaming. Commençons donc à intégrer Kafka et Spark Streaming.
 2. Intégration de Kafka et Spark Streaming
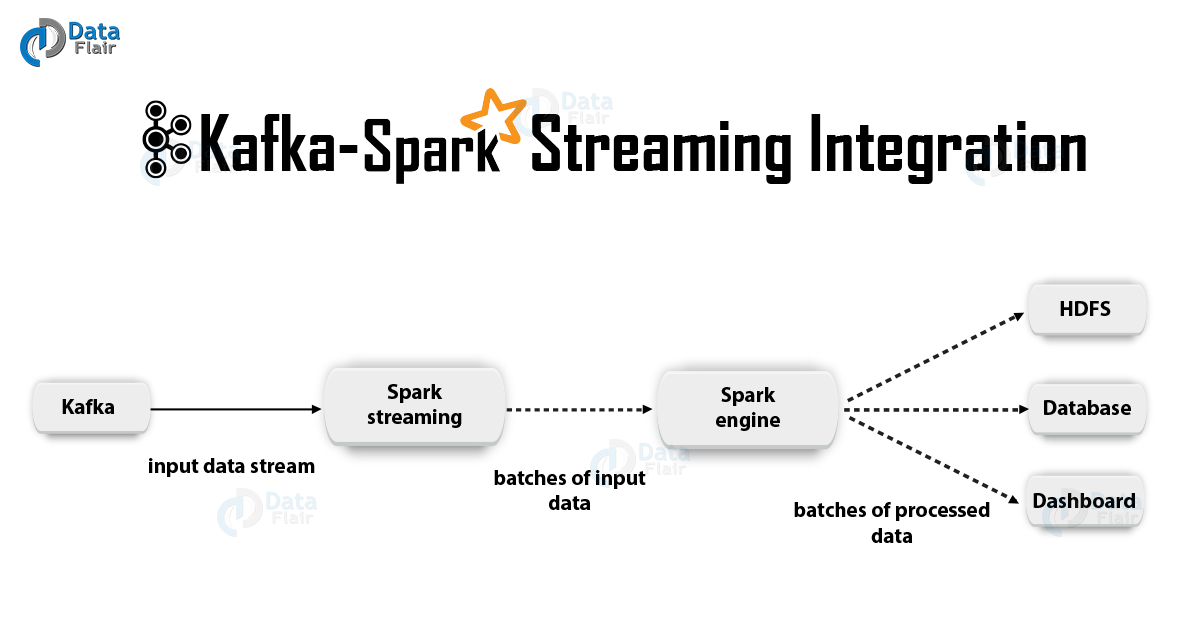
2. Intégration de Kafka et Spark StreamingLors de l'intégration d'Apache Kafka et de Spark Streaming, il existe deux approches possibles pour configurer Spark Streaming pour recevoir des données de Kafka - à savoir deux approches pour intégrer Kafka et Spark Streaming. Tout d'abord, vous pouvez utiliser les destinataires et l'API Kafka de haut niveau. La deuxième approche (plus récente) est le travail sans destinataires. Il existe différents modèles de programmation pour les deux approches, différents, par exemple, en termes de performances et de garanties sémantiques.
Examinons ces approches plus en détail.
a. Approche basée sur le bénéficiaireDans ce cas, la réception des données est assurée par le Destinataire. Ainsi, en utilisant l'API de consommation de haut niveau fournie par Kafka, nous implémentons le destinataire. De plus, les données reçues sont stockées dans Spark Artists. Ensuite, des travaux sont lancés dans Kafka - Spark Streaming, au sein duquel les données sont traitées.
Cependant, lors de l'utilisation de cette approche, le risque de perte de données en cas de panne (avec la configuration par défaut) demeure. Par conséquent, il sera nécessaire d'inclure en outre un journal d'écriture anticipée dans Kafka - Spark Streaming afin d'éliminer la perte de données. Ainsi, toutes les données reçues de Kafka sont stockées de manière synchrone dans le journal d'écriture anticipée dans un système de fichiers distribué. C'est pourquoi, même après une défaillance du système, toutes les données peuvent être restaurées.
Ensuite, nous verrons comment utiliser cette approche avec les destinataires dans une application avec Kafka - Spark Streaming.
i. ReliureNous allons maintenant connecter notre application de streaming avec l'artefact suivant pour les applications Scala / Java, nous allons utiliser les définitions de projet pour SBT / Maven.
groupId = org.apache.spark artifactId = spark-streaming-kafka-0-8_2.11 version = 2.2.0
Cependant, lors du déploiement de notre application, nous devrons ajouter la bibliothèque susmentionnée et ses dépendances, cela sera nécessaire pour les applications Python.
ii. ProgrammationEnsuite, créez un
DStream entrée
DStream en important
KafkaUtils dans le code d'application de flux:
import org.apache.spark.streaming.kafka._ val kafkaStream = KafkaUtils.createStream(streamingContext, [ZK quorum], [consumer group id], [per-topic number of Kafka partitions to consume])
De plus, à l'aide des options createStream, vous pouvez spécifier des classes de clés et des classes de valeurs, ainsi que les classes correspondantes pour leur décodage.
iii. DéploiementComme pour toute application Spark, la commande spark-submit est utilisée pour se lancer. Cependant, les détails sont légèrement différents dans les applications Scala / Java et dans les applications Python.
De plus, avec
–packages vous pouvez ajouter
spark-streaming-Kafka-0-8_2.11 et ses dépendances directement à
spark-submit , ceci est utile pour les applications Python où il est impossible de gérer des projets en utilisant SBT / Maven.
./bin/spark-submit --packages org.apache.spark:spark-streaming-kafka-0-8_2.11:2.2.0 ...
Vous pouvez également télécharger l'archive JAR de l'
spark-streaming-Kafka-0-8-assembly Maven
spark-streaming-Kafka-0-8-assembly depuis le référentiel Maven. Ajoutez-le ensuite à
spark-submit avec -
jars .
b. Approche directe (pas de destinataires)Après l'approche utilisant les destinataires, une nouvelle approche a été développée - celle «directe». Il fournit des garanties de bout en bout fiables. Dans ce cas, nous demandons périodiquement à Kafka des compensations de compensations pour chaque sujet / section, et nous ne prenons pas de dispositions pour la livraison des données via les destinataires. De plus, la taille du fragment lu est déterminée, cela est nécessaire pour le traitement correct de chaque paquet. Enfin, une simple API consommatrice est utilisée pour lire des plages avec des données de Kafka avec les décalages donnés, en particulier lorsque des travaux de traitement de données sont démarrés. L'ensemble du processus est comme lire des fichiers à partir d'un système de fichiers.
Remarque: Cette fonctionnalité est apparue dans Spark 1.3 pour Scala et l'API Java, ainsi que dans Spark 1.4 pour l'API Python.
Voyons maintenant comment appliquer cette approche dans notre application de streaming.
L'API Consumer est décrite plus en détail sur le lien suivant:
Consommateur Apache Kafka | Exemples de consommateurs Kafkai. Reliure
Certes, cette approche n'est prise en charge que dans les applications Scala / Java. Avec l'artefact suivant, générez le projet SBT / Maven.
groupId = org.apache.spark artifactId = spark-streaming-kafka-0-8_2.11 version = 2.2.0
ii. ProgrammationEnsuite, importez KafkaUtils et créez un
DStream entrée dans le code d'application de flux:
import org.apache.spark.streaming.kafka._ val directKafkaStream = KafkaUtils.createDirectStream[ [key class], [value class], [key decoder class], [value decoder class] ]( streamingContext, [map of Kafka parameters], [set of topics to consume])
Dans les paramètres de Kafka, vous devrez spécifier soit
metadata.broker.list ou
bootstrap.servers . Par conséquent, par défaut, nous consommerons des données à partir du dernier décalage dans chaque section de Kafka. Cependant, si vous souhaitez que la lecture commence à partir du plus petit fragment, dans les paramètres Kafka, vous devez définir l'option de configuration
auto.offset.reset .
De plus, en travaillant avec les options
KafkaUtils.createDirectStream , vous pouvez commencer la lecture à partir d'un décalage arbitraire. Ensuite, nous ferons ce qui suit, ce qui nous permettra d'accéder aux fragments de Kafka consommés dans chaque paquet.
Si nous voulons organiser la surveillance de Kafka basée sur Zookeeper à l'aide d'outils spéciaux, nous pouvons mettre à jour Zookeeper nous-mêmes avec leur aide.
iii. DéploiementLe processus de déploiement dans ce cas ressemble au processus de déploiement dans la variante avec le destinataire.
3. Les avantages d'une approche directeLa deuxième approche pour intégrer Spark Streaming à Kafka surpasse la première pour les raisons suivantes:
a. Accès simultané simplifiéDans ce cas, vous n'avez pas besoin de créer de nombreux flux d'entrée Kafka et de les combiner. Cependant, Kafka - Spark Streaming créera autant de segments RDD qu'il y aura de segments Kafka pour la consommation. Toutes ces données Kafka seront lues en parallèle. Par conséquent, nous pouvons dire que nous aurons une correspondance biunivoque entre les segments Kafka et RDD, et un tel modèle est plus compréhensible et plus facile à configurer.
b. EfficacitéAfin d'éliminer complètement la perte de données lors de la première approche, les informations devaient être stockées dans un journal des principaux enregistrements, puis répliquées. En fait, cela est inefficace car les données sont répliquées deux fois: la première fois par Kafka lui-même et la seconde par le journal d'écriture anticipée. Dans la deuxième approche, ce problème est éliminé, car il n'y a pas de destinataire et, par conséquent, aucun journal d'écriture de premier plan n'est nécessaire. Si nous avons un stockage de données suffisamment long dans Kafka, vous pouvez récupérer des messages directement à partir de Kafka.
s Sémantique exacteFondamentalement, nous avons utilisé l'API Kafka de haut niveau dans la première approche pour stocker les fragments de lecture consommés dans Zookeeper. Cependant, c'est la coutume de consommer les données de Kafka. Bien que la perte de données puisse être éliminée de manière fiable, il y a une petite chance que dans certains échecs, les enregistrements individuels puissent être consommés deux fois. Le point essentiel est l'incohérence entre le mécanisme de transfert de données fiable dans Kafka - Spark Streaming et la lecture de fragments qui se produit dans Zookeeper. Par conséquent, dans la deuxième approche, nous utilisons la simple API Kafka, qui ne nécessite pas de recourir à Zookeeper. Ici, les fragments lus sont suivis dans Kafka - Spark Streaming, pour cela, des points de contrôle sont utilisés. Dans ce cas, l'incohérence entre Spark Streaming et Zookeeper / Kafka est éliminée.
Par conséquent, même en cas de panne, Spark Streaming reçoit chaque enregistrement strictement une fois. Ici, nous devons nous assurer que notre opération de sortie, dans laquelle les données sont stockées dans un stockage externe, est soit idempotente soit une transaction atomique dans laquelle les résultats et les décalages sont stockés. C'est ainsi que la sémantique est réalisée une seule fois dans la dérivation de nos résultats.
Cependant, il y a un inconvénient: les décalages dans Zookeeper ne sont pas mis à jour. Par conséquent, les outils de surveillance de Kafka basés sur Zookeeper ne vous permettent pas de suivre les progrès.
Cependant, nous pouvons toujours faire référence aux compensations, si le traitement est organisé de cette manière - nous nous tournons vers chaque package et mettons à jour Zookeeper nous-mêmes.
C'est tout ce que nous voulions parler de l'intégration d'Apache Kafka et de Spark Streaming. Nous espérons que cela vous a plu.