En 2017, Jeffrey Hinton (l'un des fondateurs de l'approche de propagation de retour d'erreur) a publié un article décrivant les réseaux de neurones capsulaires et proposant un algorithme de routage dynamique entre les capsules pour enseigner l'architecture proposée.
Les réseaux de neurones convolutifs classiques présentent des inconvénients. La représentation interne des données du réseau neuronal convolutionnel ne prend pas en compte les hiérarchies spatiales entre les objets simples et complexes. Donc, si les yeux, le nez et les lèvres d'un réseau de neurones convolutifs sont affichés au hasard dans l'image, c'est un signe clair de la présence d'un visage. Et la rotation de l'objet affecte la qualité de la reconnaissance, tandis que le cerveau humain résout facilement ce problème.
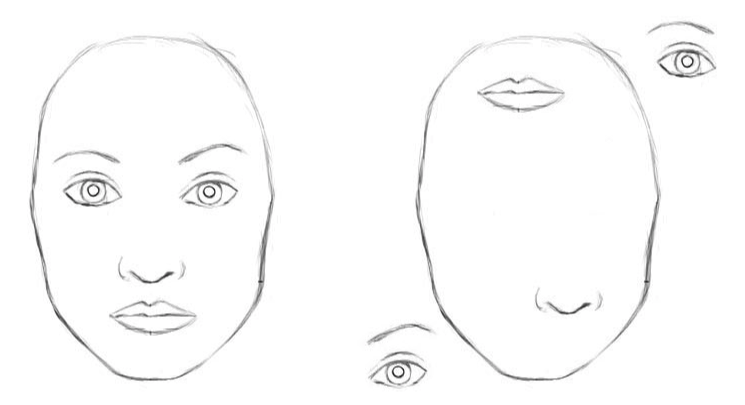
Pour un réseau neuronal convolutionnel, 2 images sont similaires [2]

Des milliers d'exemples seront nécessaires pour entraîner la reconnaissance d'objets sous différents angles CNN.

Les réseaux de capsules réduisent de 45% l'erreur de reconnaissance d'un objet sous un autre angle.
Capsules de prescription
Les capsules encapsulent des informations sur l'état de la fonction, qui se trouve sous forme vectorielle. Les capsules codent la probabilité de détecter un objet comme la longueur du vecteur de sortie. L'état de la fonction détectée est codé comme la direction dans laquelle le vecteur pointe («paramètres de création d'instance»). Par conséquent, lorsque la fonction détectée se déplace à travers l'image ou que l'état de l'image change, la probabilité reste inchangée (la longueur du vecteur ne change pas), mais l'orientation change.
Imaginez qu'une capsule détecte un visage dans une image et génère un vecteur 3D de longueur 0,99. Ensuite, déplacez le visage dans l'image. Le vecteur tournera dans son espace, représentant un état changeant, mais sa longueur restera fixe car la capsule est convaincue d'avoir détecté un visage.

Différences entre les capsules et les neurones. [2]
Un neurone artificiel peut être décrit en trois étapes:
1. pondération scalaire des scalaires d'entrée
2. somme des scalaires d'entrée pondérés
3. transformation scalaire non linéaire.
La capsule a les formes vectorielles des 3 étapes ci-dessus, en plus de la nouvelle phase de la transformation affine de l'entrée:
1. multiplication matricielle des vecteurs d'entrée
2. pondération scalaire des vecteurs d'entrée
3. somme des vecteurs d'entrée pondérés
4. non-linéarité vectorielle.
Une autre innovation introduite dans CapsNet est une nouvelle fonction d'activation non linéaire qui prend un vecteur et «donne» ensuite sa longueur pas plus de 1, mais ne change pas de direction.

Le côté droit de l'équation (rectangle bleu) met à l'échelle le vecteur d'entrée afin que le vecteur ait une longueur de bloc, et le côté gauche (rectangle rouge) effectue une mise à l'échelle supplémentaire.
La conception de la capsule est basée sur la construction d'un neurone artificiel, mais l'étend à une forme vectorielle pour fournir des capacités représentatives plus puissantes. Des pondérations matricielles sont également introduites pour coder les relations hiérarchiques entre les caractéristiques de différentes couches. L'équivariance de l'activité neuronale est atteinte par rapport aux changements des données d'entrée et à l'invariance des probabilités de détection des signes.
Routage dynamique entre capsules

L'algorithme de routage dynamique [1].
La première ligne dit que cette procédure prend des capsules au niveau inférieur l et leurs sorties u_hat, ainsi que le nombre d'itérations de routage r. La dernière ligne indique que l'algorithme produira la sortie d'une capsule de niveau supérieur v_j.
La deuxième ligne contient un nouveau coefficient b_ij, que nous n'avons pas vu auparavant. Ce coefficient est une valeur temporaire qui sera mise à jour de manière itérative, et une fois la procédure terminée, sa valeur sera stockée dans c_ij. Au début de la formation, la valeur de b_ij est initialisée à zéro.
La ligne 3 indique que les étapes 4 à 7 seront répétées r fois.
L'étape de la ligne 4 calcule la valeur du vecteur c_i, qui est tous les poids de routage pour la capsule inférieure i.
Une fois les poids c_ij calculés pour les capsules du niveau inférieur, passez à la ligne 5, où nous regardons les capsules d'un niveau supérieur. Cette étape calcule une combinaison linéaire de vecteurs d'entrée pondérés à l'aide des coefficients de routage c_ij définis à l'étape précédente.
Ensuite, à la ligne 6, les vecteurs de la dernière étape passent par une transformation non linéaire, ce qui garantit la direction du vecteur, mais sa longueur ne doit pas dépasser 1. Cette étape crée le vecteur de sortie v_j pour tous les niveaux supérieurs de la capsule [2].
L'idée de base est que la similitude entre l'entrée et la sortie est mesurée comme le produit scalaire entre l'entrée et la sortie de la capsule, puis le coefficient de routage change. La meilleure pratique consiste à utiliser trois itérations de routage.
Conclusion
Les réseaux de neurones capsulaires sont une architecture prometteuse de réseaux de neurones qui améliore la reconnaissance d'image avec des angles et une structure hiérarchique changeants. Les réseaux de neurones capsulaires sont formés en utilisant le routage dynamique entre les capsules. Les réseaux de capsules réduisent l'erreur de reconnaissance d'un objet sous un angle différent de 45% par rapport à CNN.
Les liens[1] MATRICE CAPSULES AVEC EM ROUTING. Geoffrey Hinton, Sara Sabour, Nicholas Frosst. 2017.
[2] Comprendre les réseaux de capsules de Hinton. Max pechyonkin