Il s'agit de la deuxième conférence avec J. Subbotnik sur les bases de données - la
première que nous avons publiée il y a quelques semaines.
Le chef du groupe SGBD à usage général Dmitry Sarafannikov a parlé de l'évolution de l'entrepôt de données dans Yandex: comment nous avons décidé de créer une interface compatible S3, pourquoi nous avons choisi PostgreSQL, sur quel type de râteau nous avons marché et comment y faire face.
- Bonjour à tous! Je m'appelle Dima, dans Yandex je fais des bases de données.
Je vais vous dire comment nous avons fait S3, comment nous en sommes venus à faire exactement S3 et quel type de stockage était auparavant. Le premier d'entre eux est Elliptics, il est publié en open source, disponible sur GitHub. Beaucoup l'ont peut-être rencontré.

Il s'agit essentiellement d'une table de hachage distribuée avec une clé de 512 bits, résultat de SHA-512. Il forme un porte-clés qui est divisé au hasard entre les machines. Si vous souhaitez y ajouter des machines, les clés sont redistribuées, un rééquilibrage se produit. Ce référentiel a ses propres problèmes liés notamment au rééquilibrage. Si vous avez un nombre suffisamment important de clés, alors avec des volumes en constante augmentation, vous devez constamment y vider des voitures, et sur un très grand nombre de clés, le rééquilibrage peut tout simplement ne pas converger. C'était un problème assez important.
Mais en même temps, ce stockage est idéal pour les données plus ou moins statiques, lorsque vous téléchargez une grande quantité de données uniques, puis que vous y lancez une charge en lecture seule. Pour de telles décisions, il s'intègre parfaitement.
Nous allons plus loin. Les problèmes de rééquilibrage étaient assez graves, donc le stockage suivant est apparu.

Quelle est son essence? Ce n'est pas du stockage de valeur-clé, c'est du stockage de valeur. Lorsque vous y téléchargez un objet ou un fichier, il vous répond avec une clé, par laquelle vous pouvez ensuite récupérer ce fichier. Qu'est-ce que ça donne? Théoriquement, un accès en écriture à cent pour cent, si vous avez de l'espace libre dans le stockage. Si vous avez une machine à écrire, vous écrivez simplement à d'autres qui ne sont pas couchés sur lesquels il y a de l'espace libre, vous obtenez d'autres clés et récupérez calmement vos données.
Ce stockage est très simple à mettre à l'échelle, vous pouvez le jeter avec du fer, cela fonctionnera. C'est très simple, fiable. Son seul inconvénient: le client ne gère pas la clé, et tous les clients doivent stocker les clés quelque part, stocker le mappage de leurs clés. C'est gênant pour tout le monde. En fait, c'est une tâche très similaire pour tous les clients, et chacun la résout à sa manière dans ses méta-bases, etc. Cela n'est pas pratique. Mais en même temps, je ne veux pas perdre la fiabilité et la simplicité de ce stockage, en fait il fonctionne avec la vitesse du réseau.
Ensuite, nous avons commencé à regarder S3. Il s'agit d'un stockage clé-valeur, le client gère la clé, l'ensemble du stockage est divisé en soi-disant compartiments. Dans chaque compartiment, l'espace clé va de moins l'infini à plus l'infini. La clé est une sorte de chaîne de texte. Et nous nous y sommes installés, sur cette option. Pourquoi S3?
Tout est assez simple. À ce moment, de nombreux clients prêts à l'emploi pour divers langages de programmation ont déjà été écrits, de nombreux outils prêts à l'emploi pour stocker quelque chose dans S3, par exemple, des sauvegardes de base de données, ont déjà été écrits. Andrew a
parlé de l'un des exemples. Il existe déjà une API raisonnablement bien pensée qui circule sur les clients depuis des années, et vous n'avez rien à inventer là-bas. L'API a de nombreuses fonctionnalités pratiques telles que les listes, les téléchargements en plusieurs parties, etc. Nous avons donc décidé de rester dessus.
Comment faire S3 à partir de notre stockage? Qu'est-ce qui vous vient à l'esprit? Puisque les clients eux-mêmes stockent le mappage des clés, nous prenons simplement, mettons la base de données à côté d'eux, et nous y stockons le mappage de ces clés. Lors de la lecture, nous trouverons simplement les clés et le stockage dans notre base de données, et donnerons au client ce qu'il veut. Si vous l'esquissez schématiquement, comment se produit le remplissage?

Il y a une certaine entité, ici on l'appelle Proxy, le soi-disant backend. Il accepte le fichier, le télécharge dans le stockage, obtient la clé à partir de là et l'enregistre dans la base de données. Tout est assez simple.
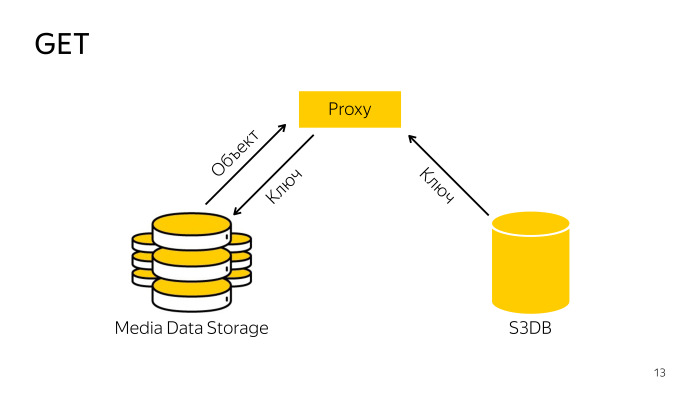
Comment est le reçu? Le proxy trouve la clé nécessaire dans la base de données, va avec la clé de stockage, télécharge l'objet à partir de là, la donne au client. Tout est simple aussi.
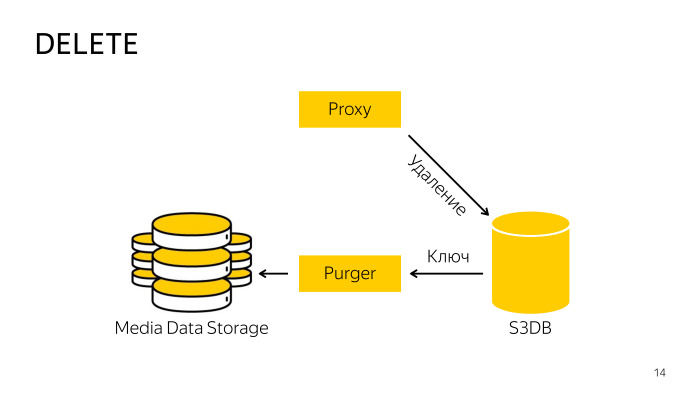
Comment est la suppression? Lors de la suppression directement du stockage, le proxy ne fonctionne pas, car il est difficile de coordonner la base de données et le stockage, il va donc simplement dans la base de données, lui dit que cet objet est supprimé, là, l'objet est déplacé vers la file d'attente de suppression, puis en arrière-plan un professionnel spécialement formé le robot prend ces clés, les supprime du stockage et de la base de données. Tout ici est également assez simple.
Nous avons choisi PostgreSQL comme base de données pour cette métabase.
Vous savez déjà que nous l'aimons beaucoup. Avec le transfert de Yandex.Mail, nous avons acquis une expertise suffisante dans PostgreSQL, et lorsque différents services de messagerie ont déménagé, nous avons développé plusieurs modèles dits de partage. L'un d'eux s'est bien comporté sur la S3 avec de légères modifications, mais cela s'est bien passé.
Quelles sont les options de partage? Il s'agit d'un grand référentiel. À l'échelle de Yandex, vous devez immédiatement penser qu'il y aura de nombreux objets, vous devez immédiatement réfléchir à la façon de tout partager. Vous pouvez scinder par hachage au nom de l'objet, c'est le moyen le plus fiable, mais cela ne fonctionnera pas ici, car S3 a, par exemple, des listes qui devraient afficher la liste des clés dans l'ordre trié, lorsque vous mettez en cache, tous les triages disparaîtront, vous devez supprimer tous les objets afin que la sortie soit conforme à la spécification API.
L'option suivante, vous pouvez partitionner par hachage au nom ou par identifiant du compartiment. Un compartiment peut vivre dans un fragment de base de données.
Une autre option consiste à répartir les plages clés. À l'intérieur du seau, il y a de l'espace de moins l'infini à plus l'infini, nous pouvons le diviser en n'importe quel nombre de plages, nous appelons cette plage un morceau, il ne peut vivre que dans un seul éclat.

Nous avons choisi la troisième option, le découpage par morceaux, car purement théoriquement, il peut y avoir un nombre infini d'objets dans un seau, et il ne rentrera pas bêtement dans une seule pièce de fer. Il y aura de gros problèmes, nous allons donc couper et organiser les fragments comme nous le souhaitons. C’est tout.

Que s'est-il passé? La base de données entière se compose de trois composants. S3 Proxy - un groupe d'hôtes, il existe également une base de données. PL / Proxy sont sous l'équilibreur, les demandes de ce backend volent là-bas. En outre S3Meta, un tel groupe de basses, qui stocke des informations sur les seaux et les morceaux. Et S3DB, des fragments où les objets sont stockés, une file d'attente de suppression. S'il est représenté schématiquement, il ressemble à ceci.
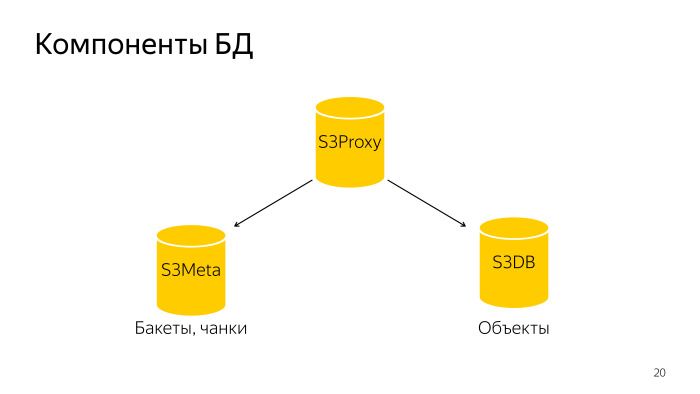
Une demande arrive à S3Proxy, elle va à S3Meta et S3DB et émet des informations vers le haut.

Examinons plus en détail. S3Proxy, les fonctions qu'il contient sont créées dans le langage procédural PLProxy, c'est un tel langage qui vous permet d'exécuter des procédures ou requêtes stockées à distance. Voici à quoi ressemble le code de la fonction ObjectInfo, essentiellement une demande Get.
Le cluster LProxy a l'opérateur Cluster, dans ce cas, db_ro. Qu'est-ce que cela signifie?

S'il s'agit d'une configuration de fragment de base de données typique, il existe un maître et deux répliques. Le maître entre dans le cluster db_rw, les trois hôtes entrent dans db-ro, c'est là que vous pouvez envoyer une demande en lecture seule et une demande d'écriture est envoyée à db_rw. Le cluster db_rw comprend tous les maîtres de tous les fragments.
La prochaine instruction RUN ON, elle prend soit la valeur all, ce qui signifie de s'exécuter sur tous les fragments soit un tableau ou une sorte de fragment. Dans ce cas, il reçoit le résultat de la fonction get_object_shard en entrée; c'est le numéro du fragment sur lequel se trouve l'objet donné.
Et cible - qui fonctionne pour appeler le fragment distant. Il appellera cette fonction et remplacera les arguments qui ont volé dans cette fonction.

La fonction get_object_shard est également écrite en PLProxy, déjà un cluster meta_ro, la requête volera vers le fragment S3Meta, qui renverra cette fonction get_bucket_meta_shard.
S3Meta peut également être fragmenté, nous l'avons également posé, bien que cela ne soit pas pertinent, mais il existe une opportunité. Et il appellera la fonction get_object_shard sur S3Meta.

get_bucket_meta_shard n'est qu'un hachage de texte au nom d'un bucket, nous avons mélangé S3Meta juste par un hachage au nom d'un bucket.

Considérez S3Meta ce qui s'y passe. L'information la plus importante qui soit est une table avec des morceaux. J'ai coupé un peu certaines informations inutiles, la chose la plus importante qui reste est bucket_id, la clé de début, la clé de fin et le fragment dans lequel se trouve ce morceau.

À quoi ressemblerait une requête sur une telle table, qui nous renverrait le morceau dans lequel, par exemple, se trouve l'objet de test? Comme ça. Moins l'infini sous forme de texte, nous l'avons présenté comme une valeur nulle, il y a de tels points subtils que vous devez vérifier start_key et end_key pour Null.

La demande ne semble pas très bonne et le plan est encore pire. Comme une des options pour un plan pour une telle demande, BitmapOr. Et 6 000 os valent un tel plan.

Comment peut-il en être autrement? Il y a une chose merveilleuse dans PostgreSQL comme l'index gist, qui peut indexer le type de plage, la plage est essentiellement ce dont nous avons besoin. Nous avons fait ce type, la fonction s3.to_keyrange nous renvoie, en fait, la plage. Nous pouvons vérifier avec l'opérateur contains, trouver le morceau dans lequel se trouve notre clé. Et pour cela, la contrainte d'exclusion est construite ici, ce qui garantit la non-intersection de ces morceaux. Nous devons autoriser, de préférence au niveau de la base de données, une certaine contrainte pour nous assurer que les morceaux ne peuvent pas se croiser, de sorte qu'une seule ligne soit renvoyée en réponse à la demande. Sinon, ce ne sera pas ce que nous voulions. Voici à quoi ressemble le plan d'une telle demande, l'index_scan habituel. Cette condition s'inscrit complètement dans la condition d'indexation, et un tel plan ne compte que 700 os, 10 fois moins.

Qu'est-ce que la contrainte d'exclusion?

Créons une table de test avec deux colonnes, et y ajoutons deux contraintes, une unique que tout le monde connaît, et une exclure la contrainte, qui a des paramètres égaux, de tels opérateurs. Mettons-le avec deux opérateurs égaux, une telle plaque a été construite.

Ensuite, nous essayons d'insérer deux lignes identiques, nous obtenons l'erreur de violation de l'unicité de la clé sur la première contrainte. Si nous l'abandonnons, nous avons déjà violé la contrainte d'exclusion. Il s'agit d'un cas courant de contrainte unique.

En fait, une contrainte unique est la même contrainte d'exclusion avec les opérateurs égaux, mais dans le cas d'une contrainte d'exclusion, vous pouvez créer des cas plus généraux.

Nous avons de tels indices. Si vous regardez de près, vous verrez que ce sont les deux index et, en général, ils sont les mêmes. Vous vous demandez probablement pourquoi dupliquer cette entreprise. Je vais te le dire.

Les index sont une telle chose, en particulier l'index gist, que la table vit sa propre vie, les mises à jour se produisent, sont divisées, et ainsi de suite, l'index va mal là-bas, il cesse d'être optimal. Et il existe une telle pratique, en particulier l'extension pg repack, les index sont reconstruits périodiquement, de temps en temps ils sont reconstruits.
Comment reconstruire un index sous une contrainte unique? Créer créer un index actuellement, créer le même index calmement à côté sans le verrouiller, puis l'expression alter table de la contrainte user_index est telle ou telle. Et tout, tout est clair et bon ici, ça marche.
Dans le cas de la contrainte d'exclusion, vous ne pouvez la reconstruire que par le verrouillage de réindexation, plus précisément, votre index sera exclusivement bloqué, et en fait il vous restera toutes les requêtes. C'est inacceptable, l'index gist peut être construit assez longtemps. Par conséquent, nous gardons à côté du deuxième index, qui est plus petit en volume, prend moins de place, le planeur l'utilise et nous pouvons reconstruire cet index de manière compétitive sans le bloquer.
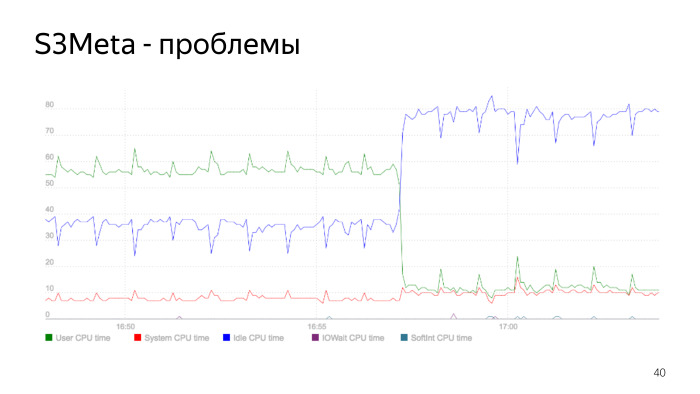
Voici un graphique de la consommation du processeur. La ligne verte représente la consommation du processeur dans user_space, elle passe de 50% à 60%. À ce stade, la consommation baisse fortement, c'est le moment où l'indice est reconstruit. Nous avons reconstruit l'index, supprimé l'ancien, la consommation de notre processeur a fortement chuté. Il s'agit d'un problème d'index essentiel, et c'est un bon exemple de la façon dont cela peut être.
Lorsque nous avons fait tout cela, nous avons commencé sur la version 9.5 S3DB, selon le plan, nous avions prévu d'empiler 10 milliards d'objets dans chaque fragment. Comme vous le savez, plus d'un milliard et même des problèmes antérieurs commencent lorsqu'une table a plusieurs lignes, tout devient bien pire. Il y a une pratique de séparation. À cette époque, il y avait deux options, soit standard par héritage, mais cela ne fonctionne pas très bien, car il existe une vitesse de sélection de partition linéaire. Et à en juger par le nombre d'objets, nous avons besoin de beaucoup de partitions. Les gars de Postgres Pro ont ensuite scié activement l'extension pg_pathman.

Nous avons choisi pg_pathman, nous n'avions pas d'autre choix. Même version 1.4. Et comme vous pouvez le voir, nous utilisons 256 partitions. Nous avons divisé la table entière des objets en 256 partitions.
Que fait pg_pathman? À l'aide de cette expression, vous pouvez créer 256 partitions partitionnées par hachage à partir de la colonne d'enchères.

Comment fonctionne pg_pathman?
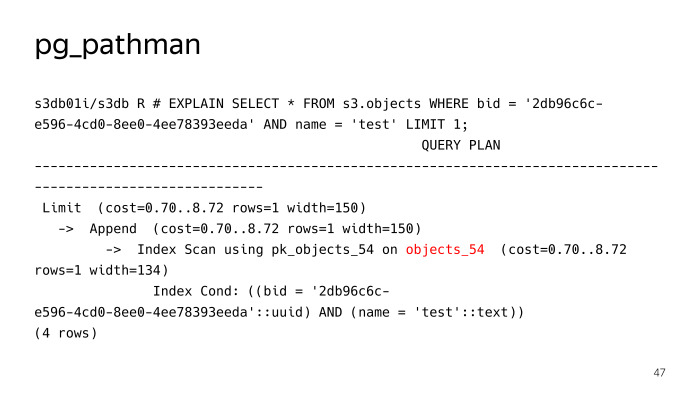
Il enregistre ses crochets dans le planeur, et plus loin sur les demandes il remplace, en substance, le plan. Nous voyons qu'il n'a pas recherché 256 partitions pour une requête de recherche régulière d'un objet avec le test de nom, mais a immédiatement déterminé qu'il était nécessaire de monter dans la table objects_54, mais tout ne se passait pas bien ici, pg_pathman a ses propres problèmes. Tout d'abord, il y avait pas mal de bugs au début, pendant qu'il sciait, mais grâce aux gars de Postgres Pro, ils les ont rapidement corrigés et corrigés.
Le premier problème est la difficulté de le mettre à jour. Le deuxième problème concerne les déclarations préparées.
Examinons plus en détail. En particulier, la mise à jour. En quoi consiste pg_pathman?

Il se compose essentiellement de code C, qui est empaqueté dans une bibliothèque. Et il se compose d'une partie SQL, de toutes sortes de fonctions pour créer des partitions, etc. De plus, les interfaces avec les fonctions qui sont dans la bibliothèque. Ces deux parties ne peuvent pas être mises à jour en même temps.
De là surgissent des difficultés, quelque chose comme cet algorithme pour mettre à jour la version de pg_pathman, nous roulons d'abord un nouveau paquet avec une nouvelle version, mais PostgreSQL a des anciennes versions chargées en mémoire, il l'utilise. C'est immédiatement dans tous les cas, la base doit être redémarrée.
Ensuite, nous appelons la fonction set_enable_parent, elle active la fonction dans la table parent, qui est désactivée par défaut. Ensuite, désactivez pathman, redémarrez la base de données, dites ALTER EXTENSION UPDATE, à ce moment-là, tout tombe dans la table parent.
Ensuite, activez pathman et exécutez la fonction, qui se trouve dans l'extension, qui transfère les objets de la table parent qui les ont attaqués pendant cette courte période de temps, les transfère vers les tables où ils doivent se trouver. Et puis désactivez l'utilisation de la table parent, recherchez-la.

Le problème suivant est celui des déclarations préparées.

Si nous bloquons la même demande ordinaire, recherchez par enchère et clé, essayez de l'exécuter. Jouez cinq fois - tout va bien. Nous réalisons le sixième - nous voyons un tel plan. Et à cet égard, nous voyons les 256 partitions. Si vous regardez attentivement ces conditions, nous voyons le dollar 1, le dollar 2, c'est le plan dit générique, le plan général. Les cinq premières requêtes ont été construites individuellement, des plans individuels ont été utilisés pour ces paramètres, pg_pathman pourrait déterminer immédiatement, car le paramètre est connu à l'avance, il pourrait immédiatement déterminer la table où aller. Dans ce cas, il ne peut pas faire cela. Par conséquent, le plan doit avoir les 256 partitions, et lorsque l'exécuteur teste cela, il va et prend un verrou partagé pour les 256 partitions et les performances d'une telle solution ne sont pas tout de suite. Il perd tout simplement tous ses avantages, et toute demande se déroule de façon insensée.

Comment en sommes-nous sortis? J'ai dû tout envelopper dans les procédures stockées en exécution, en SQL dynamique, afin que les instructions préparées ne soient pas utilisées et que le plan soit construit à chaque fois. C’est comme ça que ça fonctionne.
L'inconvénient est que vous devez entasser tout le code dans des structures qui touchent ces tables. C'est plus difficile à lire ici.

Comment est la distribution des objets? Dans chaque fragment S3DB, les compteurs de morceaux sont stockés, il y a également des informations sur les morceaux qui se trouvent dans ce fragment et les compteurs sont stockés pour eux. Pour chaque opération de mutation sur un objet - ajout, suppression, modification, réécriture - ces compteurs pour le changement de bloc. Afin de ne pas mettre à jour la même ligne lorsque le versement actif se trouve dans ce bloc, nous utilisons une technique assez standard lorsque nous insérons un compteur delta dans une table séparée, et une fois par minute, un robot spécial passe en revue et agrège tout cela, met à jour les compteurs au niveau du bloc .

De plus, ces compteurs sont livrés à S3Meta avec un certain retard, il y a déjà une image complète du nombre de compteurs dans quel segment, alors vous pouvez regarder la distribution par fragments, combien d'objets se trouvent dans quel fragment, et sur cette base, une décision est prise à l'endroit où se trouve le nouveau fragment. Lorsque vous créez un compartiment, par défaut, un seul morceau est créé de moins l'infini à plus l'infini, selon la distribution actuelle des objets que S3Meta connaît, il tombe dans une sorte de fragment.
Lorsque vous versez des données dans ce compartiment, toutes ces données sont versées dans ce bloc, lorsqu'une certaine taille est atteinte, un robot spécial vient et partage ce bloc.

Nous faisons de petits morceaux. Nous faisons cela de sorte que dans ce cas, ce petit morceau puisse être glissé dans un autre fragment. Comment se produit une séparation de morceaux? Voici un robot régulier, il va et divise ce morceau dans S3DB avec une validation en deux phases et met à jour les informations dans S3Meta.
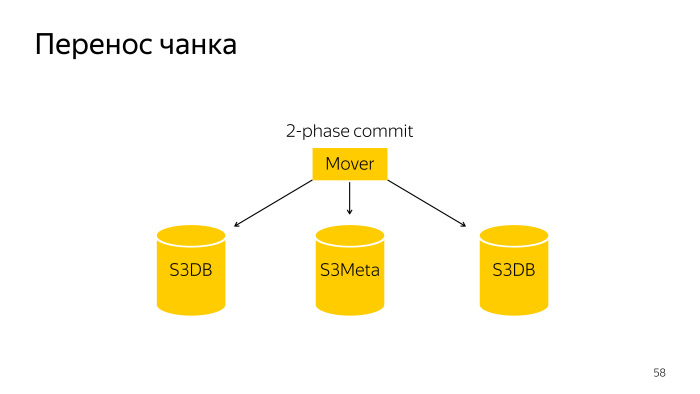
Le transfert de morceaux est une opération légèrement plus compliquée; il s'agit d'un commit en deux phases sur trois bases, S3Meta et deux fragments, S3DB, glisse de l'une à l'autre.

S3 a une fonctionnalité telle que les listes, c'est la chose la plus difficile, et elle a également posé des problèmes. En fait, les listes, vous dites S3 - montrez-moi les objets que j'ai. Le paramètre surligné en rouge est désormais Null. Ce paramètre, délimiteur, séparateur, vous permet de spécifier les listes avec quel séparateur vous souhaitez.
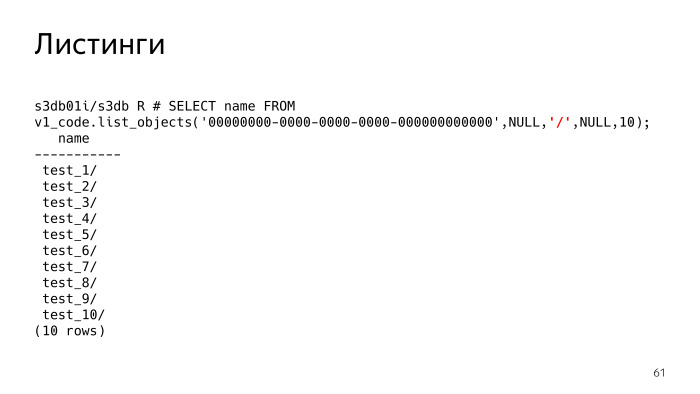
Qu'est-ce que cela signifie? Si le délimiteur n'est pas défini, on voit que l'on nous donne simplement une liste de fichiers. Si nous définissons le délimètre, S3 devrait essentiellement nous montrer les dossiers. Je dois comprendre qu'il existe de tels dossiers, et en fait, il affiche tous les dossiers et fichiers du dossier actuel. Le dossier actuel est préfixé, ce paramètre est Null. On voit qu'il y a 10 dossiers.
Toutes les clés ne sont pas stockées dans une sorte d'arborescence hiérarchique, comme dans le système de fichiers. Chaque objet est stocké sous forme de chaîne et ils ont un simple préfixe commun. S3 doit lui-même comprendre qu'il s'agit d'un cul.

Une telle logique n'est pas suffisante pour le SQL déclaratif; il est assez facile de le décrire avec du code impératif. , PL/pgSQL. , repeatable read. , . , - - , .
Recursive CTE, , - , execute PL/pgSQL. , . , , , list objects. , .
, .
. , .
Docker,
Behave Behave
. , , , .
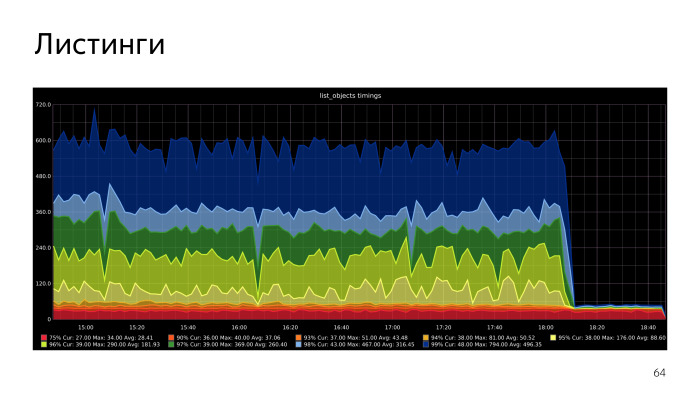
. , , CPU S3Meta. Gist index CPU, , . CPU S3Meta . , . PLProxy , S3Meta S3DB. , . S3Meta . , .
Dans la réplication logique, il y a un certain nombre de problèmes que nous allons résoudre, nous allons essayer de le pousser en amont. La deuxième option - vous pouvez refuser l'histogramme, essayez de mettre cette plage de texte dans btree. Ce n'est pas un type unidimensionnel, et btree ne fonctionne qu'avec des types unidimensionnels. Mais la condition que les morceaux ne se chevauchent pas avec nous nous permettra de mettre notre cas en btree. Pas plus tard qu'hier, nous avons créé un prototype qui fonctionne. Il est implémenté sur les fonctions PL / pgSQL. Nous avons obtenu une accélération notable, nous allons optimiser dans cette direction.