Lorsque Dropbox vient de démarrer, un utilisateur de Hacker News a déclaré qu'il pouvait être implémenté avec plusieurs scripts bash en utilisant FTP et Git. Maintenant, cela ne peut en aucun cas être dit, il s'agit d'un grand stockage de fichiers dans le cloud avec des milliards de nouveaux fichiers chaque jour, qui ne sont pas simplement stockés d'une manière ou d'une autre dans la base de données, mais de telle manière que n'importe quelle base de données puisse être restaurée à tout moment au cours des six derniers jours.
Sous la coupe, la transcription du rapport de
Glory Bakhmutov (
m0sth8 ) à Highload ++ 2017, sur le développement des bases de données dans Dropbox et leur organisation actuelle.
À propos du conférencier: Gloire à Bakhmutov - ingénieur en fiabilité de site dans l'équipe Dropbox, aime beaucoup Go et apparaît parfois dans le podcast golangshow.com.
Table des matières
Architecture Dropbox en langage clair
Dropbox est apparu en 2008. Il s'agit essentiellement d'un stockage de fichiers cloud. Lorsque Dropbox vient de démarrer, un utilisateur de Hacker News a déclaré qu'il pouvait être implémenté avec plusieurs scripts bash en utilisant FTP et Git. Mais, néanmoins, Dropbox se développe et c'est maintenant un service assez important avec plus de 1,5 milliard d'utilisateurs, 200 000 entreprises et un grand nombre (plusieurs milliards!) De nouveaux fichiers chaque jour.
À quoi ressemble Dropbox?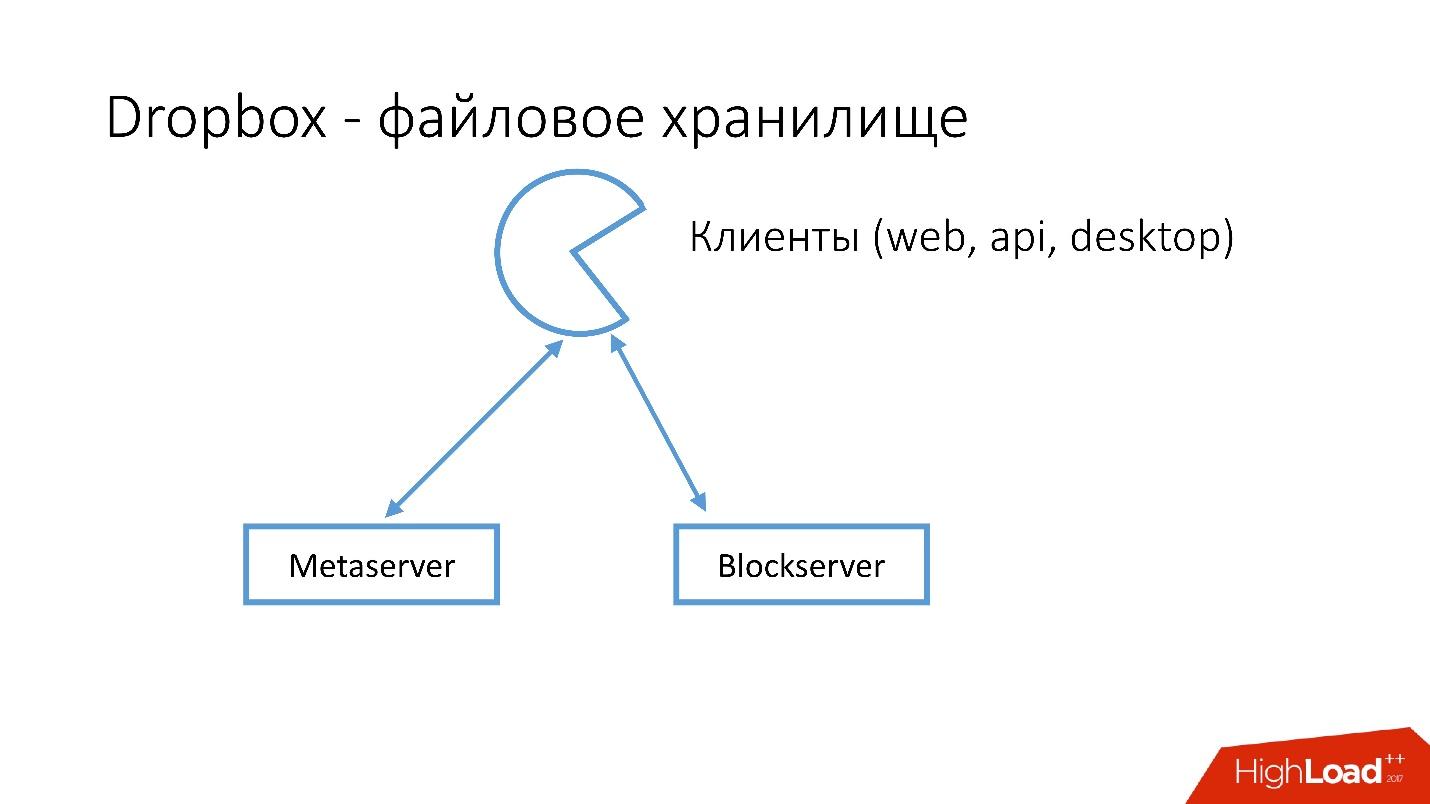
Nous avons plusieurs clients (interface web, API pour les applications qui utilisent Dropbox, applications de bureau). Tous ces clients utilisent l'API et communiquent avec deux grands services qui peuvent logiquement être divisés en:
- Metaserver
- Blockserver
Metaserver stocke des méta-informations sur le fichier: taille, commentaires sur celui-ci, liens vers ce fichier dans Dropbox, etc. Blockserver ne stocke que des informations sur les fichiers: dossiers, chemins, etc.
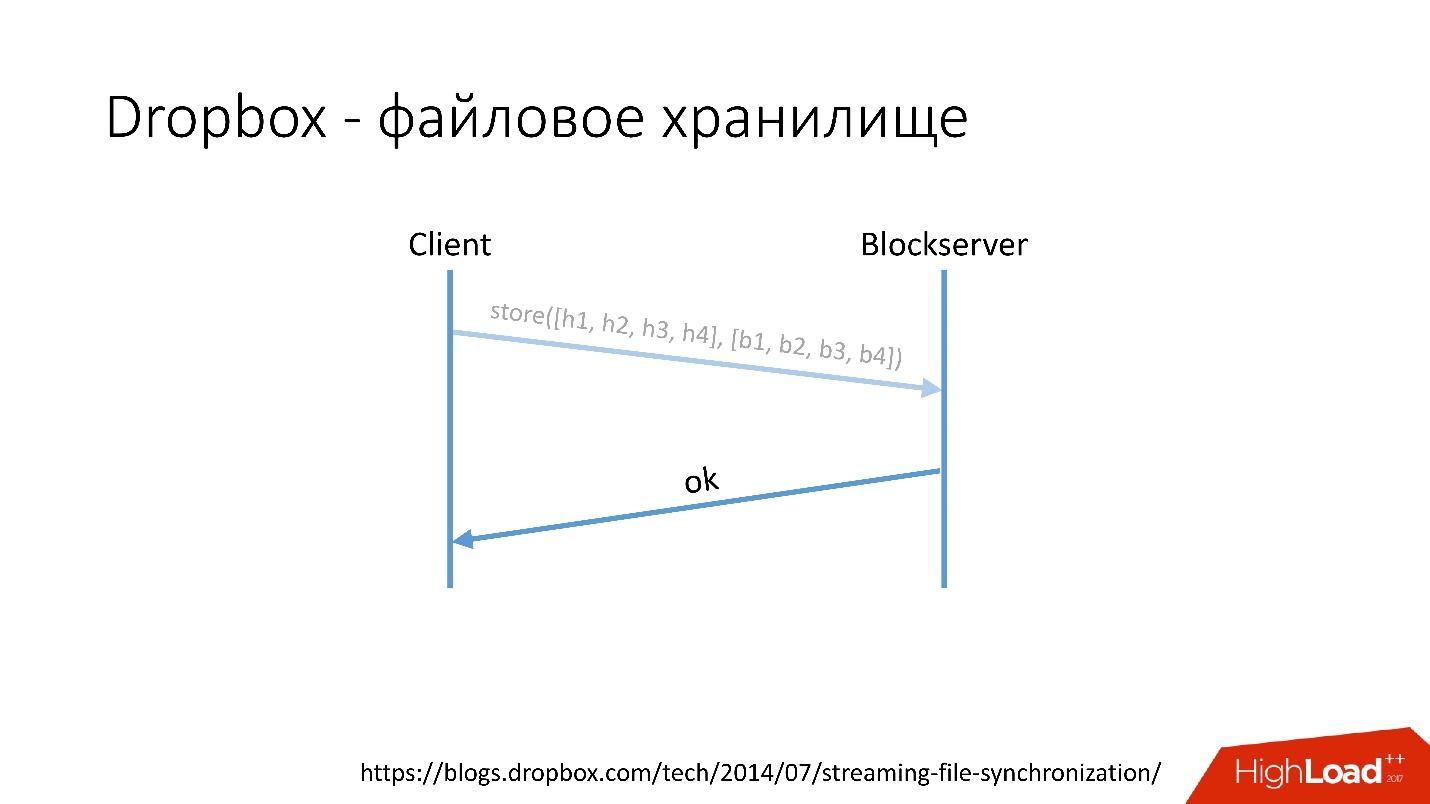
Comment ça marche?Par exemple, vous avez un fichier video.avi avec une sorte de vidéo.
 Lien depuis la diapositive
Lien depuis la diapositive- Le client divise ce fichier en plusieurs morceaux (dans ce cas, 4 Mo chacun), calcule la somme de contrôle et envoie une demande au Metaserver: "J'ai un fichier * .avi, je veux le télécharger, les quantités de hachage sont telles et telles."
- Metaserver renvoie la réponse: "Je n'ai pas ces blocs, téléchargeons!" Ou il peut répondre qu'il a tout ou partie des blocs, et que seuls les autres doivent être chargés.
 Lien depuis la diapositive
Lien depuis la diapositive- Après cela, le client va à Blockserver, envoie le montant du hachage et le bloc de données lui-même, qui est stocké sur le Blockserver.
- Blockserver confirme l'opération.
 Lien depuis la diapositive
Lien depuis la diapositiveBien sûr, c'est un schéma très simplifié, le protocole est beaucoup plus compliqué: il y a une synchronisation entre les clients au sein du même réseau, il y a des pilotes de noyau, la possibilité de résoudre les collisions, etc. C'est un protocole assez complexe, mais il fonctionne de manière schématique.

Lorsqu'un client enregistre quelque chose sur Metaserver, toutes les informations vont à MySQL. Blockserver stocke également des informations sur les fichiers, leur structure, leurs blocs, dans MySQL. Blockserver stocke également les blocs eux-mêmes dans Block Storage, qui, à son tour, stocke des informations sur l'endroit où se trouve le bloc, sur quel serveur et comment il est traité, également dans MYSQL.
Pour stocker des exaoctets de fichiers utilisateur, nous stockons simultanément des informations supplémentaires dans une base de données de plusieurs dizaines de pétaoctets répartis sur 6 000 serveurs.
Historique de développement de la base de données
Comment les bases de données ont-elles évolué dans Dropbox?

En 2008, tout a commencé avec un Metaserver et une base de données globale. Toutes les informations dont Dropbox avait besoin d'être stockées quelque part, il les a enregistrées dans le seul MySQL global. Cela n'a pas duré longtemps, car le nombre d'utilisateurs a augmenté et les bases de données et tablettes individuelles à l'intérieur des bases de données ont gonflé plus rapidement que les autres.

Par conséquent, en 2011, plusieurs tableaux ont été soumis à des serveurs distincts:
- Utilisateur , avec des informations sur les utilisateurs, par exemple, les connexions et les jetons oAuth;
- Hôte , avec des informations sur les fichiers de Blockserver;
- Divers , qui n'était pas impliqué dans le traitement des demandes de production, mais était utilisé pour des fonctions utilitaires, comme les travaux par lots.
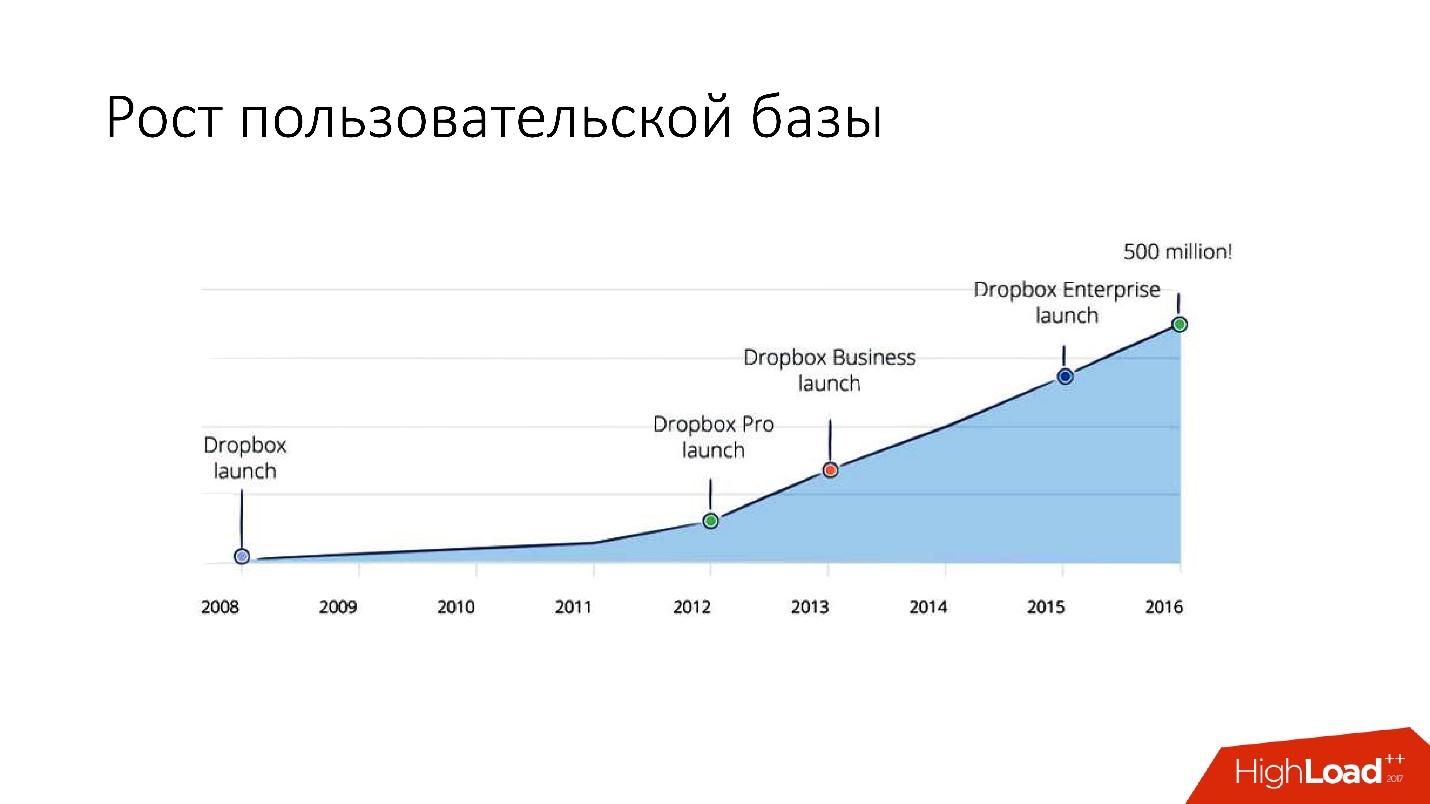
Mais après 2012, Dropbox a commencé à se développer considérablement, depuis lors,
nous avons augmenté d'
environ 100 millions d'utilisateurs par an .
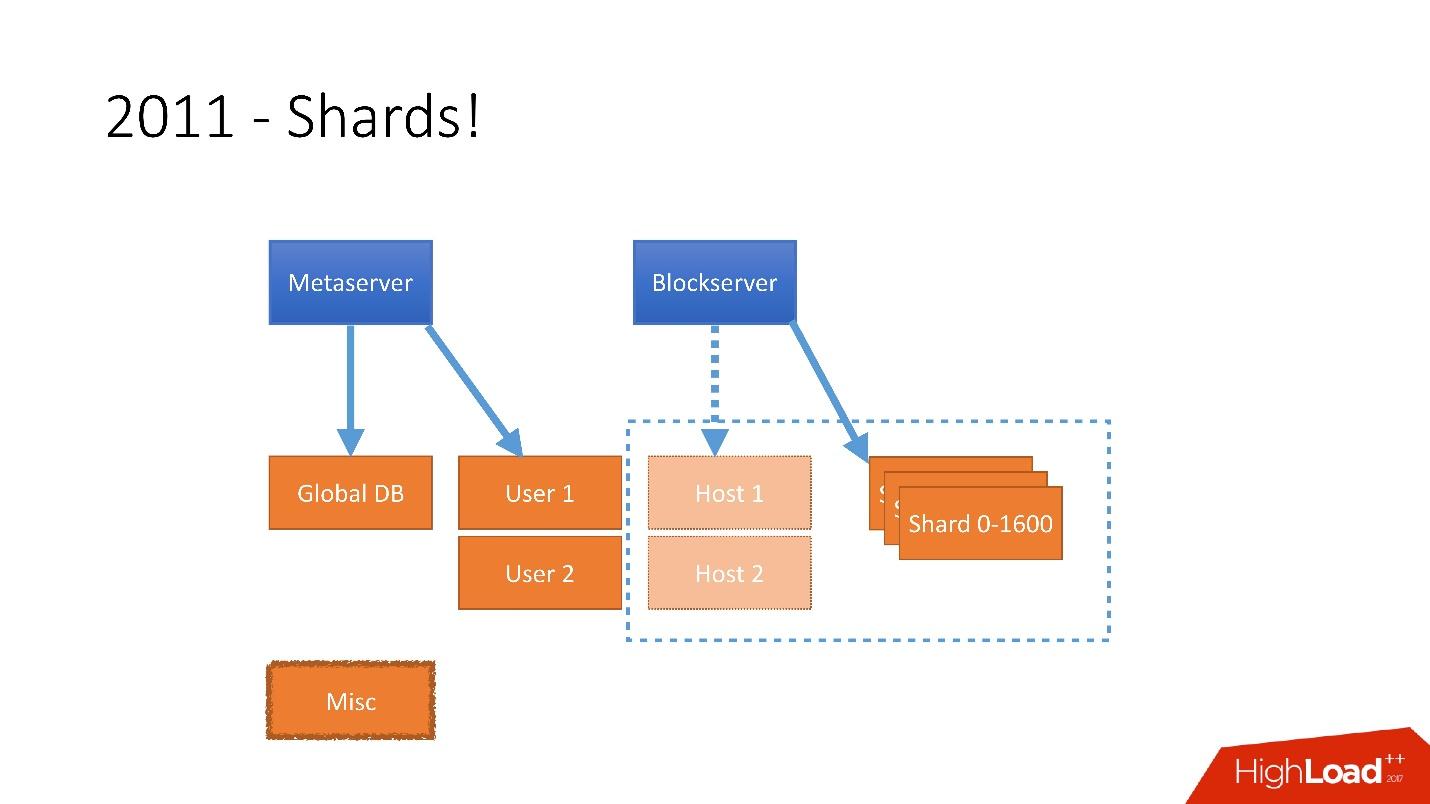
Il était nécessaire de prendre en compte une croissance aussi énorme, et donc à la fin de 2011, nous avions des tessons - une base composée de 1600 tessons. Initialement, seulement 8 serveurs avec 200 fragments chacun. Il s'agit maintenant de 400 serveurs maîtres avec chacun 4 fragments.
 Lien depuis la diapositive
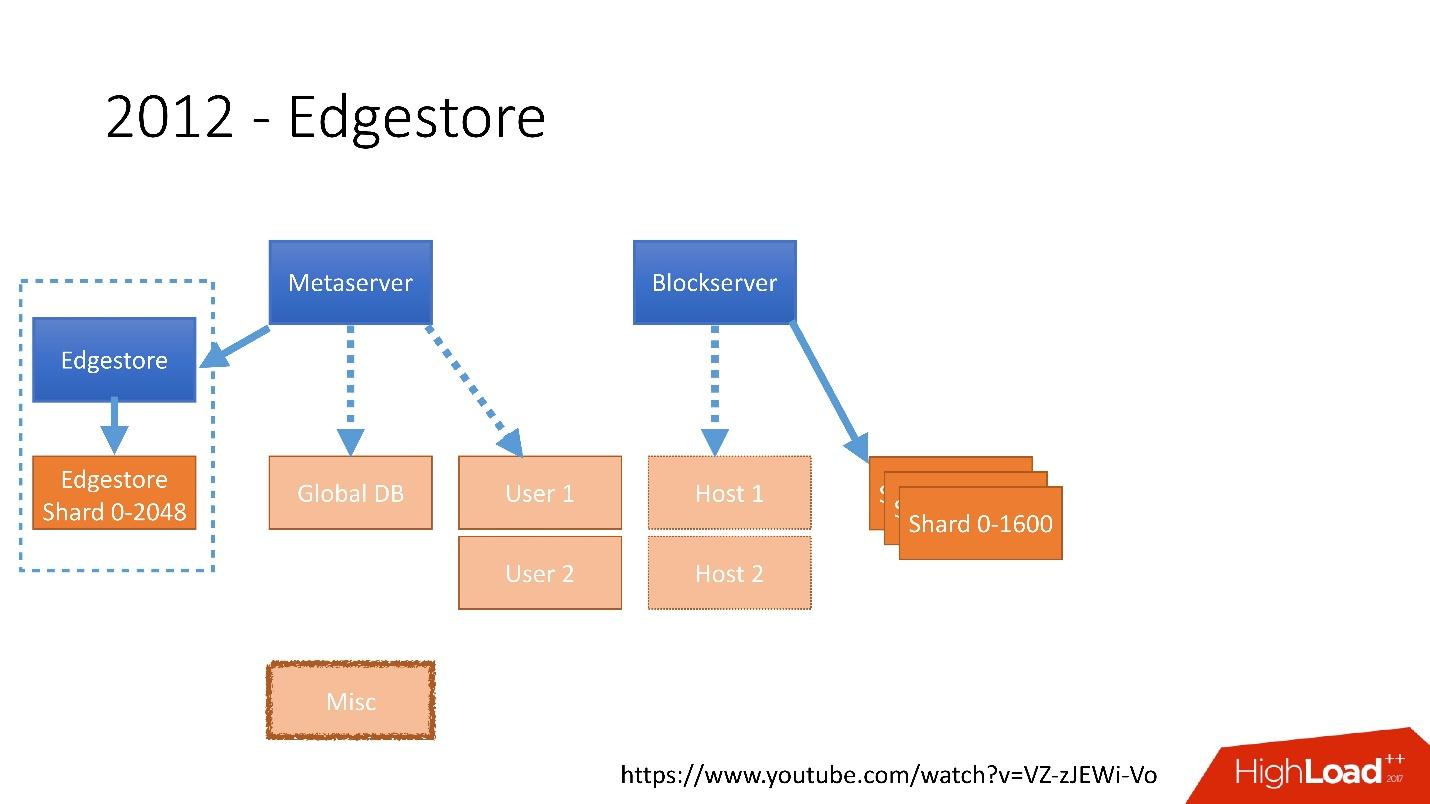
Lien depuis la diapositiveEn 2012, nous avons réalisé que la création de tables et leur mise à jour dans la base de données pour chaque logique métier ajoutée est très difficile, morne et problématique. Par conséquent, en 2012, nous avons inventé notre propre stockage graphique, que nous avons appelé
Edgestore , et depuis lors, toute la logique métier et les méta-informations que l'application génère sont stockées dans Edgestore.
Edgestore extrait essentiellement MySQL des clients. Les clients ont certaines entités qui sont interconnectées par des liens de l'API gRPC à Edgestore Core, qui convertit ces données en MySQL et les stocke en quelque sorte là-bas (en gros, il donne tout cela à partir du cache).
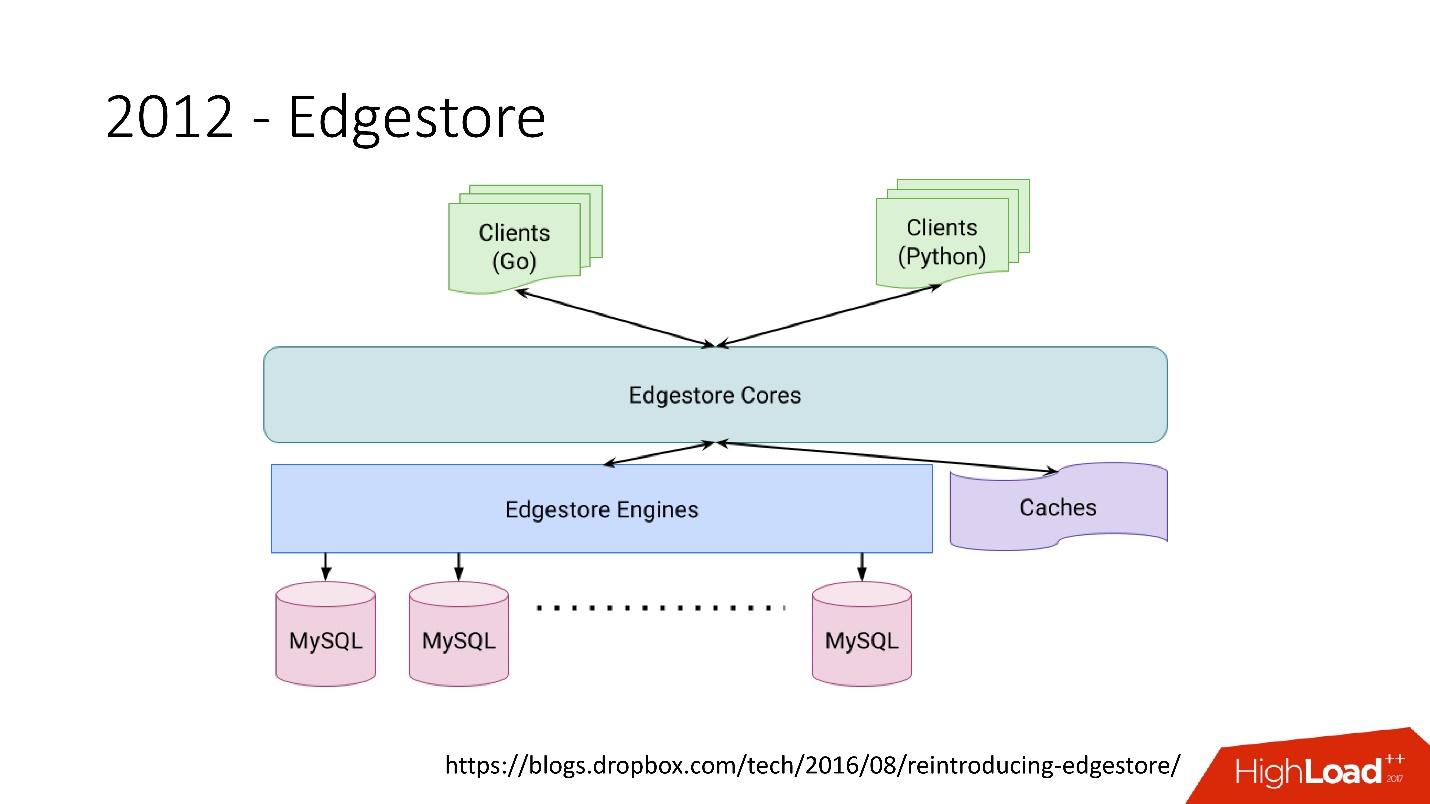 Lien depuis la diapositiveEn 2015, nous avons quitté Amazon S3
Lien depuis la diapositiveEn 2015, nous avons quitté Amazon S3 , développé notre propre stockage cloud appelé Magic Pocket. Il contient des informations sur l'emplacement d'un fichier de bloc, sur quel serveur, sur les mouvements de ces blocs entre les serveurs, stockés dans MySQL.
 Lien depuis la diapositive
Lien depuis la diapositiveMais MySQL est utilisé de manière très délicate - essentiellement, comme une grande table de hachage distribuée. Il s'agit d'une charge très différente, principalement lors de la lecture d'enregistrements aléatoires. 90% de l'utilisation est des E / S.
Architecture de base de données
Tout d'abord, nous avons immédiatement identifié certains principes par lesquels nous construisons l'architecture de notre base de données:
- Fiabilité et durabilité . C'est le principe le plus important et ce que les clients attendent de nous - les données ne doivent pas être perdues.
- L'optimalité de la solution est un principe tout aussi important. Par exemple, les sauvegardes doivent être effectuées rapidement et restaurées rapidement également.
- Simplicité de la solution - à la fois sur le plan architectural et en termes de service et de support de développement ultérieur.
- Coût de possession . Si quelque chose optimise la solution, mais coûte très cher, cela ne nous convient pas. Par exemple, un esclave qui se trouve un jour derrière le maître est très pratique pour les sauvegardes, mais vous devez ensuite ajouter 1 000 de plus à 6 000 serveurs - le coût de possession d'un tel esclave est très élevé.
Tous les principes doivent être
vérifiables et mesurables , c'est-à-dire qu'ils doivent avoir des paramètres. Si nous parlons du coût de possession, nous devons calculer le nombre de serveurs que nous avons, par exemple, va aux bases de données, combien de serveurs vont aux sauvegardes et combien cela coûte pour Dropbox à la fin. Lorsque nous choisissons une nouvelle solution, nous comptons toutes les métriques et nous concentrons sur elles. Lors du choix d'une solution, nous sommes pleinement guidés par ces principes.
Topologie de base
La base de données est structurée comme suit:
- Dans le centre de données principal, nous avons un maître, dans lequel tous les enregistrements se produisent.
- Le serveur maître possède deux serveurs esclaves vers lesquels se produit la réplication semi-synchronisée. Les serveurs meurent souvent (environ 10 par semaine), nous avons donc besoin de deux serveurs esclaves.
- Les serveurs esclaves sont dans des clusters séparés. Les clusters sont des pièces complètement séparées dans le centre de données qui ne sont pas connectées les unes aux autres. Si une pièce brûle, la seconde reste complètement fonctionnelle.
- Dans un autre centre de données, nous avons également le pseudo-maître (maître intermédiaire), qui n'est en fait qu'un esclave, qui a un autre esclave.
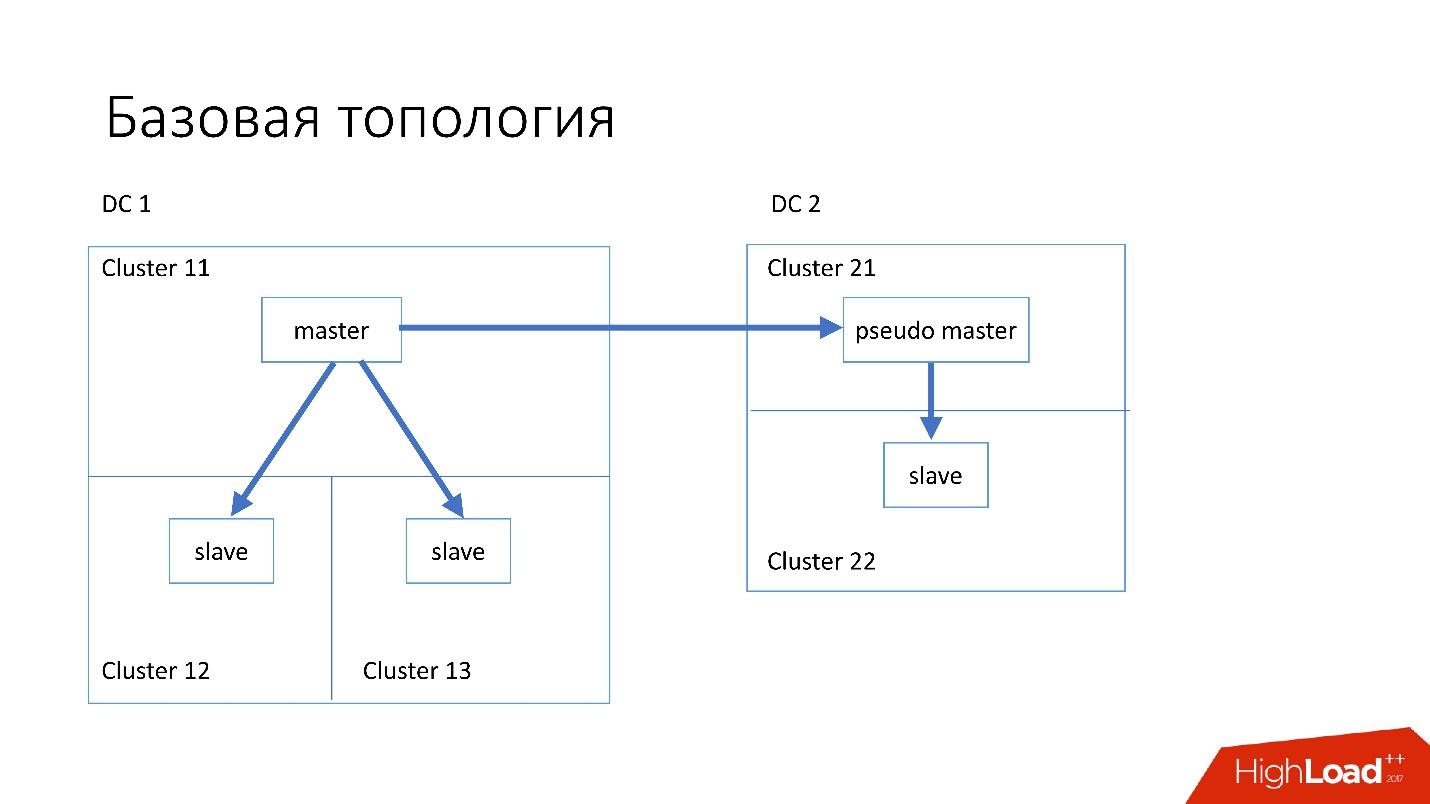
Une telle topologie a été choisie parce que si le premier centre de données meurt soudainement en nous, alors dans le deuxième centre de données, nous avons une
topologie presque complète . Nous changeons simplement toutes les adresses dans Discovery, et les clients peuvent travailler.
Topologies spécialisées
Nous avons également des topologies spécialisées.
La topologie
Magic Pocket se compose d'un serveur maître et de deux serveurs esclaves. Cela est dû au fait que Magic Pocket duplique lui-même les données entre les zones. S'il perd un cluster, il peut restaurer toutes les données d'autres zones via le code d'effacement.

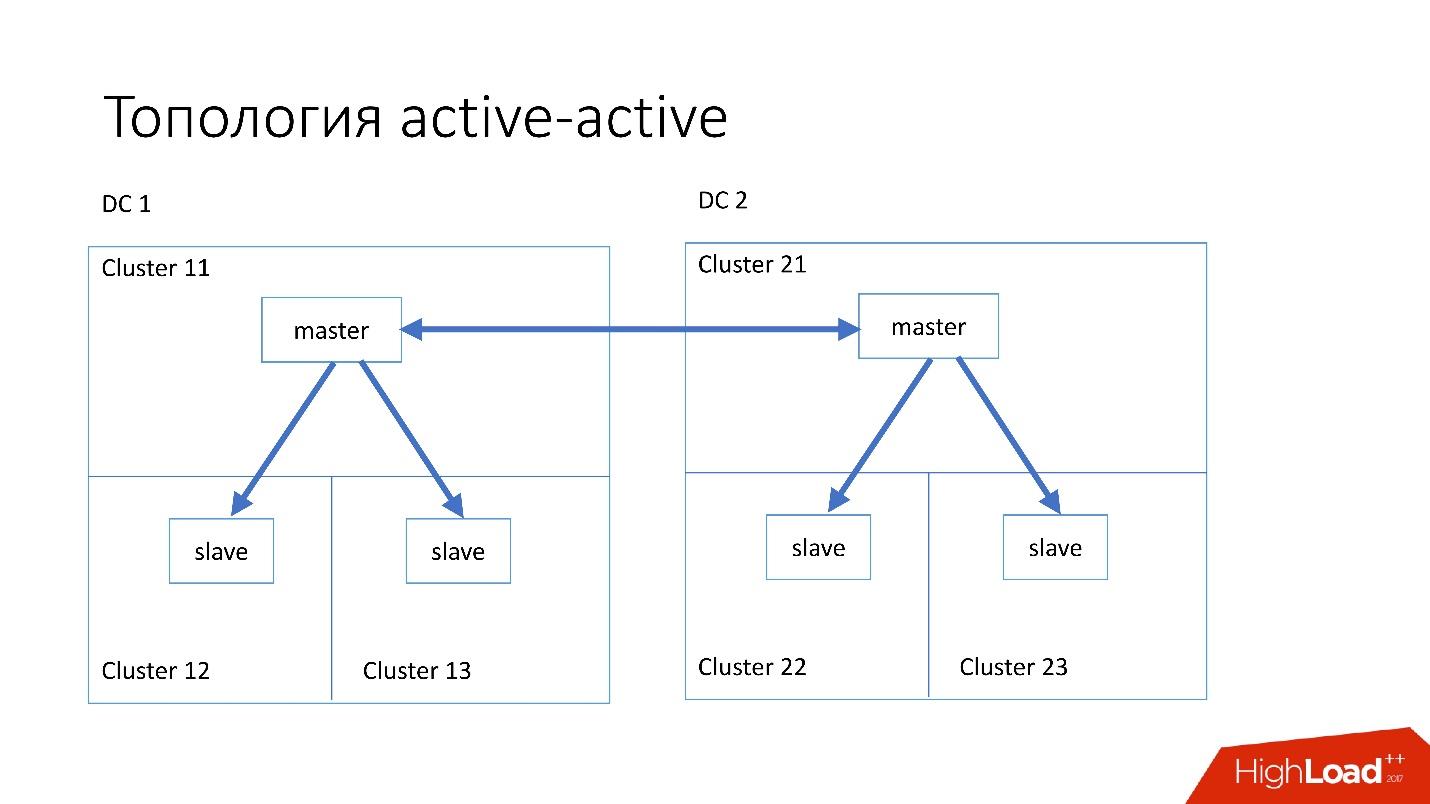
La topologie
active-active est la topologie personnalisée utilisée par Edgestore. Il a un maître et deux esclaves dans chacun des deux centres de données, et ils sont esclaves l'un pour l'autre. C'est un
schéma très
dangereux , mais Edgestore à son niveau sait exactement quelles données sur quel maître sur quelle plage il peut écrire. Par conséquent, cette topologie ne se casse pas.
Instance
Nous avons installé des serveurs assez simples avec une configuration de 4 à 5 ans:
- 2x noyaux Xeon 10;
- 5 To (8 SSD Raid 0 *);
- 384 Go de mémoire.
* Raid 0 - car il est plus facile et beaucoup plus rapide de remplacer un serveur entier que des lecteurs.
Instance unique
Sur ce serveur, nous avons une grande instance MySQL sur laquelle se trouvent plusieurs fragments. Cette instance MySQL alloue immédiatement presque toute la mémoire. D'autres processus sont également en cours d'exécution sur le serveur: proxy, collecte de statistiques, journaux, etc.
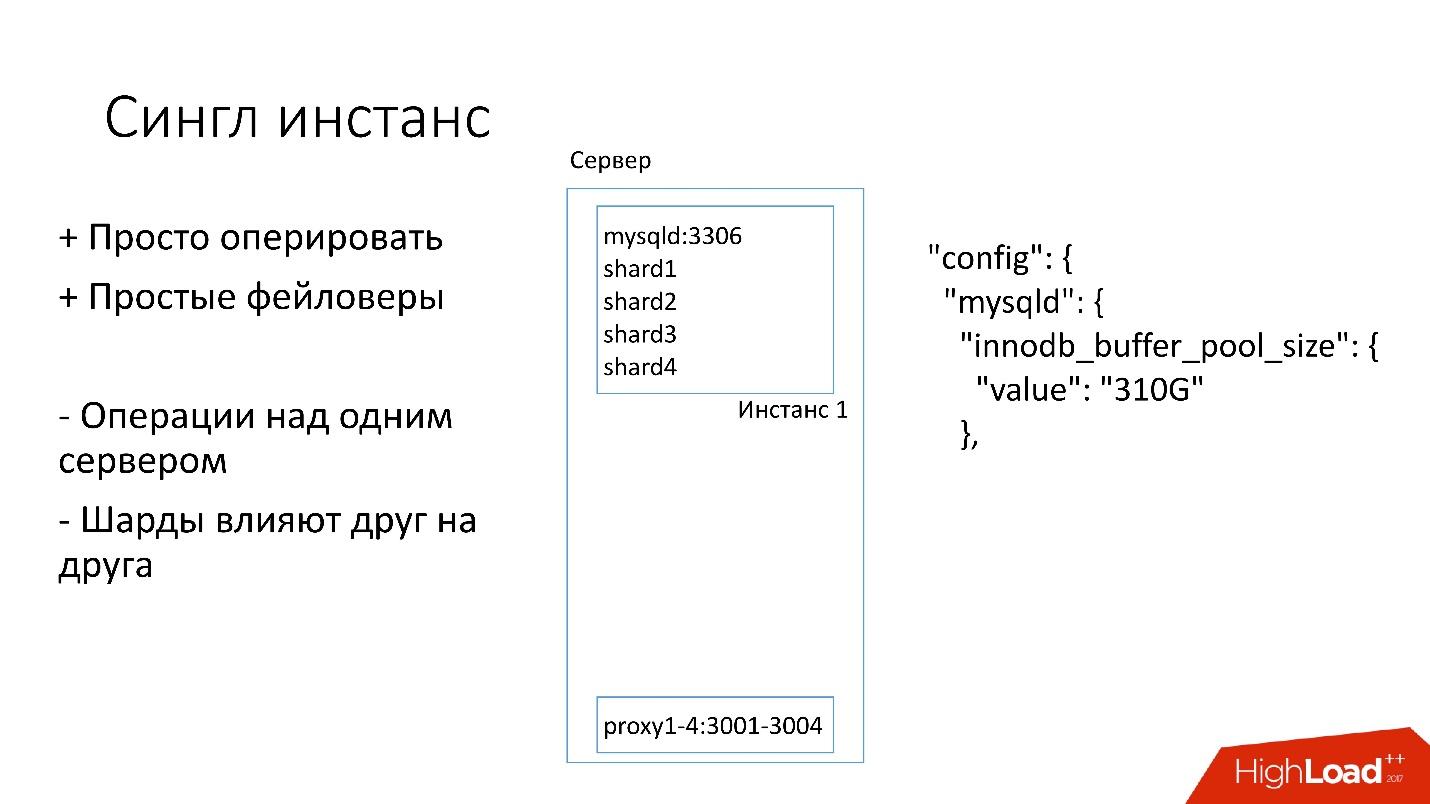
Cette solution est bonne en ce que:
+ C'est
facile à gérer . Si vous devez remplacer l'instance MySQL, remplacez simplement le serveur.
+
Faylovers .
D'un autre côté:
- Il est problématique que toutes les opérations se produisent sur l'ensemble de l'instance de MySQL et immédiatement sur tous les fragments. Par exemple, si vous avez besoin de sauvegarder, nous sauvegardons tous les fragments en même temps. Si vous devez faire un faylover, nous faisons un faylover des quatre fragments à la fois. En conséquence, l'accessibilité en souffre 4 fois plus.
- Les problèmes de réplication d'un fragment affectent d'autres fragments. La réplication MySQL n'est pas parallèle et tous les fragments fonctionnent sur un seul thread. Si quelque chose arrive à un éclat, les autres deviennent également des victimes.
Alors maintenant, nous passons à une topologie différente.
Multi-instance

Dans la nouvelle version, plusieurs instances MySQL sont lancées simultanément sur le serveur, chacune avec un fragment. Quoi de mieux?
+ Nous ne pouvons
effectuer des opérations que sur un fragment spécifique . Autrement dit, si vous avez besoin d'un faylover, changez un seul fragment, si vous avez besoin d'une sauvegarde, nous ne sauvegardons qu'un seul fragment. Cela signifie que les opérations sont considérablement accélérées - 4 fois pour un serveur à quatre fragments.
+ Les
éclats ne s'influencent guère .
+
Amélioration de la réplication. Nous pouvons mélanger différentes catégories et classes de bases de données. Edgestore prend beaucoup d'espace, par exemple, les 4 To, et Magic Pocket ne prend que 1 To, mais il a une utilisation de 90%. Autrement dit, nous pouvons combiner différentes catégories qui utilisent les E / S et les ressources machine de différentes manières, et démarrer 4 flux de réplication.
Bien sûr, cette solution a ses inconvénients:
- Le plus gros inconvénient est qu'il est
beaucoup plus difficile de gérer tout cela . Nous avons besoin d'un planificateur intelligent qui saura où il peut prendre cette instance, où il y aura une charge optimale.
-
Plus dur que les basculements .
Par conséquent, nous en venons seulement à cette décision.
Découverte
Les clients doivent savoir comment se connecter à la base de données souhaitée, nous avons donc Discovery, qui devrait:
- Informez le client très rapidement des changements de topologie. Si nous changeons de maître et d'esclave, les clients devraient en être informés presque instantanément.
- La topologie ne doit pas dépendre de la topologie de réplication MySQL, car avec certaines opérations, nous changeons la topologie MySQL. Par exemple, lorsque nous divisons, à l'étape préparatoire sur le maître cible, où nous transférerons une partie des fragments, certains des serveurs esclaves sont reconfigurés sur ce maître cible. Les clients n'ont pas besoin de le savoir.
- Il est important qu'il y ait atomicité des opérations et vérification de l'état. Il est impossible que deux serveurs différents de la même base de données deviennent maîtres au même moment.
Comment la découverte s'est développée
Au début, tout était simple: l'adresse de la base de données dans le code source de la configuration. Lorsque nous avions besoin de mettre à jour l'adresse, tout s'est déployé très rapidement.

Malheureusement, cela ne fonctionne pas s'il y a beaucoup de serveurs.
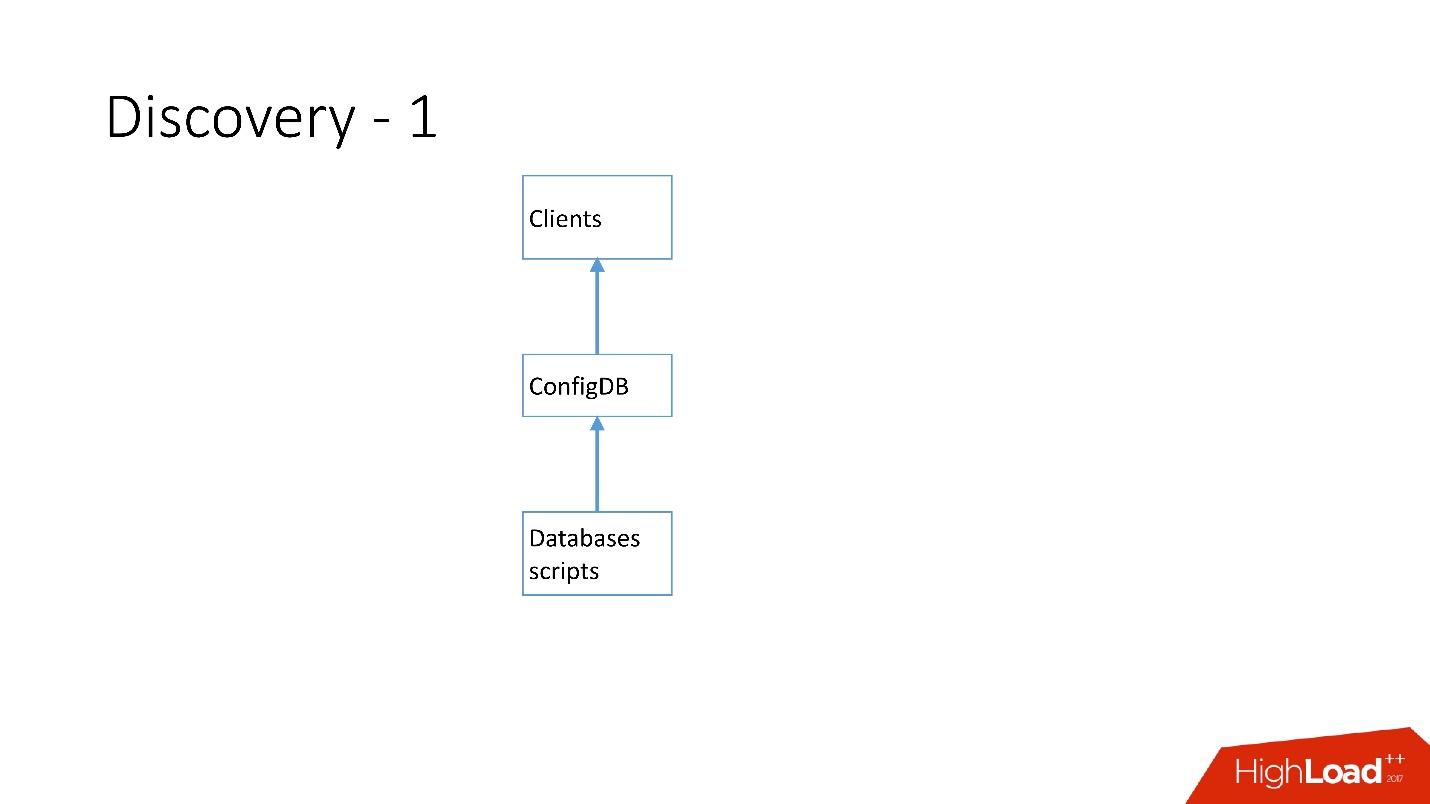
Ci-dessus est la toute première découverte que nous avons. Il y avait des scripts de base de données qui changeaient la plaque signalétique dans ConfigDB - c'était une plaque signalétique MySQL distincte, et les clients écoutaient déjà cette base de données et en prenaient périodiquement des données.

Le tableau est très simple, il y a une catégorie de base de données, une clé de partition, un maître / esclave de classe de base de données, un proxy et une adresse de base de données. En fait, le client a demandé une catégorie, une classe DB, une clé de partition et l'adresse MySQL a été retournée à laquelle il pouvait déjà établir une connexion.
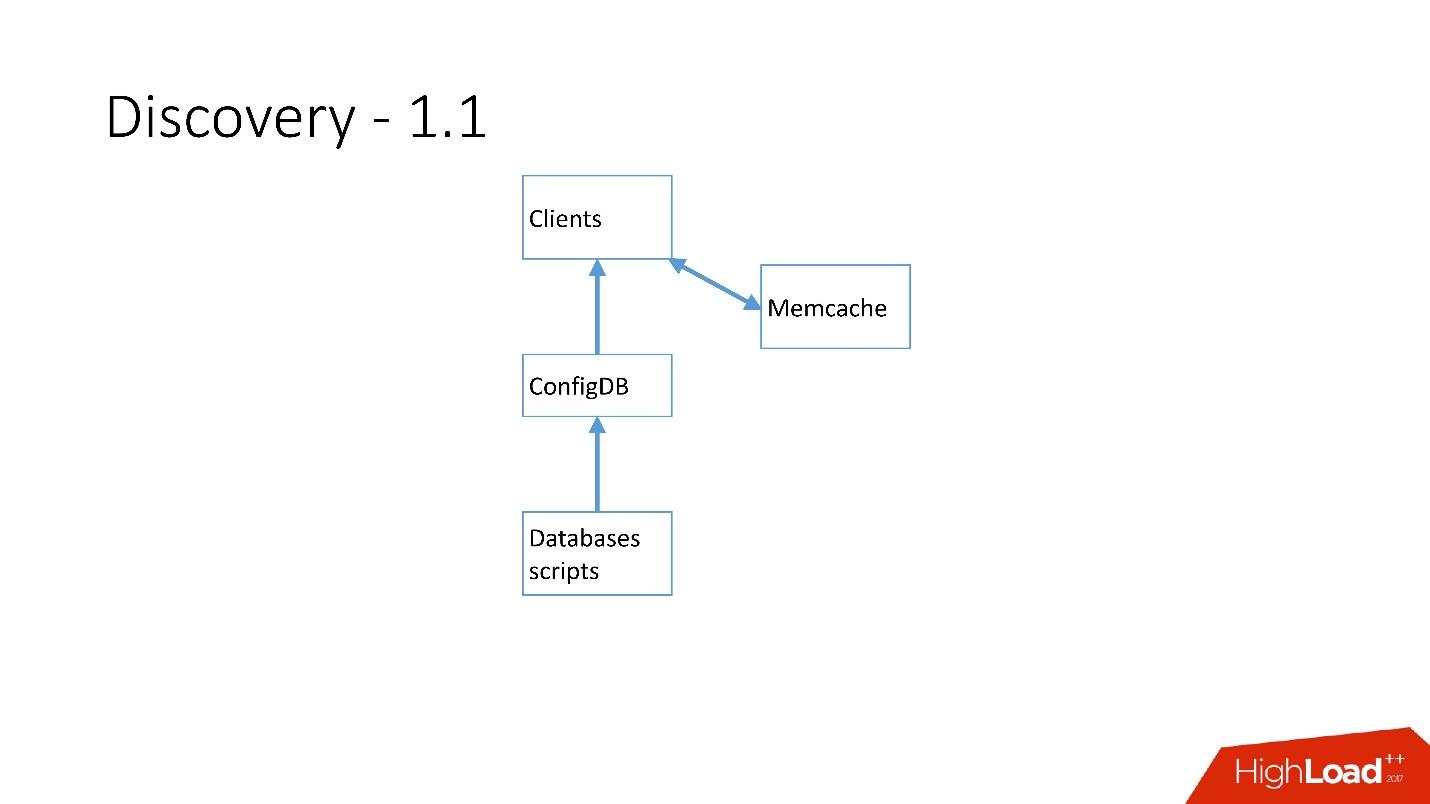
Dès qu'il y avait beaucoup de serveurs, Memcache a été ajouté et les clients ont déjà commencé à communiquer avec lui.
Mais ensuite nous l'avons retravaillé. Les scripts MySQL ont commencé à communiquer via gRPC, via un client léger avec un service appelé RegisterService. Lorsque certains changements se sont produits, RegisterService avait une file d'attente et il a compris comment appliquer ces changements. RegisterService a enregistré les données dans AFS. AFS est notre système interne basé sur ZooKeeper.

La deuxième solution, qui n'est pas présentée ici, utilisait directement ZooKeeper, ce qui créait des problèmes car chaque fragment était un nœud dans ZooKeeper. Par exemple, 100 000 clients se connectent à ZooKeeper, s'ils sont morts subitement à cause d'une sorte de bogue tous ensemble, alors 100 000 demandes à ZooKeeper viendront immédiatement, ce qui le laissera simplement tomber et il ne pourra pas augmenter.
Par conséquent,
le système AFS a été développé
, qui est utilisé par l'ensemble de Dropbox . En fait, il résume le travail avec ZooKeeper pour tous les clients. Le démon AFS s'exécute localement sur chaque serveur et fournit une API de fichier très simple du formulaire: créer un fichier, supprimer un fichier, demander un fichier, recevoir une notification de modification de fichier et comparer et échanger des opérations. Autrement dit, vous pouvez essayer de remplacer le fichier par une version et si cette version a changé pendant la modification, l'opération est annulée.
Essentiellement, une telle abstraction sur ZooKeeper, dans laquelle il existe un algorithme d'interruption et de gigue local. ZooKeeper ne plante plus sous charge. Avec AFS, nous prenons des sauvegardes dans S3 et dans GIT, puis l'AFS local lui-même informe les clients que les données ont changé.

Dans AFS, les données sont stockées sous forme de fichiers, c'est-à-dire qu'il s'agit d'une API de système de fichiers. Par exemple, ce qui précède est le fichier shard.slave_proxy - le plus grand, il prend environ 28 Ko, et lorsque nous changeons la catégorie de la classe shard et slave_proxy, tous les clients qui s'abonnent à ce fichier reçoivent une notification. Ils ont relu ce fichier, qui contient toutes les informations nécessaires. À l'aide de la clé de partition, ils obtiennent une catégorie et reconfigurent le pool de connexions à la base de données.
Les opérations
Nous utilisons des opérations très simples: promotion, clone, sauvegardes / restauration.
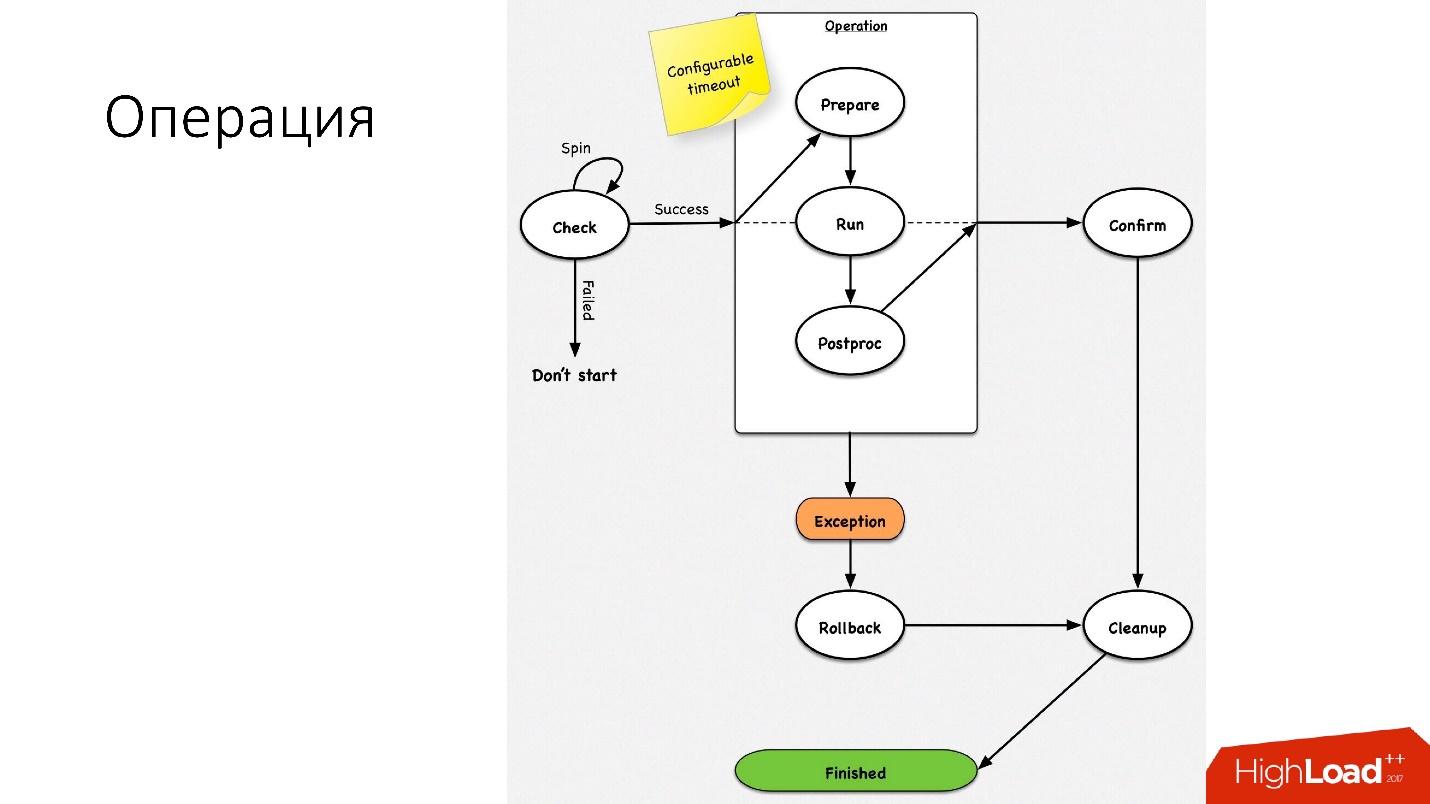 Une opération est une simple machine à états
Une opération est une simple machine à états . Lorsque nous entrons dans l'opération, nous effectuons quelques vérifications, par exemple, spin-check, qui plusieurs fois par timeout vérifie si nous pouvons effectuer cette opération. Après cela, nous faisons une action préparatoire qui n'affecte pas les systèmes externes. Ensuite, l'opération elle-même.
Toutes les étapes d'une opération ont une
étape de restauration (annuler). En cas de problème avec l'opération, l'opération tente de restaurer le système à sa position d'origine. Si tout va bien, le nettoyage a lieu et l'opération est terminée.
Nous avons une machine d'état si simple pour toute opération.
Promotion (changement de master)
Il s'agit d'une opération très courante dans la base de données. Il y avait des questions sur la façon de modifier sur un serveur maître chaud qui fonctionne - il obtiendra un enjeu. C'est juste que toutes ces opérations sont effectuées sur des serveurs esclaves, puis les changements d'esclaves avec les emplacements maîtres. Par conséquent, l'
opération de promotion est très fréquente .

Nous devons mettre à jour le noyau - nous échangeons, nous devons mettre à jour la version de MySQL - nous mettons à jour sur l'esclave, passons au maître, y mettons à jour.

Nous avons réalisé une promotion très rapide. Par exemple,
pour quatre fragments, nous avons maintenant une promotion pour environ 10-15 s. Le graphique ci-dessus montre qu'avec la disponibilité des promotions, il a souffert de 0,0003%.
Mais la promotion normale n'est pas si intéressante, car ce sont des opérations ordinaires qui sont effectuées tous les jours. Les basculements sont intéressants.
Basculement (remplacement d'un maître cassé)
Un basculement signifie que la base de données est morte.
- Si le serveur est vraiment mort, c'est juste un cas idéal.
- En fait, il arrive que les serveurs soient partiellement vivants.
- Parfois, le serveur meurt très lentement. Les contrôleurs RAID, le système de disques échouent, certaines demandes renvoient des réponses, mais certains flux sont bloqués et ne renvoient pas de réponses.
- Il arrive que le maître soit simplement surchargé et ne réponde pas à notre bilan de santé. Mais si nous faisons de la promotion, le nouveau maître sera également surchargé, et cela ne fera qu'empirer.
Le remplacement des serveurs maîtres décédés a lieu environ
2-3 fois par jour , il s'agit d'un processus entièrement automatisé, aucune intervention humaine n'est nécessaire. La section critique prend environ 30 secondes, et elle contient un tas de vérifications supplémentaires pour voir si le serveur est réellement vivant, ou peut-être qu'il est déjà mort.
Voici un exemple de schéma de fonctionnement du faylover.

Dans la section sélectionnée, nous
redémarrons le serveur maître . Ceci est nécessaire car nous avons MySQL 5.6, et la réplication semi-synchrone n'est pas sans perte. Par conséquent, les lectures fantômes sont possibles, et nous avons besoin de ce maître, même s'il n'est pas mort, tuez le plus rapidement possible afin que les clients s'en déconnectent. Par conséquent, nous effectuons une réinitialisation matérielle via Ipmi - c'est la première opération la plus importante que nous devons faire. Dans la version MySQL 5.7, ce n'est pas si critique.
Synchronisation de cluster. Pourquoi avons-nous besoin d'une synchronisation de cluster?
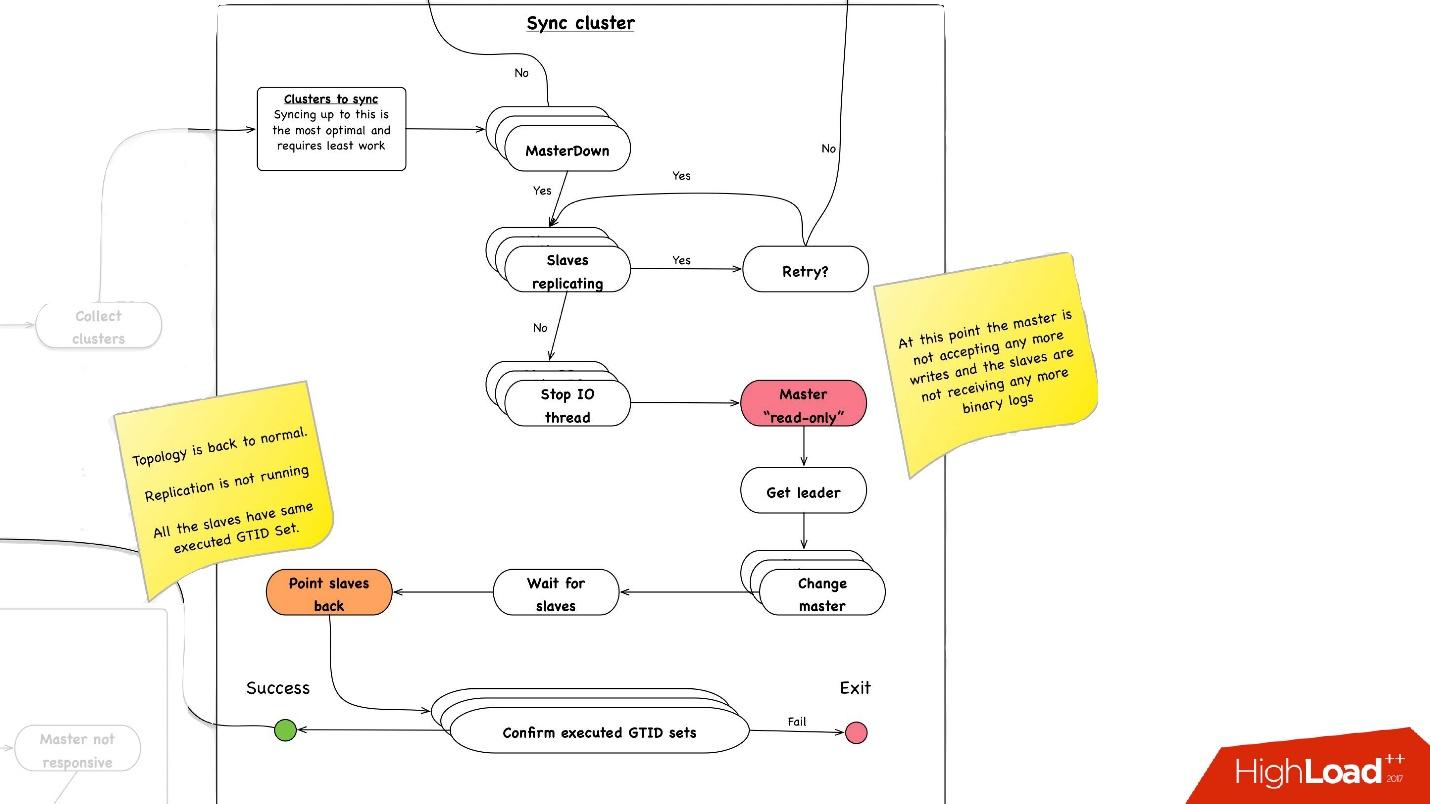
Si nous rappelons l'image précédente avec notre topologie, un serveur maître a trois serveurs esclaves: deux dans un centre de données, un dans l'autre. Avec la promotion, nous avons besoin que master soit dans le même centre de données principal. Mais parfois, lorsque des esclaves sont chargés, avec semisync, il arrive qu'un esclave semi-sync devienne un esclave dans un autre centre de données, car il n'est pas chargé. Par conséquent, nous devons d'abord synchroniser l'ensemble du cluster, puis faire déjà la promotion sur l'esclave dans le centre de données dont nous avons besoin. Cela se fait très simplement:
- Nous arrêtons tous les threads d'E / S sur tous les serveurs esclaves.
- Après cela, nous savons déjà avec certitude que master est en "lecture seule", car semisync s'est déconnecté et personne d'autre ne peut rien y écrire.
- Ensuite, nous sélectionnons l'esclave avec le plus grand ensemble GTID récupéré / exécuté, c'est-à-dire avec la plus grande transaction qu'il a téléchargée ou déjà appliquée.
- Nous reconfigurons tous les serveurs esclaves sur cet esclave sélectionné, démarrons le thread d'E / S et ils sont synchronisés.
- Nous attendons qu'ils soient synchronisés, après quoi l'ensemble du cluster est synchronisé. , executed GTID set .
—
.
promotion , :
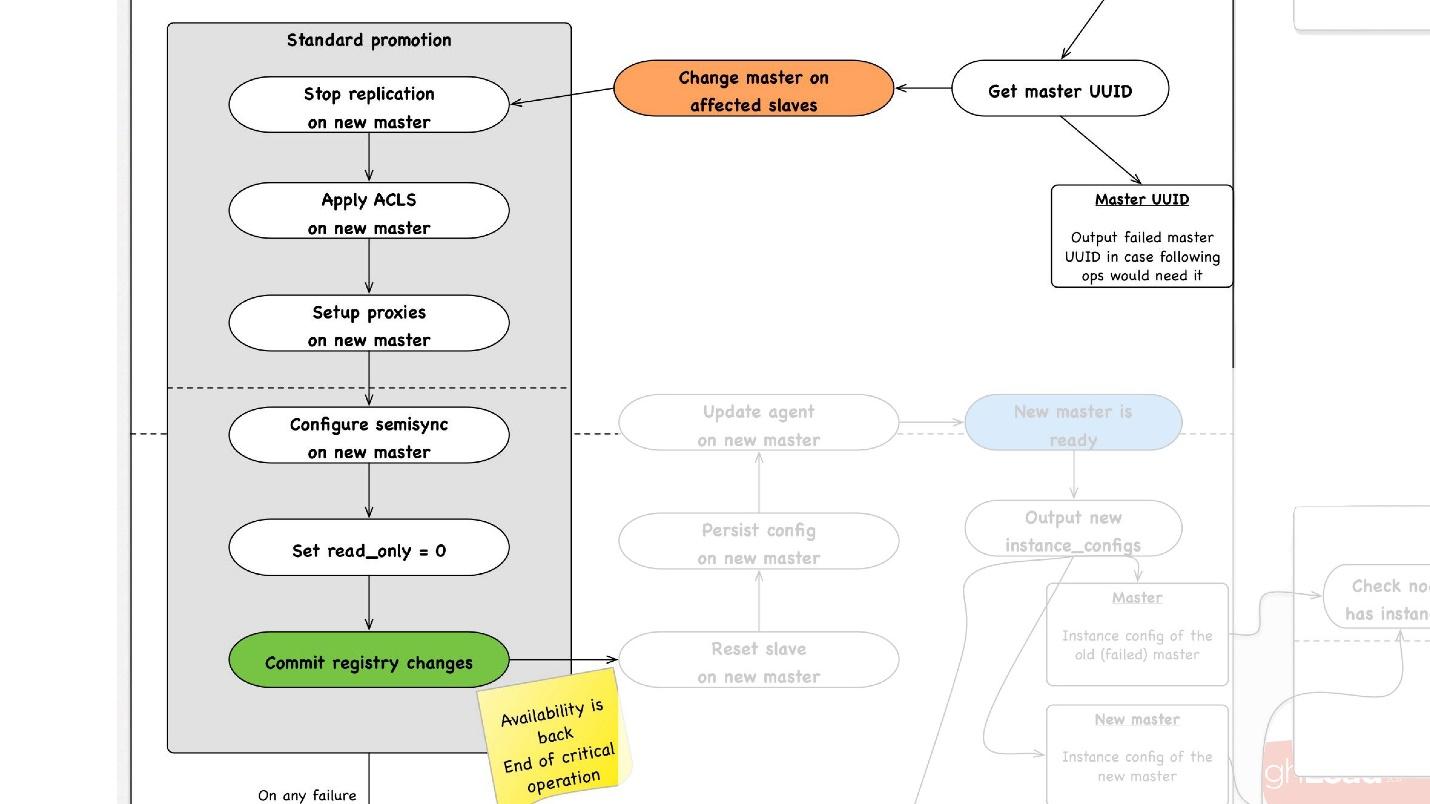
- slave -, , master, promotion.
- slave- master, , ACLs, , - proxy, , - .
- read_only = 0, , master , . master .
- - . - , , , , , proxy .
- .
, rollback , . rollback reboot. , , , — change master — master .
— . , , , , .
● slave
, slave-, . .
●
, , . .
●
, , . . 3 .
, , , :
- . 1 40 .
- .
, . 1 40 , , , .
, . . 4 .
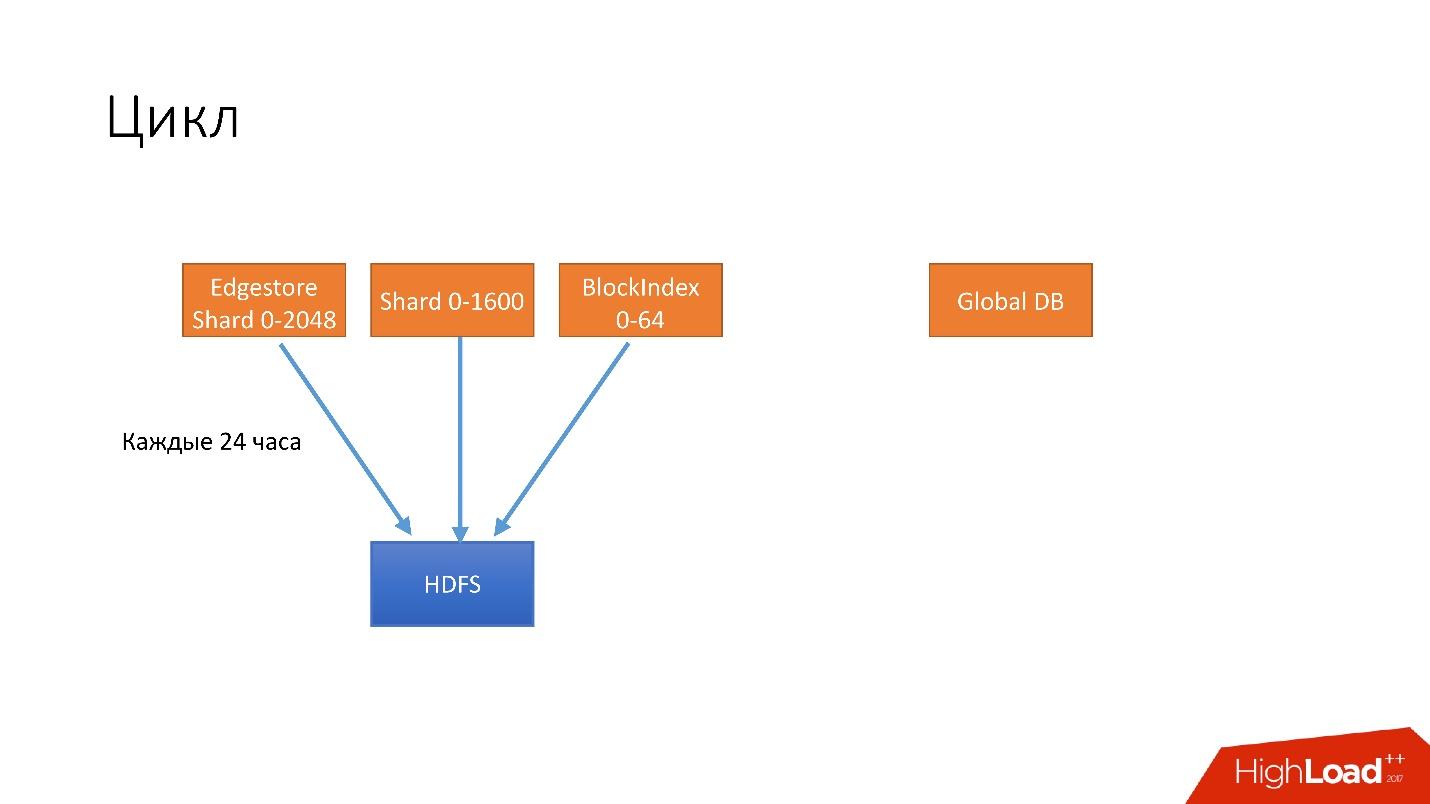
- 24 . HDFS, .
- 6 unsharded databases, Global DB. , , , .
- 3 S3.
- 3 S3 .

. , 3 , HDFS 3 , 6 S3. .
, .

, , . , , recovery - . , , - . 100 , .
, , , , , , , . .

hot-, Percona xtrabackup. —stream=xbstream, , . script-splitter, , .
MySQL 2x. 3 , , , 1 500 . , , HDFS S3.
.

, , HDFS S3, , splitter xtrabackup, . crash-recovery.
hot , crash-recovery . , . binlog, master.
binlogs?binlog'. master , 4 , 100 , HDFS.
: Binlog Backuper, . , , binlog HDFS.
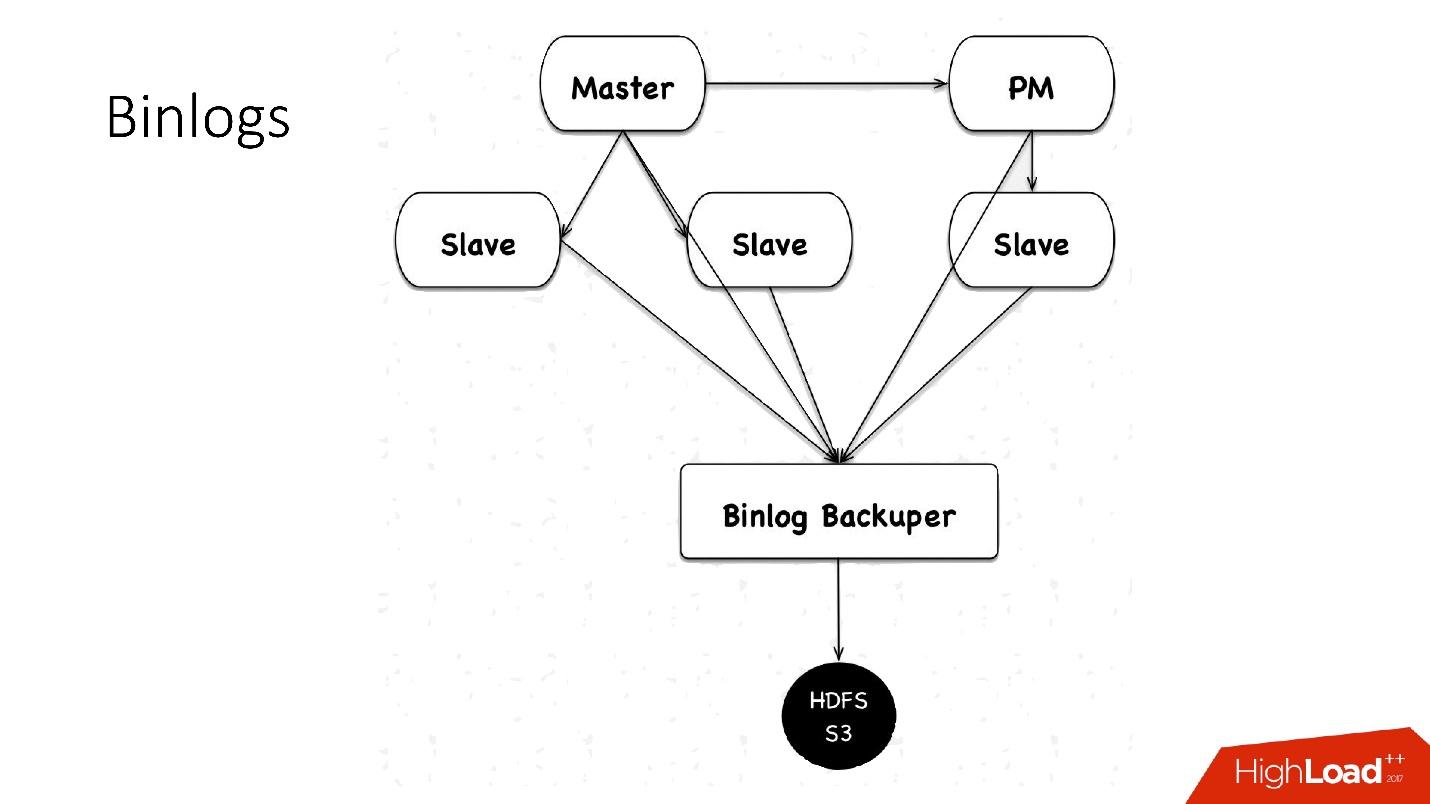
, 4 , 5 , , , . HDFS S3 .
.
:
- — 10 , 45 — .
- , scheduler multi instance slave master .
- — , . , , , , , , . pt-table-checksum , .
, :
- 1 10 , . crash-recovery, .
- .

slave -, . , . Tout est très simple.
++
. Hardware , (HDD) 10 , + crash recovery xtrabackup, . , , . , , , , HDD , HDFS .
, — :
- ;
- .
, HDFS, , , .
Automatisation
, 6 000 . , , — :
- Auto-replace;
- DBManager;
- Naoru, Wheelhouse
Auto-replace
, , , , — , -. , .
Availability () — , . — recovery , .

MySQL , heartbeat. Heartbeat — timestamp.
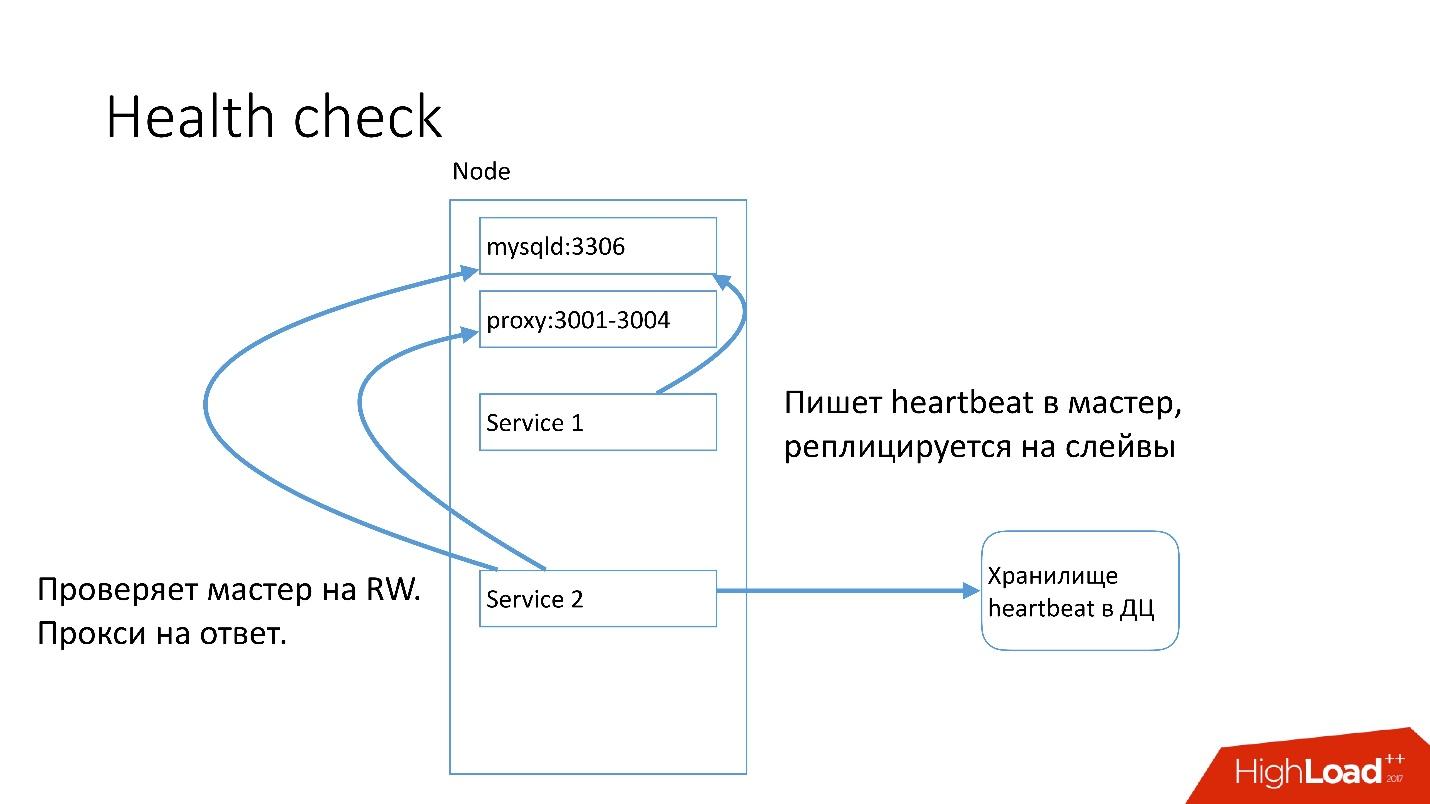
, , , master read-write. heartbeat.
auto-replace , .
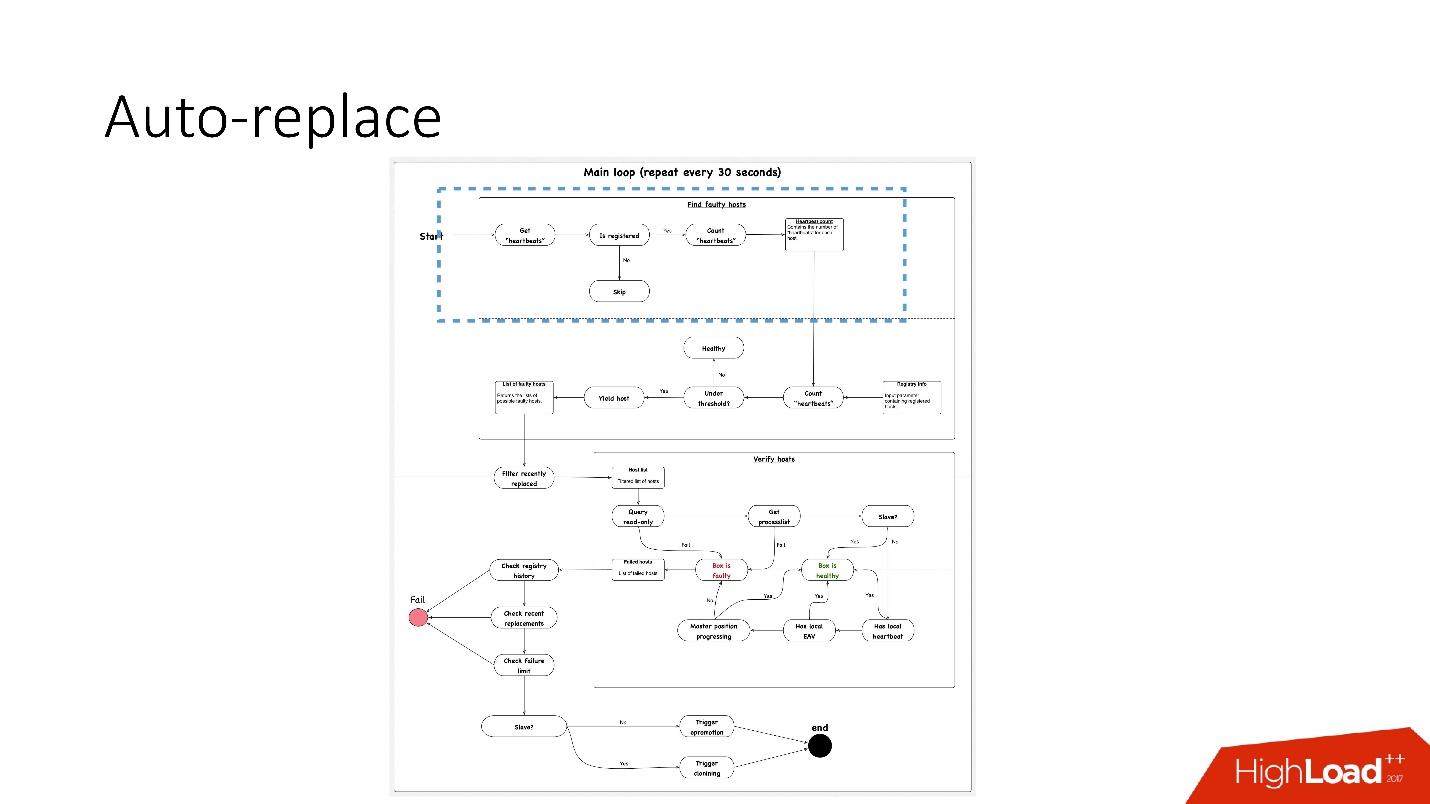 , 91 .?
, 91 .?- , heartbeat . , . heartbeat', , heartbeat' 30 .
- Ensuite, voyez si leur nombre satisfait la valeur de seuil. Sinon, alors quelque chose ne va pas avec le serveur - car il n'a pas envoyé de battement de cœur.
- Après cela, nous effectuons une vérification inverse au cas où - soudainement, ces deux services sont morts, quelque chose est avec le réseau, ou la base de données mondiale ne peut pas écrire le rythme cardiaque pour une raison quelconque. En contre-vérification, nous nous connectons à une base de données cassée et vérifions son état.
- Si tout le reste échoue, nous regardons si la position principale progresse ou non, s'il y a des enregistrements dessus. Si rien ne se passe, alors ce serveur ne fonctionne définitivement pas.
- La dernière étape est en fait le remplacement automatique.
Le remplacement automatique est très conservateur, il ne veut jamais faire beaucoup d'opérations automatiques.
- Tout d'abord, nous vérifions s'il y a eu des opérations de topologie récemment? Peut-être que ce serveur vient d'être ajouté et que quelque chose ne fonctionne pas encore.
- Nous vérifions s'il y a à tout moment des remplacements dans le même cluster.
- Vérifiez quelle limite de panne nous avons. Si nous avons de nombreux problèmes en même temps - 10, 20 - alors nous ne les résoudrons pas tous automatiquement, car nous pouvons perturber par inadvertance le fonctionnement de toutes les bases de données.
Par conséquent, nous
ne résolvons qu'un seul problème à la fois .
En conséquence, pour le serveur esclave, nous commençons le clonage et le supprimons simplement de la topologie, et s'il est maître, nous lançons alors le feylover, la soi-disant promotion d'urgence.
DBManager
DBManager est un service de gestion de nos bases de données. Il a:
- planificateur de tâches intelligent qui sait exactement quand commencer le travail;
- journaux et toutes les informations: qui, quand et quoi a été lancé - c'est la source de la vérité;
- point de synchronisation.
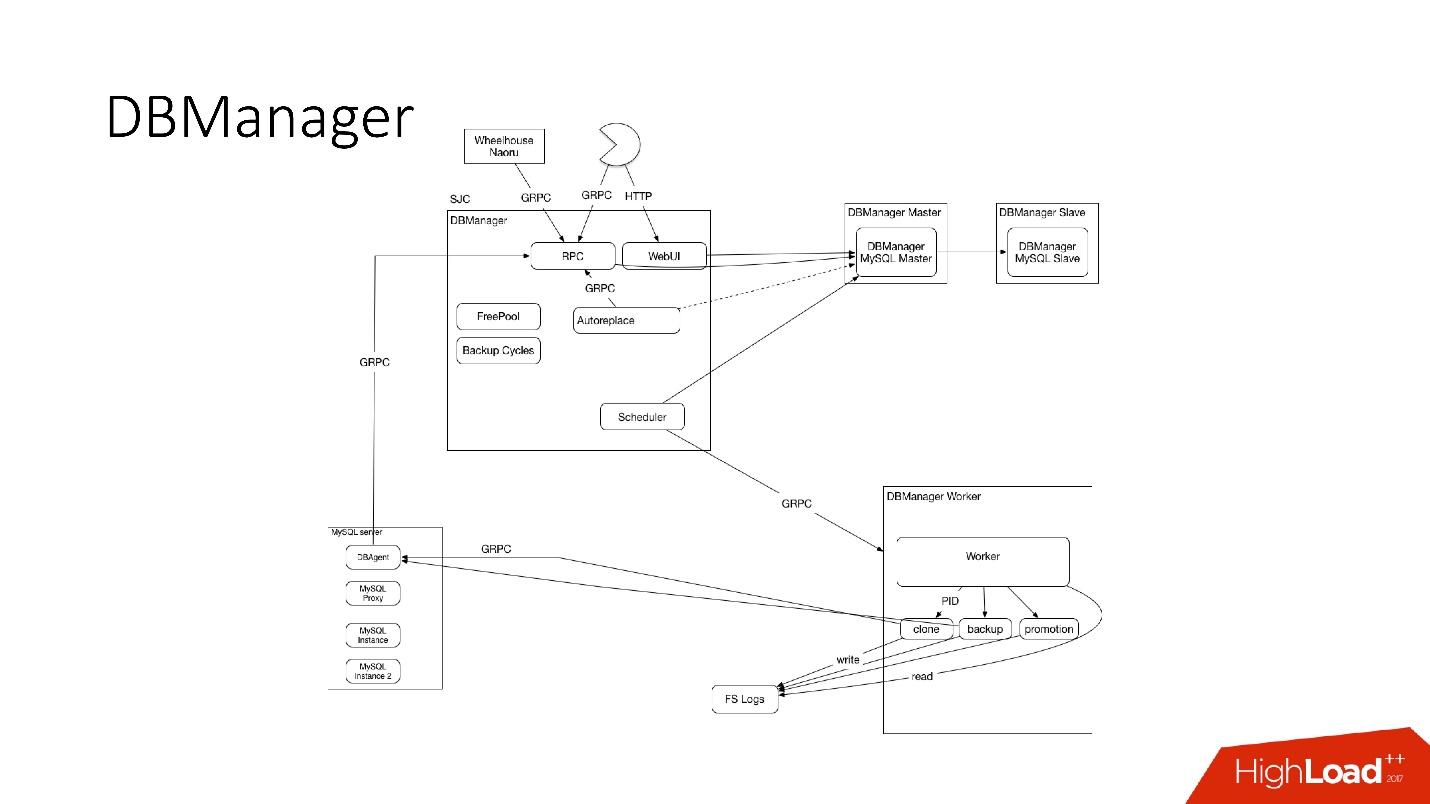
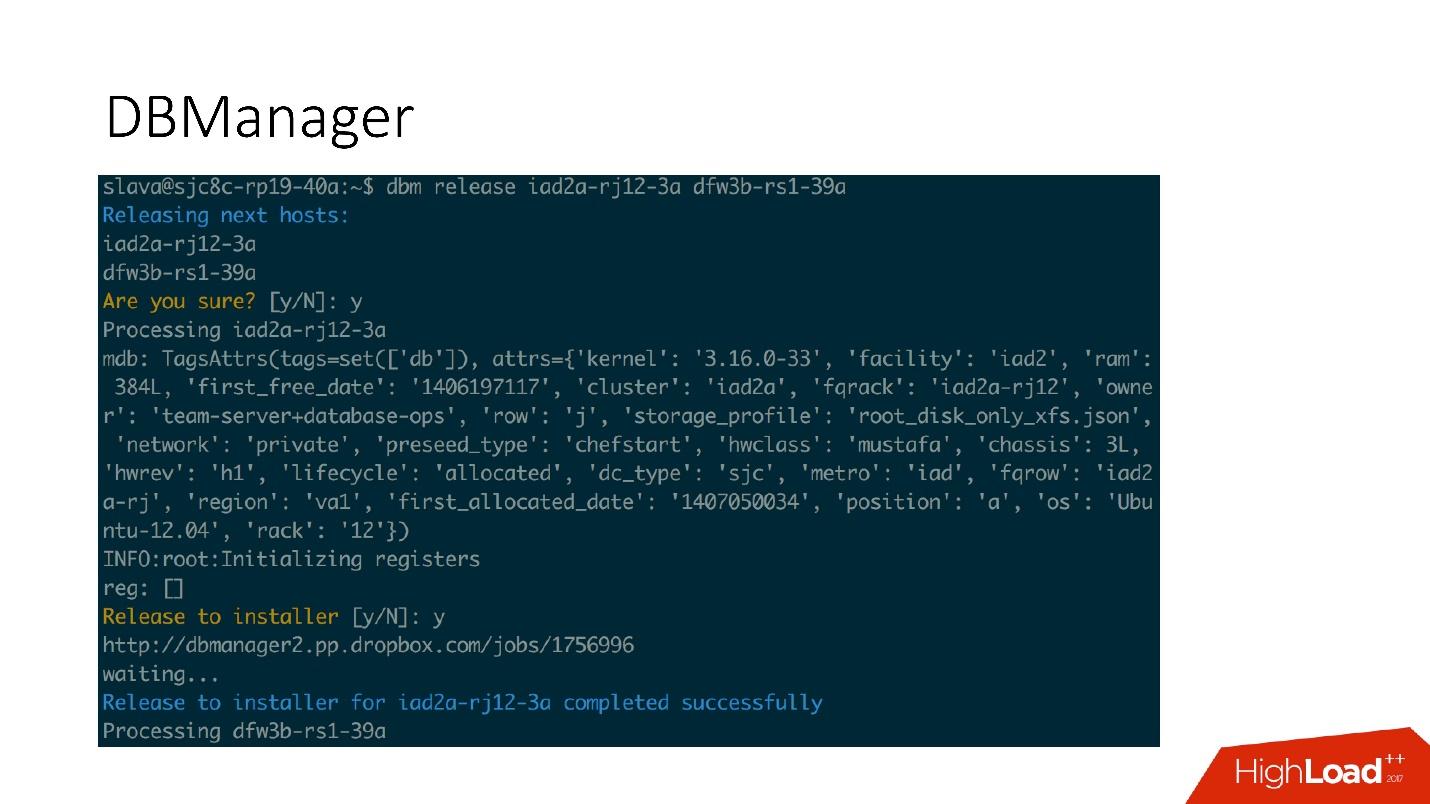
DBManager est assez simple sur le plan architectural.
- Il y a des clients, soit des DBA qui font quelque chose via l'interface Web, soit des scripts / services qui ont écrit des DBA qui accèdent via gRPC.
- Il existe des systèmes externes comme Wheelhouse et Naoru, qui vont à DBManager via gRPC.
- Il y a un planificateur qui comprend quelle opération, quand et où il peut commencer.
- Il y a un travailleur très stupide qui, quand une opération vient à lui, la démarre, vérifie par PID. Le travailleur peut redémarrer, les processus ne sont pas interrompus. Tous les employés sont situés aussi près que possible des serveurs sur lesquels les opérations ont lieu, de sorte que, par exemple, lors de la mise à jour d'ACLS, nous n'avons pas besoin d'effectuer de nombreux allers-retours.
- Sur chaque hôte SQL, nous avons un DBAgent - c'est un serveur RPC. Lorsque vous devez effectuer une opération sur le serveur, nous envoyons une demande RPC.
Nous avons une interface Web pour DBManager, où vous pouvez voir les tâches en cours d'exécution, les journaux de ces tâches, qui l'a démarrée et quand, quelles opérations ont été effectuées pour le serveur d'une base de données spécifique, etc.
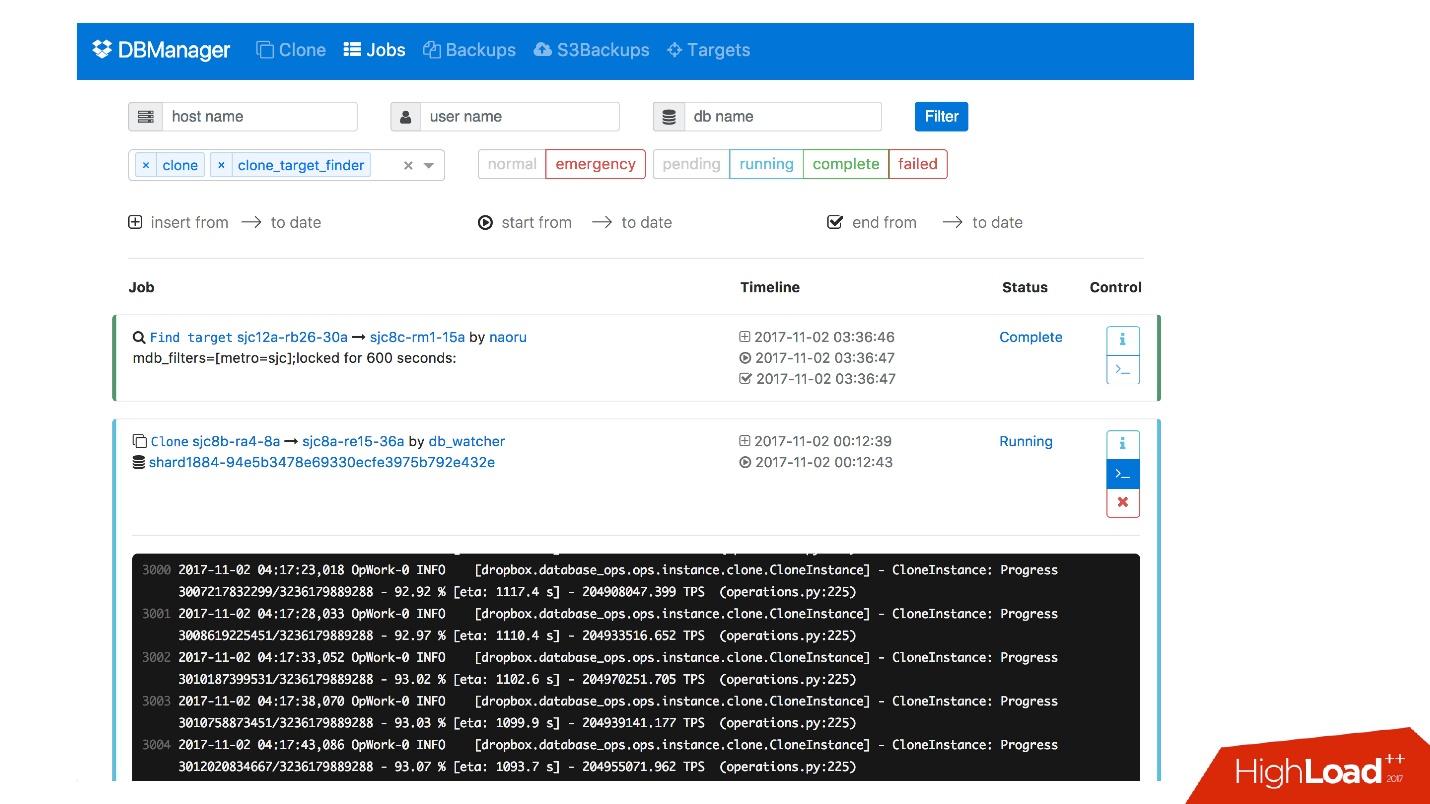
Il existe une interface CLI assez simple où vous pouvez exécuter des tâches et également les afficher dans des vues pratiques.
Remédiations
Nous avons également un système pour répondre aux problèmes. Quand quelque chose est cassé, par exemple, le disque tombe en panne, ou un service ne fonctionne pas,
Naoru fonctionne
. C'est le système qui fonctionne dans Dropbox, tout le monde l'utilise et il est spécialement conçu pour ces petites tâches. J'ai parlé de Naoru dans mon
rapport en 2016.
La timonerie est basée sur une machine d'
état et est conçue pour de longs processus. Par exemple, nous devons mettre à jour le noyau sur tout MySQL sur l'ensemble de notre cluster de 6 000 machines. Wheelhouse le fait clairement - met à jour le serveur esclave, lance la promotion, l'esclave devient maître, met à jour le serveur maître. Cette opération peut prendre un mois voire deux.
Suivi

C'est très important.
Si vous ne surveillez pas le système, il est très probable qu'il ne fonctionne pas.
Nous surveillons tout dans MySQL - toutes les informations que nous pouvons obtenir de MySQL sont stockées quelque part, nous pouvons y accéder à temps. Nous stockons des informations sur InnoDb, des statistiques sur les demandes, sur les transactions, sur la durée des transactions, le centile sur les longueurs des transactions, sur la réplication, sur le réseau - tout-tout-tout - un grand nombre de mesures.
Alerte
Nous avons 992 alertes configurées. En fait, personne ne regarde les métriques, il me semble qu'il n'y a personne qui vient travailler et commence à regarder le tableau des métriques, il y a des tâches plus intéressantes.

Par conséquent, il existe des alertes qui fonctionnent lorsque certaines valeurs de seuil sont atteintes.
Nous avons 992 alertes, quoi qu'il arrive, nous le saurons .
Incidents

Nous avons PagerDuty - un service par lequel des alertes sont envoyées aux personnes responsables qui commencent à agir.

Dans ce cas, une erreur s'est produite lors de la promotion d'urgence et, immédiatement après, une alerte a été enregistrée indiquant que le capitaine est tombé. Après cela, l'officier de permanence a vérifié ce qui empêchait la promotion d'urgence et a effectué les opérations manuelles nécessaires.
Nous analyserons certainement chaque incident qui s'est produit, pour chaque incident, nous avons une tâche dans le traqueur de tâches. Même si cet incident est un problème dans nos alertes, nous créons également une tâche, car si le problème est dans la logique et les seuils d'alerte, alors ils doivent être modifiés. Les alertes ne devraient pas simplement gâcher la vie des gens. Une alerte est toujours douloureuse, surtout à 4 heures du matin.
Test
Comme pour la surveillance, je suis sûr que tout le monde teste. En plus des tests unitaires avec lesquels nous couvrons notre code, nous avons des tests d'intégration dans lesquels nous testons:
- toutes les topologies que nous avons;
- toutes les opérations sur ces topologies.
Si nous avons des opérations de promotion, nous testons les opérations de promotion dans le test d'intégration. Si nous avons du clonage, nous faisons du clonage pour toutes les topologies que nous avons.
Exemple de topologie
Nous avons des topologies pour toutes les occasions: 2 centres de données avec plusieurs instances, avec des fragments, pas de fragments, avec des clusters, un centre de données - généralement presque n'importe quelle topologie - même ceux que nous n'utilisons pas, juste pour voir.

Dans ce fichier, nous avons juste les paramètres, quels serveurs et avec ce que nous devons augmenter. Par exemple, nous devons élever le maître, et nous disons que nous devons le faire avec telle ou telle donnée d'instance, avec telle ou telle base de données sur tel ou tel port. Presque tout va de pair avec Bazel, qui crée une topologie à partir de ces fichiers, démarre le serveur MySQL, puis le test démarre.

Le test semble très simple: nous indiquons quelle topologie est utilisée. Dans ce test, nous testons auto_replace.
- Nous créons le service auto_replace, nous le démarrons.
- Nous tuons le maître dans notre topologie, attendons un peu et constatons que l'esclave cible est devenu maître. Sinon, le test a échoué.
Les étapes
Les environnements de scène sont les mêmes bases de données qu'en production, mais il n'y a pas de trafic utilisateur sur eux, mais il y a un trafic synthétique similaire à la production via Percona Playback, sysbench et des systèmes similaires.
Dans Percona Playback, nous enregistrons le trafic, puis nous le perdons dans l'environnement scénique avec différentes intensités, nous pouvons perdre 2-3 fois plus vite. Autrement dit, il est artificiel, mais très proche de la charge réelle.
Cela est nécessaire car dans les tests d'intégration, nous ne pouvons pas tester notre production. Nous ne pouvons pas tester l'alerte ou le fait que les mesures fonctionnent. Au stade des tests, nous testons les alertes, les métriques, les opérations, tuons périodiquement les serveurs et voyons qu'ils sont collectés normalement.
De plus, nous testons toute l'automatisation ensemble, car dans les tests d'intégration, très probablement, une partie du système est testée, et dans la mise en scène, tous les systèmes automatisés fonctionnent simultanément. Parfois, vous pensez que le système se comportera de cette façon et non autrement, mais il peut se comporter de manière complètement différente.
DRT (Disaster Recovery Testing)
Nous effectuons également des tests en production - sur des bases réelles. C'est ce qu'on appelle les tests de récupération après sinistre. Pourquoi en avons-nous besoin?
● Nous voulons tester nos garanties.
Cela est fait par de nombreuses grandes entreprises. Par exemple, Google a un service qui a fonctionné de manière si stable - 100% du temps - que tous les services qui l'ont utilisé ont décidé que ce service était vraiment 100% stable et ne se bloquait jamais. Par conséquent, Google a dû abandonner ce service exprès, afin que les utilisateurs prennent en compte cette possibilité.
Nous sommes donc - nous avons une garantie que MySQL fonctionne - et parfois cela ne fonctionne pas! Et nous avons la garantie que cela peut ne pas fonctionner pendant une certaine période de temps, les clients doivent en tenir compte. De temps en temps, nous tuons le maître de production, ou si nous voulons faire un faylover, nous tuons tous les esclaves pour voir comment se comporte la réplication semi-sync.
● Les clients sont préparés à ces erreurs (remplacement et décès du maître)
Pourquoi est-ce bien? Nous avons eu un cas où lors de la promotion 4 fragments sur 1600, la disponibilité est tombée à 20%. Il semble que quelque chose ne va pas, pour 4 éclats de 1600, il devrait y avoir d'autres nombres. Les basculements pour ce système étaient rares, environ une fois par mois, et tout le monde a décidé: "Eh bien, c'est un basculement, ça arrive."
À un moment donné, lorsque nous sommes passés à un nouveau système, une personne a décidé d'optimiser ces deux services d'enregistrement du rythme cardiaque et de les combiner en un seul. Ce service a fait autre chose et, à la fin, il est mort et les battements de cœur ont cessé d'enregistrer. Il se trouve que pour ce client, nous avions 8 faylovers par jour. Tout reposait - 20% de disponibilité.
Il s'est avéré que chez ce client, la durée de vie est de 6 heures. En conséquence, dès que le maître est décédé, toutes les connexions ont été maintenues pendant 6 heures supplémentaires. Le pool n'a pas pu continuer à fonctionner - ses connexions sont conservées, il est limité et ne fonctionne pas. Il a été réparé.
Nous faisons à nouveau le feylover - non plus 20%, mais encore beaucoup. Quelque chose ne va toujours pas. Il s'est avéré qu'un bug dans l'implémentation du pool. À la demande, le pool s'est tourné vers de nombreux fragments, puis a connecté tout cela. Si certains éclats étaient fébriles, une condition de race s'est produite dans le code Go, et l'ensemble du pool était obstrué. Tous ces fragments ne pouvaient plus fonctionner.
Les tests de récupération après sinistre sont très utiles, car les clients doivent être préparés à ces erreurs, ils doivent vérifier leur code.
● De plus, les tests de reprise après sinistre sont bons car ils ont lieu pendant les heures de bureau et tout est en place, moins de stress, les gens savent ce qui va se passer maintenant. Cela ne se produit pas la nuit et c'est super.
Conclusion
1. Tout doit être automatisé, ne mettez jamais la main dessus.
Chaque fois que quelqu'un monte dans le système avec nos mains, tout meurt et se brise dans notre système - à chaque fois! - même sur des opérations simples. Par exemple, un esclave est décédé, une personne a dû en ajouter une seconde, mais a décidé de retirer l'esclave mort avec ses mains de la topologie. Cependant, au lieu du défunt, il a copié la commande en direct - le maître a été laissé sans esclave du tout. Ces opérations ne doivent pas être effectuées manuellement.
2. Les tests doivent être continus et automatisés (et en production).
Votre système évolue, votre infrastructure évolue. Si vous avez vérifié une fois et que cela a semblé fonctionner, cela ne signifie pas que cela fonctionnera demain. Par conséquent, vous devez constamment effectuer des tests automatisés chaque jour, y compris en production.
3. Assurez-vous de posséder des clients (bibliothèques).
Les utilisateurs peuvent ne pas savoir comment fonctionnent les bases de données. Ils peuvent ne pas comprendre pourquoi des délais d'attente sont nécessaires, garder en vie. Par conséquent, il vaut mieux posséder ces clients - vous serez plus calme.
4. Il est nécessaire de déterminer vos principes de construction du système et vos garanties, et de toujours vous y conformer.
Ainsi, vous pouvez prendre en charge 6 000 serveurs de bases de données.
Dans les questions qui suivent le rapport, et en particulier les réponses, il y a aussi beaucoup d'informations utiles.Q & A
- Que se passera-t-il s'il y a un déséquilibre dans la charge des fragments - certaines méta-informations sur certains fichiers se sont avérées plus populaires? Est-il possible de diffuser ce fragment ou la charge sur les fragments ne diffère nulle part par ordre de grandeur?
Elle ne diffère pas par ordre de grandeur. Il est distribué presque normalement. Nous avons la limitation, c'est-à-dire que nous ne pouvons pas surcharger le fragment en fait, nous limitons au niveau du client. En général, il arrive que certaines étoiles téléchargent une photo et l'éclat explose pratiquement. Ensuite, nous interdisons ce lien
- Vous avez dit que vous aviez 992 alertes. Pourriez-vous préciser ce que c'est - est-il sorti de la boîte ou est-il créé? S'il est créé, s'agit-il d'un travail manuel ou de quelque chose comme l'apprentissage automatique?
Tout est créé manuellement. Nous avons notre propre système interne appelé Vortex, où les mesures sont stockées, les alertes y sont prises en charge. Il existe un fichier yaml qui indique qu'il existe une condition, par exemple, que les sauvegardes doivent être exécutées tous les jours, et si cette condition est remplie, l'alerte ne fonctionne pas. S'il n'est pas exécuté, une alerte arrive.
Il s'agit de notre développement interne, car peu de personnes peuvent stocker autant de métriques que nous en avons besoin.
- Quelle doit être la force des nerfs pour faire du DRT? Vous avez chuté, CODERED, ne monte pas, avec chaque minute de panique de plus.
En général, travailler dans des bases de données est vraiment pénible. Si la base de données se bloque, le service ne fonctionne pas, l'ensemble de Dropbox ne fonctionne pas. C'est vraiment une douleur. DRT est utile car c'est une montre d'affaires. Autrement dit, je suis prêt, je suis assis à mon bureau, j'ai pris un café, je suis frais, je suis prêt à tout.
Pire encore quand cela se produit à 4 heures du matin, et ce n'est pas DRT. Par exemple, le dernier échec majeur que nous avons eu récemment. Lors de l'injection d'un nouveau système, nous avons oublié de définir le score OOM pour notre MySQL. Il y avait un autre service qui lisait binlog. À un moment donné, notre opérateur est manuel - encore une fois manuellement! - exécute la commande pour supprimer certaines informations dans la table de total de contrôle Percona. Juste une simple suppression, une opération simple, mais cette opération a généré un énorme binlog. Le service a lu ce binlog dans la mémoire, OOM Killer est venu et pense qui tuer? Et nous avons oublié de définir le score OOM, et cela tue MySQL!
Nous avons 40 maîtres qui meurent à 4 heures du matin. Quand 40 maîtres meurent, c'est vraiment très effrayant et dangereux. DRT n'est ni effrayant ni dangereux. Nous restons allongés pendant environ une heure.
Soit dit en passant, DRT est un bon moyen de répéter de tels moments afin que nous sachions exactement quelle séquence d'actions est nécessaire si quelque chose se brise en masse.
- Je voudrais en savoir plus sur la commutation maître-maître. Tout d'abord, pourquoi un cluster n'est-il pas utilisé, par exemple? Un cluster de base de données, c'est-à-dire non pas un maître-esclave avec commutation, mais une application maître-maître, de sorte que si l'on tombe, alors ce n'est pas effrayant.
Voulez-vous dire quelque chose comme la réplication de groupe, l'amas de galères, etc.? Il me semble que la candidature de groupe n'est pas encore prête pour la vie. Malheureusement, nous n'avons pas encore essayé Galera. C'est formidable lorsqu'un faylover est à l'intérieur de votre protocole, mais, malheureusement, ils ont tellement d'autres problèmes, et ce n'est pas si facile de passer à cette solution.
- Il semble que dans MySQL 8, il y ait quelque chose comme un cluster InnoDb. N'a pas essayé?
Nous en avons encore 5,6. Je ne sais pas quand nous passerons à 8. Peut-être que nous essaierons.
- Dans ce cas, si vous avez un gros maître, lors du passage de l'un à l'autre, il s'avère que la file d'attente s'accumule sur les serveurs esclaves avec une charge élevée. Si le maître est éteint, est-il nécessaire que la file d'attente atteigne, de sorte que l'esclave passe en mode maître - ou est-ce fait d'une manière ou d'une autre?
La charge sur le maître est régulée par semi-synchronisation. Semisync limite l'enregistrement maître aux performances du serveur esclave. Bien sûr, il se peut que la transaction soit arrivée, la semi-synchronisation a fonctionné, mais les esclaves ont perdu cette transaction pendant très longtemps. Vous devez ensuite attendre jusqu'à ce que l'esclave perde cette transaction jusqu'à la fin.
- Mais alors de nouvelles données viendront à maîtriser, et ce sera nécessaire ...
Lorsque nous démarrons le processus de promotion, nous désactivons les E / S. Après cela, master ne peut rien écrire car la semi-synchronisation est répliquée. La lecture fantôme peut arriver, malheureusement, mais c'est déjà un autre problème.
- Ce sont toutes de belles machines à états - sur quoi sont écrits les scripts et à quel point est-il difficile d'ajouter une nouvelle étape? Que faut-il faire à la personne qui écrit ce système?
Tous les scripts sont écrits en Python, tous les services sont écrits en Go. Telle est notre politique. Changer la logique est facile - juste dans le code Python qui génère le diagramme d'état.
- Et vous pouvez en savoir plus sur les tests. Comment sont écrits les tests, comment déploient-ils les nœuds dans une machine virtuelle - ces conteneurs sont-ils?
Oui Nous allons tester avec l'aide de Bazel. Il existe des fichiers de configuration (json) et Bazel récupère un script qui crée la topologie pour notre test à l'aide de ce fichier de configuration. Différentes topologies y sont décrites.
Tout cela fonctionne pour nous dans les conteneurs Docker: soit cela fonctionne en CI ou sur Devbox. Nous avons un système Devbox. Nous développons tous sur un serveur distant, et cela peut fonctionner, par exemple. Là, il s'exécute également à l'intérieur de Bazel, à l'intérieur d'un conteneur docker ou dans le bac à sable Bazel. Bazel est très compliqué mais amusant.
- Lorsque vous avez créé 4 instances sur un serveur, avez-vous perdu en efficacité mémoire?
Chaque instance est devenue plus petite. Par conséquent, moins MySQL fonctionne avec de la mémoire, plus il est facile à vivre. Tout système est plus facile à utiliser avec une petite quantité de mémoire. En ce lieu, nous n'avons rien perdu. Nous avons les groupes C les plus simples qui limitent ces instances de la mémoire.
- Si vous avez 6 000 serveurs qui stockent des bases de données, pouvez-vous nommer combien de milliards de pétaoctets sont stockés dans vos fichiers?
Ce sont des dizaines d'exaoctets, nous avons versé des données d'Amazon pendant un an.
- Il s'avère qu'au début, vous aviez 8 serveurs, 200 fragments sur eux, puis 400 serveurs avec 4 fragments chacun. Vous avez 1600 fragments - est-ce une sorte de valeur codée en dur? Pouvez-vous plus jamais le refaire? Cela fera-t-il mal si vous avez besoin, par exemple, de 3200 éclats?
Oui, c'était à l'origine 1600. Cela a été fait il y a un peu moins de 10 ans, et nous vivons toujours. Mais nous avons encore 4 éclats - 4 fois nous pouvons encore augmenter l'espace.
- Comment les serveurs meurent, principalement pour quelles raisons? Que se passe-t-il plus souvent, moins souvent, et c'est particulièrement intéressant, des carapteurs de bloc spontanés se produisent-ils?
La chose la plus importante est que les disques s'envolent. Nous avons RAID 0 - le disque est tombé en panne, le maître est mort. C'est le principal problème, mais il nous est plus facile de remplacer ce serveur. Google est plus facile de remplacer le centre de données, nous avons toujours un serveur. Nous n'avons presque jamais eu de somme de contrôle de la corruption. Pour être honnête, je ne me souviens pas quand c'était la dernière fois. Nous mettons souvent à jour l'assistant. Notre durée de vie pour un maître est limitée à 60 jours. Il ne peut pas vivre plus longtemps, après quoi nous le remplaçons par un nouveau serveur, car pour une raison quelconque, quelque chose s'accumule constamment dans MySQL, et après 60 jours, nous voyons que des problèmes commencent à se produire. Peut-être pas dans MySQL, peut-être sous Linux.
Nous ne savons pas quel est ce problème et nous ne voulons pas y faire face.
Nous venons de limiter le délai à 60 jours et de mettre à jour l'intégralité de la pile. Pas besoin de s'en tenir à un seul maître.— , 6 . , JPEG , JPEG, , ? , , - ? — , ?
, . — Dropbox .
— ? ? , , - , , ? , 10 . , 7 , 6 , . ?
Dropbox - , . . , , , - .
, . , , , . - , 6 , , , , .
, facebook youtube- — Highload++ 2018 . , 1 .