
Nous, dans le département d'analyse du cinéma en ligne Okko, aimons automatiser autant que possible le calcul des frais de film d'Alexander Nevsky, et pendant le temps libre pour apprendre de nouvelles choses et mettre en œuvre des choses intéressantes qui, pour une raison quelconque, se traduisent généralement en bots pour Telegram. Par exemple, avant le début de la Coupe du Monde de la FIFA 2018, nous avons déployé un bot sur le chat de travail, qui a collecté des paris sur la distribution des places finales, et après la finale, nous avons calculé les résultats selon une métrique pré-inventée et déterminé les gagnants. La Croatie n'a pas mis quatre dans le top quatre.
Récent temps libre de la compilation des 10 meilleures comédies russes que nous avons consacrées à la création d'un bot qui trouve une célébrité à laquelle l'utilisateur ressemble le plus. Dans le chat de travail, tout le monde a tellement apprécié l'idée que nous avons décidé de rendre le bot accessible au public. Dans cet article, nous rappelons brièvement la théorie, parlons de la création de notre bot et comment le faire vous-même.
Un peu de théorie (surtout en images)
En détail sur la façon dont les systèmes de reconnaissance faciale sont organisés, j'en ai parlé dans l' un de mes articles précédents . Un lecteur intéressé peut suivre le lien, et je décrirai ci-dessous uniquement les principaux points.
Donc, vous avez une photographie sur laquelle peut-être même un visage est montré et vous voulez comprendre de qui il s'agit. Pour ce faire, vous devez suivre 4 étapes simples:
- Sélectionnez le rectangle bordant le visage.
- Mettez en surbrillance les points clés du visage.
- Alignez et recadrez votre visage.
- Convertissez une image de visage en une représentation interprétée par une machine.
- Comparez cette vue avec celles dont vous disposez.
Sélection du visage
Bien que les réseaux de neurones convolutifs aient récemment appris à trouver des visages dans une image pas pire que les méthodes classiques, ils sont toujours inférieurs au HOG classique en termes de vitesse et de facilité d'utilisation.
HOG - Histogrammes de dégradés orientés. Ce gars associe chaque pixel de l'image source à son gradient - un vecteur dans le sens duquel la luminosité des pixels change le plus. L'avantage de cette approche est qu'elle ne se soucie pas des valeurs absolues de la luminosité des pixels, seul leur rapport suffit. Par conséquent, un visage normal, sombre et mal éclairé et bruyant sera affiché dans approximativement le même histogramme de dégradés.
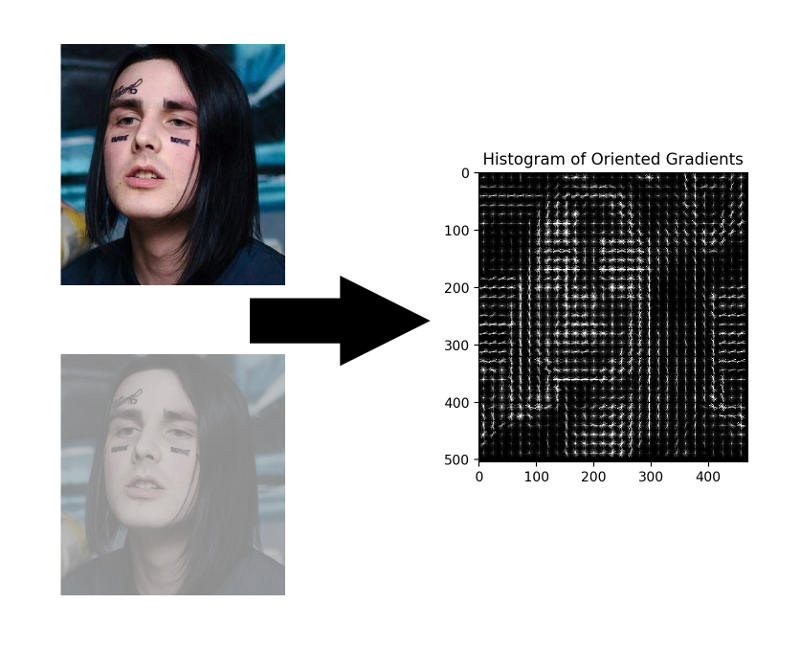
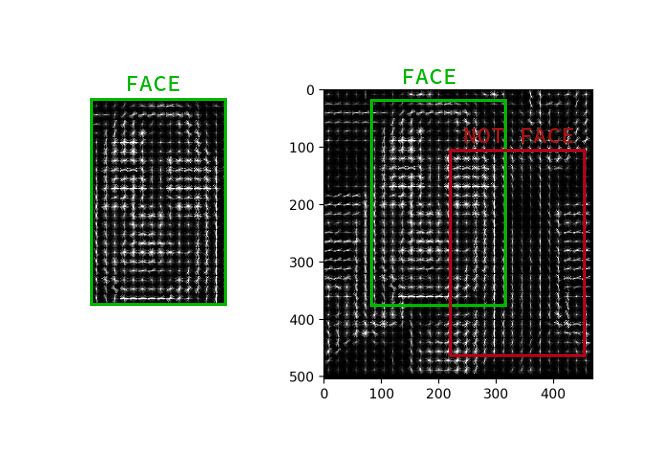
Il n'est pas nécessaire de calculer le gradient pour chaque pixel, il suffit de calculer le gradient moyen pour chaque petit carré n par n . En utilisant le champ vectoriel reçu, vous pouvez ensuite passer par un détecteur avec une fenêtre et déterminer pour chaque fenêtre la probabilité que le visage y soit. Le détecteur peut être SVM, une forêt aléatoire ou autre chose.
Mettre en évidence les points clés

Les points clés sont des points qui aident à identifier une personne dans l'espace. Les scientifiques faibles et peu sûrs ont généralement besoin de 68 points clés, et dans des cas particulièrement négligés, encore plus. Les garçons normaux et confiants, gagnant 300k par seconde, en avaient toujours assez de cinq: les coins intérieurs et extérieurs des yeux et du nez.
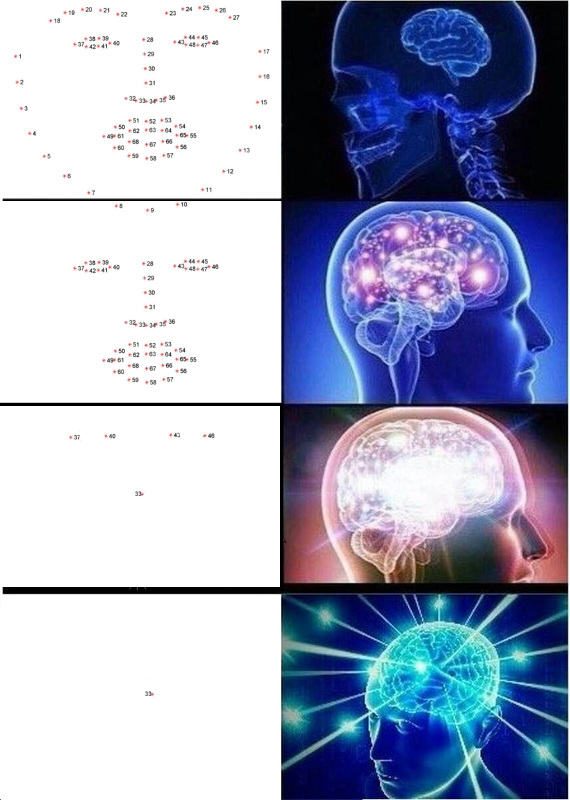
De tels points peuvent être extraits, par exemple, par une cascade de régresseurs .
Alignement du visage
Applications collées dans l'enfance? Ici, tout est exactement le même: vous créez une transformation affine qui traduit trois points arbitraires à leurs positions standard. Le nez peut être laissé tel quel, mais pour que les yeux comptent leurs centres - ce sont les trois points prêts.

Convertir des images de visage en vecteur

Trois ans se sont écoulés depuis la publication de l'article sur FaceNet , pendant ce temps de nombreux programmes de formation et fonctions de perte intéressants sont apparus, mais c'est elle qui domine parmi les solutions OpenSource disponibles. Apparemment, le tout est une combinaison de facilité de compréhension, de mise en œuvre et de résultats décents. Merci au moins pour le fait qu'au cours des trois dernières années, l'architecture a été modifiée pour ResNet.
FaceNet apprend à partir de trois exemples: (ancre, positif, négatif). L'ancre et les exemples positifs appartiennent à une personne, tandis que le négatif est choisi comme le visage d'une autre personne, ce qui, pour une raison quelconque, le réseau est trop proche de la première. La fonction de perte est conçue de manière à corriger ce malentendu, à rassembler les exemples nécessaires et à en supprimer les inutiles.

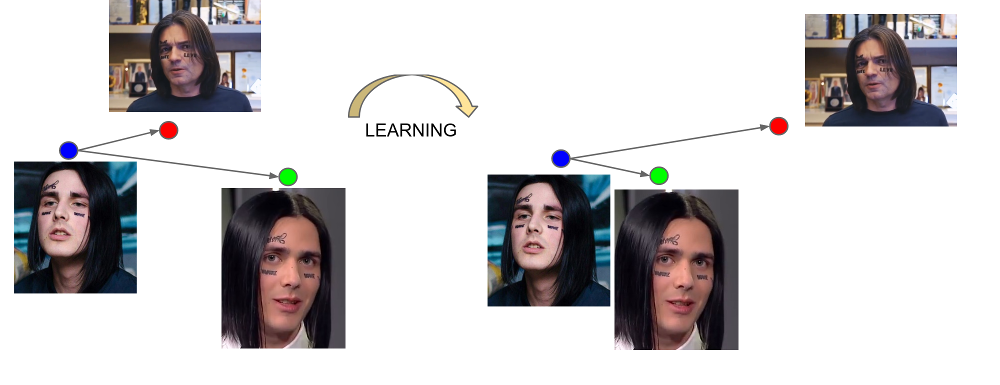
La sortie de la dernière couche du réseau est appelée intégration - une représentation représentative d'une personne dans un certain espace de petite dimension (généralement 128 dimensions).
Comparaison des visages
La beauté des plongements bien entraînés est que les visages d'une personne sont affichés dans un petit voisinage de l'espace, éloigné des incrustations des visages d'autres personnes. Ainsi, pour cet espace, vous pouvez entrer une mesure de similitude, l'inverse de la distance: euclidienne ou cosinus, selon la distance sur laquelle le réseau a été formé.
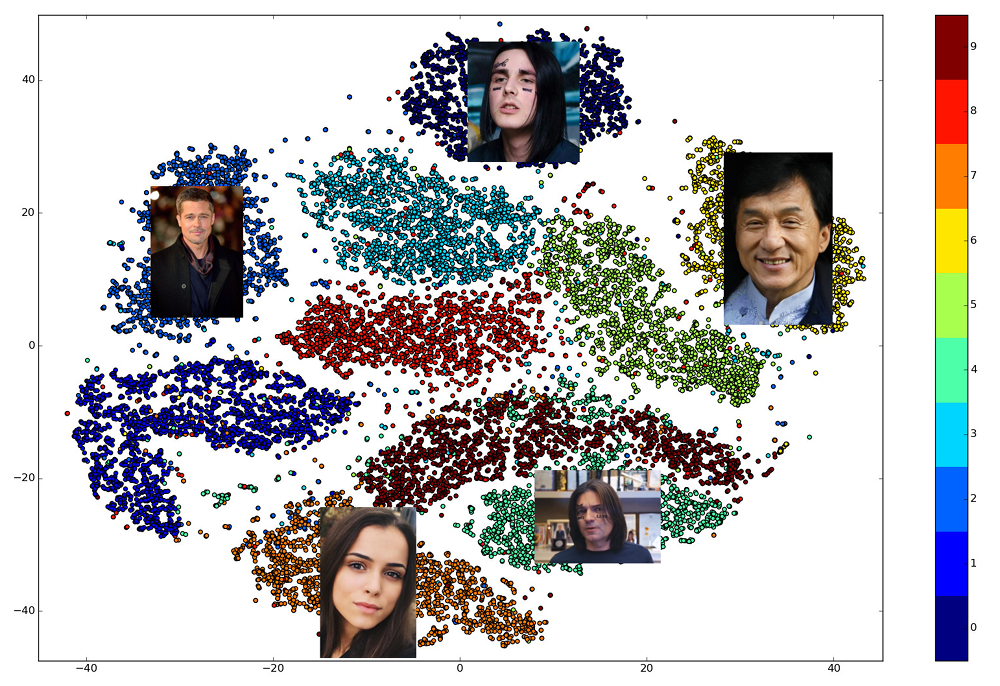
Ainsi, à l'avance, nous devons construire des intégrations pour toutes les personnes parmi lesquelles la recherche sera effectuée, puis, pour chaque demande, trouver le vecteur le plus proche parmi elles. Ou, d'une autre manière, résolvez le problème de trouver k voisins les plus proches, où k peut être égal à un, ou peut-être pas, si nous voulons utiliser une logique métier plus avancée. La personne qui possède le vecteur de résultat sera la plus similaire à la personne de demande.

Quelle bibliothèque utiliser?
Le choix des bibliothèques ouvertes qui implémentent diverses parties du pipeline est excellent. dlib et OpenCV peuvent trouver des visages et des points clés, et des versions pré-formées de réseaux peuvent être trouvées pour n'importe quelle grande infrastructure de réseau neuronal. Il y a un projet OpenFace où vous pouvez choisir l'architecture pour vos exigences de rapidité et de qualité. Mais une seule bibliothèque vous permet d'implémenter les 5 points de reconnaissance faciale dans les appels à trois fonctions de haut niveau: dlib . En même temps, il est écrit en C ++ moderne, utilise BLAS, a un wrapper pour Python, ne nécessite pas de GPU et fonctionne assez rapidement sur un CPU. Notre choix est tombé sur elle.
Faire votre propre bot
Cette section a déjà été décrite dans tous les guides de création de robots, mais une fois que nous aurons écrit la même chose, nous devrons la répéter. Nous écrivons @BotFather et lui demandons un jeton pour notre nouveau bot.
Le jeton ressemble à ceci: 643075690:AAFC8ola8WRdhGbJtzjmkOhne1FGfu1BFg . Il est nécessaire d'obtenir une autorisation à chaque demande adressée à l'API Telegram bot.
J'espère que personne à ce stade n'aura de doutes lors du choix d'un langage de programmation. Bien sûr, vous devez écrire en Haskell. Commençons par le module principal.
import System.Process main :: IO () main = do (_, _, _, handle) <- createProcess (shell "python bot.py") _ <- waitForProcess handle putStrLn "Done!"
Comme vous pouvez le voir dans le code, nous utiliserons à l'avenir une DSL spéciale pour écrire des robots télégrammes. Le code de cette DSL est écrit dans des fichiers séparés. Installez la langue du domaine et tout ce qui est nécessaire.
python -m venv .env source .env/bin/activate pip install python-telegram-bot
python-telegram-bot est actuellement le framework le plus pratique pour créer des bots. Il est facile à apprendre, flexible, évolutif, prend en charge le multithreading. Malheureusement, à l'heure actuelle, il n'y a pas un seul cadre asynchrone normal et des fils anciens doivent être utilisés à la place des coroutines divines.

Démarrer un bot avec python-telegram-bot est facile. Ajoutez le code suivant à bot.py
from telegram.ext import Updater from telegram.ext import MessageHandler, Filters
Exécutez le bot. À des fins de débogage, cela peut être fait avec la python bot.py sans exécuter le code Haskell.
Un tel robot simple est capable de maintenir une conversation minimale et, par conséquent, il peut facilement être organisé pour fonctionner en tant que développeur frontal.
Mais le frontend des développeurs est déjà trop, nous allons donc le tuer dès que possible et procéder à l'implémentation de la fonctionnalité principale. Par souci de simplicité, notre bot ne répondra qu'aux messages contenant des photos et ignorera les autres. Modifiez le code comme suit.
from telegram.ext import Updater from telegram.ext import MessageHandler, Filters
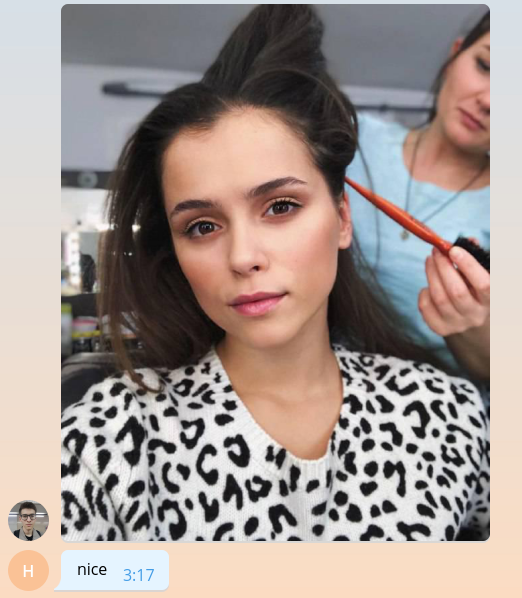
Lorsque l'image entre dans le serveur Telegram, elle est automatiquement ajustée à plusieurs tailles prédéterminées. Le bot, à son tour, peut télécharger une image de n'importe quelle taille parmi celles contenues dans la liste message.photo triée par ordre croissant. L'option la plus simple: prendre la plus grande image. Bien sûr, dans un environnement d'épicerie, vous devez penser à la charge du réseau et au temps de chargement et choisir une image de la taille minimale appropriée. Ajoutez le code de téléchargement d'image en haut de la fonction handle_photo .
import io
message = update.message photo = message.photo[~0] with io.BytesIO() as fd: file_id = bot.get_file(photo.file_id) file_id.download(out=fd) fd.seek(0)
L'image a été téléchargée et est en mémoire. Pour l'interpréter et le présenter sous la forme d'une matrice d'intensité de pixels, nous utilisons les bibliothèques Pillow et numpy .
from PIL import Image import numpy as np
Le code suivant doit être ajouté au bloc with .
image = Image.open(fd) image.load() image = np.asarray(image)
Le temps est venu dlib. En dehors de la fonction, créez un détecteur de visage.
import dlib
face_detector = dlib.get_frontal_face_detector()
Et à l'intérieur de la fonction, nous l'utilisons.
face_detects = face_detector(image, 1)
Le deuxième paramètre de la fonction signifie le grossissement qui doit être appliqué avant de tenter de détecter les visages. Plus il est grand, plus les visages seront petits et complexes que le détecteur pourra détecter, mais plus il fonctionnera longtemps. face_detects - une liste de visages triés par ordre décroissant de la confiance du détecteur que le visage est devant lui. Dans une application réelle, vous voudrez probablement appliquer une logique de choix de la personne principale, et dans l'étude de cas, nous nous limiterons à choisir la première.
if not face_detects: bot.send_message(chat_id=update.message.chat_id, text='no faces') face = face_detects[0]
Nous passons à l'étape suivante - la recherche de points clés. Téléchargez le modèle entraîné et déplacez sa charge en dehors de la fonction.
shape_predictor = dlib.shape_predictor('path/to/shape_predictor_5_face_landmarks.dat')
Trouvez les points clés.
landmarks = shape_predictor(image, face)
La seule chose qui reste est petite: pour redresser le visage, le conduire à travers ResNet et obtenir une intégration à 128 dimensions. Heureusement, dlib vous permet de faire tout cela en un seul appel. Il vous suffit de télécharger le modèle pré-formé .
face_recognition_model = dlib.face_recognition_model_v1('path/to/dlib_face_recognition_resnet_model_v1.dat')
embedding = face_recognition_model.compute_face_descriptor(image, landmarks) embedding = np.asarray(embedding)
Il suffit de regarder dans quelle merveilleuse période nous vivons. Toute la complexité des réseaux de neurones convolutifs, la méthode des vecteurs de support et les transformations affines appliquées à la reconnaissance faciale sont encapsulées dans trois appels de bibliothèque.
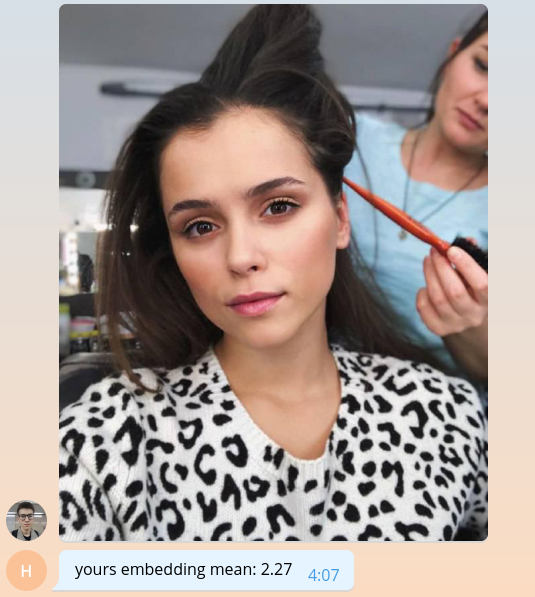
Puisque nous ne savons pas encore faire quoi que ce soit de significatif, rendons à l'utilisateur la valeur moyenne de son intégration, multipliée par mille.
bot.send_message( chat_id=update.message.chat_id, text=f'yours embedding mean: {embedding.mean() * 1e3:.2f}' )
Pour que notre bot puisse déterminer à quelles célébrités les utilisateurs ressemblent, nous devons maintenant trouver au moins une photo de chaque célébrité, construire une intégration sur elle et l'enregistrer quelque part. Nous ajouterons seulement 10 célébrités à notre bot de formation, trouvant leurs photos à la main et les mettant dans le répertoire des photos . Voici à quoi cela devrait ressembler:
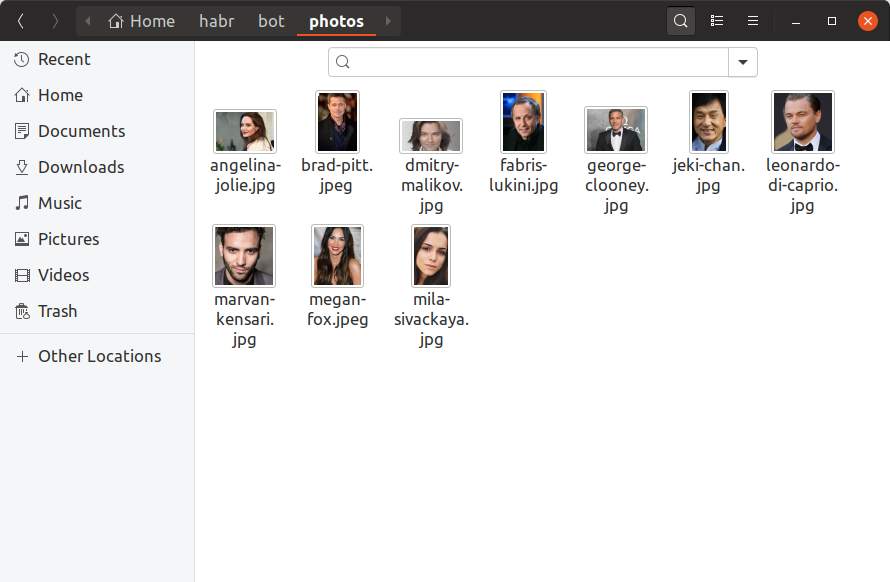
Si vous voulez avoir un million de célébrités dans la base de données, tout se ressemblera exactement, seulement il y a plus de fichiers et il est peu probable que vous puissiez les rechercher avec vos mains. build_embeddings.py utilitaire build_embeddings.py utilisant les appels dlib que nous connaissons déjà et enregistrons les incorporations de célébrités avec leurs noms au format binaire.
import os import dlib import numpy as np import pickle from PIL import Image face_detector = dlib.get_frontal_face_detector() shape_predictor = dlib.shape_predictor('assets/shape_predictor_5_face_landmarks.dat') face_recognition_model = dlib.face_recognition_model_v1('assets/dlib_face_recognition_resnet_model_v1.dat') fs = os.listdir('photos') es = [] for f in fs: print(f) image = np.asarray(Image.open(os.path.join('photos', f))) face_detects = face_detector(image, 1) face = face_detects[0] landmarks = shape_predictor(image, face) embedding = face_recognition_model.compute_face_descriptor(image, landmarks, num_jitters=10) embedding = np.asarray(embedding) name, _ = os.path.splitext(f) es.append((name, embedding)) with open('assets/embeddings.pickle', 'wb') as f: pickle.dump(es, f)
Ajoutez le chargement intégré à notre code bot.
import pickle
with open('assets/embeddings.pickle', 'rb') as f: star_embeddings = pickle.load(f)
Et grâce à une recherche exhaustive, nous découvrirons à quoi ressemble notre utilisateur.
ds = [] for name, emb in star_embeddings: distance = np.linalg.norm(embedding - emb) ds.append((name, distance)) best_match, best_distance = min(ds, key=itemgetter(1)) bot.send_message( chat_id=update.message.chat_id, text=f'your look exactly like *{best_match}*', parse_mode='Markdown' )
Veuillez noter que nous utilisons la distance euclidienne comme distance, car le réseau de dlib a été formé précisément avec l'aide de celui-ci.

C'est tout, félicitations! Nous avons créé un bot simple qui peut déterminer la célébrité de l'utilisateur. Il reste à trouver plus de photos, ajouter une image de marque, une évolutivité, une pincée de journalisation et tout peut être publié en production. Tous ces sujets sont trop volumineux pour être abordés en détail avec d'énormes listes de codes. Je vais donc simplement décrire les principaux points du format question-réponse dans la section suivante.
Le code bot de formation complet est disponible sur GitHub .
On parle de notre bot
Combien de célébrités avez-vous dans votre base de données? Où les avez-vous trouvés?
La décision la plus logique lors de la création du bot semblait prendre des données sur les célébrités de notre base de contenu interne. Dans le format du graphique, elle stocke les films et toutes les entités associées aux films, y compris les acteurs et les réalisateurs. Pour chaque personne, nous connaissons son nom, son identifiant et son mot de passe d'iCloud, des films et alias associés, qui peuvent être utilisés pour générer des liens vers le site. Après avoir nettoyé et extrait uniquement les informations nécessaires, le fichier json reste le suivant:
[ { "name": " ", "alias": "tilda-swinton", "role": "actor", "n_movies": 14 }, { "name": " ", "alias": "michael-shannon", "role": "actor", "n_movies": 22 }, ... ]
Il y avait 22 000 entrées de ce type dans le catalogue. Soit dit en passant, pas un catalogue, mais un catalogue.
Où trouver des photos pour toutes ces personnes?

Eh bien, tu sais, ici et là . Il y a, par exemple, une merveilleuse bibliothèque qui vous permet de télécharger des résultats de recherche d'images depuis Google. 22 mille personnes - pas tellement, en utilisant 56 flux, nous avons réussi à télécharger des photos pour eux en moins d'une heure.
Parmi les photos téléchargées, vous devez jeter les photos cassées, bruyantes, au mauvais format. Ne laissez ensuite que ceux où il y a des visages et où ces visages remplissent certaines conditions: la distance minimale entre les yeux, l'inclinaison de la tête. Tout cela nous laisse avec 12 000 photos.
Sur les 12 000 célébrités, les utilisateurs n'en ont trouvé que 2 pour le moment, c'est-à-dire qu'il y a environ 8 000 célébrités qui ne ressemblent à personne. Ne le laissez pas comme ça! Ouvrez des télégrammes et trouvez-les tous.
Comment déterminer le pourcentage de similitude pour la distance euclidienne?
Grande question! En effet, la distance euclidienne, contrairement au cosinus, n'est pas bornée ci-dessus. Par conséquent, une question raisonnable se pose, comment montrer à l'utilisateur quelque chose de plus significatif que "Félicitations, la distance entre votre intégration et l'intégration d'Angelina Jolie est de 0,27635462738"? Un des membres de notre équipe a proposé la solution simple et ingénieuse suivante. Si vous construisez la distribution des distances entre les encastrements, ce sera normal. Donc, pour lui, vous pouvez calculer la moyenne et l'écart-type, puis pour chaque utilisateur, en fonction de ces paramètres, considérez combien de pour cent des gens ressemblent moins à leurs célébrités que lui . Cela équivaut à intégrer une fonction de densité de probabilité de d à plus l'infini, où d est la distance entre l'utilisateur et les célébrités.
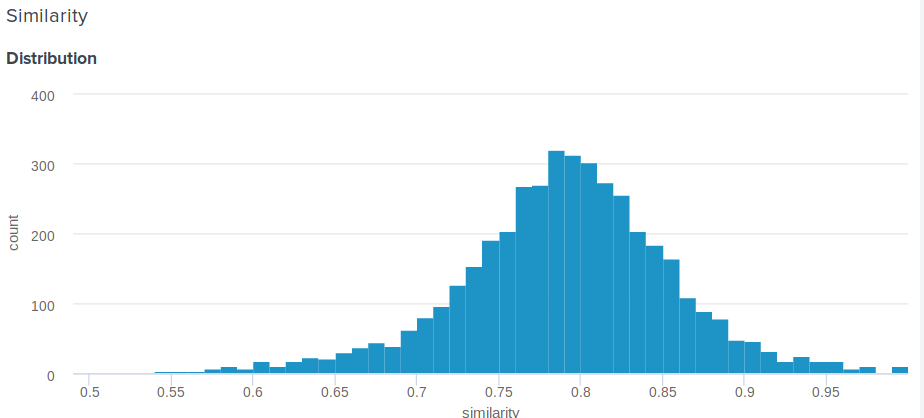
Voici la fonction exacte que nous utilisons:
def _transform_dist_to_sim(self, dist): p = 0.5 * (1 + erf((dist - self._dist_mean) / (self._dist_std * 1.4142135623730951))) return max(min(1 - p, 1.0), self._min_similarity)
Est-il vraiment nécessaire de parcourir la liste de tous les syndicats afin de trouver une correspondance?
Bien sûr que non, ce n'est pas optimal et prend beaucoup de temps. La façon la plus simple d'optimiser les calculs est d'utiliser des opérations matricielles. Au lieu de soustraire les vecteurs les uns des autres, vous pouvez en composer une matrice et soustraire un vecteur de la matrice, puis calculer la norme L2 en lignes.
scores = np.linalg.norm(emb - embeddings, axis=1) best_idx = scores.argmax()
Cela donne déjà une énorme augmentation de la productivité, mais il s'avère que vous pouvez encore plus rapidement. La recherche peut être considérablement accélérée en perdant un peu de sa précision à l'aide de la bibliothèque nmslib . Il utilise la méthode HNSW pour approximer la recherche de k voisins les plus proches. Pour tous les vecteurs disponibles, un soi-disant index doit être construit, dans lequel ensuite une recherche sera effectuée. Vous pouvez créer et enregistrer l'index pour la distance euclidienne comme suit:
import nmslib index = nmslib.init(method='hnsw', space='l2', data_type=nmslib.DataType.DENSE_VECTOR) for idx, emb in enumerate(embeddings): index.addDataPoint(idx, emb) index_time_params = { 'indexThreadQty': 4, 'skip_optimized_index': 0, 'post': 2, 'delaunay_type': 1, 'M': 100, 'efConstruction': 2000 } index.createIndex(index_time_params, print_progress=True) index.saveIndex('./assets/embeddings.bin')
Les paramètres M et efConstruction sont décrits en détail dans la documentation et sont sélectionnés expérimentalement en fonction de la précision requise, du temps de construction de l'index et de la vitesse de recherche. Avant d'utiliser l'index, vous devez télécharger:
index = nmslib.init(method='hnsw', space='l2', data_type=nmslib.DataType.DENSE_VECTOR) index.loadIndex('./assets/embeddings.bin') query_time_params = {'efSearch': 400} index.setQueryTimeParams(query_time_params)
Le paramètre efSearch affecte la précision et la vitesse des requêtes et peut ne pas correspondre à efConstruction . Vous pouvez maintenant faire des demandes.
ids, dists = index.knnQuery(embedding, k=1) best_dx = ids[0] best_dist = dists[0]
Dans notre cas, nmslib est 20 fois plus rapide que la version linéaire vectorisée, et une demande est traitée en moyenne 0.005 seconde.
Comment préparer mon bot pour la production?
1. Asynchronie
Tout d'abord, vous devez rendre la fonction handle_photo asynchrone. Comme je l'ai déjà dit, python-telegram-bot propose le multithreading pour cela et implémente un décorateur pratique.
from telegram.ext.dispatcher import run_async @run_async def handle_photo(bot, update): ...
Maintenant, le framework lui-même lancera votre gestionnaire dans un thread séparé dans son pool. La taille du pool est définie lors de la création du programme de mise à jour. "Mais en python, il n'y a pas de multithreading!" s'exclament déjà les plus impatients d'entre vous. Et ce n'est pas tout à fait vrai. En raison du GIL, le code Python ordinaire ne peut vraiment pas être exécuté en parallèle, mais le GIL est publié pour attendre toutes les opérations d'E / S, et il peut également être publié par les bibliothèques qui utilisent des extensions C.
Analysons maintenant notre fonction handle_photo : elle consiste simplement à attendre les opérations d'E / S (télécharger une photo, envoyer une réponse, lire une photo à partir du disque, etc.) et appeler les fonctions des numpy , nmslib et Pillow .
Je n'ai pas mentionné dlib pour une raison. La bibliothèque qui appelle le code natif n'est pas nécessaire pour libérer le GIL et dlib ce droit. Elle n'a pas besoin de cette serrure, elle ne la laisse pas partir. L'auteur dit qu'il acceptera volontiers la Pull Request appropriée, mais je suis trop paresseux.
2. Multiprocessing
Le moyen le plus simple de gérer dlib consiste à encapsuler le modèle dans une entité distincte et à l'exécuter dans un processus distinct. Et mieux dans le pool de processus.
def _worker_initialize(config): global model model = Model(config) model.load_state() def _worker_do(image): return model.process_image(image) pool = multiprocessing.Pool(8, initializer=_worker_initialize, initargs=(config,))
result = pool.apply(_worker_do, (image,))
3. Fer
Si votre bot a besoin de lire constamment les photos d'un disque, assurez-vous que le disque est un SSD. Ou même les monter dans la RAM. Le ping vers les serveurs de télégrammes et la qualité des canaux sont également importants.
4. Contrôle des inondations
Les télégrammes ne permettent pas aux bots d'envoyer plus de 30 messages par seconde. Si votre bot est populaire et que beaucoup de gens l'utilisent en même temps, il est très facile d'intercepter une interdiction pendant quelques secondes, ce qui se transformera en déception par rapport aux attentes de nombreux utilisateurs. Pour résoudre ce problème, python-telegram-bot nous propose une file d'attente qui ne peut pas envoyer plus que la limite de messages spécifiée par seconde, en maintenant des intervalles égaux entre les envois.
from telegram.ext.messagequeue import MessageQueue
Pour l'utiliser, vous devez définir votre propre bot et le remplacer lors de la création de Updater .
from telegram.utils.promise import Promise class MQBot(Bot): def __init__(self, *args, **kwargs): super().__init__(*args, **kwargs) self._message_queue = MessageQueue( all_burst_limit=30, all_time_limit_ms=1000 ) def __del__(self): try: self._message_queue.stop() finally: super().__del__() def send_message(self, *args, **kwargs): is_group = kwargs.get('chat_id', 0) >= 0 return self._message_queue(Promise(super().send_message, args, kwargs), is_group)
bot = MQBot(token=TOKEN) updater = Updater(bot=bot)
5. Crochets Web
Dans un environnement de produit, les Web Hooks doivent toujours être utilisés au lieu de l'interrogation longue pour recevoir des mises à jour des serveurs Telegram. De quoi s'agit-il et comment l'utiliser peut être lu ici .
6. Anecdotes
json . , ultrajson .
IO-: , , . , .
6.
, . , , , . , .
, , BI-tool Splunk .
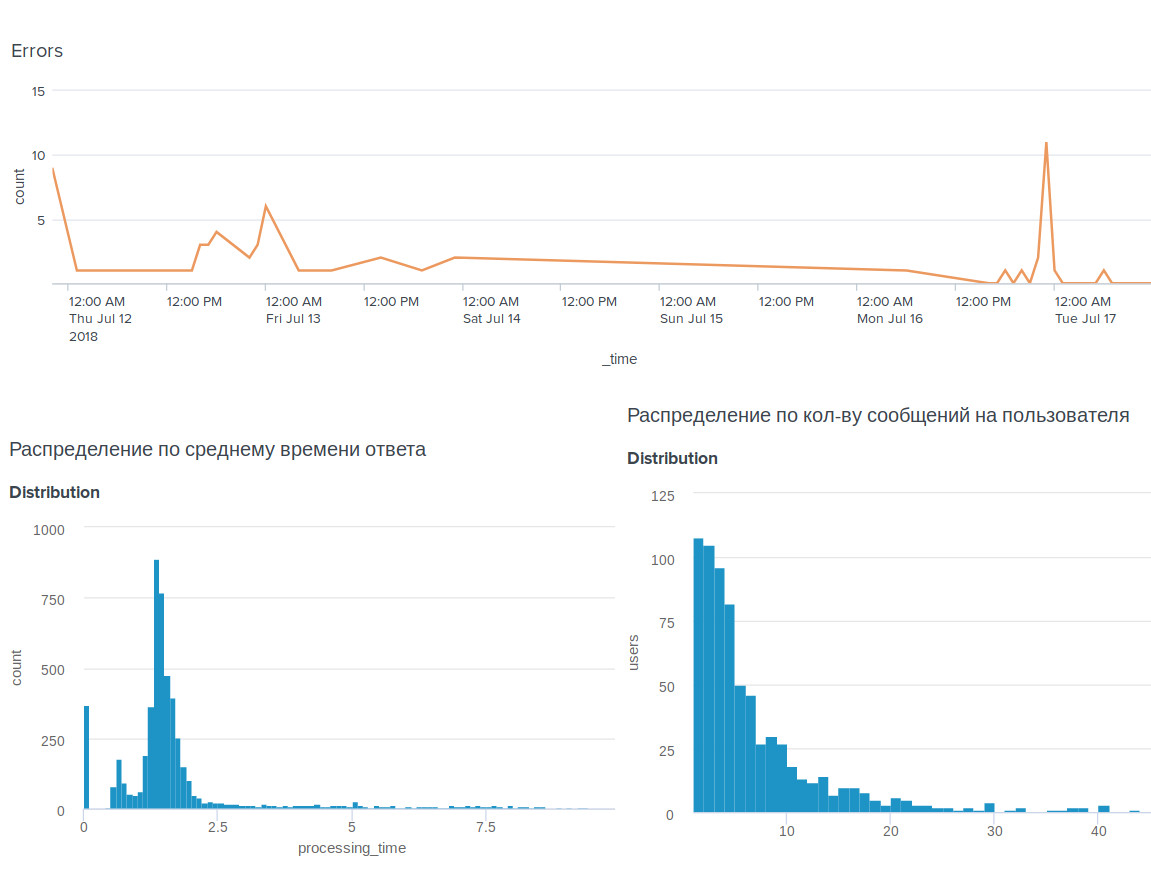
, . , .
, . , : @OkkoFaceBot .