Avant que le code que nous avons écrit soit exécuté, il va assez loin.
Andrey Melikhov dans son rapport sur RIT ++ 2018 a examiné chaque étape de ce chemin en utilisant l'exemple du moteur V8. Entrez sous le chat pour découvrir ce qui nous donne une compréhension approfondie des principes du compilateur et comment rendre le code JavaScript plus productif.

Nous verrons si WASM est une solution miracle pour améliorer les performances du code et si les optimisations sont toujours justifiées.
Spoiler: «L'optimisation prématurée est la racine de tous les maux», Donald Knuth.
 À propos de l'orateur:
À propos de l'orateur: Andrei Melikhov travaille chez Yandex.Money, écrit activement sur Node.js, et moins dans le navigateur, donc le serveur JavaScript est plus proche de lui. Andrew prend en charge et développe la communauté devShacht, alors consultez
GitHub ou
Medium .
Motivation et glossaire
Aujourd'hui, nous allons parler de la compilation JIT. Je pense que cela vous intéresse, puisque vous lisez ceci. Cependant, clarifions pourquoi vous devez savoir ce qu'est JIT et comment fonctionne V8, et pourquoi écrire React dans un navigateur n'est pas suffisant.
- Vous permet d'écrire du code plus efficace , car notre langage est spécifique.
- Il révèle des énigmes pour lesquelles dans les bibliothèques d'autres personnes le code est écrit de cette façon, et non autrement. Parfois, nous rencontrons d'anciennes bibliothèques et voyons ce qui y est écrit est quelque peu étrange, mais si c'est nécessaire, ce n'est pas nécessaire - ce n'est pas clair. Lorsque vous savez comment cela fonctionne, vous comprenez pourquoi cela a été fait.
- C'est juste intéressant . De plus, cela nous permet de comprendre ce qu'Axel Rauschmeier, Benedict Moyrer et Dan Abramov communiquent sur Twitter.
Wikipedia dit que JavaScript est un langage de programmation interprété de haut niveau avec une frappe dynamique. Nous traiterons ces conditions.
Compilation et interprétationCompilation - lorsque le programme est livré en code binaire et est initialement optimisé pour l'environnement dans lequel il fonctionnera.
Interprétation - lorsque nous livrons le code tel quel.
JavaScript est livré tel quel - c'est un langage interprété, tel qu'écrit sur Wikipedia.
Typage dynamique et statiqueLe typage statique et dynamique est souvent confondu avec un typage faible et fort. Par exemple, C est un langage avec un typage faible statique. JavaScript a un typage dynamique faible.
Lequel est le meilleur? Si le programme compile, il est orienté vers l'environnement dans lequel il sera exécuté, ce qui signifie qu'il fonctionnera mieux. La frappe statique rend ce code plus efficace. En JavaScript, l'inverse est vrai.
Mais en même temps, notre application devient plus complexe: à la fois sur le client et sur le serveur, d'énormes clusters apparaissent sur Node.js, qui fonctionnent très bien et viennent remplacer les applications Java.
Mais comment tout cela fonctionne-t-il s'il semble initialement être un perdant.
JIT va réconcilier tout le monde! Ou du moins essayez.
Nous avons une JIT (compilation Just In Time) qui se produit au moment de l'exécution. Nous parlerons d'elle.
Moteurs Js
- Chakra non aimé, qui se trouve dans Internet Explorer. Cela ne fonctionne même pas avec JavaScript, mais avec Jscript - il existe un tel sous-ensemble.
- Chakra moderne et ChakraCore qui fonctionnent dans Edge;
- SpiderMonkey dans FireFox;
- JavaScriptCore dans WebKit. Il est également utilisé dans React Native. Si vous avez une application RN pour Android, elle fonctionne également sur JavaScriptCore - le moteur est fourni avec l'application.
- Le V8 est mon préféré. Ce n'est pas le meilleur, je travaille juste avec Node.js, dans lequel c'est le moteur principal, comme dans tous les navigateurs basés sur Chrome.
- Rhino et Nashorn sont les moteurs utilisés en Java. Avec leur aide, vous pouvez également y exécuter JavaScript.
- JerryScript - pour les appareils intégrés;
- et d'autres ...
Vous pouvez écrire votre propre moteur, mais si vous vous dirigez vers une exécution efficace, vous arriverez à peu près au même schéma, que je montrerai plus tard.
Aujourd'hui, nous allons parler du V8, et oui, il porte le nom du moteur 8 cylindres.
On grimpe sous le capot
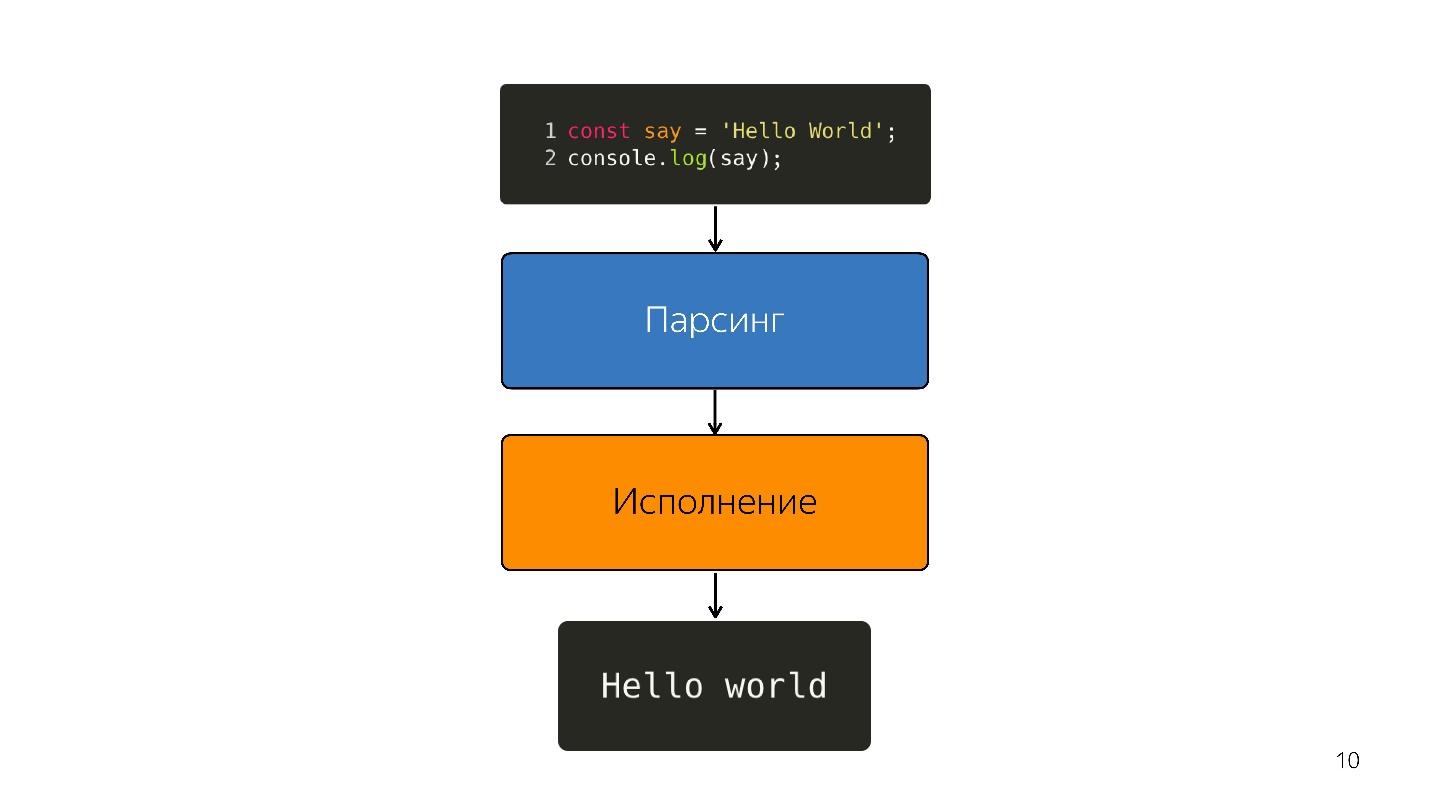
Comment est exécuté javascript?
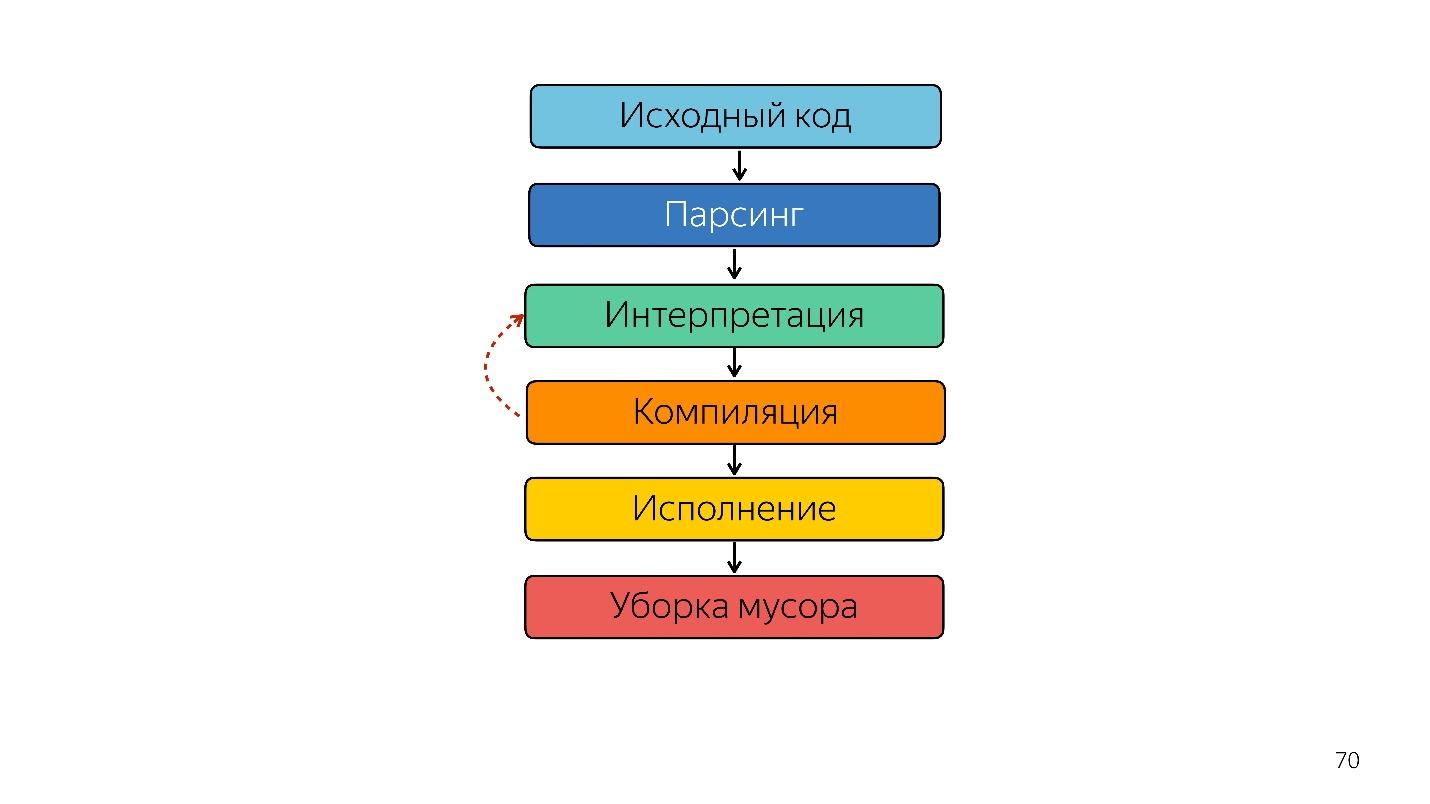
- Il y a du code écrit en JavaScript, qui est fourni.
- il analyse;
- est en cours d'exécution;
- le résultat est obtenu.
L'analyse transforme le code en une
arborescence de syntaxe abstraite . AST est un affichage de la structure syntaxique du code sous la forme d'un arbre. C'est en fait pratique pour le programme, bien qu'il soit difficile à lire.
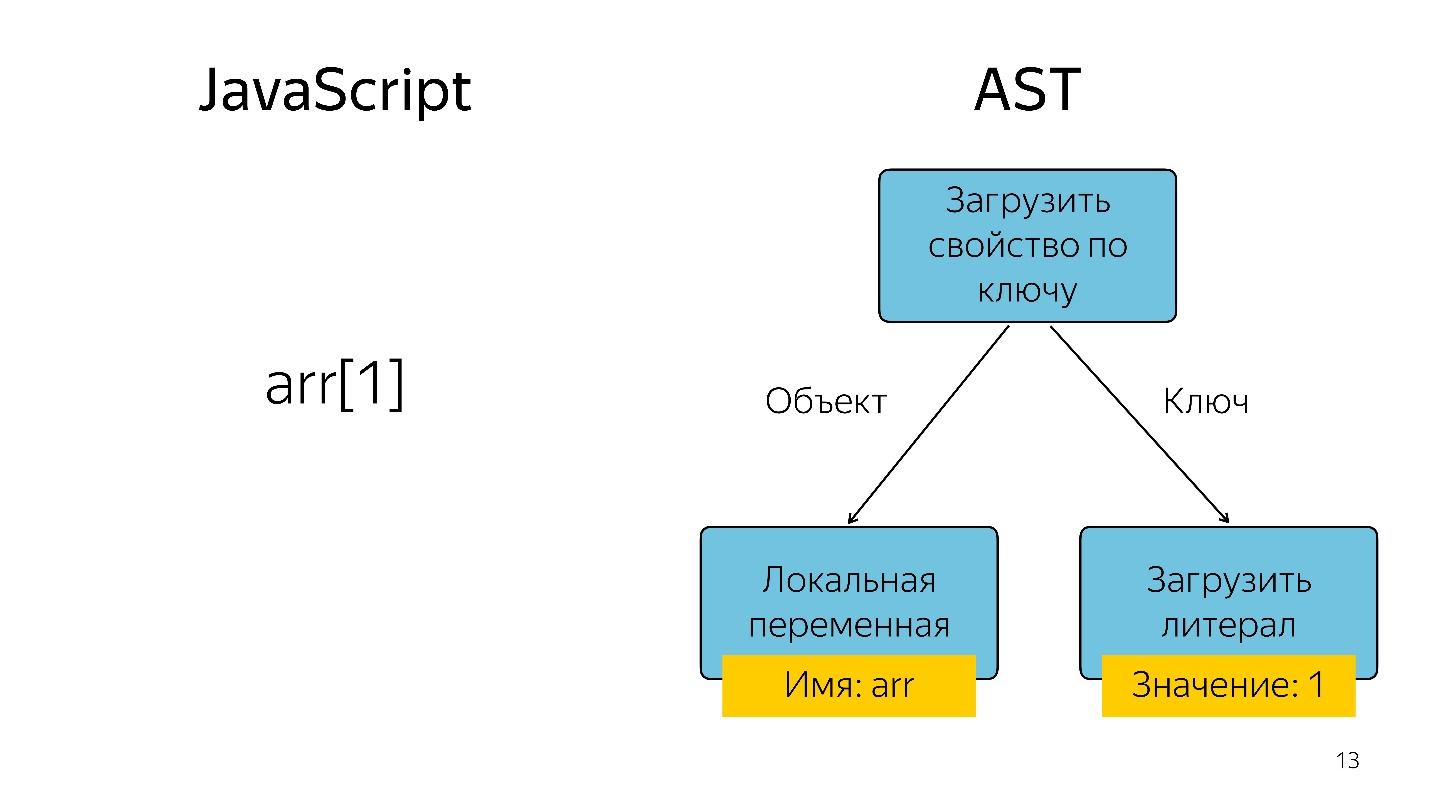
Obtenir un élément de tableau avec l'index 1 sous la forme d'une arborescence est représenté comme un opérateur et deux opérandes: chargez la propriété par clé et ces clés.
Où l'AST est-il utilisé?
AST n'est pas seulement dans les moteurs. À l'aide d'AST, de nombreux utilitaires écrivent des extensions, notamment:
- ESLint;
- Babel;
- Plus joli
- Jscodeshift.
Par exemple, le truc sympa Jscodeshift, dont tout le monde n'est pas encore au courant, vous permet d'écrire des transformations. Si vous modifiez l'API d'une fonction, vous pouvez y définir ces transformations et apporter des modifications à l'ensemble du projet.

Nous continuons. Le processeur ne comprend pas l'arborescence de syntaxe abstraite; il a besoin d'
un code machine . Par conséquent, une transformation supplémentaire a lieu via l'interpréteur, car la langue est interprétée.
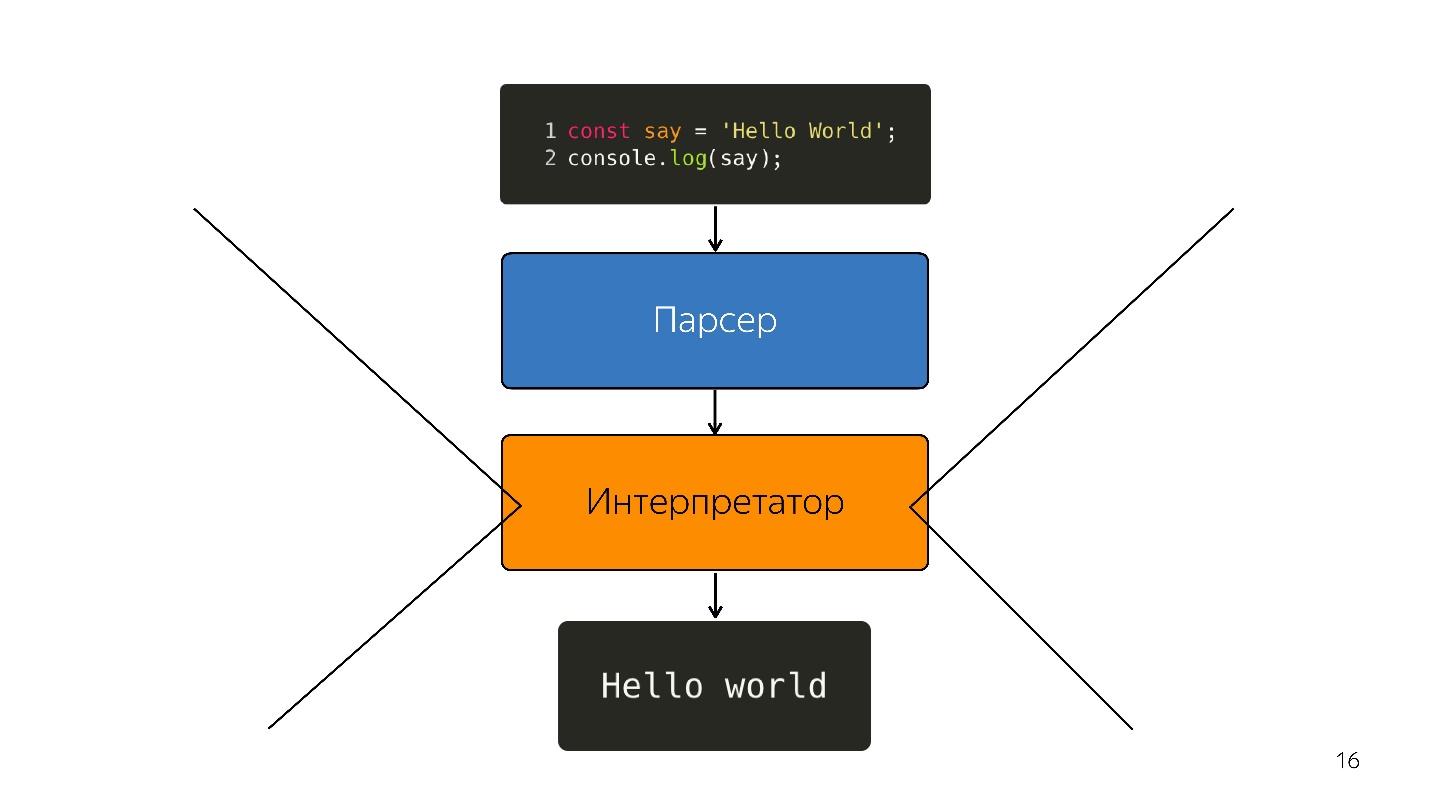
Il en était ainsi, alors que les navigateurs avaient un peu de JavaScript - mettez la ligne en surbrillance, ouvrez quelque chose, fermez. Mais maintenant, nous avons des applications - SPA, Node.js et l'
interpréteur devient un goulot d'étranglement .
Optimisation du compilateur JIT
Au lieu d'un interpréteur, un compilateur JIT d'optimisation apparaît, c'est-à-dire un compilateur juste à temps. Les compilateurs avancés travaillent avant l'exécution de l'application et JIT - pendant. Sur le problème d'optimisation, le compilateur JIT essaie de deviner comment le code sera exécuté, quels types seront utilisés et optimiser le code pour qu'il fonctionne mieux.
Une telle optimisation est appelée
spéculative , car elle spécule sur la connaissance de ce qui est arrivé au code auparavant. Autrement dit, si quelque chose avec le type de numéro a été appelé 10 fois, le compilateur pense que cela se produira tout le temps et optimise pour ce type.
Naturellement, si Boolean entre en entrée, la désoptimisation se produit. Prenons une fonction qui ajoute des nombres.
const foo=(a, b) => a + b;
foo (1, 2);
foo (2, 3);Plié une fois, la deuxième fois. Le compilateur construit la prédiction: "Ce sont des nombres, j'ai une solution sympa pour ajouter des nombres!" Et vous écrivez
foo('WTF', 'JS') , et passez les lignes à la fonction - nous avons JavaScript, nous pouvons ajouter une ligne avec un nombre.
À ce stade, la désoptimisation se produit.
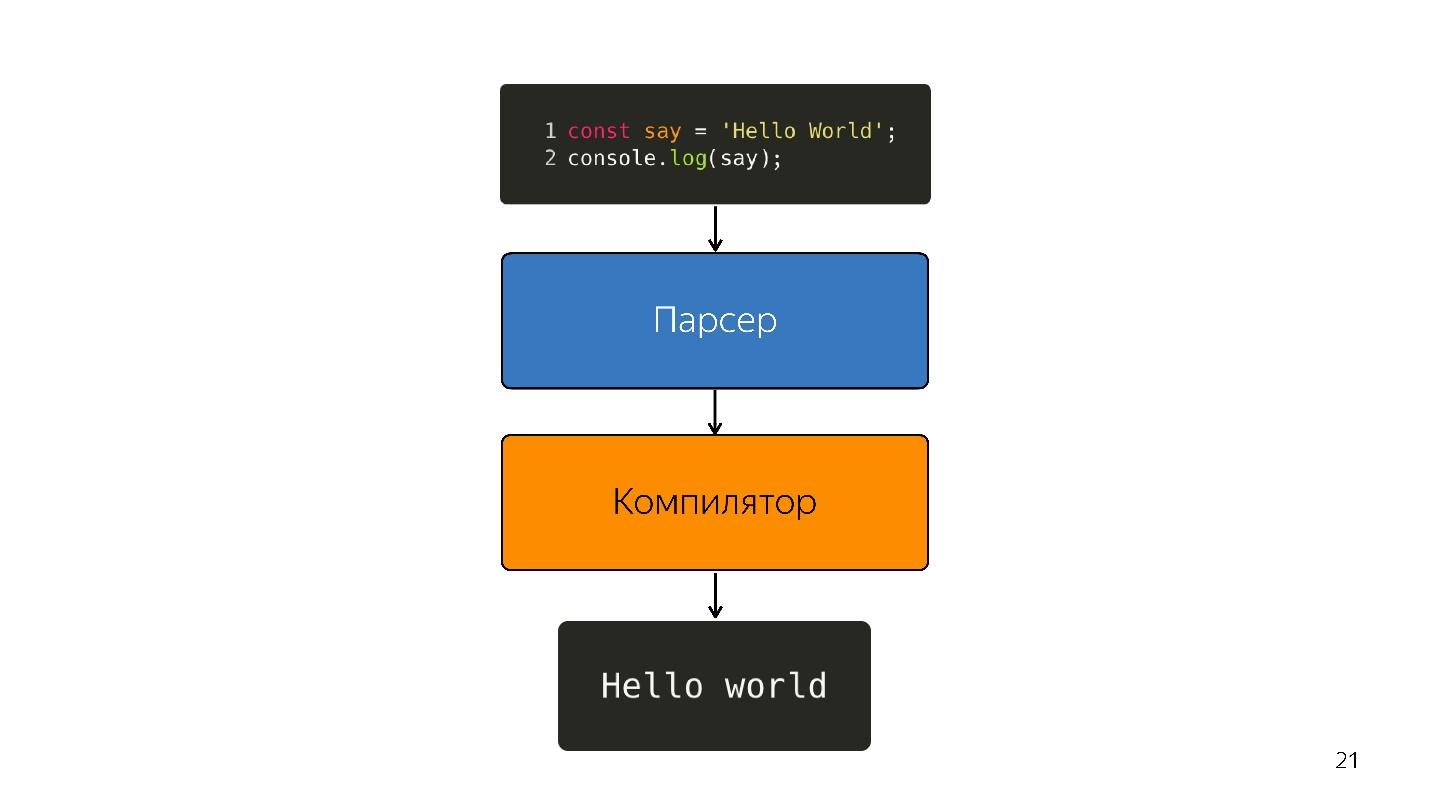
Ainsi, l'interpréteur a été remplacé par le compilateur. Le diagramme ci-dessus semble avoir un pipeline très simple. En réalité, tout est un peu différent.
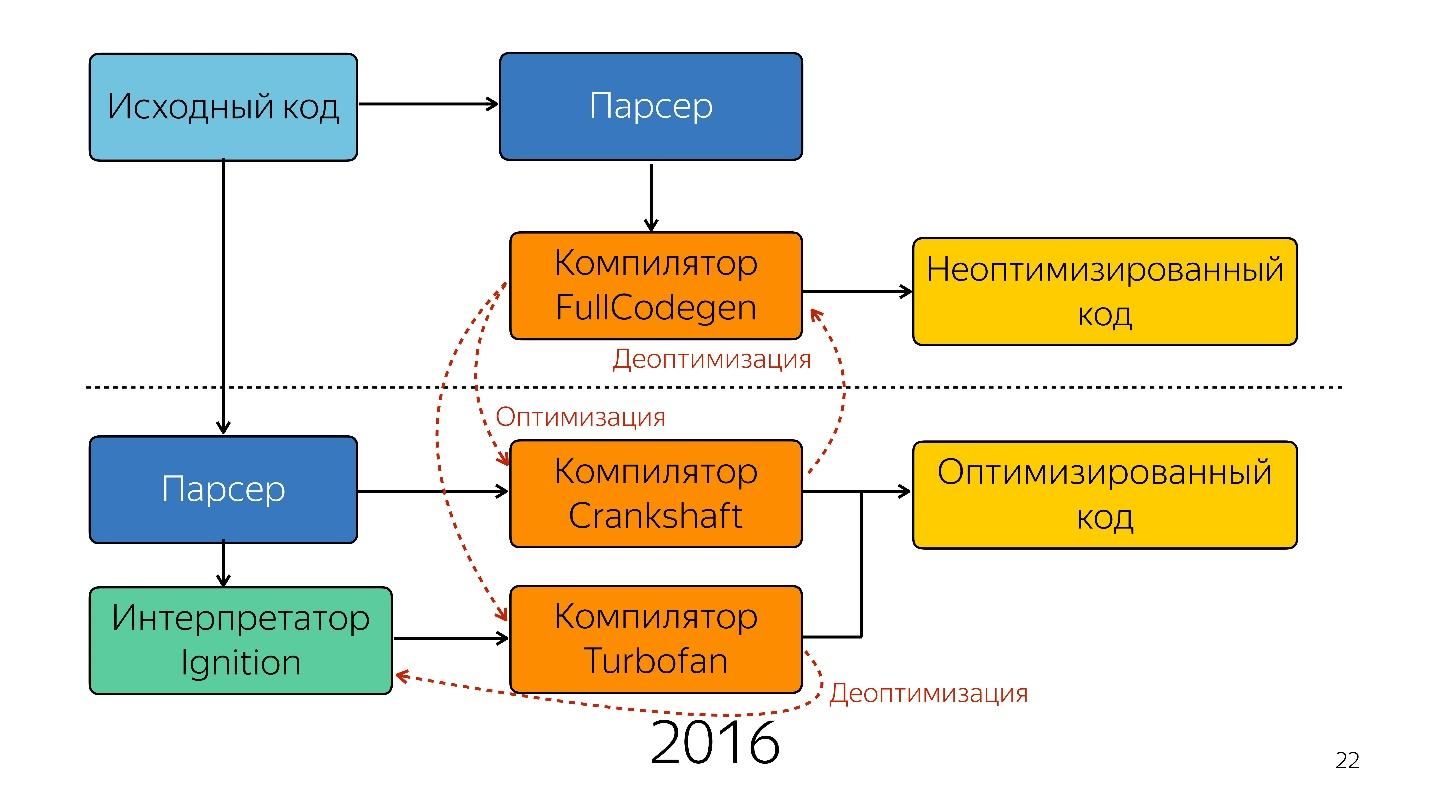
C'était jusqu'à l'année dernière. L'année dernière, vous avez entendu de nombreux rapports de Google selon lesquels ils avaient lancé un nouveau pipeline avec TurboFan et maintenant le schéma semble plus simple.
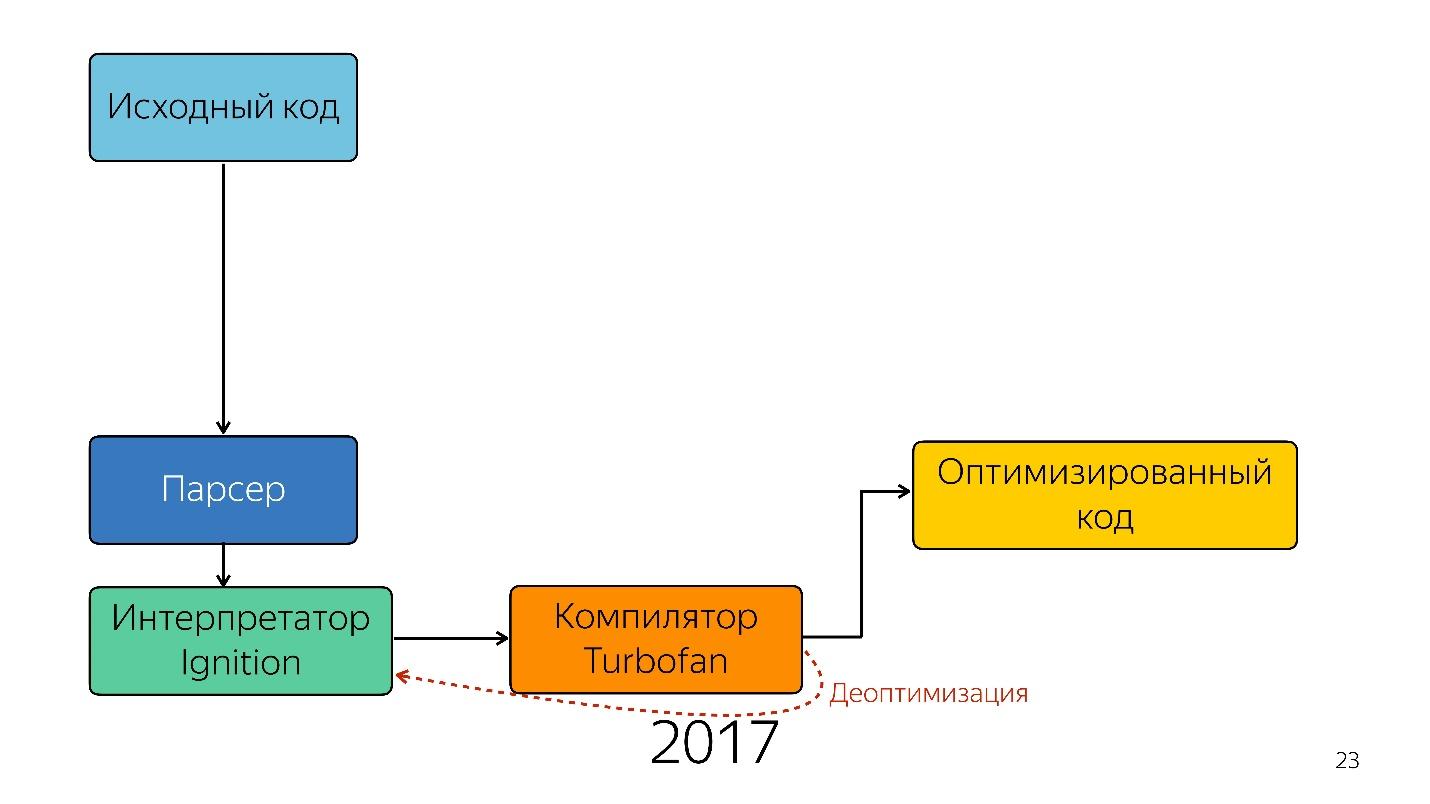
Fait intéressant, un interprète est apparu ici.
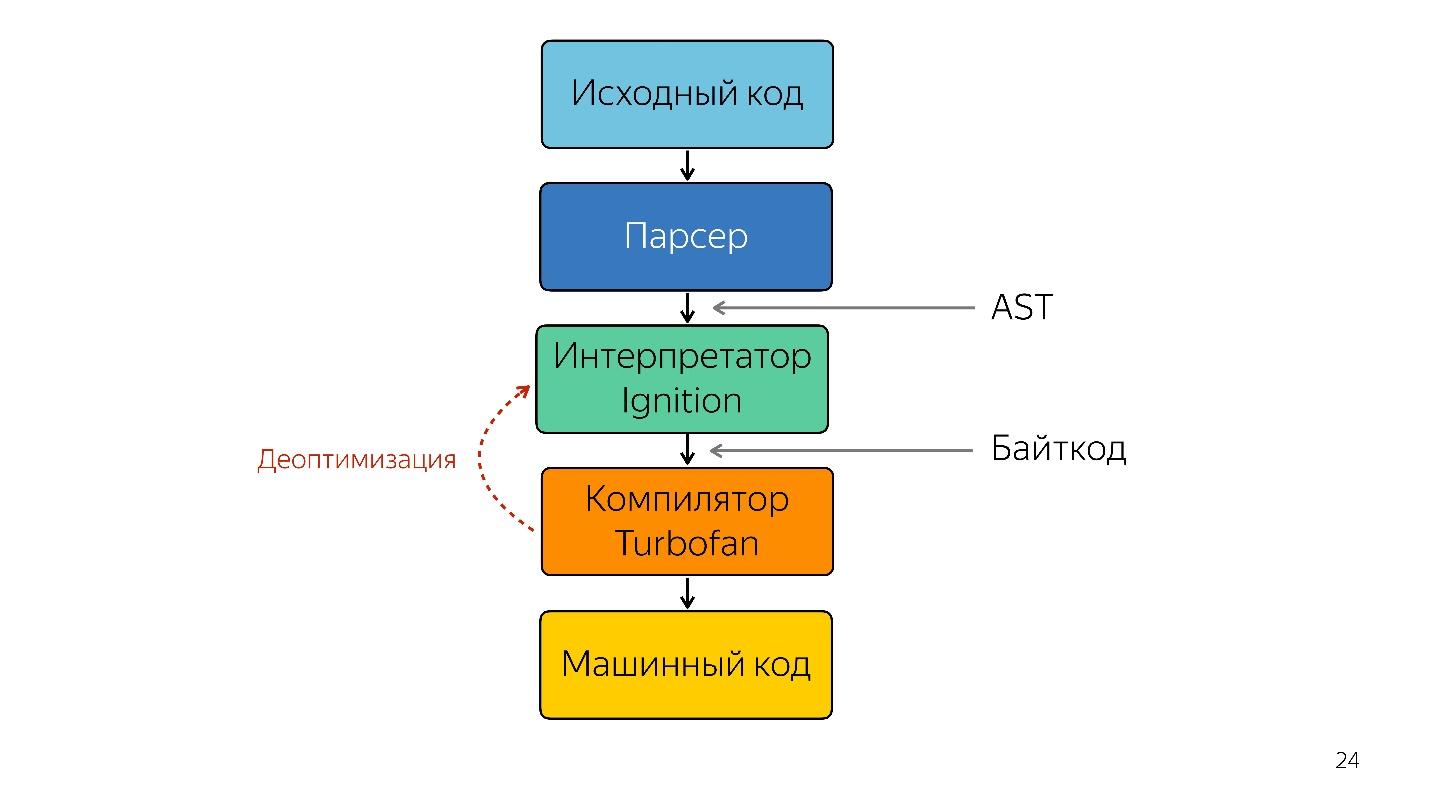
Un interpréteur est nécessaire pour transformer un arbre de syntaxe abstraite en bytecode et transmettre le bytecode à un compilateur. En cas de désoptimisation, il se rend à nouveau chez l'interprète.
Ignition de l'interprète
Auparavant, il n'existait pas de schéma d'interpréteur Ignition. Google a d'abord déclaré qu'un interprète n'était pas nécessaire - JavaScript est déjà suffisamment compact et interprétable - nous ne gagnerons rien.
Mais l'équipe qui a travaillé avec des applications mobiles a rencontré le problème suivant.

En 2013-2014, les gens ont commencé à utiliser des appareils mobiles pour accéder à Internet plus souvent que le bureau. Fondamentalement, ce n'est pas un iPhone, mais des appareils plus simples - ils ont peu de mémoire et un processeur faible.
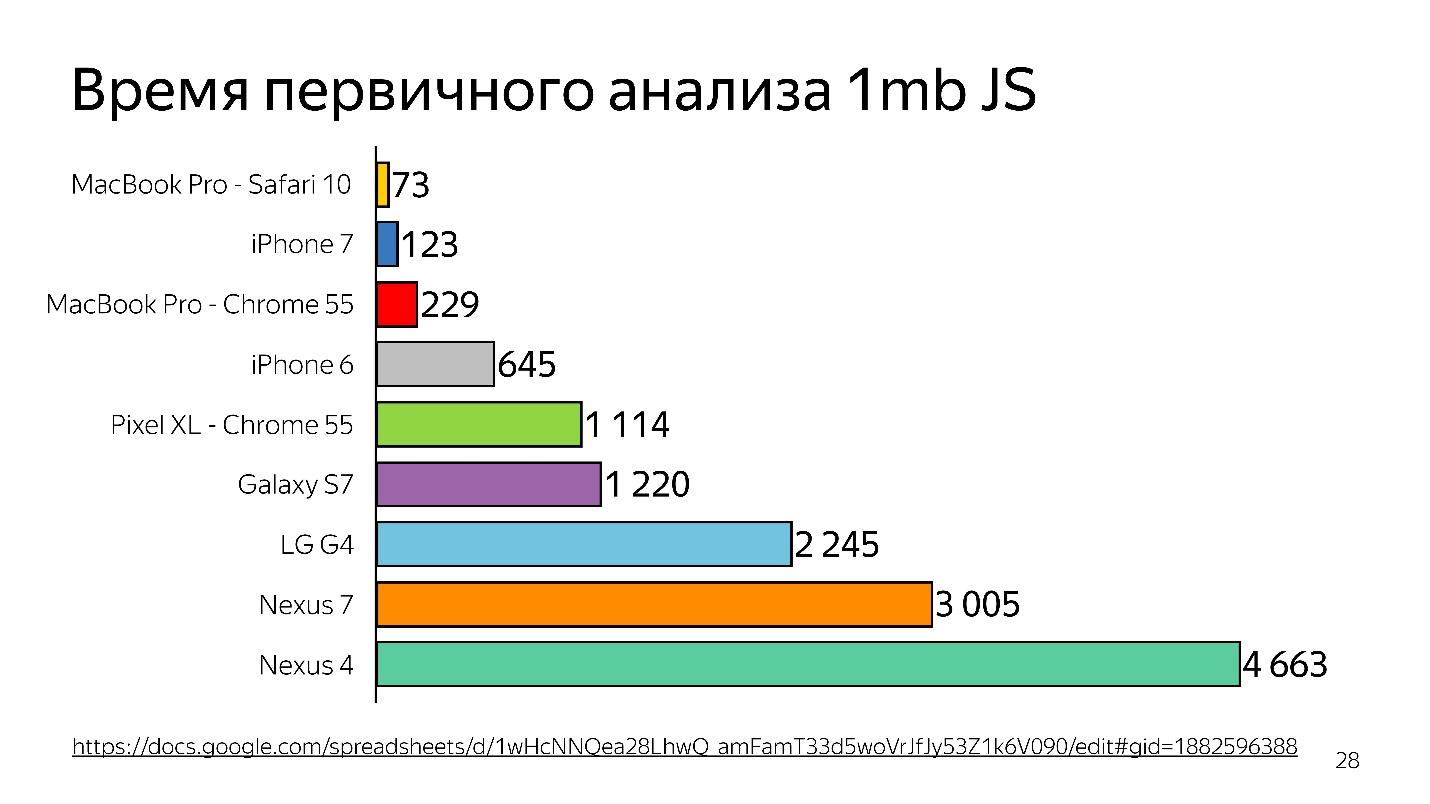
Ci-dessus est un graphique de l'analyse initiale de 1 Mo de code avant de démarrer l'interpréteur. On peut voir que le bureau gagne beaucoup. L'iPhone n'est pas mal non plus, mais il a un moteur différent, et nous parlons de V8, qui fonctionne dans Chrome.
Saviez-vous que si vous installez Chrome sur l'iPhone, cela fonctionnera toujours sur JavaScriptCore?
Ainsi, le temps est perdu - et ce n'est qu'une analyse, pas une exécution - votre fichier a été chargé, et il essaie de comprendre ce qui y est écrit.
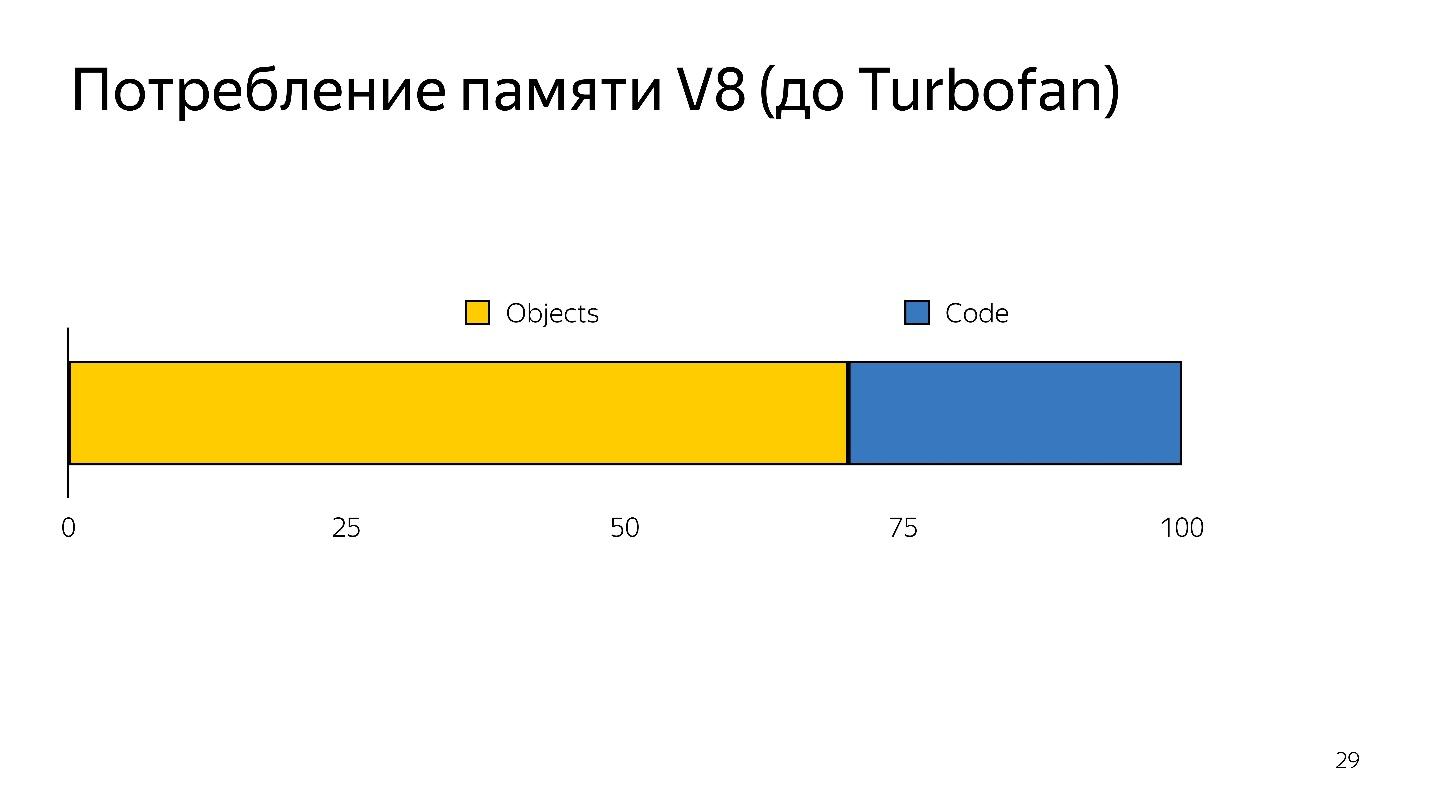
Lorsque la désoptimisation se produit, vous devez reprendre le code source, c'est-à-dire il doit être stocké quelque part. Cela a pris beaucoup de mémoire.
L'interprète avait donc deux tâches:
- réduire l'analyse des frais généraux;
- réduire la consommation de mémoire.
Les tâches ont été résolues en passant à un interpréteur de bytecode.
 Bytecode dans Chrome est une machine d'enregistrement avec une batterie
Bytecode dans Chrome est une machine d'enregistrement avec une batterie . SpiderMonkey a une machine empilée, là toutes les données sont sur la pile, mais il n'y a pas de registres. Les voici.
Nous n'analyserons pas complètement comment cela fonctionne, il suffit de regarder le fragment de code.

Il dit ici: prenez la valeur qui se trouve dans la batterie et ajoutez-la à la valeur qui se trouve dans le registre
a0 , c'est-à-dire dans la variable
a . On ne sait encore rien sur les types ici. S'il s'agissait d'un véritable code assembleur, il serait écrit en comprenant quel type de décalage se trouve dans la mémoire, ce qui s'y trouve. Voici juste une instruction - prenez ce qui se trouve dans le registre
a0 et ajoutez-le à la valeur qui se trouve dans la batterie.
Bien sûr, l'interpréteur ne prend pas simplement l'arbre de syntaxe abstraite et le traduit en bytecode.
Il existe également des optimisations, par exemple, l'élimination du code mort.
Si une section de code n'est pas appelée, elle est jetée et n'est pas stockée davantage. Si Ignition voit l'ajout de deux nombres, il les ajoute et les laisse de manière à ne pas stocker d'informations inutiles. Ce n'est qu'après cela que le bytecode est obtenu.
Optimisation et désoptimisation
Fonctions froides et chaudes
C'est le sujet le plus simple.
Les fonctions froides sont celles qui ont été appelées une fois ou pas du tout, les fonctions chaudes sont celles qui ont été appelées plusieurs fois. Il est impossible de dire exactement combien de fois - à tout moment cela peut être refait. Mais à un moment donné, la fonction devient chaude, et le moteur comprend qu'elle doit être optimisée.

Le schéma de travail.
- Ignition (interprète) recueille des informations. Il convertit non seulement JavaScript en bytecode, mais comprend également quels types sont entrés, quelles fonctions sont devenues chaudes, et il raconte tout cela au compilateur.
- Il y a une optimisation.
- Le compilateur exécute le code. Tout fonctionne bien, mais ici arrive un type auquel il ne s'attendait pas, il n'a pas de code pour fonctionner avec ce type.
- La désoptimisation se produit. Le compilateur accède à l'interpréteur Ignition pour ce code.
Il s'agit d'un cycle normal qui se produit tout le temps, mais il n'est pas infini. À un moment donné, le moteur dit: «Non, il est impossible d'optimiser» et commence à s'exécuter sans optimisation. Il est important de comprendre que le monomorphisme doit être observé.
Le monomorphisme, c'est quand les mêmes types viennent toujours à l'entrée de votre fonction. Autrement dit, si vous obtenez tout le temps de la chaîne, vous n'avez pas besoin de passer de booléen à cet endroit.
Mais que faire des objets? Les objets sont tous des objets. Nous avons des cours, mais ils ne sont pas réels - c'est juste du sucre sur le modèle prototype. Mais à l'intérieur du moteur, il existe des classes dites cachées.
Classes cachées
Il existe des classes cachées dans tous les moteurs, pas seulement dans la V8. Partout où ils sont appelés différemment, en termes de V8 c'est Map.
Tous les objets que vous avez créés ont des classes masquées. Si vous
regardez le profileur de mémoire, vous verrez qu'il y a des éléments où la liste des éléments est stockée, des propriétés où la propriété est stockée et une carte (généralement le premier paramètre), où un lien vers elle est indiqué sur sa classe cachée.
Map décrit la structure des objets, car en principe, en JavaScript, la frappe n'est possible que structurelle, pas nominale. Nous pouvons décrire à quoi ressemble notre objet, à quoi il sert.
Lorsque vous supprimez / ajoutez des propriétés d'objets de classes cachées, l'objet change, un nouveau est affecté. Regardons le code.
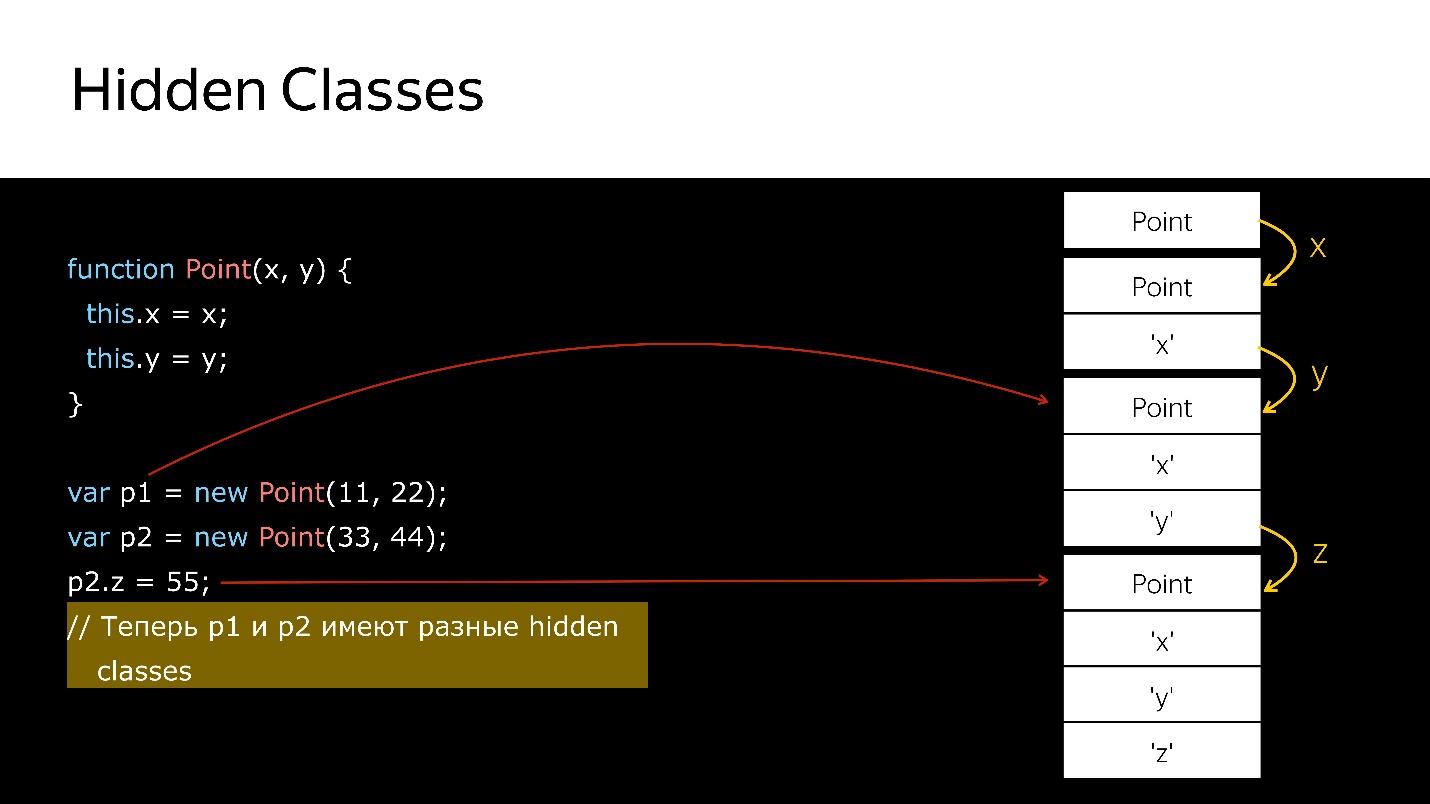
Nous avons un constructeur qui crée un nouvel objet de type Point.
- Créez un objet.
- Liez-lui une classe cachée, ce qui indique qu'il s'agit d'un objet de type Point.
- Nous avons ajouté le champ x - une nouvelle classe cachée qui dit que c'est un objet de type Point, dans lequel la valeur x vient en premier.
- Ajout de y - les nouvelles classes Hidden, dans lesquelles x, puis y.
- Créé un autre objet - la même chose se produit. Autrement dit, il lie également ce qui a déjà été créé. En ce moment, ces deux objets sont du même type (via les classes Hidden).
- Lorsqu'un nouveau champ est ajouté au deuxième objet, une nouvelle classe Hidden apparaît dans l'objet. Maintenant, pour le moteur p1 et p2, ce sont des objets de classes différentes, car ils ont des structures différentes
- Si vous transférez le premier objet quelque part, alors lorsque vous transférez le second là-bas, la désoptimisation se produira. La première fait référence à une classe cachée, la seconde à une autre.
Comment puis-je vérifier les classes cachées?Dans Node.js, vous pouvez exécuter node —allow-natives-syntax. Ensuite, vous aurez la possibilité d'écrire des commandes dans une syntaxe spéciale, qui, bien sûr, ne peut pas être utilisée en production. Cela ressemble à ceci:
%HaveSameMap({'a':1}, {'b':1})
Personne ne garantit que demain ces commandes fonctionneront, elles ne sont pas dans la spécification ECMAScript, c'est tout pour le débogage.
Selon vous, quel sera le résultat de l'appel de la fonction% HaveSameMap pour deux objets. La bonne réponse est fausse, car l'une a un champ et l'autre a
b . Ce sont des objets différents. Ces connaissances peuvent être utilisées pour la technique des caches en ligne.
Caches en ligne
Nous appelons une fonction très simple qui renvoie un champ à partir d'un objet. Le retour de l'appareil semble être très simple. Mais si vous regardez la spécification ECMAScript, vous verrez qu'il y a une énorme liste de ce que vous devez faire pour obtenir le champ de l'objet. Car, si le champ n'est pas dans l'objet, il est possible qu'il se trouve dans son prototype. Peut-être que c'est setter, getter et ainsi de suite. Tout cela doit être vérifié.

Dans ce cas, l'objet a un lien vers la carte, qui dit: pour obtenir le champ
x , vous devez faire un décalage d'un, et nous obtenons
x . Vous n'avez pas à grimper n'importe où, dans tous les prototypes, tout est à proximité. Les caches en ligne l'utilisent.
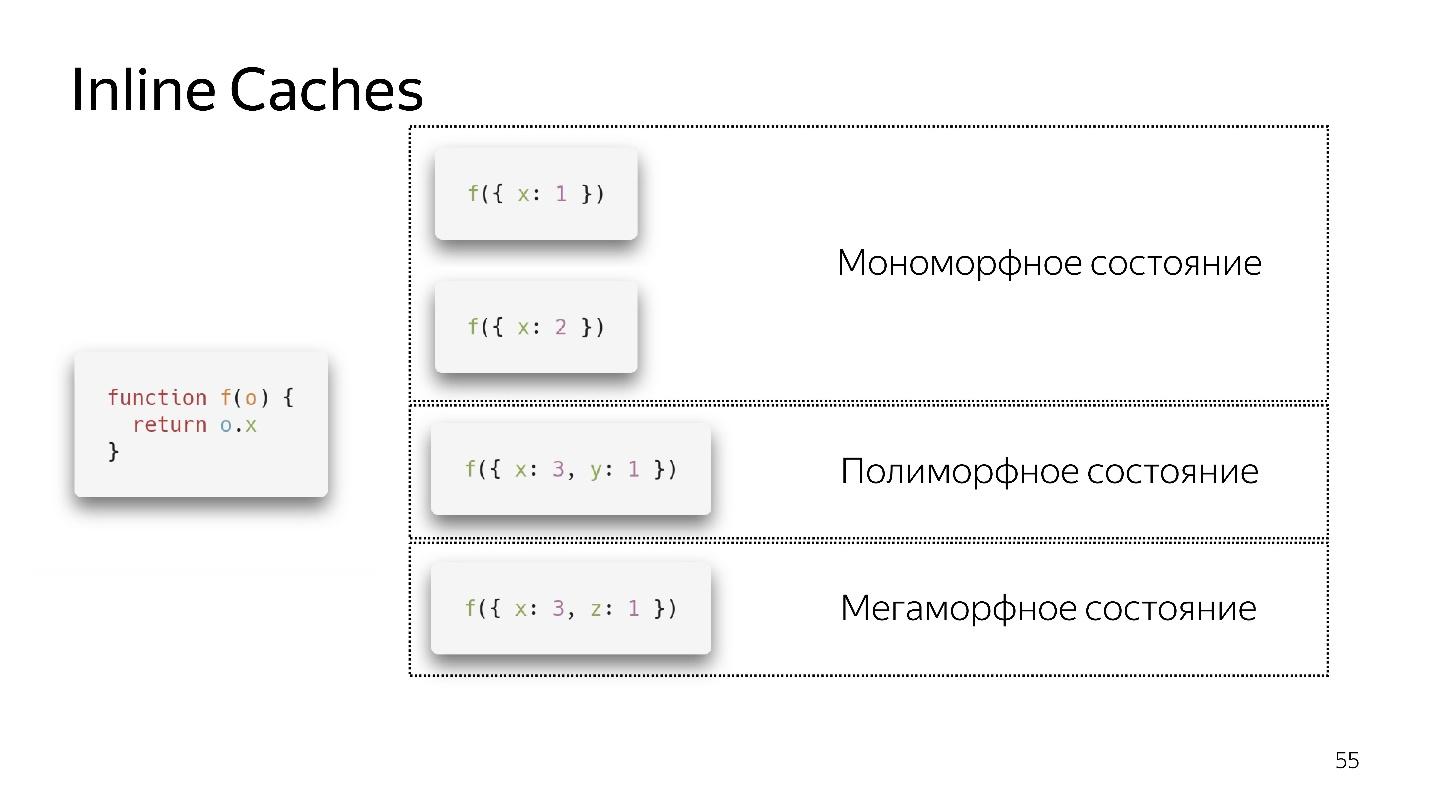
- Si on appelle la fonction pour la première fois, tout va bien, l'interprète a fait l'optimisation
- Pour le deuxième appel, un état monomorphe est enregistré.
- J'appelle la fonction une troisième fois, je passe un objet légèrement différent {x: 3, y: 1}. La désoptimisation se produit, si elle apparaît, nous entrons dans un état polymorphe. Maintenant, le code qui exécute cette fonction sait que deux types d'objets différents peuvent y voler.
- Si nous passons plusieurs objets différents plusieurs fois, il reste dans un état polymorphe, ajoutant de nouveaux ifs. Mais à un moment donné, il se rend et entre dans un état mégamorphique, c'est-à-dire quand: "Trop de types différents arrivent à l'entrée - je ne sais pas comment l'optimiser!"
Il semble que maintenant 4 états polymorphes soient autorisés, mais demain il y en aura peut-être 8. Ceci est décidé par les développeurs du moteur. Il vaut mieux rester dans un état monomorphe, dans les cas extrêmes, polymorphe. La transition entre les états monomorphes et polymorphes est coûteuse, car vous devrez aller à l'interpréteur, récupérer le code et l'optimiser à nouveau.
Tableaux
En JavaScript, outre les tableaux typés spécifiques, il existe un type
tableau. Il y en a 6 dans le moteur V8:
1. [1, 2, 3, 4] // PACKED_SMI_ELEMENTS - juste un tableau compact de petits nombres entiers. Il y a des optimisations pour lui.
2. [1.2, 2.3, 3.4, 4.6] // PACKED_DOUBLE_ELEMENTS - un tableau compact d'éléments doubles, il y a aussi des optimisations pour lui, mais plus lentes.
3. [1, 2, 3, 4, 'X'] // PACKED_ELEMENTS - un tableau compressé dans lequel il y a des objets, des chaînes et tout le reste. Pour lui aussi, il y a des optimisations.
Les trois types suivants sont des tableaux du même type que les trois premiers, mais avec des trous:
4. [1, / * trou * /, 2, / * trou * /, 3, 4] // HOLEY_SMI_ELEMENTS
5. [1.2, / * trou * /, 2, / * trou * /, 3,4] // HOLEY_DOUBLE_ELEMENTS
6. [1, / * trou * /, 'X'] // HOLEY_ELEMENTS
Lorsque des trous apparaissent dans vos tableaux, les optimisations deviennent moins efficaces. Ils commencent à mal fonctionner, car il est impossible de parcourir ce tableau d'affilée, en triant les itérations. Chaque type suivant est moins optimisé
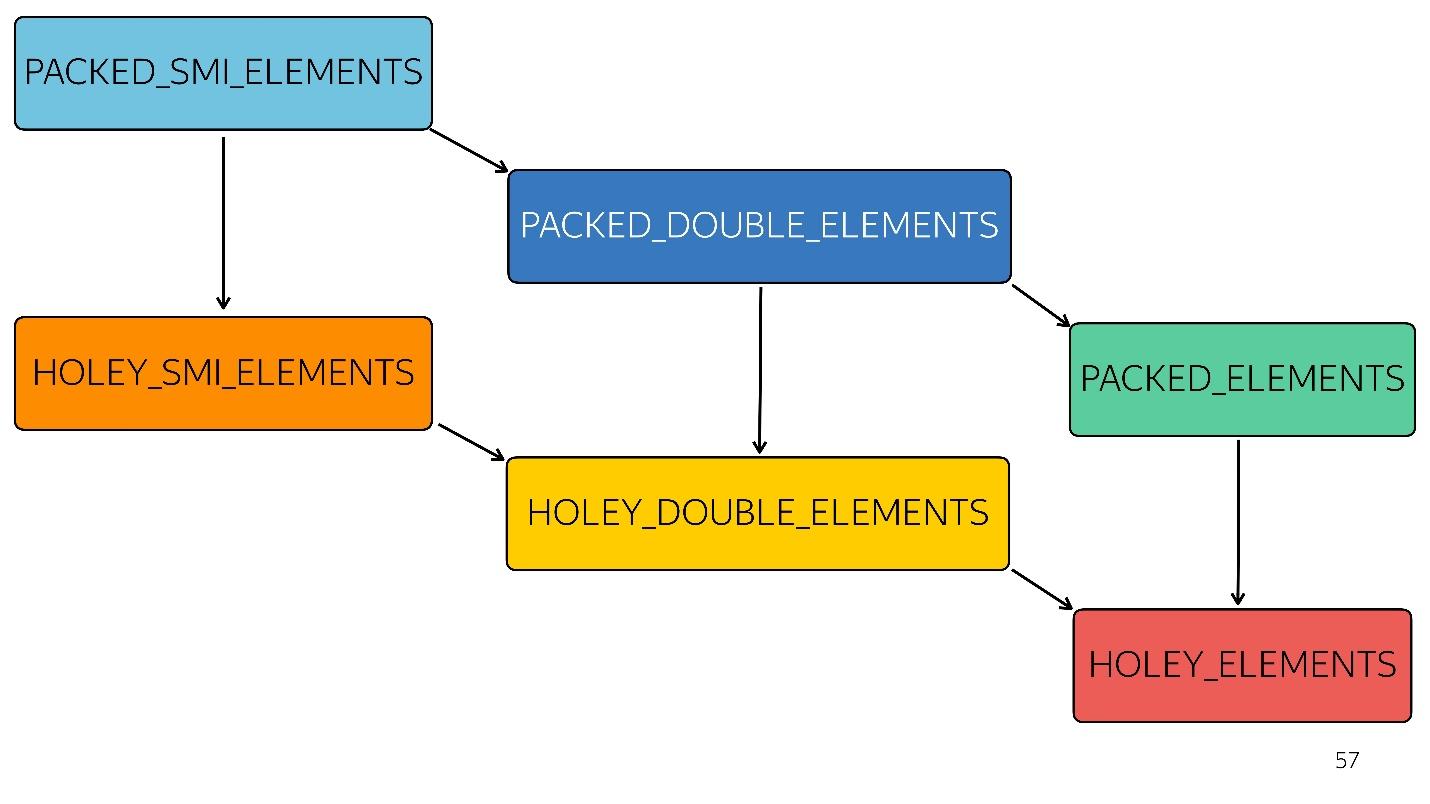
Dans le diagramme, tout ce qui précède est optimisé plus rapidement. Autrement dit, toutes vos méthodes natives - mapper, réduire, trier - à l'intérieur sont bien optimisées. Mais avec chaque type, l'optimisation empire.
Par exemple, un simple tableau [
1 ,
2 ,
3 ] est entré en entrée (petit entier de type paquet). Nous avons légèrement changé ce tableau en lui ajoutant un double - nous sommes passés à l'état PACKED_DOUBLE_ELEMENTS. Ajoutez-y un objet - passez à l'état suivant, le rectangle vert PACKED_ELEMENTS. Ajoutez-y des trous - passez à l'état HOLEY_ELEMENTS. Nous voulons le restaurer à son état précédent afin qu'il redevienne "bon" - nous supprimons tout ce que nous avons écrit et restons dans le même état ... avec des trous! Autrement dit, HOLEY_ELEMENTS en bas à droite du diagramme. Retour cela ne fonctionne pas. Vos tableaux ne peuvent qu'empirer, mais pas l'inverse.
Objet de type tableau
Nous rencontrons souvent des objets de type tableau - ce sont des objets qui ressemblent à des tableaux parce qu'ils ont un signe de longueur. En fait, ils sont comme un chat pirate, c'est-à-dire qu'ils semblent être similaires, mais dans l'efficacité de la consommation de rhum, un chat sera pire qu'un pirate. De même, un objet de type tableau ressemble à un tableau, mais n'est pas efficace.

Nos deux objets de type tableau préférés sont les arguments et document.querySelectorAII. Il y a de si belles choses fonctionnelles.
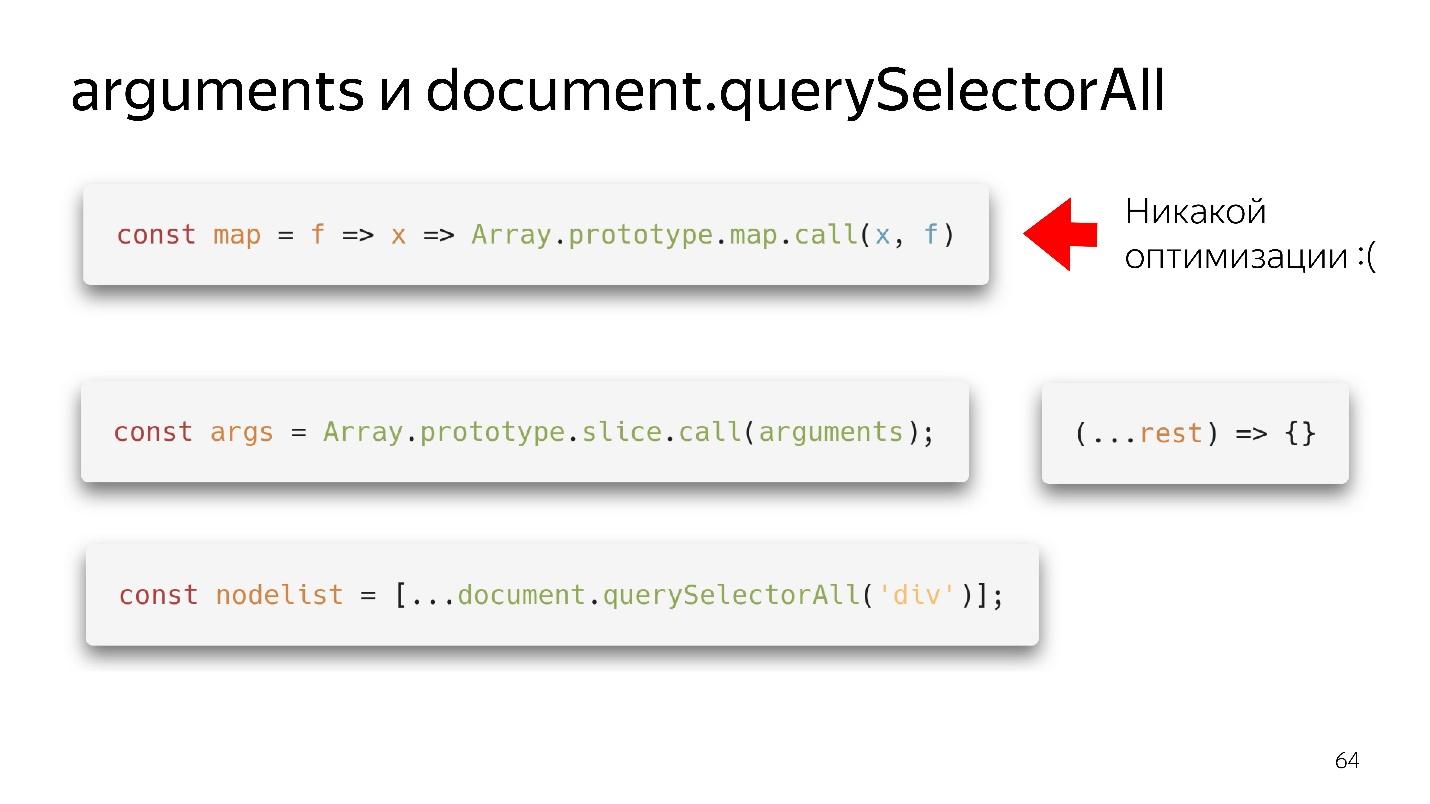
Nous avons obtenu une carte - nous l'avons extraite du prototype et, apparemment, nous pouvons l'utiliser. Mais si aucun tableau n'est venu à son entrée, il n'y aura pas d'optimisation. Notre moteur n'est pas en mesure d'optimiser les objets.
Que faut-il faire?
- L'option old-school - via slice.call () se transforme en un véritable tableau.
- L'option moderne est encore meilleure: écrire (... reste), obtenir un tableau propre - pas des arguments - tout va bien!
Avec querySelectorAll la même chose - en raison de la propagation, nous pouvons le transformer en un tableau à part entière et travailler avec toutes les optimisations.
Grands tableaux
Devinette: nouveau tableau (1000) vs tableau = []
Quelle option est la meilleure: créer immédiatement un grand tableau et le remplir de 1000 objets en boucle, ou en créer un vide et le remplir progressivement?
Bonne réponse: dépend de.
Quelle est la différence?
- Lorsque nous créons un tableau de la première manière et remplissons 1000 éléments, nous créons 1000 trous. Ce tableau ne sera pas optimisé. Mais il écrira rapidement.
- En créant un tableau selon la deuxième variante, un peu de mémoire est allouée, on écrit, par exemple, 60 éléments, un peu plus de mémoire est allouée, etc.
Autrement dit, dans le premier cas, nous écrivons rapidement - nous travaillons lentement; dans la seconde, nous écrivons lentement - nous travaillons rapidement.
Collecteur d'ordures
Le garbage collector mange aussi un peu de temps et de ressources. Sans plonger profondément, je donnerai la base la plus courante.

Notre modèle génératif a un
espace d'objets jeunes et vieux . L'objet créé tombe dans l'espace des jeunes objets. Après un certain temps, le nettoyage commence. Si l'objet ne peut pas être atteint par des liens à partir de la racine, il peut être collecté à la poubelle. Si l'objet est toujours utilisé, il se déplace vers l'espace des anciens objets, qui est moins fréquemment nettoyé. Cependant, à un certain point, les anciens objets sont supprimés.

Voici comment fonctionne un ramasse-miettes automatique - il nettoie les objets sur la base qu'il n'y a aucun lien vers eux. Ce sont deux algorithmes différents.
- Le nettoyage est rapide mais pas efficace.
- Mark-Sweep est lent mais efficace.
Si vous commencez à profiler la consommation de mémoire dans Node.js, vous obtenez quelque chose comme ça.

Au début, il croît brusquement - c'est le travail de l'algorithme Scavenge. Ensuite, une forte baisse se produit - cet algorithme Mark-Sweep a collecté des ordures dans l'espace des anciens objets. En ce moment, tout commence à ralentir un peu.
Vous ne pouvez pas le contrôler , car vous ne savez pas quand cela se produira. Vous ne pouvez ajuster que les tailles.
Par conséquent, le pipeline a une étape de récupération de place qui consomme du temps.
Encore plus vite?
Regardons l'avenir. Que faire ensuite, comment être plus rapide?
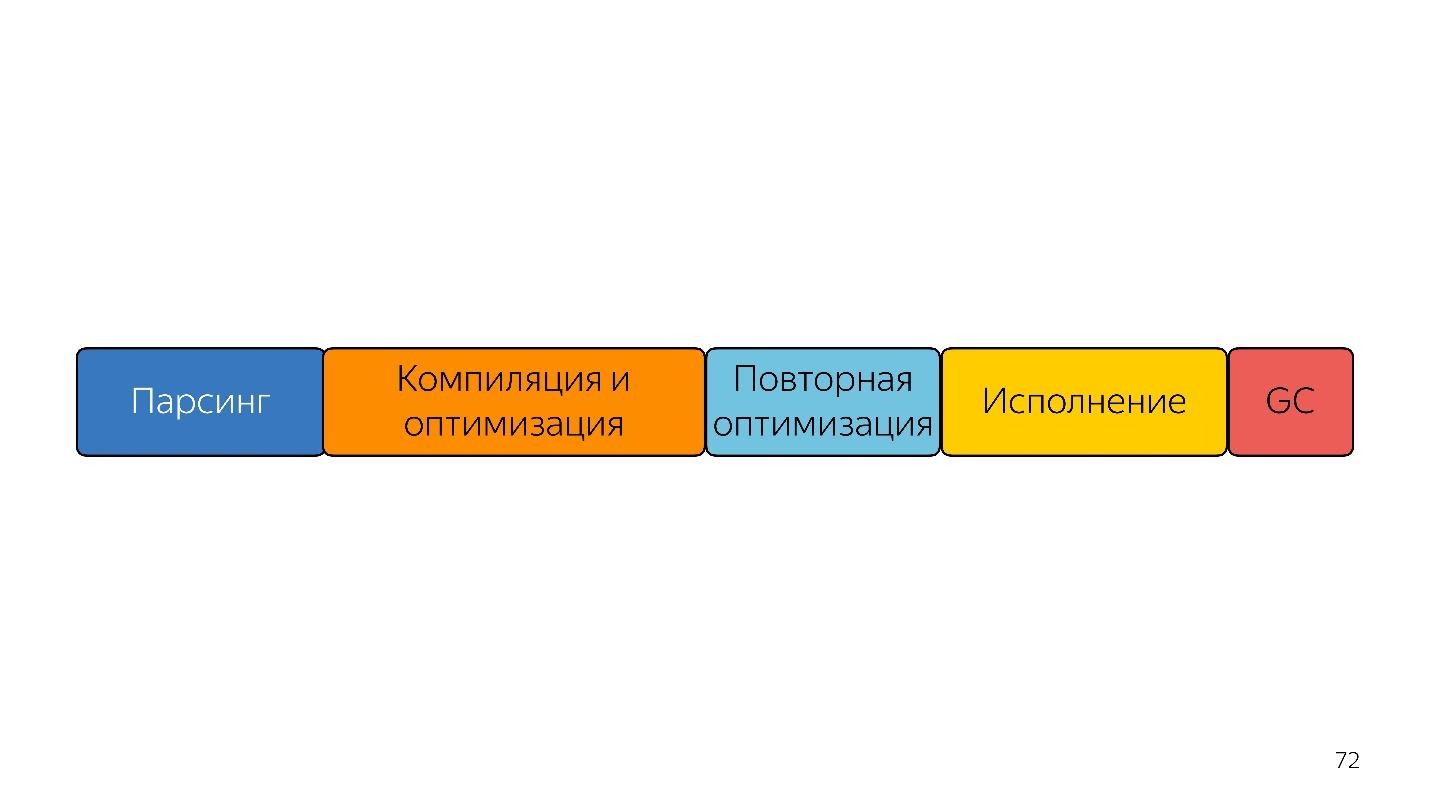
Sur cette ligne, les tailles de bloc sont à peu près liées dans le temps qu'il faut.
La première chose qui vient à l'esprit pour les personnes qui ont entendu parler du bytecode - soumettre immédiatement un bytecode à l'entrée et le décoder, plutôt que de l'analyser - sera plus rapide!

Le problème est que le bytecode est différent maintenant. Comme je l'ai dit: dans Safari un, dans FireFox un autre, dans Chrome troisième. Néanmoins, les développeurs de Mozilla, Bloomberg et Facebook ont présenté une telle
proposition , mais c'est l'avenir.
Il y a un autre problème - la compilation, l'optimisation et la réoptimisation, si le compilateur n'a pas deviné. Imaginez qu'il y ait un langage typé à l'entrée qui produit un code efficace, ce qui signifie que la réoptimisation n'est plus nécessaire, car ce que nous avons obtenu est déjà efficace. Une telle entrée ne peut être compilée et optimisée qu'une seule fois. Le code résultant sera plus efficace et s'exécutera plus rapidement.
Que peut-on faire d'autre? Imaginez que ce langage possède une gestion manuelle de la mémoire. Ensuite, vous n'avez pas besoin d'un ramasse-miettes. La ligne est devenue plus courte et plus rapide.

Devinez à quoi ça ressemble?
WebAssembly environ
voici comment cela fonctionne: gestion manuelle de la mémoire, saisie statique
langues et exécution rapide.

WebAssembly est-il une solution miracle?

Non, car il signifie JavaScript. WASM ne peut encore rien faire. Il n'a pas accès à l'API DOM. C'est à l'intérieur du moteur JavaScript - à l'intérieur du même moteur! Il fait tout via JavaScript, donc
WASM n'accélérera pas votre code . Cela peut accélérer les calculs individuels, mais votre échange entre JavaScript et WASM sera un goulot d'étranglement.
Par conséquent, alors que notre langage est JavaScript et seulement lui, et un peu d'aide de la boîte noire.
Total
On peut distinguer trois types d'optimisation.
●
Optimisations algorithmiquesIl y a un article "
Peut-être que vous n'avez pas besoin de Rust pour accélérer votre JS " par Vyacheslav Egorov, qui a autrefois développé V8 et développe maintenant Dart. Racontez brièvement son histoire.
Il y avait une bibliothèque JavaScript qui ne fonctionnait pas très rapidement. Certains gars l'ont réécrit dans Rust, compilé et obtenu WebAssembly, et l'application a commencé à fonctionner plus rapidement. Vyacheslav Egorov en tant que développeur JS expérimenté a décidé d'y répondre. Il a appliqué des optimisations algorithmiques et la solution JavaScript est devenue beaucoup plus rapide que la solution Rust. À leur tour, ces gars-là ont vu cela, ont fait les mêmes optimisations et ont gagné à nouveau, mais pas beaucoup - cela dépend du moteur: dans Mozilla, ils ont gagné, dans Chrome, non.
Aujourd'hui, nous n'avons pas parlé d'optimisations algorithmiques, et les rendus frontaux n'en parlent généralement pas. C'est très mauvais, car les
algorithmes permettent également au code de s'exécuter plus rapidement . Vous supprimez simplement les cycles dont vous n'avez pas besoin.
●
Optimisations spécifiques à la langueC'est ce dont nous avons parlé aujourd'hui: notre langage est interprété dynamiquement typé. Comprendre le fonctionnement des tableaux, des objets et du monomorphisme
vous permet d'écrire du code efficace . Cela doit être connu et écrit correctement.
●
Optimisations spécifiques au moteurCe sont les optimisations les plus dangereuses. Si votre développeur très intelligent, mais pas très sociable, qui a appliqué beaucoup de telles optimisations et n'en a parlé à personne, n'a pas écrit la documentation, alors si vous ouvrez le code, vous ne verrez pas JavaScript, mais, par exemple, Crankshaft Script. Autrement dit, JavaScript écrit avec une compréhension approfondie du fonctionnement du moteur de vilebrequin il y a deux ans. Tout fonctionne, mais maintenant il n'est plus nécessaire.
Par conséquent, ces optimisations doivent nécessairement être documentées, couvertes de tests prouvant leur efficacité à l'heure actuelle. Ils doivent être surveillés. Vous devez vous y rendre uniquement au moment où vous avez vraiment ralenti quelque part - vous ne pouvez tout simplement pas vous passer de connaître des appareils aussi profonds. Par conséquent, la célèbre phrase de Donald Knuth semble logique.

Pas besoin d'essayer de mettre en œuvre des optimisations dures, simplement parce que vous avez lu des critiques positives à leur sujet.
Il faut avoir peur de telles optimisations, s'assurer de documenter et de laisser des métriques. Généralement, collectez toujours des métriques.
Les métriques sont importantes!Liens utiles:Frontend Conf Moscow 4 5 . 15 , , :
- (KeepSolid) , Offline First Persistent Storage
- (TradingView) WebGL WebAssembly , , API .
- , Google Docs.