Présentation
Il y a quelque temps, je suis devenu participant à un projet de développement d'un logiciel conçu pour analyser les dossiers des patients et les données sur leur état de santé provenant d'organisations médicales afin de créer un dossier médical unifié. Pendant longtemps, l'équipe n'a pas pu développer une approche pour combiner les données des patients. Le point de départ a été l'étude des codes sources de la solution Open EMPI (Open Enterprise Master Patient Index), qui nous a poussés à des algorithmes d'analyse de similarité de chaînes. À partir de ce moment, une étude plus approfondie des matériaux a commencé, ce qui a permis de créer d'abord une mise en page, puis une solution de travail.
Jusqu'à présent, lors de divers types de présentations, il faut entendre beaucoup de questions sur la logique du travail de ces produits, dont je conclus qu'un examen des méthodes de liaison de texte intéressera un large cercle de lecteurs.
Le matériel est une traduction de l'article de wikipedia " Record linkage " avec copyright et ajouts.
Qu'est-ce que la liaison de texte?
Le terme « couplage d'enregistrements» décrit le processus de rattachement d'enregistrements de texte d'une source de données à des enregistrements d'une autre, à condition qu'ils décrivent le même objet. En informatique, cela s'appelle un «mappage de données» ou «problème d'identité d'objet» . Des définitions alternatives sont parfois utilisées, telles que "identification" , "liaison , " détection de doublons " , " déduplication " , " enregistrements correspondants " , " identification d'objet " , qui décrivent le même concept. Cette abondance terminologique a conduit à une séparation des approches de traitement et de structuration de l'information - liaison des enregistrements et liaison des données . Bien qu'ils déterminent tous deux l'identification des objets correspondants par différents ensembles de paramètres, le terme "liaison de documents textuels" est couramment utilisé pour désigner "l'essence" d'une personne, tandis que "liaison de données" signifie la possibilité de lier n'importe quelle ressource Web entre des ensembles de données, en utilisant, respectivement, le concept plus large d'un identifiant, à savoir un URI.
Pourquoi est-ce nécessaire?
Lors du développement de produits logiciels pour la construction de systèmes automatisés utilisés dans divers domaines liés au traitement des données personnelles d'une personne (soins de santé, histoire, statistiques, éducation, etc.), la tâche se pose d'identifier des données sur des sujets de comptabilité provenant de diverses sources.
Cependant, lors de la collecte de descriptions à partir d'un grand nombre de sources, des problèmes surviennent qui rendent difficile leur identification sans ambiguïté. Ces problèmes incluent:
- fautes de frappe;
- permutations de champ (par exemple, dans le prénom);
- l'utilisation d'abréviations et d'abréviations;
- l'utilisation d'un format différent d'identifiants (dates, numéros de documents, etc.).
- distorsion phonétique;
- etc.
La qualité des données brutes affecte directement le résultat du processus de liaison. En raison de ces problèmes, les ensembles de données sont souvent transférés vers le traitement qui, bien qu'ils décrivent le même objet, ressemble à ces enregistrements différents. Par conséquent, d'une part, tous les identifiants d'enregistrements transmis sont évalués pour leur applicabilité à une utilisation dans le processus d'identification, et d'autre part, les enregistrements eux-mêmes sont normalisés ou standardisés afin de les amener dans un format unique.
Visite historique
L'idée originale de relier les notes a été avancée par Halbert L. Dunn, qui a publié un article intitulé «Record Linkage» dans l'American Journal of Public Health en 1946.
Plus tard, en 1959, dans un article sur Automatic Linkage of Vital Records dans le magazine Science, Howard B. Newcombe a jeté les bases probabilistes de la théorie moderne de la liaison des cordes, qui a été développée et renforcée en 1969 par Ivan Fellegi et Alan Santer (Alan Sunter). Leur travail «A Theory For Record Linkage» est toujours le fondement mathématique de nombreux algorithmes de liaison.
Le développement principal des algorithmes a eu lieu dans les années 90 du siècle dernier. Puis, de divers domaines (statistiques, archivage, épidémiologie, histoire et autres), des algorithmes souvent utilisés aujourd'hui dans les produits logiciels nous sont parvenus, comme la similitude (distance) de la distance Jaro-Winkler et de la distance Levenshtein , cependant, certaines solutions, par exemple l'algorithme phonétique Soundex, sont apparues beaucoup plus tôt - dans les années 20 du siècle dernier.
Algorithmes de comparaison de saisie de texte
Distinguer les algorithmes déterministes et probabilistes pour comparer les enregistrements de texte. Les algorithmes déterministes sont basés sur la coïncidence complète des attributs d'enregistrement. Les algorithmes probabilistes permettent de calculer le degré de correspondance des attributs d'enregistrement et, sur cette base, de décider de la possibilité de leur relation.
Algorithmes déterministes
La façon la plus simple de comparer des chaînes est basée sur des règles claires lorsque des liens entre les objets sont générés en fonction du nombre de correspondances des attributs des ensembles de données. C'est-à-dire que deux enregistrements correspondent l'un à l'autre via un algorithme déterministe si tout ou partie de leurs attributs sont identiques. Les algorithmes déterministes conviennent pour comparer des sujets décrits par un ensemble de données identifiées par un identifiant commun (par exemple, le numéro d'assurance d'un compte personnel individuel dans la Caisse de pension - SNILS) ou qui ont plusieurs identifiants représentatifs (date de naissance, sexe, etc.) auxquels on peut faire confiance.
Des algorithmes déterministes peuvent être appliqués lorsque des ensembles de données clairement structurés (normalisés) sont transférés au traitement.
Par exemple, il contient l'ensemble d'entrées de texte suivant:
| Non. | SNILS | Prénom | Date de naissance | Sexe |
|---|
| A1 | 163-648-564 96 | Zhvanetsky Mikhail | 03/06/1934 | M |
| A2 | 163-648-564 96 | Zhvanetsky Mikhail | 03/06/1934 | M |
| A3 | 126-029-036 24 | Ilchenko Victor | 01/02/1937 | M |
| A4 | | Novikova Klara | 26.12.1946 | F |
| Non. | SNILS | Prénom | Date de naissance | Sexe |
|---|
| B1 | 126-029-036 24 | Ilyichenko Victor | 01/02/1937 | M |
| B2 | | Zhivanetsky Mikhail | 03/06/1934 | M |
| B3 | | Zerchaninova Klara | 26.12.1946 | 2 |
Il a été dit précédemment que l'algorithme déterministe le plus simple est l'utilisation d'un identifiant unique, qui est censé identifier de manière unique une personne. Par exemple, nous supposons que tous les enregistrements qui ont la même valeur d'identifiant (SNILS) décrivent le même sujet, sinon ce sont des sujets différents. La connexion déterministe dans ce cas va générer les paires suivantes: A1 et A2, A3 et B1. B2 ne sera pas associé à A1 et A2, car l'identifiant n'a pas d'importance, bien qu'il coïncide dans le contenu avec les enregistrements spécifiés.
Ces exceptions obligent à compléter l'algorithme déterministe par de nouvelles règles. Par exemple, s'il n'y a pas d'identifiant unique, vous pouvez utiliser d'autres attributs tels que le nom, la date de naissance et le sexe. Dans l'exemple donné, cette règle supplémentaire ne donnera pas à nouveau la correspondance B2 et A1 / A2, car maintenant les noms sont différents - il y a une distorsion phonétique du nom de famille.
Ce problème peut être résolu en utilisant les méthodes d'analyse phonétique, mais si vous changez le nom de famille (par exemple, dans le cas du mariage), vous devrez recourir à l'application d'une nouvelle règle, par exemple, comparer la date de naissance ou autoriser des différences dans les attributs existants de l'enregistrement (par exemple, le sexe).
L'exemple illustre clairement que l'algorithme déterministe est très sensible à la qualité des données, et une augmentation du nombre d'attributs d'enregistrement peut entraîner une augmentation substantielle du nombre de règles appliquées, ce qui complique considérablement l'utilisation d'algorithmes déterministes.
De plus, l'utilisation d'algorithmes déterministes est possible s'il existe un ensemble de données vérifié (référence maître) avec lequel les informations entrantes sont comparées. Cependant, dans le cas d'une reconstitution constante du répertoire maître lui-même, une refonte complète des relations existantes peut être nécessaire, ce qui rend l'utilisation d'algorithmes déterministes longue ou simplement impossible.
Algorithmes probabilistes
Les algorithmes probabilistes pour lier les enregistrements de chaînes utilisent un ensemble d'attributs plus large que ceux déterministes, et pour chaque attribut, un coefficient de pondération est calculé qui détermine la capacité d'influencer la connexion dans l'évaluation finale de la probabilité de conformité des enregistrements estimés. Les enregistrements qui ont accumulé un poids total supérieur à un certain seuil sont considérés comme liés, les enregistrements qui ont accumulé un poids total inférieur à un seuil sont considérés comme non liés. Les paires qui ont gagné la valeur du poids total au milieu de la plage sont considérées comme des candidats pour la liaison et peuvent être envisagées plus tard (par exemple, par l'opérateur), qui décidera de leur union (lien) ou les laissera non liées. Ainsi, contrairement aux algorithmes déterministes, qui sont un ensemble d'un grand nombre de règles claires (programmées), les algorithmes probabilistes peuvent être adaptés à la qualité des données en sélectionnant des valeurs de seuil et ne nécessitent pas de reprogrammation.
Ainsi, les algorithmes probabilistes attribuent des coefficients de pondération ( u et m ) aux attributs de l'enregistrement, à l'aide desquels leur correspondance ou incohérence les uns avec les autres sera déterminée.
Le coefficient u détermine la probabilité que les identifiants de deux enregistrements indépendants coïncident au hasard. Par exemple, la probabilité u du mois de naissance (lorsqu'il y a douze valeurs uniformément réparties) est 1 \ 12 = 0,083. Les identificateurs dont les valeurs ne sont pas réparties uniformément auront différentes probabilités pour différentes valeurs (parfois, y compris les valeurs manquantes).
Le coefficient m est la probabilité que les identifiants des paires comparées se correspondent ou soient assez similaires - par exemple, dans le cas d'une probabilité élevée par l'algorithme Jaro-Winkler ou faible par l'algorithme Levenshtein. Si les attributs des enregistrements sont entièrement cohérents, cette valeur devrait avoir une valeur de 1,0, mais étant donné la faible probabilité de cela, le coefficient devrait être évalué différemment. Cette évaluation peut être effectuée sur la base d'une analyse préliminaire de l'ensemble de données, par exemple en «apprenant» manuellement l' algorithme probabiliste pour identifier un grand nombre de paires correspondantes et non concordantes ou en lançant itérativement l'algorithme pour sélectionner la valeur de coefficient m la plus appropriée.
Si la probabilité m est définie à 0,95, les coefficients de conformité / non-conformité pour le mois de naissance ressembleront à ceci:
| Métrique | Partage de liens | Part des valeurs, pas des références | La fréquence | Le poids |
|---|
| Conformité | m = 0,95 | u = 0,083 | m \ u = 11,4 | ln (m / u) / ln (2) ≈ 3,51 |
| Inadéquation | 1 m = 0,05 | 1-u = 0,917 | (1 m) / (1 u) ≈ 0,0545 | ln ((1-m) / (1-u)) / ln (2) ≈ -4.20 |
Des calculs similaires devraient être effectués pour d'autres identificateurs d'enregistrement afin de déterminer leurs coefficients de conformité et de non-conformité. Ensuite, chaque identifiant d'un enregistrement est comparé à l'identifiant correspondant d'un autre enregistrement pour déterminer le poids total de la paire: le poids de la paire correspondante est ajouté au résultat total avec un total cumulé, tandis que le poids de la paire inappropriée est soustrait du résultat total. La quantité résultante est comparée aux valeurs de seuil identifiées pour déterminer s'il faut coupler automatiquement la paire analysée ou la transférer à l'opérateur pour examen.
Blocage
La détermination des seuils de conformité / non-conformité est un équilibre entre l'obtention d'une sensibilité acceptable (la part des enregistrements associés détectés par l'algorithme) et la valeur prédictive du résultat (c'est-à-dire l'exactitude, en tant que mesure des enregistrements réellement correspondants liés par l'algorithme). Étant donné que la définition de seuils peut être une tâche très difficile, en particulier pour les grands ensembles de données, une méthode connue sous le nom de blocage est souvent utilisée pour augmenter l'efficacité du calcul. Des tentatives sont faites pour effectuer une comparaison entre les enregistrements pour lesquels une différence significative ( discrimination ) dans les valeurs des attributs de base est révélée. Cela conduit à une augmentation de la précision due à une diminution de la sensibilité.
Par exemple, le verrouillage basé sur le codage phonétique d'un nom de famille réduit le nombre total de comparaisons nécessaires et augmente la probabilité que les relations entre les enregistrements soient correctes, car les deux attributs sont déjà cohérents, mais pourraient potentiellement ignorer les enregistrements liés à la même personne dont le nom de famille changé (par exemple, à la suite du mariage). Le blocage par mois de naissance est un indicateur plus stable qui ne peut être ajusté qu'en cas d'erreur dans les données source, mais offre un avantage plus modeste en termes de valeur prédictive positive et de perte de sensibilité, car il crée douze groupes différents d'ensembles de données extrêmement volumineux et n'entraîne pas une augmentation de la vitesse l'informatique.
Ainsi, les systèmes de liaison de saisie de texte les plus efficaces utilisent souvent plusieurs passes de blocage pour regrouper les données de diverses manières afin de préparer des groupes d'enregistrements qui devraient ensuite être soumis pour analyse.
Apprentissage automatique
Récemment, diverses méthodes d'apprentissage automatique ont été utilisées pour lier des enregistrements de texte. Dans un article de 2011, Randall Wilson a montré que l'algorithme de couplage probabiliste classique pour les enregistrements de texte est équivalent à l'algorithme naïf de Bayes et souffre des mêmes problèmes de l'hypothèse que les caractéristiques de classification sont indépendantes. Pour augmenter la précision de l'analyse, l'auteur propose d'utiliser un modèle de base d'un réseau neuronal appelé perceptron monocouche, dont l'utilisation permet de dépasser de manière significative les résultats obtenus à l'aide d'algorithmes probabilistes traditionnels.
Encodage phonétique
Les algorithmes phonétiques correspondent à deux mots prononcés de manière similaire avec les mêmes codes, ce qui vous permet de comparer ces mots en fonction de leur similitude phonétique.
La plupart des algorithmes phonétiques sont conçus pour analyser les mots anglais, bien que récemment certains algorithmes ont été modifiés pour être utilisés avec d'autres langues, ou ont été créés à l'origine comme solutions nationales (par exemple, Caverphone).
Soundex
L'algorithme classique pour comparer deux chaînes par leur son est Soundex (abréviation de Sound index). Il définit le même code pour les chaînes qui ont un son similaire en anglais. Soundex a été à l'origine utilisé par la US National Archives Administration dans les années 1930 pour analyser rétrospectivement les recensements de 1890 à 1920.
Les auteurs des algorithmes sont Robert C. Russel et Margaret King Odell, qui l'ont breveté dans les années 20 du siècle dernier. L'algorithme lui-même a gagné en popularité dans la seconde moitié du siècle dernier lorsqu'il est devenu le sujet de plusieurs articles dans des revues de vulgarisation scientifique aux États-Unis et a été publié dans la monographie de D. Knut «The Art of Programming».
Daitch-Mokotoff Soundex
Étant donné que Soundex ne convient que pour l'anglais, certains chercheurs ont tenté de le modifier. En 1985, Gary Mokotoff et Randy Daitch ont proposé une variante de l'algorithme Soundex, conçue pour comparer les noms de famille d'Europe de l'Est (y compris le russe) avec une qualité assez élevée.
Dans les années 90, Lawrence Philips (Lawrence Philips) a proposé une version alternative de l'algorithme Soundex, qui s'appelait Metaphone. Le nouvel algorithme a utilisé un ensemble plus large de règles pour la prononciation anglaise, grâce auquel il était plus précis. Plus tard, l'algorithme a été modifié pour être utilisé dans d'autres langues sur la base de la transcription en utilisant des lettres de l'alphabet latin.
En 2002, le 8e numéro du magazine Programmer a publié un article de Peter Kankowski racontant son adaptation de la version anglaise de l'algorithme Metaphone. Cette version de l'algorithme convertit les mots sources conformément aux règles et normes de la langue russe, en tenant compte du son phonétique des voyelles non accentuées et de la "fusion" possible des consonnes dans la prononciation.
Au lieu d'une conclusion
À la suite de plusieurs itérations, l'équipe de projet du projet de développement de produits logiciels, qui a été mentionnée dans l'introduction, a développé une solution architecturale, dont le schéma est illustré sur la figure.
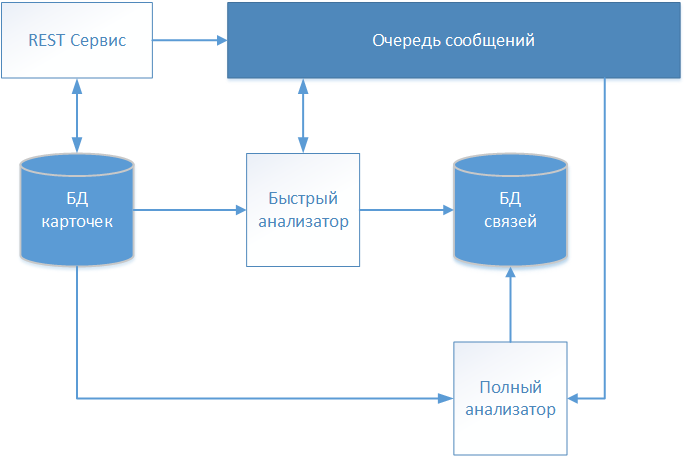
Les descriptions textuelles des patients sont acceptées via le service REST et stockées dans le référentiel (base de données de cartes) sans aucune modification. Comme notre système fonctionne avec des données médicales, la norme FHIR (Fast Healthcare Interoperability Resources) a été choisie pour l'échange d'informations. Les informations sur la carte patient reçue sont transférées dans la file d'attente de messages pour une analyse plus approfondie et une prise de décision sur l'établissement de la communication.
La première carte à traiter est le «Quick Analyzer» fonctionnant sur un algorithme déterministe. Si toutes les règles de l'algorithme déterministe ont fonctionné, il crée un enregistrement avec un lien vers la carte traitée dans un stockage séparé (base de données de liens). Le dossier contient en plus de l'identifiant de la carte analysée, la date d'établissement de la communication et un identifiant conditionnel qui identifie le patient globalement identifié. D'autres cartes sont en outre référées à l'identifiant global spécifié, formant ainsi un tableau décrivant un individu spécifique.
Si l'algorithme déterministe ne trouve pas de correspondance, les informations de la carte sont transmises via la file d'attente de messages à «l'analyseur complet».
( ). . :

1. -
, . 2.
2.
- , ().
3.
, , ( ) , .
4.
, . . , , . , , , .