Peu de gens ont un Glaster en Russie, et toute expérience est intéressante. Nous l'avons grand et industriel et, à en juger par la discussion dans le
dernier post , en demande. J'ai parlé du tout début de l'expérience de la migration des sauvegardes du stockage d'entreprise vers Glusterfs.
Ce n'est pas assez hardcore. Nous ne nous sommes pas arrêtés et avons décidé de collecter quelque chose de plus sérieux. Par conséquent, nous parlerons ici de choses telles que le codage d'effacement, le sharding, le rééquilibrage et sa limitation, les tests de résistance, etc.

- Plus de théorie du volume / sous-volume
- pièce de rechange chaude
- guérir / guérir complet / rééquilibrer
- Conclusions après le redémarrage de 3 nœuds (ne faites jamais cela)
- Comment l'enregistrement à différentes vitesses à partir de différentes machines virtuelles et l'activation / la désactivation des fragments affectent-ils la charge du sous-volume?
- rééquilibrage après le départ du disque
- rééquilibrage rapide
Que vouliez-vous
La tâche est simple: collecter un magasin bon marché mais fiable. Moins cher que possible, fiable - de sorte qu'il ne serait pas effrayant de stocker nos propres fichiers à vendre. Au revoir. Ensuite, après de longs tests et sauvegardes sur un autre système de stockage - également client.
Application (IO séquentielle) :
- Sauvegardes
- Tester les infrastructures
- Testez le stockage des fichiers multimédias lourds.
Nous y sommes.
- Fichier de bataille et infrastructure de test sérieuse
- Stockage des données importantes.
Comme la dernière fois, la principale exigence est la vitesse du réseau entre les instances de Glaster. 10G au début, c'est bien.
Théorie: qu'est-ce que le volume dispersé?
Le volume dispersé est basé sur la technologie de codage d'effacement (EC), qui fournit une protection assez efficace contre les pannes de disque ou de serveur. C'est comme RAID 5 ou 6, mais pas vraiment. Il stocke le fragment codé du fichier pour chaque brique de telle manière que seul un sous-ensemble des fragments stockés dans les briks restants est requis pour restaurer le fichier. Le nombre de briques indisponibles sans perte d'accès aux données est configuré par l'administrateur lors de la création du volume.
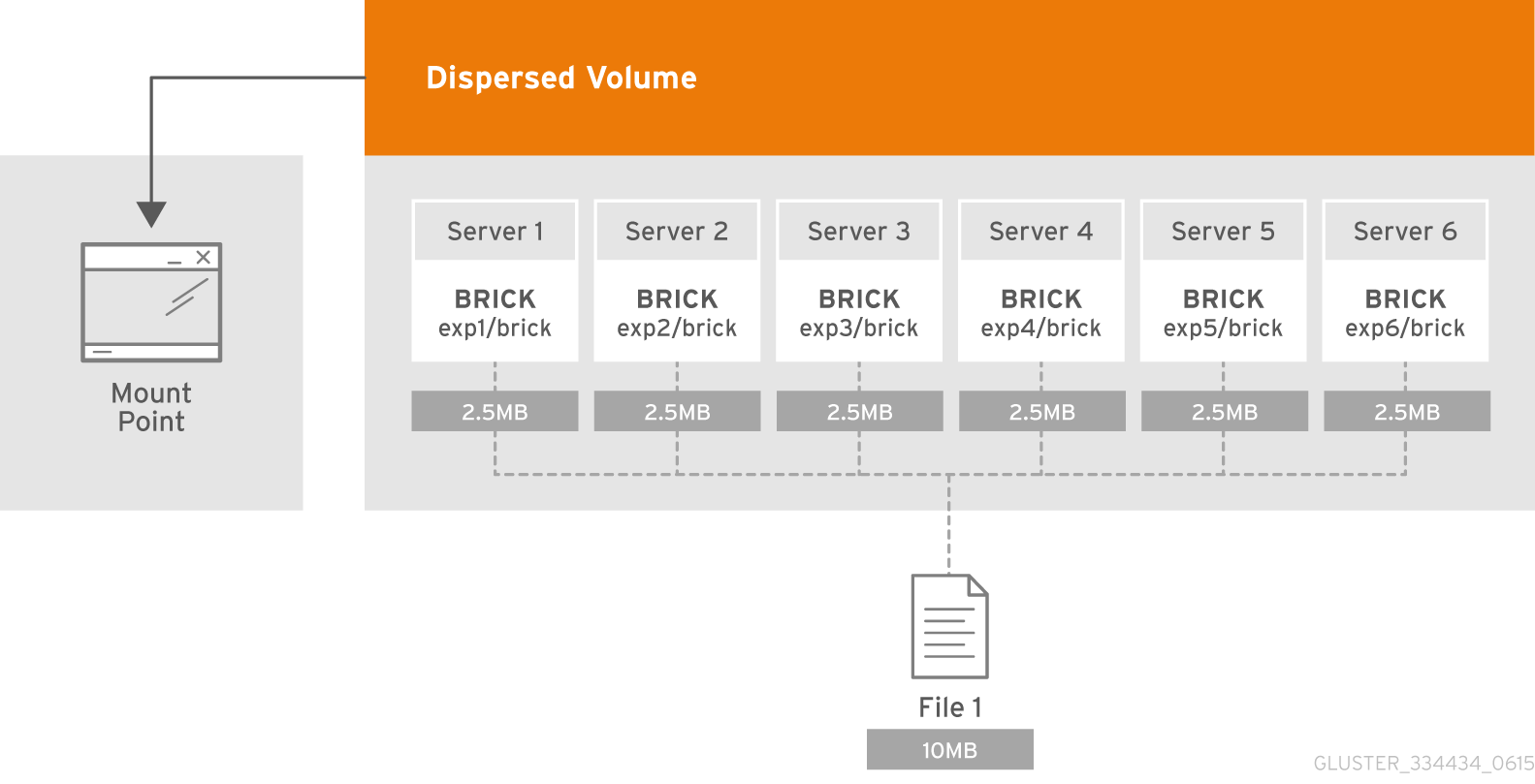
Qu'est-ce qu'un sous-volume?
L'essence du sous-volume dans la terminologie de GlusterFS se manifeste avec les volumes distribués. En effacement distribué-dispersé, le codage ne fonctionnera que dans le cadre du subwoofer. Et dans le cas, par exemple, avec des données répliquées distribuées seront répliquées dans le cadre du subwoofer.
Chacun d'eux est distribué sur des serveurs différents, ce qui leur permet de perdre librement ou de se synchroniser. Sur la figure, les serveurs (physiques) sont marqués en vert, les sous-loups sont en pointillés. Chacun d'eux est présenté comme un disque (volume) au serveur d'applications:

Il a été décidé que la configuration 4 + 2 distribuée-dispersée sur 6 nœuds semble assez fiable, nous pouvons perdre 2 serveurs ou 2 disques dans chaque caisson de basses, tout en continuant d'avoir accès aux données.
Nous avions à notre disposition 6 anciens DELL PowerEdge R510 avec 12 emplacements de disque et 48 disques SATA de 48x2 To. En principe, s'il existe un serveur avec 12 emplacements de disque et ayant jusqu'à 12 To de disques sur le marché, nous pouvons collecter jusqu'à 576 To d'espace de stockage utilisable. Mais n'oubliez pas que même si les tailles maximales de disques durs continuent de croître d'année en année, leurs performances restent immobiles et une reconstruction d'un disque de 10 à 12 To peut vous prendre une semaine.
 Création de volume:
Création de volume:Une description détaillée de la façon de préparer des briques, vous pouvez lire dans mon
post précédentgluster volume create freezer disperse-data 4 redundancy 2 transport tcp \ $(for i in {0..7} ; do echo {sl051s,sl052s,sl053s,sl064s,sl075s,sl078s}:/export/brick$i/freezer ; done)
Nous créons, mais nous ne sommes pas pressés de lancer et de monter, car nous devons encore appliquer plusieurs paramètres importants.
Ce que nous avons obtenu: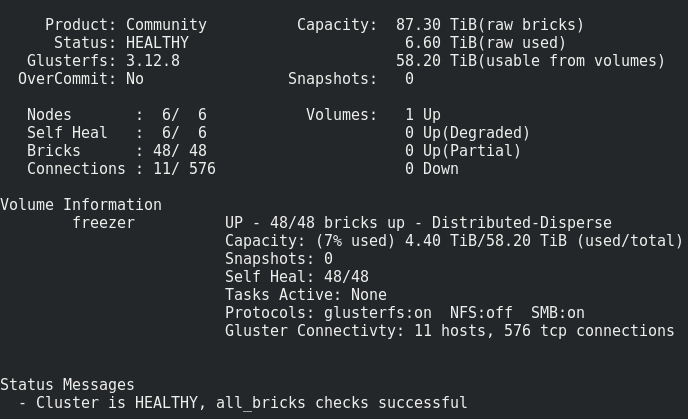
Tout semble tout à fait normal, mais il y a une mise en garde.
Il consiste à enregistrer un tel volume sur les briques:Les fichiers sont placés un par un dans les sous-loups et ne sont pas répartis uniformément entre eux.Par conséquent, tôt ou tard, nous rencontrerons sa taille, et non la taille de tout le volume. La taille de fichier maximale que nous pouvons mettre dans ce référentiel est la taille utilisable du subwoofer moins l'espace déjà occupé dessus. Dans mon cas, c'est <8 To.
Que faire? Comment être?Ce problème est résolu par le partitionnement ou le volume de bande, mais, comme la pratique l'a montré, la bande fonctionne très mal.
Par conséquent, nous allons essayer de partager.
Qu'est-ce que le sharding, en détail ici .
Qu'est-ce que le sharding, en bref :
Chaque fichier que vous placez dans un volume sera divisé en parties (fragments), qui sont disposées de manière relativement uniforme en sous-loups. La taille du fragment est spécifiée par l'administrateur, la valeur standard est de 4 Mo.
Activez le partitionnement après avoir créé un volume, mais avant qu'il ne commence :
gluster volume set freezer features.shard on
Nous définissons la taille du fragment (ce qui est optimal? Les mecs de oVirt recommandent 512 Mo) :
gluster volume set freezer features.shard-block-size 512MB
Empiriquement, il s'avère que la taille réelle du fragment dans les briques lors de l'utilisation du volume dispersé 4 + 2 est égale à shard-block-size / 4, dans notre cas 512M / 4 = 128M.
Chaque éclat selon la logique de codage d'effacement est décomposé selon les briques dans le cadre du sous-monde avec ces pièces: 4 * 128M + 2 * 128M
Dessinez les cas de défaillance qui survivent avec cette configuration:Dans cette configuration, nous pouvons survivre à la chute de 2 nœuds ou de 2 disques dans le même sous-volume.
Pour les tests, nous avons décidé de glisser le stockage résultant sous notre cloud et d'exécuter fio à partir de machines virtuelles.
Nous activons l'enregistrement séquentiel à partir de 15 machines virtuelles et procédons comme suit.
Redémarrage du 1er nœud:17:09
Il ne semble pas critique (~ 5 secondes d'indisponibilité par le paramètre ping.timeout).
17:19
Lancé guérir complètement.
Le nombre d'entrées de soins ne fait qu'augmenter, probablement en raison du niveau élevé d'écriture dans le cluster.
17:32
Il a été décidé de désactiver l'enregistrement à partir de la machine virtuelle.
Le nombre d'entrées de soins a commencé à diminuer.
17:50
guérir fait.
Redémarrez 2 nœuds:Les mêmes résultats sont observés qu'avec le 1er nœud.Redémarrez 3 nœuds:Le point d'extrémité de transport émis par le point de montage n'est pas connecté, les machines virtuelles ont reçu une erreur io.
Après avoir allumé les nœuds, le Glaster s'est rétabli, sans interférence de notre côté, et le processus de traitement a commencé.Mais 4 machines virtuelles sur 15 n'ont pas pu augmenter. J'ai vu des erreurs sur l'hyperviseur:
2018.04.27 13:21:32.719 ( volumes.py:0029): I: Attaching volume vol-BA3A1BE1 (/GLU/volumes/33/33e3bc8c-b53e-4230-b9be-b120079c0ce1) with attach type generic... 2018.04.27 13:21:32.721 ( qmp.py:0166): D: Querying QEMU: __com.redhat_drive_add({'file': u'/GLU/volumes/33/33e3bc8c-b53e-4230-b9be-b120079c0ce1', 'iops_rd': 400, 'media': 'disk', 'format': 'qcow2', 'cache': 'none', 'detect-zeroes': 'unmap', 'id': 'qdev_1k7EzY85TIWm6-gTBorE3Q', 'iops_wr': 400, 'discard': 'unmap'})... 2018.04.27 13:21:32.784 ( instance.py:0298): E: Failed to attach volume vol-BA3A1BE1 to the instance: Device 'qdev_1k7EzY85TIWm6-gTBorE3Q' could not be initialized Traceback (most recent call last): File "/usr/lib64/python2.7/site-packages/ic/instance.py", line 292, in emulation_started c2.qemu.volumes.attach(controller.qemu(), device) File "/usr/lib64/python2.7/site-packages/c2/qemu/volumes.py", line 36, in attach c2.qemu.query(qemu, drive_meth, drive_args) File "/usr/lib64/python2.7/site-packages/c2/qemu/_init_.py", line 247, in query return c2.qemu.qmp.query(qemu.pending_messages, qemu.qmp_socket, command, args, suppress_logging) File "/usr/lib64/python2.7/site-packages/c2/qemu/qmp.py", line 194, in query message["error"].get("desc", "Unknown error") QmpError: Device 'qdev_1k7EzY85TIWm6-gTBorE3Q' could not be initialized qemu-img: Could not open '/GLU/volumes/33/33e3bc8c-b53e-4230-b9be-b120079c0ce1': Could not read image for determining its format: Input/output error
Difficile paiement 3 nœuds avec partitionnement désactivé Transport endpoint is not connected (107) /GLU/volumes/e0/e0bf9a42-8915-48f7-b509-2f6dd3f17549: ERROR: cannot read (Input/output error)
Nous perdons également des données, il n'est pas possible de restaurer.
Remboursez doucement 3 nœuds avec sharding, y aura-t-il une corruption de données?Il y en a, mais beaucoup moins (coïncidence?), J'ai perdu 3 des 30 disques.
Conclusions:- La guérison de ces fichiers se bloque sans fin, le rééquilibrage n'aide pas. Nous concluons que les fichiers sur lesquels l'enregistrement actif était en cours lorsque le 3e nœud a été désactivé sont perdus à jamais.
- Ne rechargez jamais plus de 2 nœuds dans une configuration 4 + 2 en production!
- Comment ne pas perdre de données si vous voulez vraiment redémarrer 3 nœuds ou plus? P Arrêtez l'enregistrement au point de montage et / ou arrêtez le volume.
- Les nœuds ou les briques doivent être remplacés dès que possible. Pour cela, il est hautement souhaitable d'avoir, par exemple, 1 à 2 briques de rechange à chaud dans chaque nœud pour un remplacement rapide. Et un nœud de rechange supplémentaire avec des briques en cas de vidage de nœud.
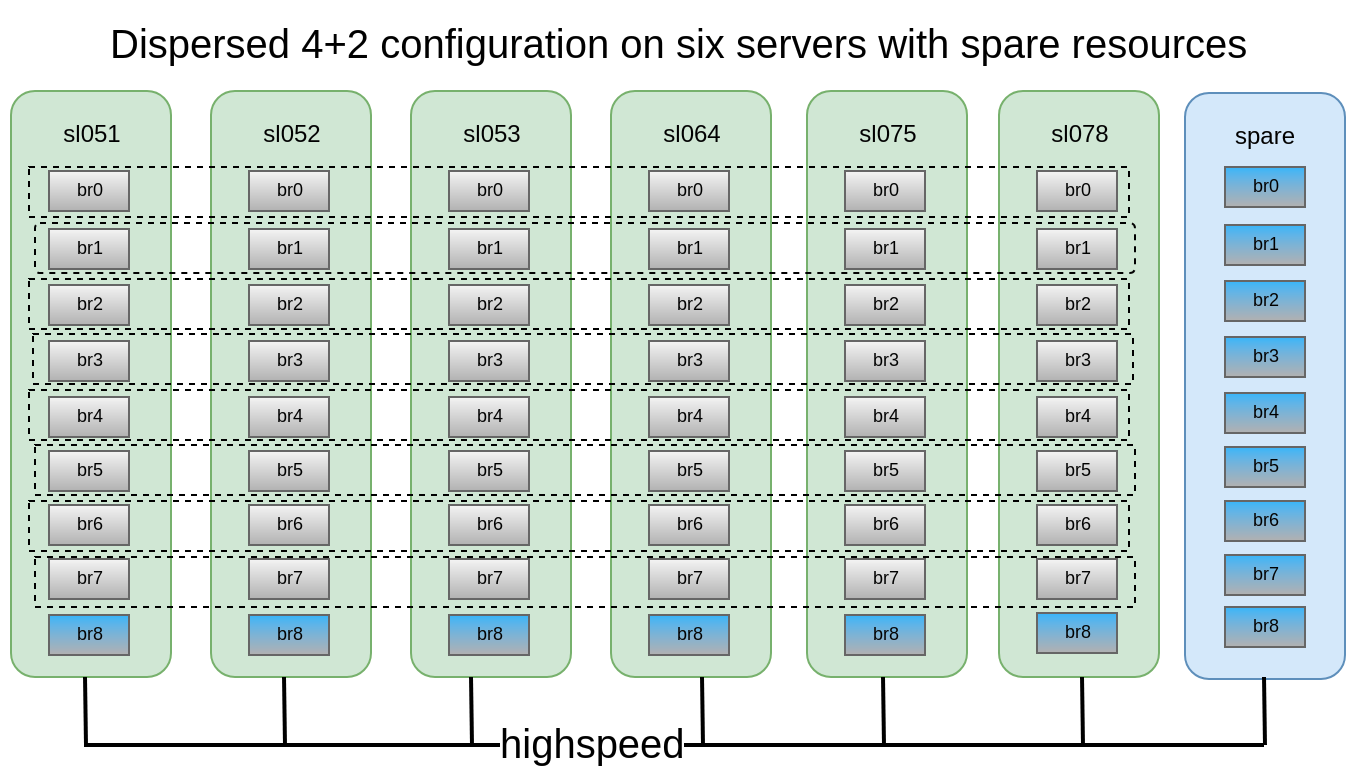
Il est également très important de tester les cas de remplacement de lecteur
Départs de briks (disques):
17:20Nous sortons une brique:
/dev/sdh 1.9T 598G 1.3T 33% /export/brick6
17:22 gluster volume replace-brick freezer sl051s:/export/brick_spare_1/freezer sl051s:/export/brick2/freezer commit force
Vous pouvez voir un tel rabattement au moment du remplacement de la brique (enregistrement à partir d'une source):

Le processus de remplacement est assez long, avec un petit niveau d'enregistrement par cluster et des paramètres par défaut de 1 To, il faut environ une journée pour récupérer.
Paramètres réglables pour le traitement: gluster volume set cluster.background-self-heal-count 20
Option: disperse.background-heals
Valeur par défaut: 8
Description: Cette option peut être utilisée pour contrôler le nombre de soins parallèles
Option: disperse.heal-wait-qlength
Valeur par défaut: 128
Description: cette option peut être utilisée pour contrôler le nombre de soins pouvant attendre
Option: disperse.shd-max-threads
Valeur par défaut: 1
Description: Nombre maximum de soins parallèles que SHD peut effectuer par brique locale. Cela peut réduire considérablement les temps de guérison, mais peut également écraser vos briques si vous ne disposez pas du matériel de stockage pour le prendre en charge.
Option: disperse.shd-wait-qlength
Valeur par défaut: 1024
Description: cette option peut être utilisée pour contrôler le nombre de soins pouvant attendre en SHD par sous-volume
Option: disperse.cpu-extensions
Valeur par défaut: auto
Description: forcer les extensions cpu à être utilisées pour accélérer les calculs du champ galois.
Option: disperse.self-heal-window-size
Valeur par défaut: 1
Description: Nombre maximum de blocs (128 Ko) par fichier pour lequel le processus d'auto-guérison serait appliqué simultanément.Stood:
disperse.shd-max-threads: 6 disperse.self-heal-window-size: 4 cluster.self-heal-readdir-size: 2KB cluster.data-self-heal-algorithm: diff cluster.self-heal-window-size: 2 cluster.heal-timeout: 500 cluster.background-self-heal-count: 20 cluster.disperse-self-heal-daemon: enable disperse.background-heals: 18
Avec de nouveaux paramètres, 1 To de données a été complété en 8 heures (3 fois plus vite!)
Le moment désagréable est que le résultat est un brik plus grand qu'il ne l'étaitétait: Filesystem Size Used Avail Use% Mounted on /dev/sdd 1.9T 645G 1.2T 35% /export/brick2
est devenu: Filesystem Size Used Avail Use% Mounted on /dev/sdj 1.9T 1019G 843G 55% /export/hot_spare_brick_0
Il faut comprendre. La chose gonfle probablement des disques minces. Avec le remplacement ultérieur de la brique augmentée, la taille est restée la même.
Rééquilibrage:Après avoir développé ou réduit (sans migrer les données) un volume (à l'aide des commandes add-brick et remove-brick respectivement), vous devez rééquilibrer les données entre les serveurs. Dans un volume non répliqué, toutes les briques doivent être en place pour effectuer l'opération de remplacement des briques (option de démarrage). Dans un volume répliqué, au moins une des briques de la réplique doit être en place.Façonner le rééquilibrage:Option: cluster.rebal-throttle
Valeur par défaut: normal
Description: définit le nombre maximal de migrations de fichiers parallèles autorisées sur un nœud pendant l'opération de rééquilibrage. La valeur par défaut est normale et autorise un maximum de [($ (unités de traitement) - 4) / 2), 2] fichiers à b
Nous avons migré à la fois. Lazy autorise la migration d'un seul fichier à la fois et l'agressif autorise un maximum de [($ (unités de traitement) - 4) / 2), 4]Option: migration cluster.lock
Valeur par défaut: off
Description: si elle est activée, cette fonction fera migrer les verrous posix associés à un fichier lors du rééquilibrageOption: rééquilibrage pondéré en cluster
Valeur par défaut: on
Description: Une fois activé, les fichiers seront attribués aux briques avec une probabilité proportionnelle à leur taille. Sinon, toutes les briques auront la même probabilité (comportement hérité).Comparaison de l'écriture, puis lecture des mêmes paramètres fio (résultats plus détaillés des tests de performances - en PM): fio --fallocate=keep --ioengine=libaio --direct=1 --buffered=0 --iodepth=1 --bs=64k --name=test --rw=write/read --filename=/dev/vdb --runtime=6000


 Si c'est intéressant, comparez la vitesse de rsync au trafic vers les nœuds Glaster:
Si c'est intéressant, comparez la vitesse de rsync au trafic vers les nœuds Glaster: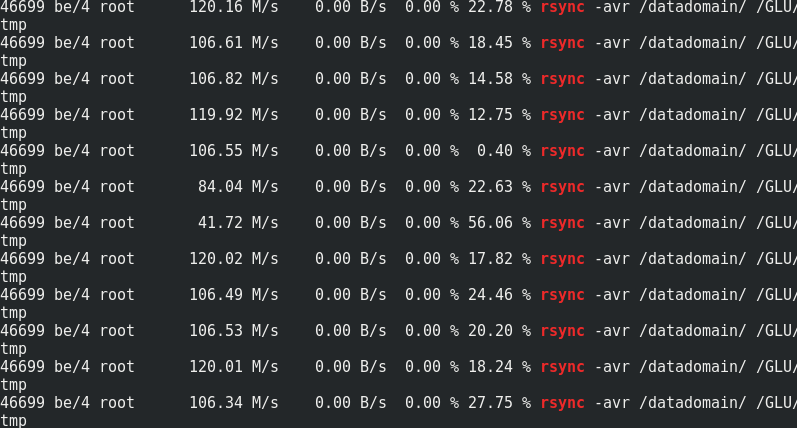
 On peut voir qu'environ 170 Mo / s / trafic à 110 Mo / s / charge utile. Il s'avère que cela représente 33% du trafic supplémentaire, ainsi que 1/3 de la redondance du codage d'effacement.La consommation de mémoire côté serveur avec et sans charge ne change pas:
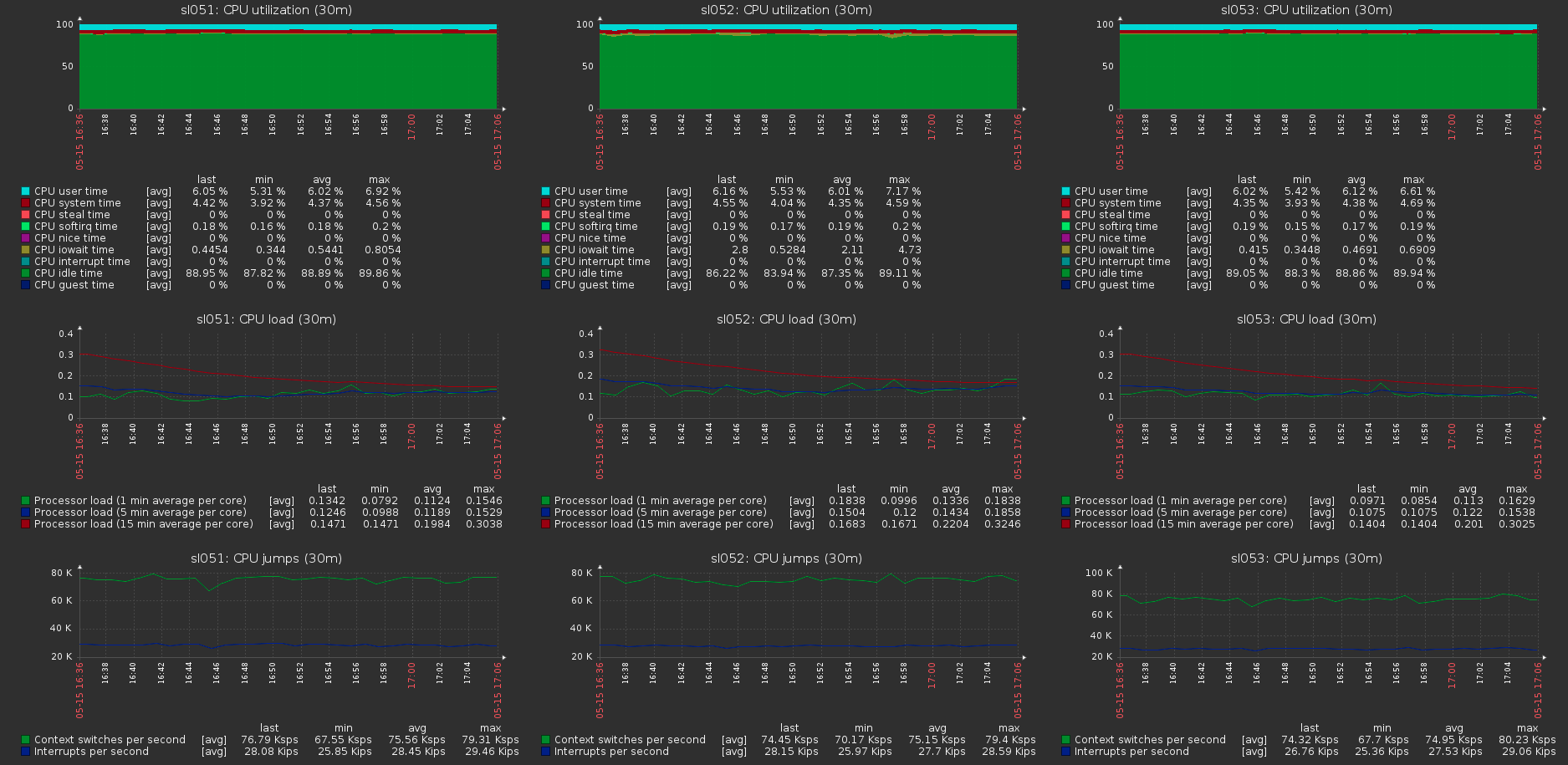
On peut voir qu'environ 170 Mo / s / trafic à 110 Mo / s / charge utile. Il s'avère que cela représente 33% du trafic supplémentaire, ainsi que 1/3 de la redondance du codage d'effacement.La consommation de mémoire côté serveur avec et sans charge ne change pas: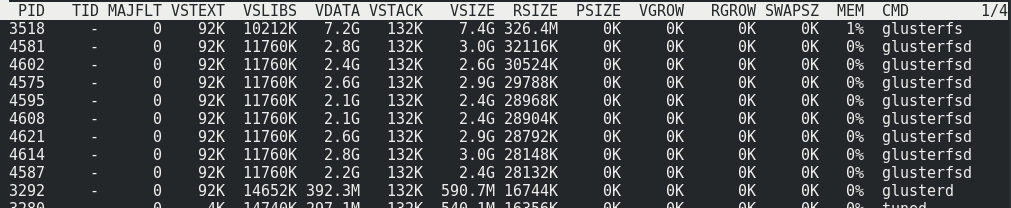 La charge sur les hôtes du cluster avec la charge maximale sur le volume:
La charge sur les hôtes du cluster avec la charge maximale sur le volume: