
En 2014, j'ai rejoint la petite équipe du Schibsted Media Group en tant que 6ème Data Science Specialist de cette entreprise. Depuis lors, j'ai travaillé sur de nombreuses initiatives dans le domaine de la science des données dans une organisation qui compte aujourd'hui plus de 40 personnes de ce type. Dans cet article, je parlerai de certaines des choses que j'ai apprises au cours des quatre dernières années, d'abord en tant que spécialiste, puis en tant que responsable de la science des données.
Ce billet suit l'exemple de Robert Chang et son excellent article, « Doing Data Science in Twitter », que j'ai trouvé très précieux lorsque je l'ai lu pour la première fois en 2015. Le but de ma propre contribution est de partager des réflexions tout aussi utiles avec des spécialistes et des gestionnaires de la science des données du monde entier.
J'ai divisé le message en deux parties:
- Partie I: La science des données dans la vraie vie
- Partie II: Gestion de l'équipe Data Science
Dans la partie I, je me suis concentré sur le travail effectué par les experts en science des données, tandis que la partie II explique comment gérer l'équipe de science des données le plus efficacement possible. Je dirais que les deux parties sont importantes pour les spécialistes et les gestionnaires.
Je ne passerai pas beaucoup de temps à décrire qui et qui est le spécialiste de la science des données et qui ne l'est pas - il y a suffisamment d'articles sur ce sujet partout sur Internet.
En bref sur Schibsted: les médias et les marchés dans plus de 20 pays à travers le monde. Je travaille principalement sur notre activité de marketplaces, où des millions de personnes achètent et vendent des marchandises chaque jour. Si vous souhaitez jeter un coup d'œil à quelques exemples concrets de travaux en science des données chez Schibsted, voici une petite sélection:
Dans cet esprit, plongeons-nous!
Partie I: La science des données dans la vraie vie
Commencer en tant que spécialiste de la science des données dans une nouvelle entreprise aux grandes ambitions est vraiment génial, mais cela peut aussi sembler effrayant. Qu'attendent les gens autour de moi? Quel niveau de compétence mes collègues auront-ils? Comment puis-je travailler pour être au service de l'entreprise? Dans une position autour de laquelle il y a tellement de battage médiatique, il est parfois difficile de ne pas se sentir comme un imposteur .
La peur d'être un simplet incite souvent un professionnel de la science des données à se concentrer principalement sur la complexité. Cela nous amène à la première conclusion.
1.1. La difficulté augmente la valeur, commencez simplement
Ils ont embauché un spécialiste de la science des données, donc ce problème doit sûrement être vraiment complexe, non?

Cette hypothèse vous induira souvent en erreur en tant que spécialiste de la science des données. Tout d'abord, les problèmes que vous rencontrez en entreprise sont très souvent résolus à l'aide de méthodes assez simples. Deuxièmement, il est important de se rappeler que la complexité augmente la valeur. Un modèle complexe impliquera probablement plus de travail sur sa mise en œuvre, un risque d'erreur plus élevé et plus de difficultés à l'expliquer aux clients. Par conséquent, vous devez toujours rechercher d'abord l'approche la plus simple.
Mais comment comprendre si l'approche la plus simple est suffisante?
1.2. Ayez toujours un modèle de base
Les estimations de la qualité de votre modèle, très probablement, n'ont pas de sens en elles-mêmes sans comparaison avec le modèle de base. La comparaison avec la précision avec une sélection aléatoire, dans la plupart des cas, n'est tout simplement pas suffisante.

À un moment donné, nous avons construit un modèle pour prédire la probabilité qu'un utilisateur revienne sur notre site - le modèle de retour. Environ 15 attributs basés sur le comportement des utilisateurs ont été utilisés dans notre modèle, et nous avons atteint une précision d'environ 0,8 ROC-AUC. En comparant avec la précision de la prédiction aléatoire (0,5), nous étions assez satisfaits de ce résultat. Mais lorsque nous avons tout jeté du modèle, à l'exception des deux signes les plus importants: récent (le nombre de jours depuis la dernière visite) et la fréquence (nombre de jours de visites dans le passé), nous avons constaté qu'une simple régression logistique sur ces deux variables nous donnait 78% ROC-AUC ! En d'autres termes, nous pourrions atteindre plus de 97% des performances en supprimant plus de 85% des attributs.
J'ai vu tant de fois comment les experts en science des données montrent les résultats d'expériences hors ligne sur des modèles complexes sans aucun modèle de base simple pour comparaison. Lorsque vous voyez cela, vous devez toujours vous demander: pourrions-nous obtenir le même résultat en utilisant un modèle beaucoup plus simple?
1.3. Utilisez les données dont vous disposez
J'ai déjeuné une fois avec un ingénieur de données et un autre spécialiste de la science des données. Les yeux de ce dernier se sont éclairés quand il a parlé de toutes les choses incroyables qu'il pouvait faire «si seulement il avait des données sur X, Y ou Z». À un moment donné au cours de la conversation, l'ingénieur a ri: «Vous, experts en science des données, parlez toujours de ce que vous pourriez faire avec des données que vous ne possédez pas. Que diriez-vous de faire quelque chose avec les données dont vous disposez? »

Cela semblait grossier, mais l'ingénieur a exprimé une vérité importante. Vous n'aurez jamais le jeu de données parfait et il y aura toujours des données que vous pourrez utiliser. Dans la plupart des cas, vous pouvez faire quelque chose avec ce que vous avez.
1.4 Prendre la responsabilité des données
Comme indiqué ci-dessus, la qualité et l'exhaustivité des données sont presque toujours un problème. Mais au lieu de rester assis et d'attendre que quelqu'un vous présente des données sur un plateau d'argent, vous devez parler et assumer la responsabilité des données dont vous avez besoin.

Je ne parle pas de propriété formelle dans le sens d'un modèle de gestion des données. Je parle d'élargir mon rôle et d'aider, dans la mesure du possible, à obtenir les données dont vous avez besoin.
Cela peut signifier participer à la création de schémas et de formats de collecte de données. Cela peut signifier de regarder le code Javascript exécuté dans l'interface de l'application Web pour vous assurer que les événements sont déclenchés comme il se doit. Ou cela pourrait signifier la construction de pipelines de données sans attendre que les ingénieurs de données fassent tout pour vous.
1.5. Oubliez les données
Évidemment, cela contredit tout ce que j'ai dit ci-dessus, mais il est très important de ne pas trop se concentrer sur les données dont vous disposez.

Lorsqu'un nouveau problème apparaît, vous devez d'abord essayer d'oublier les données existantes. Pourquoi Oui, car vos données existantes peuvent limiter l'espace de décision, ce qui peut vous distraire de trouver la meilleure approche. Vous serez coincé dans un optimum local, où vous essayez de trouver la solution à tout problème sur l'ensemble de données qui est à votre disposition (utilisation au-delà de l'apprentissage). Par conséquent, vous n'aurez jamais de nouveaux jeux de données.
1.6. Développer une compréhension détaillée de la causalité
Nous savons tous que la corrélation n'implique pas une relation causale. Le problème est que de nombreux experts en Data Science s'arrêtent à cela et ont peur de relier la cause à l'effet.

Pourquoi est-ce un problème? Parce que les chefs de produit, l'équipe marketing, votre PDG, ou avec qui vous travaillez là-bas, ne sont pas du tout inquiets de la corrélation. Ils se soucient d'une relation causale.
Le chef de produit veut être sûr que lorsqu'il décidera de publier cette nouvelle fonctionnalité, il déclenchera une augmentation de 10% de l'implication du produit. L'équipe marketing souhaite savoir que l'augmentation du nombre de lettres de 2 par semaine à 4 n'obligera pas les utilisateurs à se désinscrire de la newsletter. Et le PDG veut savoir qu'investir dans un meilleur ciblage entraînera une augmentation des revenus publicitaires.
Eh bien, existe-t-il une solution de compromis? Il s'avère qu'il y en a deux.
Les expériences en ligne les plus célèbres. En fait, vous exécutez des essais randomisés, parmi eux les tests A / B les plus populaires. L'idée est simple: puisque nous avons accidentellement choisi qui sera dans le groupe cible et qui sera dans le groupe témoin, alors si nous trouvons une différence statistiquement significative entre les groupes, le «traitement» que nous avons utilisé peut être considéré comme la raison. Sans entrer dans le raisonnement philosophique, dans la pratique, c'est une hypothèse raisonnable.
La modélisation causale est une approche moins connue de la recherche de relations causales. L'idée ici est de faire des hypothèses sur la structure causale du monde, puis d'utiliser des données d'observation (non expérimentales) pour vérifier si ces hypothèses sont cohérentes avec les données, ou pour évaluer la force de diverses relations de cause à effet. Adam Kelleher a écrit une grande série d'articles, « Causal Data Science », que je recommande de lire. En outre, la Bible de causalité est le livre Causalité de Judea Pearl.
D'après mon expérience, la plupart des experts en science des données ont une vaste expérience dans la création de modèles d'apprentissage automatique et leur évaluation hors ligne. Beaucoup moins de gens ont de l'expérience en matière d'évaluation et d'expérimentation en ligne. L'explication est simple: vous pouvez télécharger l'ensemble de données depuis Kaggle, former le modèle et l'évaluer hors ligne en quelques minutes. Pour évaluer ce modèle en ligne, en revanche, vous devez avoir accès au monde réel. Même si vous travaillez dans une entreprise Internet avec des millions d'utilisateurs, vous devez souvent surmonter de nombreux obstacles pour exposer votre modèle d'apprentissage automatique aux utilisateurs.
Maintenant, alors que peu d'experts en science des données ont une vaste expérience de l'évaluation en ligne, très peu ont une expérience de la modélisation causale. Je pense qu'il y a plusieurs bonnes raisons. L'une des raisons est que la plupart des livres sur la causalité sont assez théoriques, parmi eux il y a peu de directives pratiques sur la façon de commencer la modélisation causale dans le monde réel. Je prédis qu'au cours des prochaines années, nous verrons des directives plus pratiques pour la modélisation causale.
Développer une compréhension détaillée de la causalité vous permettra de donner des recommandations pratiques à vos clients tout en soutenant votre intégrité en tant que spécialiste de la science des données.
Partie II: Gestion de l'équipe Data Science
Schibsted, comme de nombreuses autres entreprises, a deux parcours professionnels: en tant que travailleur indépendant et en tant que leader. Dans le cadre de la Data Science, le premier s'adresse à ceux qui souhaitent vraiment approfondir leurs connaissances dans le domaine de la Data Science et contribuer à l'entreprise par des travaux pratiques et un leadership technique. Le chemin du leadership est pour ceux qui sont plus passionnés par le développement des personnes et la gestion d'équipe.
Je ne savais pas du tout quel chemin me convenait, mais finalement j'ai décidé d'essayer le chemin du leader. Il ne s'est pas passé beaucoup de temps lorsque j'ai réalisé que c'était vraiment la bonne façon pour moi, mais bien sûr, j'ai rencontré beaucoup de problèmes (et je le fais toujours!).
Le premier défi auquel vous serez confronté est qu'il existe très peu d'autres responsables de la Data Science dans le monde. Si vous pensiez que les spécialistes expérimentés en science des données sont rares, alors les gestionnaires expérimentés de la science des données sont beaucoup moins nombreux. Ainsi, vous êtes plus ou moins laissé à vous-même.
Mais est-il vrai que la gestion d'une équipe Data Science est si différente de la gestion d'autres types d'équipes? Oui et non.
Si vous n'avez jamais dirigé une équipe auparavant, vous pouvez probablement trouver le matériel de lecture classique pour la gestion comme la gestion à haut rendement d' Andrew Grove. En outre, le recours proactif à des cadres supérieurs (d'autres disciplines) pour obtenir des conseils est également crucial.
Cependant, les équipes de Data Science ont plusieurs différences clés, nous allons donc maintenant nous concentrer sur les conclusions, en particulier celles liées aux équipes de Data Science.
2.1. L'équipe Data Science n'est pas vraiment une équipe
Quand la plupart des gens pensent aux équipes, ils pensent à quelque chose comme ça:

Quelles sont les caractéristiques d'une équipe de football comme le FC Barcelone? Au moins trois choses:
- Objectif commun
- Différents rôles dans l'équipe, chacun avec des responsabilités différentes
- Indépendance pour atteindre votre objectif
Si vous gérez une équipe composée uniquement de spécialistes de la science des données, il est fort probable qu'aucune de ces caractéristiques ne soit remplie. Au lieu de cela, votre équipe aura:
- Des objectifs multiples et changeants
- Des spécialistes, et ils sont bons à la même chose: Data Science
- D'autres équipes avec lesquelles vous pouvez travailler pour avoir un impact final sur les utilisateurs et les revenus
Une analogie plus appropriée qu'une équipe de football pour une équipe de spécialistes de la science des données est:
La demande pour les services de Mulder et Scully évolue avec le temps. Ils sont attirés lorsque leur expérience est requise. Et ils ne résoudront jamais le problème sans parler à des personnes extérieures au FBI.
Pourquoi cette distinction est-elle importante?
Parce que si vous avez une équipe d'experts en Data Science et que vous les gérez comme une équipe «classique» avec un objectif commun, des rôles variés et une autonomie complète, vous obtiendrez rapidement une équipe frustrée.
J'ai vu des équipes de Data Science gérées comme n'importe quel autre produit ou équipe de développement, et la conséquence inévitable de cela est que les spécialistes de Data Science commencent à faire autre chose que Data Science. Au lieu de cela, ils finissent par développer, décomposer ou gérer le produit.
Les experts en science des données sont donc différents. Mais comment garantissez-vous alors que votre Data Science ne vivra pas dans une tour d'ivoire?
2.2. Intégrer des professionnels de la science des données dans d'autres équipes
La magie opère lorsque vous associez des experts en science des données à des chefs de produit, des programmeurs, des chercheurs en interface, des spécialistes du marketing, etc.
Simplement, la fonction objective que vous souhaitez maximiser est la suivante: interaction fructueuse entre les spécialistes de la science des données de votre équipe et les personnes des autres équipes.
J'aime y penser en utilisant le concept de canal large. Illustrons cela avec un chef de produit associé à un spécialiste de la science des données.
Le pire de tous, quand il n'y a pas de canal entre eux:

Cela signifie qu'il n'y a pas de communication entre DS et PM. En d'autres termes, DS ne sera au courant d'aucun problème de produit auquel PM est confronté, ce qui rend impossible l'analyse ou la résolution de ces problèmes.
Un peu mieux quand nous avons un canal étroit entre eux:
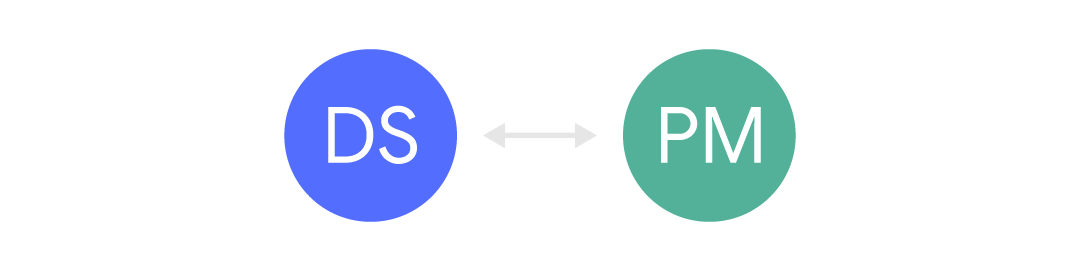
Dans ce cas, les informations viennent, mais généralement limitées et souvent de manière asynchrone. Les informations proviennent d'autres personnes (par exemple, un autre gestionnaire) ou de formulaires de demande, etc. Ce type de communication est courant lorsque l'on s'attend à ce que les spécialistes de la science des données servent de nombreux clients différents. Mais cela peut être frustrant, car le contexte commercial est souvent absent, ce qui peut conduire à des malentendus et à des histoires stupides.
La condition la plus efficace est lorsque nous avons un canal large:

Dans le sens le plus littéral, un canal large est lorsqu'un spécialiste de la science des données est assis à côté d'un chef de produit. Bien entendu, cela leur permet de communiquer beaucoup plus efficacement. Garder les gens physiquement proches n'est pas toujours pratique ni même possible (nous, chez Schibsted, sommes dispersés dans 22 pays différents!), Mais il existe des versions virtuelles de ce principe: de Slack à la programmation de paires distantes et Hangouts.
Naturellement, il ne sera pas possible pour chaque chef de produit de l'entreprise d'organiser un large canal avec chaque spécialiste Data Science de votre équipe, cela ne va pas. Votre tâche en tant que responsable de Data Science est de déterminer quand organiser quels canaux larges. Et puis dégagez!
L'un des cas à Schibsted lorsque nous travaillions activement à la création d'un large canal était le développement de notre outil de tarification de voiture, qui vous aide à fixer le prix lors de la vente de votre voiture ( essayez-le sur notre marché finlandais en Norvège ). Au départ, nous avions un canal assez mince, comme celui-ci: «Essayez de créer le modèle de tarification le plus précis possible.» Nous avons trouvé cela assez inefficace, car il y avait de nombreuses questions sur les produits auxquelles nous ne pouvions pas répondre sans expérimenter avec les utilisateurs au début.
Cependant, après un certain temps, tout s'est terminé par le fait que nous avons intégré l'un de nos spécialistes de la science des données dans l'équipe produit, et nous avons obtenu de bien meilleurs résultats. Vous pouvez lire sur certains de nos premiers travaux sur un outil d'évaluation des voitures dans ce post .
Un exemple de quand nous avions une large chaîne depuis le tout début est un modèle de prévision pour les nouveaux abonnements numériques . Le modèle a contribué à augmenter les conversions de ventes de 540% et a été récompensé par le prix INMA de la meilleure utilisation des données en 2017.
2.3. Prenez en charge la productivité analytique
Andrew Grove déclare dans le livre High Output Management que vous, en tant que manager, possédez les résultats de votre équipe. Cela signifie que le responsable Data Science doit investir dans la création du meilleur environnement possible pour que ses spécialistes Data Science soient productifs.

Cela est à bien des égards contraire au modèle d'intégration décrit ci-dessus. Si vous intégrez tout tout le temps, il y a une forte probabilité que vous obtiendrez ainsi des entrepôts de données et une infrastructure non optimale, dupliqués plusieurs fois.
Certains responsables du développement affirment que lorsque vous devenez un leader, vous devez complètement arrêter de coder. , Data Science 10% : , . . Data Science.
« 15 , , , , ad-hoc ?! , ».
« ― ?»
.
, . , , , Data Science.
, Lean Management, Data Science. XKCD :
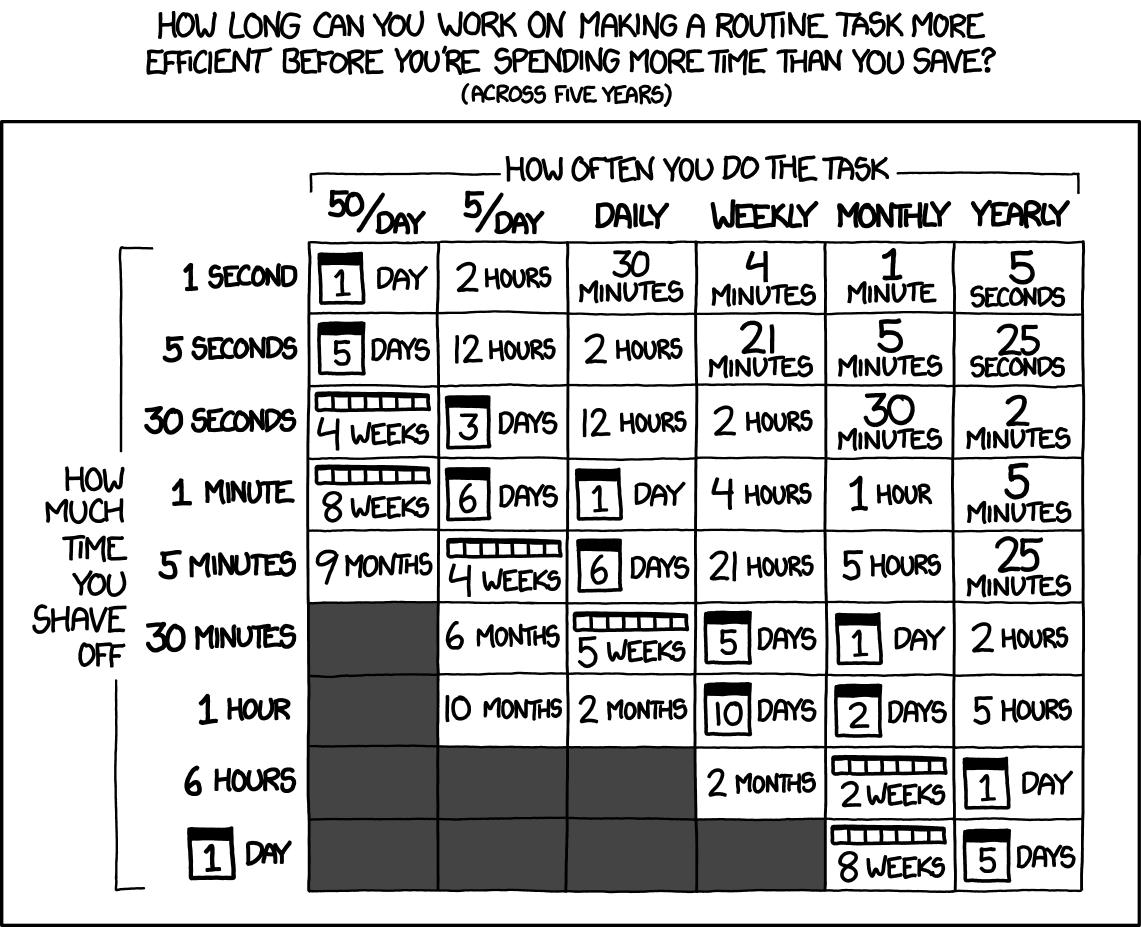
, Data Science . !
2.4. -> ->
«» , Data Science, . Data Science . , , , .

:
- . 98% , , (… , ).
- , , - , .
, Data Science, , , , .
, , .
, , , , . , .
, ― . , . . Slack . ( !) , .
. . , !
, ? , , . , , , Data Science.
. , , , , . .
2.5. ,
Data Science. , . , , - , ?
Ferrari, .

, .

Ferrari , .

Data Science ― , , . , , , , (ROI).
Data Science. - , .
, , . , , , , ― , . , , .
, Data Science . , . , , , .
2.6. OKR
, Data Science. Objectives and Key Results (OKR). , OKR ― , . , . OKR , .
OKR , , , , .
, OKR , . , : , .
, , OKR.
-: OKR. OKR , , , . « », . , . , .
LSTM ? , NLP-, , LSTM . ? . ? , .
OKR, .
, OKR . , .
-: OKR . , . , :
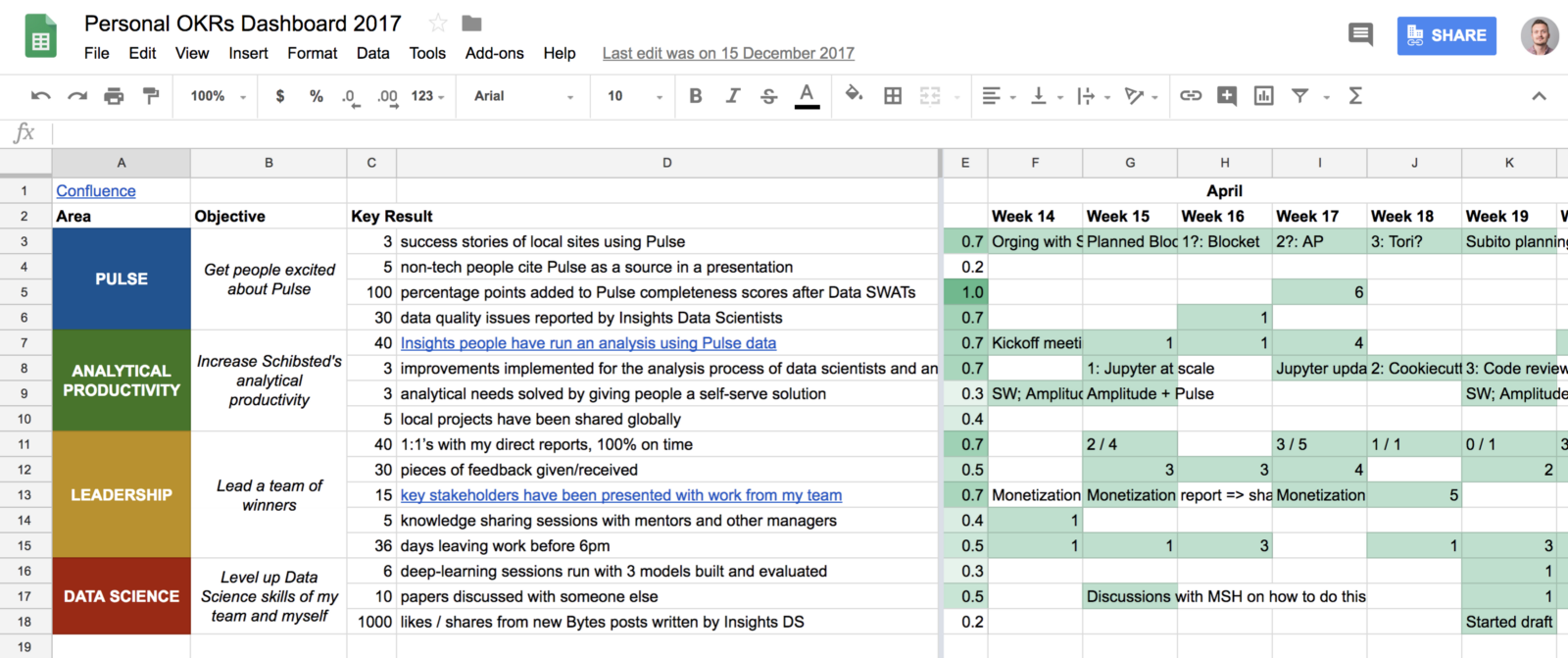
, , 10 , . , , ― . . OKR .
, , OKRs ― .
2.7.
Et à la fin, le point le plus important.
Lorsque Google a étudié ses équipes pendant deux ans pour découvrir ce qui fait que certaines équipes fonctionnent bien et d'autres le rendent moins efficace, il y a une chose qui s'est démarquée. C'est la sécurité psychologique .
En bref, la sécurité psychologique peut être résumée comme la croyance que vous ne serez pas puni en cas d'erreur.
Réfléchissez maintenant à cela dans le contexte de l'introduction à la partie I. Le syndrome de l'imposteur est très important en science des données. De quoi avez-vous peur quand vous vous sentez comme un imposteur? Faites des erreurs.
Au fil des ans, j'ai découvert que des gens de divers domaines viennent à la science des données. Au sein de notre équipe Schibsted, nous avons la chance d'avoir des gens fantastiques avec un très large éventail d'expérience. Personnes ayant de l'expérience en finance, recherche, éducation, conseil, développement de logiciels, etc.
Il serait insensé de supposer que tous ces gens savent la même chose. Au contraire, la valeur d'une expérience aussi diversifiée réside dans le fait que chacun apporte quelque chose de nouveau à l'équipe.
L'idée d'une Data Science «licorne» est un poison pour la sécurité psychologique.
Existe-t-il une solution rapide pour augmenter la sécurité psychologique? Je ne pense pas. Mais je pense que cela devrait être en haut de votre liste de priorités en tant que manager - en particulier lorsque vous créez une nouvelle équipe ou lorsque de nouveaux membres vous rejoignent. Bien qu'il n'y ait pas de solution miracle, il existe des mesures claires que vous pouvez prendre pour accroître la sécurité psychologique. Voici certains de ceux qui ont bien fonctionné pour nous:
- Créez une culture de rétroaction . Expliquez clairement que les membres de votre équipe sont tenus de se communiquer «les avantages et les améliorations» après les présentations, les sprints, etc. Soit dit en passant, vous, en tant que manager, devez le faire aussi! Et apprenez aux gens comment donner des commentaires constructifs correctement - ce n'est pas une chose naturelle pour tout le monde.
- Augmentez le temps face à face . Programmation en binôme, résolution de problèmes sur la carte ... Ceci est particulièrement important pour les équipes distantes. Ce billet vaut presque certainement l'argent.
- Créez des paires ou des équipes au lieu d'un travail individuel. Vous finirez peut-être par faire moins de choses dans l'équipe, mais vous le ferez mieux. Et ceux qui travaillent ensemble établiront une confiance mutuelle.
- Encouragez les discussions ouvertes et honnêtes lors des réunions. Travaillez activement pour équilibrer le temps d'antenne de tous les participants - il peut être nécessaire de demander à certaines personnes de parler.
- N'oubliez pas les différences culturelles . Vous pouvez provenir d'une culture égalitaire, explicite et directe . Il y a une forte probabilité que vous manquiez des signaux d'un membre de l'équipe provenant d'une culture hiérarchique, implicite et indirecte.
- Mener des expériences de groupe pour une amélioration continue. Impliquer toute l'équipe dans le problème «Comment gérer une équipe avec succès» donne à chacun le sens des responsabilités pour le bien-être de l'équipe.
- Mesurez le bonheur et la sécurité psychologique. Trouvez un moyen facile de poser régulièrement des questions sur le bonheur et la sécurité psychologique. Si vous ne disposez pas d'un système RH à la mode à ces fins, commencez simplement par Typeform et parcourez jusqu'à ce que vous et l'équipe le trouviez utile. Partagez (anonymes) les notes ou les résultats moyens avec l'équipe et incluez-les dans la façon d'améliorer la situation.
...
Félicitations, vous avez atteint la fin! J'espère que ce post vous a été un peu utile en tant que spécialiste ou gestionnaire de Data Science.
Nous avons traversé pas mal de choses, voici une courte liste:
Partie I: La science des données dans la vraie vie
1.1. La complexité augmente la valeur, commencez par simple
1.2. Ayez toujours un modèle de base
1.3. Utilisez les données dont vous disposez
1.4. Prendre en charge les données
1.5. Oubliez les données
1.6. Développer une compréhension détaillée de la causalité
Partie II: Gestion de l'équipe Data Science
2.1. L'équipe Data Science n'est pas vraiment une équipe
2.2. Intégrer des professionnels de la science des données dans d'autres équipes
2.3. Prenez en charge la productivité analytique
2.4. Données -> Pouvoir -> Politique
2.5. Utilisez vos ressources, visez un retour sur investissement élevé
2.6. OKR pour la mise au point et l'alignement
2.7. Tout d'abord, la sécurité psychologique
...
Merci d'avoir lu! Si cela vous a été utile, envisagez de partager ce message avec d'autres personnes. J'espère voir un jour vos propres réflexions sur le travail en tant que spécialiste ou responsable de la science des données