Bonjour à tous! Je m'appelle Misha Kamenshchikov, je suis engagée dans la Data Science et le développement de microservices dans l'équipe de recommandations Avito. Dans cet article, je vais parler de nos recommandations pour des annonces similaires et de la façon dont nous les améliorons avec des bandits multi-armés. J'ai fait une présentation sur ce sujet lors de la conférence Highload ++ Siberia et lors de l'événement "Data & Science: Marketing" .

Aperçu de l'article
Recommandations sur Avito
Tout d'abord, un bref aperçu de tous les types de recommandations qui sont sur Avito.
Recommandations personnalisées d'articles utilisateur
Les recommandations User-Item sont basées sur les actions de l'utilisateur et sont conçues pour l'aider à trouver rapidement le produit qui l'intéresse ou à montrer quelque chose de potentiellement intéressant. Ils sont visibles sur la page principale du site et des applications ou dans les listes de diffusion. Pour créer de telles recommandations, nous utilisons deux types de modèles: hors ligne et en ligne.
Les modèles hors ligne sont basés sur des algorithmes de factorisation matricielle qui sont formés sur toutes les données en quelques jours, et les recommandations sont stockées dans un magasin rapide pour distribution aux utilisateurs. Les modèles en ligne prennent en compte les recommandations à la volée en utilisant le contenu des annonces de l'historique de l'utilisateur. L'avantage des modèles hors ligne est qu'ils fournissent des recommandations plus précises et de haute qualité, mais ils ne prennent pas en compte les dernières actions des utilisateurs qui pourraient se produire pendant la formation du modèle, lorsque l'échantillon de formation a été corrigé. Les modèles en ligne répondent immédiatement aux actions des utilisateurs et les recommandations peuvent changer à chaque action.
Recommandations de démarrage à froid
Tous les systèmes de recommandation ont un problème dit de «démarrage à froid». Cela signifie que les modèles décrits ci-dessus ne peuvent pas donner de recommandations à un nouvel utilisateur sans historique des actions. Dans de tels cas, il est préférable de familiariser l'utilisateur avec ce qui se trouve sur le site, tout en choisissant non seulement des annonces aléatoires, mais, par exemple, des annonces de catégories populaires dans la région de l'utilisateur.
Recommandations de recherche
Pour les utilisateurs qui utilisent souvent la recherche, nous proposons des raccourcis recommandés pour la recherche - ils envoient l'utilisateur vers une catégorie spécifique et définissent des filtres. Ces recommandations se trouvent en haut de la page principale de l'application.
Recommandations article par article
Les recommandations article par article sont présentées sur le site sous forme d'annonces similaires sur la fiche produit. Ils sont visibles sur toutes les plateformes sous la description de l'annonce. Le modèle de recommandation est actuellement exclusivement contenu et n'utilise pas d'informations sur les actions des utilisateurs, nous pouvons donc immédiatement en récupérer des similaires parmi les annonces actives sur le site pour une nouvelle annonce. Plus loin dans l'article, je parlerai de ce type particulier de recommandation.
Plus en détail sur tous les types de recommandations sur Avito, nous avons déjà écrit dans notre blog. Lisez si vous êtes intéressé.
Annonces similaires
Voici à quoi ressemble un bloc avec des annonces similaires:

Ce type de recommandation est apparu tout d'abord sur le site, et la logique a été implémentée sur le moteur de recherche Sphinx . En fait, ce modèle est une combinaison linéaire de divers facteurs: correspondance des mots, distance, différence de prix et autres paramètres.
En fonction des paramètres de l'annonce cible, une demande est générée dans Sphinx et des classeurs intégrés sont utilisés pour le classement.
Exemple de demande:
SELECT id, weight as ranker_weight, ranker_weight * 10 + (metro_id=42) * 5 + (location_id=2525) * 10 + (110000 / (abs(price - 1100000) + 110000)) * 5 as rel FROM items WHERE MATCH('@title |scott|scale|700|premium') AND microcat_id=100 ORDER BY rel DESC, sort_time DESC LIMIT 0,32 OPTION max_matches=32, ranker=expr('sum(word_count)')
Si vous essayez de décrire cette approche de manière plus formelle, vous pouvez imaginer les classeurs sous la forme de poids et les paramètres des annonces (la source est l'annonce d'origine) et (annonce ciblée). Pour chacun des paramètres, nous introduisons la fonction de similarité . Ils peuvent être binaires (par exemple, la coïncidence de la ville de l'annonce), peuvent être discrets (la distance entre les annonces) et continus (par exemple, la différence relative de prix). Ensuite, pour deux annonces, le score final sera exprimé par la formule
Le moteur de recherche vous permet de lire rapidement la valeur de cette formule pour un nombre d'annonces suffisamment important et de classer la diffusion en temps réel.
Cette approche se montrait assez bien dans sa forme originale, mais elle présentait des inconvénients importants.
Problèmes d'approche
Premièrement, les poids ont été initialement sélectionnés de manière experte et ne faisaient aucun doute. Parfois, il y a eu des changements de poids, mais ils ont été faits sur la base d'une rétroaction ponctuelle, et non sur la base d'une analyse du comportement des utilisateurs en général.
Deuxièmement, les poids étaient codés en dur sur le site et leur modification était très gênante.
Pas vers l'automatisation
La première étape vers l'amélioration du modèle de recommandation a été la suppression de toute la logique dans un microservice distinct en Python. Ce service appartenait déjà entièrement à notre équipe de recommandations, et nous pouvions mener des expériences assez souvent.
Chaque expérience peut être caractérisée par la soi-disant «config» - un ensemble de poids pour les classeurs. Nous voulons générer des configurations et choisir la meilleure en fonction des actions des utilisateurs. Comment générer ces configurations?
La première option, qui était dès le début, est la génération experte de configurations. Autrement dit, en utilisant les connaissances du domaine, nous supposons que, par exemple, lors de la recherche d'une voiture, les gens sont intéressés par des options proches du prix de celle qu'elles consultent, et pas seulement des modèles similaires, qui peuvent coûter beaucoup plus cher.
La deuxième option est la configuration aléatoire. Nous définissons une sorte de distribution pour chacun des paramètres, puis prenons simplement un échantillon de cette distribution. Cette méthode est plus rapide car vous n'avez pas besoin de penser à chacun des paramètres pour toutes les catégories.
Une option plus compliquée consiste à utiliser des algorithmes génétiques. Nous savons laquelle des configurations nous donne le meilleur effet en termes d'actions utilisateur, donc à chaque itération nous pouvons les laisser et en ajouter de nouvelles: aléatoires ou expertes.
Une option encore plus complexe, qui nécessite une longue histoire satisfaite d'expériences, est l'utilisation de l'apprentissage automatique. Nous pouvons représenter un ensemble de paramètres en tant que vecteur d'entités et une métrique cible en tant que variable cible. Ensuite, nous trouverons un tel ensemble de paramètres qui, selon l'évaluation du modèle, maximisera notre métrique cible.
Dans notre cas, nous avons opté pour les deux premières approches, ainsi que des algorithmes génétiques sous la forme la plus simple: nous laissons le meilleur, supprimons le pire.
Nous arrivons maintenant à la partie la plus intéressante de l'article: nous pouvons générer des configurations, mais comment mener des expériences pour qu'elles soient rapides et efficaces?
Expérimentation
L'expérience peut être menée sous la forme du test A / B / .... Pour ce faire, nous devons générer N configurations, attendre des résultats statistiquement significatifs et enfin sélectionner la meilleure configuration. Cela peut prendre un certain temps et tout au long du test, un groupe fixe d'utilisateurs peut recevoir des recommandations de mauvaise qualité - avec une génération aléatoire de configurations, cela est tout à fait possible. De plus, si nous voulons ajouter une nouvelle configuration à l'expérience, nous devrons recommencer le test. Mais nous voulons mener des expériences rapidement, pour pouvoir changer les conditions de l'expérience. Et pour que les utilisateurs ne souffrent pas de configs délibérément mauvaises. Des bandits armés de nombreuses armes nous aideront dans cette tâche.
Bandits multi-armés
Le nom de la méthode vient des "bandits à un bras" - des machines à sous dans un casino avec un levier pour lequel vous pouvez tirer et gagner. Imaginez que vous êtes dans une pièce avec une douzaine de ces machines et que vous avez N tentatives gratuites pour jouer sur l'une d'entre elles. Bien sûr, vous voulez gagner plus d'argent, mais vous ne savez pas à l'avance quelle machine donne le plus gros gain. Le problème avec les bandits à plusieurs bras réside précisément dans la recherche de la machine la plus rentable avec un minimum de pertes (en jouant sur des machines désavantageuses).
Si nous formulons cela en termes de notre tâche de recommandations, il s'avère que les machines sont des configurations, chaque tentative est un choix de configuration pour générer des recommandations, et le gain est une métrique cible en fonction des commentaires de l'utilisateur.
L'avantage des bandits sur les tests A / B / ...
Leur principal avantage est qu'ils nous permettent de modifier la quantité de trafic en fonction du succès d'une configuration particulière. Cela résout simplement le problème selon lequel les gens obtiendront de mauvaises recommandations tout au long de l'expérience. S'ils ne cliquent pas sur les recommandations, le bandit le comprendra rapidement et ne choisira pas cette configuration. De plus, nous pouvons toujours ajouter une nouvelle configuration à l'expérience ou simplement supprimer l'une des configurations actuelles. Tous ensemble nous donne la flexibilité de mener des expériences et résout les problèmes de l'approche avec les tests A / B / ....

Stratégies de gangsters
Il existe de nombreuses stratégies pour résoudre le problème des bandits armés. Ensuite, je décrirai plusieurs classes de stratégies faciles à mettre en œuvre que nous avons essayé d'appliquer dans notre tâche. Mais vous devez d'abord comprendre comment comparer l'efficacité des stratégies. Si nous savons à l'avance quel stylo donne le gain maximum, alors la stratégie optimale sera toujours de tirer ce stylo. Nous fixons le nombre d'étapes et calculons la récompense optimale . Pour la stratégie, nous compterons également la récompense. et présenter le concept :
D'autres stratégies peuvent être comparées uniquement à cette valeur. Je note que les stratégies ont une nature de changement
peut être différent, et une stratégie peut être meilleure pour un petit nombre d'étapes, et une autre pour une grande.
Stratégies gourmandes
Comme son nom l'indique, les stratégies gourmandes sont basées sur un principe simple - choisissez toujours le stylo qui donne en moyenne la plus grande récompense. Les stratégies de cette classe diffèrent dans la façon dont nous explorons l'environnement pour déterminer ce stylo. Il y a, par exemple, stratégie. Elle a un paramètre - , qui détermine la probabilité avec laquelle nous choisissons non pas le meilleur stylo, mais au hasard, explorant ainsi notre environnement. Vous pouvez également réduire la probabilité de recherche au fil du temps. Cette stratégie s'appelle . Les stratégies gourmandes sont très faciles à mettre en œuvre et compréhensibles, mais pas toujours efficaces.
UCB1
Cette stratégie est complètement déterministe - le stylo est uniquement déterminé à partir des informations actuellement disponibles. Voici la formule:
Partie de la formule avec
signifie le milieu de la j-ème plume et est responsable de l'exploitation, tout comme dans les stratégies gourmandes. La deuxième partie de la formule est responsable de l'exploration,
Est le nombre total d'actions
- le nombre d'actions du j-ème stylo. Il existe une estimation avérée de cette stratégie sur
. Vous pouvez en lire plus
ici .
Échantillonnage de Thompson
Dans cette stratégie, nous attribuons une distribution aléatoire à chaque plume, et à chaque étape, nous échantillonnons un nombre de cette distribution, en choisissant un stylo en fonction du maximum. Sur la base des retours, nous mettons à jour les paramètres de distribution afin que les meilleurs stylos correspondent à une distribution avec une moyenne élevée, et sa dispersion diminue avec le nombre d'actions. Vous pouvez en savoir plus sur cette stratégie dans un excellent article .
Comparaison de stratégie
Simulons les stratégies décrites ci-dessus sur un environnement artificiel à trois poignées, chacune correspondant à une distribution de Bernoulli avec un paramètre en conséquence. Nos stratégies:
- avec ;
- UCB1;
- Échantillonnage bêta de Thompson
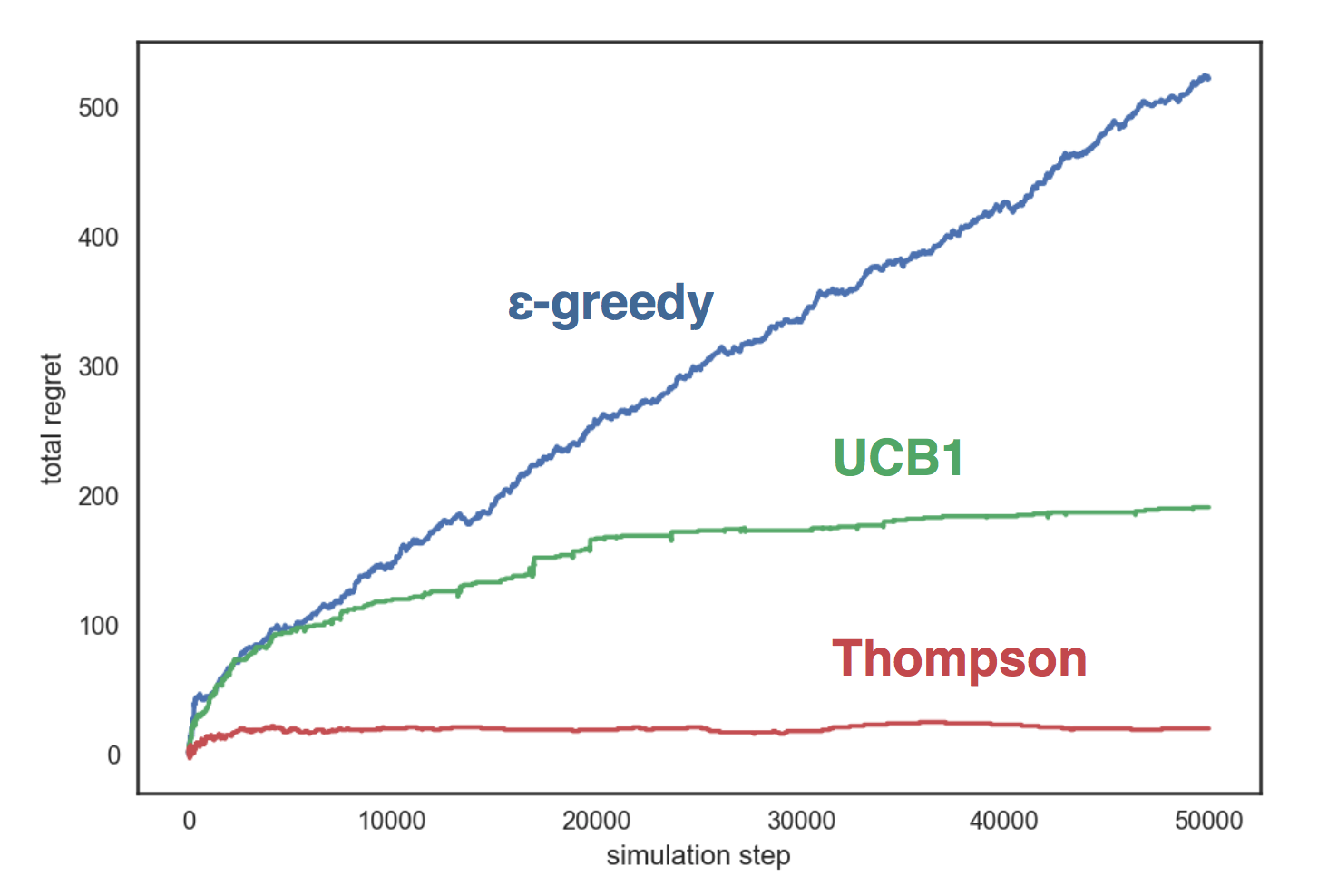
Le graphique montre que la stratégie gourmande croît de façon linéaire, et dans les deux autres stratégies - logarithmiquement, et l'échantillonnage de Thompson se montre beaucoup mieux que les autres et elle ne grandit presque pas avec le nombre d'étapes.
Le code de comparaison est disponible sur GitHub .
Je vous ai présenté des bandits multi-armés et maintenant je peux vous dire comment nous les avons utilisés.
Des bandits armés à Avito
Donc, nous avons plusieurs configurations (ensembles de paramètres), et nous voulons en choisir la meilleure à l'aide de bandits multi-armés. Pour que les bandits apprennent, nous avons besoin d'un détail important: les commentaires des utilisateurs. Dans le même temps, le choix des actions sur lesquelles nous sommes formés doit correspondre à nos objectifs - je souhaite que les utilisateurs effectuent plus de transactions avec de meilleures recommandations.
Choisissez les actions cibles
La première approche de la sélection des actions ciblées était assez simple et naïve. En tant que métrique cible, nous avons choisi le nombre de vues et les bandits ont appris à bien optimiser cette métrique. Mais il y avait un problème: plus de vues ne sont pas toujours bonnes. Par exemple, dans la catégorie «Auto», nous avons réussi à augmenter le nombre de vues de 15%, mais en même temps le nombre de demandes de contact a diminué à peu près du même montant. Après un examen plus approfondi, il s'est avéré que les bandits ont choisi un stylo dans lequel le filtre par région était désactivé. Par conséquent, le bloc a montré des annonces de toute la Russie, où le choix d'annonces similaires, bien sûr, est plus grand. Cela a provoqué une augmentation du nombre de vues: extérieurement, les recommandations semblaient être de meilleure qualité, mais quand elles sont entrées dans la carte du produit, les gens ont réalisé que la voiture était très loin d'eux et n'ont pas fait de demande de contact.
La deuxième approche consiste à apprendre comment passer de l'affichage d'un bloc à une demande de contact. Cette approche semblait meilleure que la précédente, ne serait-ce que parce que cette métrique est presque directement responsable de la qualité des recommandations. Mais un autre problème est apparu - la saisonnalité quotidienne. Selon l'heure de la journée, les valeurs de conversion peuvent différer de quatre (!) Fois (c'est souvent plus que l'effet d'une meilleure configuration), et le stylo qui a eu la chance d'être sélectionné dans le premier intervalle avec une conversion élevée a continué à être sélectionné plus souvent que les autres.
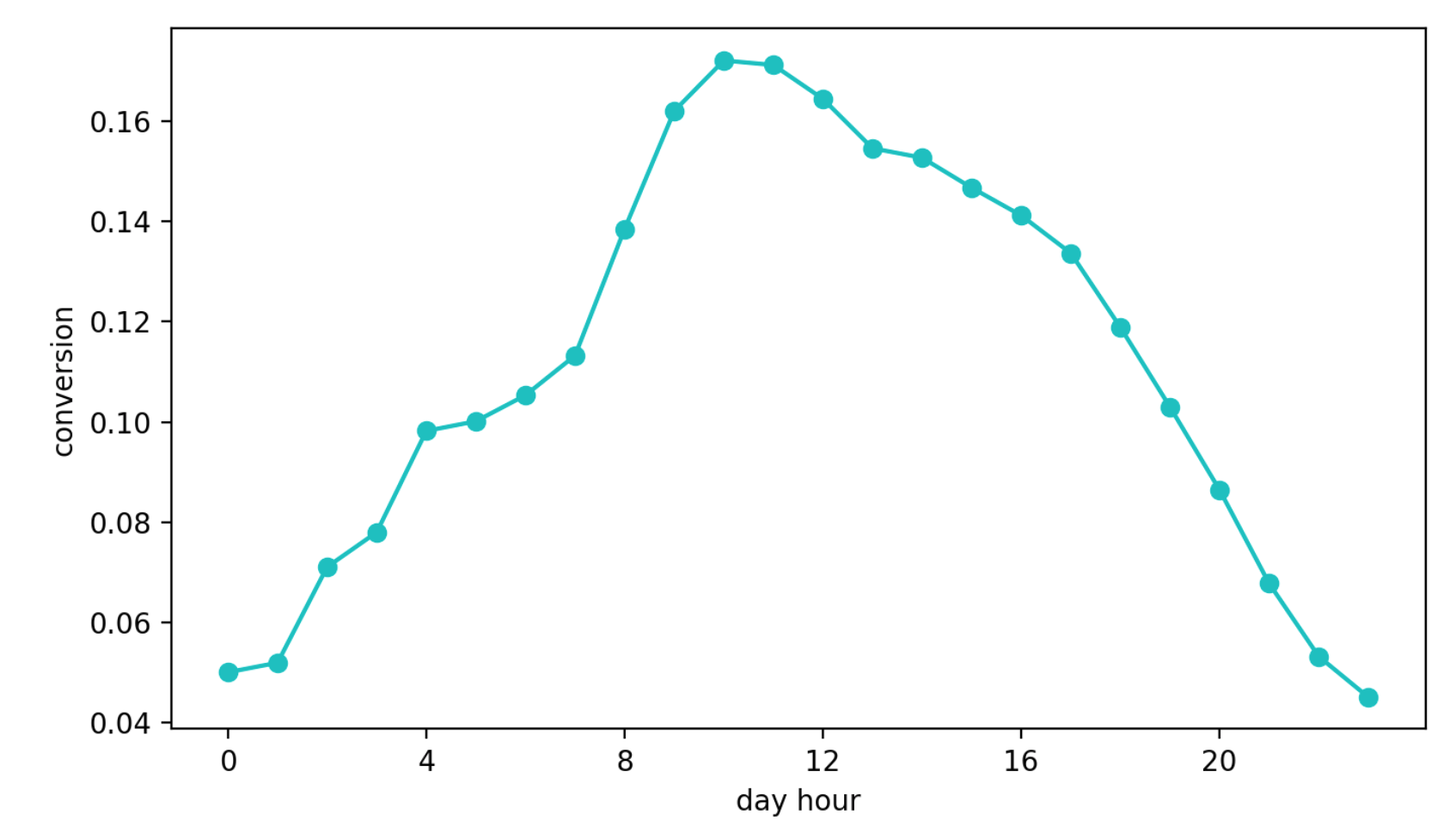
Dynamique de conversion quotidienne (les valeurs de l'axe Y ont été modifiées)
Enfin, la troisième approche. Nous l'utilisons maintenant. On distingue le groupe de référence, qui reçoit toujours des recommandations sur le même algorithme et n'est pas soumis à l'influence des bandits. Ensuite, nous regardons le nombre absolu de contacts dans notre groupe cible et référence. Leur relation n'est pas sujette à la saisonnalité, car nous sélectionnons le groupe de référence au hasard, et cette approche repose commodément sur l'échantillonnage de Thompson.
Notre stratégie
Nous distinguons les groupes de référence et cibles, comme décrit ci-dessus. Ensuite, initialisez N descripteurs (chacun d'eux correspond à une configuration) avec la distribution bêta
À chaque étape:
- pour chaque plume, nous échantillonnons un nombre dans la distribution qui lui correspond et sélectionnons la plume en fonction du maximum;
- compter le nombre d'actions en groupes et pendant un certain laps de temps (dans notre cas, il est de 10 secondes) et mettre à jour les paramètres de distribution pour le stylo sélectionné: , .
En utilisant cette stratégie, nous optimisons la métrique dont nous avons besoin, le nombre de demandes de contact dans le groupe cible et évitons les problèmes que j'ai décrits ci-dessus. De plus, dans le test global A / B, cette approche a donné les meilleurs résultats.
Résultats
Le test A / B global a été organisé comme suit: toutes les annonces sont réparties au hasard en deux groupes. Aux annonces de l'un d'eux, nous montrons des recommandations avec l'aide de bandits, et à l'autre - avec l'ancien algorithme expert. Ensuite, nous mesurons le nombre de demandes de contact de conversion dans chacun des groupes (demandes effectuées après le passage aux annonces du bloc similaire). En moyenne, dans toutes les catégories, un groupe de bandits reçoit environ 10% d'actions ciblées de plus que le contrôle, mais dans certaines catégories cette différence peut atteindre 30%.
Et la plate-forme créée vous permet de changer rapidement la logique, d'ajouter des configurations aux bandits et de valider des hypothèses.
Si vous avez des questions sur notre service de recommandation ou sur les bandits multi-armés, posez-les dans les commentaires. Je serai ravi de répondre.