Jusqu'à récemment, à Odnoklassniki, environ 50 To de données en temps réel étaient stockées dans SQL Server. Pour un tel volume, il est presque impossible de fournir un accès au centre de données rapide, fiable et même à sécurité intégrée à l'aide de SGBD SQL. Habituellement, dans de tels cas, ils utilisent l'un des référentiels NoSQL, mais tout ne peut pas être transféré vers NoSQL: certaines entités exigent des garanties de transactions ACID.
Cela nous a amenés à utiliser le stockage NewSQL, c'est-à-dire un SGBD qui offre la tolérance aux pannes, l'évolutivité et les performances des systèmes NoSQL, tout en préservant les garanties ACID familières aux systèmes classiques. Il y a peu de systèmes industriels qui fonctionnent dans cette nouvelle classe, nous avons donc implémenté un tel système nous-mêmes et l'avons mis en service commercial.
Comment cela fonctionne et ce qui s'est passé - lire sous la coupe.
Aujourd'hui, l'audience mensuelle d'Odnoklassniki est de plus de 70 millions de visiteurs uniques. Nous sommes
parmi les cinq plus grands réseaux sociaux du monde et les vingt sites sur lesquels les utilisateurs passent le plus de temps. L'infrastructure "OK" gère des charges très élevées: plus d'un million de requêtes HTTP / sec vers les fronts. Des parties du parc de serveurs de plus de 8 000 pièces sont situées à proximité les unes des autres - dans quatre centres de données de Moscou, ce qui permet une latence du réseau de moins de 1 ms entre elles.
Nous utilisons Cassandra depuis 2010, à partir de la version 0.6. Aujourd'hui, plusieurs dizaines de clusters sont en activité. Le cluster le plus rapide traite plus de 4 millions d'opérations par seconde et le plus grand stocke 260 To.
Cependant, tous ces clusters NoSQL ordinaires sont utilisés pour stocker
des données
peu cohérentes . Mais nous voulions remplacer le principal stockage cohérent, Microsoft SQL Server, qui est utilisé depuis la fondation d'Odnoklassniki. Le stockage comprenait plus de 300 machines SQL Server Standard Edition, qui contenaient 50 To de données - entités commerciales. Ces données sont modifiées dans le cadre des transactions ACID et nécessitent
une cohérence élevée .
Pour répartir les données entre les nœuds SQL Server, nous avons utilisé un
partitionnement vertical et horizontal (
partitionnement ). Historiquement, nous avons utilisé un schéma de partage de données simple: chaque entité était associée à un jeton - une fonction de l'ID de l'entité. Les entités avec le même jeton ont été placées sur le même serveur SQL. La relation de type maître-détail a été implémentée de sorte que les jetons des enregistrements principaux et générés coïncident toujours et se trouvent sur le même serveur. Dans un réseau social, presque tous les enregistrements sont générés au nom d'un utilisateur, ce qui signifie que toutes les données utilisateur d'un même sous-système fonctionnel sont stockées sur un serveur. Autrement dit, les tables d'un serveur SQL ont presque toujours participé à une transaction commerciale, ce qui a permis d'assurer la cohérence des données à l'aide de transactions ACID locales, sans avoir besoin de transactions ACID distribuées
lentes et peu fiables .
Grâce au sharding et à l'accélération de SQL:
- Nous n'utilisons pas de contraintes de clé étrangère, car lors du partage, l'ID d'entité peut être sur un autre serveur.
- Nous n'utilisons pas de procédures stockées et de déclencheurs en raison de la charge supplémentaire sur le processeur du SGBD.
- Nous n'utilisons pas de JOIN à cause de tout ce qui précède et de nombreuses lectures aléatoires à partir du disque.
- En dehors d'une transaction, pour réduire les blocages, nous utilisons le niveau d'isolement Read Uncommitted.
- Nous n'effectuons que des transactions courtes (en moyenne, inférieures à 100 ms).
- Nous n'utilisons pas UPDATE et DELETE sur plusieurs lignes en raison du grand nombre de blocages - nous mettons à jour un seul enregistrement.
- Nous n'exécutons toujours les requêtes que par index - une requête avec un plan pour une analyse complète de la table signifie pour nous une surcharge de la base de données et son échec.
Ces étapes ont permis d'extraire des performances presque maximales des serveurs SQL. Cependant, les problèmes sont devenus de plus en plus. Regardons-les.
Problèmes SQL
- Depuis que nous avons utilisé le partage propriétaire, les administrateurs ont ajouté manuellement de nouveaux fragments. Pendant tout ce temps, les répliques de données évolutives n'ont pas répondu aux demandes.
- À mesure que le nombre d'enregistrements dans la table augmente, la vitesse d'insertion et de modification diminue, lors de l'ajout d'index à une table existante, la vitesse diminue plusieurs fois, la création et la recréation d'index s'accompagnent de temps d'arrêt.
- Avoir peu de Windows pour SQL Server en production rend la gestion de votre infrastructure difficile
Mais le principal problème est
Tolérance aux pannes
Classic SQL Server a une faible tolérance aux pannes. Supposons que vous n'ayez qu'un seul serveur de base de données et qu'il échoue une fois tous les trois ans. Pour le moment, le site ne fonctionne pas pendant 20 minutes, c'est acceptable. Si vous avez 64 serveurs, le site ne fonctionne pas une fois toutes les trois semaines. Et si vous avez 200 serveurs, le site ne fonctionne pas toutes les semaines. C'est un problème.
Que peut-on faire pour améliorer la résilience de SQL Server? Wikipedia nous propose de construire un
cluster hautement accessible : là où en cas de panne de l'un des composants il y en a un en double.
Cela nécessite une flotte d'équipements coûteux: redondance multiple, fibre, stockage partagé, et l'inclusion d'une réserve ne fonctionne pas de manière fiable: environ 10% des inclusions échouent avec un nœud de sauvegarde par le moteur derrière le nœud principal.
Mais le principal inconvénient d'un tel cluster hautement accessible est la disponibilité nulle en cas de panne du datacenter dans lequel il se trouve. Odnoklassniki dispose de quatre centres de données, et nous devons fournir du travail en cas d'accident complet dans l'un d'entre eux.
Pour ce faire, vous pouvez utiliser la réplication multimaître intégrée à SQL Server. Cette solution est beaucoup plus coûteuse en raison du coût du logiciel et souffre de problèmes bien connus de réplication - des retards de transaction imprévisibles pendant la réplication synchrone et des retards dans l'utilisation de la réplication (et, par conséquent, des modifications perdues) pendant asynchrone. La
résolution manuelle implicite
des conflits rend cette option totalement inapplicable pour nous.
Tous ces problèmes nécessitaient une solution radicale et nous en avons procédé à une analyse détaillée. Ici, nous devons nous familiariser avec ce que fait essentiellement SQL Server - les transactions.
Transaction simple
Considérez la plus simple, du point de vue d'un programmeur SQL appliqué, la transaction: ajouter une photo à un album. Les albums et les photos sont stockés dans différentes plaques. L'album a un comptoir photo public. Une telle transaction est ensuite divisée en plusieurs étapes:
- Nous verrouillons l'album par clé.
- Créez une entrée dans le tableau de photos.
- Si la photo a un statut public, nous liquidons le compteur de photos public dans l'album, mettons à jour l'enregistrement et validons la transaction.
Ou sous forme de pseudo-code:
TX.start("Albums", id); Album album = albums.lock(id); Photo photo = photos.create(…); if (photo.status == PUBLIC ) { album.incPublicPhotosCount(); } album.update(); TX.commit();
Nous constatons que le scénario de transaction commerciale le plus courant consiste à lire les données de la base de données dans la mémoire du serveur d'applications, à modifier quelque chose et à enregistrer les nouvelles valeurs dans la base de données. Habituellement, dans une telle transaction, nous mettons à jour plusieurs entités, plusieurs tables.
Lors de l'exécution d'une transaction, une modification compétitive des mêmes données d'un autre système peut se produire. Par exemple, Antispam peut décider que l'utilisateur est suspect et donc toutes les photos de l'utilisateur ne devraient plus être publiques, elles doivent être envoyées pour modération, ce qui signifie changer photo.status à une autre valeur et dévisser les compteurs correspondants. Évidemment, si cette opération se produit sans garantie d'atomicité d'application et d'isolement des modifications concurrentes, comme dans
ACID , le résultat ne sera pas ce qui est nécessaire - soit le compteur de photos affichera la mauvaise valeur, soit toutes les photos ne seront pas envoyées pour modération.
Il y a beaucoup de code similaire qui manipule diverses entités commerciales dans le cadre d'une transaction pendant toute l'existence d'Odnoklassniki. De l'expérience de la migration vers NoSQL avec une
cohérence éventuelle, nous savons que les plus grandes difficultés (et les coûts en temps) sont la nécessité de développer un code visant à maintenir la cohérence des données. Par conséquent, nous avons considéré la principale exigence d'un nouveau référentiel pour fournir des transactions ACID logiques réelles pour la logique d'application.
D'autres exigences tout aussi importantes étaient:
- Si le centre de données tombe en panne, la lecture et l'écriture sur le nouveau stockage doivent être disponibles.
- Garder la vitesse de développement actuelle. Autrement dit, lorsque vous travaillez avec un nouveau référentiel, la quantité de code doit être à peu près la même, il ne devrait pas être nécessaire d'ajouter quelque chose au référentiel, de développer des algorithmes pour résoudre les conflits, maintenir des index secondaires, etc.
- La vitesse du nouveau stockage devrait être suffisamment élevée à la fois lors de la lecture des données et lors du traitement des transactions, ce qui signifiait effectivement l'inapplicabilité de solutions universellement rigoureuses, universelles mais lentes, telles que, par exemple, les validations en deux phases .
- Mise à l'échelle automatique à la volée.
- Utiliser des serveurs ordinaires bon marché, sans avoir besoin d'acheter des morceaux de fer exotiques.
- La possibilité de développer le stockage par les développeurs de l'entreprise. En d'autres termes, la priorité a été donnée à leurs propres solutions ou à des solutions open source, de préférence en Java.
Décisions, décisions
En analysant les solutions possibles, nous sommes arrivés à deux choix d'architecture possibles:
La première consiste à prendre n'importe quel serveur SQL et à implémenter la tolérance aux pannes, le mécanisme de mise à l'échelle, le cluster de basculement, la résolution des conflits et les transactions ACID distribués, fiables et rapides. Nous avons évalué cette option comme étant très simple et longue.
La deuxième option consiste à prendre un référentiel NoSQL prêt à l'emploi avec mise à l'échelle implémentée, un cluster de basculement, la résolution des conflits et à implémenter nous-mêmes les transactions et SQL. À première vue, même la tâche d'implémentation de SQL, sans parler des transactions ACID, ressemble à une tâche pendant des années. Mais ensuite, nous avons réalisé que l'ensemble de fonctionnalités SQL que nous utilisons dans la pratique est aussi loin de ANSI SQL que
Cassandra CQL est loin de ANSI SQL. En examinant de plus près le CQL, nous avons réalisé qu'il était suffisamment proche de ce dont nous avions besoin.
Cassandra et CQL
Alors, qu'est-ce qui est intéressant avec Cassandra, quelles sont ses capacités?
Tout d'abord, ici, vous pouvez créer des tableaux avec la prise en charge de divers types de données, vous pouvez faire SELECT ou UPDATE sur la clé primaire.
CREATE TABLE photos (id bigint KEY, owner bigint,…); SELECT * FROM photos WHERE id=?; UPDATE photos SET … WHERE id=?;
Pour garantir la cohérence des données de réplique, Cassandra utilise une
approche de quorum . Dans le cas le plus simple, cela signifie que lorsque trois répliques de la même ligne sont placées sur des nœuds différents du cluster, l'enregistrement est considéré comme réussi si la plupart des nœuds (c'est-à-dire deux sur trois) confirment le succès de cette opération d'écriture. Les données d'une série sont considérées comme cohérentes si, à la lecture, la plupart des nœuds ont été interrogés et confirmés. Ainsi, avec la présence de trois répliques, la cohérence complète et instantanée des données est garantie en cas de défaillance d'un nœud. Cette approche nous a permis de mettre en œuvre un schéma encore plus fiable: toujours envoyer des demandes aux trois répliques, en attendant une réponse des deux plus rapides. La réponse tardive de la troisième réplique est ensuite ignorée. Un nœud en retard avec une réponse peut avoir de graves problèmes - freins, récupération de place dans la JVM, récupération directe de mémoire dans le noyau linux, panne matérielle, déconnexion du réseau. Cependant, cela n'affecte pas les opérations ou les données du client.
L'approche lorsque nous nous tournons vers trois nœuds et obtenons une réponse de deux s'appelle la
spéculation : une demande de remarques supplémentaires est envoyée avant même qu'elle ne «tombe».
Un autre avantage de Cassandra est Batchlog - un mécanisme qui garantit soit une application complète, soit une non-application complète de l'ensemble des modifications que vous apportez. Cela nous permet de résoudre A dans ACID - atomicité hors de la boîte.
Les transactions les plus proches de Cassandra sont les «
transactions légères ». Mais ils sont loin d'être des transactions "réelles" ACID: en fait, c'est l'occasion de faire du
CAS sur des données d'un seul enregistrement, en utilisant le consensus sur le lourd protocole Paxos. Par conséquent, la vitesse de ces transactions est faible.
Ce que nous avons manqué à Cassandra
Nous avons donc dû implémenter de véritables transactions ACID à Cassandra. À l'aide de laquelle nous pourrions facilement implémenter deux autres fonctionnalités pratiques du SGBD classique: des index rapides et cohérents, qui nous permettraient d'effectuer un échantillonnage de données non seulement sur la clé primaire et le générateur habituel d'ID d'auto-incrémentation monotone.
C * un
Ainsi, le nouveau SGBD
C * One est né, composé de trois types de nœuds de serveur:
- Stockage - les serveurs Cassandra (presque) standard chargés du stockage des données sur les disques locaux. À mesure que la charge et la quantité de données augmentent, leur nombre peut facilement être mis à l'échelle à des dizaines ou des centaines.
- Coordinateurs de transactions - Permet l'exécution de transactions.
- Les clients sont des serveurs d'applications qui mettent en œuvre des opérations commerciales et initient des transactions. Il peut y avoir des milliers de ces clients.
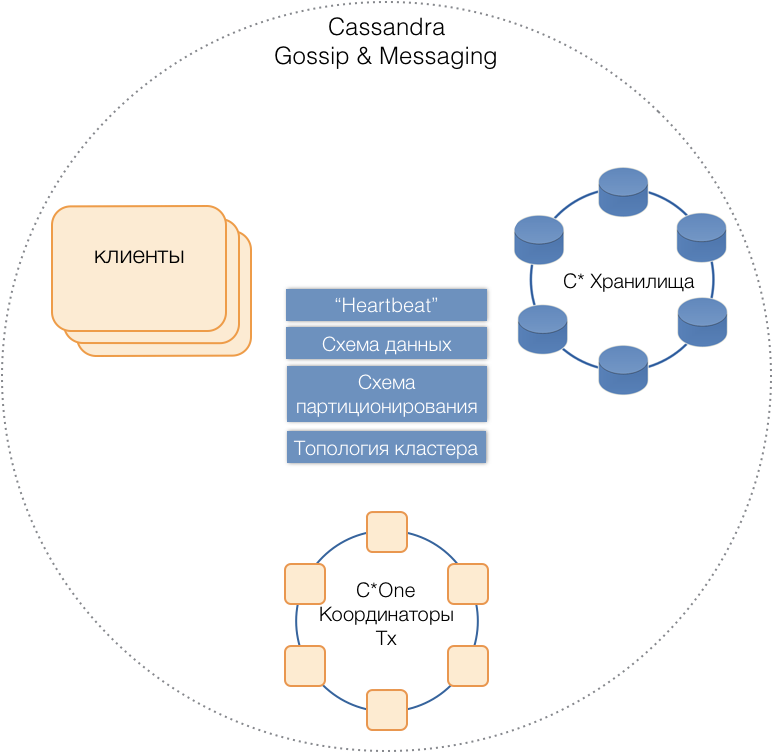
Tous les types de serveurs sont dans un cluster commun, utilisez le protocole de message interne Cassandra pour communiquer entre eux et
potins pour échanger des informations sur le cluster. Avec l'aide de Heartbeat, les serveurs apprennent les défaillances mutuelles, prennent en charge un schéma de données unique - les tables, leur structure et leur réplication; schéma de partitionnement, topologie de cluster, etc.
Les clients
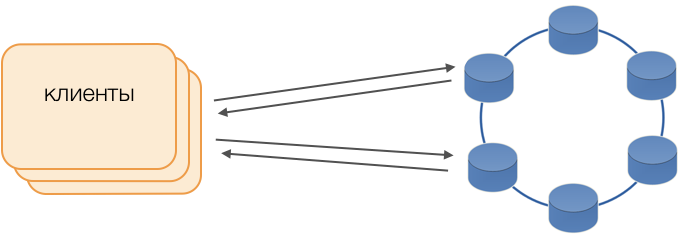
Au lieu des pilotes standard, le mode Fat Client est utilisé. Un tel nœud ne stocke pas de données, mais peut agir en tant que coordinateur de l'exécution des requêtes, c'est-à-dire que le Client lui-même remplit la fonction de coordinateur de ses requêtes: il interroge les référentiels de répliques et résout les conflits. Ceci est non seulement plus fiable et plus rapide qu'un pilote standard qui nécessite une communication avec un coordinateur distant, mais vous permet également de contrôler le transfert des demandes. En dehors d'une transaction ouverte sur le client, les demandes sont envoyées au stockage. Si le client a ouvert la transaction, toutes les demandes de la transaction sont envoyées au coordinateur de transaction.

Coordinateur de transactions C * One
Le coordinateur est ce que nous avons implémenté pour C * One à partir de zéro. Il est responsable de la gestion des transactions, des verrous et de l'ordre dans lequel les transactions sont appliquées.
Pour chaque transaction traitée, le coordinateur génère un horodatage: chaque horodatage suivant est supérieur à la transaction précédente. Étant donné que le système de résolution des conflits de Cassandra est basé sur des horodatages (sur deux enregistrements en conflit, l'actuel avec le dernier horodatage est considéré comme pertinent), le conflit sera toujours résolu en faveur de la transaction suivante. Ainsi, nous avons implémenté les
montres Lamport - un moyen peu coûteux de résoudre les conflits dans un système distribué.
Serrures
Pour garantir l'isolement, nous avons décidé d'utiliser la méthode la plus simple: des verrous pessimistes sur la clé primaire de l'enregistrement. En d'autres termes, dans une transaction, l'enregistrement doit d'abord être verrouillé, puis lu, modifié et sauvegardé. Ce n'est qu'après une validation réussie qu'un enregistrement peut être déverrouillé afin que les transactions concurrentes puissent l'utiliser.
L'implémentation de ce verrou est simple dans un environnement non alloué. Il existe deux façons principales dans un système distribué: soit d'implémenter un verrouillage distribué sur le cluster, soit de répartir les transactions de sorte que les transactions impliquant un seul enregistrement soient toujours gérées par le même coordinateur.
Étant donné que dans notre cas, les données sont déjà distribuées par des groupes de transactions locaux dans SQL, il a été décidé d'affecter des groupes de transactions locaux aux coordinateurs: un coordinateur effectue toutes les transactions avec un token de 0 à 9, le second avec un token de 10 à 19, etc. Par conséquent, chacune des instances de coordinateur devient un maître de groupe de transactions.
Ensuite, les verrous peuvent être implémentés comme un HashMap banal dans la mémoire du coordinateur.
Échecs du coordinateur
Étant donné qu'un coordinateur dessert exclusivement un groupe de transactions, il est très important de déterminer rapidement le fait de son échec, afin qu'une tentative répétée d'exécuter la transaction soit expirée. Pour le rendre rapide et fiable, nous avons appliqué un protocole de rythme cardiaque de quorum entièrement connecté:
Chaque centre de données possède au moins deux nœuds coordinateurs. Périodiquement, chaque coordinateur envoie un message de pulsation aux autres coordinateurs et les informe de leur fonctionnement, ainsi que les messages de pulsation à partir desquels les coordinateurs du cluster pour la dernière fois.

Après avoir reçu des informations similaires des autres dans la composition de leurs messages de pulsation, chaque coordinateur décide lui-même quels nœuds de cluster fonctionnent et lesquels ne sont pas guidés par le principe du quorum: si le nœud X a reçu des informations de la majorité des nœuds du cluster sur la réception normale des messages du nœud Y, alors , Y fonctionne. Inversement, dès que la majorité signale la perte de messages du nœud Y, alors Y a échoué. Il est curieux que si un quorum indique au nœud X qu'il n'en reçoit pas plus de messages, le nœud X lui-même se considérera comme ayant échoué.
Les messages de pulsation sont envoyés à une fréquence élevée, environ 20 fois par seconde, avec une période de 50 ms. En Java, il est difficile de garantir une réponse d'application de 50 ms en raison de la durée comparable des pauses provoquées par le garbage collector. Nous avons pu atteindre un tel temps de réponse en utilisant le garbage collector G1, ce qui nous permet de spécifier la cible pour la durée des pauses du GC. Cependant, parfois, assez rarement, la pause du collecteur dépasse 50 ms, ce qui peut conduire à une fausse détection d'échec. Pour éviter cela, le coordinateur ne signale pas l'échec du nœud distant lorsque le premier message de pulsation en disparaît, seulement si plusieurs disparaissent consécutivement. Nous avons donc réussi à détecter l'échec du nœud du coordinateur en 200 ms.
Mais il ne suffit pas de comprendre rapidement quel nœud a cessé de fonctionner. Vous devez y faire quelque chose.
Réservation
Le schéma classique suppose qu'en cas de refus d'un maître de lancer une nouvelle élection en utilisant l'un des algorithmes
universels à la
mode . Cependant, ces algorithmes ont des problèmes bien connus avec la convergence temporelle et la durée du processus électoral lui-même. Nous avons réussi à éviter de tels retards supplémentaires en utilisant le circuit équivalent de coordinateurs dans un réseau entièrement connecté:
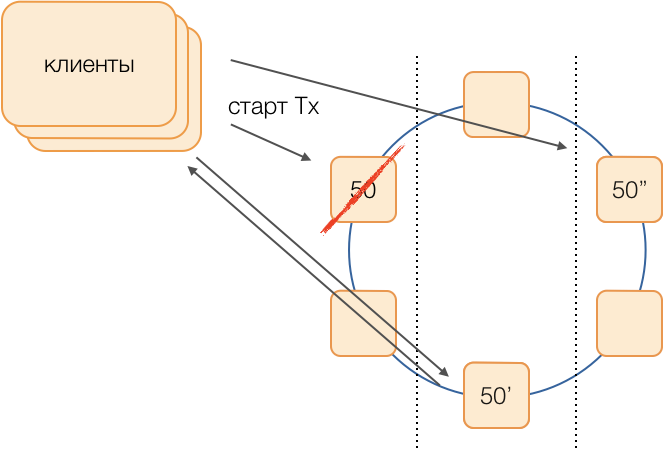
Supposons que nous voulons exécuter une transaction dans le groupe 50. Nous déterminerons à l'avance un schéma de substitution, c'est-à-dire quels nœuds exécuteront les transactions du groupe 50 en cas de défaillance du coordinateur principal. Notre objectif est de maintenir le système opérationnel en cas de panne du centre de données. Nous déterminons que la première réserve sera un nœud d'un autre centre de données, et la deuxième réserve sera un nœud du troisième. Ce schéma est sélectionné une fois et ne change pas tant que la topologie du cluster ne change pas, c'est-à-dire jusqu'à ce que de nouveaux nœuds y entrent (ce qui arrive très rarement). La procédure pour choisir un nouveau maître actif en cas de défaillance de l'ancien sera toujours la suivante: la première réserve deviendra le maître actif, et si elle a cessé de fonctionner, la deuxième réserve deviendra.
Un tel schéma est plus fiable que l'algorithme universel, car pour activer un nouveau maître, il suffit de déterminer le fait de l'échec de l'ancien.
Mais comment les clients comprendront-ils lequel des maîtres travaille actuellement? Pendant 50 ms, il n'est pas possible d'envoyer des informations à des milliers de clients. Une situation est possible lorsqu'un client envoie une demande d'ouverture de transaction, ne sachant pas encore que cet assistant ne fonctionne plus et que la demande se bloque sur un délai d'attente. Pour éviter que cela ne se produise, les clients envoient de manière spéculative une demande d'ouverture immédiate d'une transaction au maître de groupe et à ses deux réserves, mais seul celui qui est actuellement le maître actif répondra à cette demande. Le client effectuera toutes les communications ultérieures au sein de la transaction uniquement avec le maître actif.
Les maîtres de sauvegarde reçoivent des demandes de transactions non propres dans la file d'attente des transactions à naître, où elles sont stockées pendant un certain temps. Si le maître actif décède, le nouveau maître traite les demandes d'ouverture de transactions de sa file d'attente et répond au client. Si le client a déjà réussi à ouvrir une transaction avec l'ancien maître, alors la deuxième réponse est ignorée (et, évidemment, une telle transaction ne sera pas terminée et sera répétée par le client).
Fonctionnement d'une transaction
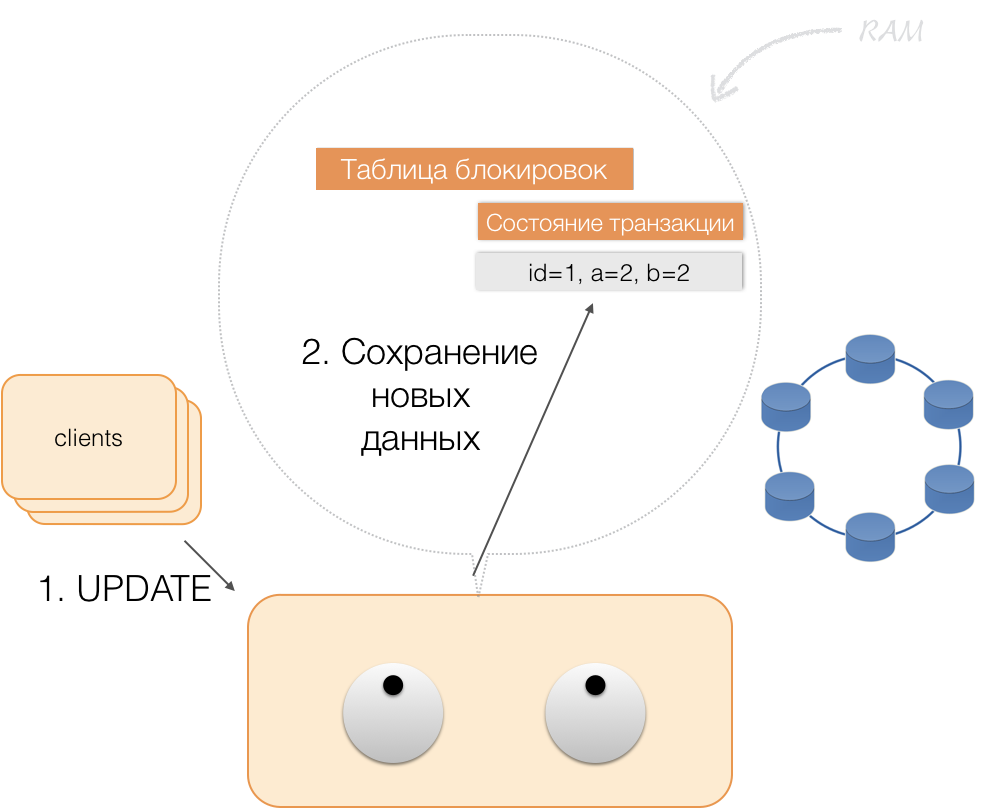
Supposons qu'un client envoie au coordinateur une demande d'ouverture d'une transaction pour une telle entité avec une telle clé primaire. Le coordinateur verrouille cette entité et la place dans la table des verrous en mémoire. Si nécessaire, le coordinateur lit cette entité dans la mémoire et stocke les données reçues dans un état de transaction dans la mémoire du coordinateur.
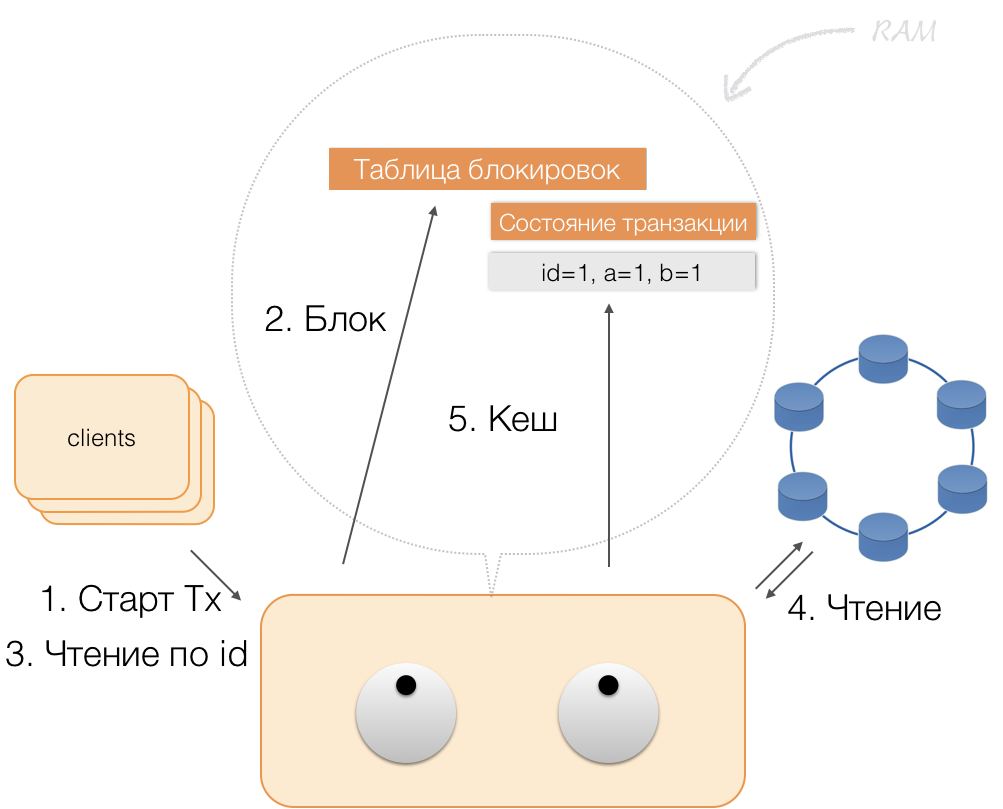
Lorsque le client souhaite modifier les données de la transaction, il envoie au coordinateur une demande de mise à jour de l'entité, et il place les nouvelles données dans la table d'état de la transaction en mémoire. Ceci termine l'enregistrement - l'enregistrement n'est pas effectué dans le référentiel.
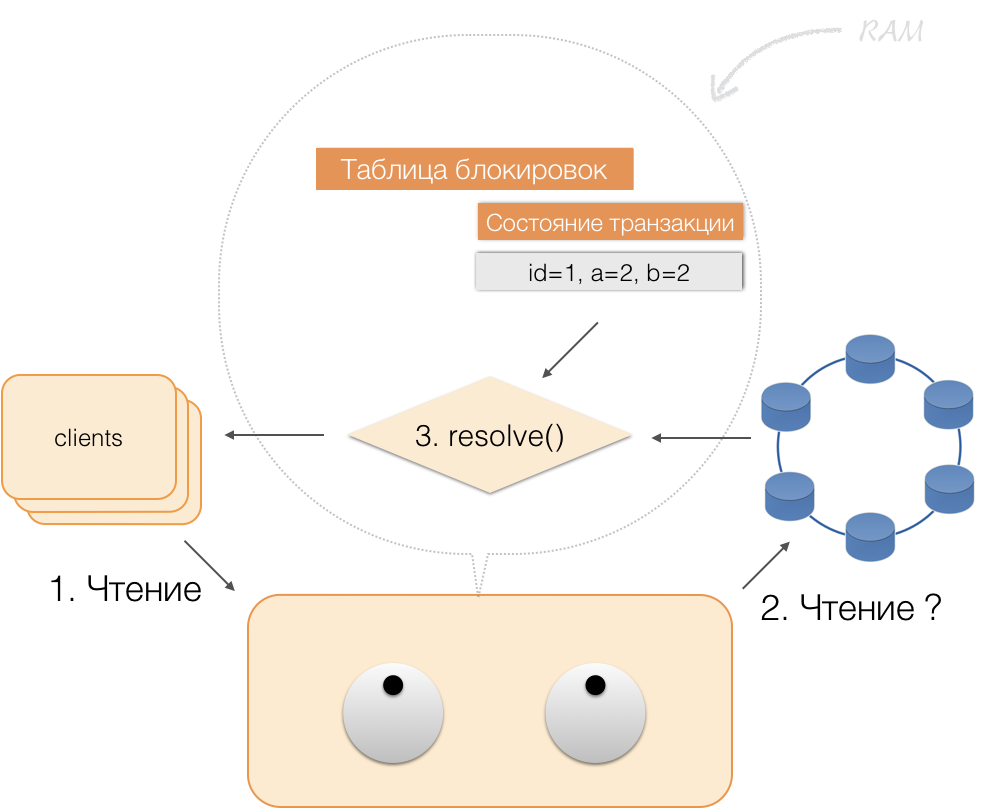
Lorsqu'un client demande, dans le cadre d'une transaction active, ses propres données modifiées, le coordinateur agit ainsi:
- si l'ID est déjà dans la transaction, les données sont extraites de la mémoire;
- s'il n'y a pas d'ID dans la mémoire, les données manquantes sont lues à partir des nœuds de stockage, combinées avec celles déjà en mémoire, et le résultat est renvoyé au client.
Ainsi, le client peut lire ses propres modifications, tandis que d'autres clients ne voient pas ces modifications, car elles ne sont stockées que dans la mémoire du coordinateur, elles ne sont pas encore dans les nœuds Cassandra.
Lorsque le client envoie une validation, l'état dans la mémoire du service est enregistré par le coordinateur dans le lot enregistré, et déjà sous la forme d'un lot enregistré, il est envoyé aux référentiels Cassandra. Les référentiels font tout ce qui est nécessaire pour que ce package soit appliqué (entièrement) atomiquement et retournent une réponse au coordinateur, qui libère les verrous et confirme le succès de la transaction au client.

Et pour revenir au coordinateur, il suffit de libérer la mémoire occupée par l'état de la transaction.
À la suite des améliorations ci-dessus, nous avons mis en œuvre les principes de l'ACID:
- Atomicité . Ceci est une garantie qu'aucune transaction ne sera partiellement engagée dans le système, toutes ses sous-opérations seront terminées, ou pas une seule ne sera exécutée. Nous respectons ce principe en raison du lot enregistré à Cassandra.
- Cohérence . Chaque transaction réussie, par définition, ne capture que des résultats acceptables. Si, après l'ouverture d'une transaction et l'exécution d'une partie des opérations, il s'avère que le résultat n'est pas valide, une restauration est effectuée.
- Isolement . Lorsqu'une transaction est exécutée, les transactions parallèles ne doivent pas affecter son résultat. Les transactions concurrentes sont isolées à l'aide de verrous pessimistes sur le coordinateur. Pour les lectures en dehors de la transaction, le principe d'isolement au niveau Read Committed est respecté.
- Durabilité . Indépendamment des problèmes aux niveaux inférieurs - mise hors tension du système, défaillance matérielle, - les modifications apportées par une transaction réussie doivent rester enregistrées après la reprise de l'opération.
Lecture d'index
Prenez un tableau simple:
CREATE TABLE photos ( id bigint primary key, owner bigint, modified timestamp, …)
Elle a un identifiant (clé primaire), un propriétaire et une date de changement. Vous devez faire une demande très simple - sélectionnez les informations du propriétaire avec la date de changement "pour le dernier jour".
SELECT * WHERE owner=? AND modified>?
Pour qu'une telle requête fonctionne rapidement, dans le SGBD SQL classique, vous devez créer un index par colonnes (propriétaire, modifié). Nous pouvons le faire tout simplement, puisque nous avons maintenant des garanties ACID!
Indices en C * One
Il existe une table source avec des photos, dans laquelle l'ID d'enregistrement est la clé primaire.

Pour l'index C *, One crée une nouvelle table, qui est une copie de l'original. La clé correspond à l'expression d'index et comprend également la clé primaire de l'enregistrement de la table source:
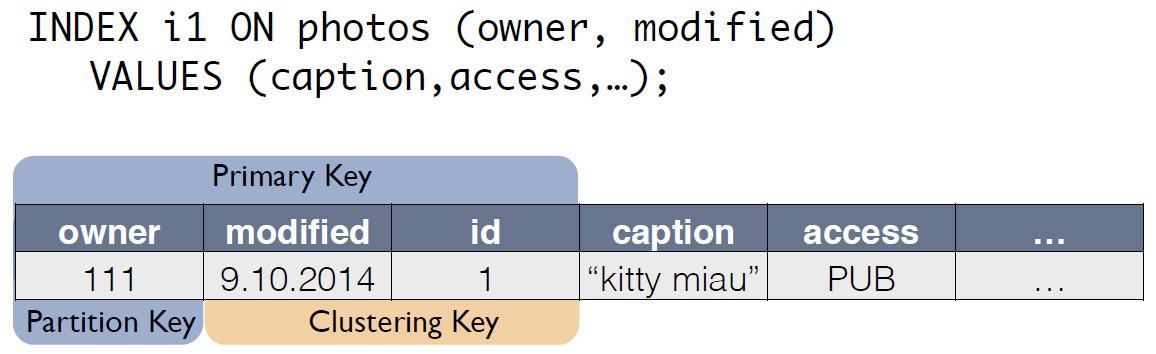
Maintenant, la demande pour le "propriétaire du dernier jour" peut être réécrite en sélectionnant dans une autre table:
SELECT * FROM i1_test WHERE owner=? AND modified>?
La cohérence des données de la table de photos d'origine et de l'index i1 est maintenue automatiquement par le coordinateur. Sur la base du schéma de données seul, lorsque le changement est reçu, le coordinateur génère et se souvient du changement non seulement dans le tableau principal, mais également dans les copies. Aucune action supplémentaire n'est effectuée avec la table d'index, les journaux ne sont pas lus, les verrous ne sont pas utilisés. En d'autres termes, l'ajout d'index ne consomme presque pas de ressources et n'affecte pratiquement pas la vitesse d'application des modifications.
En utilisant ACID, nous avons pu implémenter des index «comme en SQL». Ils ont une cohérence, peuvent être mis à l'échelle, fonctionnent rapidement, peuvent être composites et intégrés dans le langage de requête CQL.
Pour prendre en charge les index, vous n'avez pas besoin de modifier le code d'application. Tout est simple, comme en SQL. Et surtout, les index n'affectent pas la vitesse d'exécution des modifications apportées à la table de transactions d'origine.Qu'est-il arrivé?
Nous avons développé C * One il y a trois ans et l'avons mis en service commercial.Qu'avons-nous finalement obtenu? Évaluons cela en utilisant l'exemple d'un sous-système de traitement et de stockage de photos, l'un des types de données les plus importants d'un réseau social. Il ne s'agit pas du corps des photos elles-mêmes, mais de toutes sortes de méta-informations. Or, à Odnoklassniki, il existe environ 20 milliards de ces enregistrements, le système traite 80 000 demandes de lecture par seconde, jusqu'à 8 000 transactions ACID par seconde associées à la modification des données.Lorsque nous avons utilisé SQL avec un facteur de réplication = 1 (mais en RAID 10), les méta-informations photo ont été stockées sur un cluster hautement accessible de 32 machines avec Microsoft SQL Server (plus 11 de sauvegarde). Il a également alloué 10 serveurs pour le stockage des sauvegardes. Un total de 50 voitures chères. Dans le même temps, le système fonctionnait à charge nominale, sans réserve.Après la migration vers le nouveau système, nous avons obtenu un facteur de réplication = 3 - une copie dans chaque centre de données. Le système comprend 63 nœuds de stockage Cassandra et 6 machines coordinatrices, totalisant 69 serveurs. Mais ces machines sont beaucoup moins chères, leur coût total est d'environ 30% du coût du système en SQL. Dans ce cas, la charge est maintenue à 30%.Avec l'introduction de C * One, les retards ont également diminué: en SQL, l'opération d'écriture prenait environ 4,5 ms. En C * One - environ 1,6 ms. La durée de la transaction est en moyenne inférieure à 40 ms, la validation est effectuée en 2 ms, la durée de lecture et d'écriture est en moyenne de 2 ms. Le 99e centile - seulement 3-3,1 ms, le nombre de délais d'attente a diminué de 100 fois - tout cela en raison de l'utilisation généralisée de la spéculation.À ce jour, la plupart des nœuds SQL Server ont été mis hors service; les nouveaux produits sont développés uniquement à l'aide de C * One. Nous avons adapté C * One pour travailler dans notre cloud unique , ce qui nous a permis d'accélérer le déploiement de nouveaux clusters, de simplifier la configuration et d'automatiser le fonctionnement. Sans code source, ce serait beaucoup plus difficile et difficile à réaliser.Maintenant, nous travaillons sur le transfert de nos autres installations de stockage vers le cloud - mais c'est une histoire complètement différente.