À quelles exigences le stockage de métadonnées pour un service cloud doit-il répondre? Oui, pas le plus ordinaire, mais pour les entreprises prenant en charge les centres de données géographiquement distribués et Active-Active. De toute évidence, le système doit évoluer correctement, être
tolérant aux pannes et souhaiter pouvoir implémenter une cohérence des opérations personnalisable.Seule Cassandra convient à toutes ces exigences, et rien d'autre ne convient. Il convient de noter que Cassandra est vraiment cool, mais travailler avec elle ressemble à des montagnes russes.
Dans un rapport à Highload ++ 2017,
Andrei Smirnov (
smira ) a décidé qu'il n'était pas intéressant de parler de bien, mais il a parlé en détail de chaque problème qui devait être rencontré: de la perte de données et de la corruption, des zombies et de la perte de performances. Ces histoires rappellent vraiment les montagnes russes, mais pour tous les problèmes, il existe une solution, pour laquelle vous êtes les bienvenus au chat.
À propos du conférencier: Andrey Smirnov travaille pour Virtustream, une entreprise qui implémente le stockage cloud pour les entreprises. L'idée est qu'Amazon conditionnellement fait le cloud pour tout le monde, et Virtustream fait les choses spécifiques dont une grande entreprise a besoin.
Quelques mots sur Virtustream
Nous travaillons dans une petite équipe complètement éloignée et nous sommes engagés dans l'une des solutions cloud Virtustream. Il s'agit d'un nuage de stockage de données.

En termes très simples, il s'agit d'une API compatible S3 dans laquelle vous pouvez stocker des objets. Pour ceux qui ne savent pas ce qu'est S3, c'est juste une API HTTP avec laquelle vous pouvez télécharger des objets dans le cloud quelque part, les récupérer, les supprimer, obtenir une liste d'objets, etc. En outre - des fonctionnalités plus complexes basées sur ces opérations simples.
Nous avons certaines caractéristiques distinctives qu'Amazon n'a pas. L'un d'eux est ce qu'on appelle les géorégions. Dans la situation habituelle, lorsque vous créez un référentiel et dites que vous stockerez des objets dans le cloud, vous devez sélectionner une région. Une région est essentiellement un centre de données et vos objets ne quitteront jamais ce centre de données. Si quelque chose lui arrive, vos objets ne seront plus disponibles.
Nous proposons des géorégions dans lesquelles les données sont localisées simultanément dans plusieurs centres de données (DC), au moins dans deux, comme sur la photo. Le client peut contacter n'importe quel centre de données, pour lui c'est transparent. Les données entre eux sont répliquées, c'est-à-dire que nous travaillons en mode actif-actif et en permanence. Cela fournit au client des fonctionnalités supplémentaires, notamment:
- une plus grande fiabilité du stockage, de la lecture et de l'écriture en cas de panne DC ou de perte de connectivité;
- la disponibilité des données même si l'un des contrôleurs de domaine tombe en panne;
- rediriger les opérations vers le contrôleur de domaine «le plus proche».
Il s'agit d'une opportunité intéressante - même si ces contrôleurs de domaine sont géographiquement éloignés, certains d'entre eux peuvent être plus proches du client à différents moments. Et l'accès aux données au contrôleur de domaine le plus proche est tout simplement plus rapide.
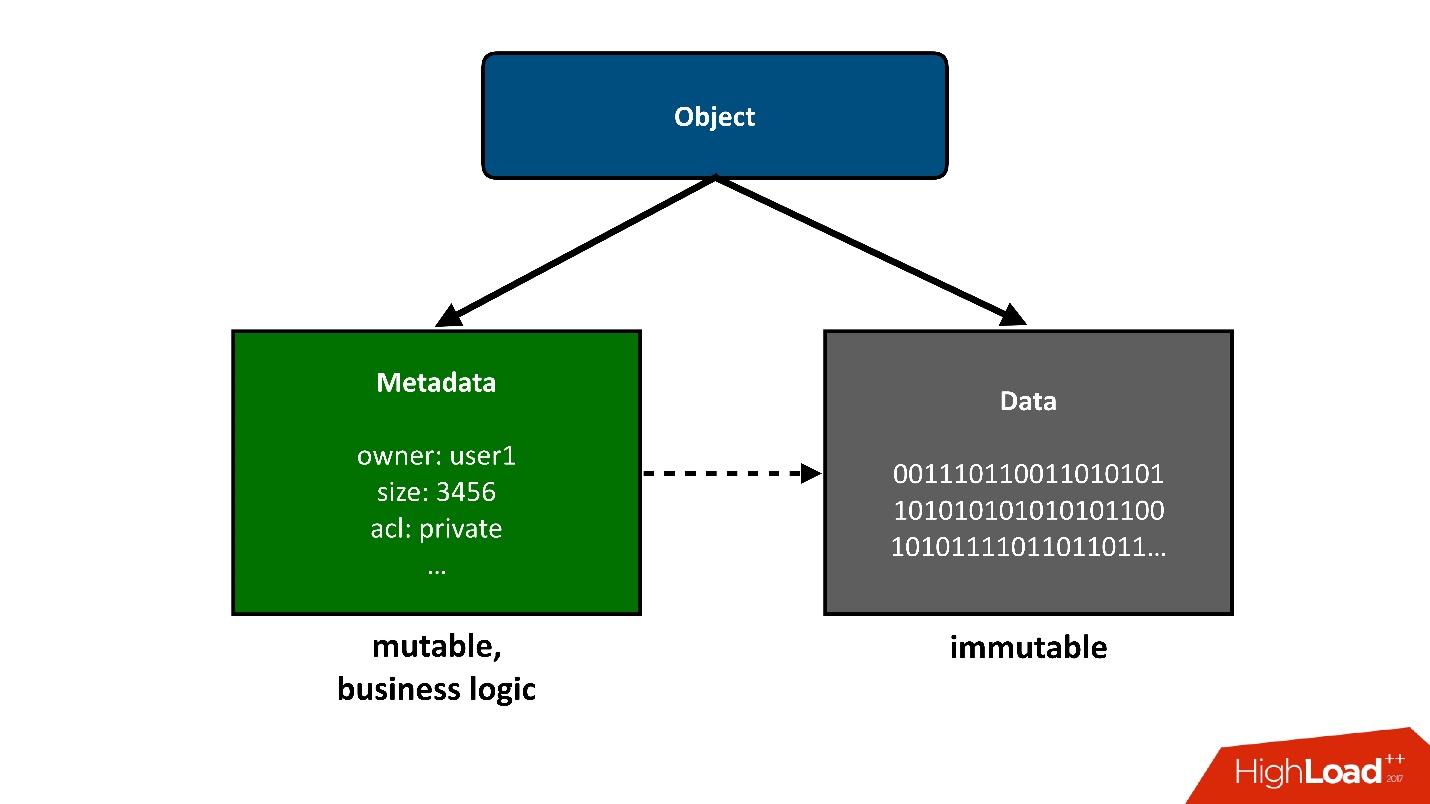
Afin de diviser la construction dont nous parlerons en parties, je présenterai ces objets qui sont stockés dans le nuage en deux gros morceaux:
1. La première pièce simple d'un objet est une
donnée . Ils sont inchangés, ils ont été téléchargés une fois et c'est tout. La seule chose qui peut leur arriver par la suite, c'est que nous pouvons les retirer s'ils ne sont plus nécessaires.
Notre projet précédent était lié au stockage d'exaoctets de données, nous n'avons donc eu aucun problème avec le stockage de données. C'était déjà une tâche résolue pour nous.
2.
Métadonnées . Toute logique métier, la plus intéressante, liée à la concurrence: accès, enregistrements, réécritures - dans le domaine des métadonnées.
Les métadonnées sur l'objet prennent en elles-mêmes la plus grande complexité du projet, les métadonnées stockent un pointeur sur le bloc de données stockées de l'objet.
Du point de vue de l'utilisateur, il s'agit d'un objet unique, mais nous pouvons le diviser en deux parties. Aujourd'hui, je ne parlerai
que des métadonnées .
Les chiffres
- Données : 4 octets.
- Clusters de métadonnées : 3.
- Objets : 40 milliards.
- Taille des métadonnées : 160 To (y compris la réplication).
- Taux de changement (métadonnées): 3000 objets / s.
Si vous regardez attentivement ces indicateurs, la première chose qui attire votre attention est la très petite taille moyenne de l'objet stocké. Nous avons beaucoup de métadonnées par volume unitaire de données de base. Pour nous, ce n'était pas moins une surprise que peut-être pour vous maintenant.
Nous avions prévu d'avoir au moins un ordre de données, sinon 2, de plus que des métadonnées. Autrement dit, chaque objet sera considérablement plus grand et la quantité de métadonnées sera moindre. Parce que les données sont moins chères à stocker, moins d'opérations avec elles et les métadonnées sont beaucoup plus chères à la fois dans le sens du matériel, et dans le sens de l'entretien et de l'exécution de diverses opérations sur elles.
De plus, ces données changent à une vitesse assez élevée. J'ai donné la valeur de crête ici, la valeur non crête n'est pas beaucoup moins, mais, néanmoins, une charge assez importante peut être obtenue à des moments spécifiques.
Ces chiffres ont déjà été obtenus à partir d'un système fonctionnel, mais revenons un peu en arrière, à l'époque de la conception du stockage cloud.
Choix d'un référentiel pour les métadonnées
Lorsque nous avons été confrontés au défi que nous voulons avoir des géorégions, Active-Active, et que nous devons stocker des métadonnées quelque part, nous pensions que cela pourrait être?
De toute évidence, le référentiel (base de données) doit avoir les propriétés suivantes:
- Support actif-actif ;
- Évolutivité.
Nous aimerions vraiment que notre produit soit extrêmement populaire, et nous ne savons pas comment il évoluera en même temps, donc le système devrait évoluer.
- L'équilibre entre la tolérance aux pannes et la fiabilité du stockage.
Les métadonnées doivent être stockées en toute sécurité, car si nous les perdons et qu'il y avait un lien vers les données qu'elles contiennent, alors nous perdrons tout l'objet.
- Cohérence des opérations personnalisable.
Étant donné que nous travaillons dans plusieurs contrôleurs de domaine et permettons la possibilité que les contrôleurs de domaine soient indisponibles, en outre, les contrôleurs de domaine sont éloignés les uns des autres, nous ne pouvons pas, pendant la plupart des opérations API, exiger que cette opération soit effectuée simultanément deux DC. Ce sera trop lent et impossible si le deuxième DC n'est pas disponible. Par conséquent, une partie des opérations devrait fonctionner localement dans un seul contrôleur de domaine.
Mais, évidemment, une sorte de convergence devrait se produire à un moment donné et après avoir résolu tous les conflits, les données devraient être visibles dans les deux centres de données. Par conséquent, la cohérence des opérations doit être ajustée.
De mon point de vue, Cassandra convient à ces exigences.
Cassandra
Je serais très heureux si nous n'avions pas à utiliser Cassandra, car pour nous, c'était une sorte de nouvelle expérience. Mais rien d'autre ne convient. Il me semble que c'est la situation la plus triste sur le marché pour de tels systèmes de stockage - pas d'
alternative .

Qu'est-ce que Cassandra?
Il s'agit d'une base de données de valeurs-clés distribuée. Du point de vue de l'architecture et des idées qui y sont ancrées, il me semble que tout est cool. Si je le faisais, je ferais de même. Lorsque nous avons commencé, nous avons pensé à écrire notre propre système de stockage de métadonnées. Mais plus nous nous rendons compte de plus en plus que nous devrons faire quelque chose de très similaire à Cassandra, et les efforts que nous y consacrerons n'en valent pas la peine. Pour l'ensemble du développement
, nous n'avions qu'un mois et demi . Il serait étrange de les dépenser pour écrire votre base de données.
Si Cassandra était en couches comme un gâteau de couches, je sélectionnerais 3 couches:
1.
Stockage KV local sur chaque nœud.Il s'agit d'un cluster de nœuds, chacun pouvant stocker localement des données de valeur-clé.
2.
Partage des données sur les nœuds (hachage cohérent).Cassandra peut distribuer des données entre les nœuds du cluster, y compris la réplication, et il le fait de telle sorte que le cluster peut augmenter ou diminuer en taille, et les données seront redistribuées.
3. Un
coordinateur pour rediriger les demandes vers d'autres nœuds.Lorsque nous accédons aux données de certaines requêtes de notre application, Cassandra peut distribuer notre requête en nœuds afin que nous obtenions les données que nous voulons et avec le niveau de cohérence dont nous avons besoin - nous voulons simplement les lire quorum, ou souhaitez un quorum avec deux DC, etc.
Pour nous, deux ans avec Cassandra - c'est un roller coaster ou un roller coaster - tout ce que vous voulez. Tout a commencé en profondeur, nous n'avions aucune expérience avec Cassandra. Nous avions peur. Nous avons commencé et tout allait bien. Mais des chutes et des décollages constants commencent: le problème, tout est mauvais, nous ne savons pas quoi faire, nous obtenons des erreurs, puis nous résolvons le problème, etc.
Ces montagnes russes, en principe, ne se terminent pas à ce jour.
Bon
Le premier et dernier chapitre, où je dis que Cassandra est cool. C'est vraiment cool, un excellent système, mais si je continue à dire à quel point c'est bon, je pense que vous ne serez pas intéressé. Par conséquent, nous ferons plus attention aux mauvais, mais plus tard.
Cassandra est vraiment bonne.
- C'est l'un des systèmes qui nous permet d'avoir un temps de réponse en millisecondes , c'est-à-dire évidemment inférieur à 10 ms. C'est bon pour nous, car le temps de réponse en général est important pour nous. L'opération avec des métadonnées pour nous n'est qu'une partie de toute opération liée au stockage d'un objet, qu'il soit en réception ou en enregistrement.
- D'un point de vue d'enregistrement, une évolutivité élevée est obtenue. Vous pouvez écrire dans Cassandra à une vitesse folle, et dans certaines situations, cela est nécessaire, par exemple, lorsque nous déplaçons de grandes quantités de données entre les enregistrements.
- Cassandra est vraiment tolérante aux pannes . La chute d'un nœud ne conduit pas immédiatement à des problèmes, mais tôt ou tard, ils commenceront. Cassandra déclare qu'elle n'a pas un seul point d'échec, mais, en fait, il y a des points d'échec partout. En fait, celui qui a travaillé avec la base de données sait que même un crash de nœud n'est pas quelque chose qui souffre généralement jusqu'au matin. Habituellement, cette situation doit être corrigée plus rapidement.
- Simplicité. Pourtant, par rapport aux autres bases de données relationnelles Cassandra standard, il est plus facile de comprendre ce qui se passe. Très souvent, quelque chose ne va pas et nous devons comprendre ce qui se passe. Cassandra a plus de chances de le comprendre, d'obtenir la plus petite vis, probablement, qu'avec une autre base de données.
Cinq mauvaises histoires
Je le répète, Cassandra est bonne, cela fonctionne pour nous, mais je vais raconter cinq histoires de mauvais. Je pense que c'est pour cela que vous l'avez lu. Je vais donner les histoires par ordre chronologique, bien qu'elles ne soient pas très liées les unes aux autres.

Cette histoire a été la plus triste pour nous. Puisque nous stockons des données utilisateur, la pire chose possible est de les perdre, et de les
perdre pour toujours , comme cela s'est produit dans cette situation. Nous avons fourni des moyens de récupérer des données si nous les perdons dans Cassandra, mais nous les avons perdues de sorte que nous ne pouvions vraiment pas récupérer.
Afin d'expliquer comment cela se produit, je vais devoir parler un peu de la façon dont tout est organisé en nous.
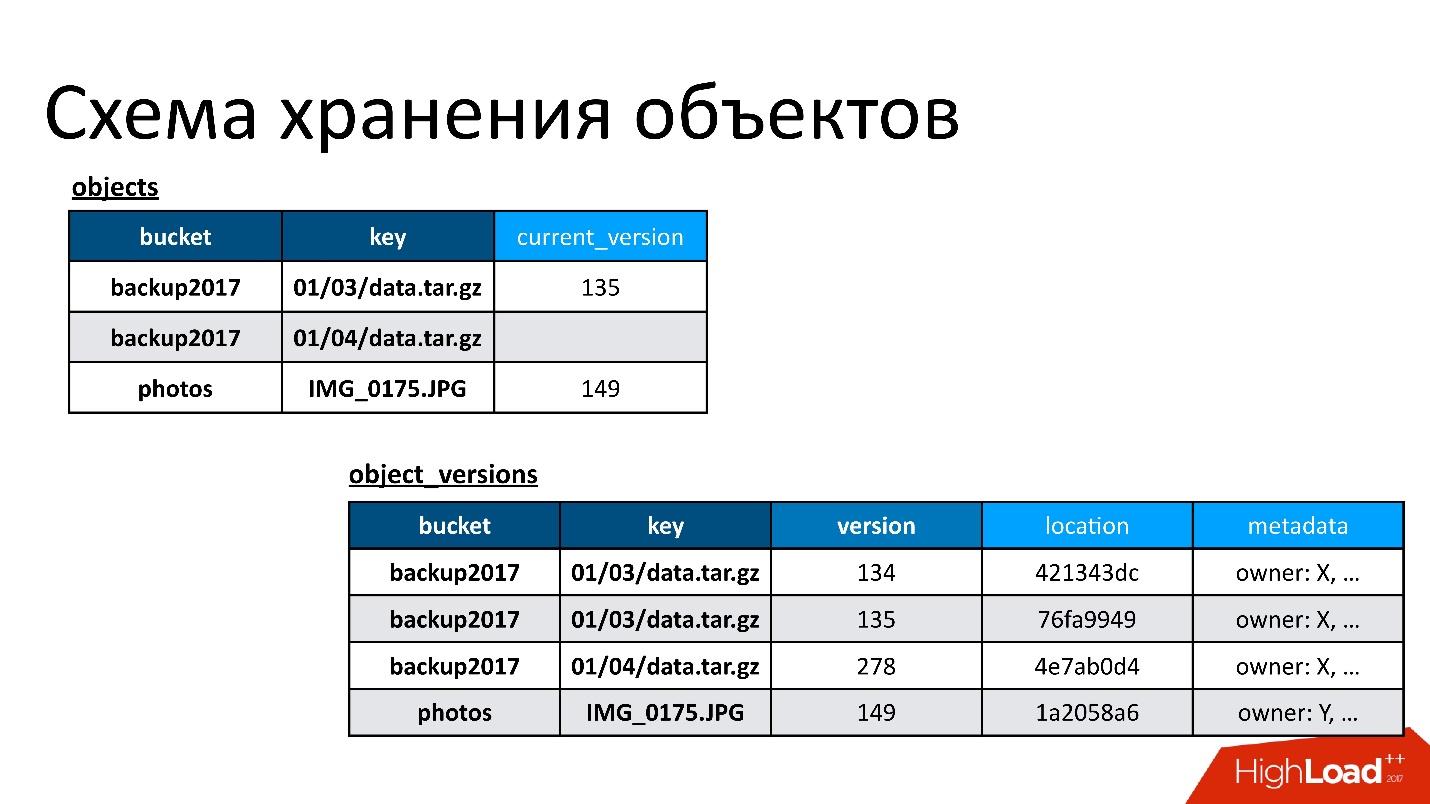
Du point de vue S3, il y a quelques éléments de base:
- Bucket - il peut être imaginé comme un énorme catalogue dans lequel l'utilisateur télécharge un objet (ci-après dénommé le bucket).
- Chaque objet a un nom (clé) et des métadonnées qui lui sont associées: taille, type de contenu et un pointeur vers les données de l'objet. Dans le même temps, la taille du seau n'est limitée par rien. Autrement dit, il peut s'agir de 10 clés, peut-être de 100 milliards de clés - il n'y a pas de différence.
- Toutes les opérations concurrentielles sont possibles, c'est-à-dire qu'il peut y avoir plusieurs remplissages compétitifs dans la même clé, il peut y avoir une suppression concurrentielle, etc.
Dans notre situation, des opérations actives-actives peuvent se produire, y compris de manière compétitive dans différents DC, pas seulement dans un. Par conséquent, nous avons besoin d'une sorte de schéma de conservation qui nous permettra de mettre en œuvre une telle logique. Au final, nous avons choisi une politique simple: la dernière version enregistrée l'emporte. Parfois, plusieurs opérations concurrentielles ont lieu, mais il n'est pas nécessaire que nos clients le fassent exprès. Il peut s'agir simplement d'une demande qui a commencé, mais le client n'a pas attendu de réponse, quelque chose d'autre s'est produit, a réessayé, etc.
Par conséquent, nous avons deux tables de base:
- Table d'objets . Dans ce document, une paire - le nom du compartiment et le nom de la clé - est associée à sa version actuelle. Si l'objet est supprimé, il n'y a rien dans cette version. Si l'objet existe, il existe sa version actuelle. En fait, dans ce tableau, nous modifions uniquement le champ de la version actuelle.
- Table de version des objets . Nous n'insérons que de nouvelles versions dans ce tableau. Chaque fois qu'un nouvel objet est téléchargé, nous insérons une nouvelle version dans le tableau des versions, lui donnons un numéro unique, enregistrons toutes les informations le concernant et, à la fin, mettons à jour le lien vers celui-ci dans le tableau des objets.
La figure montre un exemple de la façon dont les tables d'objets et les versions d'objets sont liées.

Voici un objet qui a deux versions - une actuelle et une ancienne, il y a un objet qui a déjà été supprimé et sa version est toujours là. Nous devons nettoyer de temps en temps les versions inutiles, c'est-à-dire supprimer quelque chose auquel personne d'autre ne fait référence. De plus, nous n'avons pas besoin de le supprimer tout de suite, nous pouvons le faire en mode différé. Il s'agit de notre nettoyage interne, nous supprimons simplement ce qui n'est plus nécessaire.
Il y avait un problème.
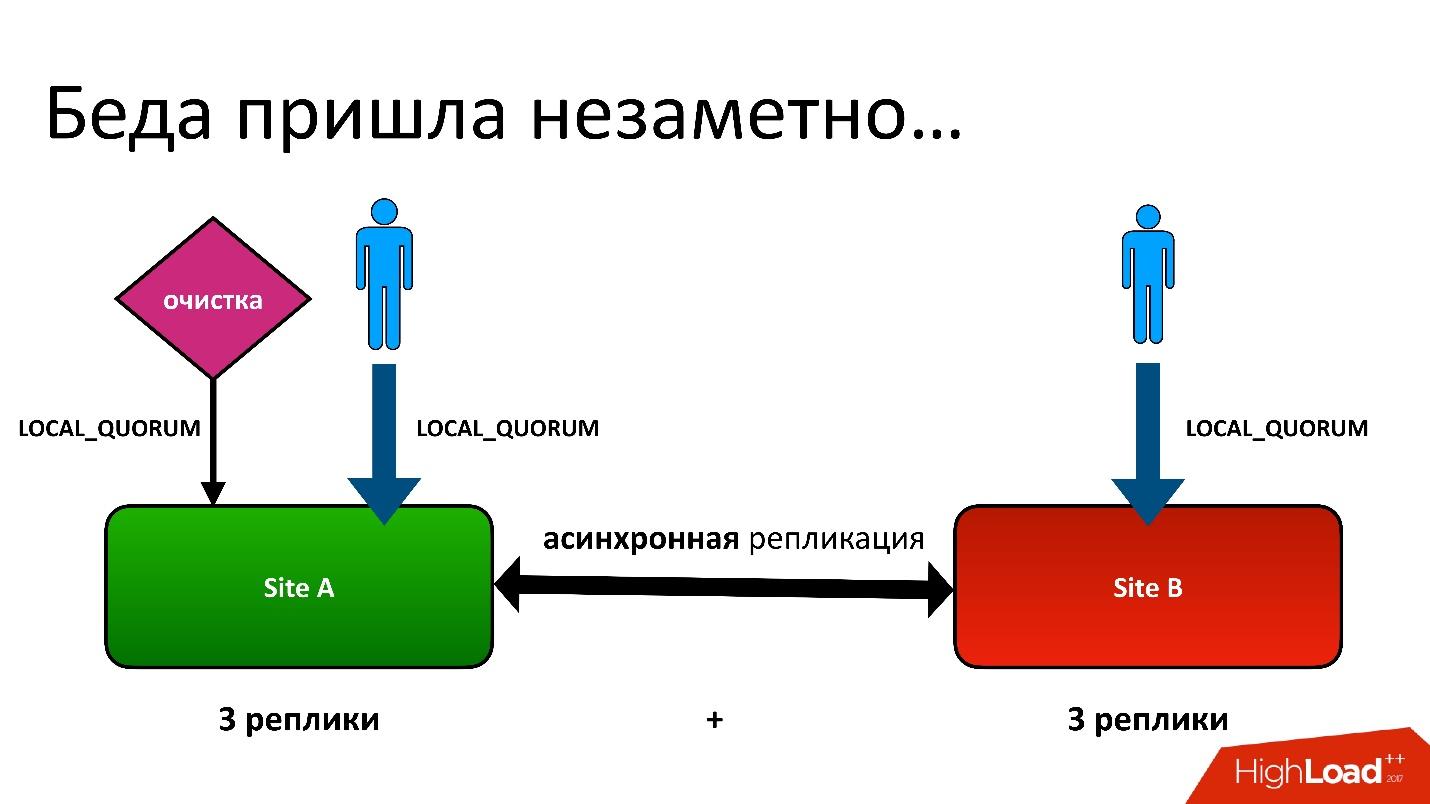
Le problème était le suivant: nous avons actif-actif, deux DC. Dans chaque DC, les métadonnées sont stockées en trois copies, c'est-à-dire que nous avons 3 + 3 - seulement 6 répliques. Lorsque les clients nous contactent, nous effectuons des opérations avec cohérence (du point de vue de Cassandra cela s'appelle LOCAL_QUORUM). Autrement dit, il est garanti que l'enregistrement (ou la lecture) s'est produit dans 2 répliques dans le contrôleur de domaine local. Ceci est une garantie - sinon l'opération échouera.
Cassandra essaiera toujours d'écrire dans les 6 lignes - 99% du temps tout ira bien. En fait, les 6 répliques seront les mêmes, mais garanties pour nous 2.
Nous avons eu une situation difficile, même si ce n'était même pas une géorégion. Même pour les régions ordinaires qui se trouvent dans un DC, nous avons toujours stocké la deuxième copie des métadonnées dans un autre DC. C'est une longue histoire, je ne donnerai pas tous les détails. Mais à la fin, nous avons eu un processus de nettoyage qui a supprimé les versions inutiles.
Et puis le même problème s'est posé. Le processus de nettoyage a également fonctionné avec la cohérence du quorum local dans un centre de données, car cela n'a aucun sens de le faire fonctionner en deux - ils se battront.
Tout allait bien jusqu'à ce qu'il s'avère que nos utilisateurs écrivent encore parfois dans un autre centre de données, ce que nous ne soupçonnions pas. Tout a été mis en place juste au cas où le feylover, mais il s'est avéré qu'ils l'utilisaient déjà.
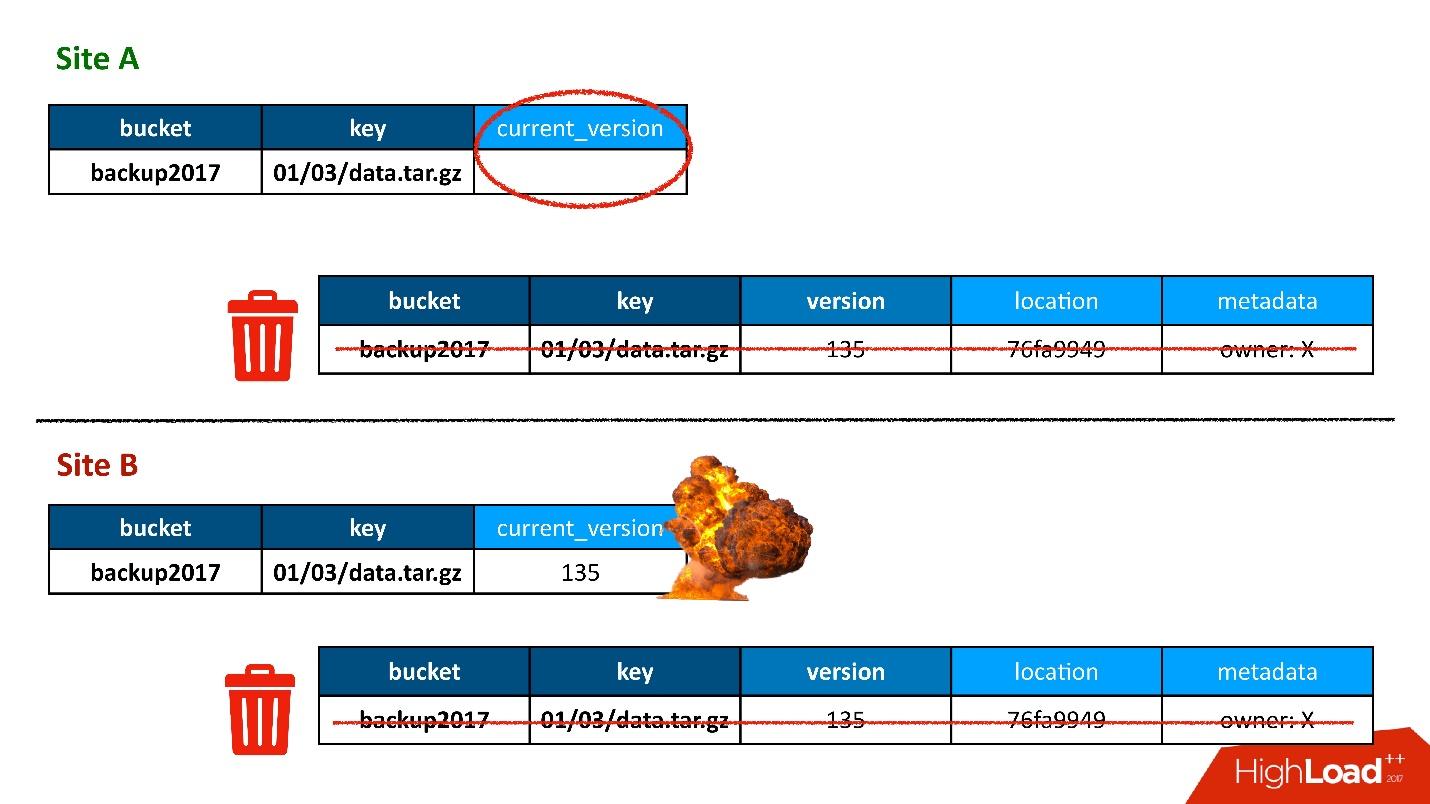
La plupart du temps, tout allait bien jusqu'au jour où une situation s'est produite lorsqu'un enregistrement dans la table des versions a été répliqué dans les deux contrôleurs de domaine, mais l'enregistrement dans la table des objets s'est avéré ne se trouver que dans un seul contrôleur de domaine, mais n'est pas entré dans le second. En conséquence, la procédure de nettoyage, lancée dans le premier DC (supérieur), a vu qu'il y avait une version à laquelle personne ne faisait référence et l'a supprimée. Et j'ai supprimé non seulement la version, mais aussi, bien sûr, les données - tout est complètement, car ce n'est qu'un objet inutile. Et cette suppression est irrévocable.
Bien sûr, il y a un «boom» supplémentaire, car nous avons encore un enregistrement dans la table des objets qui fait référence à une version qui n'existe plus.
Donc, la première fois que nous avons perdu des données, nous les avons perdues de manière irrévocable - bien, un peu.
Solution
Que faire Dans notre situation, tout est simple.
Comme nous avons des données stockées dans deux centres de données, le processus de nettoyage est un processus de convergence et de synchronisation. Nous devons lire les données des deux DC. Ce processus ne fonctionnera que lorsque les deux contrôleurs de domaine seront disponibles. Puisque j'ai dit que c'est un processus retardé qui ne se produit pas pendant le traitement de l'API, ce n'est pas effrayant.
La cohérence TOUT est une caractéristique de Cassandra 2. Dans Cassandra 3, tout va un peu mieux - il y a un niveau de cohérence, qui est appelé quorum dans chaque DC. Mais en tout cas, il y a le problème qu'il est
lent , car, tout d'abord, nous devons nous tourner vers le DC distant. Deuxièmement, dans le cas de la cohérence des 6 nœuds, cela signifie que cela fonctionne à la vitesse du pire de ces 6 nœuds.
Mais en même temps, le processus dit de
réparation en lecture se produit, lorsque toutes les répliques ne sont pas synchrones. Autrement dit, lorsque l'enregistrement a échoué quelque part, ce processus les répare simultanément. C’est ainsi que Cassandra fonctionne.
Lorsque cela s'est produit, nous avons reçu une plainte du client selon laquelle l'objet n'était pas disponible. Nous l'avons compris, compris pourquoi, et la première chose que nous voulions faire était de découvrir combien d'autres objets de ce type nous avions. Nous avons exécuté un script qui tentait de trouver une construction similaire à celle-ci lorsqu'il y avait une entrée dans une table, mais aucune entrée dans une autre.
Soudain, nous avons constaté que nous possédions
10% de ces enregistrements . Rien de pire, probablement, n'aurait pas pu se produire si nous n'avions pas deviné que ce n'était pas le cas. Le problème était différent.

Des zombies se sont glissés dans notre base de données. Il s'agit du nom semi-officiel de ce problème. Pour comprendre de quoi il s'agit, vous devez parler du fonctionnement de la suppression à Cassandra.
Par exemple, nous avons des données
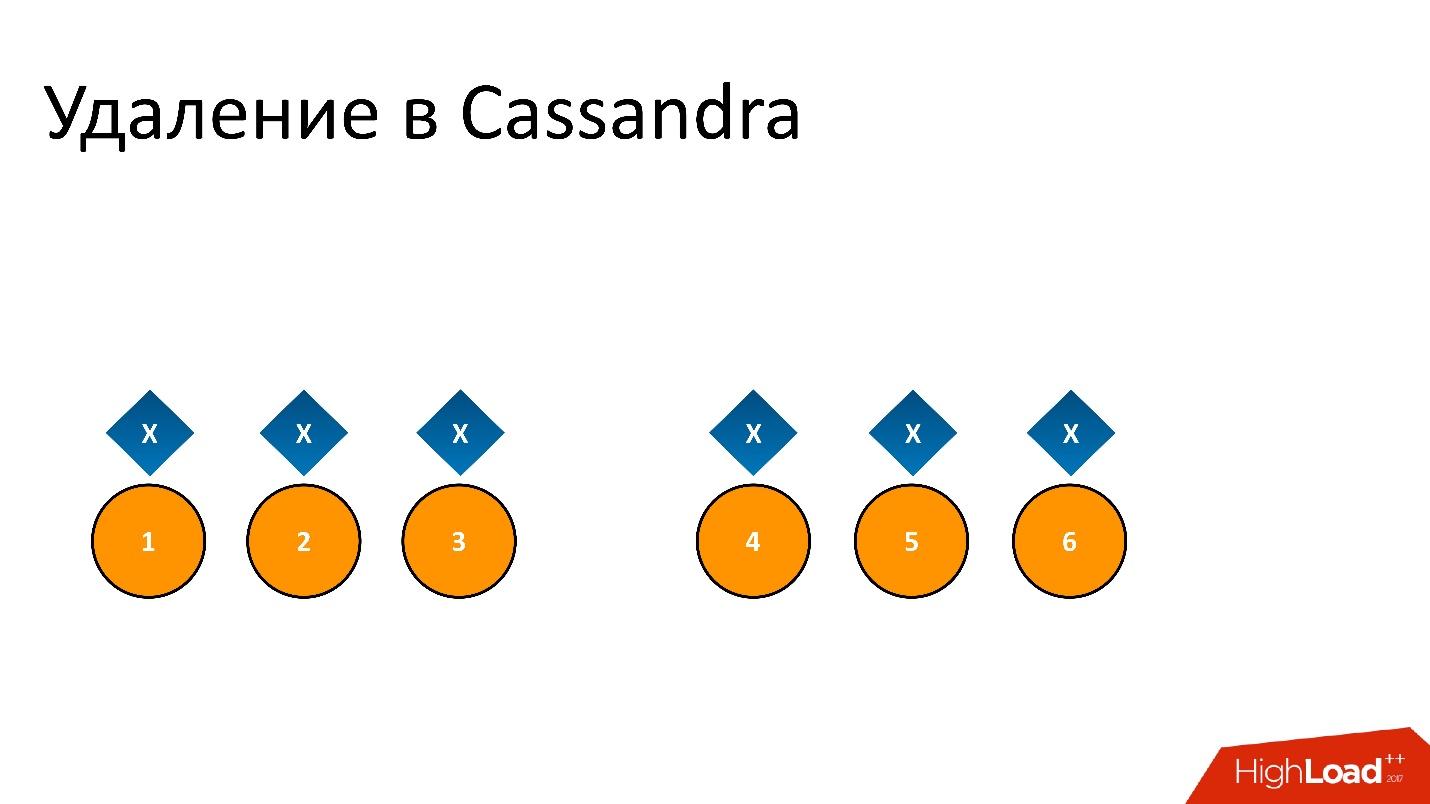
x qui sont enregistrées et parfaitement répliquées sur les 6 répliques. Si nous voulons le supprimer, la suppression, comme toute opération dans Cassandra, peut ne pas être effectuée sur tous les nœuds.
Par exemple, nous voulions garantir la cohérence de 2 sur 3 dans un DC. Laissez l'opération de suppression être effectuée sur cinq nœuds, mais restez sur un enregistrement, par exemple, car le nœud n'était pas disponible à ce moment.
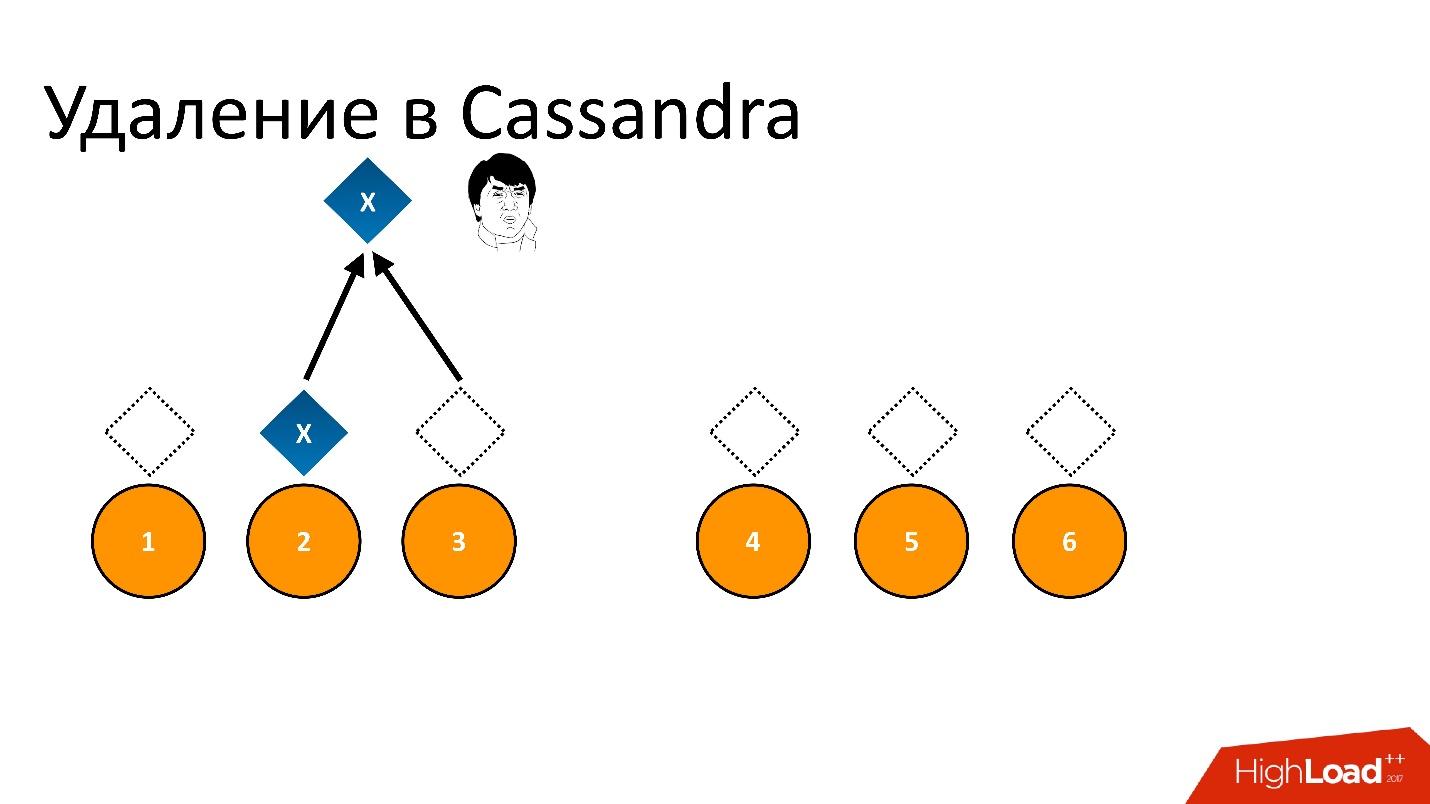
Si nous supprimons cela et essayons ensuite de lire «Je veux 2 sur 3» avec la même cohérence, alors Cassandra, voyant la valeur et son absence, interprète cela comme la présence de données. Autrement dit, en relisant, elle dira: "Oh, il y a des données!", Bien que nous les ayons supprimées. Par conséquent, vous ne pouvez pas supprimer de cette manière.

Cassandra enlève différemment.
La suppression est en fait un record . Lorsque nous supprimons des données, Cassandra écrit un petit marqueur appelé
Tombstone (tombstone). Il marque que les données sont supprimées. Ainsi, si nous lisons le jeton de suppression et les données en même temps, Cassandra préfère toujours le jeton de suppression dans cette situation et dit qu'il n'y a en fait aucune donnée. Voilà ce dont vous avez besoin.
Tombstone — , , , , - , . Tombstone .
Tombstone gc_grace_period . , , .
?
Repair
Cassandra , Repair (). — , . , , , , / , , - - , .. . Repair , .

, - , - . Repair , , . - , — . , .

Repair, , , , — , . 6 . — , , .

, — , - . , . , - , , , .
Solution
, :
, repair. , , .
repair — , repair. , , 10-20 , , 3 . Tombstone , . , , -.

Cassandra, . .
S3 . , — 10 , 100 . API, — . , , , , , . , , , — , . .
API?

, — , , — , , . . — . , , . , , Cassandra. , — , , , .
, , , , . , . , , . , - , .
Cassandra , . , , , , , .
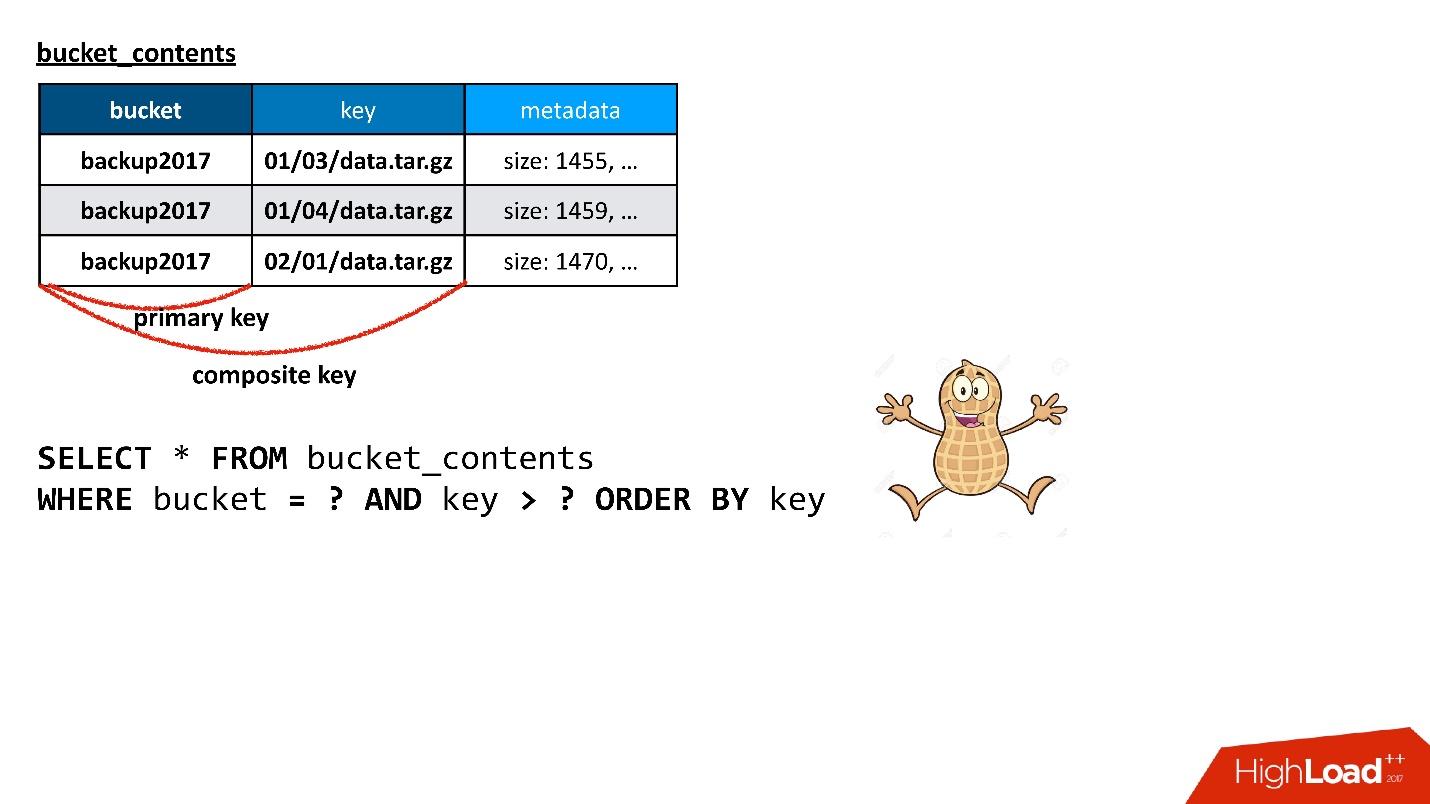
, Cassandra
composite key . , — , - , — . , . ? , , !
, , , , — , .
. Cassandra ,
Cassandra . , , Cassandra, : , , SQL .. !

. Cassandra ? , , API. , , , , ( ) .
, .
, . , , , . , — — . , , , .
Cassandra , . : « 100 », , , , , , 100, .
, ( ), — , , . , , , , , - . 100 , - , , . , SQL .
Cassandra , , Java, . ,
Large Partition , . — , , , , — . , , garbage collection .. .
, ,
, , .
, , - .

, , . . , Large Partition.
:
- ( , - );
- , , . , .
, , , key_hash 0. ,
, . , . , , .
, .

— , , , - - .
— , N ? , Large Partition, — . , . : . , , , , - . , . , , .

— , , - . - , , . , , . , , ..
— , ? , . ? - md5- — , - 30 — , - . . , , .

, , , , . — , . , . , - - - , - - — . , . .
, , , .
- .
- .
- Cassandra.
- Redistribution en ligne (sans arrêt des opérations ni perte de cohérence).
Nous avons maintenant un état du compartiment, il est en quelque sorte divisé en partitions. On comprend alors que certaines partitions sont trop grandes ou trop petites. Nous devons trouver une nouvelle partition, qui, d'une part, sera optimale, c'est-à-dire que la taille de chaque partition sera inférieure à certaines de nos limites, et elles seront plus ou moins uniformes. Dans ce cas, la transition de l'état actuel à un nouvel état doit nécessiter un nombre minimum d'actions. Il est clair que toute transition nécessite de déplacer des clés entre les partitions, mais moins nous les déplaçons, mieux c'est.
Nous l'avons fait. Probablement, la partie qui traite de la sélection de la distribution est l'élément le plus difficile de l'ensemble du service, si nous parlons de travailler avec les métadonnées en général. Nous l'avons réécrit, retravaillé et le faisons toujours, car certains clients ou certains modèles de création de clés sont toujours trouvés qui ont atteint un point faible de ce schéma.
Par exemple, nous avons supposé que le seau se développerait plus ou moins uniformément. Autrement dit, nous avons choisi une sorte de distribution et nous espérions que toutes les partitions se développeraient conformément à cette distribution. Mais nous avons trouvé un client qui écrit toujours à la fin, dans le sens où ses clés sont toujours triées. Il bat tout le temps dans la toute dernière partition, qui croît à une vitesse telle qu'en une minute, elle peut atteindre 100 000 touches. Et 100 000 est approximativement la valeur qui tient dans une partition.
Nous n'aurions tout simplement pas le temps de traiter un tel ajout de clés avec notre algorithme, et nous avons dû introduire une distribution préliminaire spéciale pour ce client. Puisque nous savons à quoi ressemblent ses clés, si nous voyons que c'est lui, nous commençons juste à créer des partitions vides à l'avance à la fin, afin qu'il puisse y écrire calmement, et jusqu'à présent, nous aurions un peu de repos jusqu'à la prochaine itération, quand nous devrons à nouveau tout redistribuer.
Tout cela se passe en ligne dans le sens où nous n'arrêtons pas l'opération. Il peut y avoir des opérations de lecture, d'écriture, à tout moment vous pouvez demander une liste de clés. Il sera toujours cohérent, même si nous sommes en train de repartitionner.
C'est assez intéressant, et ça s'avère avec Cassandra. Ici, vous pouvez jouer avec des astuces liées au fait que Cassandra est capable de résoudre les conflits. Si nous avons écrit deux valeurs différentes sur la même ligne, alors la valeur qui a un horodatage plus grand l'emporte.
L'horodatage est généralement l'horodatage actuel, mais il peut être transmis manuellement. Par exemple, nous voulons écrire une valeur dans une chaîne, qui dans tous les cas doit être effacée si le client écrit lui-même quelque chose. Autrement dit, nous copions certaines données, mais nous voulons que le client, s'il écrit soudainement avec nous en même temps, puisse les écraser. Ensuite, nous pouvons simplement copier nos données avec un horodatage un peu du passé. Ensuite, tout enregistrement en cours sera délibérément effiloché, quel que soit l'ordre dans lequel l'enregistrement a été effectué.
Ces astuces vous permettent de le faire en ligne.
Solution
- Ne laissez jamais, jamais l'apparence d'une grande partition .
- Répartissez les données par clé primaire en fonction de la tâche.
Si quelque chose de similaire à une grande partition est prévu dans le schéma de données, vous devez immédiatement essayer de faire quelque chose - comprendre comment le casser et comment s'en éloigner. Tôt ou tard, cela se produit, car tout index inversé se produit tôt ou tard dans presque toutes les tâches. Je vous ai déjà raconté une telle histoire - nous avons une clé de compartiment dans l'objet, et nous devons obtenir une liste de clés du compartiment - en fait, c'est un index.
De plus, la partition peut être volumineuse non seulement à partir des données, mais également à partir de pierres tombales (marqueurs de suppression). Du point de vue des internes de Cassandra (nous ne les voyons jamais de l'extérieur), les marqueurs de suppression sont également des données, et une partition peut être grande si beaucoup de choses y sont supprimées, car la suppression est un enregistrement. N'oubliez pas non plus.

Une autre histoire qui est en fait constante est que quelque chose ne va pas du début à la fin. Par exemple, vous voyez que le temps de réponse de Cassandra a augmenté, il répond lentement. Comment comprendre et comprendre quel est le problème? Il n'y a jamais de signal externe indiquant que le problème existe.

Par exemple, je vais donner un graphique - c'est le temps de réponse moyen du cluster dans son ensemble. Cela montre que nous avons un problème - le temps de réponse maximum est de 12 secondes - c'est le timeout interne de Cassandra. Cela signifie qu'elle va s'arrêter elle-même. Si le délai est supérieur à 12 s, cela signifie très probablement que le ramasse-miettes fonctionne et que Cassandra n'a même pas le temps de répondre au bon moment. Elle se répond par timeout, mais le temps de réponse à la plupart des demandes, comme je l'ai dit, devrait être en moyenne de 10 ms.
Sur le graphique, la moyenne a déjà dépassé des centaines de millisecondes - quelque chose s'est mal passé. Mais en regardant cette photo, il est impossible de comprendre quelle est la raison.

Mais si vous développez les mêmes statistiques sur les nœuds Cassandra, vous pouvez voir qu'en principe, tous les nœuds ne sont plus ou moins rien, mais le temps de réponse pour un nœud diffère par ordre de grandeur. Il y a très probablement un problème avec lui.
Les statistiques sur les nœuds changent complètement l'image. Ces statistiques sont du côté de l'application. Mais ici, il est en fait très souvent difficile de comprendre quel est le problème. Lorsqu'une application accède à Cassandra, elle accède à un nœud, l'utilisant comme coordinateur. En d'autres termes, l'application envoie une demande et le coordinateur la redirige vers les répliques contenant les données. Ceux-là répondent déjà, et le coordinateur forme la réponse finale.
Mais pourquoi le coordinateur répond-il lentement? Peut-être que le problème est avec lui, en tant que tel, c'est-à-dire qu'il ralentit et répond lentement? Ou peut-être qu'il ralentit, parce que les répliques lui répondent lentement? Si les répliques répondent lentement, du point de vue de l'application, cela ressemblera à une réponse lente du coordinateur, même si cela n'a rien à voir avec cela.
Voici une situation heureuse - il est clair qu'un seul nœud répond lentement, et très probablement le problème est là-dedans.
Complexité de l'interprétation
- Temps de réponse du coordinateur (nœud vs réplique lui-même).
- Une table spécifique ou le nœud entier?
- GC Pause? Pool de threads inadéquat?
- Trop de SSTables non compactés?
Il est toujours difficile de comprendre ce qui ne va pas. Il a juste
besoin de beaucoup de statistiques et de surveillance , à la fois du côté des applications et de Cassandra lui-même, car si c'est vraiment mauvais, rien n'est visible de Cassandra. Vous pouvez regarder le niveau des requêtes individuelles, au niveau de chaque table spécifique, à chaque nœud spécifique.
Il peut y avoir, par exemple, une situation où une table de ce qui est appelé dans Cassandra SSTables (fichiers séparés) en a trop. Pour la lecture, Cassandra doit, grosso modo, trier toutes les SSTables. S'il y en a trop, alors simplement le processus de ce tri prend trop de temps et la lecture commence à s'affaisser.
La solution est le compactage, ce qui réduit le nombre de ces SSTables, mais il convient de noter qu'il ne peut être que sur un nœud pour une table spécifique. Étant donné que Cassandra, malheureusement, est écrit en Java et s'exécute sur la JVM, peut-être que le garbage collector est entré dans une telle pause qu'il n'a tout simplement pas le temps de répondre. Lorsque le garbage collector entre en pause, non seulement vos demandes ralentissent, mais l'
interaction au sein du cluster Cassandra entre les nœuds commence à ralentir . Les nœuds l'un de l'autre commencent à être considérés comme étant tombés, c'est-à-dire tombés, morts.
Une situation encore plus amusante commence, car lorsqu'un nœud pense qu'un autre nœud est en panne, il ne lui envoie pas de demandes, et deuxièmement, il commence à essayer d'enregistrer les données dont il aurait besoin pour se répliquer sur un autre nœud à lui-même localement, alors il commence à se tuer lentement, etc.
Il existe des situations où ce problème peut être résolu simplement en utilisant les paramètres corrects. Par exemple, il peut y avoir suffisamment de ressources, tout va bien et merveilleux, mais juste un pool de threads, dont le nombre est de taille fixe, doit être augmenté.
Enfin, nous devons peut-être limiter la compétitivité du côté conducteur. Parfois, il arrive que trop de demandes concurrentielles ont été envoyées, et comme toute base de données, Cassandra ne peut pas les traiter et va au corps à corps lorsque le temps de réponse augmente de façon exponentielle, et nous essayons de donner de plus en plus de travail.
Compréhension du contexte
Il y a toujours un certain contexte pour le problème - ce qui se passe dans le cluster, si Repair fonctionne maintenant, sur quel nœud, dans quels espaces clés, dans quelle table.
Par exemple, nous avons eu des problèmes assez ridicules avec le fer. Nous avons vu qu'une partie des nœuds est lente. Il a été découvert plus tard que la raison en était que dans le BIOS, leurs processeurs étaient en mode d'économie d'énergie. Pour une raison quelconque, lors de l'installation initiale de fer, cela s'est produit et environ 50% des ressources du processeur ont été utilisées par rapport aux autres nœuds.
En fait, comprendre un tel problème peut être difficile. Le symptôme est le suivant: il semble que le nœud effectue le compactage, mais il le fait lentement. Parfois, il est lié au fer, parfois non, mais ce n'est qu'un autre bug de Cassandra.
Par conséquent, la surveillance est obligatoire et nécessite beaucoup. Plus la fonctionnalité de Cassandra est complexe, plus elle est éloignée de l'écriture et de la lecture simples, plus il y a de problèmes et plus vite elle peut tuer une base de données avec un nombre suffisant de requêtes. Par conséquent, si possible, ne regardez pas des chips "savoureuses" et essayez de les utiliser, il vaut mieux les éviter autant que possible. Pas toujours possible - bien sûr, tôt ou tard, c'est nécessaire.

La dernière histoire concerne la façon dont Cassandra a gâché les données. Dans cette situation, cela s'est produit à l'intérieur de Cassandra. C'était intéressant.
Nous avons vu qu'environ une fois par semaine dans notre base de données plusieurs dizaines de lignes endommagées apparaissent - elles sont littéralement obstruées par des ordures. De plus, Cassandra valide les données qui vont à son entrée. Par exemple, s'il s'agit d'une chaîne, elle doit être dans utf8. Mais dans ces lignes, il y avait des ordures, pas utf8, et Cassandra n'a même rien donné à voir avec cela. Lorsque j'essaie de supprimer (ou de faire autre chose), je ne peux pas supprimer une valeur qui n'est pas utf8, car, en particulier, je ne peux pas la saisir dans OERE, car la clé doit être utf8.
Des lignes gâtées apparaissent, comme un flash, à un moment donné, puis elles disparaissent à nouveau pendant plusieurs jours ou semaines.
Nous avons commencé à chercher un problème. Nous avons pensé qu'il y avait peut-être un problème dans un nœud particulier avec lequel nous jouions, en faisant quelque chose avec les données, en copiant SSTables. Peut-être, tout de même, vous pouvez voir des répliques de ces données? Peut-être que ces répliques ont un nœud commun, le plus petit facteur commun? Peut-être que certains nœuds se bloquent? Non, rien de tel.
Peut-être quelque chose avec un disque? Les données sont-elles corrompues sur le disque? Non encore.
Peut-être un souvenir? Non! Dispersé sur un cluster.
C'est peut-être une sorte de problème de réplication? Un nœud a tout gâché et reproduit une mauvaise valeur? - Non.
Enfin, c'est peut-être un problème d'application?
De plus, à un moment donné, les lignes endommagées ont commencé à apparaître dans deux grappes de Cassandra. L'un a travaillé sur la version 2.1, le second sur le troisième. Il semble que Cassandra soit différente, mais le problème est le même. Peut-être que notre service envoie de mauvaises données? Mais c'était difficile à croire. Cassandra valide les données d'entrée; elle n'a pas pu écrire d'ordures. Mais tout d'un coup?
Rien ne va.
Une aiguille a été trouvée!
Nous nous sommes battus longtemps et durement jusqu'à ce que nous découvrions un petit problème: pourquoi avons-nous une sorte de vidage sur incident de la JVM sur les nœuds auquel nous n'avons pas prêté beaucoup d'attention? Et d'une manière ou d'une autre, cela semble suspect dans le collecteur de déchets de trace de pile ... Et pour une raison quelconque, certaines traces de pile sont également obstruées par des déchets.
En fin de compte, nous avons réalisé - oh,
pour une raison quelconque, nous utilisons la JVM de l'ancienne version de 2015 . C'était la seule chose courante qui unissait les clusters Cassandra sur différentes versions de Cassandra.
Je ne sais toujours pas quel était le problème, car rien n’était écrit à ce sujet dans les notes de version officielles de la JVM. Mais après la mise à jour, tout a disparu, le problème ne s'est plus posé. De plus, cela ne s'est pas produit dans le cluster dès le premier jour, mais à un moment donné, bien qu'il ait longtemps fonctionné sur la même machine virtuelle Java.
Récupération de données
Quelle leçon en avons-nous tirée:
● La sauvegarde est inutile.
Comme nous l'avons découvert, les données ont été corrompues dès la seconde où elles ont été enregistrées. Au moment où les données sont entrées dans le coordinateur, elles étaient déjà corrompues.
● Une restauration partielle des colonnes intactes est possible.
Certaines colonnes n'ont pas été endommagées, nous avons pu lire ces données, les restaurer partiellement.
● En fin de compte, nous avons dû effectuer une récupération à partir de diverses sources.
Nous avions des métadonnées de sauvegarde dans l'objet, mais dans les données elles-mêmes. Pour renouer avec l'objet, nous avons utilisé des journaux, etc.
● Les journaux sont inestimables!
Nous avons pu récupérer toutes les données corrompues, mais au final, il est très difficile de faire confiance à la base de données si elle perd vos données même sans aucune action de votre part.
Solution
- Mettez à jour la JVM après des tests approfondis.
- Surveillance des plantages JVM.
- Ayez une copie indépendante de Cassandra des données.
Un conseil: essayez d'avoir une sorte de copie indépendante de Cassandra des données à partir de laquelle vous pouvez récupérer si nécessaire. Cela peut être la solution de dernier niveau. Laissez cela prendre beaucoup de temps, de ressources, mais il devrait y avoir une option qui vous permettra de renvoyer des données.
Bugs
●
Mauvaise qualité des tests de versionLorsque vous commencez à travailler avec Cassandra, il y a un sentiment constant (surtout si vous vous déplacez, relativement parlant, de «bonnes» bases de données, par exemple, PostgreSQL) que si vous avez corrigé un bogue dans la version de la précédente, vous en ajouterez certainement un nouveau. Et le bug n'est pas un non-sens, il s'agit généralement de données corrompues ou d'un autre comportement incorrect.
●
Problèmes persistants avec des fonctionnalités complexesPlus la fonctionnalité est complexe, plus elle pose de problèmes, de bugs, etc.
●
N'utilisez pas de réparation incrémentielle en 2.1La fameuse réparation, dont j'ai parlé, qui corrige la cohérence des données, en mode standard, quand elle interroge tous les nœuds, fonctionne bien. Mais pas dans le mode dit incrémentiel (lorsque la réparation ignore les données qui n'ont pas changé depuis la réparation précédente, ce qui est assez logique). Il a été annoncé il y a longtemps, officiellement, car une fonctionnalité existe, mais tout le monde dit: «Non, dans la version 2.1, ne l'utilisez jamais! Il va certainement manquer quelque chose. En 3, nous le réparons. »
●
Mais n'utilisez pas la réparation incrémentielle dans 3.xLorsque la troisième version est sortie, quelques jours plus tard, ils ont dit: «Non, vous ne pouvez pas l'utiliser dans la 3e. Il y a une liste de 15 bugs, donc en aucun cas n'utilisez pas de réparation incrémentielle. En 4e, nous ferons mieux! »
Je ne les crois pas. Et c'est un gros problème, surtout avec l'augmentation de la taille du cluster. Par conséquent, vous devez surveiller constamment leur bugtracker et voir ce qui se passe. Malheureusement, il est impossible de vivre avec eux sans lui.
●
Besoin de garder une trace de JIRA
Si vous dispersez toutes les bases de données sur le spectre de prévisibilité, pour moi, Cassandra est à gauche dans la zone rouge. Cela ne veut pas dire que c'est mauvais, il suffit de se préparer au fait que Cassandra est imprévisible dans tous les sens du terme: à la fois dans la façon dont cela fonctionne et dans le fait que quelque chose peut arriver.

Je vous souhaite de trouver d'autres râteaux et de marcher dessus, car, de mon point de vue, quoi qu'il arrive, Cassandra est bonne et certainement pas ennuyeuse. N'oubliez pas les bosses sur la route!
Réunion ouverte des militants de HighLoad ++
Le 31 juillet à Moscou, à 19h00, une réunion des orateurs, du Comité du programme et des militants de la conférence des développeurs de systèmes à haute charge HighLoad ++ 2018 aura lieu . Nous organiserons un petit brainstorming sur le programme de cette année afin de ne rien manquer de nouveau et d'important. La réunion est ouverte, mais vous devez vous inscrire .
Appel à communications
Accepter activement les demandes de rapports à Highload ++ 2018. Le Comité du programme attend votre résumé jusqu'à la fin de l'été.