
Il s'agit d'une continuation de la première partie de l'article.
Dans la première partie de l'article, l'auteur a parlé des conditions du concours pour le jeu Agario sur mail.ru, de la structure du monde du jeu et en partie de la structure du bot. En partie, car ils n'affectaient que le dispositif des capteurs d'entrée et des commandes en sortie du réseau neuronal (ci-après en images et texte il y aura une abréviation NN). Essayons donc d'ouvrir la boîte noire et de comprendre comment tout y est organisé.
Et voici la première photo:
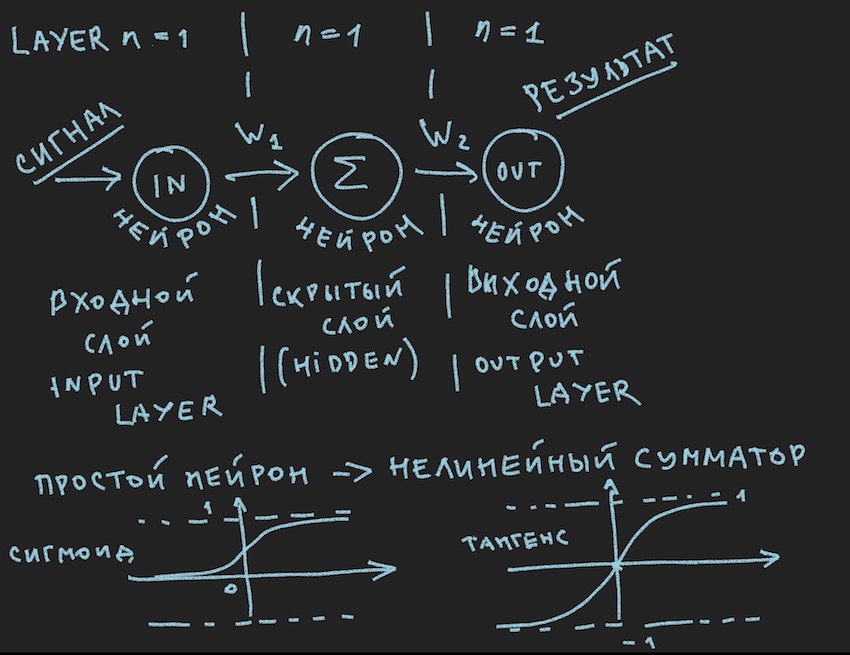
Il décrit schématiquement ce qui devrait provoquer un sourire ennuyé de mon lecteur, disent-ils encore en première année, ils ont été vus plusieurs fois dans diverses sources . Mais nous voulons vraiment appliquer pratiquement cette image à la gestion du bot, donc après la note importante, nous l'examinons de plus près.
Remarque importante: il existe un grand nombre de solutions prêtes à l'emploi (frameworks) pour travailler avec les réseaux de neurones:

Tous ces packages résolvent les tâches principales du développeur de réseaux de neurones: la construction et l'entraînement de NN ou la recherche de poids "optimaux". Et la méthode principale de cette recherche est la rétropropagation . Il a été inventé dans les années 70 du siècle dernier, comme l'indique l'article au lien ci-dessus, pendant ce temps, en tant que bas du navire, il a acquis diverses améliorations, mais l'essence est la même: trouver des coefficients de poids avec une base d'exemples de formation et il est hautement souhaitable que tout le monde de ces exemples contenaient une réponse toute faite sous la forme d'un signal de sortie d'un réseau neuronal. Le lecteur peut m'objecter. que des réseaux d'auto-apprentissage de diverses classes et principes ont déjà été inventés, mais tout ne se passe pas bien là-bas, pour autant que je sache. Bien sûr, il est prévu d'étudier ce zoo plus en détail, mais je pense que je trouverai des personnes partageant les mêmes idées qu'un vélo fabriqué sans dessin spécial est encore plus incurvé au cœur du créateur qu'un clone de convoyeur d'un vélo idéal.
Comprenant que le serveur de jeu n'aura probablement pas ces bibliothèques et que la puissance de calcul allouée par les organisateurs en tant que cœur de processeur n'est clairement pas suffisante pour un cadre lourd, l'auteur a ensuite créé son propre vélo. Un commentaire important à ce sujet a pris fin.
Revenons à l'image représentant probablement le plus simple des réseaux de neurones possibles avec une couche cachée (aka couche cachée ou couche cachée). Maintenant, l'auteur lui-même a regardé fixement l'image avec des idées sur cet exemple simple pour révéler au lecteur les profondeurs des réseaux de neurones artificiels. Lorsque tout est simplifié en primitif, il est plus facile de comprendre l'essence. L'essentiel est que le neurone de la couche cachée n'a rien à résumer. Et très probablement, ce n'est même pas un réseau de neurones, dans les manuels, le NN le plus simple est un réseau à deux entrées. Nous voici donc pour ainsi dire les découvreurs des réseaux les plus simples.
Essayons de décrire ce réseau neuronal (pseudocode):
Nous introduisons la topologie du réseau sous la forme d'un tableau, où chaque élément correspond à la couche et au nombre de neurones qu'elle contient:
int array Topology= { 1, 1, 1}
Nous avons également besoin d'un tableau flottant de poids du réseau de neurones W, considérant notre réseau comme un «réseaux de neurones à action directe (FF ou FFNN)», où chaque neurone de la couche actuelle est connecté à chaque neurone de la couche suivante, nous obtenons la dimension du réseau W [nombre de couches , le nombre de neurones dans la couche, le nombre de neurones dans la couche]. Pas tout à fait l'encodage optimal, mais étant donné le souffle chaud du GPU quelque part très proche dans le texte, il est compréhensible.
Une courte procédure CalculateSize pour compter le nombre de neurones neuroncount et le nombre de leurs connexions dans le réseau de neurones dendritecount , je pense, expliquera mieux à l'auteur la nature de ces connexions:
void CalculateSize(array int Topology, int neuroncount, int dendritecount) { for (int i : Topology) // i neuroncount += i; for (int layer = 0, layer <Topology.Length - 1, layer++) // for (int i = 0, i < Topology[layer] + 1, i++) // for (int j = 0, j < Topology[layer + 1], j++) // dendritecount++; }
Mon lecteur, celui qui sait déjà tout cela, l'auteur est venu à cette opinion dans le premier article, ne se demandera certainement pas: pourquoi dans la troisième boucle imbriquée Topologie [couche1 + 1] au lieu de Topologie [couche1], qui donne plus au neurone que dans la topologie du réseau . Je ne répondrai pas. Il est également utile pour le lecteur de demander des devoirs.
Nous sommes presque à deux pas de la construction d'un réseau de neurones fonctionnel. Il reste à ajouter la fonction de sommation des signaux à l'entrée du neurone et son activation. Il existe de nombreuses fonctions d'activation, mais les plus proches de la nature du neurone sont Sigmoid et Tangensoid (il est probablement préférable de l'appeler ainsi, bien que ce nom ne soit pas utilisé dans la littérature, le maximum est tangent, mais c'est le nom du graphique, bien que qu'est-ce qu'un graphique s'il ne reflète pas la fonction?)
Nous avons donc ici les fonctions d'activation des neurones (elles sont présentes dans l'image, dans sa partie inférieure)
float Sigmoid(float x) { if (x < -10.0f) return 0.0f; else if (x > 10.0f) return 1.0f; return (float)(1.0f / (1.0f + expf(-x))); }
Sigmoid renvoie des valeurs de 0 à 1.
float Tanh(float x) { if (x < -10.0f) return -1.0f; else if (x > 10.0f) return 1.0f; return (float)(tanhf(x)); }
La tangente renvoie des valeurs de -1 à 1.
L'idée principale d'un signal passant à travers un réseau de neurones est une onde: un signal est envoyé aux neurones d'entrée -> via des connexions neuronales, le signal va à la deuxième couche -> les neurones de la deuxième couche résument les signaux qui les ont atteints modifiés par des poids interneuronaux -> est ajouté à travers un poids de polarisation supplémentaire -> nous utilisons la fonction d'activation-> et wu-al nous allons à la couche suivante (lisez le premier cycle de l'exemple par couches), c'est-à-dire en répétant la chaîne depuis le tout début, seuls les neurones de la couche suivante deviendront des neurones d'entrée. Pour simplifier, vous n'avez même pas besoin de stocker les valeurs des neurones de l'ensemble du réseau, il vous suffit de stocker uniquement les poids NN et les valeurs des neurones de la couche active.
Encore une fois, nous envoyons un signal à l'entrée NN, l'onde a traversé les couches et sur la couche de sortie, nous supprimons la valeur obtenue.
Ici, du goût du lecteur, il est possible de résoudre la récursivité par programmation ou simplement un triple cycle comme celui de l'auteur, pour accélérer les calculs, vous n'avez pas besoin de clôturer des objets sous forme de neurones et de leurs connexions et autres POO. Encore une fois, cela est dû au sentiment de calculs GPU proches, et sur les GPU, en raison de leur nature de parallélisme de masse, la POO s'arrête un peu, cela est relatif à c # et C ++.
De plus, le lecteur est invité à suivre indépendamment la voie de la construction d'un réseau neuronal en code, avec son lecteur qui le veut volontairement, dont l'absence est assez claire et familière à l'auteur, comme pour les exemples de construction de NN à partir de zéro, il y a beaucoup d'exemples dans le réseau, donc il sera difficile de s'égarer, c'est comme ça aussi simple qu'un réseau de neurones à distribution directe dans l'image ci-dessus.
Mais où s'exclamera le lecteur, qui n'est pas encore sorti du passage précédent, et aura raison, dans l'enfance, l'auteur a déterminé la valeur du livre par des illustrations. Vous voilà:
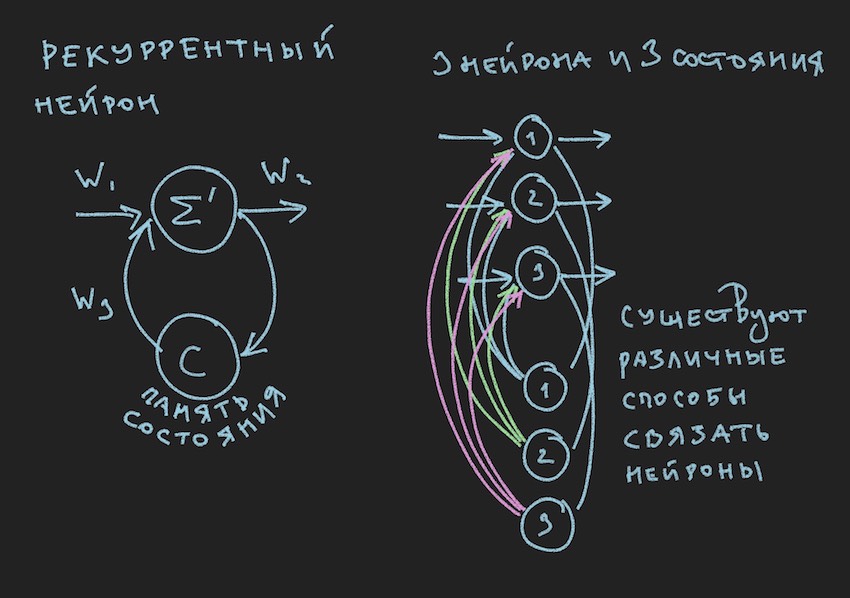
Dans l'image, nous voyons un neurone récurrent et un NN construit à partir de ces neurones est appelé récurrent ou RNN. Le réseau neuronal spécifié a une mémoire à court terme et a été sélectionné par l'auteur pour le bot comme le plus prometteur en termes d'adaptation au processus de jeu. Bien sûr, l'auteur a construit un réseau de neurones à distribution directe, mais dans le processus de recherche d'une solution «efficace», il est passé au RNN.
Un neurone récurrent a un état supplémentaire C, qui se forme après le premier passage d'un signal à travers un neurone, Tick + 0 sur la chronologie. En termes simples, il s'agit d'une copie du signal de sortie d'un neurone. Dans la deuxième étape, lisez Tick + 1 (puisque le réseau fonctionne à la fréquence du bot de jeu et du serveur), la valeur C revient à l'entrée de la couche neuronale à travers des poids supplémentaires et participe ainsi à la formation du signal, mais déjà à Tick + 1 fois.
Remarque: dans les travaux des groupes de recherche concernant la gestion des bots de jeu NN , il y a une tendance à utiliser deux rythmes pour un réseau neuronal, un rythme est la fréquence du jeu Tick, le deuxième rythme, par exemple, est deux fois plus lent que le premier. Différentes parties du NN fonctionnent à différentes fréquences, ce qui donne une vision différente de la situation de jeu à l'intérieur du NN, augmentant ainsi sa flexibilité.
Pour construire RNN dans le code bot, nous introduisons un tableau supplémentaire dans la topologie, où chaque élément correspond à la couche et au nombre d'états neuronaux qu'elle contient:
int array TopologyNN= { numberofSensors, 16, 8, 4}
int array TopologyRNN= { 0, 16, 0, 0 }
Il ressort de la topologie ci-dessus que la deuxième couche est récurrente, car elle contient des états neuronaux. Nous introduisons également des poids supplémentaires sous la forme d'un flotteur du tableau WRR, de la même dimension que le tableau W.
Le nombre de connexions dans notre réseau de neurones changera un peu:
for (int layer = 0, layer < TopologyNN.Length - 1, layer++) for (int i = 0, i < TopologyNN[layer] + 1, i++) for (int j = 0, j < TopologyNN[layer + 1] , j++) dendritecount++; for (int layer = 0, layer < TopologyRNN.Length - 1, layer++) for (int i = 0, i< TopologyRNN[layer] + 1 , i++) for (int j = 0, j< TopologyRNN[layer], j++) dendritecount++;
L'auteur joindra le code général d'un réseau neuronal récurrent à la fin de cet article, mais l'essentiel à comprendre est le principe: le passage d'une onde à travers des couches dans le cas d'un NN récurrent ne change rien fondamentalement, un seul terme supplémentaire est ajouté à la fonction d'activation des neurones. C'est le terme de l'état des neurones sur le Tick précédent multiplié par le poids de la connexion neuronale.
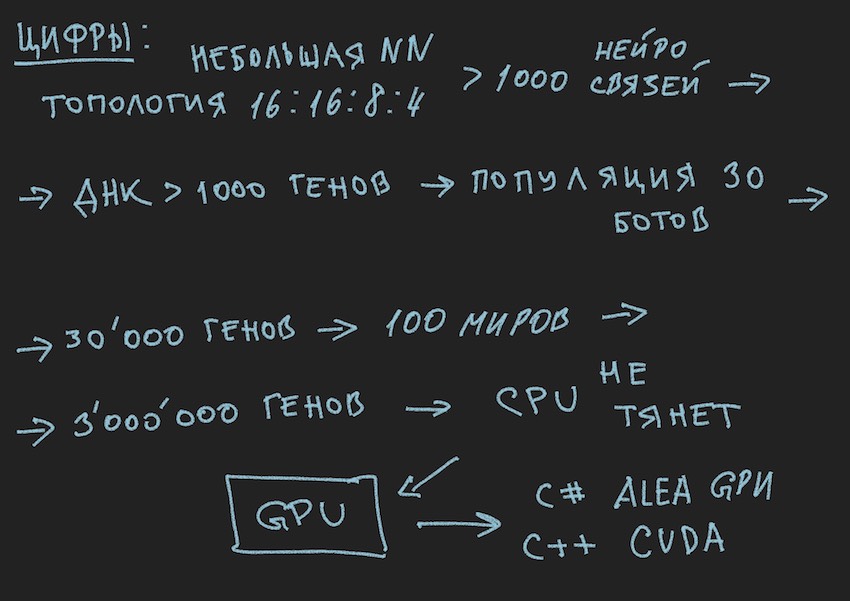
Nous supposons que la théorie et la pratique des réseaux de neurones ont été rafraîchies, mais l'auteur est clairement conscient qu'il n'a pas rapproché le lecteur de la façon d'enseigner cette structure simple des réseaux de neurones pour prendre des décisions dans le gameplay. Nous n'avons pas de bibliothèques avec des exemples pour enseigner NN. Dans les groupes Internet de développeurs de bots, il y avait un avis: donnez-nous un fichier journal sous forme de coordonnées de bots et d'autres informations de jeu pour former une bibliothèque d'exemples. Mais l'auteur, malheureusement, n'a pas pu comprendre comment utiliser ce fichier journal pour la formation NN. Je serai heureux d'en discuter dans les commentaires de l'article. Par conséquent, la seule méthode dont dispose l'auteur pour comprendre la méthode d'entraînement, ou plutôt pour trouver des neurobalances "efficaces" (neuroconnexions), était l'algorithme génétique.
Préparer une image sur les principes de l'algorithme génétique:
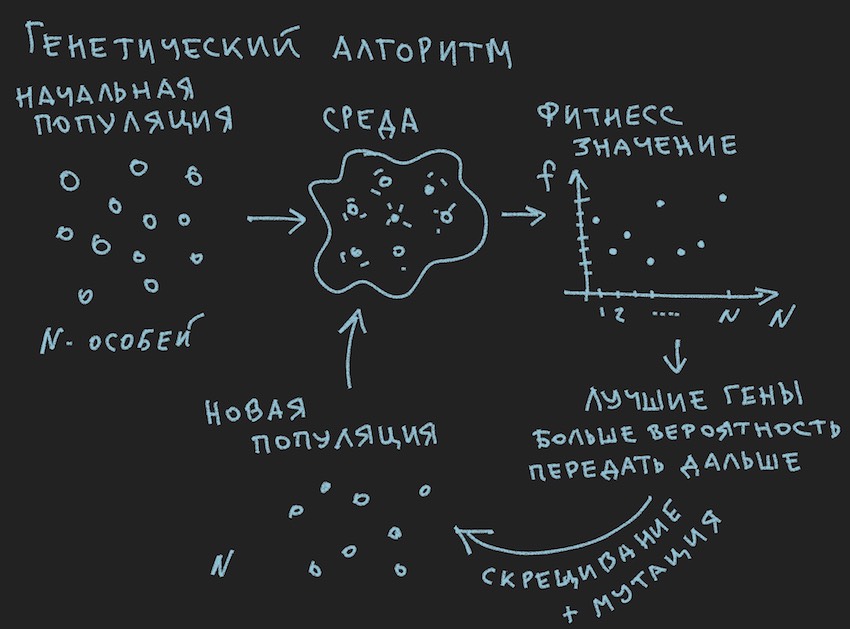
Donc, l' algorithme génétique .
L'auteur tentera de ne pas se plonger dans la théorie de ce processus , mais ne rappellera que le minimum nécessaire pour poursuivre une lecture complète de l'article.
Dans l'algorithme génétique, le principal fluide de travail est le gène (l'ADN est le nom de la molécule). Le génome dans notre cas est un ensemble séquentiel de gènes ou un tableau unidimensionnel de flotteur long ...
Au stade initial du travail avec un réseau neuronal nouvellement construit, il est nécessaire de l'initialiser. L'initialisation fait référence à l'attribution de valeurs aléatoires de -1 à 1 aux équilibres neuronaux. L'auteur a rencontré mentionne que la plage de valeurs de -1 à 1 est trop extrême et que les réseaux formés ont des poids dans une plage plus petite, par exemple de -0,5 à 0,5 et qu'une plage de valeurs initiale doit être acceptée comme excellente de -1 à 1. Mais nous allons suivre la méthode classique de collecte de toutes les difficultés dans une seule porte et prendre le segment le plus large possible de variables aléatoires initiales comme base pour initialiser le réseau neuronal.
Maintenant, une bijection va se produire. Nous supposerons que la longueur (taille) du génome du bot sera égale à la longueur totale des réseaux du réseau neuronal TopologyNN.Length + TopologyRNN.Length non pour rien que l'auteur a passé le temps du lecteur sur la procédure de comptage des connexions neuronales.
Remarque: Comme le lecteur l'a déjà noté par lui-même, nous transférons uniquement les poids du réseau neuronal au génotype, la structure de connexion, les fonctions d'activation et les états des neurones ne sont pas transmis. Pour un algorithme génétique, seules les connexions neuronales sont suffisantes, ce qui suggère qu'elles sont porteuses d'informations. Il y a des développements où l'algorithme génétique modifie également la structure des connexions dans le réseau neuronal et il est assez simple à mettre en œuvre. Ici, l'auteur laisse place à la créativité du lecteur, bien qu'il y réfléchisse avec intérêt: il faut comprendre l'utilisation de deux génomes indépendants et de deux fonctions de fitness (simplifié deux algorithmes génétiques indépendants) ou vous pouvez tous utiliser le même gène et algorithme.
Et puisque nous avons initialisé NN avec des variables aléatoires, nous avons ainsi initialisé le génome. Le processus inverse est également possible: initialisation du génotype par des variables aléatoires et sa copie ultérieure en poids neuronaux. La deuxième option est courante. Puisque l'algorithme génétique dans le programme existe souvent en dehors de l'essence elle-même et n'y est associé que par les données du génome et la valeur de la fonction de fitness ... Arrêtez, arrêtez, dira le lecteur, l'image montre clairement la population et pas un mot sur le génome individuel.
Ok, ajoutez quelques images au four de l'esprit du lecteur:
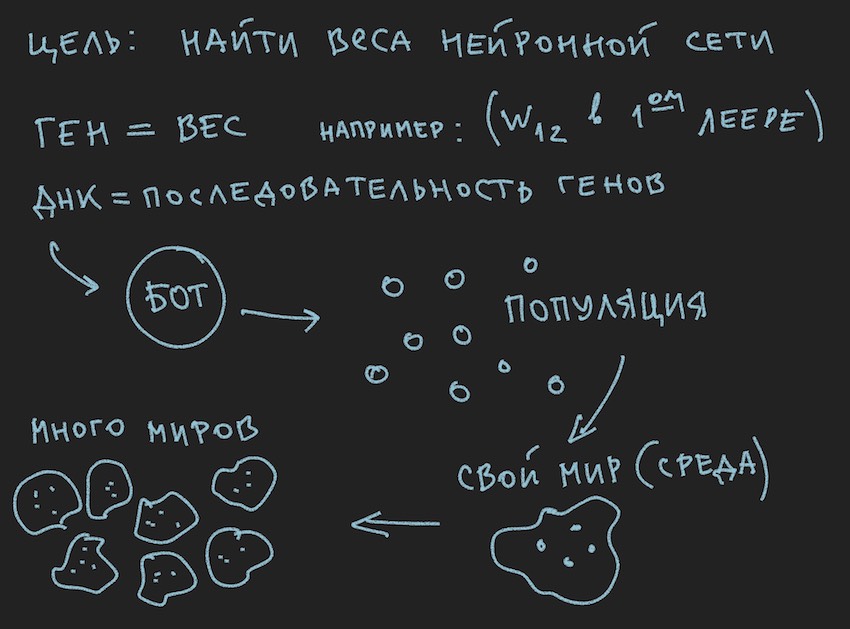
Puisque l'auteur a peint les images avant d'écrire le texte de l'article, elles soutiennent le texte, mais ne suivent pas la lettre à la lettre de l'histoire actuelle.
D'après les informations recueillies, il s'ensuit que le principal organe de travail de l'algorithme génétique est une population de génomes . C'est un peu contraire à ce que l'auteur a dit plus tôt, mais comment faire dans le monde réel sans petites contradictions. Hier, le soleil tournait autour de la terre et aujourd'hui, l'auteur parle du réseau neuronal à l'intérieur du bot logiciel. Pas étonnant qu'il se souvienne du four de la raison.
Je fais confiance au lecteur lui-même pour régler la question des contradictions du monde. Le monde des robots est complètement autosuffisant pour l'article.
Mais ce que l'auteur a déjà réussi à faire, dans cette partie de l'article, c'est de former une population de bots.
Regardons cela du côté logiciel:
Il existe un Bot (il peut s'agir d'un objet en POO, d'une structure, bien qu'il s'agisse probablement aussi d'un objet ou simplement d'un tableau de données). À l'intérieur, le Bot contient des informations sur ses coordonnées, sa vitesse, sa masse et d'autres informations utiles dans le processus de jeu, mais l'essentiel pour nous maintenant est qu'il contient un lien vers son génotype ou son génotype lui-même, en fonction de la mise en œuvre. Ensuite, vous pouvez procéder de différentes manières, vous limiter à des tableaux de poids de réseau neuronal ou introduire un tableau supplémentaire de génotypes, car il sera commode pour le lecteur d'imaginer cela dans son imagination. Dans les premières étapes, l'auteur du programme a attribué des tableaux de neurobalances et de génotypes. Puis il a refusé de dupliquer les informations et s'est limité aux poids du réseau neuronal.
En suivant la logique de l'histoire, vous devez dire que la population de bots est un tableau des bots ci-dessus. Quelle boucle de jeu ... Arrêtez-vous encore, quel cycle de jeu? les développeurs ont poliment fourni une place pour un seul bot à bord d'un programme de simulation du monde du jeu sur un serveur ou un maximum de quatre bots dans un simulateur local. Et si vous vous souvenez de la topologie du réseau neuronal choisi par l'auteur:
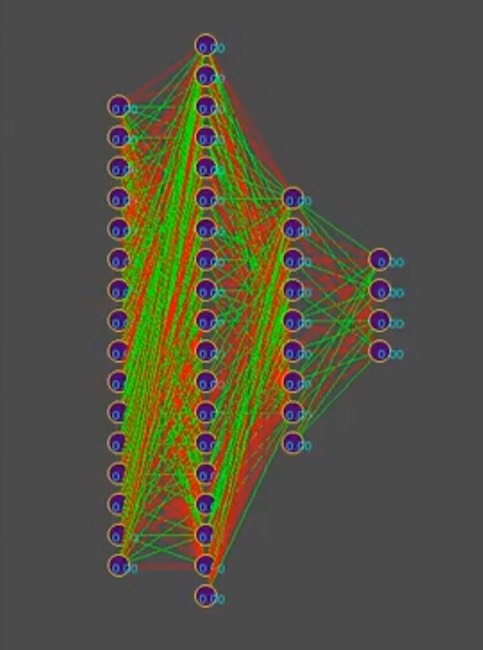
Et pour simplifier l'histoire, supposons que le génotype contient environ 1000 connexions neuronales, soit dit en passant, dans le simulateur, les génotypes ressemblent à ceci (le rouge est une valeur de gène négative, le vert est une valeur positive, chaque lignée est un génome distinct):

Remarque sur la photo: au fil du temps, le motif change dans le sens de la dominance de l'une des solutions, les rayures verticales sont des gènes de génotype courants.
Ainsi, nous avons 1000 gènes dans le génotype et un maximum de quatre robots dans le programme de simulation du monde du jeu des organisateurs de la compétition. Combien de fois avez-vous besoin d'exécuter une simulation d'une bataille de bots pour que, par la force brute, même la plus intelligente, se rapproche à la recherche de "efficace"
génotype, lisez la combinaison "efficace" de connexions neuronales, à condition que chaque connexion neuronale varie de -1 à 1 par étapes, et quelle étape? l'initialisation était flottante aléatoire, elle est de 15 décimales. L'étape n'est pas encore claire pour nous. Sur le nombre de variantes de combinaisons de poids neuronaux, l'auteur suppose qu'il s'agit d'un nombre infini, lors du choix d'une certaine taille de pas, probablement un nombre fini, mais dans tous les cas, ces nombres sont bien plus de 4 places dans le simulateur, même en considérant le lancement séquentiel à partir de la file d'attente des robots plus le lancement parallèle simultané des simulateurs officiels, jusqu'à 10 sur un ordinateur (pour les amateurs de programmation vintage: ordinateurs).
J'espère que les photos aideront le lecteur.
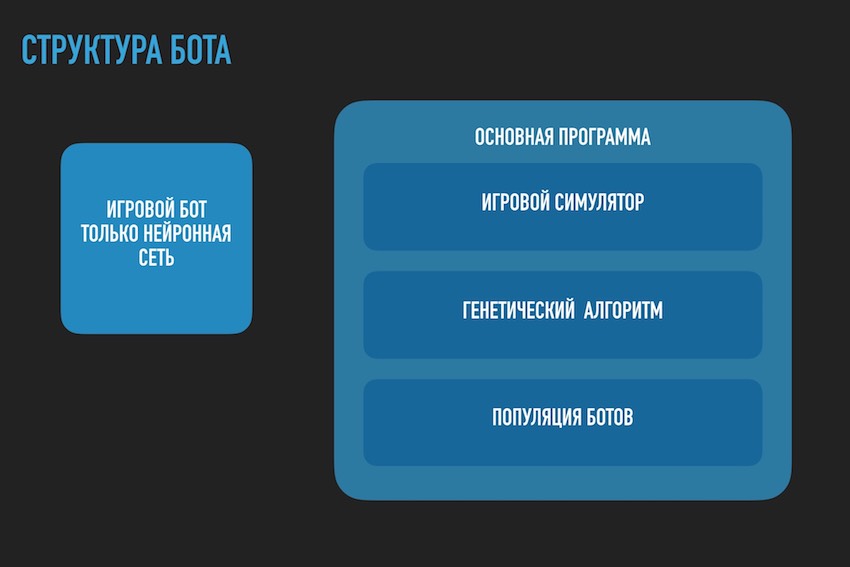
Ici, vous devez faire une pause et parler de l'architecture de la solution logicielle. Étant donné que la solution sous la forme d'un bot logiciel distinct téléchargé sur le site du concours n'était plus appropriée. Il fallait séparer le bot jouant selon les règles de la compétition dans le cadre de l'écosystème d'organisateurs et du programme essayant de lui trouver la configuration du réseau neuronal. Le diagramme suivant est tiré de la présentation de la conférence, mais reflète généralement l'image réelle.
Il a rappelé une blague barbu:
Grande organisation.
Heure 18.00, tous les employés travaillent comme un. Soudain, l'un des employés éteint l'ordinateur, s'habille et s'en va.
Tout le monde le suit avec un regard surpris.
Le lendemain. À 18 heures, le même employé éteint l'ordinateur et part. Tout le monde continue de travailler et commence à chuchoter de mécontentement.
Le lendemain. A 18h00, le même employé éteint l'ordinateur ...
Un collègue s'approche de lui:
-Comme tu n'as pas honte, on travaille, la fin du trimestre, tant de reportages, on veut aussi rentrer à la maison à temps et tu es une telle personne ...
- Les gars, je suis généralement en vacances!
... à suivre.
Oui, j'ai presque oublié de joindre le code de procédure de calcul RNN, il est valide et écrit indépendamment, il y a donc peut-être des erreurs. Pour l'amplification, je vais l'apporter tel quel, c'est en c ++ tel qu'appliqué à CUDA (une librairie de calcul sur le GPU).
Remarque: les tableaux multidimensionnels ne s'entendent pas bien sur les GPU, il existe bien sûr des textures et des calculs matriciels, mais ils recommandent d'utiliser des tableaux unidimensionnels.
Un exemple un tableau [i, j] de dimension M par j se transforme en un tableau de la forme [i * M + j].
Code source de la procédure de calcul RNN __global__ void cudaRNN(Bot *bot, argumentsRNN *RNN, ConstantStruct *Const, int *Topology, int *TopologyRNN, int numElements, int gameTick) { int tid = blockIdx.x * blockDim.x + threadIdx.x; int threadN = gridDim.x * blockDim.x; int TopologySize = Const->TopologySize; for (int pos = tid; pos < numElements; pos += threadN) { const int ii = pos; const int iiA = pos*Const->ArrayDim; int ArrayDim = Const->ArrayDim; const int iiAT = ii*TopologySize*ArrayDim; if (bot[pos].TTF != 0 && bot[pos].Mass>0) { RNN->outputs[iiA + Topology[0]] = 1.f; //bias int neuroncount7 = Topology[0]; neuroncount7++; for (int layer1 = 0; layer1 < TopologySize - 1; layer1++) { for (int j4 = 0; j4 < Topology[layer1 + 1]; j4++) { for (int i5 = 0; i5 < Topology[layer1] + 1; i5++) { RNN->sums[iiA + j4] = RNN->sums[iiA + j4] + RNN->outputs[iiA + i5] * RNN->NNweights[((ii*TopologySize + layer1)*ArrayDim + i5)*ArrayDim + j4]; } } if (TopologyRNN[layer1] > 0) { for (int j14 = 0; j14 < Topology[layer1]; j14++) { for (int i15 = 0; i15 < Topology[layer1]; i15++) { RNN->sumsContext[iiA + j14] = RNN->sumsContext[iiA + j14] + RNN->neuronContext[iiAT + ArrayDim * layer1 + i15] * RNN->MNweights[((ii*TopologySize + layer1)*ArrayDim + i15)*ArrayDim + j14]; } RNN->sumsContext[iiA + j14] = RNN->sumsContext[iiA + j14] + 1.0f* RNN->MNweights[((ii*TopologySize + layer1)*ArrayDim + Topology[layer1])*ArrayDim + j14]; //bias=1 } for (int t = 0; t < Topology[layer1 + 1]; t++) { RNN->outputs[iiA + t] = Tanh(RNN->sums[iiA + t] + RNN->sumsContext[iiA + t]); RNN->neuronContext[iiAT + ArrayDim * layer1 + t] = RNN->outputs[iiA + t]; } //SoftMax /* double sum = 0.0; for (int k = 0; k <ArrayDim; ++k) sum += exp(RNN->outputs[iiA + k]); for (int k = 0; k < ArrayDim; ++k) RNN->outputs[iiA + k] = exp(RNN->outputs[iiA + k]) / sum; */ } else { for (int i1 = 0; i1 < Topology[layer1 + 1]; i1++) { RNN->outputs[iiA + i1] = Sigmoid(RNN->sums[iiA + i1]); //sigma } } if (layer1 + 1 != TopologySize - 1) { RNN->outputs[iiA + Topology[layer1 + 1]] = 1.f; } for (int i2 = 0; i2 < ArrayDim; i2++) { RNN->sums[iiA + i2] = 0.f; RNN->sumsContext[iiA + i2] = 0.f; } } } } }