Imaginez que vous ayez un paragraphe de texte. Est-il possible de comprendre quelle émotion ce texte véhicule: joie, tristesse, colère? Tu peux. Nous simplifions notre tâche et classerons l'émotion comme positive ou négative, sans précision. Il existe de nombreuses façons de résoudre ce problème, et l'un d'eux est
les réseaux de neurones convolutionnels (réseaux de neurones convolutionnels). CNN a été développé à l'origine pour le traitement d'images, mais ils ont réussi à gérer des tâches dans le domaine du traitement automatique de texte. Je vais vous présenter une analyse binaire de la tonalité des textes en russe à l'aide d'un réseau neuronal convolutif pour lequel des représentations vectorielles de mots ont été formées sur la base d'un modèle
Word2Vec formé.
L'article est de nature générale, j'ai insisté sur le volet pratique. Et je veux vous avertir tout de suite que les décisions prises à chaque étape peuvent ne pas être optimales. Avant de lire, je vous recommande de vous familiariser avec l'
article introductif sur l'utilisation de CNN dans les tâches de traitement du langage naturel, ainsi que de lire du
matériel sur les méthodes de représentation vectorielle des mots.
L'architecture
L'architecture CNN considérée est basée sur les approches [1] et [2]. L'approche [1], qui utilise l'ensemble des réseaux convolutionnels et récurrents, lors du plus grand concours annuel de linguistique informatique SemEval-2017 a pris la première place [3] dans cinq nominations dans la tâche d'analyse de la tonalité
Tâche 4 .
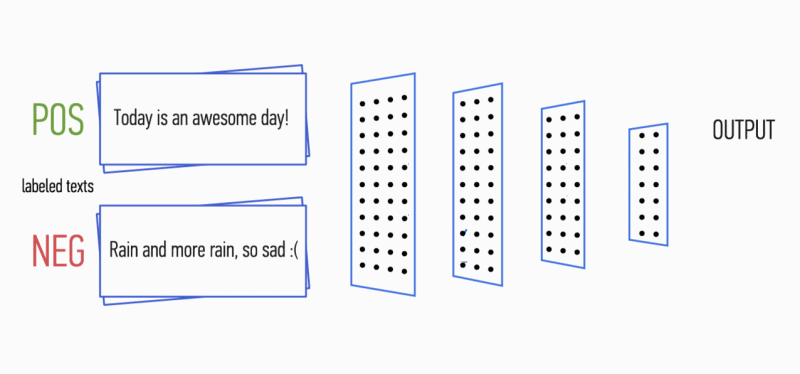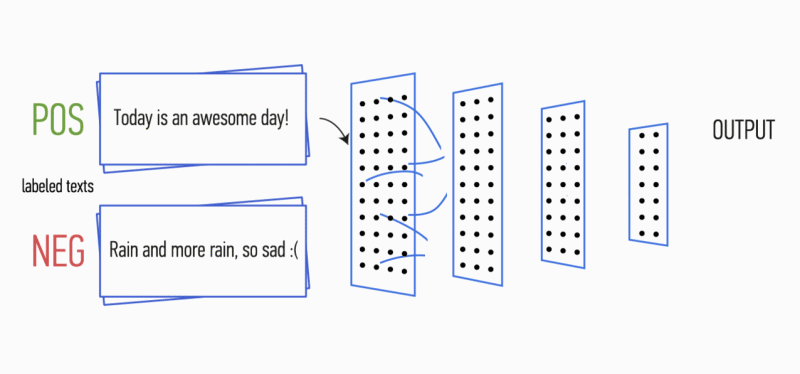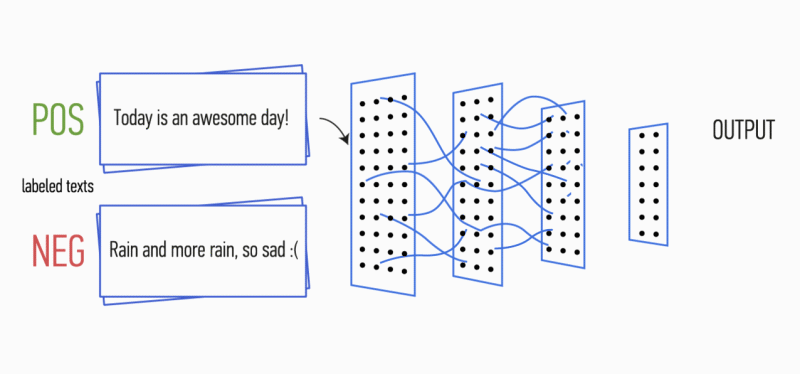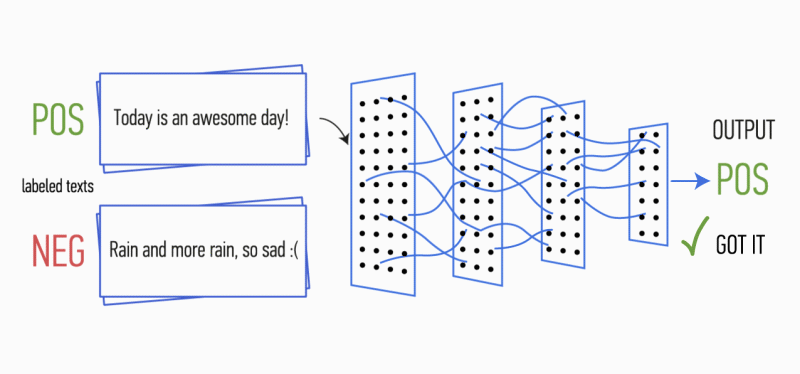
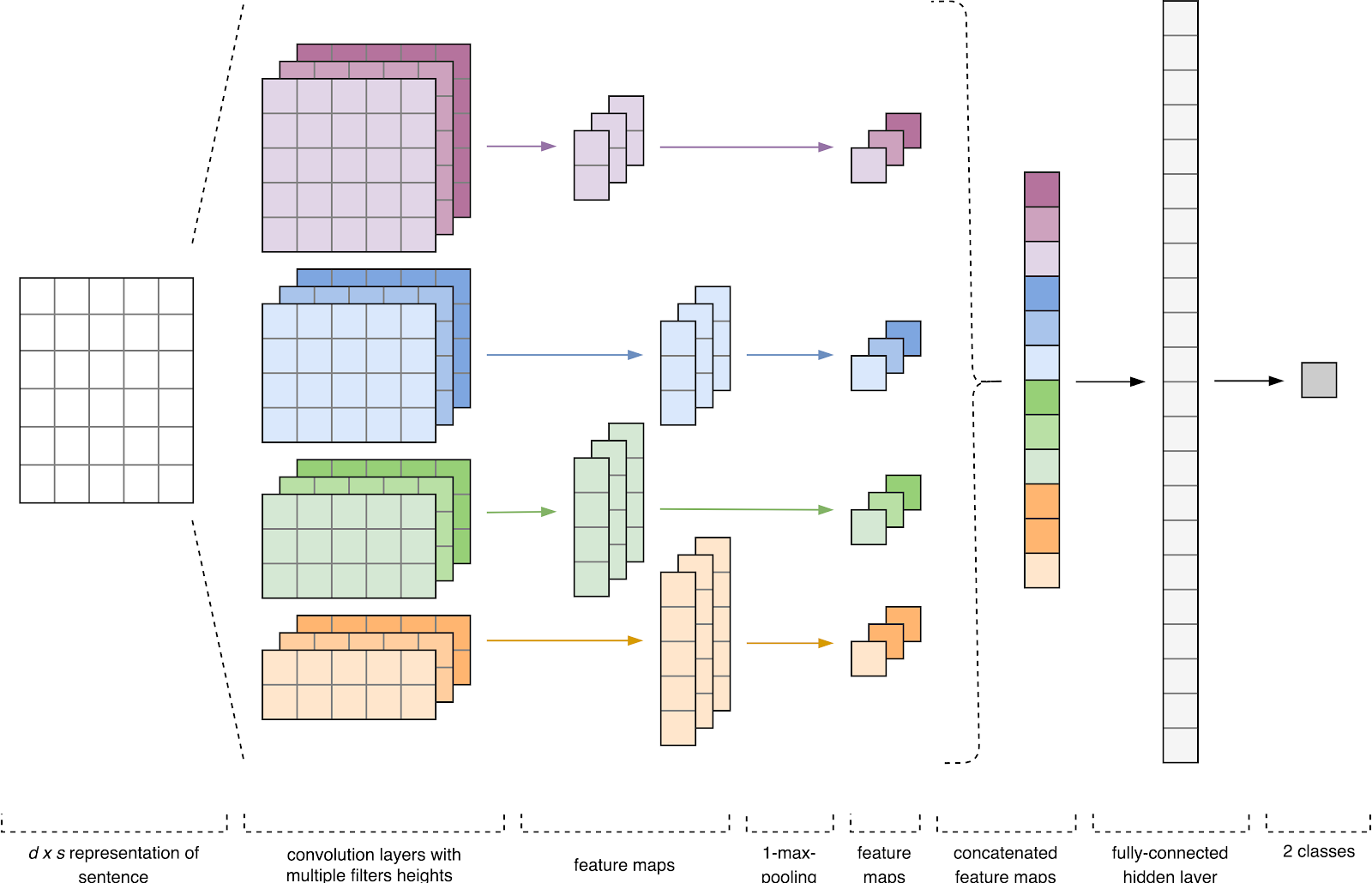 Figure 1. Architecture CNN [2].
Figure 1. Architecture CNN [2].L'entrée CNN (Fig. 1) est une matrice à hauteur fixe
n , où chaque ligne est un mappage vectoriel d'un jeton dans un espace caractéristique de dimension
k . Des outils de sémantique distributive tels que Word2Vec, Glove, FastText, etc. sont souvent utilisés pour former un espace de fonctionnalité.
Au premier stade, la matrice d'entrée est traitée par des couches de convolution. En règle générale, les filtres ont une largeur fixe égale à la dimension de l'espace attributaire et un seul paramètre est configuré pour les tailles de filtre - hauteur
h . Il s'avère que
h est la hauteur des lignes adjacentes considérées ensemble par le filtre. En conséquence, la dimension de la matrice de caractéristiques de sortie pour chaque filtre varie en fonction de la hauteur de ce filtre
h et de la hauteur de la matrice d'origine
n .
Ensuite, la carte des caractéristiques obtenue à la sortie de chaque filtre est traitée par une couche de sous-échantillonnage avec une fonction de compactage spécifique (regroupement 1-max dans l'image), c'est-à-dire réduit la dimension de la carte d'entités générée. Ainsi, les informations les plus importantes sont extraites pour chaque convolution, quelle que soit sa position dans le texte. En d'autres termes, pour l'affichage vectoriel utilisé, la combinaison des couches de convolution et des couches de sous-échantillonnage permet d'extraire les
n- grammes les plus significatifs du texte.
Après cela, les cartes d'entités calculées à la sortie de chaque couche de sous-échantillonnage sont combinées en un vecteur d'entités commun. Il est envoyé à l'entrée d'une couche cachée et entièrement connectée, puis envoyé à la couche de sortie du réseau neuronal, où les étiquettes de classe finales sont calculées.
Données d'entraînement
Pour la formation, j'ai choisi le
corpus de courts textes de Yulia Rubtsova , formé sur la base de messages en russe de Twitter [4]. Il contient 114 991 tweets positifs, 111 923 tweets négatifs, ainsi qu'une base de tweets non alloués avec un volume de 17 639 674 messages.
import pandas as pd import numpy as np
Avant la formation, les textes ont passé le traitement préliminaire:
- moulé en minuscules;
- remplacement de "e" par "e";
- Remplacement des liens vers le jeton «URL»;
- remplacement de la mention de l'utilisateur par le jeton UTILISATEUR;
- supprimer les signes de ponctuation.
import re def preprocess_text(text): text = text.lower().replace("", "") text = re.sub('((www\.[^\s]+)|(https?://[^\s]+))', 'URL', text) text = re.sub('@[^\s]+', 'USER', text) text = re.sub('[^a-zA-Z--1-9]+', ' ', text) text = re.sub(' +', ' ', text) return text.strip() data = [preprocess_text(t) for t in raw_data]
Ensuite, j'ai divisé l'ensemble de données en un échantillon de formation et de test dans un rapport 4: 1.
from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(data, labels, test_size=0.2, random_state=1)
Affichage vectoriel des mots
Les données d'entrée du réseau neuronal convolutif sont une matrice de hauteur fixe
n , où chaque ligne est un mappage vectoriel d'un mot dans un espace caractéristique de dimension
k . Pour former la couche d'intégration d'un réseau de neurones, j'ai utilisé l'utilitaire de sémantique distributive Word2Vec [5] conçu pour cartographier la signification sémantique des mots dans l'espace vectoriel. Word2Vec trouve des relations entre les mots en supposant que les mots sémantiquement liés se trouvent dans des contextes similaires. Vous pouvez en savoir plus sur Word2Vec dans l'
article d'origine , ainsi
qu'ici et
ici . Étant donné que les tweets sont caractérisés par la ponctuation des auteurs et des émoticônes, la définition des limites des phrases devient une tâche plutôt longue. Dans ce travail, j'ai supposé que chaque tweet ne contient qu'une seule phrase.
La base de tweets non alloués est stockée au format SQL et contient plus de 17,5 millions d'enregistrements. Pour plus de commodité, je l'ai converti en SQLite à l'aide de
ce script.
import sqlite3
Ensuite, en utilisant la bibliothèque Gensim, j'ai formé le modèle Word2Vec avec les paramètres suivants:
- taille = 200 - dimension de l'espace attributaire;
- window = 5 - le nombre de mots du contexte que l'algorithme analyse;
- min_count = 3 - le mot doit apparaître au moins trois fois pour que le modèle en tienne compte.
import logging import multiprocessing import gensim from gensim.models import Word2Vec logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
 Figure 2. Visualisation de groupes de mots similaires à l'aide de t-SNE.
Figure 2. Visualisation de groupes de mots similaires à l'aide de t-SNE.Pour une compréhension plus détaillée du fonctionnement de Word2Vec sur la Fig.
La figure 2 montre la visualisation de plusieurs grappes de mots similaires du modèle entraîné, mappés dans un espace bidimensionnel à
l' aide de
l'algorithme de visualisation t-SNE .
Affichage vectoriel des textes
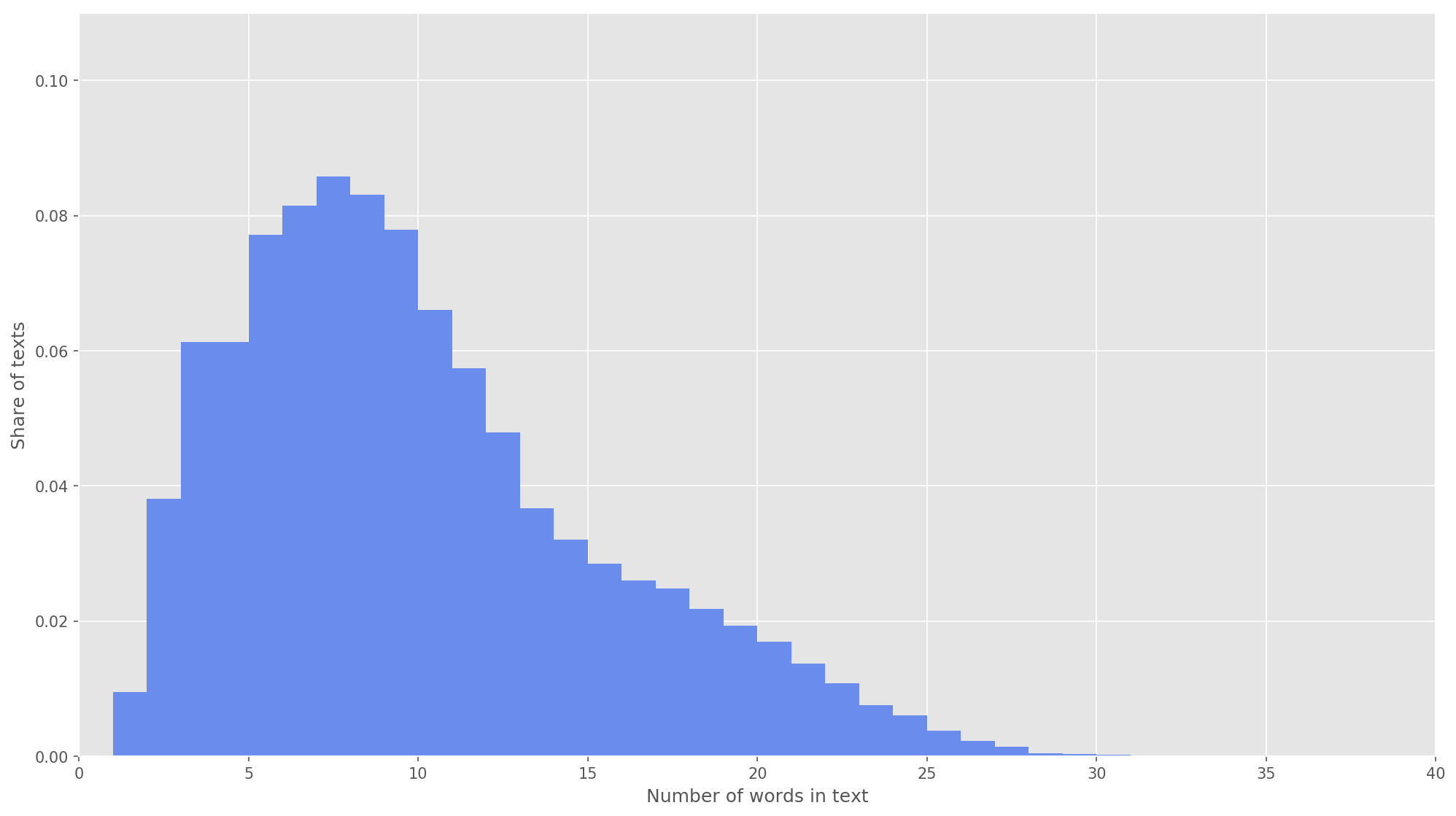 Fig 3. La distribution de la longueur des textes.
Fig 3. La distribution de la longueur des textes.À l'étape suivante, chaque texte a été mappé à un tableau d'identificateurs de jeton. J'ai choisi la dimension du vecteur texte
s = 26 , car à cette valeur 99,71% de tous les textes du corps formé sont entièrement couverts (Fig. 3). Si lors de l'analyse le nombre de mots dans le tweet dépassait la hauteur de la matrice, les mots restants étaient jetés et n'étaient pas pris en compte dans la classification. La dimension finale de la matrice de proposition était
s × d = 26 × 200 .
from keras.preprocessing.text import Tokenizer from keras.preprocessing.sequence import pad_sequences
Réseau de neurones convolutifs
Pour construire un réseau neuronal, j'ai utilisé la bibliothèque Keras, qui agit comme un module complémentaire de haut niveau pour TensorFlow, CNTK et Theano. Keras possède une excellente documentation, ainsi qu'un blog qui couvre de nombreuses tâches d'apprentissage automatique, telles que l'
initialisation de la couche d'intégration . Dans notre cas, la couche d'intégration a été initiée par les poids obtenus en apprenant Word2Vec. Pour minimiser les changements dans la couche d'intégration, je l'ai gelée au premier stade de la formation.
from keras.layers import Input from keras.layers.embeddings import Embedding tweet_input = Input(shape=(SENTENCE_LENGTH,), dtype='int32') tweet_encoder = Embedding(NUM, DIM, input_length=SENTENCE_LENGTH, weights=[embedding_matrix], trainable=False)(tweet_input)
Dans l'architecture développée, des filtres de hauteur
h = (2, 3, 4, 5) ont été utilisés, qui sont conçus pour le traitement parallèle de bigrammes, trigrammes, 4 grammes et 5 grammes, respectivement. Ajout de 10 couches convolutionnelles à chaque réseau de neurones pour chaque hauteur de filtre, la fonction d'activation est ReLU. Les recommandations pour trouver la hauteur optimale et le nombre de filtres se trouvent dans [2].
Après traitement par couches de convolution, les cartes d'attributs ont été introduites dans des couches de sous-échantillonnage, où l'opération de regroupement 1-max leur a été appliquée, extrayant ainsi les n-grammes les plus significatifs du texte. À l'étape suivante, ils ont fusionné en un vecteur caractéristique commun (couche de combinaison), qui a été introduit dans une couche cachée entièrement connectée avec 30 neurones. À la dernière étape, la carte des caractéristiques finale a été envoyée à la couche de sortie du réseau neuronal avec une fonction d'activation sigmoïdale.
Étant donné que les réseaux de neurones sont susceptibles de se recycler, après la couche d'intégration et avant la couche entièrement connectée cachée, j'ai ajouté une régularisation de décrochage avec la probabilité d'une éjection de vertex p = 0,2.
from keras import optimizers from keras.layers import Dense, concatenate, Activation, Dropout from keras.models import Model from keras.layers.convolutional import Conv1D from keras.layers.pooling import GlobalMaxPooling1D branches = []
J'ai configuré le modèle final avec la fonction d'optimisation d'Adam (Adaptive Moment Estimation) et l'entropie croisée binaire en fonction des erreurs. La qualité du classificateur a été évaluée en termes d'exactitude macro-moyenne, d'exhaustivité et de mesures f.
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=[precision, recall, f1]) model.summary()
Au premier stade de la formation, la couche d'intégration a été gelée, toutes les autres couches ont été formées pendant 10 époques:
- La taille du groupe d'exemples utilisé pour la formation est de 32.
- Taille de l'échantillon de validation: 25%.
from keras.callbacks import ModelCheckpoint checkpoint = ModelCheckpoint("models/cnn/cnn-frozen-embeddings-{epoch:02d}-{val_f1:.2f}.hdf5", monitor='val_f1', save_best_only=True, mode='max', period=1) history = model.fit(x_train_seq, y_train, batch_size=32, epochs=10, validation_split=0.25, callbacks = [checkpoint])
JournauxTrain on 134307 samples, validate on 44769 samples
Epoch 1/10
134307/134307 [==============================] - 221s 2ms/step - loss: 0.5703 - precision: 0.7006 - recall: 0.6854 - f1: 0.6839 - val_loss: 0.5014 - val_precision: 0.7538 - val_recall: 0.7493 - val_f1: 0.7452
Epoch 2/10
134307/134307 [==============================] - 218s 2ms/step - loss: 0.5157 - precision: 0.7422 - recall: 0.7258 - f1: 0.7263 - val_loss: 0.4911 - val_precision: 0.7413 - val_recall: 0.7924 - val_f1: 0.7602
Epoch 3/10
134307/134307 [==============================] - 213s 2ms/step - loss: 0.5023 - precision: 0.7502 - recall: 0.7337 - f1: 0.7346 - val_loss: 0.4825 - val_precision: 0.7750 - val_recall: 0.7411 - val_f1: 0.7512
Epoch 4/10
134307/134307 [==============================] - 215s 2ms/step - loss: 0.4956 - precision: 0.7545 - recall: 0.7412 - f1: 0.7407 - val_loss: 0.4747 - val_precision: 0.7696 - val_recall: 0.7590 - val_f1: 0.7584
Epoch 5/10
134307/134307 [==============================] - 229s 2ms/step - loss: 0.4891 - precision: 0.7587 - recall: 0.7492 - f1: 0.7473 - val_loss: 0.4781 - val_precision: 0.8014 - val_recall: 0.7004 - val_f1: 0.7409
Epoch 6/10
134307/134307 [==============================] - 217s 2ms/step - loss: 0.4830 - precision: 0.7620 - recall: 0.7566 - f1: 0.7525 - val_loss: 0.4749 - val_precision: 0.7877 - val_recall: 0.7411 - val_f1: 0.7576
Epoch 7/10
134307/134307 [==============================] - 219s 2ms/step - loss: 0.4802 - precision: 0.7632 - recall: 0.7568 - f1: 0.7532 - val_loss: 0.4730 - val_precision: 0.7969 - val_recall: 0.7241 - val_f1: 0.7522
Epoch 8/10
134307/134307 [==============================] - 215s 2ms/step - loss: 0.4769 - precision: 0.7644 - recall: 0.7605 - f1: 0.7558 - val_loss: 0.4680 - val_precision: 0.7829 - val_recall: 0.7542 - val_f1: 0.7619
Epoch 9/10
134307/134307 [==============================] - 227s 2ms/step - loss: 0.4741 - precision: 0.7657 - recall: 0.7663 - f1: 0.7598 - val_loss: 0.4672 - val_precision: 0.7695 - val_recall: 0.7784 - val_f1: 0.7682
Epoch 10/10
134307/134307 [==============================] - 221s 2ms/step - loss: 0.4727 - precision: 0.7670 - recall: 0.7647 - f1: 0.7590 - val_loss: 0.4673 - val_precision: 0.7833 - val_recall: 0.7561 - val_f1: 0.7636
Il a ensuite sélectionné le modèle avec les mesures F les plus élevées sur l'ensemble de données de validation, c'est-à-dire modèle obtenu à la huitième époque de l'éducation (F
1 = 0,77971). Le modèle a décongelé la couche d'intégration, après quoi il a lancé cinq autres périodes d'entraînement.
from keras import optimizers
JournauxTrain on 134307 samples, validate on 44769 samples
Epoch 1/5
134307/134307 [==============================] - 2042s 15ms/step - loss: 0.4495 - precision: 0.7806 - recall: 0.7797 - f1: 0.7743 - val_loss: 0.4560 - val_precision: 0.7858 - val_recall: 0.7671 - val_f1: 0.7705
Epoch 2/5
134307/134307 [==============================] - 2253s 17ms/step - loss: 0.4432 - precision: 0.7857 - recall: 0.7842 - f1: 0.7794 - val_loss: 0.4543 - val_precision: 0.7923 - val_recall: 0.7572 - val_f1: 0.7683
Epoch 3/5
134307/134307 [==============================] - 2018s 15ms/step - loss: 0.4372 - precision: 0.7899 - recall: 0.7879 - f1: 0.7832 - val_loss: 0.4519 - val_precision: 0.7805 - val_recall: 0.7838 - val_f1: 0.7767
Epoch 4/5
134307/134307 [==============================] - 1901s 14ms/step - loss: 0.4324 - precision: 0.7943 - recall: 0.7904 - f1: 0.7869 - val_loss: 0.4504 - val_precision: 0.7825 - val_recall: 0.7808 - val_f1: 0.7762
Epoch 5/5
134307/134307 [==============================] - 1924s 14ms/step - loss: 0.4256 - precision: 0.7986 - recall: 0.7947 - f1: 0.7913 - val_loss: 0.4497 - val_precision: 0.7989 - val_recall: 0.7549 - val_f1: 0.7703
L'indicateur
F 1 le plus élevé
= 76,80% dans l'échantillon de validation a été atteint dans la troisième ère de la formation. La qualité du modèle formé sur les données de test était
F 1 = 78,1% .
Tableau 1. Qualité de l'analyse des sentiments sur les données de test.
Résultat
En tant que solution de base, j'ai
formé un classificateur bayésien naïf avec un modèle de distribution multinomial, les résultats de la comparaison sont présentés dans le tableau. 2.
Tableau 2. Comparaison de la qualité de l'analyse de tonalité.
Comme vous pouvez le voir, la qualité de la classification CNN a dépassé MNB de plusieurs pour cent. Les valeurs métriques peuvent être encore augmentées si vous travaillez sur l'optimisation des hyperparamètres et de l'architecture réseau. Par exemple, vous pouvez modifier le nombre d'époques d'apprentissage, vérifier l'efficacité de l'utilisation de diverses représentations vectorielles des mots et de leurs combinaisons, sélectionner le nombre de filtres et leur hauteur, implémenter un prétraitement de texte plus efficace (correction de faute de frappe, normalisation, estampage), ajuster le nombre de couches et de neurones entièrement connectés cachés. .
Le code source
est disponible sur Github , les modèles CNN et Word2Vec formés peuvent être téléchargés
ici .
Les sources
- Cliche M. BB_twtr à SemEval-2017 Tâche 4: Analyse de sentiment Twitter avec CNN et LSTM // Actes du 11e atelier international sur l'évaluation sémantique (SemEval-2017). - 2017 .-- art.573-580.
- Zhang Y., Wallace B. Une analyse de sensibilité des réseaux neuronaux convolutionnels (et le guide du praticien) pour la classification des phrases // arXiv preprint arXiv: 1510.03820. - 2015.
- Rosenthal S., Farra N., Nakov P. SemEval-2017 tâche 4: Analyse de sentiment sur Twitter // Actes du 11e atelier international sur l'évaluation sémantique (SemEval-2017). - 2017 .-- art.502-518.
- Yu. V. Rubtsova. Construire un corps de textes pour définir le classificateur de tonalité // Produits et systèmes logiciels, 2015, n ° 1 (109), —C.72-78.
- Mikolov T. et al. Représentations distribuées des mots et des phrases et leur compositionnalité // Advances in Neural Information Processing Systems. - 2013 .-- S. 3111-3119.