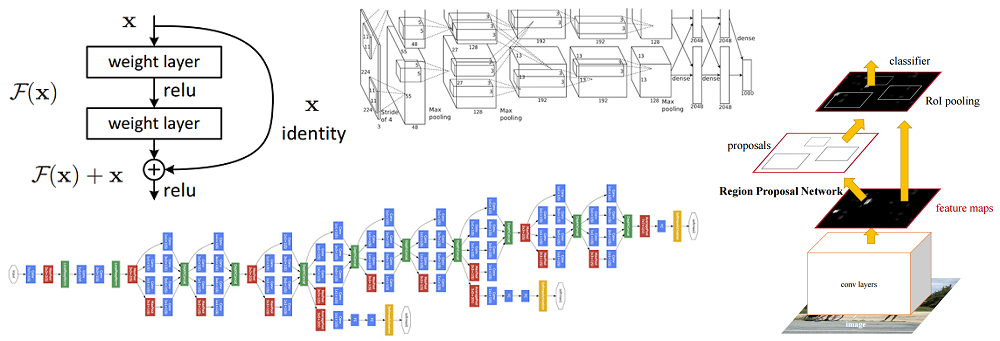
Dans un article précédent,
Overview of Neural Networks for Image Classification , nous nous sommes familiarisés avec les concepts de base des réseaux de neurones convolutifs, ainsi que les idées sous-jacentes. Dans cet article, nous allons examiner quelques architectures de réseaux de neurones profonds avec une grande puissance de traitement - comme AlexNet, ZFNet, VGG, GoogLeNet et ResNet - et résumer les principaux avantages de chacune de ces architectures. La structure de l'article est basée sur une entrée de blog
Concepts de base des réseaux de neurones convolutionnels, partie 3 .
Actuellement,
ImageNet Challenge est le principal incitatif sous-jacent au développement de systèmes de reconnaissance de machines et de classification d'images. La campagne est un concours pour travailler avec des données, dans lequel les participants reçoivent un grand ensemble de données (plus d'un million d'images). La tâche du concours est de développer un algorithme qui vous permet de classer les images requises en objets dans 1000 catégories - comme les chiens, les chats, les voitures et autres - avec un nombre minimum d'erreurs.
Selon les règles officielles du concours, les algorithmes doivent fournir une liste de cinq catégories d'objets au maximum par ordre décroissant de confiance pour chaque catégorie d'images. La qualité du marquage d'image est évaluée sur la base de l'étiquette qui correspond le mieux à la propriété de vérité terrain de l'image. L'idée est de permettre à l'algorithme d'identifier plusieurs objets dans l'image et de ne pas accumuler de points de pénalité dans le cas où l'un des objets détectés était effectivement présent dans l'image mais n'était pas inclus dans la propriété de vérité terrain.
Au cours de la première année du concours, les participants ont reçu des attributs d'image présélectionnés pour la formation du modèle. Il peut s'agir, par exemple, de signes de l'algorithme
SIFT traités à l'aide de la quantification vectorielle et adaptés à une utilisation dans la méthode du sac de mots ou à une présentation sous forme de pyramide spatiale. Cependant, en 2012, il y a eu une véritable percée dans ce domaine: un groupe de scientifiques de l'Université de Toronto a démontré qu'un réseau neuronal profond peut obtenir des résultats nettement meilleurs par rapport aux modèles d'apprentissage automatique traditionnels construits sur la base de vecteurs à partir de propriétés d'image précédemment sélectionnées. Dans les sections suivantes, la première architecture innovante proposée en 2012 sera considérée, ainsi que les architectures qui en sont les adeptes jusqu'en 2015.
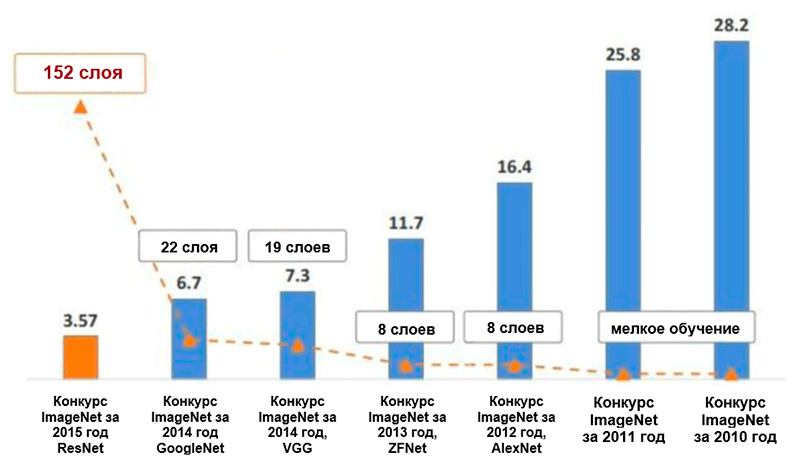 Diagramme des changements dans le nombre d'erreurs (en pourcentage) dans la classification des images ImageNet * pour les cinq principales catégories. Image tirée de la présentation de Kaiming He, Deep Residual Learning for Image Recognition
Diagramme des changements dans le nombre d'erreurs (en pourcentage) dans la classification des images ImageNet * pour les cinq principales catégories. Image tirée de la présentation de Kaiming He, Deep Residual Learning for Image RecognitionAlexnet
L' architecture
AlexNet a été proposée en 2012 par un groupe de scientifiques (A. Krizhevsky, I. Sutskever et J. Hinton) de l'Université de Toronto. Il s'agissait d'un travail innovant dans lequel les auteurs ont d'abord utilisé (à cette époque) des réseaux de neurones convolutionnels profonds avec une profondeur totale de huit couches (cinq couches convolutionnelles et trois couches entièrement connectées).
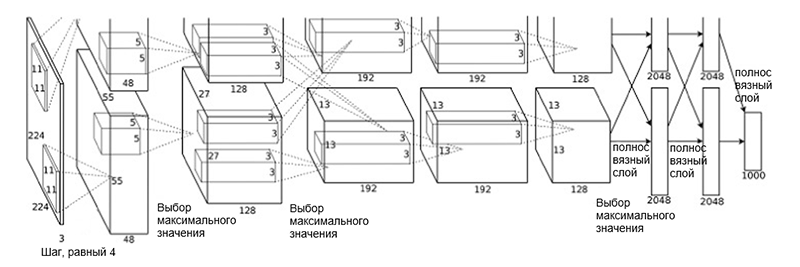 Architecture AlexNet
Architecture AlexNetL'architecture réseau se compose des couches suivantes:
- [Couche de convolution + sélection de la valeur maximale + normalisation] x 2
- [Couche de convolution] x 3
- [Choisir la valeur maximale]
- [Couche complète] x 3
Un tel schéma peut sembler un peu étrange, car le processus d'apprentissage a été divisé entre les deux GPU en raison de sa grande complexité de calcul. Cette séparation du travail entre les GPU nécessite une séparation manuelle du modèle en blocs verticaux qui interagissent les uns avec les autres.
L'architecture d'AlexNet a réduit le nombre d'erreurs pour les cinq principales catégories à 16,4% - près de la moitié par rapport aux développements avancés précédents! Dans le cadre de cette architecture a également été introduite une telle fonction d'activation comme unité de rectification linéaire (
ReLU ), qui est actuellement la norme de l'industrie. Voici un bref résumé des autres fonctionnalités clés de l'architecture AlexNet et de son processus d'apprentissage:
- Augmentation intensive des données
- Méthode d'exclusion
- Optimisation à l'aide du moment SGD (voir le guide d'optimisation «Présentation des algorithmes d'optimisation de descente de gradient»)
- Réglage manuel de la vitesse d'apprentissage (réduction de 10 de ce coefficient avec stabilisation de la précision)
- Le modèle final est une collection de sept réseaux de neurones convolutifs
- La formation a été menée sur deux processeurs graphiques NVIDIA * GeForce GTX * 580 avec un total de 3 Go de mémoire vidéo sur chacun d'eux.
Zfnet
L'architecture de réseau
ZFNet proposée par les chercheurs M. Zeiler et R. Fergus de l'Université de New York est presque identique à l'architecture AlexNet. Les seules différences importantes entre eux sont les suivantes:
- Taille et pas du filtre dans la première couche convolutive (dans AlexNet, la taille du filtre est 11 × 11 et le pas est 4; dans ZFNet - 7 × 7 et 2, respectivement)
- Le nombre de filtres dans des couches convolutives propres (3, 4, 5).
 Architecture ZFNet
Architecture ZFNetGrâce à l'architecture ZFNet, le nombre d'erreurs pour les cinq principales catégories est tombé à 11,4%. Le rôle principal est peut-être joué par le réglage précis des hyperparamètres (taille et nombre de filtres, taille des paquets, vitesse d'apprentissage, etc.). Cependant, il est également probable que les idées de l'architecture ZFNet soient devenues une contribution très importante au développement de réseaux de neurones convolutifs. Ziller et Fergus ont proposé un système de visualisation des noyaux, des poids et une vue cachée des images appelé DeconvNet. Grâce à elle, une meilleure compréhension et un développement ultérieur des réseaux de neurones convolutifs sont devenus possibles.
VGG Net
En 2014, K. Simonyan et E. Zisserman de l'Université d'Oxford ont proposé une architecture appelée
VGG . L'idée principale et distinctive de cette structure est de
garder les filtres aussi simples que possible . Par conséquent, toutes les opérations de convolution sont effectuées en utilisant un filtre de taille 3 et une étape de taille 1, et toutes les opérations de sous-échantillonnage sont effectuées en utilisant un filtre de taille 2 et une étape de taille 2. Cependant, ce n'est pas tout. Parallèlement à la simplicité des modules convolutifs, le réseau s'est considérablement développé en profondeur - il compte désormais 19 couches! L'idée la plus importante, d'abord proposée dans ce travail, est d'
imposer des couches convolutives sans couches de sous-échantillonnage . L'idée sous-jacente est qu'une telle superposition fournit toujours un champ récepteur suffisamment grand (par exemple, trois couches convolutionnelles superposées de taille 3 × 3 par pas de 1 ont un champ récepteur similaire à une couche convolutionnelle de 7 × 7), cependant, le nombre de paramètres est nettement inférieur à celui des réseaux avec de grands filtres (sert de régularisateur). De plus, il devient possible d'introduire des transformations non linéaires supplémentaires.
Essentiellement, les auteurs ont démontré que même avec des blocs de construction très simples, vous pouvez obtenir des résultats de qualité supérieure dans le cadre du concours ImageNet. Le nombre d'erreurs pour les cinq principales catégories a été réduit à 7,3%.
 Architecture VGG. Veuillez noter que le nombre de filtres est inversement proportionnel à la taille spatiale de l'image.
Architecture VGG. Veuillez noter que le nombre de filtres est inversement proportionnel à la taille spatiale de l'image.GoogleNet
Auparavant, tout le développement de l'architecture devait simplifier les filtres et augmenter la profondeur du réseau. En 2014, C. Szegedy, avec d'autres participants, a proposé une approche complètement différente et a créé l'architecture la plus complexe de l'époque, appelée GoogLeNet.
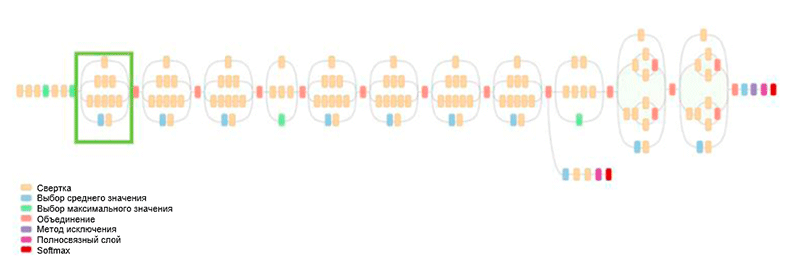 Architecture de GoogLeNet. Il utilise le module Inception, surligné en vert sur la figure; la construction du réseau est basée sur ces modules
Architecture de GoogLeNet. Il utilise le module Inception, surligné en vert sur la figure; la construction du réseau est basée sur ces modulesL'une des principales réalisations de ce travail est le soi-disant module Inception, qui est illustré dans la figure ci-dessous. Les réseaux d'autres architectures traitent les données d'entrée séquentiellement, couche par couche, tout en utilisant le module Inception,
les données d'entrée sont traitées en parallèle . Cela vous permet d'accélérer la sortie et de minimiser le
nombre total de paramètres .
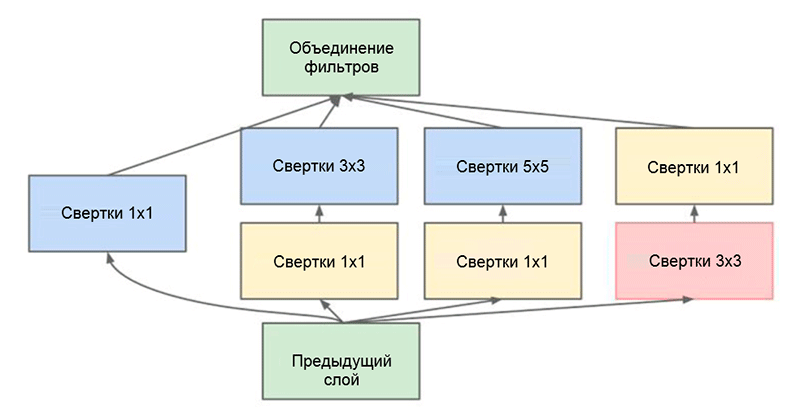 Module de création. Notez que le module utilise plusieurs branches parallèles, qui calculent différentes propriétés en fonction des mêmes données d'entrée, puis combinent les résultats
Module de création. Notez que le module utilise plusieurs branches parallèles, qui calculent différentes propriétés en fonction des mêmes données d'entrée, puis combinent les résultatsUne autre astuce intéressante utilisée dans le module Inception est d'utiliser des couches convolutives de taille 1 × 1. Cela peut sembler inutile jusqu'à ce que nous rappelions le fait que le filtre couvre toute la dimension de la profondeur. Ainsi, une convolution 1 × 1 est un moyen simple de réduire la dimension d'une carte de propriété. Ce type de couches convolutives a été présenté pour la première fois dans
Network par M. Lin et al., Une explication complète et compréhensible peut également être trouvée dans le billet de blog
Convolution [1 × 1] - utilité contraire à l'intuition de A. Prakash.
En fin de compte, cette architecture a réduit le nombre d'erreurs pour les cinq principales catégories d'un autre demi pour cent - à une valeur de 6,7 pour cent.
Resnet
En 2015, un groupe de chercheurs (Cuming Hee et autres) de Microsoft Research Asia est venu avec une idée qui est actuellement considérée par la plupart de la communauté comme l'une des étapes les plus importantes dans le développement du deep learning.
L'un des principaux problèmes des réseaux de neurones profonds est le problème d'un gradient en voie de disparition. En résumé, il s'agit d'un problème technique qui se pose lors de l'utilisation de la méthode de propagation de l'erreur en retour pour l'algorithme de calcul de gradient. Lorsque vous travaillez avec une propagation inverse des erreurs, une règle de chaîne est utilisée. De plus, si le gradient a une petite valeur à la fin du réseau, il peut prendre une valeur infiniment petite au moment où il atteint le début du réseau. Cela peut entraîner des problèmes de nature complètement différente, notamment l'impossibilité d'apprendre le réseau en principe (pour plus d'informations, voir l'entrée de blog de R. Kapur
Le problème d'un gradient de décoloration ).
Pour résoudre ce problème, Caiming Hee et son groupe ont proposé l'idée suivante - permettre au réseau d'étudier la cartographie résiduelle (un élément qui devrait être ajouté à l'entrée) au lieu de l'affichage lui-même. Techniquement, cela se fait en utilisant la connexion de dérivation illustrée sur la figure.
 Schéma de principe du bloc résiduel: les données d'entrée sont transmises via une connexion raccourcie contournant les couches de conversion et ajoutées au résultat. Veuillez noter qu'une connexion «identique» n'ajoute pas de paramètres supplémentaires au réseau, donc sa structure n'est pas compliquée
Schéma de principe du bloc résiduel: les données d'entrée sont transmises via une connexion raccourcie contournant les couches de conversion et ajoutées au résultat. Veuillez noter qu'une connexion «identique» n'ajoute pas de paramètres supplémentaires au réseau, donc sa structure n'est pas compliquéeCette idée est extrêmement simple, mais en même temps extrêmement efficace. Il résout le problème de la disparition du gradient, lui permettant de se déplacer sans aucun changement des couches supérieures vers les couches inférieures à travers des connexions "identiques". Grâce à cette idée, vous pouvez former des réseaux très profonds, extrêmement profonds.
Le réseau qui a remporté le Défi ImageNet en 2015 contenait 152 couches (les auteurs ont pu former le réseau contenant 1001 couches, mais il a produit approximativement le même résultat, alors ils ont cessé de travailler avec lui). De plus, cette idée a permis de réduire littéralement de moitié le nombre d'erreurs pour les cinq principales catégories - à une valeur de 3,6%. Selon une étude de
ce que j'ai appris en faisant concurrence à un réseau de neurones convolutifs dans le cadre du concours ImageNet par A. Karpathy, la performance humaine pour cette tâche est d'environ 5%. Cela signifie que l'architecture ResNet est capable de dépasser les résultats humains, au moins dans cette tâche de classification d'image.