
Depuis plusieurs mois, nous collectons des mémos sur l'intelligence artificielle, que nous partageons périodiquement avec des amis et des collègues. Récemment, toute une collection s'est développée et nous avons ajouté des descriptions et / ou des citations aux mémos pour les rendre plus intéressants à lire. Et au final, vous trouverez une sélection de complexité "O big" (Big-O). Profitez-en.
UPD De nombreuses images seront plus lisibles si vous les ouvrez dans des onglets séparés ou les enregistrez sur le disque.Réseaux de neurones
 Mémo du réseau neuronal
Mémo du réseau neuronalGraphes de réseaux de neurones
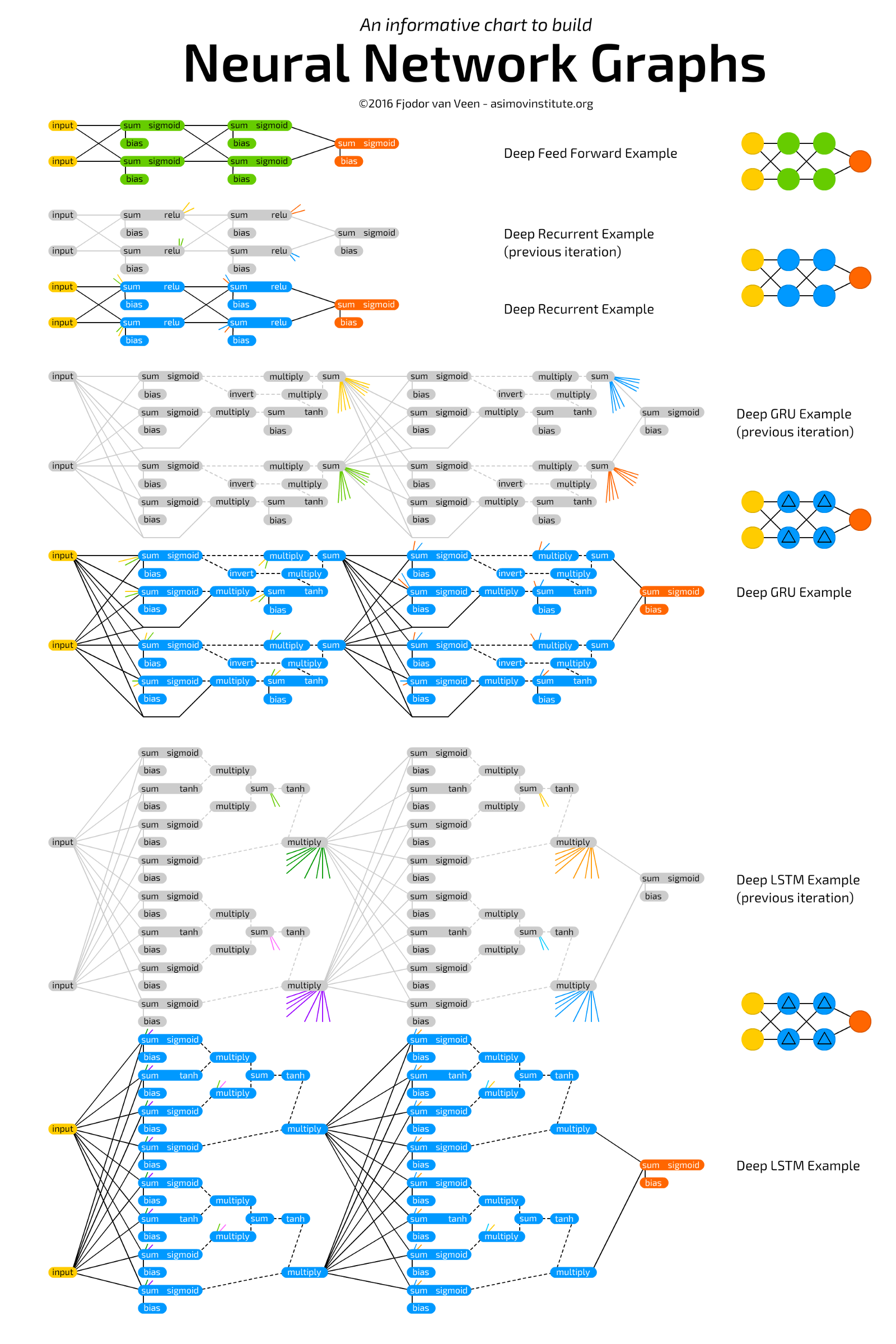 Mémo sur les graphiques des réseaux de neurones
Mémo sur les graphiques des réseaux de neurones Mémo du réseau neuronal
Mémo du réseau neuronalPrésentation de l'apprentissage automatique
 Guide d'apprentissage automatique
Guide d'apprentissage automatiqueAlgorithme Scikit-learn
Ce guide d'apprentissage automatique vous aidera à trouver le bon algorithme de classement, qui est la partie la plus difficile du travail. L'organigramme vous aidera à vérifier la documentation et à définir une direction générale pour chaque algorithme. Cela vous aidera à mieux comprendre les problèmes que vous rencontrez et comment les résoudre.
Scikit-learn (anciennement
scikits.learn ) est une bibliothèque d'apprentissage automatique gratuite pour Python. Il comprend différents types d'
algorithmes de
classification , de
régression et de
regroupement , y compris
la méthode du vecteur de support , l'algorithme de
forêt aléatoire («forêt aléatoire»), l'
amplification du gradient , la
méthode k- means et
DBSCAN . Scikit-learn il est conçu pour interagir avec les ordinateurs et les bibliothèques de recherche Python
numpy et
SciPy .

 Mémo Scikit-learn
Mémo Scikit-learnGuide d'algorithme d'apprentissage automatique
Ce mémo Microsoft Azure vous aidera à choisir les bons algorithmes d'apprentissage automatique pour votre solution d'analyse prédictive. Tout d'abord, le mémo pose des questions sur la nature des données, puis conseille le meilleur algorithme.

Python pour la science des données
 Mémo Python pour la science des données
Mémo Python pour la science des données Mémo Big Data
Mémo Big DataTensorflow
En mai 2017, Google a annoncé la deuxième génération de TPU, ainsi que leur disponibilité dans
Google Compute Engine . Les TPU de deuxième génération ont des performances allant jusqu'à 180 téraflops et avec 64 TPU en cluster jusqu'à 11,5 pétaflops.
 Mémo TensorFlow
Mémo TensorFlowKeras
En 2017, l'équipe TensorFlow de Google a décidé d'intégrer la prise en charge Keras dans la bibliothèque principale TensorFlow. Chollet a expliqué que Keras est une interface plutôt qu'un système d'apprentissage automatique de bout en bout. Il fournit un ensemble d'abstractions de niveau supérieur et plus intuitif qui simplifie la configuration des réseaux de neurones, quelle que soit la bibliothèque de calcul scientifique utilisée dans le backend.

Numpy
NumPy pour
CPython , l'implémentation de référence Python, qui est pas optimisé bytecode interprète. Les algorithmes mathématiques écrits pour cette version de Python fonctionnent souvent beaucoup plus lentement que leurs homologues compilés. La bibliothèque NumPy résout partiellement le problème de vitesse dû aux tableaux multidimensionnels, ainsi qu'aux fonctions et opérateurs optimisés pour travailler avec les tableaux. Il sera nécessaire de réécrire une partie du code en utilisant NumPy, principalement des boucles internes.
 Numpy Memo
Numpy MemoPandas
Le nom «Pandas» vient du terme économétrique «
données de panel », qui est utilisé pour les ensembles de données structurées multidimensionnelles.
 Pandas Memo
Pandas MemoLutte contre les données
Data Wrangling (données de
«pâturage», traitement de données primaires ) - ce terme commence à pénétrer dans la culture pop. Dans le film Kong 2017: Skull Island en 2017, l'un des personnages est présenté comme Steve Woodward, notre lutteur de données.
 Mémo sur la lutte contre les données
Mémo sur la lutte contre les données Pandas Data Wrangling Memo
Pandas Data Wrangling MemoLutte de données avec dplyr et tidyr
 Mémo sur la lutte contre les données avec dplyr et tidyr
Mémo sur la lutte contre les données avec dplyr et tidyr Mémo sur la lutte contre les données avec dplyr et tidyr
Mémo sur la lutte contre les données avec dplyr et tidyrScipy
SciPy est basé sur un objet tableau NumPy. Cette bibliothèque fait partie de la pile NumPy, qui comprend des outils tels que
Matplotlib ,
Pandas et
SymPy , ainsi qu'un ensemble croissant de bibliothèques pour le calcul scientifique. La pile NumPy et les applications
MATLAB ,
GNU Octave et
Scilab ont le même public d'utilisateurs. La pile NumPy est aussi parfois appelée pile SciPy.
 Scipy Memo
Scipy MemoMatplotlib
Matplotlib est une bibliothèque graphique pour Python et son extension mathématique de calcul NumPy. Il fournit une API orientée objet pour incorporer des graphiques dans des applications utilisant des outils GUI universels tels que
Tkinter ,
wxPython ,
Qt ou
GTK + . Il existe également une interface procédurale pylab basée sur une machine à états (comme OpenGL) conçue pour ressembler à
MATLAB , bien que son utilisation ne soit pas recommandée.
SciPy utilise matplotlib.
Pyplot est un module matplotlib qui fournit une interface comme MATLAB. Matplotlib est utilisé de la même manière que MATLAB, vous permet d'utiliser Python, et également gratuitement.
 Matplotlib Memo
Matplotlib MemoVisualisation des données
 Mémo de visualisation des données
Mémo de visualisation des données Mémo Ggplot
Mémo GgplotPyspark
 PySpark Memo
PySpark Memo"Oh Big" (Big-O)
 Mémo de complexité d'algorithme
Mémo de complexité d'algorithme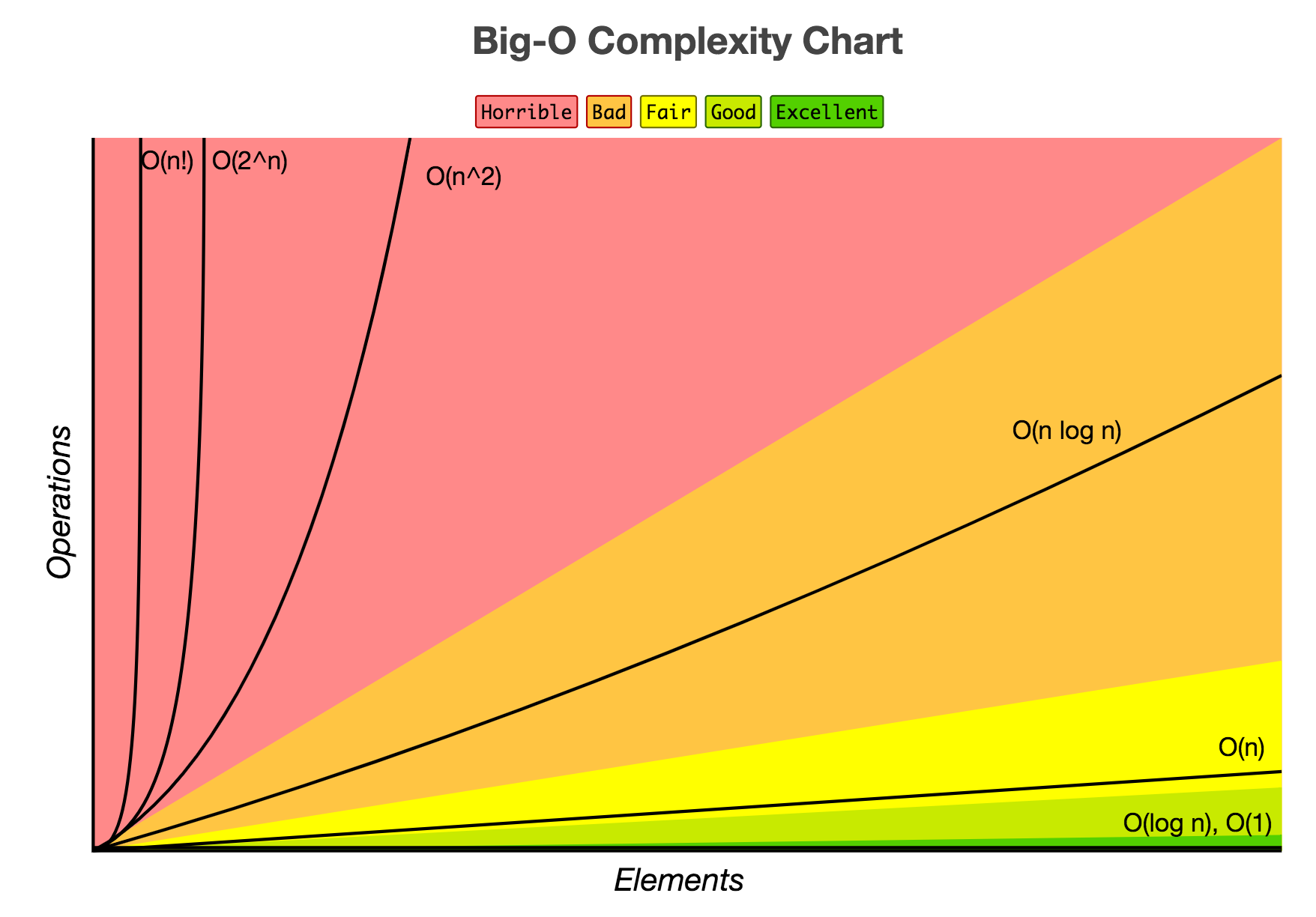 Mémo de complexité d'algorithme
Mémo de complexité d'algorithme Un mémo sur la complexité des opérations avec les structures de données dans les algorithmes
Un mémo sur la complexité des opérations avec les structures de données dans les algorithmes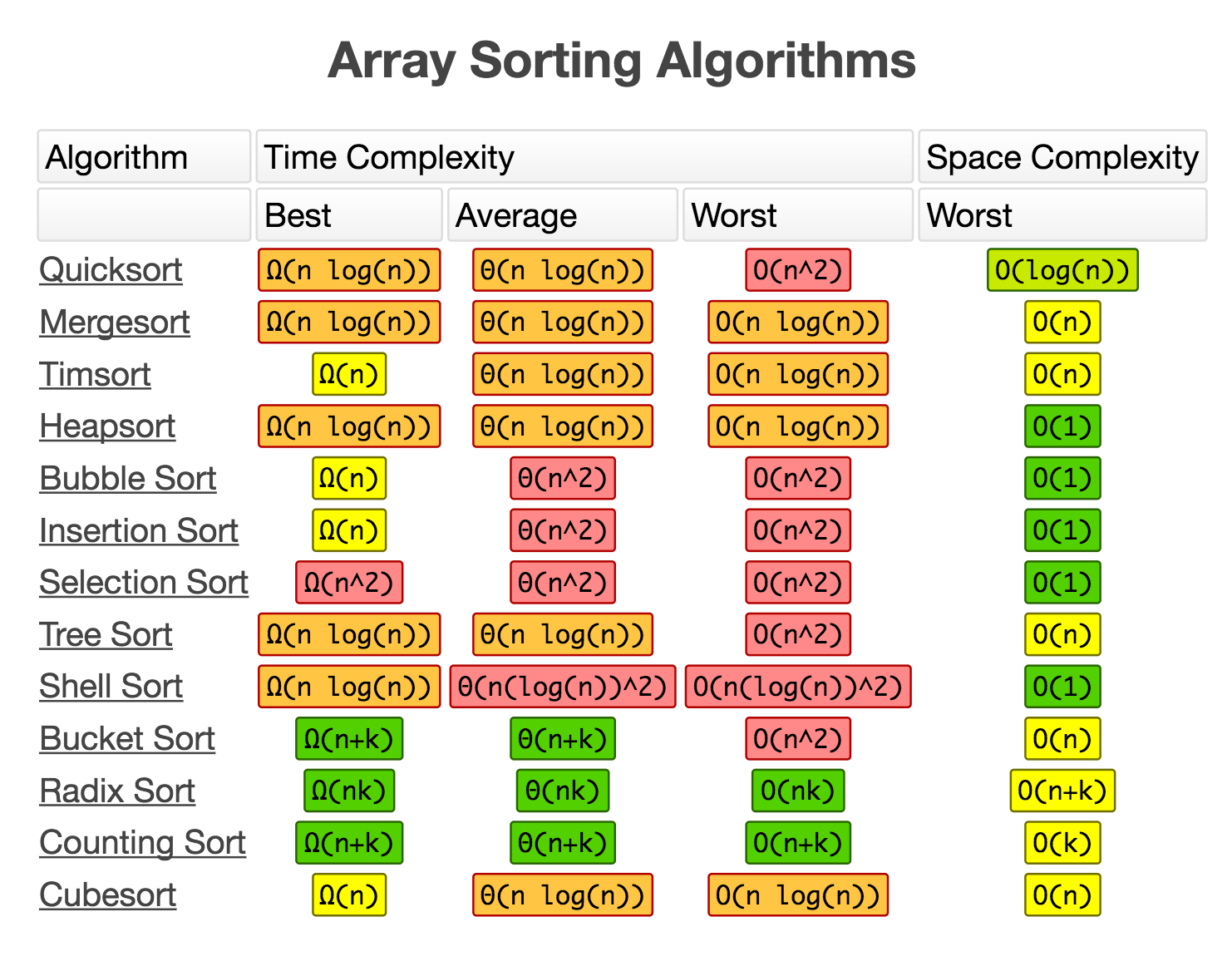 Un mémo sur la complexité des algorithmes de tri des tableaux
Un mémo sur la complexité des algorithmes de tri des tableauxLes sources
Mémo de complexité d'algorithmeBokeh MemoMémo sur la science des donnéesMémo sur la lutte contre les donnéesMémo GgplotKeras MemoGuide d'apprentissage automatiqueGuide d'apprentissage automatiqueGuide d'apprentissage automatiqueMatplotlib MemoMémo du réseau neuronalMémo sur les graphiques des réseaux de neuronesRéseaux de neuronesNumpy MemoPandas MemoPandas MemoPyspark MemoScikit MemoMémo Scikit-learnScipy MemoMémo TensorFlow