Puis-je informer les développeurs frontaux de l'architecture sans serveur sans cloud dans AWS (Amazon Web Services) de manière simple? Pourquoi pas. Rendons l'application AWS React / Redux, puis parlons des avantages et des inconvénients des lambdas AWS.
Le matériel est basé sur la transcription du rapport de Marina Mironovich de notre conférence de printemps HolyJS 2018 à Saint-Pétersbourg.Officiellement, Marina est l'un des principaux développeurs d'EPAM. Aujourd'hui, elle travaille dans un groupe d'architectes de solutions pour un client et participe de ce fait à un grand nombre de projets. Par conséquent, il nous sera plus facile de tracer le cercle de ses intérêts actuels que d'énumérer toutes les technologies avec lesquelles elle travaille.
 Tout d'abord, je m'intéresse à toutes les technologies cloud, en particulier AWS, car je travaille beaucoup avec cela en production. Mais j'essaie de suivre tout le reste.
Tout d'abord, je m'intéresse à toutes les technologies cloud, en particulier AWS, car je travaille beaucoup avec cela en production. Mais j'essaie de suivre tout le reste.
Frontend est mon premier amour et semble éternel. En particulier, je travaille actuellement avec React et React Native, donc j'en sais un peu plus à ce sujet. J'essaie également de garder une trace de tout le reste. Je m'intéresse à tout ce qui concerne la documentation du projet, par exemple les diagrammes UML. Comme je suis membre du groupe d'architectes de solutions, je dois en faire beaucoup.
Partie 1. Contexte
L'idée de parler de Serverless m'est venue il y a environ un an. Je voulais parler de Serverless pour les développeurs frontaux facilement et naturellement. Pour que vous n'ayez pas besoin de connaissances supplémentaires pour l'utiliser, plus les technologies vous le permettent désormais.
Dans une certaine mesure, l'idée a été réalisée - j'ai
parlé de Serverless à FrontTalks 2017. Mais il s'est avéré que 45 minutes ne suffisaient pas pour une histoire simple et compréhensible. Par conséquent, le rapport était divisé en deux parties, et maintenant vous avez devant vous la deuxième "série". Qui n'a pas vu le premier - ne vous inquiétez pas, cela ne fera pas de mal à comprendre ce qui est écrit ci-dessous. Comme dans les émissions de télévision décentes, je vais commencer par un résumé de la partie précédente. Ensuite, je vais passer au jus lui-même - nous rendrons l'application React / Redux. Et enfin, je parlerai des avantages et des inconvénients des fonctions cloud en principe (en particulier, les lambdas AWS) et de ce qui peut être fait d'autre avec elles. J'espère que cette partie sera utile à tous ceux qui connaissent déjà l'AWS lambda. Plus important encore, le monde ne se termine pas avec Amazon, alors parlons de ce qu'il y a d'autre dans le domaine des fonctions cloud.
Ce que j'utiliserai
Pour rendre l'application, j'utiliserai de nombreux services Amazon:
- S3 est un système de fichiers dans les nuages. Nous y stockerons des actifs statiques.
- IAM (droits d'accès pour les utilisateurs et les services) - implicitement, mais il sera utilisé en arrière-plan afin que les services communiquent entre eux.
- API Gateway (URL pour accéder au site) - vous verrez l'URL où nous pouvons appeler notre lambda.
- CloudFormation (pour le déploiement) - sera utilisé implicitement en arrière-plan.
- AWS Lambda - nous sommes venus ici pour cela.
Qu'est-ce que sans serveur et qu'est-ce qu'AWS Lambda?
En fait, Serverless est une grosse fraude, car il y a bien sûr des serveurs: quelque part, tout commence. Mais que se passe-t-il là-bas?
Nous écrivons une fonction, et cette fonction s'exécute sur les serveurs. Bien sûr, cela commence non seulement comme ça, mais dans une sorte de conteneur. Et, en fait, cette fonction dans le conteneur sur le serveur est appelée lambda.
Dans le cas de lambda, nous pouvons oublier les serveurs. Je dirais même ceci: lorsque vous écrivez la fonction lambda, il est nuisible d'y penser. Nous ne travaillons pas avec lambda comme nous le faisons avec un serveur.
Comment déployer lambda
Une question logique se pose: si nous n'avons pas de serveur, comment le déployer? Il y a SSH sur le serveur, nous avons téléchargé le code, l'avons lancé - tout va bien. Que faire avec lambda?
Option 1. Nous ne pouvons pas le déployer.AWS dans la console a fait un IDE agréable et doux pour nous, où nous pouvons venir écrire une fonction là-bas.

C'est sympa, mais pas très extensible.
Option 2. Nous pouvons créer un zip et le télécharger depuis la ligne de commandeComment créer un fichier zip?
zip -r build/lambda.zip index.js [node_modules/] [package.json]
Si vous utilisez node_modules, tout cela est compressé dans une archive.
De plus, selon que vous créez une nouvelle fonction ou si vous en avez déjà une, vous effectuez soit
aws lambda create-function...
soit
aws lambda update-function-code...
Quel est le problème? Tout d'abord, l'AWS CLI souhaite savoir si une fonction est en cours de création ou si vous en avez déjà une. Ce sont deux équipes différentes. Si vous souhaitez mettre à jour non seulement le code, mais également certains attributs de cette fonction, les problèmes commencent. Le nombre de ces commandes augmente, et vous devez vous asseoir avec un répertoire et réfléchir à la commande à utiliser.
Nous pouvons le faire mieux et plus facilement. Pour cela, nous avons des cadres.
Cadres AWS Lambda
Il existe de nombreux cadres de ce type. Il s'agit principalement d'AWS CloudFormation, qui fonctionne conjointement avec l'AWS CLI. CloudFormation est un fichier Json décrivant vos services. Vous les décrivez dans un fichier Json, puis via l'AWS CLI dites «exécuter», et il créera automatiquement tout pour vous dans le service AWS.
Mais c'est toujours difficile pour une tâche aussi simple que de rendre quelque chose. Ici, le seuil d'entrée est trop grand - vous devez lire la structure de CloudFormation, etc.
Essayons de le simplifier. Et ici divers frameworks apparaissent: APEX, Zappa (uniquement pour Python), Claudia.js. Je n'en ai énuméré que quelques-uns, au hasard.
Le problème et la force de ces cadres sont qu'ils sont hautement spécialisés. Donc, ils sont très bons pour faire une tâche simple. Par exemple, Claudia.js est très bon pour créer une API REST. Elle fera l'AWS call API Gateway, elle créera un lambda pour vous, tout sera magnifiquement verrouillé. Mais si vous devez déployer un peu plus, les problèmes commencent - vous devez ajouter quelque chose, aider, regarder, etc.
Zappa a été écrit uniquement pour Python. Et je veux quelque chose de plus ambitieux. Et voici Terraform et mon amour sans serveur.
Sans serveur se situe quelque part entre la très grande CloudFormation, qui peut presque tout faire, et ces frameworks hautement spécialisés. Presque tout peut y être déployé, mais tout faire est encore assez facile. Il a également une syntaxe très légère.
Terraform est, dans une certaine mesure, un analogue de CloudFormation. Terraform est open source, vous pouvez y déployer tout - enfin, ou presque tout. Et quand AWS crée les services, vous pouvez y ajouter quelque chose de nouveau. Mais c'est gros et compliqué.
Pour être honnête, en production, nous utilisons Terraform, car avec Terraform, tout ce que nous avons monte plus facilement - Serverless ne décrira pas tout cela. Mais Terraform est très complexe. Et quand j'écris quelque chose pour le travail, je l'écris d'abord sur Serverless, je le teste pour les performances, et seulement après que ma configuration a été testée et testée, je le réécris sur Terraform (c'est "amusant" pendant quelques jours de plus).
Sans serveur
Pourquoi j'aime Serverless?
- Serverless a un système qui vous permet de créer des plugins. À mon avis, c'est un salut de tout. Sans serveur - open source. Mais ajouter quelque chose à l'open source n'est pas toujours facile. Vous devez comprendre ce qui se passe dans le code existant, observer les directives, au moins codestyle, soumettre un PR, ils oublieront ce PR et il accumulera de la poussière pendant trois ans. Selon les résultats, vous bifurquez, et ce sera quelque part pour vous séparément. Tout cela n'est pas très sain. Mais quand il y a des plugins, tout est simplifié. Vous devez ajouter quelque chose - vous êtes à genoux en train de créer votre propre petit plugin. Pour ce faire, vous n'avez plus besoin de comprendre ce qui se passe à l'intérieur de Serverless (si ce n'est pas une question super personnalisée). Vous utilisez simplement l'API disponible, quelque part où vous enregistrez le plugin ou le déployez pour tout le monde. Et tout fonctionne pour vous. De plus, il existe déjà un grand zoo de plugins et de personnes qui écrivent ces plugins. Autrement dit, peut-être que quelque chose a déjà été décidé pour vous.
- Sans serveur permet d'exécuter lambda localement. Le plus gros inconvénient de la lambda est qu'AWS n'a pas réfléchi à la façon dont nous allons le déboguer et le tester. Mais Serverless vous permet de tout exécuter localement, voir ce qui se passe (il le fait même en conjonction avec l'API Gateway).
Démonstration
Je vais maintenant montrer comment tout cela fonctionne vraiment. Au cours des prochaines 1h30 à 2 minutes, nous pourrons créer un service qui rendra notre page HTML.
Tout d'abord, dans un nouveau dossier, je lance le modèle SLS Create:
mkdir sls-holyjs
cd sls-holyjs
sls create --template aws-nodejs-ecma-script

npm install

Les développeurs sans serveur ont pris soin de nous - ont permis de créer des services à partir de modèles. Dans ce cas, j'utilise le modèle
nodejs-ecma-script , qui va créer des fichiers pour moi, tels que la configuration du webpack, package.json, certaines fonctions et serverless.yml:
ls

Je n'ai pas besoin de toutes les fonctionnalités. Je vais supprimer le premier, le deuxième renommage dans HolyJS:

Je vais modifier un peu serveless.yml, où j'ai une description de tous les services nécessaires:
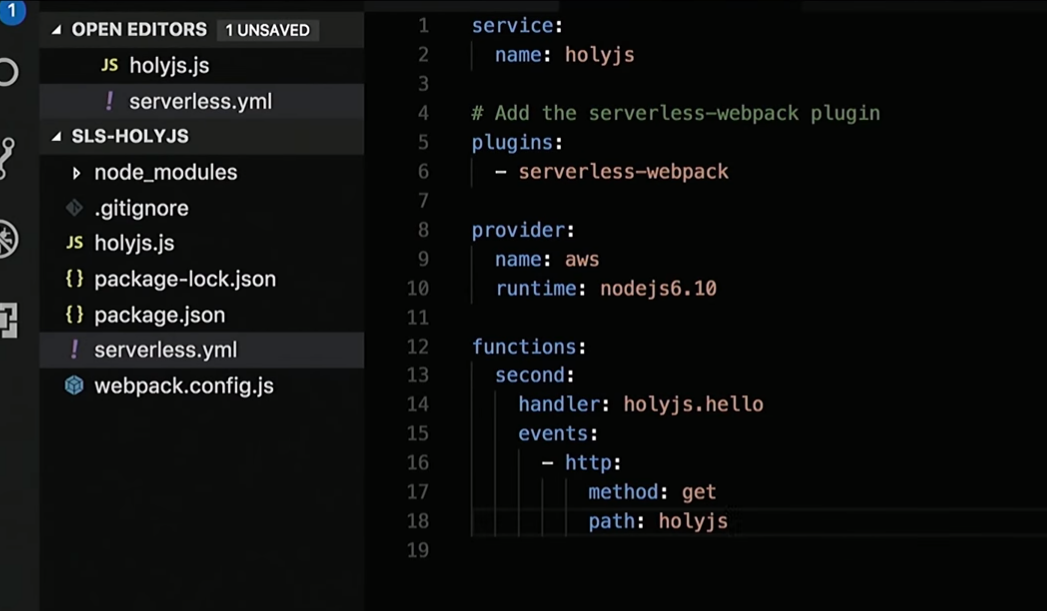
Eh bien, je vais corriger la réponse que la fonction renvoie:

Je vais créer le code HTML "Bonjour HolyJS" et ajouter une poignée pour le rendu.
Suivant:
sls deploy
Et le tour est joué! Il y a une URL où je peux voir en accès public ce qui est rendu:

Faites confiance, mais vérifiez. Je vais accéder à la console AWS et vérifier que j'ai créé une fonction HolyJS:
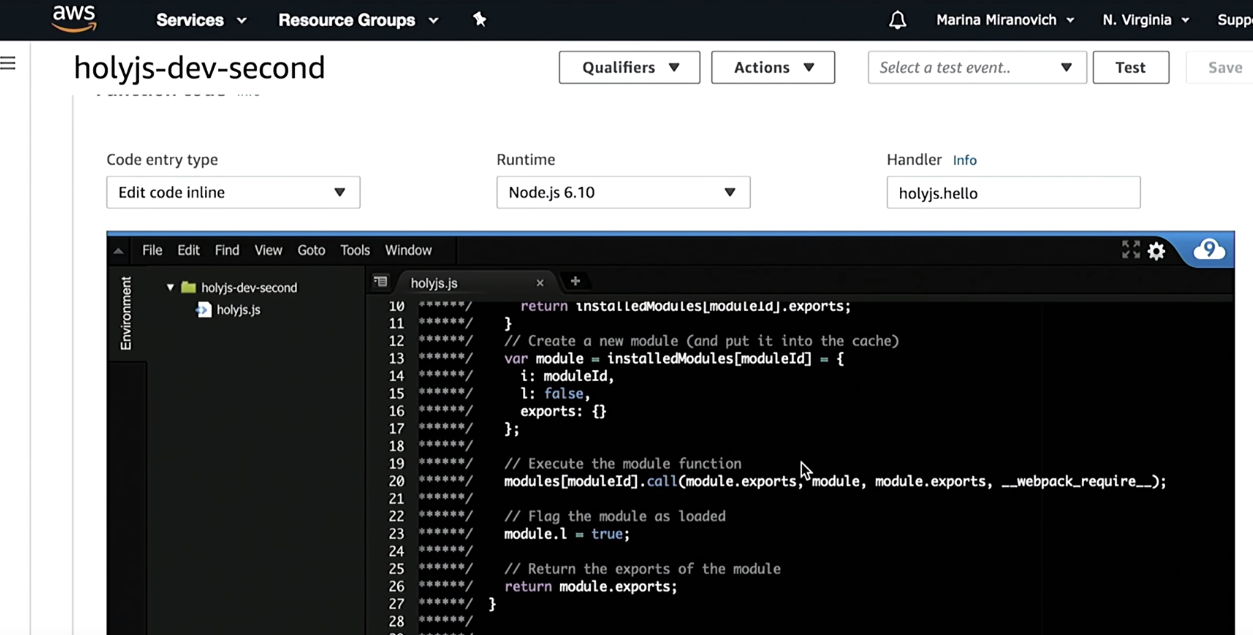
Comme vous pouvez le voir, avant de le déployer, Serverless le construira à l'aide de webpack. De plus, le reste de l'infrastructure qui y est décrite sera créé - API Gateway, etc.
Quand je veux supprimer ceci:
sls remove
Toute infrastructure décrite dans serverless.yml sera supprimée.

Si quelqu'un est derrière le processus décrit ici, je vous invite à simplement consulter mon
rapport précédent .
Exécutez lambda localement
J'ai mentionné que lambda peut être exécuté localement. Il existe deux options de lancement ici.
Option 1. Nous exécutons tout simplement dans le terminalNous obtenons ce que notre fonction retourne.
sls invoke local -f [fn_name]
N'oubliez pas, nous faisons une application isomorphe, ce sera HTML et CSS, donc dans le terminal ce n'est pas très intéressant de regarder les longues lignes HTML. Là, vous pouvez vérifier que la fonction fonctionne. Mais je voudrais exécuter et rendre cela dans le navigateur. En conséquence, j'ai besoin d'un tas de passerelles API avec lambda.
Pour ce faire, il existe un plugin séparé sans serveur qui lancera votre lambda sur un port (c'est écrit), puis il affichera une URL dans le terminal où vous pourrez y accéder.
sls offline --port 8000 start
La meilleure partie est qu'il y a un rechargement à chaud. Autrement dit, vous écrivez le code de fonction, mettez à jour votre navigateur et vous êtes mis à jour ce que la fonction renvoie. Vous n'avez pas besoin de tout redémarrer.
Il s'agit d'un résumé de la première partie du rapport. Nous passons maintenant à la partie principale.
Partie 2. Rendu avec AWS
Le projet décrit ci-dessous est
déjà sur GitHub. Si vous êtes intéressé, vous pouvez y télécharger le code.
Commençons par comment tout cela fonctionne.

Supposons qu'il existe un utilisateur - moi.
- J'ouvre le site.
- À une certaine URL, nous accédons à l'API de passerelle. Je tiens à noter que l'API Gateway est déjà un service AWS, nous sommes déjà dans les nuages.
- L'API de passerelle appellera lambda.
- Le lambda rendra le site, et tout cela reviendra au navigateur.
- Le navigateur commencera à afficher et à réaliser que certains fichiers statiques sont manquants. Ensuite, il se tournera vers le compartiment S3 (notre système de fichiers, où nous stockons toutes les statistiques; dans le compartiment S3, vous pouvez tout mettre - polices, images, CSS, JS).
- Les données du compartiment S3 reviendront au navigateur.
- Le navigateur affichera la page.
- Tout le monde est content.
Faisons un petit examen du code de ce que j'ai écrit.
Si vous allez sur GitHub, vous verrez la structure de fichiers suivante:
lambda-react
README.md
config
package.json
public
scripts
serverless.yml
src
yarn.lock
Tout cela est généré automatiquement dans la trousse d'outils React / Redux. En fait, ici, nous ne serons intéressés que par quelques fichiers et ils devront être légèrement corrigés:
- config
- package.json
- serverless.yml - parce que nous allons déployer,
- src - nulle part sans lui.
Commençons par la configuration
Pour tout rassembler sur le serveur, nous devons ajouter un autre webpack.config:

Ce webpack.config sera déjà généré pour vous si vous utilisez un modèle. Et là, la variable
slsw.lib.entries est automatiquement substituée, ce qui pointera vers vos gestionnaires lambda. Si vous le souhaitez, vous pouvez le modifier vous-même en spécifiant autre chose.

Nous devrons tout rendre pour le nœud (
target: 'node' ). En principe, tous les autres chargeurs restent les mêmes que pour une application React standard.
Suite à package.json
Nous allons simplement ajouter quelques scripts - le démarrage et la génération ont déjà été générés avec React / Redux - rien ne change. Ajoutez un script pour lancer le lambda et un script pour déployer le lambda.

serverless.yml
Un très petit fichier - seulement 17 lignes, toutes ci-dessous:

Qu'est-ce qui nous intéresse? Tout d'abord, gestionnaire. Le chemin complet du fichier y est
src/lambda/handler (
src/lambda/handler ) et la fonction de gestionnaire est spécifiée via le point.
Si vous le souhaitez vraiment, vous pouvez enregistrer plusieurs gestionnaires dans un seul fichier. Voici également le chemin vers webpack, qui devrait collecter tout cela. Fondamentalement, tout: le reste est déjà généré automatiquement.
Le plus intéressant est src
Voici une énorme application React / Redux (dans mon cas ce n'est pas énorme - vers la page). Dans le dossier lambda supplémentaire se trouve tout ce dont nous avons besoin pour rendre le lambda:
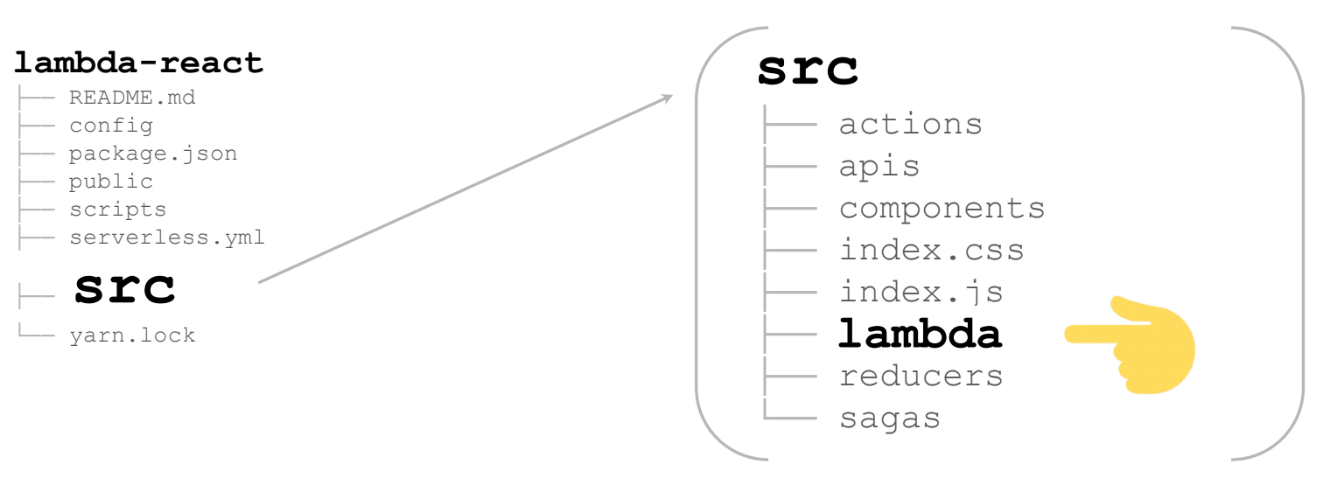
Ce sont 2 fichiers:
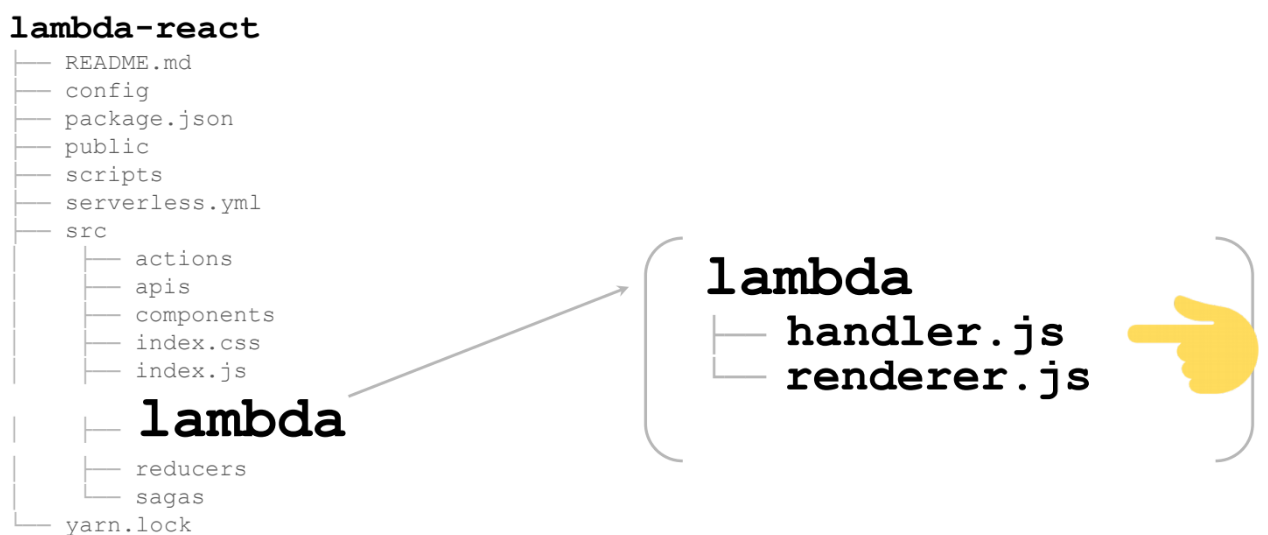
Commençons par le gestionnaire. Le plus important est la ligne 13. Voici le moteur de rendu, qui est le lambda même qui sera appelé dans les nuages:

Comme vous pouvez le voir, la fonction
render () renvoie une promesse, à partir de laquelle toutes les exceptions doivent être interceptées. C'est la particularité du lambda, sinon le lambda ne se terminera pas immédiatement, mais fonctionnera jusqu'à la temporisation. Vous devrez payer un supplément pour un code déjà tombé. Pour éviter que cela ne se produise, vous devez terminer le lambda le plus tôt possible - tout d'abord, intercepter et gérer toutes les exceptions. Plus tard, nous y reviendrons.
Si nous n'avons aucune erreur ou exception, nous appelons la fonction
createResponse , qui prend littéralement cinq lignes. Nous ajoutons simplement tous les en-têtes pour qu'il s'affiche correctement dans le navigateur:

La chose la plus intéressante ici est la fonction de
render , qui rendra notre page:

Cette fonction nous vient de renderer.js. Voyons ce qu'il y a.
Une application isomorphe y est rendue. De plus, il est rendu sur n'importe quel serveur - peu importe qu'il s'agisse de lambda ou non.
Je ne vous dirai pas en détail ce qu'est une application isomorphe, comment la rendre, car c'est un sujet complètement différent, et il y a des gens qui l'ont mieux dit que moi. Voici quelques tutoriels que j'ai trouvés en cherchant sur Google en quelques minutes:

Si vous connaissez d'autres rapports, vous pouvez le conseiller, je leur donnerai des liens sur mon Twitter.
Afin de ne perdre personne, je monte simplement à l'étage, je raconte ce qui se passe là-bas.
Tout d'abord, nous devons rendre cela avec HTML / React / Redux.
Cela se fait via la méthode React standard -
renderToString :

Ensuite, nous devons rendre les styles afin que notre contenu ne clignote pas. Ce n'est pas une tâche très triviale. Il existe plusieurs packages npm qui le résolvent. Par exemple, j'ai utilisé le
node-style-loader , qui rassemblera tout dans
styleTag , puis vous pourrez le coller en HTML.

S'il y a de meilleurs forfaits - c'est à votre discrétion.
Ensuite, nous devons passer l'état Redux. Puisque vous effectuez le rendu sur le serveur, vous voulez probablement obtenir des données et vous ne voulez pas que Redux les redemande et les restitue à nouveau. Il s'agit d'une tâche assez standard. Il existe des exemples sur le site Web principal de Redux sur la façon de procéder: nous créons un objet et le passons ensuite à travers une variable globale:

Maintenant un peu plus près de la lambda.
Il est nécessaire de gérer les erreurs. Nous voulons tout attraper et faire quelque chose avec eux, au moins arrêter le développement de lambda. Par exemple, je l'ai fait par
promise :

Ensuite, nous devons remplacer nos URL par des fichiers statiques. Et pour cela, nous devons découvrir où le lambda s'exécute - localement ou quelque part dans les nuages. Comment le découvrir?
Nous le ferons à travers des variables d'environnement:
…
const bundleUrl = process.env.NODE_ENV === 'AWS' ?
AWS_URL : LOCAL_URL;
Une question intéressante: comment les variables d'environnement se réunissent dans un lambda. En fait assez simple. En yml, vous pouvez transmettre toutes les variables à l'
environment . Lorsqu'il est verrouillé, ils seront disponibles:

Eh bien, un bonus - après avoir déployé un lambda, nous voulons déployer tous les actifs statiques. Pour ce faire, nous avons déjà écrit un plugin où vous pouvez désigner le panier S3 où vous souhaitez déployer quelque chose:

Au total, nous avons fait une application isomorphe en cinq minutes environ pour montrer que tout cela est simple.
Parlons maintenant un peu de la théorie - les avantages et les inconvénients de lambda.
Commençons par le mauvais.
Fonctions lambda
Les inconvénients peuvent inclure (ou peut-être pas) l'heure d'un démarrage à froid. Par exemple, pour le lambda sur Node.js que nous écrivons maintenant, l'heure de démarrage à froid ne signifie pas grand-chose.
Le graphique ci-dessous montre l'heure de démarrage à froid. Et cela peut être un gros problème, en particulier pour Java et C # (faites attention aux points orange) - vous ne voulez pas que cela prenne seulement cinq à six secondes pour commencer à exécuter le code.
Pour Node.js, l'heure de début est presque nulle - 30 - 50 ms. Bien sûr, pour certains, cela peut également être un problème. Mais les fonctions peuvent être réchauffées (bien que ce ne soit pas le sujet de ce rapport). Si quelqu'un est intéressé par la façon dont ces tests ont été effectués, bienvenue sur acloud.guru, il vous dira tout (
dans l'article ).

Quels sont donc les inconvénients?
Limites de taille du code de fonction
Le code doit être inférieur à 50 Mo. Est-il possible d'écrire une fonction aussi grande? N'oubliez pas les node_modules. Si vous connectez quelque chose, surtout s'il y a des fichiers binaires, vous pouvez très facilement dépasser 50 Mo, même pour les fichiers zip. J'ai eu de tels cas. Mais c'est une raison supplémentaire pour voir à quoi vous vous connectez à node_modules.
Limitations d'exécution
Par défaut, la fonction est exécutée pendant une seconde. Si cela ne se termine pas après une seconde, vous aurez un timeout. Mais ce temps peut être augmenté dans les paramètres. Lors de la création d'une fonction, vous pouvez définir la valeur sur cinq minutes. Cinq minutes est une date limite difficile. Ce n'est pas un problème pour le site. Mais si vous voulez faire quelque chose de plus intéressant sur les lambdas, par exemple, traiter des images, convertir du texte en son ou du son en texte, etc., de tels calculs peuvent facilement prendre plus de cinq minutes. Et ce sera un problème. Que faire à ce sujet? Optimiser ou ne pas utiliser lambda.
Une autre chose intéressante qui se pose à propos du délai d'exécution de lambda. Rappelez-vous la disposition de notre site. Tout fonctionnait parfaitement jusqu'à ce que le produit vienne et veuille sur le flux en temps réel du site - afficher les actualités en temps réel. Nous savons que cela est implémenté avec WebSockets. Mais les WebSockets ne fonctionnent pas pendant cinq minutes, ils doivent être conservés plus longtemps. Et ici, la limite de cinq minutes devient un problème.

Une petite remarque. Pour AWS, ce n'est plus un problème. Ils ont trouvé comment contourner cela. Mais d'une manière générale, dès l'apparition des sockets Web, lambda n'est pas une solution pour vous. Vous devez à nouveau passer aux bons vieux serveurs.
Le nombre de fonctions parallèles par minute
Ci-dessus, une limite de 500 à 3 000, selon la région où vous vous trouvez. À mon avis, en Europe, près de 500. 3000 est pris en charge aux États-Unis.
Si vous avez un site occupé et que vous attendez plus de trois mille requêtes par minute (ce qui est facile à imaginer), cela devient un problème. Mais avant de parler de ce moins, parlons un peu de la façon dont lambda évolue.
Une demande nous parvient et nous obtenons un lambda. Pendant l'exécution de cette lambda, deux autres requêtes nous parviennent - nous démarrons deux lambdas supplémentaires. Les gens commencent à venir sur notre site, des demandes apparaissent et des lambdas sont lancés, de plus en plus.

Ce faisant, vous payez le temps pendant lequel le lambda fonctionne. Supposons que vous payez un centime pour une seconde d'exécution lambda. Si vous avez 10 lambdas par seconde, vous paierez 10 cents pour cette seconde. Si vous avez un million de lambdas en cours d'exécution par seconde, cela représente environ 10 000 dollars. Figure désagréable.
Par conséquent, AWS a décidé de ne pas vider votre portefeuille en une seconde si vous aviez mal effectué vos tests et que vous démarriez DDOS vous-même, provoquant des lambdas, ou quelqu'un d'autre venait faire DDOS. Par conséquent, une limite de trois mille a été établie - afin que vous ayez la possibilité de réagir à la situation.
Si le chargement de 3000 requêtes est régulier pour vous, vous pouvez écrire dans AWS et ils augmenteront la limite.
Apatride
C'est le dernier, encore une fois, un inconvénient controversé.
Qu'est-ce qu'un apatride? Voici une blague sur le poisson rouge - ils ne tiennent tout simplement pas le contexte:

Le lambda, appelé la deuxième fois, ne sait rien du premier appel.
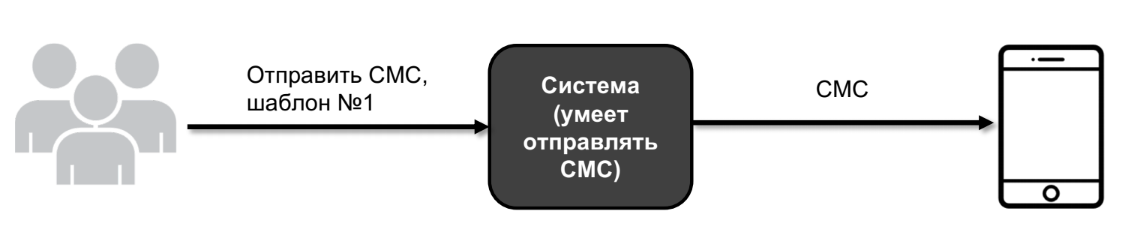
Permettez-moi de vous montrer un exemple. Disons que j'ai un système - une grande boîte noire. Et ce système, entre autres, peut envoyer des SMS.
L'utilisateur vient et dit: envoyez le modèle de SMS numéro 1. Et le système l'envoie à un véritable appareil.
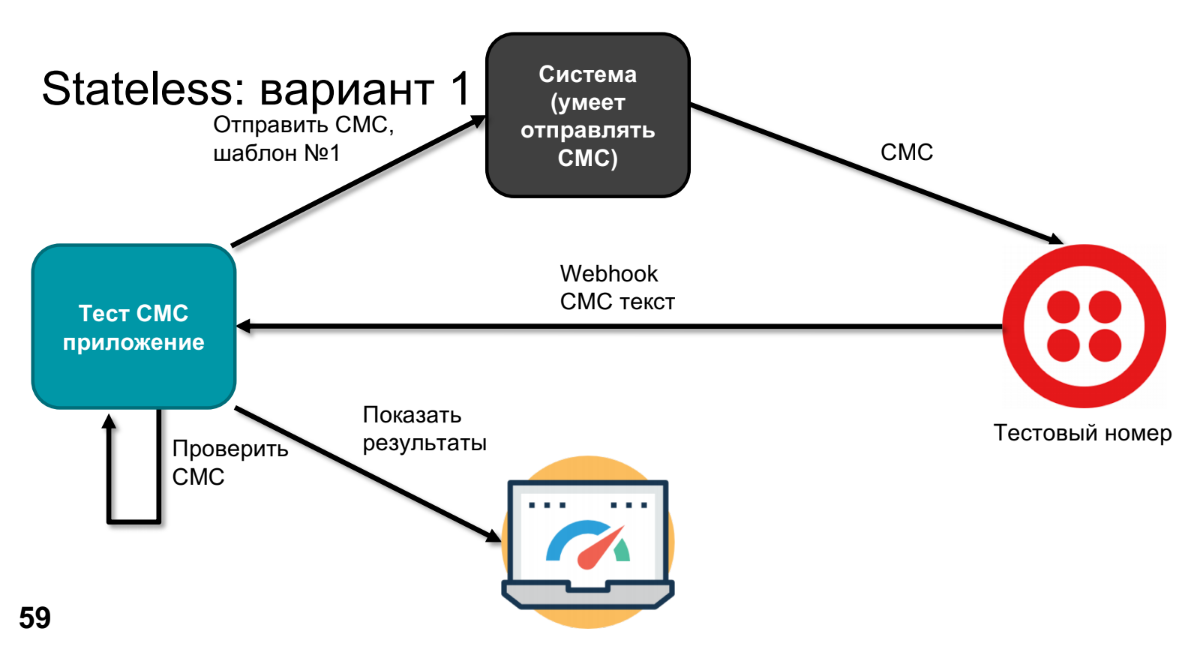
À un moment donné, le produit exprime le désir de savoir ce qui se passera là-bas et de vérifier que rien ne s'est cassé dans ce système. Pour ce faire, nous remplacerons le véritable appareil par une sorte de numéro de test - par exemple, Twilio peut le faire. Il appellera Webhook, enverra le texte SMS, nous traiterons ce texte SMS dans l'application (nous devons vérifier que notre modèle est devenu le bon SMS).
Pour vérifier, nous devons savoir ce qui a été envoyé - nous le ferons via une application de test. Reste à comparer et afficher les résultats.
Essayons de faire de même sur lambda.
Lambda enverra des SMS, des SMS arriveront à Twilio.
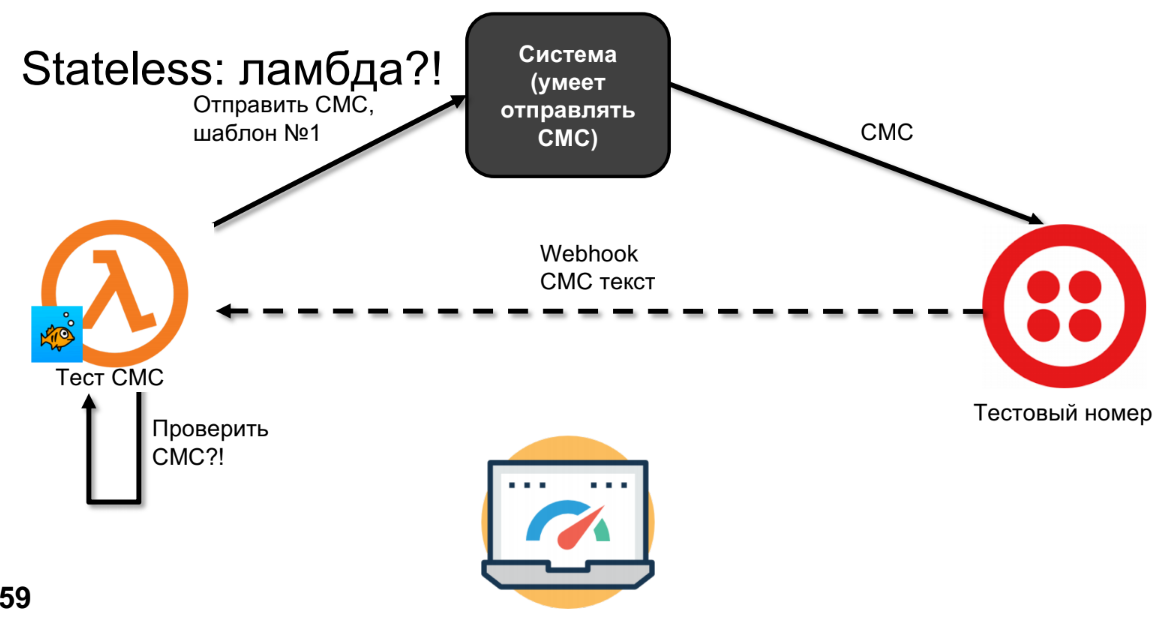
J'ai tracé la ligne pointillée non par accident, car les SMS peuvent remonter en quelques minutes, heures ou jours - cela dépend de votre opérateur, c'est-à-dire qu'il ne s'agit pas d'un appel synchrone. À ce moment, la lambda oubliera tout et nous ne pourrons pas vérifier les SMS.
Je dirais que ce n'est pas un inconvénient, mais une fonctionnalité. Le schéma peut être refait. Il existe plusieurs options pour ce faire, je proposerai la mienne. Si nous avons des apatrides et que nous voulons enregistrer quelque chose, alors nous devons absolument utiliser le stockage, par exemple, une base de données, S3, mais tout ce qui stockera notre contexte.
Dans le schéma avec le stockage SMS, il sera envoyé au numéro de test. Et lorsque Webhook l'appelle - je suggère d'appeler, par exemple, le deuxième lambda, car c'est une fonction légèrement différente. Et le deuxième lambda pourra déjà aller chercher le SMS-ku qui est parti de la base de données, le vérifier et afficher les résultats.

Bingo!
Au tout début, j'ai dit que vous devez oublier les serveurs si vous écrivez lambda. J'ai rencontré des gens qui écrivent sur node.js et qui sont habitués à exprimer des serveurs. Ils aiment s'appuyer sur le cache, et le cache reste dans lambdas. Et parfois, quand ils testent, cela fonctionnera, et parfois non. Comment est-ce possible?Supposons que nous ayons un serveur et qu'un conteneur commence dedans. Le lancement d'un conteneur est une opération assez coûteuse. Tout d'abord, vous devez fabriquer ce conteneur. Ce n'est qu'après sa création que le code de fonction y est déployé et peut être exécuté. Une fois votre fonction exécutée, le conteneur n'est pas supprimé, car AWS pense que vous pouvez à nouveau appeler cette fonction. AWS n'a jamais écrit la durée de vie du conteneur après l'arrêt de la fonction. Nous avons fait des expériences. À mon avis, pour le nœud, c'est trois minutes, pour Java, ils peuvent contenir un conteneur pendant 12-15 minutes. Mais cela signifie que lorsque la prochaine fonction sera appelée, elle sera appelée dans le même conteneur et dans le même environnement. Si vous utilisez le cache de nœuds quelque part, vous y créez des variables, etc. - si vous ne les avez pas nettoyés, ils y resteront. Donc, si vous écrivez sur lambda,alors vous devez oublier le cache en général, sinon vous pouvez vous retrouver dans des situations désagréables. C'est difficile à dévier.Avantages des fonctions lambda
Il y en a moins, mais elles me semblent plus agréables.- Tout d'abord, nous oublions vraiment qu'il y a un serveur. En tant que développeur, j'écris une fonction en javascript, et c'est tout. Je suis sûr que beaucoup d'entre vous ont écrit des fonctions en javascript, vous n'avez pas besoin d'en savoir plus.
- Pas besoin de penser au cache, ni à la mise à l'échelle, verticale ou horizontale. Ce que vous avez écrit fonctionnera. Peu importe qu'une personne visite votre site par mois ou qu'il y ait un million de visites.
- Dans le cas d'AWS lambdas, ils ont déjà leur propre intégration avec presque tous leurs serveurs (DynamoDB, Alexa, API Gateway, etc.).
Que peut-on faire d'autre sur les lambdas?
J'ai donné un exemple assez standard - j'ai parlé du rendu d'une application isomorphe, car fondamentalement, ils considèrent les lambdas comme une API REST. Mais je veux donner plus d'exemples de ce qui peut être fait avec eux, juste pour vous donner matière à réflexion et à imagination.En principe, sur lambdas, vous pouvez tout faire ... avec un astérisque.- Les services HTTP sont ce dont je parlais. API REST, chaque API de noeud final est un lambda. Cela correspond parfaitement. Surtout compte tenu de la façon dont l'entreprise utilise souvent node.js pour créer un middleware. Nous avons java qui fait tout le coût, puis nous écrivons une couche sur js qui gère les demandes très facilement. Il peut être réécrit en lambdas et sera encore plus frais.
- IoT — , Alexa - -, , .
- Chat Bots — , IoT.
- Image/Video conversions.
- Machine learning.
- Batch Jobs — - , Batch Job .
Désormais, outre Amazon, Google, Azure, IBM, Twillio, presque tous les grands services souhaitent implémenter des fonctions cloud dans leur maison. Si Roskomnadzor bloque tout, nous démarrons un petit serveur préféré dans notre garage et y déployons notre cloud computing. Pour ce faire, nous avons besoin de l'open source (d'autant plus que vous devez payer pour les services, et l'open source est gratuit). Et l'open source ne reste pas immobile. Ils ont déjà fait un nombre irréaliste de mises en œuvre de tout cela. Je vais maintenant dire des mots effrayants pour les frontends - Docker Swarm, Kubernetes - tout fonctionne de cette façon.La meilleure partie est que, premièrement, les fonctions cloud restent tout aussi simples. Si vous aviez des fonctions sur AWS ou lambdas, les traduire en open source est tout aussi simple.Tous les développements ne sont pas répertoriés ci-dessous. Je viens d'en choisir une plus grande et plus intéressante. La liste complète est énorme: de nombreuses startups commencent à travailler sur ce sujet maintenant:- Fonctions de fer
- Fnproject
- Openfaas
- Apache OpenWhisk
- Kubeless
- La fission
- Funktion
J'ai essayé Fnproject et n'ai passé que quelques heures pour transférer cette application isomorphe vers Fnproject et l'exécuter localement avec un conteneur Kubernetes.Il est toujours rapidement évolutif. Vous aurez un tas d'API de passerelle (bien sûr, sans le reste des services), mais vous aurez toujours une URL qui appelle le lambda. Et en fait, presque tout le monde peut oublier les serveurs, comme promis, à l'exception d'une personne qui déploiera ce cadre et configurera cette orchestration Kubernetes afin que les développeurs heureux puissent l'utiliser plus tard.. HolyJS 2018 Moscow, 24-25 . , Early Bird-.