De l'extérieur, il pourrait sembler que Kotlin a simplifié le développement d'Android sans introduire de nouvelles difficultés du tout: le langage est compatible Java, donc même un grand projet Java peut être progressivement traduit en lui sans déranger personne, non? Mais si vous regardez plus profondément, dans chaque boîte, il y a un double fond et dans la coiffeuse, il y a une porte secrète. Les langages de programmation sont des projets trop complexes pour être combinés sans nuances délicates.
Bien sûr, cela ne signifie pas "tout va mal et vous n'avez pas besoin d'utiliser Kotlin avec Java", mais cela signifie que vous devez connaître les nuances et les prendre en compte. Lors de notre conférence
Mobius , Sergei Ryabov
a expliqué comment écrire du code sur Kotlin qui serait facilement accessible depuis Java. Et le public a tellement aimé le reportage que nous avons non seulement décidé de publier une vidéo, mais aussi de faire une version texte pour Habr:
J'écris Kotlin depuis plus de trois ans, maintenant seulement dessus, mais au début j'ai traîné Kotlin dans des projets Java existants. Par conséquent, la question «comment lier Java et Kotlin ensemble» s'est posée assez souvent à ma manière.
Souvent, lorsque vous ajoutez Kotlin à un projet, vous pouvez voir comment cela ...
compile 'rxbinding:xyx' compile 'rxbinding-appcompat-v7:xyx' compile 'rxbinding-design:xyx' compile 'autodispose:xyz' compile 'autodispose-android:xyz' compile 'autodispose-android-archcomponents:xyz'
... se transforme en ceci:
compile 'rxbinding:xyx' compile 'rxbinding-kotlin:xyx' compile 'rxbinding-appcompat-v7:xyx' compile 'rxbinding-appcompat-v7-kotlin:xyx' compile 'rxbinding-design:xyx' compile 'rxbinding-design-kotlin:xyx' compile 'autodispose:xyz' compile 'autodispose-kotlin:xyz' compile 'autodispose-android:xyz' compile 'autodispose-android-kotlin:xyz' compile 'autodispose-android-archcomponents:xyz' compile 'autodispose-android-archcomponents-kotlin:xyz'
Les spécificités des deux dernières années: les bibliothèques les plus populaires acquièrent des wrappers pour pouvoir les utiliser de manière plus idiomatique auprès de Kotlin.
Si vous avez écrit dans Kotlin, alors vous savez qu'il existe des fonctions d'extension sympas, des fonctions en ligne, des expressions lambda qui sont disponibles à partir de Java 6. Et c'est cool, cela nous attire vers Kotlin, mais la question se pose. L'interopérabilité avec Java est l'une des fonctionnalités les plus importantes et les plus publiées du langage. Si vous prenez en compte toutes les fonctionnalités répertoriées, pourquoi ne pas simplement écrire des bibliothèques dans Kotlin? Ils fonctionneront tous parfaitement avec Java, et vous n'aurez pas besoin de prendre en charge tous ces wrappers, tout le monde sera content et content.
Mais, bien sûr, dans la pratique, tout n'est pas aussi rose que dans les brochures, il y a toujours un "petit attribut de police", il y a des arêtes vives à la jonction de Kotlin et Java, et aujourd'hui nous allons en parler un peu.
Arêtes vives
Commençons par les différences. Par exemple, savez-vous que dans Kotlin il n'y a pas de mots-clés volatile, synchronisé, strictfp, transitoire? Ils sont remplacés par des annotations du même nom situées dans le package kotlin.jvm. Ainsi, la plupart de la conversation portera sur le contenu de ce package.
Il y a
Timber - une telle abstraction de bibliothèque sur les enregistreurs du célèbre
Zheka Vartanov . Il vous permet de l'utiliser partout dans votre application, et tout ce que vous souhaitez envoyer des journaux (à logcat, ou à votre serveur pour analyse, ou rapport de plantage, etc.) se transforme en plug-ins.
Imaginons par exemple que nous voulons écrire une bibliothèque similaire, uniquement pour l'analytique. Désengagez également.
object Analytics { fun send(event: Event) {} fun addPlugins(plugs: List<Plugin>) {} fun getPlugins(): List<Plugin> {} } interface Plugin { fun init() fun send(event: Event) fun close() } data class Event( val name: String, val context: Map<String, Any> = emptyMap() )
Nous prenons le même modèle de construction, nous avons un point d'entrée - c'est Analytics. Nous pouvons y envoyer des événements, ajouter des plugins et voir ce que nous y avons déjà ajouté.
Le plugin est une interface de plugin qui résume une API analytique spécifique.
Et, en fait, la classe Event contenant la clé et nos attributs que nous envoyons. Ici, le rapport n'est pas sur la question de savoir s'il vaut la peine d'utiliser des singletones, alors ne reproduisons pas un holivar, mais nous verrons comment peigner tout cela.
Maintenant un petit plongeon. Voici un exemple d'utilisation de notre bibliothèque dans Kotlin:
private fun useAnalytics() { Analytics.send(Event("only_name_event")) val props = mapOf( USER_ID to 1235, "my_custom_attr" to true ) Analytics.send(Event("custom_event", props)) val hasPlugins = Analytics.hasPlugins Analytics.addPlugin(EMPTY_PLUGIN)
En principe, il semble comme prévu. Un point d'entrée, les méthodes sont appelées à la statique. Événement sans paramètres, événement avec attributs. Nous vérifions pour voir si nous avons des plugins, poussons un plugin vide dedans afin de simplement faire une sorte de "dry run". Ou ajoutez quelques autres plugins, affichez-les, etc. En général, dans les cas d'utilisation standard, j'espère que tout est clair jusqu'à présent.
Voyons maintenant ce qui se passe en Java lorsque nous faisons de même:
private static void useAnalytics() { Analytics.INSTANCE.send(new Event("only_name_event", Collections.emptyMap())); final Map<String, Object> props = new HashMap<>(); props.put(USER_ID, 1235); props.put("my_custom_attr", true); Analytics.INSTANCE.send(new Event("custom_event", props)); boolean hasPlugins = Analytics.INSTANCE.getHasPlugins(); Analytics.INSTANCE.addPlugin(Analytics.INSTANCE.getEMPTY_PLUGIN());
L'agitation avec INSTANCE se précipite immédiatement dans mes yeux, ce qui est étiré, la présence de valeurs explicites pour le paramètre par défaut avec des attributs, des getters avec des noms stupides. Puisque nous, en général, nous sommes réunis ici pour transformer cela en quelque chose de similaire au fichier précédent avec Kotlin, passons à chaque instant que nous n'aimons pas et essayons de l'adapter d'une manière ou d'une autre.
Commençons par l'événement. Nous supprimons le paramètre Colletions.emptyMap () de la deuxième ligne et une erreur de compilation apparaît. Quelle en est la raison?
data class Event( val name: String, val context: Map<String, Any> = emptyMap() )
Notre constructeur a un paramètre par défaut auquel nous transmettons la valeur. Nous venons de Java à Kotlin, il est logique de supposer que la présence d'un paramètre par défaut génère deux constructeurs: un complet avec deux paramètres, et un partiel, pour lequel seul le nom peut être spécifié. De toute évidence, le compilateur ne le pense pas. Voyons pourquoi il pense que nous avons tort.
Notre principal outil pour analyser tous les rebondissements de la façon dont Kotlin se transforme en un bytecode JVM - Kotlin Bytecode Viewer. Dans Android Studio et IntelliJ IDEA, il se trouve dans le menu Tools - Kotlin - Show Kotlin Bytecode. Vous pouvez simplement appuyer sur Cmd + Maj + A et taper Kotlin Bytecode dans la barre de recherche.

Ici, étonnamment, nous voyons un bytecode de ce que notre classe Kotlin est en train de devenir. Je ne m'attends pas à ce que vous ayez une excellente connaissance du bytecode, et surtout, les développeurs IDE ne s'y attendent pas non plus. Par conséquent, ils ont créé un bouton Décompiler.
Après avoir cliqué dessus, nous voyons un code Java à peu près aussi bon:
public final class Event { @NotNull private final String name; @NotNull private final Map context; @NotNull public final String getName() { return this.name; } @NotNull public final Map getContext() { return this.context; } public Event(@NotNull String name, @NotNull Map context) { Intrinsics.checkParameterIsNotNull(name, "name"); Intrinsics.checkParameterIsNotNull(context, "context"); super(); this.name = name; this.context = context; }
Nous voyons nos champs, getters, le constructeur attendu avec deux paramètres nom et contexte, tout se passe bien. Et ci-dessous, nous voyons le deuxième constructeur, et le voici avec une signature inattendue: pas avec un paramètre, mais pour une raison quelconque avec quatre.
Ici, vous pouvez être gêné, mais vous pouvez grimper un peu plus profondément et fouiller autour. En commençant à comprendre, nous comprendrons que DefaultConstructorMarker est une classe privée de la bibliothèque standard de Kotlin, ajoutée ici afin qu'il n'y ait pas de conflits avec nos constructeurs écrits, car nous ne pouvons pas définir un paramètre de type DefaultConstructorMarker avec nos mains. Et la chose intéressante à propos de int var3 est le masque de bits des valeurs par défaut que nous devons utiliser. Dans ce cas, si le masque binaire correspond aux deux, nous savons que var2 n'est pas défini, nos attributs ne sont pas définis et nous utilisons la valeur par défaut.
Comment pouvons-nous régler la situation? Pour ce faire, il y a une annotation miraculeuse @JvmOverloads du package dont j'ai déjà parlé. Nous devons l'accrocher au constructeur.
data class Event @JvmOverloads constructor( val name: String, val context: Map<String, Any> = emptyMap() )
Et que va-t-elle faire? Passons au même outil. Maintenant, nous voyons notre constructeur complet, et le constructeur avec DefaultConstructorMarker, et, voilà, un constructeur avec un paramètre, qui est maintenant disponible à partir de Java:
@JvmOverloads public Event(@NotNull String name) { this.name, (Map)null, 2, (DefaultConstructorMarker)null); }
Et, comme vous pouvez le voir, il délègue tout le travail avec des paramètres par défaut à notre constructeur avec des masques de bits. Ainsi, nous ne produisons pas d'informations sur la valeur par défaut que nous devons y mettre, nous déléguons simplement tout dans un constructeur. Sympa. Nous vérifions ce que nous obtenons du côté Java: le compilateur est content et pas indigné.
Voyons ce que nous n'aimons pas ensuite. Nous n'aimons pas cette INSTANCE, qui dans IDEA est une callosité en violet. Je n'aime pas la couleur violette :)

Vérifions, à cause de ce qui se passe. Regardons à nouveau le bytecode.
Par exemple, nous mettons en évidence la fonction init et nous nous assurons que init est bien généré et non statique.

Autrement dit, quoi que l'on puisse dire, nous devons travailler avec une instance de cette classe et appeler ces méthodes dessus. Mais nous pouvons forcer la génération de toutes ces méthodes à être statiques. Il y a une merveilleuse annotation @JvmStatic pour cela. Ajoutons-le aux fonctions init et send et vérifions ce que le compilateur en pense maintenant.
Nous voyons que le mot-clé statique a été ajouté au public final init (), et nous nous sommes sauvés de travailler avec INSTANCE. Nous allons vérifier cela dans le code Java.
Le compilateur nous dit maintenant que nous invoquons la méthode statique à partir du contexte INSTANCE. Cela peut être corrigé: appuyez sur Alt + Entrée, sélectionnez "Code de nettoyage", et le tour est joué, INSTANCE disparaît, tout ressemble à peu près à Kotlin:
Analytics.send(new Event("only_name_event"));
Nous avons maintenant un schéma pour travailler avec des méthodes statiques. Ajoutez cette annotation partout où cela nous importe:

Et le commentaire: si les méthodes que nous avons sont évidemment les méthodes d'instance, alors, par exemple, avec des propriétés, tout n'est pas si évident. Les champs eux-mêmes (par exemple les plugins) sont générés sous forme statique. Mais les getters et setters fonctionnent comme des méthodes d'instance. Par conséquent, pour les propriétés, vous devez également ajouter cette annotation pour rendre les setters et les getters statiques. Par exemple, nous voyons la variable isInited, y ajoutons l'annotation @JvmStatic, et maintenant nous voyons dans Kotlin Bytecode Viewer que la méthode isInited () est devenue statique, tout va bien.
Passons maintenant au code Java, «pour le nettoyage», et tout ressemble à Kotlin, à l'exception des points-virgules et du mot nouveau - eh bien, vous ne vous en débarrasserez pas.
public static void useAnalytics() { Analytics.send(new Event("only_name_event")); final Map<String, Object> props = new HashMap<>(); props.put(USER_ID, 1235); props.put("my_custom_attr", true); Analytics.send(new Event("custom_event", props)); boolean hasPlugins = Analytics.getHasPlugins(); Analytics.addPlugin(Analytics.INSTANCE.getEMPTY_PLUGIN());
Étape suivante: nous voyons ce getter getHasPlugins dumblement nommé avec deux préfixes à la fois. Bien sûr, je ne suis pas un grand connaisseur de la langue anglaise, mais il me semble que quelque chose d'autre était impliqué ici. Pourquoi cela se produit-il?
Comme ils le savaient étroitement avec Kotlin, les noms de propriété des getters et setters sont générés selon les règles JavaBeans. Cela signifie que les getters seront généralement avec des préfixes get, les setters avec des préfixes set. Mais il y a une exception: si vous avez un champ booléen et que son nom a le préfixe is, le getter sera préfixé avec is. Cela peut être vu dans l'exemple du champ isInited ci-dessus.
Malheureusement, les champs booléens sont loin d'être toujours appelés via is. isPlugins ne satisferait pas tout à fait ce que nous voulons montrer sémantiquement par son nom. Comment on va?
Et ce n'est pas difficile pour nous, pour cela il y a notre propre annotation (comme vous l'avez déjà compris, je vais souvent le répéter aujourd'hui). L'annotation @JvmName vous permet de spécifier n'importe quel nom que nous voulons (naturellement pris en charge par Java). Ajoutez-le:
@JvmStatic val hasPlugins @JvmName("hasPlugin") get() = plugins.isNotEmpty()
Vérifions ce que nous avons obtenu en Java: la méthode getHasPlugins n'est plus là, mais hasPlugins est quelque chose en soi. Cela a résolu notre problème, encore une fois, avec une annotation. Maintenant, nous résolvons toutes les annotations!
Comme vous pouvez le voir, nous plaçons ici l'annotation directement sur le getter. Quelle en est la raison? Avec le fait que sous la propriété, il y a beaucoup de tout, et on ne sait pas à quoi s'applique @JvmName. Si vous transférez l'annotation à val hasPlugins lui-même, le compilateur ne comprendra pas à quoi l'appliquer.
Cependant, Kotlin a également la possibilité de spécifier où les annotations sont utilisées directement. Vous pouvez spécifier le getter cible, le fichier entier, le paramètre, le délégué, le champ, les propriétés, les fonctions d'extension du récepteur, le setter et le paramètre setter. Dans notre cas, getter est intéressant. Et si vous aimez cela, cela aura le même effet que lorsque nous avons suspendu l'annotation sur get:
@get:JvmName("hasPlugins") @JvmStatic val hasPlugins get() = plugins.isNotEmpty()
En conséquence, si vous n'avez pas de getter personnalisé, vous pouvez le joindre directement à votre propriété et tout ira bien.
Le point suivant qui nous déroute un peu est "Analytics.INSTANCE.getEMPTY_PLUGIN ()". Ici, la question n'est même plus en anglais, mais simplement: POURQUOI? La réponse est à peu près la même, mais d'abord une petite introduction.
Pour rendre un champ constant, vous avez deux façons. Si vous définissez une constante en tant que type primitif ou en tant que chaîne, et également à l'intérieur de l'objet, vous pouvez utiliser le mot clé const, puis les getter-setters et autres ne seront pas générés. Ce sera une constante ordinaire - statique finale privée - et elle sera insérée, c'est-à-dire une chose Java absolument ordinaire.
Mais si vous voulez créer une constante à partir d'un objet différent de la chaîne, vous ne pourrez pas utiliser le mot const pour cela. Ici, nous avons val EMPTY_PLUGIN = EmptyPlugin (), selon lui, ce terrible getter a évidemment été généré. Nous pouvons renommer @JvmName avec une annotation, supprimer ce préfixe get, mais cela reste une méthode - avec des crochets. Ainsi, les anciennes solutions ne fonctionneront pas, nous recherchons de nouvelles.
Et voici pour cela l'annotation @JvmField, qui dit: "Je ne veux pas de getters ici, je ne veux pas de setters, faites-moi un champ." Mettez-le devant val EMPTY_PLUGIN et vérifiez que tout est vrai.
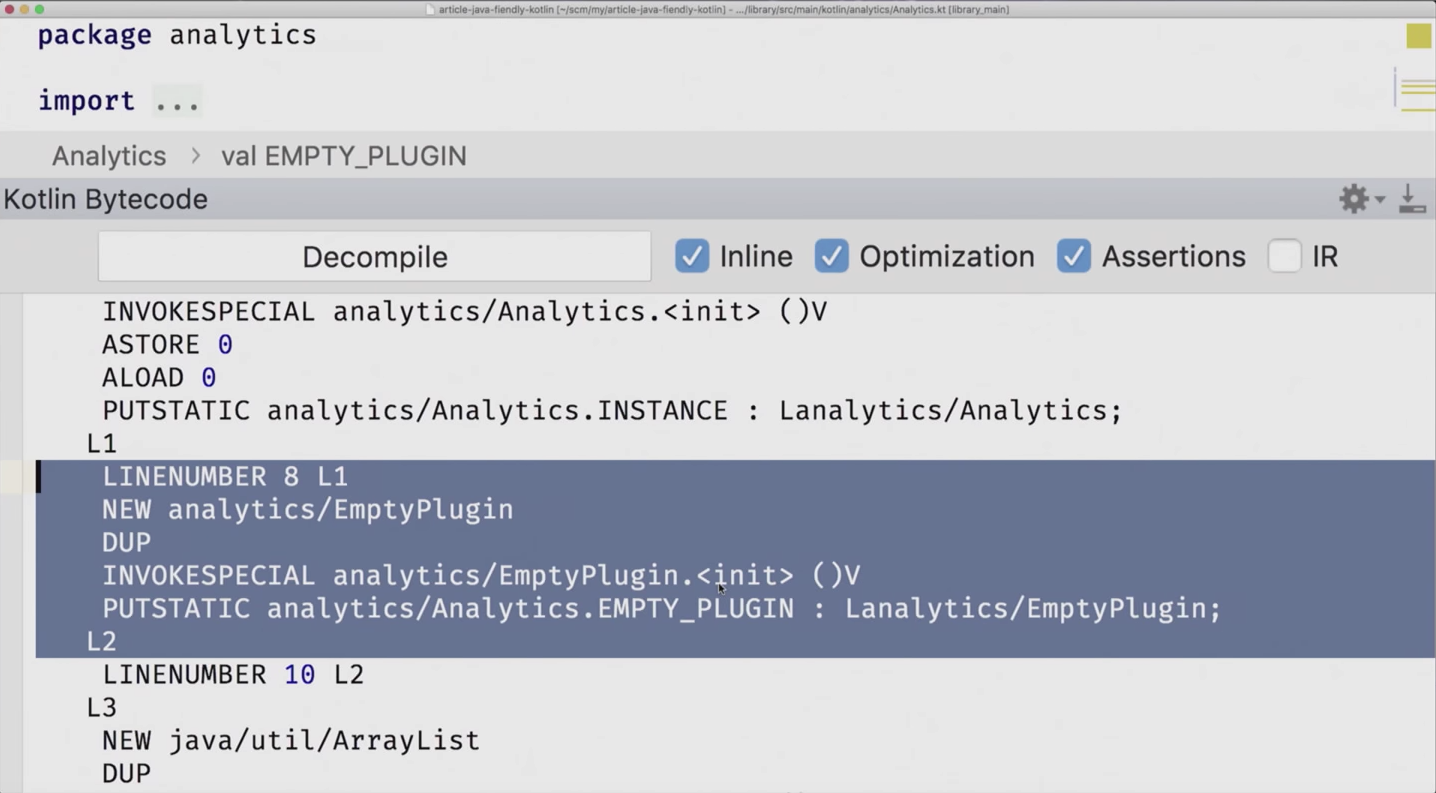
Kotlin Bytecode Viewer affiche la pièce en surbrillance sur laquelle vous vous trouvez actuellement dans le fichier. Nous sommes maintenant sur EMPTY_PLUGIN, et vous voyez qu'ici une sorte d'initialisation est écrite dans le constructeur. Le fait est que le getter n'est plus là et que l'accès n'y est que pour l'enregistrement. Et si vous cliquez sur décompiler, nous voyons que «final statique statique EmptyPlugin EMPTY_PLUGIN» est apparu, c'est exactement ce que nous avons réalisé. Sympa. Nous vérifions que tout plaît à tout le monde, en particulier au compilateur. La chose la plus importante que vous devez apaiser est le compilateur.
Génériques
Prenons une pause dans le code et regardons les génériques. C'est un sujet assez chaud. Ou glissante, qui n'aime plus ça. Java a ses propres complexités, mais Kotlin est différent. Tout d'abord, nous nous préoccupons de la variation. Qu'est ce que c'est
La variabilité est un moyen de transférer des informations sur une hiérarchie de types des types de base aux dérivés, par exemple, aux conteneurs ou aux génériques. Nous avons ici les classes Animal et Dog avec une connexion très évidente: Dog est un sous-type, Animal est un sous-type, la flèche vient du sous-type.

Et quel lien leurs dérivés auront-ils? Regardons quelques cas.
Le premier est Iterator. Pour déterminer ce qu'est un sous-type et ce qui est un sous-type, nous serons guidés par la règle de substitution Barbara Liskov. Il peut être formulé comme suit: "le sous-type ne devrait pas exiger plus et ne pas fournir moins".
Dans notre situation, la seule chose qu'Iterator fait est de nous donner des objets dactylographiés, par exemple, Animal. Si nous acceptons Iterator quelque part, nous pouvons bien y mettre Iterator et obtenir Animal de la méthode next (), car le chien est aussi Animal. Nous fournissons non pas moins, mais plus, car un chien est un sous-type.

Je le répète: nous ne lisons que sur ce type, donc la relation entre le type et le sous-type est préservée ici. Et ces types sont appelés covariants.
Un autre cas: l'action. Action est une fonction qui ne renvoie rien, prend un paramètre, et nous écrivons seulement à Action, c'est-à-dire qu'elle nous prend un chien ou un animal.

Ainsi, ici, nous ne fournissons plus, mais demandons, et nous ne devons plus exiger. Cela signifie que notre dépendance évolue. "Pas plus" nous avons Animal (Animal moins qu'un chien). Et ces types sont appelés contravariants.
Il y a un troisième cas - par exemple, ArrayList, à partir duquel nous lisons et écrivons. Par conséquent, dans ce cas, nous violons l'une des règles, nous en demandons plus pour un dossier (un chien, pas un animal). Ces types ne sont pas liés en aucune façon, et ils sont appelés invariants.

Ainsi, en Java, quand il a été conçu avant la version 1.5 (où les génériques sont apparus), par défaut, ils ont fait des tableaux covariants. Cela signifie que vous pouvez affecter un tableau de chaînes au tableau d'objets, puis le transmettre quelque part à la méthode où le tableau d'objets est nécessaire, et essayer d'y pousser l'objet, bien qu'il s'agisse d'un tableau de chaînes. Tout vous reviendra.
Ayant appris d'une expérience amère que cela ne peut pas être fait, lors de la conception de génériques, ils ont décidé "nous rendrons les collections invariantes, nous ne ferons rien avec elles".
Et à la fin, il s'avère que dans une chose aussi apparemment évidente, tout devrait être ok, mais en fait pas ok:
Mais nous devons en quelque sorte déterminer ce que, après tout, nous pouvons: si nous ne lisons que cette feuille, pourquoi ne pas permettre de transférer la liste des chiens ici? Par conséquent, il est possible de caractériser avec un caractère générique le type de variation que ce type aura:
List<Dog> dogs = new ArrayList<>(); List<? extends Animal> animals = dogs;
Comme vous pouvez le voir, cette variation est indiquée sur le lieu d'utilisation, où nous affectons les chiens. Par conséquent, cela s'appelle la variance du site d'utilisation.
Quels sont les inconvénients de cela? Le côté négatif est que vous devez spécifier ces caractères génériques effrayants partout où vous utilisez votre API, et tout cela est très fructueux dans le code. Mais dans Kotlin pour une raison quelconque, une telle chose fonctionne hors de la boîte, et vous n'avez rien à spécifier:
val dogs: List<Dog> = ArrayList() val animals: List<Animal> = dogs
Quelle en est la raison? Avec le fait que les draps sont réellement différents. La liste en Java signifie l'écriture, tandis qu'en Kotlin, elle est en lecture seule, ce qui n'implique pas. Par conséquent, en principe, nous pouvons immédiatement dire que nous ne faisons que lire d'ici, nous pouvons donc être covariants. Et cela est défini précisément dans la déclaration de type avec le mot clé out remplaçant le caractère générique:
interface List<out E> : Collection<E>
C'est ce qu'on appelle la variance du site de déclaration. Ainsi, nous avons tout indiqué en un seul endroit, et là où nous l'utilisons, nous ne touchons plus à ce sujet. Et c'est nishtyak.
Retour au code
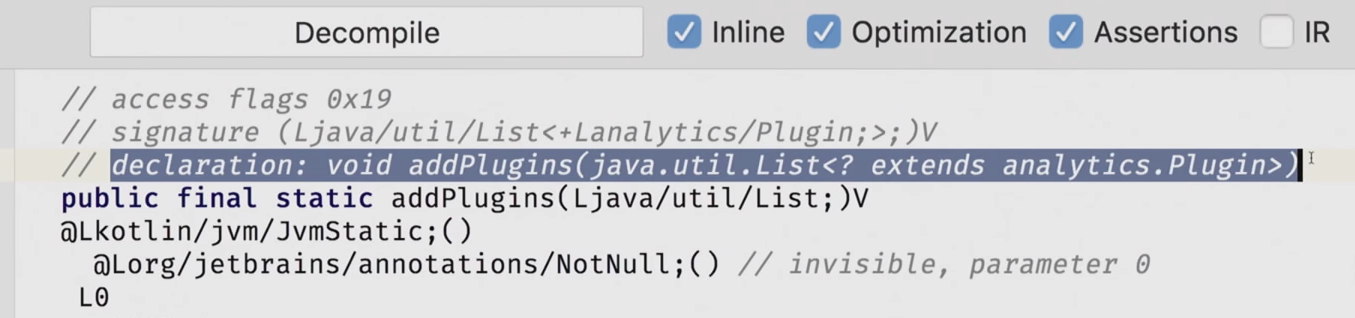
Revenons à nos profondeurs. Ici, nous avons la méthode addPlugins, elle prend une liste:
@JvmStatic fun addPlugins (plugs: List<Plugin>) { plugs.forEach { addPlugin(it) } } , , List<EmptyPlugin>, , : <source lang="java"> final List<EmptyPlugin> pluginsToSet = Arrays.asList(new LoggerPlugin("Alog"), new SegmentPlugin());
Étant donné que List in Kotlin est covariant, nous pouvons facilement transmettre la liste des héritiers du plugin ici. Tout fonctionnera, le compilateur ne s'en soucie pas. Mais étant donné que nous avons une variance de site de déclaration où nous avons tout spécifié, nous ne pouvons pas contrôler la connexion avec Java au stade de l'utilisation. Mais que se passe-t-il si nous voulons vraiment une feuille de plugin là-bas, nous ne voulons pas d'héritiers là-bas? Il n'y a pas de modificateurs pour cela, mais quoi? C'est vrai, il y a une annotation. Et l'annotation s'appelle @JvmSuppressWildcards, c'est-à-dire que par défaut, nous pensons qu'il s'agit d'un type avec caractère générique, le type est covariant.
@JvmStatic fun addPlugins(plugs: List<@JvmSuppressWildcards Plugin>) { plugs.forEach { addPlugin(it) } }
En parlant de SuppressWildcards, nous supprimons toutes ces questions, et notre signature change en fait. Encore plus que cela, je vais vous montrer à quoi tout ressemble en bytecode:

Je vais supprimer l'annotation du code pour l'instant. Voici notre méthode. Vous savez probablement que l'effacement de type existe. Et dans votre bytecode, il n'y a aucune information sur le type de questions qu'il y avait, eh bien, les génériques en général. Mais le compilateur suit cela et le signe dans les commentaires du bytecode: et c'est le type avec la question.
Maintenant, nous insérons à nouveau l'annotation et voyons que c'est notre type sans remettre en question.

Maintenant, notre code précédent arrêtera de compiler précisément parce que nous avons coupé les caractères génériques. Vous pouvez voir par vous-même.
Nous avons fait des types covariants. Maintenant, l'inverse est vrai.
Nous pensons que List a une question.
Il est évident de supposer que lorsque cette feuille reviendra de getPlugins, ce sera aussi avec une question. Qu'est-ce que cela signifie? Cela signifie que nous ne pourrons pas y écrire, car le type est covariant et non contravariant. Jetons un coup d'œil à ce qui se passe en Java. final List<Plugin> plugins = Analytics.getPlugins(); displayPlugins(plugins); Analytics.getPlugins().add(new EmptyPlugin());
Personne n'est scandalisé que dans la dernière ligne, nous écrivions quelque chose, ce qui signifie que quelqu'un ici a tort. Si nous regardons le bytecode, nous serons convaincus de l'exactitude de nos soupçons. Nous n'avons pas raccroché d'annotations, et le type pour une raison quelconque sans poser de question.La surprise est basée sur cela. Kotlin se postule comme un langage pragmatique, donc quand tout cela a été conçu, des statistiques ont été collectées, car les caractères génériques sont généralement utilisés en Java. Il s'est avéré que l'entrée est le plus souvent autorisée la variance, c'est-à-dire rendre les types covariants. Eh bien, c'est utile partout où nous voulons qu'une liste puisse y mettre une feuille de n'importe quel héritier du plugin. Et ici, là où nous revenons, au contraire, nous voulons avoir des types purs: comme il y a une fiche Plugin, elle sera retournée.. , , usecase, - , .
Mais dans ce cas, nous voyons qu'une telle situation n'est pas pour nous, car nous ne voulons pas que quelque chose y soit enregistré. Et nous ne voulons pas non plus que cela soit possible à partir de Java. Dans Kotlin, ici List est un type en lecture seule, et nous ne pouvons rien écrire là-bas, mais le client de notre bibliothèque est venu de Java et a tout bourré là-dedans - qui voudrait? Par conséquent, nous allons forcer cette méthode à renvoyer une liste avec un caractère générique. Et nous pouvons expliquer clairement comment. En ajoutant l'annotation @JvmWildcard, nous disons: générez un type avec une question pour nous, tout est assez simple. Voyons maintenant ce qui se passe en Java à cet endroit. Java dit "que faites-vous?": Ici, nous pouvons même lancer dans la liste correcte <? étend le plugin>, mais elle dit toujours "que faites-vous?" Et, en principe, cette situation nous convient jusqu'à présent. Mais il y a un script kiddie qui dit: "J'ai vu la source, c'est une source ouverte, je sais qu'il y a une ArrayList, et je vais vous pirater." Et tout fonctionnera, car il y a vraiment une ArrayList et il sait ce qui peut y être écrit.
Ici, nous pouvons même lancer dans la liste correcte <? étend le plugin>, mais elle dit toujours "que faites-vous?" Et, en principe, cette situation nous convient jusqu'à présent. Mais il y a un script kiddie qui dit: "J'ai vu la source, c'est une source ouverte, je sais qu'il y a une ArrayList, et je vais vous pirater." Et tout fonctionnera, car il y a vraiment une ArrayList et il sait ce qui peut y être écrit. ((ArrayList<Plugin>) Analytics.getPlugins()).add(new EmptyPlugin());
Par conséquent, bien sûr, accrochez des annotations intéressantes, mais vous devez toujours utiliser la copie défensive, qui est connue depuis longtemps. Soryan, nulle part sans lui, si vous voulez que les script kiddies ne vous dérangent pas. @JvmStatic fun getPlugins(): List<@JvmWildcard Plugin> = plugin.toImmutableList()
, @JvmSuppressWildcard , , , , .
, . , : .
Java. , :
@Override public void send(@NotNull Event event) throws IOException
:
interface Plugin { fun init() fun send(event: Event)
À Kotlin, il n'y a pas d'exception vérifiée. Et nous disons dans la documentation: vous pouvez jeter ici. Eh bien, nous jetons, jetons, jetons. Mais Java n'aime pas pour une raison quelconque. Dit: "mais Throws pour une raison quelconque n'est pas dans votre signature, monsieur": Mais comment puis-je ajouter quelque chose ici, ici Kotlin? Eh bien, vous connaissez la réponse ...Il y a une annotation @Throws qui fait exactement cela. Il modifie la partie des lancers dans la signature de la méthode. Nous disons que nous pouvons lancer une IOExeption ici:
Mais comment puis-je ajouter quelque chose ici, ici Kotlin? Eh bien, vous connaissez la réponse ...Il y a une annotation @Throws qui fait exactement cela. Il modifie la partie des lancers dans la signature de la méthode. Nous disons que nous pouvons lancer une IOExeption ici: open class EmptyPlugin : Plugin { @Throws(IOException::class) override fun send(event: Event) {}
Et ajoutez cette chose en même temps à l'interface: interface Plugin { fun init() @Throws(IOException::class) fun send(event: Event)
Et maintenant quoi? Maintenant, notre plugin, écrit en Java, où nous avons des informations sur l'exception, est satisfait de tout. Tout fonctionne, compile. En principe, c'est plus ou moins tout avec des annotations, mais il y a deux autres nuances sur la façon d'utiliser @JvmName. Un intéressant.Nous avons ajouté toutes ces annotations pour rendre Java magnifique. Et ici ... package util fun List<Int>.printReversedSum() { println(this.foldRight(0) { it, acc -> it + acc }) } @JvmName("printReversedConcatenation") fun List<String>.printReversedSum() { println(this.foldRight(StringBuilder()) { it, acc -> acc.append(it) }) }
Supposons qu'en Java, nous ne nous soucions pas ici, supprimez l'annotation. Erreurs, l'EDI affiche maintenant une erreur dans les deux fonctions. Selon vous, quelle en est la raison? Oui, sans annotation, ils sont générés avec le même nom, mais ici il est écrit que l'un est sur la liste, l'autre sur la liste. À droite, tapez effacement. On peut même vérifier ce cas: Vous savez déjà, si je comprends bien, que toutes les fonctions de niveau supérieur sont générées dans un contexte statique. Et sans cette annotation, nous allons essayer de générer printReversedSum à partir de List, et en dessous d'un autre également à partir de List. Parce que le compilateur Kotlin connaît les génériques, mais pas le bytecode Java. Par conséquent, c'est le seul cas où les annotations du package kotlin.jvm sont nécessaires non pas pour que Java soit bon et pratique, mais pour que votre Kotlin compile. Nous définissons un nouveau nom - une fois que nous travaillons avec des chaînes, puis nous utilisons la concaténation - et tout fonctionne bien, maintenant tout se compile.Et le deuxième cas d'utilisation. C'est lié à cela. Nous avons une fonction d'extension inverse.
Vous savez déjà, si je comprends bien, que toutes les fonctions de niveau supérieur sont générées dans un contexte statique. Et sans cette annotation, nous allons essayer de générer printReversedSum à partir de List, et en dessous d'un autre également à partir de List. Parce que le compilateur Kotlin connaît les génériques, mais pas le bytecode Java. Par conséquent, c'est le seul cas où les annotations du package kotlin.jvm sont nécessaires non pas pour que Java soit bon et pratique, mais pour que votre Kotlin compile. Nous définissons un nouveau nom - une fois que nous travaillons avec des chaînes, puis nous utilisons la concaténation - et tout fonctionne bien, maintenant tout se compile.Et le deuxième cas d'utilisation. C'est lié à cela. Nous avons une fonction d'extension inverse. inline fun String.reverse() = StringBuilder(this).reverse().toString() inline fun <reified T> reversedClassName() = T::class.java.simpleName.reverse() inline fun <T> Iterable<T>.forEachReversed(action: (T) -> Unit) { for (element in this.reversed()) action(element) }
Ce reverse compile dans une méthode de classe statique appelée ReverserKt. private static void useUtils() { System.out.println(ReverserKt.reverse("Test")); SumsKt.printReversedSum(asList(1, 2, 3, 4, 5)); SumsKt.printReversedConcatenation(asList("1", "2", "3", "4", "5")); }
Je pense que ce n'est pas nouveau pour vous. La nuance est que les personnes utilisant notre bibliothèque en Java peuvent suspecter que quelque chose ne va pas. Nous avons divulgué les détails de la mise en œuvre de notre bibliothèque du côté de l'utilisateur et voulons couvrir nos traces. Comment pouvons-nous faire cela? Comme déjà clair, l'annotation @JvmName, dont je parle maintenant, mais il y a une mise en garde.Pour commencer, nous lui donnerons le nom que nous voulons, nous ne graverons pas, et il est important de dire que nous utilisons cette annotation sur le fichier, nous devons renommer le fichier. @file:Suppress("NOTHING_TO_INLINE") @file:JvmName("ReverserUtils")
Java ReverserKt, , ReverserUtils . « 2.1» — , top-level , . , , sums.kt SumsKt, , reversing ReverserUtils. @JvmName, «ReverserUtils», , , , .
Bien que l'environnement ne vous avertisse pas à l'avance, lorsque vous essayez de compiler, ils nous diront que "vous voulez générer deux classes dans le même package avec le même nom, ata". Que faut-il faire? Ajoutez la dernière annotation @JvmMultifileClass dans ce package, qui indique que le contenu de plusieurs fichiers se transformera en une seule classe, c'est-à-dire qu'il n'y aura qu'une seule façade pour cela.Dans les deux cas, nous ajoutons "@file: JvmMultifileClass", et vous pouvez remplacer SumsKt par ReverserUtils, tout le monde est content - croyez-moi. Avec des annotations faites!Nous avons parlé avec vous de ce package, de toutes les annotations. En principe, il est déjà clair d'après leurs noms à quoi chacun est utilisé. Il y a des cas délicats lorsque vous avez besoin, par exemple, @JvmName est même facile à utiliser dans Kotlin.Spécifique à Kotlin
Mais ce n'est probablement pas tout ce que vous aimeriez savoir. Il est également important de noter comment travailler avec des choses spécifiques à Kotlin.Par exemple, les fonctions en ligne. Ils sont en ligne dans Kotlin et, semble-t-il, seront-ils même accessibles depuis Java en bytecode? Il s'avère qu'ils le feront, tout ira bien et les méthodes sont réellement disponibles pour Java. Bien que si vous écrivez, par exemple, un projet Kotlin uniquement, cela n'affecte pas assez bien votre limite de nombre de dex. Parce qu'à Kotlin, ils ne sont pas nécessaires, mais en réalité ils seront en bytecode.Ensuite, notez les paramètres de type Reified. Ces paramètres sont spécifiques à Kotlin, ils ne sont disponibles que pour les fonctions en ligne et vous permettent d'inverser les hacks qui ne sont pas disponibles en Java avec réflexion. Comme il s'agit uniquement de Kotlin, il n'est disponible que pour Kotlin et, en Java, vous ne pouvez malheureusement pas utiliser de fonctions avec réifié.java.lang.Class. Si nous voulons réfléchir un peu et que notre bibliothèque est également pour Java, elle doit être prise en charge. Voyons un exemple. Nous avons un tel «notre retrofit», rapidement écrit sur mon genou (je ne comprends pas ce que les gars ont écrit depuis si longtemps): class Retrofit private constructor( val baseUrl: String, val client: Client ) { fun <T : Any> create(service: Class<T>): T {...} fun <T : Any> create(service: KClass<T>): T { return create(service.java) } }
Il y a une méthode qui fonctionne avec la classe Java, il y a une méthode qui fonctionne avec Kotlin KClass, vous n'avez pas besoin de faire deux implémentations différentes, vous pouvez utiliser des propriétés d'extension qui obtiennent Class de KClass, KClass de Class (cela s'appelle Kotlin, en principe évidemment).Tout cela fonctionnera, mais c'est un peu non idiomatique. Dans le code Kotlin, vous ne passez pas KClass, vous écrivez en utilisant des types réifiés, il est donc préférable de refaire la méthode comme ceci: inline fun <reified T : Any> create(): T { return create(T::class.java.java)
. Kotlin , .
val api = retrofit.create(Api::class) val api = retrofit.create<Api>() , ::class . Reified-, -.
Unit. Unit, , void Java, . . , . - Scala, Scala , - , , , void.
Mais à Kotlin, ce n'est pas le cas. Kotlin n'a que 22 interfaces qui acceptent un ensemble différent de paramètres et renvoient quelque chose. Ainsi, le lambda qui retourne Unit retournera non nul, mais Unit. Et cela impose ses limites. À quoi ressemble le lambda qui retourne Unit? Maintenant, regardez-la dans ce fragment de code. Apprenez à vous connaître. inline fun <T> Iterable<T>.forEachReversed(action: (T) -> Unit) { for (element in this.reversed()) action(element) }
Utilisation de Kotlin: tout va bien, nous utilisons même une référence de méthode, si nous le pouvons, et elle se lit parfaitement, nos yeux ne sont pas calleux. private fun useMisc() { listOf(1, 2, 3, 4).forEachReversed(::println) println(reversedClassName<String>()) }
Que se passe-t-il en Java? En Java, le canoë suivant se produit: private static void useMisc() { final List<Integer> list = asList(1, 2, 3, 4); ReverserUtils.forEachReversed(list, integer -> { System.out.println(integer); return Unit.INSTANCE; });
En raison du fait que nous devons retourner quelque chose ici. C'est comme un Vide avec une majuscule, on ne peut pas simplement prendre et marquer dessus. Nous ne pouvons pas utiliser la méthode de référence ici, qui retourne nulle, malheureusement. Et c'est probablement la première chose qui cogne vraiment les yeux après toutes nos manipulations avec des annotations. Malheureusement, vous devrez renvoyer l'instance d'unité d'ici. Vous pouvez annuler, de toute façon, personne n'en a besoin. Je veux dire, personne n'a besoin d'une valeur de retour.Allons plus loin: Typealiases est aussi une chose assez spécifique, ce sont juste des alias ou des synonymes, ils ne sont disponibles que chez Kotlin, et en Java, malheureusement, vous utiliserez ce qui se trouve sous ces alias. Soit c'est une corbeille de génériques trois fois fermés, soit une sorte de classes imbriquées. Les programmeurs Java ont l'habitude de vivre avec cela.Maintenant, pour la partie intéressante: la visibilité. Ou plutôt, une visibilité interne. Vous savez probablement que dans Kotlin il n'y a pas de paquet privé, si vous écrivez sans aucun modificateur, il sera public. Mais il y a interne. Interne est une chose tellement délicate que nous allons même l'examiner maintenant. Dans Retrofit, nous avons une méthode de validation interne. internal fun validate(): Retrofit { println("!!!!!! internal fun validate() was called !!!!!!") return this }
Il ne peut pas être appelé depuis Kotlin, et cela est compréhensible. Que se passe-t-il avec Java? Pouvons-nous appeler valider? Ce n'est peut-être pas un secret pour vous que les transformations internes deviennent publiques. Si vous ne me croyez pas, croyez la visionneuse de bytecode Kotlin. C'est vraiment public, mais avec une signature si terrible qui laisse entendre à une personne qu'il n'a probablement pas été entièrement conçu qu'un tel fluage rampe dans l'API publique. Si quelqu'un a formaté 80 caractères, cette méthode peut même ne pas tenir sur une seule ligne.En Java, nous avons maintenant ceci:
C'est vraiment public, mais avec une signature si terrible qui laisse entendre à une personne qu'il n'a probablement pas été entièrement conçu qu'un tel fluage rampe dans l'API publique. Si quelqu'un a formaté 80 caractères, cette méthode peut même ne pas tenir sur une seule ligne.En Java, nous avons maintenant ceci: final Api api = retrofit .validate$production_sources_for_module_library_main() .create(Api.class); api.sendMessage("Hello from Java"); }
Essayons de compiler ce cas. Donc, au moins ça ne compilera pas, pas mal déjà. Nous pourrions nous arrêter ici, mais laissez-moi vous expliquer cela. Et si j'aime ça? final Api api = retrofit .validate$library() .create(Api.class); api.sendMessage("Hello from Java"); }
Compile ensuite. Et la question se pose: "Pourquoi?" Que puis-je dire ... MAGIQUE!Par conséquent, il est très important que si vous collez quelque chose de critique en interne, cela soit mauvais car cela fuira dans votre API publique. Et si le script kiddie est armé d'un Kotlin Bytecode Viewer, alors ce sera mauvais. N'utilisez rien de très important dans les méthodes à visibilité interne.Si vous voulez plus de joie, je recommande deux choses. Pour le rendre plus confortable pour travailler avec le bytecode et le lire, je recommande un rapport de Zhenya Vartanov, il y a une vidéo gratuite , malgré le fait que cela provienne de l'événement SkillsMatter. Très cool.Et une assez vieille sériede trois articles de Christophe Bales sur les différentes fonctionnalités de Kotlin. Tout est cool écrit là-bas, quelque chose n'a plus d'importance maintenant, mais en général c'est très intelligible. Tout de même avec le visualiseur de bytecode Kotlin et tout ça.Je vous remercie!
Si vous avez aimé le rapport, faites attention: les 8 et 9 décembre, le nouveau Mobius se tiendra à Moscou , et il y aura également beaucoup de choses intéressantes. Des informations déjà connues sur le programme sont sur le site , et des billets peuvent y être achetés.