Très souvent, on nous demande pourquoi nous n'organisons pas de concours pour les scientifiques des données. Le fait est que, par expérience, nous savons que les solutions qu'ils contiennent ne s'appliquent pas du tout à la prod. Oui, et pour embaucher ceux qui seront dans les premières places, cela n'a pas toujours de sens.
De telles compétitions sont souvent gagnées à l'aide de ce que l'on appelle l'empilement chinois, lorsque tous les algorithmes et valeurs d'hyperparamètres possibles sont pris de manière combinatoire et que les modèles résultants utilisent un signal les uns des autres à plusieurs niveaux. Les satellites habituels de ces solutions sont la complexité, l'instabilité, les difficultés de débogage et de support, la très forte consommation de ressources en formation et prévision, la nécessité d'une supervision humaine attentive à chaque cycle de formation répétée des modèles. Il est logique de le faire uniquement dans les compétitions - pour dix millièmes dans les métriques locales et les positions au classement.
Mais nous avons essayé
Il y a environ un an, nous avons décidé d'essayer d'utiliser l'empilage en production. On sait que les modèles linéaires permettent d'extraire un signal utile à partir de textes représentés comme un sac de mots et vectorisés avec tf-idf, malgré la grande dimension de tels vecteurs. Notre système a déjà effectué une telle vectorisation, il n'a donc pas été très difficile pour nous de combiner des vecteurs pour des CV, des postes vacants et, sur la base de ceux-ci, d'enseigner la régression logistique afin qu'il prédit la probabilité qu'un candidat clique avec un CV donné pour un poste vacant donné.
Cette prévision est ensuite utilisée par les modèles principaux comme une caractéristique supplémentaire, car le modèle considère un méta-attribut. La beauté est que même avec ROC AUC 0.7, le signal de ces modèles de méta-attribut est utile. La mise en œuvre a donné environ 2 000 réponses par jour. Et le plus important - nous avons réalisé que nous pouvons aller de l'avant.
Le modèle linéaire ne prend pas en compte les interactions non linéaires entre les entités. Par exemple, il ne peut pas tenir compte du fait que si le curriculum vitae contient «C» et que l'offre d'emploi contient «programmeur système», alors la probabilité d'une réponse devient très élevée. En plus de la vacance et du CV, en plus du texte, il existe de nombreux champs numériques et catégoriques, et dans le CV, le texte est divisé en plusieurs blocs distincts. Par conséquent, nous avons décidé d'ajouter une extension quadratique des fonctionnalités pour les modèles linéaires et de trier toutes les combinaisons possibles de vecteurs tf-idf à partir des champs et des blocs.
Nous avons essayé des méta-signes qui prédisent la probabilité d'une réponse dans diverses conditions:
- dans la description de poste, il y a un ensemble donné de termes, catégories;
- Dans le champ de texte du poste vacant et le champ de texte du CV, un certain ensemble de termes est rencontré;
- dans le champ de texte de la vacance il y avait un certain ensemble de termes qui ne se rencontraient pas dans le champ de texte du curriculum vitae;
- certains termes sont apparus dans le poste vacant, la valeur de la catégorie définie a été respectée dans le curriculum vitae;
- dans les postes vacants et les curriculum vitae, une paire donnée de valeurs de catégorie s'est rencontrée.
Ensuite, avec l'aide de la sélection des fonctionnalités, ils ont sélectionné plusieurs dizaines de méta-attributs qui ont donné un effet maximal, effectué des tests A / B et les ont mis en production.
En conséquence, nous avons reçu plus de 23 000 nouvelles réponses par jour. Certains des attributs sont entrés dans les attributs supérieurs en force.
Par exemple, dans un système de recommandation, les principaux attributs sont
dans un modèle de régression logistique filtrant les CV appropriés:- région géographique à partir du curriculum vitae;
- espace professionnel du CV;
- la différence entre les descriptions de travail et l'expérience de travail récente;
- différence de régions géographiques dans les postes vacants et les curriculum vitae;
- la différence entre le titre du poste vacant et le titre du curriculum vitae;
- la différence entre les spécialisations en postes vacants et en curriculum vitae;
- la probabilité que le candidat avec un certain salaire dans un curriculum vitae clique sur un poste vacant avec un certain salaire (méta-signe sur une régression logistique);
- la probabilité qu'une personne avec un certain nom de curriculum vitae clique sur des postes vacants avec une certaine expérience de travail (méta-signe sur la régression logistique);
dans un modèle XGBoost filtrant les CV pertinents:- Dans quelle mesure les postes vacants et les curriculum vitae sont-ils similaires?
- la différence entre le nom du poste vacant et le nom du curriculum vitae et tous les postes dans l'expérience du curriculum vitae, en tenant compte des interactions textuelles;
- la différence entre le titre du poste vacant et le titre du CV, en tenant compte des interactions textuelles;
- la différence entre le nom du poste vacant et le nom du curriculum vitae et tous les postes dans l'expérience du curriculum vitae, sans tenir compte des interactions textuelles;
- la probabilité qu'un candidat possédant l'expérience de travail spécifiée accède à un poste vacant portant ce nom (méta-signe sur la régression logistique);
- la différence entre la description de travail et l'expérience de travail précédente dans le curriculum vitae;
- combien le poste vacant et le curriculum vitae diffèrent dans le texte;
- la différence entre la description de travail et l'expérience de travail précédente dans le curriculum vitae;
- la probabilité qu'une personne d'un certain sexe réponde à un poste vacant portant un certain nom (un méta-signe sur la régression logistique).
dans le modèle de classement sur XGBoost:- la probabilité d'une réponse par des termes qui sont présents dans le nom du poste vacant et ne sont pas dans le titre et la position du curriculum vitae (méta-signe sur la régression logistique);
- correspondre à la région à partir de la vacance et reprendre
- la probabilité d'une réponse par des termes qui sont présents dans le poste vacant et ne sont pas dans le curriculum vitae (méta-signe sur la régression logistique);
- attractivité prévue de la vacance pour l'utilisateur (méta-tag sur ALS);
- la probabilité d'une réponse par les termes qui sont présents dans l'offre d'emploi et reprendre (méta-signe sur la régression logistique);
- la distance entre le nom du poste vacant et le titre + poste du CV, où les termes sont pondérés par les actions de l'utilisateur (interaction);
- distance entre les spécialisations de l'offre d'emploi et du curriculum vitae;
- la distance entre le titre du poste vacant et le nom du CV, où les termes sont pondérés par les actions des utilisateurs (interaction);
- la probabilité d'une réponse sur l'interaction de tf-idf à partir d'un poste vacant et la spécialisation à partir d'un curriculum vitae (méta-signe sur la régression logistique);
- distance entre les offres d'emploi et les textes de curriculum vitae;
- DSSM par le nom du poste vacant et le nom du CV (méta-attribut sur le réseau neuronal).
Un bon résultat montre que dans cette direction, vous pouvez toujours extraire un certain nombre de réponses et d'invitations par jour aux mêmes coûts marketing.
Par exemple, il est connu qu'avec un grand nombre de signes, la régression logistique augmente la probabilité de recyclage.
Utilisons pour les textes des CV et postes vacants le vectoriseur tf-idf avec un dictionnaire de 10 mille mots et phrases. Ensuite, dans le cas d'une expansion quadratique de notre régression logistique, il y aura 2 * 10 000 + 10 000 m² de poids. Il est clair qu'avec une telle rareté, même les cas individuels peuvent affecter de manière significative chaque poids individuel "dans le CV, il y avait un mot rare tel ou tel - dans une vacance telle ou telle, l'utilisateur a cliqué".
Par conséquent, nous essayons maintenant de créer des méta-signes sur la régression logistique, dans lesquels les coefficients d'expansion quadratiques sont compressés à l'aide de machines de factorisation. Nos poids de 10 000 m² sont représentés comme une matrice de vecteurs latents d'une dimension de, par exemple, 10 000 x 150 (où nous avons choisi la dimension d'un vecteur latent de 150). Dans le même temps, les cas individuels pendant la compression cessent de jouer un grand rôle, et le modèle commence à mieux prendre en compte des modèles plus généraux, plutôt que de se souvenir de cas spécifiques.
Nous utilisons également des méta-attributs sur les réseaux de neurones DSSM sur lesquels nous avons déjà
écrit et sur la SLA, sur lesquels nous avons également
écrit , mais de manière simplifiée. Au total, l'introduction de méta-attributs à ce jour nous a donné (ainsi qu'à nos clients) plus de 44 000 réponses supplémentaires (pistes) à des postes vacants par jour.
Par conséquent, le schéma d'empilement de modèles simplifié dans les recommandations de travaux pour les CV ressemble maintenant à ceci:
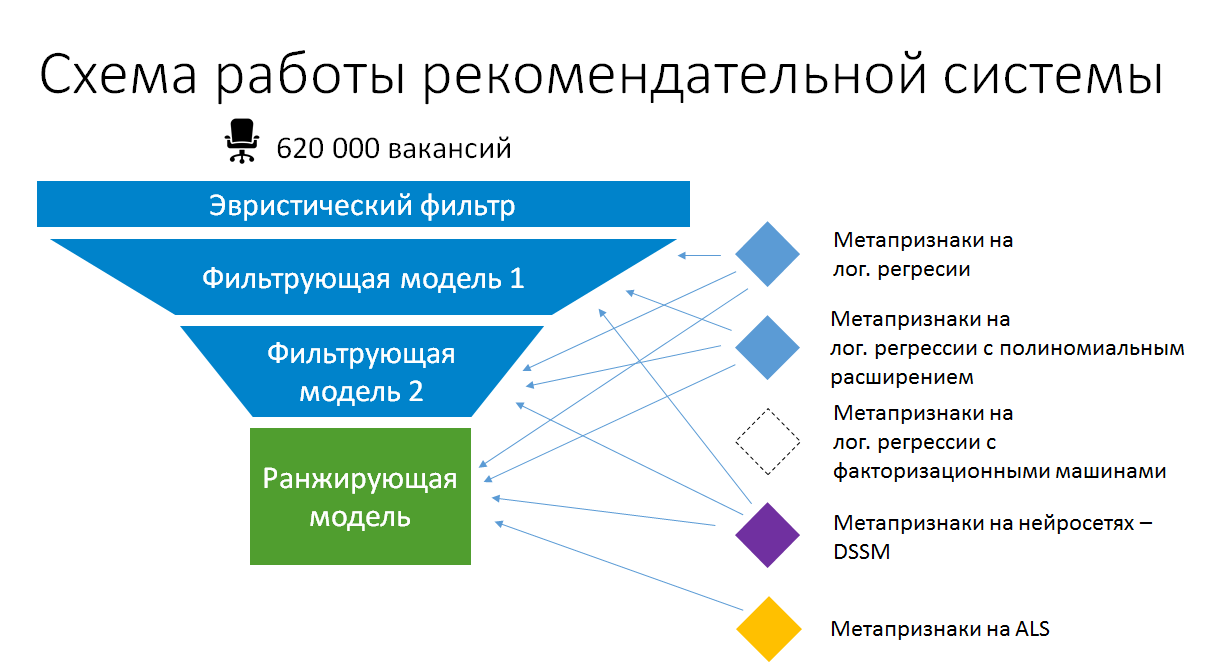
L'empilement en production est donc logique. Mais ce n'est pas cet empilement combinatoire automatique. Nous nous assurons que les modèles sur la base desquels les méta-attributs sont créés restent simples et utilisent au maximum les données existantes et les attributs statiques calculés. Ce n'est que de cette manière qu'ils peuvent rester en production sans se transformer progressivement en une boîte noire non prise en charge et rester dans un état où ils peuvent être recyclés et améliorés.