
Sur la base des résultats de nombreuses évaluations opérationnelles des centres de données du monde entier, l'Uptime Institute a noté que le niveau de dotation en personnel des centres de données varie considérablement d'un endroit à l'autre. Cette observation est quelque peu déroutante, mais elle n'est pas surprenante. Bien que la dotation soit une activité importante pour les centres de données qui tentent de maintenir l'excellence opérationnelle, de nombreux autres facteurs influencent les décisions des organisations concernant le niveau de dotation requis.
Parmi les facteurs susceptibles d'affecter le niveau global du personnel, on peut distinguer la complexité du datacenter, le roulement du personnel, le nombre d'heures nécessaires au support technique, le nombre de contrats avec les prestataires et les objectifs commerciaux d'accessibilité. Les coûts sont également préoccupants, car chaque employé représente un coût direct pour le centre de données. En raison de ces nombreux facteurs, il est nécessaire de revoir constamment les niveaux de dotation des centres de données pour fournir une assistance efficace à un prix raisonnable.
L'Uptime Institute pose souvent la question: "Quel est le niveau de dotation approprié pour mon centre de données?" Malheureusement, il n'y a pas de réponse concise qui serait universelle pour chaque centre de données. La dotation adéquate dépend d'un certain nombre de variables.
Le temps requis pour terminer les tâches de maintenance et garantir que les changements de support technique sont terminés sont deux variables principales. La dotation en personnel nécessaire pour répondre aux besoins de maintenance est un facteur relativement fixe, mais dépend des actions effectuées par le personnel du centre de données et des fonctions attribuées aux entrepreneurs. La gestion des changements de support technique est définie comme la dotation en personnel pour surveiller un centre de données et pour répondre à tout incident et événement. L'effectif du quart de travail pour le support technique peut être déterminé de différentes manières. Chaque méthode de dotation a un impact potentiel sur les opérations, selon les processus couverts par le support technique.
Tendances des changements
L'objectif principal de la présence permanente de personnel qualifié en place est de minimiser le risque de pannes causées par des événements anormaux en prévenant un incident, en le dissuadant ou en l'isolant, ainsi qu'en empêchant sa propagation ou son impact sur d'autres systèmes. De nombreux centres de données continuent de fournir une présence constante d'une équipe d'électriciens qualifiés, d'ingénieurs en mécanique et d'autres techniciens qui fournissent un mode de fonctionnement 24x7. Cependant, les technologies de télésurveillance, la disposition spéciale des bâtiments sous la forme d'un complexe, le désir d'équilibrer les coûts et d'autres raisons peuvent inciter les organisations à recruter du personnel de différentes manières.
La gestion d'un régime d'assistance technique sans personnel qualifié en place à tout moment peut augmenter les risques en raison d'une réponse retardée à des incidents anormaux. En fin de compte, l'entreprise doit prendre une décision avec un niveau de risque acceptable.
Les autres modèles de support technique à couverture complète comprennent:
- Former le personnel de sécurité pour répondre aux alarmes et effectuer des procédures pour résoudre les problèmes;
- Surveillance du centre de données via un système de surveillance de bâtiment (BMS) local ou régional et impliquant des techniciens d'appel;
- Disponibilité du personnel sur place pendant les heures normales de bureau et sur appel la nuit et le week-end;
- Le travail de plusieurs centres de données sous la forme d'un complexe spécial de bâtiments, dont l'équipe prend en charge plusieurs centres de données sans avoir besoin d'être en place dans chaque centre de données distinct à tout moment.
Ces méthodes et d'autres devraient être évaluées en termes d'efficacité individuellement. Afin d'évaluer le modèle de support technique, le centre de données doit déterminer les risques potentiels d'incidents dans le centre de données et leur impact potentiel sur l'entreprise.
Au cours des 20 dernières années, l'Uptime Institute a compilé une base de données sur les incidents anormaux (Abnormal Incident Reports, AIRs), en utilisant les informations reçues des membres du réseau Uptime Institute. Uptime Institute analyse chaque année les données et présente ses résultats aux membres du réseau. La base de données AIRs contient des informations intéressantes sur les problèmes de personnel et des modèles de dotation efficaces pour les centres de données.
Les incidents se produisent en dehors des heures de travail
En 2013, une petite majorité des incidents (sur 277 cas) se sont produits pendant les heures de bureau. Cependant, 44% des incidents se sont produits entre minuit et 8 h 00, ce qui souligne le besoin potentiel d'un mode d'assistance technique 24h / 24 et 7j / 7 (voir figure 1).
Figure 1. Environ la moitié des incidents anormaux survenus en 2013 ont eu lieu entre 8 h et midi, l'autre moitié de minuit à 8 h.
Les incidents peuvent survenir à tout moment de l'année. Centrer l'activité du personnel sur une certaine période de l'année en priorité sur les autres ne serait pas productif (par exemple, une interdiction de vacances). Les incidents sont répartis de manière assez uniforme tout au long de l'année.
La figure 2 montre la répartition des incidents par jour de la semaine. Le diagramme montre que chaque jour de la semaine a une part presque égale, ce qui suggère que la dotation devrait être la même pour les quarts de travail de chaque jour de la semaine. Il s'agit d'une conclusion importante, car certains centres de données ont concentré les ressources en main-d'œuvre de leur support technique pour la période du lundi au vendredi et laissent les jours de congé pour la surveillance à distance (voir figure 2).
Figure 2. Le personnel du centre de données doit être prêt tous les jours de la semaine.Incidents par industrie
La figure 3 illustre davantage les incidents de l'industrie et ne montre pas de différence significative dans les tendances entre les industries. Le graphique montre que le secteur des services financiers a signalé beaucoup plus d'incidents que les autres secteurs, mais cela reflète probablement la composition de l'échantillon.
 Figure 3. Les incidents dans les centres de données ont lieu toute l'année.
Figure 3. Les incidents dans les centres de données ont lieu toute l'année.Causes des échecs et méthodes de détection
Sachant quand des incidents se produisent, on ne peut pas dire grand-chose du personnel qui devrait être en place. Comprendre quels incidents se produisent le plus souvent aidera à façonner la structure des équipes et à découvrir comment les incidents sont le plus souvent détectés. La figure 4 montre que la plupart des incidents affectent les systèmes électriques, suivis des systèmes mécaniques. En revanche, les charges de travail informatiques critiques provoquent un nombre relativement faible d'incidents.
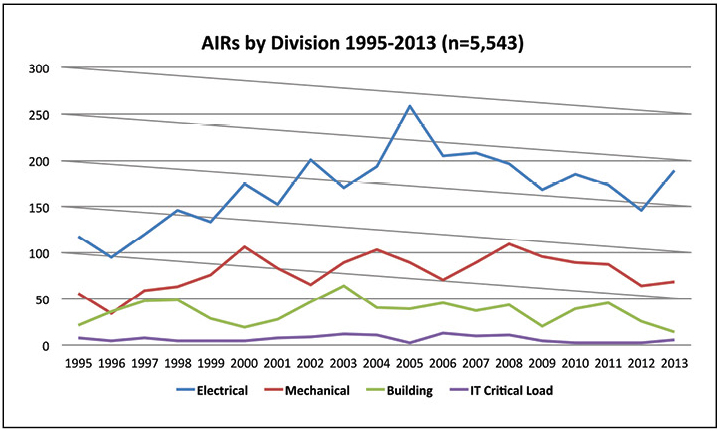 Figure 4. Plus de la moitié des incidents anormaux signalés en 2013 sont liés au système électrique.
Figure 4. Plus de la moitié des incidents anormaux signalés en 2013 sont liés au système électrique.Par conséquent, il est logique que les équipes de tous les quarts aient suffisamment d'expérience pour répondre aux incidents les plus courants dans les systèmes électriques. L'équipe de support doit également répondre à d'autres types d'incidents. La formation croisée d'ingénieurs électriciens sur les systèmes mécaniques et de construction peut fournir une couverture suffisante, et les préposés aux appels peuvent couvrir des incidents informatiques relativement rares.
La base de données AIRs éclaire également la façon dont les incidents sont détectés. La figure 5 montre que plus de la moitié des informations primaires sur tous les incidents détectés en 2013 ont été obtenues à partir de systèmes d'alarme, plus de 40% des incidents sont détectés par des spécialistes techniques sur site, ce qui représente à lui seul environ 95% des cas. Le plus grand changement au cours des années montré dans le diagramme est la croissance lente des incidents détectés par les alarmes.
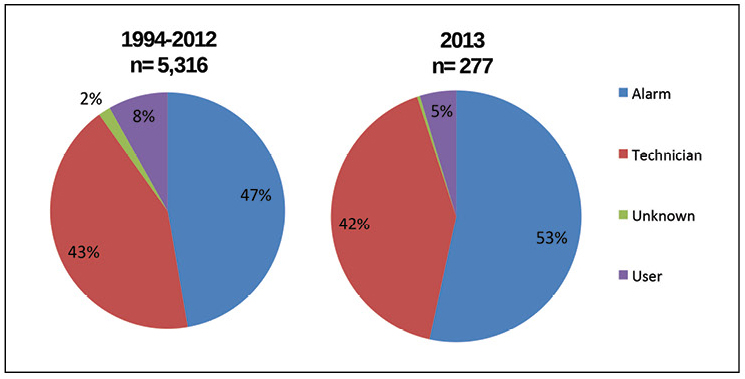 Figure 5. Les alarmes sont désormais un moyen de détecter la plupart des incidents; cependant, les problèmes d'accessibilité sont plus souvent constatés par les experts techniques.
Figure 5. Les alarmes sont désormais un moyen de détecter la plupart des incidents; cependant, les problèmes d'accessibilité sont plus souvent constatés par les experts techniques.Cependant, les alarmes ne peuvent pas répondre aux incidents ou atténuer les conséquences. L'Institut Uptime a été témoin d'un certain nombre de méthodes qui permettent aux centres de données d'éviter les dysfonctionnements et de réduire leur impact. Ces méthodes nécessitent que le personnel réponde à l'incident, crée une redondance dans les systèmes critiques et des programmes de maintenance prédictive efficaces pour prévoir les pannes potentielles avant qu'elles ne se produisent. La figure 6 montre la fréquence à laquelle chacune de ces méthodes «sauve» les centres de données.
 Figure 6. La redondance des équipements en 2013 a contribué à davantage de «sauvetage» que les années précédentes.
Figure 6. La redondance des équipements en 2013 a contribué à davantage de «sauvetage» que les années précédentes.Le diagramme montre également que ces dernières années, la redondance des équipements et la maintenance préventive sont devenues plus efficaces et font économiser de plus en plus d'argent aux centres de données. Il y a plusieurs explications possibles à cela, notamment l'augmentation de la fiabilité des systèmes, le recours plus large à des services proactifs et des coupes budgétaires, qui conduisent à une réduction du nombre de personnel ou à leur relocalisation en dehors du centre de données.
Échecs dans le contexte de la cause première
Les données montrent que tous les problèmes d'accessibilité en 2013 ont été causés par des incidents avec le système électrique. La plupart des échecs se sont produits parce que les procédures de maintenance n'ont pas été exécutées correctement. Cette constatation souligne l'importance d'avoir des procédures adéquates et un personnel bien formé.
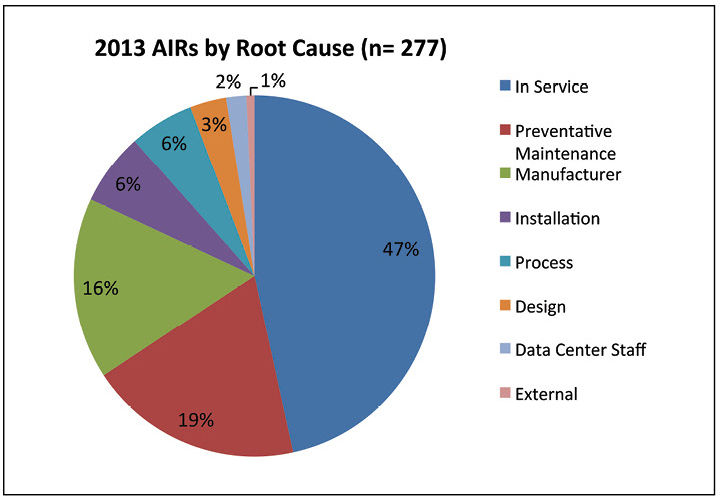 Figure 7. Près de la moitié des défaillances signalées en 2013 étaient dues à des problèmes de maintenance.
Figure 7. Près de la moitié des défaillances signalées en 2013 étaient dues à des problèmes de maintenance.Dans la fig. 7 examine plus en détail les causes des incidents en 2013. Environ la moitié des incidents ont été décrits comme «en service», ce qui est défini comme un entretien inadéquat, une mauvaise configuration de l'équipement, un arrêt de travail ou l'absence d'une cause racine spécifique. Les cas de «maintenance préventive» se réfèrent en fait à une maintenance préventive mal effectuée. Le personnel du centre de données n'a causé que 2% des incidents, ce qui montre que les interactions entre le personnel et l'équipement n'étaient pas la principale cause des incidents et des pannes.
Conclusion
La complexité croissante de la gestion de l'infrastructure des centres de données (DCIM), des systèmes de gestion des bâtiments (BMS) et des systèmes d'automatisation des bâtiments (BAS) rend difficile de trouver la réponse à la question de savoir s'il est possible de réduire le nombre de personnel dans les centres de données. Les progrès dans l'amélioration de ces systèmes sont importants. Ils peuvent améliorer les performances de votre centre de données; cependant, les données montrent que la prévention des incidents nécessite souvent du personnel sur place. C'est pourquoi le maintien de l'effectif équivalent temps plein (ETP) est une directive pour les centres de données certifiés Tier III et Tier IV.
L'objectif principal est de fournir un temps de réponse rapide pour atténuer les conséquences de tout incident et événement. Les données montrent que lorsque des incidents se produisent, aucun schéma temporaire n'est observé. Leur apparence est assez bien répartie sur les 24 heures et les 7 jours de la semaine.
L'objectif principal est la prévention des risques. Les centres de données continuent d'évoluer, permettant une gestion par accès à distance et augmentant la redondance matérielle. Chaque centre de données est unique et comporte son propre ensemble de risques inhérents. Le mode de support technique n'est qu'un facteur, mais très important. La décision sur la quantité de personnel à impliquer dans chaque quart de travail et avec quelles qualifications peut avoir un impact majeur sur la prévention des risques et la disponibilité des centres de données. Faites des choix intelligents.
Autres articles du blog Cloud4Y:→
Quel est le véritable coût des temps d'arrêt des infrastructures informatiques pour les petites et moyennes entreprises? (lien externe)→
L'apogée du cloud computing dans l'automatisation des entreprises industrielles (lien externe)→
Que se passe-t-il avec les prix du cloud computing ces dernières années (Habr)→
Comment créer des échantillons pour le système biométrique unifié et pourquoi il peut être dangereux (Habr)