Cet article décrit les différents types de tests en production et les conditions dans lesquelles chacun d'eux est le plus utile, et décrit également comment organiser des tests sécurisés de divers services en production.
Il convient de noter que le contenu de cet article s'applique uniquement aux
services dont le déploiement est contrôlé par les développeurs. En outre, vous devez immédiatement avertir que l'utilisation de l'un des types de tests décrits ici n'est pas une tâche facile, ce qui nécessite souvent des modifications sérieuses de la conception, du développement et des tests des systèmes. Et, malgré le titre de l'article, je ne pense pas que l'un des types de tests en production soit absolument fiable. Il n'y a qu'une opinion selon laquelle de tels tests peuvent réduire considérablement le niveau de risques à l'avenir, et les coûts d'investissement seront justifiés.
(Remarque: l'article original étant Longrid, pour la commodité des lecteurs, il est divisé en deux parties).Pourquoi les tests en production sont-ils nécessaires si cela peut être fait en staging?
L'importance du cluster de mise en scène (ou environnement de mise en scène) par différentes personnes est perçue différemment. Pour de nombreuses entreprises, le déploiement et le test d'un produit en staging est une étape intégrale précédant sa sortie définitive.
De nombreuses organisations bien connues perçoivent la mise en scène comme une copie miniature de l'environnement de travail. Dans de tels cas, il est nécessaire d'assurer leur synchronisation maximale. Dans ce cas, il est généralement nécessaire de garantir le fonctionnement de différentes instances de systèmes avec état, tels que des bases de données, et de synchroniser régulièrement les données de l'environnement de production avec le transfert. L'exception est uniquement les informations confidentielles qui vous permettent d'établir l'identité de l'utilisateur (cela est nécessaire pour se conformer aux exigences du
RGPD ,
PCI ,
HIPAA et autres réglementations).
Le problème avec cette approche (d'après mon expérience) est que la différence ne réside pas seulement dans l'utilisation d'une instance distincte de la base de données contenant les données réelles de l'environnement de production. Souvent, la différence s'étend aux aspects suivants:
- La taille du cluster intermédiaire (si vous pouvez l'appeler un «cluster» - il s'agit parfois d'un seul serveur déguisé en cluster);
- Le fait que le transfert utilise généralement un cluster beaucoup plus petit signifie également que les paramètres de configuration de presque tous les services varient. Cela s'applique aux configurations d'équilibreurs de charge, de bases de données et de files d'attente, par exemple, le nombre de descripteurs de fichiers ouverts, le nombre de connexions de base de données ouvertes, la taille du pool de threads, etc. Si la configuration est stockée dans une base de données ou un stockage de données de valeurs-clés (par exemple, Zookeeper ou Consul), ces systèmes auxiliaires doivent également être présents dans l'environnement de mise en scène;
- Le nombre de connexions en ligne traitées par le service sans état ou la méthode de réutilisation des connexions TCP par un serveur proxy (si cette procédure est exécutée);
- Manque de surveillance dans la mise en scène. Mais même si la surveillance est effectuée, certains signaux peuvent se révéler totalement inexacts, car un environnement autre que celui de travail est surveillé. Par exemple, même si vous surveillez la latence ou le temps de réponse d'une requête MySQL, il est difficile de déterminer si le nouveau code contient une requête qui peut lancer une analyse complète de la table dans MySQL, car il est beaucoup plus rapide (et parfois même préférable) d'effectuer une analyse complète de la petite table utilisée dans le test. une base de données plutôt qu'une base de données de production, où une requête peut avoir un profil de performances complètement différent.
Bien qu'il soit juste de supposer que toutes les différences ci-dessus ne sont pas des arguments sérieux contre l'utilisation de la mise en scène en tant que telle, contrairement aux antipatterns qui devraient être évités. Dans le même temps, le désir de tout faire correctement nécessite souvent les énormes coûts de main-d'œuvre des ingénieurs pour garantir un environnement cohérent. La production est en constante évolution et est influencée par divers facteurs, donc essayer d'atteindre ce match, c'est comme aller nulle part.
De plus, même si les conditions de la mise en scène seront aussi similaires que possible à l'environnement de travail, il existe d'autres types de tests qui sont mieux à utiliser sur la base d'informations réelles de production. Un bon exemple serait le test d'imprégnation, dans lequel la fiabilité et la stabilité d'un service sont testées sur une longue période à des niveaux réels de multitâche et de charge. Il est utilisé pour détecter les fuites de mémoire, déterminer la durée des pauses dans le CPG, le niveau de charge du processeur et d'autres indicateurs pendant une certaine période de temps.
Rien de ce qui précède ne suggère que la mise en scène est
complètement inutile (cela deviendra évident après avoir lu la section sur la duplication fantôme des données lors des tests de services). Cela indique seulement que, bien souvent, ils reposent davantage sur la mise en scène que nécessaire, et dans de nombreuses organisations, il reste le
seul type de test effectué avant la sortie complète du produit.
L'art du test en production
Il est arrivé historiquement que le concept de «test en production» soit associé à certains stéréotypes et connotations négatives («programmation guérilla», manque ou absence de tests unitaires et d'intégration, négligence ou inattention à la perception du produit par l'utilisateur final).
Les tests en production mériteront certainement une telle réputation s'ils sont effectués avec négligence et mal. Il
ne remplace en aucun cas les tests au stade de la pré-production et n'est en aucun cas une
tâche simple . De plus, je soutiens que
des tests
réussis et
sûrs en production nécessitent un niveau d'automatisation important, une bonne compréhension des pratiques établies et la conception de systèmes avec une orientation initiale vers ce type de tests.
Afin d'organiser un processus complet et sûr de test efficace des services en production, il est important de ne pas le considérer comme un terme généralisant un ensemble d'outils et de techniques différents. Malheureusement, cette erreur a également été commise par moi -
dans mon article précédent, une classification pas tout à fait scientifique des méthodes de test a été présentée, et dans la section "Test en production", une variété de méthodologies et d'outils ont été regroupés.
Extrait de la note Testing Microservices, the sane way ("A smart approach to testing microservices")Depuis la publication de la note fin décembre 2017, je discute de son contenu et généralement du thème des tests en production avec plusieurs personnes.
Au cours de ces discussions, et également après une série de conversations séparées, il m'est apparu clairement que le sujet des tests en production ne pouvait pas être réduit à plusieurs points énumérés ci-dessus.
Le concept de «test en production» comprend toute une gamme de techniques appliquées
à trois stades différents . Lesquelles - comprenons.
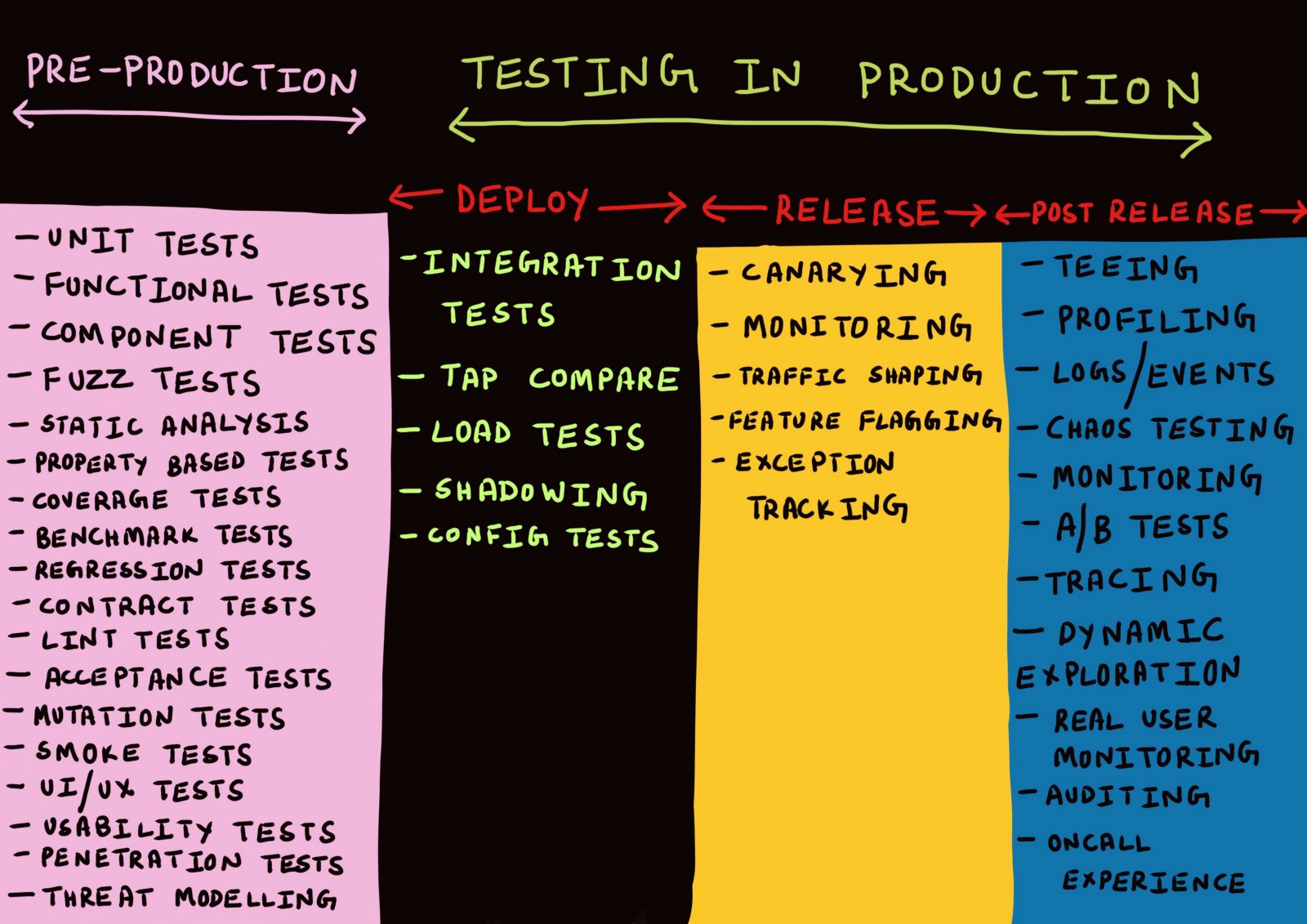
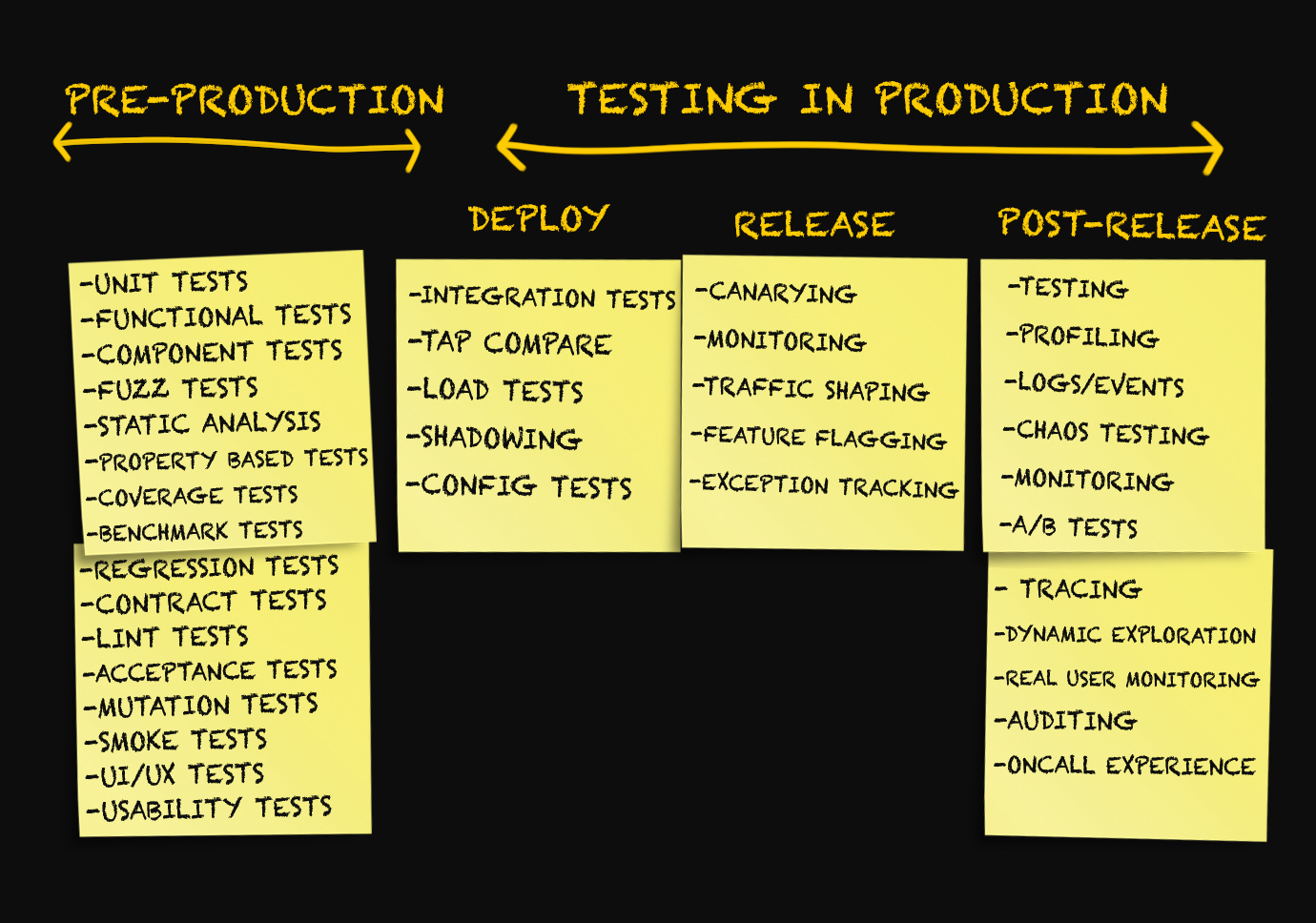
Trois étapes de production
Habituellement, les discussions sur la production sont menées uniquement dans le contexte du déploiement de code dans la production, la surveillance ou dans des situations d'urgence en cas de problème.
J'ai moi-même jusqu'à présent utilisé des termes tels que «déploiement», «libération», «livraison», etc., comme synonymes, sans trop réfléchir à leur signification. Il y a quelques mois, toutes les tentatives pour distinguer ces termes seraient rejetées par moi comme quelque chose d'insignifiant.
Après y avoir réfléchi, j'en suis venu à l'idée qu'il
y a un réel besoin de distinguer les différentes étapes de la production.
Étape 1. Déploiement
Lorsque les tests (même en production) sont un test de l'atteinte des
meilleurs indicateurs possibles , la précision des tests (et en fait de tous les tests) n'est assurée qu'à condition que la méthode de test soit aussi proche que possible de la manière dont le service est réellement utilisé en production.
En d'autres termes, les tests doivent être exécutés dans un environnement qui
simule le mieux un environnement de travail .
Et la
meilleure imitation de l' environnement de travail est ... l'environnement de travail lui-même. Pour effectuer le nombre maximal de tests possible dans un environnement de production, il est nécessaire que le résultat infructueux de l'un d'eux n'affecte pas l'utilisateur final.
Ceci, à son tour, n'est possible que si,
lors du déploiement du service dans un environnement de production, les utilisateurs n'obtiennent pas un accès direct à ce service .
Dans cet article, j'ai décidé d'utiliser la terminologie de l'article
Deploy! = Release écrit par
Turbine Labs . Il définit le terme «déploiement» comme suit:
«Le déploiement est l'installation par un groupe de travail d'une nouvelle version du code du programme de service dans l'infrastructure de production. Lorsque nous disons qu'une nouvelle version du logiciel a été
déployée , nous voulons dire qu'il s'exécute quelque part dans le cadre de l'infrastructure de travail. Il peut s'agir d'une nouvelle instance EC2 dans AWS ou d'un conteneur Docker s'exécutant au cœur d'un cluster Kubernetes. Le service a démarré avec succès, a passé un bilan de santé et est prêt (vous l’espérez!) À traiter les données de l’environnement de production, mais peut ne pas recevoir de données. C'est un point important, je le souligne à nouveau:
pour le déploiement, il n'est pas nécessaire que les utilisateurs aient accès à la nouvelle version de votre service . Compte tenu de cette définition, le déploiement peut être qualifié de processus avec un risque presque nul. »
Les mots «processus à risque zéro» sont simplement un baume pour l'âme de nombreuses personnes qui ont souffert de déploiements infructueux. La possibilité d'installer un logiciel
dans un environnement réel sans y permettre aux utilisateurs présente un certain nombre d'avantages en matière de test.
Premièrement, la nécessité de maintenir des environnements séparés pour le développement, les tests et la mise en scène, qui doivent inévitablement être synchronisés avec la production, est minimisée (et peut même complètement disparaître).
De plus, au stade de la conception des services, il devient nécessaire de les isoler les uns des autres afin que l'échec du test d'une instance spécifique du service en production
n'entraîne pas une cascade ou n'affecte pas les utilisateurs de l'échec des autres services. Une solution à cela peut être la conception d'un modèle de données et d'un schéma de base de données dans lesquels les requêtes non idempotentes (principalement les
opérations d'écriture ) peuvent:
- A réaliser en relation avec la base de données de l'environnement de production lors de tout lancement de test du service en production (je préfère cette approche);
- Être rejeté en toute sécurité au niveau de l'application jusqu'à ce qu'ils atteignent le niveau d'écriture ou de sauvegarde;
- Être alloué ou isolé au niveau de l'enregistrement ou de la sauvegarde d'une manière ou d'une autre (par exemple, en stockant des métadonnées supplémentaires).
Étape 2. Libération
Remarque
Deploy! = Release définit le terme release comme suit:
«Lorsque nous disons que la
sortie de la version de service a eu lieu, nous voulons dire qu'elle assure le traitement des données dans l'environnement de production. En d'autres termes, une
version est un processus qui dirige les données de l'environnement de production vers une nouvelle version du logiciel. Avec cette définition à l'esprit, tous les risques que nous associons à l'envoi de nouveaux flux de données (interruptions, insatisfaction des clients, notes vénéneuses dans
The Register ) concernent la
sortie d'un nouveau logiciel, et non son déploiement (dans certaines entreprises, cette étape est également appelée
libération . Dans cet article, nous utiliserons le terme
version ). "
Dans le livre de Google sur SRE, le terme "version" est utilisé dans le
chapitre sur l'organisation d'une version logicielle pour le décrire .
«Un
problème est un élément logique du travail consistant en une ou plusieurs tâches distinctes. Notre objectif est de coordonner le processus de déploiement avec le profil de risque de ce service .
Dans les environnements de développement ou de pré-production, nous pouvons construire toutes les heures et distribuer automatiquement les versions après avoir passé tous les tests. Pour les grands services orientés utilisateur, nous pouvons commencer la version avec un cluster, puis augmenter son échelle jusqu'à ce que nous mettions à jour tous les clusters.
Pour les éléments d'infrastructure importants, nous pouvons étendre la période de mise en œuvre à plusieurs jours et l'exécuter à tour de rôle dans différentes régions géographiques. »Dans cette terminologie, les mots «version» et «version» signifient ce que le vocabulaire général appelle «déploiement», et les termes souvent utilisés pour décrire diverses stratégies de
déploiement (par exemple, déploiement bleu-vert ou déploiement canari) se réfèrent à la
publication d'un nouveau logiciel.
De plus, une
libération infructueuse
des applications peut entraîner des interruptions partielles ou importantes du travail. À ce stade, une
restauration ou un
correctif est également effectué s'il s'avère que la nouvelle version
publiée du service est instable.
Le processus de
publication fonctionne mieux lorsqu'il est automatisé et s'exécute de manière
incrémentielle . De même, une
restauration ou un
correctif d'un service est plus utile lorsque le taux d'erreur et la fréquence des demandes sont automatiquement corrélés avec la ligne de base.
Étape 3. Après la libération
Si la publication
s'est bien déroulée et que la nouvelle version du service traite les données de l'environnement de production sans problèmes évidents, nous pouvons considérer
qu'elle a réussi. Une libération réussie est suivie d'une étape qui peut être appelée «après la libération».
Tout système suffisamment complexe sera
toujours dans un état de perte progressive de performances. Cela ne signifie pas qu'une
restauration ou un
correctif est requis . Au lieu de cela, il est nécessaire de surveiller une telle détérioration (à diverses fins opérationnelles et opérationnelles) et de déboguer si nécessaire. Pour cette raison, les tests après la publication ne sont plus des routines, mais le
débogage ou la collecte de données analytiques.
En général, je pense que chaque composant du système doit être créé en tenant compte du fait qu'aucun grand système ne fonctionne parfaitement à 100% et que les dysfonctionnements doivent être reconnus et pris en compte aux étapes de la conception, du développement, des tests, du déploiement et de la surveillance du logiciel fournir.
Maintenant que nous avons identifié les trois étapes de la production, regardons les différents mécanismes de test disponibles sur chacun d'eux. Tout le monde n'a pas la possibilité de travailler sur de nouveaux projets ou de réécrire du code à partir de zéro. Dans cet article, j'ai essayé d'identifier clairement les méthodes qui fonctionneront le mieux lors du développement de nouveaux projets, ainsi que de parler de ce que nous pouvons faire d'autre pour tirer parti des méthodes proposées sans apporter de modifications importantes aux projets de travail.
Test de déploiement
Nous avons séparé les étapes de déploiement et de publication les unes des autres, et nous allons maintenant considérer certains types de tests qui peuvent être appliqués après le déploiement du code dans l'environnement de production.
Test d'intégration
En règle générale, les tests d'intégration sont effectués par un serveur d'intégration continue dans un environnement de test isolé pour chaque branche Git. Une copie de la topologie de service
complète (y compris les bases de données, les files d'attente, les proxys, etc.) est déployée pour les suites de tests de
tous les services qui fonctionneront ensemble.
Je pense que ce n'est pas particulièrement efficace pour plusieurs raisons. Tout d'abord, l'environnement de test, comme l'environnement de transfert, ne peut pas être déployé de manière à être
identique à l' environnement de production réel,
même si les tests sont exécutés dans le même conteneur Docker qui sera utilisé dans la production. Cela est particulièrement vrai lorsque la
seule chose qui s'exécute dans un environnement de test est les tests eux-mêmes.
Que le test soit exécuté en tant que conteneur Docker ou processus POSIX, il établit très probablement
une ou plusieurs connexions à un service, une base de données ou un cache supérieur, ce qui est rare si le service se trouve dans un environnement de production où il peut simultanément traiter plusieurs connexions simultanées, en réutilisant souvent des connexions TCP inactives (c'est ce qu'on appelle la réutilisation des connexions HTTP).
En outre, le problème est dû au fait que la plupart des tests à chaque démarrage créent une nouvelle table de base de données ou un espace de clé de cache sur
le même nœud où ce test est effectué (de cette manière, les tests sont isolés des pannes de réseau). Ce type de test peut au mieux montrer que le système fonctionne correctement avec une demande très spécifique. Il est rarement efficace pour simuler des types de défaillances graves et bien répartis, sans parler des différents types de défaillances partielles.
Des études exhaustives existent qui confirment que les systèmes distribués présentent souvent un
comportement imprévisible qui ne peut être prévu par une analyse effectuée différemment que pour l'ensemble du système.
Mais cela ne signifie pas que les tests d'intégration sont
en principe inutiles. Nous pouvons seulement dire que la mise en œuvre de tests d'intégration dans un
environnement artificiel, complètement isolé , n'a généralement pas de sens. Des tests d'intégration doivent toujours être effectués pour vérifier que la nouvelle version du service:
- N'interfère pas avec l'interaction avec les services en amont ou en aval;
- N'affecte pas négativement les buts et objectifs des services supérieurs ou inférieurs.
Le premier peut être fourni dans une certaine mesure par des tests de contrat.
Étant donné que les
interfaces entre les services fonctionnent correctement,
les tests de contrat sont une méthode efficace pour développer et tester des services individuels au
stade de la pré-production , ce qui ne nécessite pas le déploiement de la topologie de service complète.
Les plates-formes de test de contrat orientées client, telles que
Pact , ne prennent actuellement en charge que l'interopérabilité entre les services via RESTful JSON RPC, bien qu'il soit probable que des
travaux soient en cours pour prendre en charge l'interaction asynchrone via les sockets Web, les applications non serveur et les files d'attente de messages . La prise en charge des protocoles gRPC et GraphQL devrait être ajoutée à l'avenir, mais elle n'est pas encore disponible.
Cependant, avant la
sortie d'une nouvelle version, il peut être nécessaire de vérifier non seulement le bon fonctionnement des
interfaces . , , , RPC- . , , , .
,
, — ,
, ( , ).
:
?
. – , : - - ( C) MySQL ( D) memcache ( B).
, ( ), stateful- stateless- .
,
.
service discovery
( ),
.
.
,
C .
,
, , . , , . ,
, .
Google
Just Say No to More End-to-End Tests (« »), :
«
( ) . , ? , .
, , , »., :
. , A .
,
C MySQL, .
( , , «» ,
).
MySQL , , .
— -. , . -, .
, -
, /:
, (, ).
, ,
. IP- , , , , , , , , .
, , , , . . Facebook,
Kraken , :
«
— , . - , . , . - , , , »., , , , , .
- . service mesh . -. -, , , :
Si nous testons le service B, son serveur proxy sortant peut être configuré pour ajouter un en
X-ServiceB-Test tête
X-ServiceB-Test spécial à chaque demande de test. Dans ce cas, le serveur proxy entrant du service supérieur C pourra:
- Détectez cet en-tête et envoyez une réponse standard au service B;
- Dites au service C que la demande est un test .
Test d'intégration de l'interaction de la version déployée du service B avec la version publiée du service C, où les opérations d'écriture n'atteignent jamais la base de donnéesLes tests d'intégration de cette manière permettent également de tester l'interaction du service B avec des services supérieurs
lorsqu'ils traitent des données d'environnement de production normales - c'est probablement une imitation plus proche de la façon dont le service B se comportera lors de sa
mise en production.
Il serait également intéressant que chaque service de cette architecture prenne en charge de véritables appels d'API en mode test ou simulé, vous permettant de tester l'exécution de contrats de service avec des services en aval sans modifier les données réelles. Cela reviendrait à tester les contrats, mais au niveau du réseau.
Duplication de données fantômes (test de flux de données sombres ou mise en miroir)
La duplication des
clichés instantanés (dans l'article du blog Google, elle est appelée
lancement sombre , et le terme de
mise en miroir est utilisé dans
Istio ) a dans bien des cas plus d'avantages que les tests d'intégration.
Les
principes de l'ingénierie du chaos stipulent ce qui suit:
«Les
systèmes se comportent différemment selon l'environnement et le schéma de transfert de données. Étant donné que le mode d'utilisation peut changer à tout moment , l'
échantillonnage de données réelles est le seul moyen fiable de corriger le chemin de la demande. »La duplication de données fantômes est une méthode par laquelle le flux de données d'environnement de production entrant dans un service donné est capturé et reproduit dans une nouvelle version
déployée du service. Ce processus peut être effectué en temps réel, lorsque le flux de données entrant est divisé et envoyé aux versions
publiées et
déployées du service, ou de manière asynchrone, lorsqu'une copie des données précédemment capturées est lue dans le service
déployé .
Lorsque j'ai travaillé chez
imgix (une start-up
employant 7 ingénieurs, dont seulement quatre étaient des ingénieurs système), des flux de données sombres ont été activement utilisés pour tester les changements dans notre infrastructure de visualisation d'images. Nous avons enregistré un certain pourcentage de toutes les demandes entrantes et les avons envoyées au cluster Kafka - nous avons transmis les journaux d'accès HAProxy au pipeline
heka , qui à son tour a transmis le flux de requêtes analysé au cluster Kafka. Avant la phase de
publication, une nouvelle version de notre application de traitement d'image a été testée sur un flux de données sombre capturé, ce qui a permis de vérifier que les demandes étaient correctement traitées. Cependant, notre système de visualisation d'images était dans l'ensemble un service sans état qui était particulièrement bien adapté à ce type de test.
Certaines entreprises préfèrent ne pas capturer une partie du flux de données, mais transmettre une
copie complète de ce flux à la nouvelle version de l'application.
Le McRouter de Facebook (proxy memcached) prend en charge ce type de duplication fantôme du flux de données memcache.
«
Lors du test d'une nouvelle installation pour le cache, nous avons trouvé très pratique de pouvoir rediriger une copie complète du flux de données des clients. McRouter prend en charge les paramètres de duplication d'ombre flexibles. Il est possible d'effectuer une duplication fantôme d'un pool de différentes tailles (en remettant en cache l'espace clé), de copier uniquement une partie de l'espace clé ou de modifier dynamiquement les paramètres pendant le fonctionnement .
L'aspect négatif de la duplication fantôme de l'ensemble du flux de données pour un service
déployé dans un environnement de production est que s'il est exécuté au moment de l'intensité de transfert de données maximale, il peut alors nécessiter deux fois plus de puissance.
Des proxys tels qu'Envoy prennent en charge la duplication fantôme du flux de données vers un autre cluster en mode incendie et oubli. Sa
documentation dit:
«
Un routeur peut effectuer une duplication fantôme du flux de données d'un cluster à un autre. Actuellement, le mode de tir et d'oubli est implémenté, dans lequel le serveur proxy Envoy n'attend pas de réponse du cluster fantôme avant de renvoyer une réponse du cluster principal. Pour le cluster fantôme, toutes les statistiques habituelles sont collectées, ce qui est utile à des fins de test. Avec la duplication fantôme, l'option -shadow est ajoutée à l'en- -shadow hôte / autorité. Ceci est utile pour la journalisation. Par exemple, cluster1 transforme en cluster1-shadow . "
Cependant, il est souvent impossible ou impossible de créer une réplique d'un cluster synchronisé avec la production pour les tests (pour la même raison qu'il est problématique d'organiser un cluster intermédiaire synchronisé). Si la duplication miroir est utilisée pour tester un nouveau service
déployé qui a de nombreuses dépendances, il peut déclencher des changements imprévus dans l'état des services de niveau supérieur par rapport à celui testé. La duplication fantôme du volume quotidien d'inscriptions d'utilisateurs dans la version
déployée du service avec enregistrement dans la base de données de production peut entraîner une augmentation du taux d'erreur jusqu'à 100% du fait que le flux de données fantôme sera perçu comme des tentatives répétées d'enregistrement et rejetées.
Mon expérience personnelle suggère que la duplication d'ombre est la mieux adaptée pour tester les demandes non idempotentes ou les services sans état avec des stubs côté serveur. Dans ce cas, la duplication fantôme des données est plus souvent utilisée pour tester la charge, la stabilité et les configurations. Dans le même temps, à l'aide de tests d'intégration ou de transfert, vous pouvez tester la façon dont le service interagit avec un serveur avec état lorsque vous travaillez avec des requêtes non idempotentes.
Comparaison TAP
La seule mention de ce terme se trouve dans un
article du blog Twitter consacré au lancement de services à haut niveau de qualité de service.
«Pour vérifier l'exactitude de la nouvelle implémentation du système existant, nous avons utilisé une méthode appelée tap-comparaison . Notre outil de comparaison de prises reproduit les données de production d'échantillons dans le nouveau système et compare les réponses reçues avec les résultats de l'ancien. Les résultats obtenus nous ont aidés à trouver et à corriger les erreurs dans le système avant même que les utilisateurs finaux ne les rencontrent. »Un autre article de blog Twitter définit les comparaisons de prises comme suit:
«Envoi de demandes aux instances de service à la fois dans les environnements de production et de transfert avec vérification des résultats et évaluation des caractéristiques de performance.»La différence entre la comparaison de prises et la duplication fantôme est que dans le premier cas, la réponse renvoyée par la version
publiée est comparée à la réponse retournée par la version
déployée , et dans le second, la demande est dupliquée vers la version
déployée en mode hors ligne comme le feu et oublie.
Un autre outil pour travailler dans ce domaine est la bibliothèque
scientifique , disponible sur GitHub. Cet outil a été développé pour tester le code Ruby, mais a ensuite été porté dans
plusieurs autres langages . Il est utile pour certains types de tests, mais présente un certain nombre de problèmes non résolus. Voici ce qu'un développeur GitHub a écrit dans une communauté Slack professionnelle:
«Cet outil exécute simplement deux branches de code et compare les résultats. Vous devez être prudent avec le code de ces branches. Il est nécessaire de s'assurer que les requêtes de base de données ne sont pas dupliquées si cela entraîne des problèmes. Je pense que cela s'applique non seulement à un scientifique, mais aussi à toute situation dans laquelle vous faites quelque chose deux fois, puis comparez les résultats. L'outil scientifique a été créé pour vérifier que le nouveau système d'autorisation fonctionne de la même manière que l'ancien, et à certains moments, il a été utilisé pour comparer les données typiques de pratiquement chaque demande de Rails. Je pense que le processus prendra plus de temps, car le traitement est effectué séquentiellement, mais c'est un problème Ruby dans lequel les threads ne sont pas utilisés.
Dans la plupart des cas que je connais, l'outil scientifique a été utilisé pour travailler avec des opérations de lecture plutôt que d'écriture, par exemple, pour savoir si les nouvelles requêtes améliorées et les nouveaux schémas d'autorisation reçoivent la même réponse que les anciens. Les deux options sont exécutées dans un environnement de production (sur des répliques). Si les ressources testées ont des effets secondaires, je pense que les tests devront être effectués au niveau de l'application. »Diffy est un outil open source écrit Scala introduit par Twitter en 2015.
Un article du blog Twitter intitulé
Testing without Writing Tests est probablement la meilleure ressource pour comprendre comment fonctionnent les comparaisons de touches dans la pratique.
«Diffy détecte les erreurs potentielles dans le service en lançant simultanément une nouvelle et une ancienne version du code. Cet outil fonctionne comme un serveur proxy et envoie toutes les demandes reçues à chacune des instances en cours d'exécution. Il compare ensuite les réponses des instances et rapporte tous les écarts trouvés lors de la comparaison. Diffy est basé sur l'idée suivante: si deux implémentations d'un service retournent les mêmes réponses avec un ensemble de requêtes suffisamment grand et varié, alors ces deux implémentations peuvent être considérées comme équivalentes, et la plus récente d'entre elles sans dégradation des performances. La technique innovante de réduction du bruit de Diffy la distingue des autres outils d'analyse de régression comparative. »La comparaison des prises est excellente lorsque vous devez vérifier si deux versions donnent les mêmes résultats. Selon Mark McBride,
«L'outil Diffy était souvent utilisé dans la refonte des systèmes. Dans notre cas, nous avons divisé la base de code source de Rails en plusieurs services créés à l'aide de Scala, et un grand nombre de clients API ont utilisé les fonctions différemment de ce que nous attendions. Des fonctions telles que le formatage de la date étaient particulièrement dangereuses. »La comparaison de prises n'est pas la meilleure option pour tester l'activité des utilisateurs ou l'identité du comportement de deux versions du service à la charge maximale. Comme pour la duplication fantôme, les effets secondaires restent un problème non résolu, en particulier lorsque la version déployée et la version de production écrivent des données dans la même base de données. Comme pour les tests d'intégration, une solution à ce problème consiste à utiliser des tests de comparaison de prises avec uniquement un ensemble limité de comptes.
Test de charge
Pour ceux qui ne sont pas familiers avec les tests de résistance,
cet article peut servir de bon point de départ. Il ne manque pas d'outils et de plates-formes pour les tests de charge open source. Les plus populaires d'entre eux sont
Apache Bench ,
Gatling ,
wrk2 ,
Tsung , écrit en Erlang,
Siege ,
Iago de Twitter, écrit en Scala (qui reproduit les journaux d'un serveur HTTP, d'un serveur proxy ou d'un analyseur de paquets réseau dans une instance de test). Certains experts estiment que le meilleur outil pour générer de la charge est
mzbench , qui prend en charge une variété de protocoles, y compris MySQL, Postgres, Cassandra, MongoDB, TCP, etc. Le
NDBench de Netflix est un autre outil open source pour tester la charge des entrepôts de données. , qui prend en charge la plupart des protocoles connus.
Le blog officiel Twitter d'
Iago décrit plus en détail les fonctionnalités qu'un bon générateur de charge devrait avoir:
«Les demandes non bloquantes sont générées à une fréquence donnée sur la base d'une distribution statistique personnalisée interne ( le processus de Poisson est modélisé par défaut). La fréquence des demandes peut être modifiée au besoin, par exemple pour préparer le cache avant de travailler à pleine charge.
En général, l'accent est mis sur la fréquence des demandes conformément à la loi de Little , et non sur le nombre d'utilisateurs simultanés, qui peut varier en fonction du délai inhérent à ce service. De ce fait, de nouvelles opportunités apparaissent pour comparer les résultats de plusieurs tests et prévenir la détérioration du service, ralentissant le fonctionnement du générateur de charge.
En d'autres termes, l'outil Iago cherche à simuler un système dans lequel les demandes sont reçues quelle que soit la capacité de votre service à les traiter. En cela, il diffère des générateurs de charge simulant des systèmes fermés dans lesquels les utilisateurs travailleront patiemment avec le retard existant. Cette différence nous permet de modéliser assez précisément les modes de défaillance qui peuvent être rencontrés en production. "Un autre type de test de charge est le test de contrainte en redistribuant le flux de données. Son essence est la suivante: l'ensemble du flux de données de l'environnement de production est dirigé vers un cluster plus petit que celui préparé pour le service; en cas de problème, le flux de données est retransféré vers le cluster le plus important. Cette technique est utilisée par Facebook, comme décrit dans l'un des
articles de son blog officiel :
«Nous redirigeons spécifiquement un flux de données plus important vers des clusters ou nœuds individuels, mesurons la consommation de ressources sur ces nœuds et déterminons les limites de la stabilité des services. Ce type de test, en particulier, est utile pour déterminer les ressources CPU nécessaires pour prendre en charge le nombre maximal de diffusions simultanées de Facebook Live. »Voici ce qu'écrit un ancien ingénieur LinkedIn de la communauté professionnelle Slack:
«LinkedIn a également utilisé des tests de redline en production - les serveurs ont été supprimés de l'équilibreur de charge jusqu'à ce que la charge atteigne des valeurs seuil ou que des erreurs commencent à se produire.En effet, une recherche Google fournit un lien vers un
livre blanc complet et un
article de blog LinkedIn sur ce sujet:
«La solution Redliner pour les mesures utilise un véritable flux de données de l'environnement de production, ce qui évite les erreurs qui empêchent des mesures précises des performances en laboratoire.
Redliner redirige une partie du flux de données vers le service testé et analyse en temps réel ses performances. Cette solution a été mise en œuvre dans des centaines de services LinkedIn internes et est utilisée quotidiennement pour divers types d'analyses de performances.
Redliner prend en charge l'exécution de tests parallèles pour les instances canaries et de production. Cela permet aux ingénieurs de transférer la même quantité de données vers deux instances de service différentes: 1) une instance de service qui contient des innovations, telles que de nouvelles configurations, propriétés ou nouveau code; 2) une instance de service de la version de travail actuelle."Les résultats des tests de charge sont pris en compte lors de la prise de décisions et aident à empêcher le déploiement de code, ce qui peut entraîner de mauvaises performances."Facebook a fait passer les tests de charge à l'aide de flux de données réels à un tout autre niveau grâce au système Kraken, et sa
description mérite également d'être lue.
Le test est mis en œuvre en redistribuant le flux de données lors de la modification des valeurs de poids (lues depuis le magasin de configuration distribué) pour les périphériques et les clusters de bordure dans la configuration
Proxygen (équilibreur de charge Facebook). Ces valeurs déterminent le volume de données réelles envoyées, respectivement, à chaque cluster et région à un point de présence donné.
Données du livre blanc KrakenLe système de surveillance (
Gorilla ) affiche des indicateurs de divers services (comme indiqué dans le tableau ci-dessus). Sur la base des données de surveillance et des seuils, il est décidé d'envoyer des données supplémentaires conformément aux valeurs de poids, ou s'il est nécessaire de réduire, voire d'arrêter complètement le transfert de données vers un cluster spécifique.
Tests de configuration
Une nouvelle vague d'outils d'infrastructure open source a rendu possible la capture de tous les changements dans l'infrastructure sous forme de code, mais aussi relativement
facile . Il est également devenu possible à des degrés divers de
tester ces changements, bien que la plupart des tests d'infrastructure en tant que code au stade de la pré-production ne puissent que confirmer les spécifications et la syntaxe correctes.
De plus, le refus de tester la nouvelle configuration avant la
sortie du code est devenu la cause d'un
nombre important d'interruptions .
Pour un test holistique des changements de configuration, il est important de distinguer les différents types de configurations. Fred Hebert a suggéré une fois d'utiliser le quadrant suivant:
Cette option, bien sûr, n'est pas universelle, mais cette distinction vous permet de décider comment tester au mieux chacune des configurations et à quelle étape le faire. La configuration du temps de construction est logique si vous pouvez garantir une véritable répétabilité des assemblages. Toutes les configurations ne sont pas statiques, mais sur les plates-formes modernes, un changement de configuration dynamique est inévitable (même si nous avons affaire à une «infrastructure permanente»).
, , blue-green , . (
Jamie Wilkinson ), Google ,
:
« , , , - . . - , — , , . ., . , , — ».Facebook :
« . — , . . , .
. Facebook , . , .
(, JSON). , . .
(, Facebook Thrift) . , .
, , - . . — A/B-, 1 % . A/B-, . A/B- . , , , , . , A/B- . , A/B-. Facebook .
, A/B- 1% , 1% , ( « »). , . , .
Facebook . , . , , . , , .- Annulation simple et pratique des modifications
Dans certains cas, malgré toutes les mesures préventives, le déploiement d'une configuration inopérante est effectué. Trouver et annuler rapidement les modifications est essentiel pour résoudre un tel problème. "Les outils de contrôle de version sont disponibles dans notre système de configuration, ce qui facilite beaucoup l'annulation des modifications."
À suivre!UPD: continué ici .