Il n'y a peut-être pas d'autre technologie aujourd'hui autour de laquelle il y aurait autant de mythes, de mensonges et d'incompétence. Les journalistes qui parlent de la technologie mentent, les politiciens qui parlent d'une mise en œuvre réussie mentent, la plupart des vendeurs de technologie mentent. Chaque mois, je vois les conséquences de la façon dont les gens essaient de mettre en œuvre la reconnaissance faciale dans des systèmes qui ne peuvent pas fonctionner avec.

Le sujet de cet article est devenu douloureux il y a longtemps, mais il était en quelque sorte trop paresseux pour l'écrire. Beaucoup de texte que j'ai déjà répété vingt fois à différentes personnes. Mais, après avoir lu le prochain paquet de poubelles, j'ai néanmoins décidé qu'il était temps. Je vais donner un lien vers cet article.
Alors. Dans l'article, je répondrai à quelques questions simples:
- Est-il possible de vous reconnaître dans la rue? Et comment automatique / fiable?
- Avant-hier, ils ont écrit que des criminels étaient détenus dans le métro de Moscou et hier, ils ont écrit qu'ils ne pouvaient pas à Londres. Et aussi en Chine, ils reconnaissent tout le monde, tout le monde dans la rue. Et ici, ils disent que 28 membres du Congrès américain sont des criminels. Ou, ils ont attrapé un voleur.
- Qui lance maintenant des solutions de reconnaissance faciale, quelle est la différence entre les solutions et les fonctionnalités technologiques?
La plupart des réponses seront fondées sur des preuves, avec un lien vers la recherche où les paramètres clés des algorithmes + avec les mathématiques du calcul sont affichés. Une petite partie sera basée sur l'expérience de la mise en œuvre et du fonctionnement de divers systèmes biométriques.
Je n'entrerai pas dans les détails de la façon dont la reconnaissance des visages est mise en œuvre maintenant. Sur Habré il y a beaucoup de bons articles sur ce sujet:
a ,
b ,
c (il y en a bien plus, bien sûr, ils apparaissent en mémoire). Mais encore, certains points qui affectent différentes décisions - je vais décrire. La lecture d'au moins un des articles ci-dessus simplifiera donc la compréhension de cet article. Commençons!
Introduction, base
La biométrie est une science exacte. Il n'y a pas de place pour les phrases «fonctionne toujours» et «idéal». Tout est très bien considéré. Et pour calculer, vous devez connaître seulement deux quantités:
- Erreurs du premier type - une situation où une personne n'est pas dans notre base de données, mais nous l'identifions comme une personne présente dans la base de données (en biométrie FAR (faux taux d'accès))
- Erreurs du deuxième type - situations où une personne est dans la base de données, mais nous l'avons manqué. (En biométrie FRR (taux de faux rejet))
Ces erreurs peuvent avoir un certain nombre de fonctionnalités et de critères d'application. Nous en parlerons ci-dessous. En attendant, je vais vous dire où les trouver.
CARACTÉRISTIQUES
La première option . Il était une fois, les fabricants eux-mêmes ont publié des erreurs. Mais voici la chose: vous ne pouvez pas faire confiance au fabricant. Dans quelles conditions et comment il a mesuré ces erreurs - personne ne sait. Et que ce soit mesuré du tout, ou que le service marketing a dessiné.
La deuxième option. Des bases ouvertes sont apparues. Les fabricants ont commencé à indiquer des erreurs sur les bases. L'algorithme peut être affiné pour les bases de données bien connues, afin qu'elles présentent une qualité impressionnante pour elles. Mais en réalité, un tel algorithme peut ne pas fonctionner.
La troisième option est les concours ouverts avec une solution fermée. L'organisateur vérifie la décision. Essentiellement kaggle. Le plus célèbre d'entre eux est
MegaFace . Les premières places dans cette compétition ont donné une grande popularité et renommée. Par exemple, N-Tech et Vocord se sont largement fait un nom sur MegaFace.
Tout irait bien, mais honnêtement. Vous pouvez personnaliser la solution ici. C'est beaucoup plus difficile, plus long. Mais vous pouvez calculer des personnes, vous pouvez marquer manuellement la base, etc. Et surtout - cela n'aura rien à voir avec la façon dont le système fonctionnera sur des données réelles. Vous pouvez voir qui est le leader sur MegaFace maintenant, puis rechercher les solutions de ces gars-là dans le paragraphe suivant.
La quatrième option . À ce jour, le plus honnête. Je ne sais pas comment tricher là-bas. Bien que je ne les exclue pas.
Un grand institut de renommée mondiale accepte de déployer un système de test de solution indépendant. Un SDK est reçu des fabricants, qui est soumis à des tests fermés, auxquels le fabricant ne participe pas. Les tests ont de nombreux paramètres, qui sont ensuite officiellement publiés.
Maintenant, ces
tests sont effectués par le NIST - l'American National Institute of Standards and Technology. Ces tests sont les plus honnêtes et les plus intéressants.
Je dois dire que le NIST fait un excellent travail. Ils ont développé cinq cas, publié de nouvelles mises à jour tous les deux mois, constamment amélioré et inclus de nouveaux fabricants. Vous trouverez ici le dernier numéro de l'étude.
Il semblerait que cette option soit idéale pour l'analyse. Mais non! Le principal inconvénient de cette approche est que nous ne savons pas ce qui se trouve dans la base de données. Regardez ce tableau ici:

Ce sont les données de deux sociétés pour lesquelles des tests ont été effectués. L'axe des x est le mois, y est le pourcentage d'erreurs. J'ai fait le test "Wild faces" (juste en dessous de la description).
Une augmentation soudaine de la précision de 10 fois dans deux sociétés indépendantes (en général, tout le monde y a décollé). D'où?
Le journal du NIST indique que "la base de données était trop compliquée, nous l'avons simplifiée." Et il n'y a aucun exemple de l'ancienne base ou de la nouvelle. À mon avis, c'est une grave erreur. C'est sur l'ancienne base que la différence entre les algorithmes des fournisseurs était visible. Sur le nouveau tous les 4-8% des passes. Et sur l'ancien, c'était de 29 à 90%. Ma communication avec la reconnaissance faciale sur les systèmes de vidéosurveillance dit que 30% plus tôt - c'était le vrai résultat des algorithmes de grand maître. Il est difficile de reconnaître à partir de telles photos:

Et bien sûr, une précision de 4% ne brille pas sur eux. Mais sans voir la base du NIST, il est 100% impossible de faire de telles déclarations. Mais c'est le NIST qui est la principale source de données indépendante.
Dans l'article, je décris la situation pertinente pour juillet 2018. Dans le même temps, je m'appuie sur la précision, selon l'ancienne base de données des personnes pour les tests liés à la tâche «Faces in the wild».
Il est possible que dans six mois, tout change complètement. Ou peut-être que ce sera stable au cours des dix prochaines années.
Donc, nous avons besoin de ce tableau:
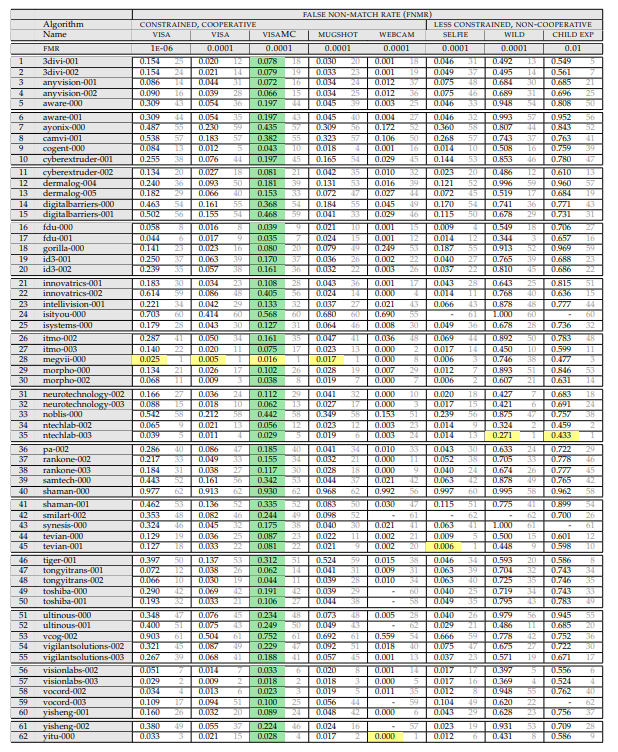
(Avril 2018, car le sauvage est plus adéquat ici)
Voyons ce qui y est écrit et comment il est mesuré.
Ci-dessus, une liste d'expériences. L'expérience consiste en:
Celui sur lequel l'ensemble est mesuré. Les ensembles sont:
- Photo de passeport (idéale, frontale). Le fond est blanc, des systèmes de prise de vue idéaux. Cela peut parfois être trouvé au point de contrôle, mais très rarement. Habituellement, ces tâches sont une comparaison d'une personne à l'aéroport avec la base.

- La photographie est un bon système, mais sans qualité supérieure. Il y a des arrière-plans, une personne peut ne pas se tenir uniformément / regarder devant la caméra, etc.

- Selfies à partir d'un appareil photo smartphone / ordinateur. Lorsque l'utilisateur coopère, mais les conditions de prise de vue sont mauvaises. Il existe deux sous-ensembles, mais ils ne contiennent que beaucoup de photos dans les selfies.

- "Visages à l'état sauvage" - prise de vue de presque n'importe quel côté / prise de vue cachée. Les angles de rotation maximum du visage par rapport à la caméra sont de 90 degrés. C'est là que le NIST a considérablement simplifié la base.

- Les enfants. Tous les algorithmes fonctionnent mal pour les enfants.
De plus, à quel niveau d'erreurs du premier type les erreurs sont mesurées (ce paramètre n'est pris en compte que pour les photos de passeport):
- 10 ^ -4 - FAR (un faux positif du premier type) pour 10 mille comparaisons avec la base
- 10 ^ -6 - FAR (un faux positif du premier type) par million de comparaisons avec la base
Le résultat de l'expérience est la valeur FRR. La probabilité que nous ayons raté la personne qui se trouve dans la base de données.
Et déjà ici, le lecteur attentif a pu remarquer le premier point intéressant. "Que signifie FAR 10 ^ -4?" Et c'est le moment le plus intéressant!
Configuration principale
Que signifie une telle erreur dans la pratique? Cela signifie que sur la base de 10 000 personnes, il y aura une coïncidence erronée lors de la vérification de toute personne moyenne. Autrement dit, si nous avons une base de 1 000 criminels et que nous comparons avec 10 000 personnes par jour, nous aurons en moyenne 1 000 faux positifs. Quelqu'un a-t-il vraiment besoin de cela?
En réalité, tout n'est pas si mal.
Si vous cherchez à construire un graphique de la dépendance d'une erreur du premier type à une erreur du second type, vous obtenez une image tellement cool (ici immédiatement pour une douzaine de sociétés différentes, pour l'option Wild, c'est ce qui se passera à la station de métro si vous placez l'appareil photo quelque part afin que les gens ne le voient pas) :
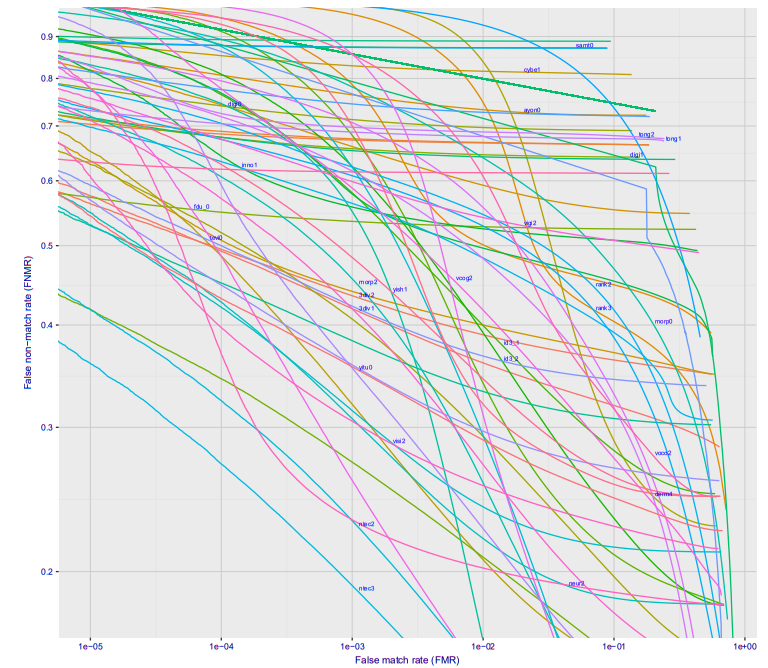
Avec une erreur de 10 ^ -4, 27% des personnes non reconnues. 10 ^ -5 environ 40%. Très probablement, une perte de 10 ^ -6 sera d'environ 50%
Alors qu'est-ce que cela signifie en chiffres réels?
Il vaut mieux passer du paradigme du «combien d’erreurs par jour peuvent être commises». Nous avons un flux de personnes à la station, si toutes les 20-30 minutes le système donne un faux positif, alors personne ne le prendra au sérieux. Nous fixons le nombre autorisé de faux positifs à la station de métro 10 personnes par jour (si c'est bien que le système ne soit pas éteint comme ennuyeux, il en faut encore moins). Le flux d'une station du métro de Moscou
20-120 mille passagers par jour. La moyenne est de 60 000.
Que la valeur fixe de FAR soit 10 ^ -6 (vous ne pouvez pas le mettre ci-dessous, nous perdrons 50% des criminels si nous sommes optimistes). Cela signifie que nous pouvons autoriser 10 fausses alarmes avec une taille de base de 160 personnes.
Est-ce beaucoup ou peu? La taille de la base sur la liste de recherche fédérale est d'environ
300 000 personnes . Interpol 35 mille. Il est logique de supposer qu’environ 30 000 Moscovites sont recherchés.
Cela donnera un nombre irréaliste de fausses alarmes.
Il convient de noter que 160 personnes peuvent constituer une base suffisante si le système fonctionne en ligne. Si vous recherchez ceux qui ont commis un crime au cours de la dernière journée - c'est déjà un volume de travail considérable. En même temps, en portant des lunettes / casquettes noires, etc., vous pouvez vous déguiser. Mais combien les portent dans le métro?
Le deuxième point important. Il est facile de créer un système dans le métro donnant une photo de meilleure qualité. Par exemple, mettez le cadre des caméras de tourniquet. Il n'y aura déjà pas 50% de pertes d'ici 10 ^ -6, mais seulement 2-3%. Et de 10 ^ -7 5-10%. Voici la précision du graphique sur Visa, tout sera certainement bien pire sur de vrais appareils photo, mais je pense qu'à 10 ^ -6 vous pouvez laisser cette perte de 10%:

Encore une fois, le système ne tirera pas la base des 30 000, mais tout ce qui se passe en temps réel permettra la détection.
Premières questions
Il semble temps de répondre à la première partie des questions:
Liksutov a
déclaré que 22 personnes recherchées avaient été identifiées. Est-ce vrai?
Ici, la question principale est de savoir ce que ces personnes ont commis, combien de personnes non recherchées ont été contrôlées, combien la reconnaissance faciale a aidé à la détention de ces 22 personnes.
Très probablement, si ce sont ces personnes que recherchait le plan «d'interception», ce sont vraiment des détenus. Et c'est un bon résultat. Mais mes modestes hypothèses me permettent de dire que pour parvenir à ce résultat, au moins 2-3 mille personnes ont été contrôlées, mais plutôt une dizaine de milliers.
Il bat très bien avec les numéros qui ont été appelés à
Londres . Seulement, ces chiffres sont honnêtement publiés, car les gens
protestent . Et nous sommes silencieux ...
Hier, sur Habré, il y avait un article sur le récit des
faux visages sur la reconnaissance faciale. Mais ceci est un exemple de manipulation en sens inverse. Amazon n'a jamais eu un bon système de reconnaissance faciale. Plus la question de savoir comment fixer des seuils. Je peux au moins faire 100% des arachides en tordant les réglages;)
À propos des Chinois, qui reconnaissent tout le monde dans la rue - un faux évident. Bien que, s'ils ont effectué un suivi compétent, vous pouvez effectuer une analyse plus adéquate. Mais, pour être honnête, je ne pense pas que cela soit réalisable jusqu'à présent. Plutôt, un ensemble de bouchons.
Et ma sécurité? Dans la rue, au rassemblement?
Allons plus loin. Évaluons un autre moment. Recherchez une personne avec une biographie bien connue et un bon profil dans les réseaux sociaux.
Le NIST vérifie la reconnaissance face à face. Deux visages de personnes identiques / différentes sont pris et comparés à quel point ils sont proches les uns des autres. Si la proximité est supérieure au seuil, alors c'est une personne. Si plus loin - différent. Mais il existe une approche différente.
Si vous lisez les articles que j'ai conseillés au début, vous savez que lors de la reconnaissance d'un visage, un code de hachage du visage est généré, qui affiche sa position dans l'espace N-dimensionnel. Il s'agit généralement d'un espace dimensionnel 256/512, bien que tous les systèmes aient des manières différentes.
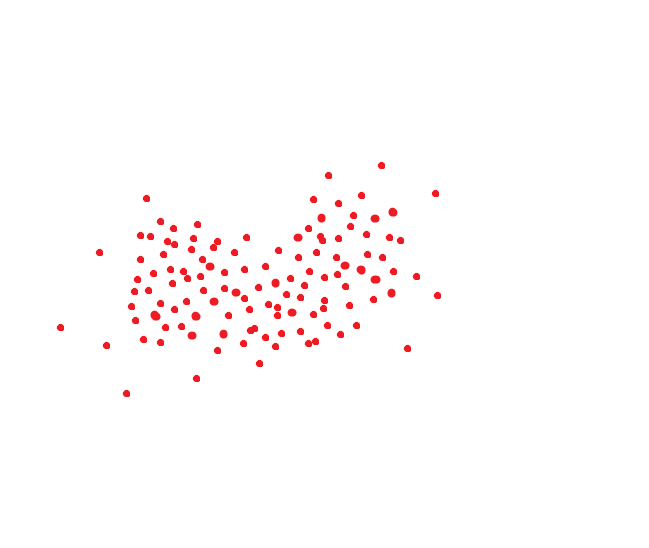
Un système de reconnaissance de visage idéal traduit le même visage dans le même code. Mais il n'y a pas de système idéal. Une seule et même personne occupe généralement une zone d'espace. Eh bien, par exemple, si le code était bidimensionnel, cela pourrait ressembler à ceci:
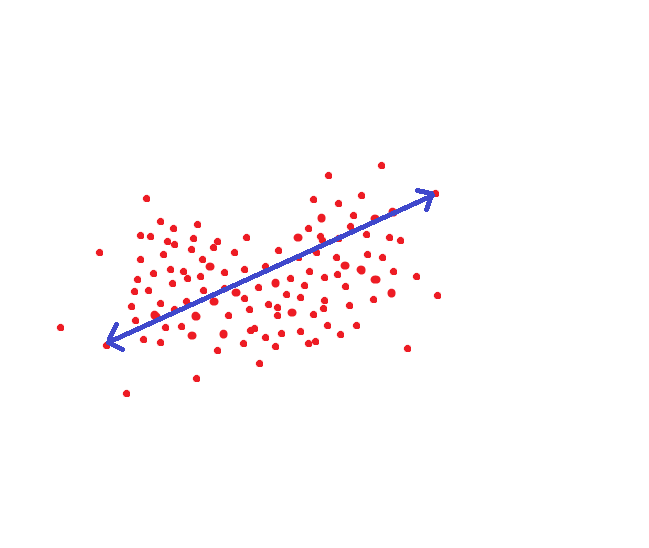
Si nous sommes guidés par la méthode adoptée par le NIST, alors cette distance serait un seuil cible pour que nous puissions reconnaître une personne comme une seule et même personne avec une probabilité de 95%:
Mais vous pouvez faire autrement. Pour chaque personne, configurez la zone d'hyperespace où sont stockées les valeurs qui lui sont valables:

Ensuite, la distance de seuil, tout en maintenant la précision, diminuera de plusieurs fois.
Seulement, nous avons besoin de beaucoup de photos pour chaque personne.
Si une personne a un profil sur les réseaux sociaux / la base de ses photos d'âges différents, la précision de reconnaissance peut être considérablement augmentée. Je ne connais pas l'évaluation exacte de la croissance de FAR | FRR. Et il est déjà incorrect d'évaluer de telles quantités. Quelqu'un dans cette base de données a 2 photos, quelqu'un en a 100. Beaucoup de logique d'emballage. Il me semble que la note maximale est une / une et demie. Cela vous permet d'ajouter 10 ^ -7 aux erreurs avec une probabilité de ne pas reconnaître 20-30%. Mais c'est spéculatif et optimiste.
En général, bien sûr, il y a beaucoup de problèmes avec la gestion de cet espace (puces d'âge, puces d'édition d'image, puces de bruit, puces de netteté), mais si je comprends bien, la plupart d'entre elles ont déjà été résolues avec succès par de grandes entreprises qui avaient besoin d'une solution.
Pourquoi je fais ça. De plus, l'utilisation de profils permet à plusieurs reprises d'augmenter la précision des algorithmes de reconnaissance. Mais c'est loin d'être absolu. Les profils nécessitent beaucoup de travail manuel. Il y a beaucoup de gens similaires. Mais si vous commencez à définir des restrictions sur l'âge, l'emplacement, etc., cette méthode vous permet d'obtenir une bonne solution. Pour un exemple de la façon dont ils ont trouvé une personne sur le principe "trouver le profil par photo" -> "utiliser le profil pour rechercher une personne", j'ai donné un
lien au début.
Mais, à mon avis, il s'agit d'un processus hautement évolutif. Et, encore une fois, les gens avec un grand nombre de photos dans le profil, Dieu nous en préserve 40-50% dans notre pays. Oui, et beaucoup d'entre eux sont des enfants pour lesquels tout fonctionne mal.
Mais, encore une fois - c'est une évaluation.
Alors voilà. À propos de votre sécurité. Moins vous avez de photos de profil, mieux c'est. Plus le rallye où vous allez est grand, mieux c'est. Personne n'analysera manuellement 20 000 photos. Pour ceux qui se soucient de leur sécurité et de leur vie privée - je vous conseillerais de ne pas faire de profils avec vos photos.
Lors d'un rassemblement dans une ville de 100 000 habitants, ils vous trouveront facilement en regardant 1-2 matchs. A Moscou, ils se coincent un peu. Il y a environ
six mois ,
Vasyutka , avec qui nous travaillons ensemble, a donné une conférence sur ce sujet:
Au fait, sur les réseaux sociaux
Puis je me permets de faire une petite excursion sur le côté. La qualité de la formation pour l'algorithme de reconnaissance faciale dépend de trois facteurs:
- La qualité du visage.
- Mesure utilisée de la proximité des personnes lors de la formation Perte de triplet, Perte centrale, Perte sphérique, etc.
- Taille de base
Selon la revendication 2, il semble que la limite soit maintenant atteinte. En principe, les mathématiques se développent très rapidement sur de telles choses. Et même après la perte du triplet, le reste des fonctions de perte n'a pas produit une augmentation spectaculaire, seulement une amélioration en douceur et une diminution de la taille de la base.
L'extraction des visages est difficile si vous devez trouver des visages sous tous les angles, ayant perdu une fraction de pour cent. Mais la création d'un tel algorithme est un processus assez prévisible et bien géré. Plus tout est bleu, mieux les grands angles sont traités correctement:

Et il y a six mois, c'était comme ça:

On peut voir que de plus en plus d'entreprises évoluent lentement de cette façon, les algorithmes commencent à reconnaître de plus en plus de visages tournés.
Mais avec la taille de la base - tout est plus intéressant. Les bases ouvertes sont petites. De bonnes bases pour un maximum de quelques dizaines de milliers de personnes. Ceux qui sont gros sont étrangement structurés / mauvais (
mégaface ,
MS-Celeb-1M ).
Où pensez-vous que les créateurs des algorithmes ont obtenu ces bases de données?
Petit indice. Le premier produit NTech qu'ils déploient actuellement est Find Face, une recherche de personnes à contacts. Je pense qu'aucune explication n'est nécessaire. Bien sûr, le contact se bat avec des bots qui dégonflent tous les profils ouverts. Mais, d'après ce que j'ai entendu, les gens tremblent encore. Et mes camarades de classe. Et instagram.
On dirait qu'avec Facebook - tout y est plus compliqué. Mais je suis presque sûr que quelque chose a également été inventé.
Alors oui, si votre profil est ouvert - vous pouvez en être fier, il a été utilisé pour apprendre des algorithmes;)
À propos des solutions et des entreprises
Ici, vous pouvez être fier. Sur les 5 premières entreprises mondiales, deux sont désormais russes. Ce sont N-Tech et VisionLabs. Il y a six mois, NTech et Vocord étaient les leaders, les premiers fonctionnaient beaucoup mieux sur les faces tournées, les seconds sur les fronts.
Maintenant, le reste des leaders - 1-2 entreprises chinoises et 1 américaine, Vocord a réussi quelque chose dans les notes.
Toujours russe dans le classement de itmo, 3divi, intellivision. Synesis est une entreprise biélorusse, même si certains étaient à Moscou, il y a environ 3 ans, ils avaient un blog sur Habré. Je connais également plusieurs solutions qui appartiennent à des sociétés étrangères, mais les bureaux de développement sont également en Russie. Il existe encore plusieurs entreprises russes qui ne sont pas en compétition, mais qui semblent avoir de bonnes solutions. Par exemple, les OMD ont. De toute évidence, Odnoklassniki et Vkontakte ont également leurs propres bons, mais ils sont à usage interne.
En bref, oui, nous et les Chinois sommes pour la plupart décalés sur nos visages.
NTech a été généralement le premier au monde à afficher de bonnes performances à un nouveau niveau. Quelque part
fin 2015 . VisionLabs a rattrapé NTech uniquement. En 2015, ils étaient leaders du marché. Mais leur solution était de la dernière génération, et ils n'ont commencé à rattraper NTech qu'à la fin de 2016.
Pour être honnête, je n'aime pas ces deux sociétés. Marketing très agressif. J'ai vu des gens qui avaient une solution clairement inappropriée qui n'a pas résolu leurs problèmes.
De ce côté, j'aimais beaucoup plus Vocord. D'une manière ou d'une autre, il a conseillé aux gars à qui Vokord a dit très honnêtement "votre projet ne fonctionnera pas avec de telles caméras et points d'installation." NTech et VisionLabs ont heureusement essayé de vendre. Mais quelque chose que Vokord a récemment disparu.
Conclusions
Dans les conclusions, je veux dire ce qui suit. . . .
OpenSource . ( ), VisionLabs|Ntech, , . OpenSource .
, , . , . , . , . , — . - .